حديقة الحيوان الرقمية توفر خدمات الترجمة والوسائط الشاملة لتكييف محتوى التلفزيون والأفلام الأصلي مع اللغات والمناطق والثقافات المختلفة. إنها تجعل العولمة أسهل بالنسبة لأفضل منشئي المحتوى في العالم. تحظى ZOO Digital بثقة أكبر الأسماء في مجال الترفيه، وتوفر خدمات الترجمة والوسائط عالية الجودة على نطاق واسع، بما في ذلك الدبلجة والترجمة النصية والنصوص والامتثال.
تتطلب عمليات سير عمل الترجمة النموذجية تسجيلًا يدويًا للمكبر، حيث يتم تجزئة التدفق الصوتي بناءً على هوية المتحدث. يجب إكمال هذه العملية التي تستغرق وقتًا طويلاً قبل أن تتم دبلجة المحتوى إلى لغة أخرى. باستخدام الطرق اليدوية، يمكن أن تستغرق الحلقة التي تبلغ مدتها 30 دقيقة ما بين 1-3 ساعات لترجمتها. من خلال الأتمتة، تهدف ZOO Digital إلى تحقيق الترجمة في أقل من 30 دقيقة.
في هذا المنشور، نناقش نشر نماذج التعلم الآلي (ML) القابلة للتطوير لتدوين محتوى الوسائط باستخدام الأمازون SageMaker، مع التركيز على WhisperX نموذج.
خلفيّة
تتمثل رؤية ZOO Digital في توفير تحول أسرع للمحتوى المترجم. ويواجه هذا الهدف اختناقًا بسبب الطبيعة المكثفة يدويًا للتمرين بالإضافة إلى القوى العاملة الصغيرة من الأشخاص المهرة الذين يمكنهم توطين المحتوى يدويًا. تعمل ZOO Digital مع أكثر من 11,000 موظف مستقل وتقوم بترجمة أكثر من 600 مليون كلمة في عام 2022 وحده. ومع ذلك، فإن الطلب المتزايد على المحتوى يفوق المعروض من الأشخاص المهرة، مما يتطلب التشغيل الآلي للمساعدة في توطين سير العمل.
بهدف تسريع توطين سير عمل المحتوى من خلال التعلم الآلي، استخدمت ZOO Digital برنامج AWS Prototyping، وهو برنامج استثماري من AWS للمشاركة في بناء أعباء العمل مع العملاء. ركزت المشاركة على تقديم حل وظيفي لعملية الترجمة، مع توفير التدريب العملي لمطوري ZOO Digital على SageMaker، الأمازون النسخو ترجمة أمازون.
تحدي العملاء
بعد نسخ عنوان (فيلم أو حلقة من مسلسل تلفزيوني)، يجب تعيين مكبرات الصوت لكل مقطع من الكلام حتى يمكن تعيينهم بشكل صحيح لفناني الصوت الذين تم اختيارهم للعب الشخصيات. وتسمى هذه العملية مذكرات المتحدث. تواجه ZOO Digital التحدي المتمثل في تدوين المحتوى على نطاق واسع مع كونها مجدية اقتصاديًا.
حل نظرة عامة
في هذا النموذج الأولي، قمنا بتخزين ملفات الوسائط الأصلية في ملف خدمة تخزين أمازون البسيطة دلو (أمازون S3). تم تكوين حاوية S3 هذه لإصدار حدث عند اكتشاف ملفات جديدة بداخلها، مما يؤدي إلى حدوث خطأ AWS لامدا وظيفة. للحصول على إرشادات حول تكوين هذا المشغل، راجع البرنامج التعليمي استخدام مشغل Amazon S3 لاستدعاء وظيفة Lambda. وبعد ذلك، قامت دالة Lambda باستدعاء نقطة نهاية SageMaker للاستدلال باستخدام دالة عميل Boto3 SageMaker Runtime.
