يواجه العملاء تهديدات أمنية ونقاط ضعف متزايدة عبر البنية التحتية وموارد التطبيقات مع توسع بصمتهم الرقمية ونمو التأثير التجاري لهذه الأصول الرقمية. يتمثل التحدي المشترك للأمن السيبراني في شقين:
- استهلاك السجلات من الموارد الرقمية التي تأتي بتنسيقات ومخططات مختلفة وأتمتة تحليل نتائج التهديدات بناءً على تلك السجلات.
- سواء كانت السجلات تأتي من Amazon Web Services (AWS) أو موفري الخدمات السحابية الآخرين أو الأجهزة المحلية أو الأجهزة الطرفية، يحتاج العملاء إلى مركزية وتوحيد بيانات الأمان.
علاوة على ذلك، يجب أن تكون التحليلات لتحديد التهديدات الأمنية قادرة على التوسع والتطور لتلبية المشهد المتغير للجهات الفاعلة في مجال التهديد، وناقلات الأمن، والأصول الرقمية.
يجمع النهج الجديد لحل هذا السيناريو المعقد لتحليلات الأمان بين استيعاب البيانات الأمنية وتخزينها باستخدام بحيرة أمان أمازون وتحليل البيانات الأمنية باستخدام التعلم الآلي (ML). الأمازون SageMaker. Amazon Security Lake هي خدمة مصممة خصيصًا لهذا الغرض، حيث تقوم تلقائيًا بمركزية بيانات أمان المؤسسة من المصادر السحابية والمحلية في بحيرة بيانات مخصصة لهذا الغرض ومخزنة في حساب AWS الخاص بك. تعمل Amazon Security Lake على أتمتة الإدارة المركزية لبيانات الأمان، وتطبيع السجلات من خدمات AWS المتكاملة وخدمات الطرف الثالث، وتدير دورة حياة البيانات مع الاحتفاظ القابل للتخصيص، كما تعمل أيضًا على أتمتة طبقات التخزين. تستوعب Amazon Security Lake ملفات السجل في ملف فتح إطار مخطط الأمن السيبراني (OCSF)، مع دعم للشركاء مثل Cisco Security، وCrowdStrike، وPalo Alto Networks، وسجلات OCSF من موارد خارج بيئة AWS الخاصة بك. يعمل هذا المخطط الموحد على تبسيط الاستهلاك والتحليلات النهائية لأن البيانات تتبع مخططًا موحدًا ويمكن إضافة مصادر جديدة بأقل قدر من التغييرات في تدفق البيانات. بعد تخزين بيانات سجل الأمان في Amazon Security Lake، يصبح السؤال هو كيفية تحليلها. الطريقة الفعالة لتحليل بيانات سجل الأمان هي استخدام التعلم الآلي؛ على وجه التحديد، الكشف عن الحالات الشاذة، الذي يفحص بيانات النشاط وحركة المرور ويقارنها بخط الأساس. يحدد خط الأساس النشاط الطبيعي إحصائيًا لتلك البيئة. يتجاوز اكتشاف الحالات الشاذة توقيع حدث فردي، ويمكن أن يتطور مع إعادة التدريب الدوري؛ يمكن بعد ذلك التعامل مع حركة المرور المصنفة على أنها غير طبيعية أو شاذة مع التركيز على الأولوية والإلحاح. Amazon SageMaker هي خدمة مُدارة بالكامل تمكن العملاء من إعداد البيانات وإنشاء نماذج تعلم الآلة وتدريبها ونشرها لأي حالة استخدام مع بنية تحتية وأدوات وسير عمل مُدارة بالكامل، بما في ذلك العروض بدون تعليمات برمجية لمحللي الأعمال. يدعم SageMaker خوارزميتين مدمجتين للكشف عن الحالات الشاذة: رؤى الملكية الفكرية و قطع الغابة العشوائية. يمكنك أيضًا استخدام SageMaker لإنشاء نموذج الكشف عن القيم الخارجية المخصص الخاص بك باستخدام خوارزميات مصدرها أطر تعلم الآلة المتعددة.
