المُقدّمة
في الماضي، استحوذ الذكاء الاصطناعي التوليدي على السوق، ونتيجة لذلك، أصبح لدينا الآن نماذج مختلفة بتطبيقات مختلفة. بدأ تقييم Gen AI ببنية Transformer، ومنذ ذلك الحين تم اعتماد هذه الإستراتيجية في مجالات أخرى. لنأخذ مثالا. وكما نعلم، فإننا نستخدم حاليًا نموذج VIT في مجال الانتشار المستقر. عندما تستكشف النموذج بشكل أكبر، سترى أن هناك نوعين من الخدمات متاحان: الخدمات المدفوعة والنماذج مفتوحة المصدر التي يمكن استخدامها مجانًا. يمكن للمستخدم الذي يريد الوصول إلى الخدمات الإضافية استخدام الخدمات المدفوعة مثل OpenAI، وبالنسبة للنموذج مفتوح المصدر، لدينا وجه معانق.
يمكنك الوصول إلى النموذج ووفقًا لمهمتك، يمكنك تنزيل النموذج المعني من الخدمات. لاحظ أيضًا أنه قد يتم تطبيق رسوم على نماذج الرموز المميزة وفقًا للخدمة المعنية في الإصدار المدفوع. وبالمثل، توفر AWS أيضًا خدمات مثل AWS Bedrock، والتي تتيح الوصول إلى نماذج LLM من خلال واجهة برمجة التطبيقات (API). في نهاية منشور المدونة هذا، دعونا نناقش أسعار الخدمات.
أهداف التعلم
- فهم الذكاء الاصطناعي التوليدي مع الانتشار المستقر وLLAMA 2 ونماذج كلود.
- استكشاف ميزات وإمكانيات AWS Bedrock's Stable Diffusion وLLaMA 2 ونماذج Claude.
- استكشاف AWS Bedrock وتسعيره.
- تعرف على كيفية الاستفادة من هذه النماذج في مهام مختلفة، مثل إنشاء الصور وتوليف النص وإنشاء التعليمات البرمجية.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
ما هو الذكاء الاصطناعي التوليدي؟
الذكاء الاصطناعي التوليدي هو مجموعة فرعية من الذكاء الاصطناعي (AI) الذي تم تطويره لإنشاء محتوى جديد بناءً على طلبات المستخدم، مثل الصور أو النص أو التعليمات البرمجية. يتم تدريب هذه النماذج تدريبًا عاليًا على كميات كبيرة من البيانات، مما يجعل إنتاج المحتوى أو الاستجابة لطلبات المستخدم أكثر دقة وأقل تعقيدًا من حيث الوقت. يمتلك الذكاء الاصطناعي التوليدي الكثير من التطبيقات في مجالات مختلفة، مثل الفنون الإبداعية، وتوليد المحتوى، وزيادة البيانات، وحل المشكلات.
يمكنك الرجوع إلى بعض مدوناتي التي تم إنشاؤها باستخدام نماذج LLM، مثل روبوت الدردشة (الجوزاء برو) و الضبط الدقيق الآلي لنماذج LLaMA 2 على Gradient AI Cloud. لقد قمت أيضًا بإنشاء وجه المعانقة إزهار نموذج من Meta لتطوير روبوت الدردشة.
الميزات الرئيسية لGenAI
- انشاء محتوى: يمكن لنماذج LLM إنشاء محتوى جديد باستخدام الاستعلامات التي يتم توفيرها كمدخلات من قبل المستخدم لإنشاء نص أو صور أو تعليمات برمجية.
- الكون المثالى: يمكننا الضبط بسهولة، مما يعني أنه يمكننا تدريب النموذج على معلمات مختلفة لزيادة أداء نماذج LLM وتحسين قوتها.
- التعلم القائم على البيانات: يتم تدريب نماذج الذكاء الاصطناعي التوليدي على مجموعات بيانات كبيرة ذات معلمات مختلفة، مما يسمح لها بتعلم الأنماط من البيانات والاتجاهات في البيانات لإنشاء مخرجات دقيقة وذات معنى.
- الكفاءة: توفر نماذج الذكاء الاصطناعي التوليدية نتائج دقيقة؛ وبهذه الطريقة، فإنها توفر الوقت والموارد مقارنة بطرق الإنشاء اليدوية.
- التنوع: هذه النماذج مفيدة في جميع المجالات. يمتلك الذكاء الاصطناعي التوليدي تطبيقات في مجالات مختلفة، بما في ذلك الفنون الإبداعية وتوليد المحتوى وزيادة البيانات وحل المشكلات.