• WhisperX نموذج، على أساس الهمس OpenAI، يقوم بإجراء النسخ والتدوين لأصول الوسائط. انها مبنية على أسرع الهمس إعادة التنفيذ، مما يوفر نسخًا أسرع بما يصل إلى أربع مرات مع تحسين محاذاة الطوابع الزمنية على مستوى الكلمة مقارنةً بـ Whisper. بالإضافة إلى ذلك، فهو يقدم مذكرات للمتحدث، غير موجودة في نموذج Whisper الأصلي. يستخدم WhisperX نموذج Whisper للنسخ الصوتي Wav2Vec2 نموذج لتحسين محاذاة الطابع الزمني (ضمان مزامنة النص المكتوب مع الطوابع الزمنية الصوتية)، و بيانو نوت نموذج لليوميات. FFMPEG يستخدم لتحميل الصوت من الوسائط المصدر، ودعم مختلف صيغ الوسائط. تتيح بنية النموذج الشفافة والمعيارية المرونة، لأنه يمكن تبديل كل مكون من مكونات النموذج حسب الحاجة في المستقبل. ومع ذلك، من الضروري ملاحظة أن WhisperX يفتقر إلى ميزات الإدارة الكاملة وليس منتجًا على مستوى المؤسسة. وبدون الصيانة والدعم، قد لا يكون مناسبًا لنشر الإنتاج.
في هذا التعاون، قمنا بنشر وتقييم WhisperX على SageMaker، باستخدام نقطة نهاية الاستدلال غير المتزامن لاستضافة النموذج. تدعم نقاط النهاية غير المتزامنة من SageMaker أحجام تحميل تصل إلى 1 جيجابايت وتتضمن ميزات القياس التلقائي التي تخفف من ارتفاع حركة المرور بكفاءة وتوفر التكاليف خارج أوقات الذروة. تعتبر نقاط النهاية غير المتزامنة مناسبة بشكل خاص لمعالجة الملفات الكبيرة، مثل الأفلام والمسلسلات التلفزيونية في حالة الاستخدام لدينا.
يوضح الرسم البياني التالي العناصر الأساسية للتجارب التي أجريناها في هذا التعاون.

في الأقسام التالية، نتعمق في تفاصيل نشر نموذج WhisperX على SageMaker، ونقيم أداء التدوين.
تحميل النموذج ومكوناته
WhisperX هو نظام يتضمن نماذج متعددة للنسخ والمحاذاة القسرية والتدوين. لتشغيل SageMaker بسلاسة دون الحاجة إلى جلب عناصر النموذج أثناء الاستدلال، من الضروري تنزيل جميع عناصر النموذج مسبقًا. يتم بعد ذلك تحميل هذه العناصر في حاوية تقديم SageMaker أثناء البدء. نظرًا لأنه لا يمكن الوصول إلى هذه النماذج بشكل مباشر، فإننا نقدم الأوصاف ونموذج التعليمات البرمجية من مصدر WhisperX، مع توفير إرشادات حول تنزيل النموذج ومكوناته.
يستخدم WhisperX ستة نماذج:
يمكن الحصول على معظم هذه النماذج من وجه يعانق باستخدام مكتبة Huggingface_hub. نحن نستخدم ما يلي download_hf_model() وظيفة لاسترداد هذه القطع الأثرية النموذجية. مطلوب رمز وصول من Hugging Face، يتم إنشاؤه بعد قبول اتفاقيات المستخدم لنماذج Pyannote التالية:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
يتم جلب نموذج VAD من Amazon S3، ويتم استرداد نموذج Wav2Vec2 من وحدة torchaudio.pipelines. استنادًا إلى الكود التالي، يمكننا استرداد جميع عناصر النماذج، بما في ذلك تلك الموجودة في Hugging Face، وحفظها في دليل النموذج المحلي المحدد:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
حدد حاوية AWS Deep Learning Container المناسبة لخدمة النموذج
بعد حفظ عناصر النموذج باستخدام نموذج التعليمات البرمجية السابق، يمكنك اختيار التصميم المُصمم مسبقًا حاويات AWS Deep Learning (DLCs) من ما يلي جيثب ريبو. عند تحديد صورة Docker، ضع في اعتبارك الإعدادات التالية: إطار العمل (Hugging Face)، والمهمة (الاستدلال)، وإصدار Python، والأجهزة (على سبيل المثال، GPU). ننصح باستخدام الصورة التالية: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 تحتوي هذه الصورة على كافة حزم النظام الضرورية المثبتة مسبقًا، مثل ffmpeg. تذكر استبدال [REGION] بمنطقة AWS التي تستخدمها.