في هذا المنشور، ستتعرف على كيفية إعداد البيانات التي يتم الحصول عليها من Amazon Security Lake، ثم تدريب نموذج التعلم الآلي ونشره باستخدام خوارزمية IP Insights في SageMaker. يحدد هذا النموذج حركة مرور الشبكة أو السلوك الشاذ الذي يمكن بعد ذلك تكوينه كجزء من حل أمني أكبر من طرف إلى طرف. يمكن لمثل هذا الحل استدعاء التحقق من المصادقة متعددة العوامل (MFA) إذا كان المستخدم يسجل الدخول من خادم غير عادي أو في وقت غير عادي، وإخطار الموظفين إذا كان هناك فحص مشبوه للشبكة قادم من عناوين IP جديدة، وتنبيه المسؤولين إذا كانت الشبكة غير عادية يتم استخدام البروتوكولات أو المنافذ، أو إثراء نتيجة تصنيف رؤى IP بمصادر بيانات أخرى مثل واجب الحرس الأمازون ونتائج سمعة IP لترتيب نتائج التهديدات.
حل نظرة عامة
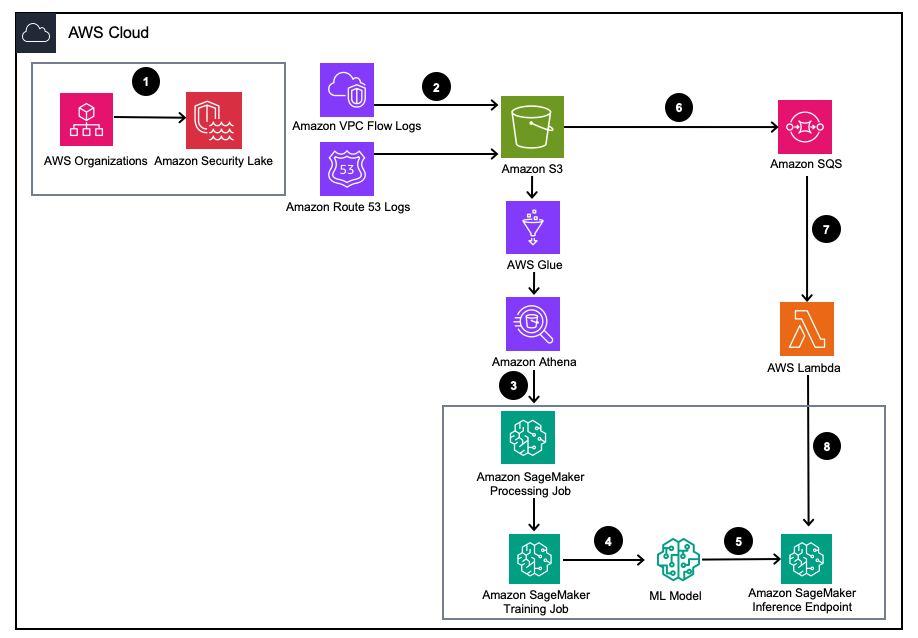
الشكل 1 - هندسة الحلول
- تمكين بحيرة الأمن الأمازون مع منظمات AWS لحسابات AWS ومناطق AWS وبيئات تكنولوجيا المعلومات الخارجية.
- قم بإعداد مصادر Security Lake من سحابة أمازون الافتراضية الخاصة (Amazon VPC) سجلات التدفق و أمازون روت 53 تسجل DNS إلى مجموعة Amazon Security Lake S3.
- قم بمعالجة بيانات سجل Amazon Security Lake باستخدام مهمة معالجة SageMaker لتصميم الميزات. يستخدم أمازون أثينا للاستعلام عن بيانات سجل OCSF المنظمة من خدمة Amazon Simple Storage (Amazon S3) من خلال غراء AWS الجداول التي تديرها AWS LakeFormation.
- قم بتدريب نموذج SageMaker ML باستخدام مهمة تدريب SageMaker التي تستهلك سجلات Amazon Security Lake المعالجة.
- انشر نموذج تعلم الآلة الذي تم تدريبه على نقطة نهاية استدلال SageMaker.
- قم بتخزين سجلات الأمان الجديدة في حاوية S3 وقائمة الانتظار للأحداث فيها خدمة Amazon Simple Queue Service (Amazon SQS).
- اشترك ان AWS لامدا وظيفة إلى قائمة انتظار SQS.
- قم باستدعاء نقطة نهاية استنتاج SageMaker باستخدام دالة Lambda لتصنيف سجلات الأمان على أنها حالات شاذة في الوقت الفعلي.
المتطلبات الأساسية المسبقة
لنشر الحل، يجب عليك أولاً إكمال المتطلبات الأساسية التالية:
- تمكين بحيرة الأمن الأمازون داخل مؤسستك أو حساب واحد مع تمكين كل من سجلات تدفق VPC وسجلات محلل الطريق 53.
- تأكد من أن إدارة الهوية والوصول (IAM) AWS تم منح الدور الذي تستخدمه مهام معالجة SageMaker ودفاتر الملاحظات سياسة IAM بما في ذلك إذن الوصول للاستعلام عن المشتركين في Amazon Security Lake لقاعدة بيانات Amazon Security Lake المُدارة والجداول المُدارة بواسطة AWS Lake Formation. يجب تشغيل مهمة المعالجة هذه من داخل حساب التحليلات أو أدوات الأمان لتظل متوافقة معها البنية المرجعية لأمان AWS (AWS SRA).
- تأكد من أن دور IAM الذي تستخدمه وظيفة Lambda قد تم منحه سياسة IAM بما في ذلك إذن الوصول إلى بيانات المشتركين في Amazon Security Lake.
انشر الحل
لإعداد البيئة ، أكمل الخطوات التالية:
- إطلاق استوديو SageMaker أو دفتر SageMaker Jupyter المزود بملحق
ml.m5.largeحتة. ملحوظة: يعتمد حجم المثيل على مجموعات البيانات التي تستخدمها. - استنساخ جيثب مستودع.
- افتح دفتر الملاحظات
01_ipinsights/01-01.amazon-securitylake-sagemaker-ipinsights.ipy. - تنفيذ سياسة IAM المقدمة و سياسة الثقة المقابلة لـ IAM لمثيل SageMaker Studio Notebook الخاص بك للوصول إلى جميع البيانات الضرورية في S3 وLake Formation وAthena.
تتنقل هذه المدونة عبر الجزء ذي الصلة من التعليمات البرمجية داخل دفتر الملاحظات بعد نشره في بيئتك.
قم بتثبيت التبعيات واستيراد المكتبة المطلوبة
استخدم التعليمة البرمجية التالية لتثبيت التبعيات، واستيراد المكتبات المطلوبة، وإنشاء مجموعة SageMaker S3 اللازمة لمعالجة البيانات والتدريب على النماذج. إحدى المكتبات المطلوبة awswrangler، هو AWS SDK لإطار بيانات الباندا يتم استخدامه للاستعلام عن الجداول ذات الصلة داخل كتالوج بيانات AWS Glue وتخزين النتائج محليًا في إطار بيانات.
استعلم عن جدول سجل تدفق Amazon Security Lake VPC
يستخدم هذا الجزء من التعليمات البرمجية AWS SDK للباندا للاستعلام عن جدول AWS Glue المرتبط بسجلات تدفق VPC. كما هو مذكور في المتطلبات الأساسية، تتم إدارة جداول Amazon Security Lake بواسطة تكوين بحيرة AWS، لذلك يجب منح جميع الأذونات المناسبة للدور الذي يستخدمه دفتر ملاحظات SageMaker. سيسحب هذا الاستعلام عدة أيام من حركة مرور سجل تدفق VPC. كانت مجموعة البيانات المستخدمة أثناء تطوير هذه المدونة صغيرة. اعتمادًا على حجم حالة الاستخدام الخاصة بك، يجب أن تكون على دراية بحدود AWS SDK للباندا. عند التفكير في حجم التيرابايت، يجب عليك التفكير في AWS SDK لدعم الباندا مودين.
عندما تقوم بعرض إطار البيانات، سترى مخرجات عمود واحد يحتوي على حقول مشتركة يمكن العثور عليها في نشاط الشبكة (4001) فئة OCSF.
قم بتطبيع بيانات سجل تدفق Amazon Security Lake VPC إلى تنسيق التدريب المطلوب لـ IP Insights.