بالنسبة لحزم Python المطلوبة الأخرى، أنشئ ملف requirements.txt ملف يحتوي على قائمة الحزم وإصداراتها. سيتم تثبيت هذه الحزم عند إنشاء AWS DLC. فيما يلي الحزم الإضافية اللازمة لاستضافة نموذج WhisperX على SageMaker:
قم بإنشاء برنامج نصي للاستدلال لتحميل النماذج وتشغيل الاستدلال
بعد ذلك، نقوم بإنشاء العرف inference.py البرنامج النصي لتوضيح كيفية تحميل نموذج WhisperX ومكوناته في الحاوية وكيفية تشغيل عملية الاستدلال. يحتوي البرنامج النصي على وظيفتين: model_fn و transform_fn. model_fn يتم استدعاء الوظيفة لتحميل النماذج من مواقعها الخاصة. وبعد ذلك، يتم نقل هذه النماذج إلى transform_fn وظيفة أثناء الاستدلال، حيث يتم تنفيذ عمليات النسخ، والمحاذاة، والتدوين. ما يلي هو نموذج التعليمات البرمجية لـ inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
ضمن دليل النموذج، بجانب ملف requirements.txt الملف، تأكد من وجود inference.py في دليل فرعي للتعليمات البرمجية. ال models يجب أن يشبه الدليل ما يلي:
إنشاء كرة القطران من النماذج
بعد إنشاء النماذج وأدلة التعليمات البرمجية، يمكنك استخدام أسطر الأوامر التالية لضغط النموذج في ملف tarball (ملف .tar.gz) وتحميله إلى Amazon S3. في وقت كتابة هذا التقرير، وباستخدام نموذج Large V2 الأسرع، يبلغ حجم كرة القطران الناتجة التي تمثل نموذج SageMaker 3 جيجابايت. لمزيد من المعلومات، راجع نماذج الاستضافة في Amazon SageMaker ، الجزء 2: الشروع في نشر نماذج الوقت الفعلي على SageMaker.
قم بإنشاء نموذج SageMaker ونشر نقطة نهاية باستخدام أداة توقع غير متزامنة
يمكنك الآن إنشاء نموذج SageMaker وتكوين نقطة النهاية ونقطة النهاية غير المتزامنة باستخدام AsyncPredictor باستخدام نموذج القطران الذي تم إنشاؤه في الخطوة السابقة. للحصول على التعليمات، راجع قم بإنشاء نقطة نهاية للاستدلال غير المتزامن.
تقييم أداء التدبير
لتقييم أداء التدوين لنموذج WhisperX في سيناريوهات مختلفة، اخترنا ثلاث حلقات من عنوانين باللغة الإنجليزية: عنوان درامي يتكون من حلقات مدتها 30 دقيقة، وعنوان وثائقي يتكون من حلقات مدتها 45 دقيقة. استخدمنا مجموعة أدوات مقاييس بياننوت، pyannote.metrics، لحساب معدل خطأ التوسيع (DER). في التقييم، كانت النصوص المكتوبة والمسجلة يدويًا المقدمة من ZOO بمثابة الحقيقة الأساسية.