تتطلب خوارزمية IP Insights أن تكون بيانات التدريب بتنسيق CSV وتحتوي على عمودين. يجب أن يكون العمود الأول عبارة عن سلسلة غير شفافة تتوافق مع المعرف الفريد للكيان. يجب أن يكون العمود الثاني هو عنوان IPv4 لحدث وصول الكيان بتدوين النقطة العشرية. في نموذج مجموعة البيانات لهذه المدونة، المعرف الفريد هو معرفات المثيلات الخاصة بمثيلات EC2 المرتبطة بـ instance_id القيمة داخل dataframe. سيتم اشتقاق عنوان IPv4 من src_endpoint. استنادًا إلى الطريقة التي تم بها إنشاء استعلام Amazon Athena، فإن البيانات المستوردة موجودة بالفعل بالتنسيق الصحيح لتدريب نموذج IP Insights، لذلك لا يلزم هندسة ميزات إضافية. إذا قمت بتعديل الاستعلام بطريقة أخرى، فقد تحتاج إلى دمج هندسة ميزات إضافية.
الاستعلام عن جدول سجل محلل Amazon Security Lake Route 53 وتطبيعه
تمامًا كما فعلت أعلاه، تقوم الخطوة التالية من دفتر الملاحظات بتشغيل استعلام مماثل مقابل جدول محلل Amazon Security Lake Route 53. نظرًا لأنك ستستخدم جميع البيانات المتوافقة مع OCSF داخل دفتر الملاحظات هذا، فإن أي مهام هندسية للميزات تظل كما هي بالنسبة لسجلات محلل الطريق 53 كما كانت بالنسبة لسجلات تدفق VPC. يمكنك بعد ذلك دمج إطاري البيانات في إطار بيانات واحد يُستخدم للتدريب. نظرًا لأن استعلام Amazon Athena يقوم بتحميل البيانات محليًا بالتنسيق الصحيح، فلا يلزم إجراء المزيد من هندسة الميزات.
احصل على صورة تدريب IP Insights وقم بتدريب النموذج باستخدام بيانات OCSF
في هذا الجزء التالي من دفتر الملاحظات، يمكنك تدريب نموذج تعلم الآلة استنادًا إلى خوارزمية IP Insights واستخدام dataframe OCSF من أنواع مختلفة من السجلات. يمكن العثور على قائمة بمقاييس IP Insights الفائقة هنا. في المثال أدناه، قمنا بتحديد المعلمات الفائقة التي أنتجت النموذج الأفضل أداءً، على سبيل المثال، 5 للعصر و128 لـ Vector_dim. نظرًا لأن مجموعة بيانات التدريب لعينتنا كانت صغيرة نسبيًا، فقد استخدمنا ml.m5.large مثال. يجب اختيار المعلمات الفائقة وتكوينات التدريب الخاصة بك مثل عدد المثيلات ونوع المثيل بناءً على مقاييسك الموضوعية وحجم بيانات التدريب الخاصة بك. إحدى الإمكانيات التي يمكنك الاستفادة منها داخل Amazon SageMaker للعثور على أفضل إصدار من النموذج الخاص بك هي Amazon SageMaker ضبط تلقائي للنموذج يبحث عن أفضل نموذج عبر مجموعة من قيم المعلمات الفائقة.
انشر النموذج المُدرب واختبره مع حركة المرور الصالحة والشاذة
بعد تدريب النموذج، يمكنك نشر النموذج إلى نقطة نهاية SageMaker وإرسال سلسلة من المعرفات الفريدة ومجموعات عناوين IPv4 لاختبار النموذج الخاص بك. يفترض هذا الجزء من التعليمات البرمجية أن لديك بيانات اختبار محفوظة في حاوية S3 الخاصة بك. بيانات الاختبار عبارة عن ملف بتنسيق .csv، حيث يكون العمود الأول عبارة عن معرفات المثيلات والعمود الثاني عبارة عن عناوين IP. يوصى باختبار البيانات الصحيحة وغير الصالحة لمعرفة نتائج النموذج. تنشر التعليمة البرمجية التالية نقطة النهاية الخاصة بك.
الآن بعد أن تم نشر نقطة النهاية الخاصة بك، يمكنك الآن إرسال طلبات الاستدلال لتحديد ما إذا كان من المحتمل أن تكون حركة المرور غير طبيعية. فيما يلي نموذج لما يجب أن تبدو عليه بياناتك المنسقة. في هذه الحالة، يكون معرف العمود الأول عبارة عن معرف مثيل والعمود الثاني هو عنوان IP مرتبط كما هو موضح في ما يلي:
بعد حصولك على بياناتك بتنسيق CSV، يمكنك إرسال البيانات للاستدلال باستخدام الكود من خلال قراءة ملف .csv الخاص بك من حاوية S3.:
توفر مخرجات نموذج IP Insights مقياسًا لمدى التوقعات الإحصائية لعنوان IP والمورد عبر الإنترنت. ومع ذلك، فإن نطاق هذا العنوان وهذا المورد غير محدود، لذلك هناك اعتبارات حول كيفية تحديد ما إذا كان يجب اعتبار مجموعة معرف المثيل وعنوان IP غير طبيعية.
في المثال السابق، تم إرسال أربع مجموعات مختلفة من المعرفات وIP إلى النموذج. كانت المجموعتان الأوليتان عبارة عن مجموعات صالحة لمعرف المثيل وعناوين IP المتوقعة بناءً على مجموعة التدريب. تحتوي المجموعة الثالثة على المعرف الفريد الصحيح ولكن لها عنوان IP مختلف داخل نفس الشبكة الفرعية. يجب أن يحدد النموذج وجود شذوذ متواضع حيث أن التضمين يختلف قليلاً عن بيانات التدريب. تحتوي المجموعة الرابعة على معرف فريد صالح ولكن لها عنوان IP لشبكة فرعية غير موجودة داخل أي VPC في البيئة.
ملحوظة: ستتغير بيانات حركة المرور العادية وغير العادية بناءً على حالة الاستخدام المحددة لديك، على سبيل المثال: إذا كنت تريد مراقبة حركة المرور الخارجية والداخلية، فستحتاج إلى معرف فريد يتماشى مع كل عنوان IP ونظام لإنشاء المعرفات الخارجية.
لتحديد ما يجب أن يكون عليه الحد الخاص بك لتحديد ما إذا كانت حركة المرور غير طبيعية، يمكنك القيام بذلك باستخدام حركة المرور العادية وغير الطبيعية المعروفة. الخطوات الموضحة في هذا دفتر العينة هي كما يلي:
- إنشاء مجموعة اختبار لتمثيل حركة المرور العادية.
- أضف حركة مرور غير طبيعية إلى مجموعة البيانات.
- رسم توزيع
dot_productدرجات للنموذج على حركة المرور العادية وحركة المرور غير الطبيعية. - حدد قيمة العتبة التي تميز المجموعة الفرعية العادية عن المجموعة الفرعية غير الطبيعية. تعتمد هذه القيمة على التسامح الإيجابي الكاذب
قم بإعداد مراقبة مستمرة لحركة مرور سجل تدفق VPC الجديد.
لتوضيح كيفية استخدام نموذج تعلم الآلة الجديد هذا مع Amazon Security Lake بطريقة استباقية، سنقوم بتكوين وظيفة Lambda ليتم استدعاؤها في كل PutObject حدث داخل حاوية Amazon Security Lake المُدارة، وتحديدًا بيانات سجل تدفق VPC. يوجد داخل Amazon Security Lake مفهوم المشترك الذي يستهلك السجلات والأحداث من Amazon Security Lake. يجب منح وظيفة Lambda التي تستجيب للأحداث الجديدة اشتراكًا للوصول إلى البيانات. يتم إخطار المشتركين في الوصول إلى البيانات بكائنات Amazon S3 الجديدة لمصدر ما حيث تتم كتابة الكائنات في حاوية Security Lake. يمكن للمشتركين الوصول مباشرة إلى كائنات S3 وتلقي إشعارات بالكائنات الجديدة من خلال نقطة نهاية الاشتراك أو عن طريق استقصاء قائمة انتظار Amazon SQS.
- فتح وحدة تحكم بحيرة الأمن.
- في جزء التنقل، حدد عدد المشتركين.
- في صفحة المشتركين، اختر إنشاء مشترك.
- للحصول على تفاصيل المشترك، أدخل
inferencelambdaFor اسم المشترك واختياري الوصف. - • بلد المنشأ يتم تعيينها تلقائيًا على أنها منطقة AWS المحددة حاليًا ولا يمكن تعديلها.
- في حالة مصادر السجل والأحداث، اختر مصادر محددة للسجلات والأحداث واختر سجلات تدفق VPC وسجلات المسار 53
- في حالة طريقة الوصول إلى البيانات، اختر S3.
- في حالة بيانات اعتماد المشترك، قم بتوفير معرف حساب AWS الخاص بك للحساب الذي ستتواجد فيه وظيفة Lambda والحساب الذي يحدده المستخدم معرف خارجي.