قمنا بتعريف DER على النحو التالي:
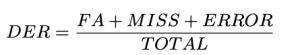
الإجمالي هو طول الفيديو الحقيقة الأرض. FA (الإنذار الكاذب) هو طول المقاطع التي تعتبر كلامًا في التنبؤات، ولكن ليس في الحقيقة الأرضية. Miss هو طول المقاطع التي تعتبر كلامًا في الحقيقة الأرضية، ولكن ليس في التنبؤ. خطأودعا أيضا ارتباك، هو طول المقاطع المخصصة لمتحدثين مختلفين في التنبؤ والحقيقة الأساسية. يتم قياس جميع الوحدات بالثواني. يمكن أن تختلف القيم النموذجية لـ DER اعتمادًا على التطبيق المحدد ومجموعة البيانات وجودة نظام diaration. لاحظ أن DER يمكن أن يكون أكبر من 1.0. انخفاض DER هو الأفضل.
لتتمكن من حساب DER لقطعة من الوسائط، يلزم تدوين الحقيقة الأساسية بالإضافة إلى مخرجات WhisperX المكتوبة والمسجلة. يجب أن يتم تحليلها وينتج عنها قوائم من المجموعات التي تحتوي على تسمية المتحدث ووقت بدء مقطع الكلام ووقت انتهاء مقطع الكلام لكل مقطع من الكلام في الوسائط. لا يلزم أن تتطابق تسميات السماعات بين يوميات WhisperX والحقيقة الأرضية. تعتمد النتائج في الغالب على وقت المقاطع. تأخذ pyannote.metrics هذه المجموعات من يوميات الحقيقة الأساسية ويوميات المخرجات (المشار إليها في وثائق pyannote.metrics باسم مرجع و فرضية) لحساب DER. ويلخص الجدول التالي نتائجنا.
| نوع الفيديو | DER | صيح | Miss | خطأ | انذار كاذب |
| دراما | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| وثائقي | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| متوسط | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
تكشف هذه النتائج عن اختلاف كبير في الأداء بين عناوين الدراما والأفلام الوثائقية، حيث حقق النموذج نتائج أفضل بشكل ملحوظ (باستخدام DER كمقياس إجمالي) لحلقات الدراما مقارنة بعنوان الفيلم الوثائقي. يوفر التحليل الدقيق للعناوين نظرة ثاقبة للعوامل المحتملة التي تساهم في فجوة الأداء هذه. قد يكون أحد العوامل الرئيسية هو الحضور المتكرر لموسيقى الخلفية المتداخلة مع الكلام في عنوان الفيلم الوثائقي. على الرغم من أن المعالجة المسبقة للوسائط لتعزيز دقة التسجيل، مثل إزالة ضوضاء الخلفية لعزل الكلام، كانت خارج نطاق هذا النموذج الأولي، إلا أنها تفتح آفاقًا للعمل المستقبلي الذي يمكن أن يعزز أداء WhisperX.
وفي الختام
في هذا المنشور، استكشفنا الشراكة التعاونية بين AWS وZOO Digital، باستخدام تقنيات التعلم الآلي مع SageMaker ونموذج WhisperX لتعزيز سير عمل التدوين. لعب فريق AWS دورًا محوريًا في مساعدة ZOO في إنشاء النماذج الأولية وتقييم وفهم النشر الفعال لنماذج تعلم الآلة المخصصة، المصممة خصيصًا للتدوين. وشمل ذلك دمج القياس التلقائي لقابلية التوسع باستخدام SageMaker.
سيؤدي تسخير الذكاء الاصطناعي للتدوين إلى توفير كبير في التكلفة والوقت عند إنشاء محتوى مترجم لـ ZOO. من خلال مساعدة الناسخين في إنشاء المتحدثين وتحديد هويتهم بسرعة ودقة، تعالج هذه التقنية طبيعة المهمة التي تستغرق وقتًا طويلاً وعرضة للأخطاء. تتضمن العملية التقليدية غالبًا تمريرات متعددة عبر الفيديو وخطوات إضافية لمراقبة الجودة لتقليل الأخطاء. إن اعتماد الذكاء الاصطناعي للتدوين يتيح اتباع نهج أكثر استهدافًا وكفاءة، وبالتالي زيادة الإنتاجية خلال إطار زمني أقصر.
لقد حددنا الخطوات الأساسية لنشر نموذج WhisperX على نقطة النهاية غير المتزامنة لـ SageMaker، ونشجعك على تجربته بنفسك باستخدام التعليمات البرمجية المتوفرة. لمزيد من المعلومات حول خدمات وتقنيات ZOO Digital، تفضل بزيارة الموقع الرسمي لـZOO Digital. للحصول على تفاصيل حول نشر نموذج OpenAI Whisper على SageMaker وخيارات الاستدلال المتنوعة، راجع استضافة نموذج Whisper على Amazon SageMaker: استكشاف خيارات الاستدلال. لا تتردد في مشاركة أفكارك في التعليقات.
حول المؤلف
 يينغ هو، دكتوراه، هو مهندس النماذج الأولية للتعلم الآلي في AWS. تشمل مجالات اهتمامها الأساسية التعلم العميق، مع التركيز على GenAI، ورؤية الكمبيوتر، والبرمجة اللغوية العصبية، والتنبؤ ببيانات السلاسل الزمنية. تستمتع في أوقات فراغها بقضاء لحظات ممتعة مع عائلتها، والانغماس في الروايات، والمشي لمسافات طويلة في المتنزهات الوطنية في المملكة المتحدة.
يينغ هو، دكتوراه، هو مهندس النماذج الأولية للتعلم الآلي في AWS. تشمل مجالات اهتمامها الأساسية التعلم العميق، مع التركيز على GenAI، ورؤية الكمبيوتر، والبرمجة اللغوية العصبية، والتنبؤ ببيانات السلاسل الزمنية. تستمتع في أوقات فراغها بقضاء لحظات ممتعة مع عائلتها، والانغماس في الروايات، والمشي لمسافات طويلة في المتنزهات الوطنية في المملكة المتحدة.
 إيثان كمبرلاند هو مهندس أبحاث الذكاء الاصطناعي في ZOO Digital، حيث يعمل على استخدام الذكاء الاصطناعي والتعلم الآلي كتقنيات مساعدة لتحسين سير العمل في الكلام واللغة والتوطين. لديه خلفية في هندسة البرمجيات والبحث في مجال الأمن والشرطة، مع التركيز على استخراج المعلومات المنظمة من الويب والاستفادة من نماذج تعلم الآلة مفتوحة المصدر لتحليل وإثراء البيانات المجمعة.
إيثان كمبرلاند هو مهندس أبحاث الذكاء الاصطناعي في ZOO Digital، حيث يعمل على استخدام الذكاء الاصطناعي والتعلم الآلي كتقنيات مساعدة لتحسين سير العمل في الكلام واللغة والتوطين. لديه خلفية في هندسة البرمجيات والبحث في مجال الأمن والشرطة، مع التركيز على استخراج المعلومات المنظمة من الويب والاستفادة من نماذج تعلم الآلة مفتوحة المصدر لتحليل وإثراء البيانات المجمعة.
 غوراف كايلا يقود فريق AWS Prototyping في المملكة المتحدة وأيرلندا. يعمل فريقه مع العملاء عبر الصناعات المتنوعة لتصور أعباء العمل الهامة للأعمال والمشاركة في تطويرها مع تفويض لتسريع اعتماد خدمات AWS.
غوراف كايلا يقود فريق AWS Prototyping في المملكة المتحدة وأيرلندا. يعمل فريقه مع العملاء عبر الصناعات المتنوعة لتصور أعباء العمل الهامة للأعمال والمشاركة في تطويرها مع تفويض لتسريع اعتماد خدمات AWS.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