ملحوظة: إذا قمت بذلك محليًا داخل الحساب، فلن تحتاج إلى معرف خارجي. - اختار إنشاء.
قم بإنشاء وظيفة Lambda
لإنشاء وظيفة Lambda ونشرها، يمكنك إما إكمال الخطوات التالية أو نشر قالب SAM الذي تم إنشاؤه مسبقًا 01_ipinsights/01.02-ipcheck.yaml في جيثب الريبو. يتطلب قالب SAM توفير SQS ARN واسم نقطة نهاية SageMaker.
- في وحدة تحكم لامدا ، اختر خلق وظيفة.
- اختار مؤلف من الصفر.
- في حالة اسم الوظيفة، أدخل
ipcheck. - في حالة وقت التشغيل، اختر بيثون 3.10.
- في حالة معمار، حدد x86_64.
- في حالة دور التنفيذ، حدد أنشئ دورًا جديدًا باستخدام أذونات Lambda.
- بعد إنشاء الوظيفة، أدخل محتويات الملف ipcheck.py ملف من جيثب الريبو.
- في جزء التنقل ، اختر متغيرات البيئة.
- اختار تعديل.
- اختار أضف متغير البيئة.
- لمتغير البيئة الجديد، أدخل
ENDPOINT_NAMEوللحصول على القيمة، أدخل ARN لنقطة النهاية التي تم إخراجها أثناء نشر نقطة نهاية SageMaker. - أختار حفظ.
- اختار نشر.
- في جزء التنقل ، اختر الاعداد.
- أختار مشغلات.
- أختار إضافة الزناد.
- تحت اختر المصدر، اختر SQS.
- تحت قائمة انتظار SQS، أدخل ARN لقائمة انتظار SQS الرئيسية التي أنشأتها Security Lake.
- حدد خانة الاختيار لـ تنشيط الزناد.
- أختار أضف.
التحقق من صحة نتائج لامدا
- فتح وحدة تحكم Amazon CloudWatch.
- في الجزء الأيمن، حدد مجموعات السجل.
- في شريط البحث، أدخل ipcheck، ثم حدد مجموعة السجل بالاسم
/aws/lambda/ipcheck. - حدد أحدث دفق سجل ضمن سجل التدفقات.
- ضمن السجلات، من المفترض أن ترى النتائج التي تبدو كما يلي لكل سجل Amazon Security Lake جديد:
{'predictions': [{'dot_product': 0.018832731992006302}, {'dot_product': 0.018832731992006302}]}
تعمل وظيفة Lambda هذه باستمرار على تحليل حركة مرور الشبكة التي يتم استيعابها بواسطة Amazon Security Lake. يتيح لك هذا إنشاء آليات لإخطار فرق الأمان لديك عند انتهاك حد معين، مما يشير إلى وجود حركة مرور شاذة في بيئتك.
تنظيف
عند الانتهاء من تجربة هذا الحل ولتجنب فرض رسوم على حسابك، قم بتنظيف مواردك عن طريق حذف حاوية S3 ونقطة نهاية SageMaker وإيقاف تشغيل الحوسبة المرفقة بدفتر ملاحظات SageMaker Jupyter وحذف وظيفة Lambda وتعطيل Amazon Security لايك في حسابك.
وفي الختام
تعلمت في هذا المنشور كيفية إعداد بيانات حركة مرور الشبكة التي يتم الحصول عليها من Amazon Security Lake للتعلم الآلي، ثم قمت بتدريب ونشر نموذج تعلم الآلة باستخدام خوارزمية IP Insights في Amazon SageMaker. يمكن تكرار جميع الخطوات الموضحة في دفتر Jupyter في مسار تعلم الآلة الشامل. لقد قمت أيضًا بتنفيذ وظيفة AWS Lambda التي استهلكت سجلات Amazon Security Lake الجديدة وأرسلت استنتاجات بناءً على نموذج الكشف عن الحالات الشاذة المُدرب. يمكن لاستجابات نموذج تعلم الآلة التي تتلقاها AWS Lambda إخطار فرق الأمان بشكل استباقي بحركة المرور الشاذة عند استيفاء حدود معينة. يمكن تمكين التحسين المستمر للنموذج من خلال تضمين فريق الأمان الخاص بك في مراجعات الحلقة لتحديد ما إذا كانت حركة المرور التي تم تحديدها على أنها شاذة كانت إيجابية كاذبة أم لا. ويمكن بعد ذلك إضافتها إلى مجموعة التدريب الخاصة بك وإضافتها أيضًا إلى مجموعة التدريب الخاصة بك عادي مجموعة بيانات حركة المرور عند تحديد عتبة تجريبية. يمكن لهذا النموذج تحديد حركة مرور الشبكة أو السلوك الشاذ المحتمل حيث يمكن تضمينه كجزء من حل أمني أكبر لبدء فحص MFA إذا كان المستخدم يسجل الدخول من خادم غير عادي أو في وقت غير عادي، وتنبيه الموظفين إذا كان هناك أمر مريب فحص الشبكة من عناوين IP الجديدة، أو دمج نقاط رؤى IP مع مصادر أخرى مثل Amazon Guard Duty لتصنيف نتائج التهديدات. يمكن أن يتضمن هذا النموذج مصادر سجل مخصصة مثل Azure Flow Logs أو السجلات المحلية عن طريق إضافة مصادر مخصصة إلى نشر Amazon Security Lake الخاص بك.
في الجزء الثاني من سلسلة منشورات المدونة هذه، ستتعلم كيفية إنشاء نموذج للكشف عن الحالات الشاذة باستخدام قطع الغابة العشوائية تم تدريب الخوارزمية باستخدام مصادر Amazon Security Lake الإضافية التي تدمج بيانات سجل أمان الشبكة والمضيف وتطبق تصنيف العيوب الأمنية كجزء من حل تلقائي وشامل لمراقبة الأمان.
عن المؤلفين
 جو موروتي مهندس حلول في Amazon Web Services (AWS) ، يساعد عملاء المؤسسات في جميع أنحاء الغرب الأوسط بالولايات المتحدة. لقد شغل مجموعة واسعة من الأدوار الفنية ويستمتع بإظهار فن العميل الممكن. في أوقات فراغه ، يستمتع بقضاء وقت ممتع مع عائلته في استكشاف أماكن جديدة والإفراط في تحليل أداء فريقه الرياضي
جو موروتي مهندس حلول في Amazon Web Services (AWS) ، يساعد عملاء المؤسسات في جميع أنحاء الغرب الأوسط بالولايات المتحدة. لقد شغل مجموعة واسعة من الأدوار الفنية ويستمتع بإظهار فن العميل الممكن. في أوقات فراغه ، يستمتع بقضاء وقت ممتع مع عائلته في استكشاف أماكن جديدة والإفراط في تحليل أداء فريقه الرياضي
 بشر الطباع مهندس حلول في Amazon Web Services. بشر متخصصة في مساعدة العملاء في تطبيقات التعلم الآلي والأمان والمراقبة. خارج العمل ، يستمتع بلعب التنس والطهي وقضاء الوقت مع العائلة.
بشر الطباع مهندس حلول في Amazon Web Services. بشر متخصصة في مساعدة العملاء في تطبيقات التعلم الآلي والأمان والمراقبة. خارج العمل ، يستمتع بلعب التنس والطهي وقضاء الوقت مع العائلة.
 سريهارش أداري هو مهندس حلول أول في Amazon Web Services (AWS) ، حيث يساعد العملاء على العمل بشكل عكسي من نتائج الأعمال لتطوير حلول مبتكرة على AWS. على مر السنين ، ساعد العديد من العملاء في تحويلات منصة البيانات عبر قطاعات الصناعة. تشمل مجالات خبرته الأساسية استراتيجية التكنولوجيا وتحليلات البيانات وعلوم البيانات. في أوقات فراغه ، يستمتع بلعب التنس ومشاهدة البرامج التلفزيونية بنهم ولعب الطبلة.
سريهارش أداري هو مهندس حلول أول في Amazon Web Services (AWS) ، حيث يساعد العملاء على العمل بشكل عكسي من نتائج الأعمال لتطوير حلول مبتكرة على AWS. على مر السنين ، ساعد العديد من العملاء في تحويلات منصة البيانات عبر قطاعات الصناعة. تشمل مجالات خبرته الأساسية استراتيجية التكنولوجيا وتحليلات البيانات وعلوم البيانات. في أوقات فراغه ، يستمتع بلعب التنس ومشاهدة البرامج التلفزيونية بنهم ولعب الطبلة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/identify-cybersecurity-anomalies-in-your-amazon-security-lake-data-using-amazon-sagemaker/