ما هو AWS Bedrock؟
AWS Bedrock عبارة عن منصة تقدمها Amazon Web Services (AWS). توفر AWS مجموعة متنوعة من الخدمات، لذلك أضافت مؤخرًا خدمة الذكاء الاصطناعي التوليدي Bedrock، والتي أضافت مجموعة متنوعة من نماذج اللغات الكبيرة (LLMs). تم تصميم هذه النماذج لمهام محددة في مجالات مختلفة. لدينا نماذج مختلفة مثل نموذج إنشاء النص ونموذج الصورة التي يمكن دمجها بسلاسة في برنامج مثل VSCode بواسطة علماء البيانات. يمكننا استخدام LLMs للتدريب والنشر لمهام البرمجة اللغوية العصبية المختلفة مثل إنشاء النص والتلخيص والترجمة والمزيد.
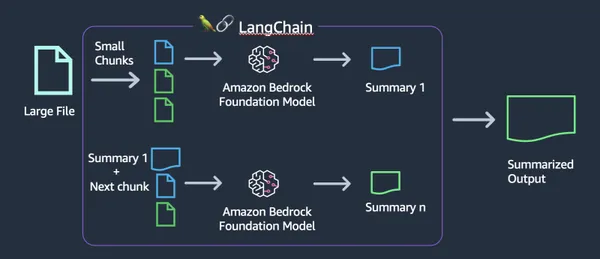
الميزات الرئيسية لـ AWS Bedrock
- الوصول إلى النماذج المدربة مسبقًا: تقدم AWS Bedrock الكثير من نماذج LLM المدربة مسبقًا والتي يمكن للمستخدمين استخدامها بسهولة دون الحاجة إلى إنشاء نماذج أو تدريبها من البداية.
- الكون المثالى: يمكن للمستخدمين ضبط النماذج المدربة مسبقًا باستخدام مجموعات البيانات الخاصة بهم لتكييفها مع حالات استخدام ومجالات محددة.
- التدرجية: تم بناء AWS Bedrock على البنية التحتية لـ AWS، مما يوفر قابلية التوسع للتعامل مع مجموعات البيانات الكبيرة وأحمال عمل الذكاء الاصطناعي التي تتطلب حوسبة مكثفة.
- واجهة برمجة التطبيقات الشاملة: يوفر Bedrock واجهة برمجة تطبيقات شاملة يمكننا من خلالها التواصل بسهولة مع النموذج.
كيفية بناء AWS Bedrock؟
يعد إعداد AWS Bedrock أمرًا بسيطًا ولكنه قوي. يوفر هذا الإطار، المستند إلى Amazon Web Services (AWS)، أساسًا موثوقًا لتطبيقاتك. دعنا نسير عبر الخطوات المباشرة للبدء.
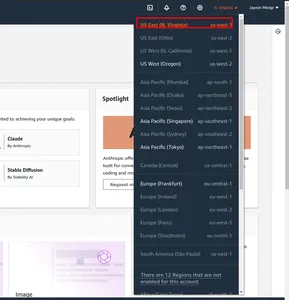
خطوة 1 أولاً، انتقل إلى وحدة الإدارة في AWS. وتغيير المنطقة. لقد وضعت علامة في المربع الأحمر لنا-الشرق-1.
خطوة 2 بعد ذلك، ابحث عن "Bedrock" في وحدة الإدارة في AWS وانقر عليه. ثم انقر على زر "البدء". سينقلك هذا إلى لوحة تحكم Bedrock، حيث يمكنك الوصول إلى واجهة المستخدم.
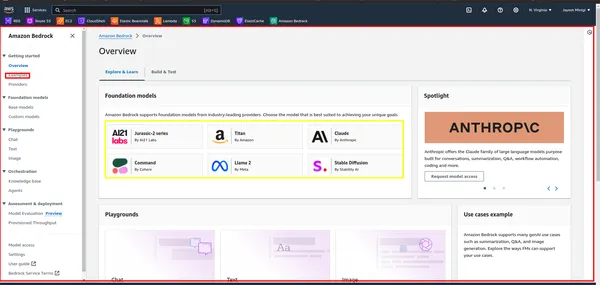
خطوة 3 داخل لوحة المعلومات، ستلاحظ وجود مستطيل أصفر يحتوي على نماذج أساسية مختلفة مثل LLaMA 2، وClaude، وما إلى ذلك. انقر على المستطيل الأحمر لعرض أمثلة وعروض توضيحية لهذه النماذج.
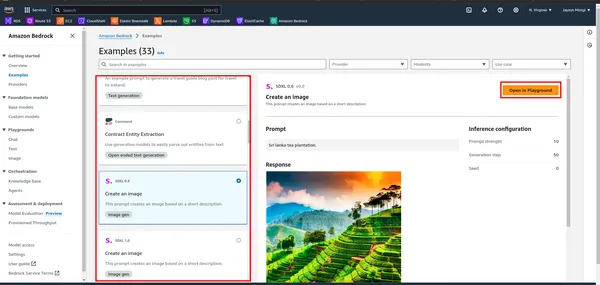
خطوة 4 عند النقر على المثال، سيتم توجيهك إلى صفحة ستجد فيها مستطيلًا أحمر. انقر على أي من هذه الخيارات لأغراض الملعب.
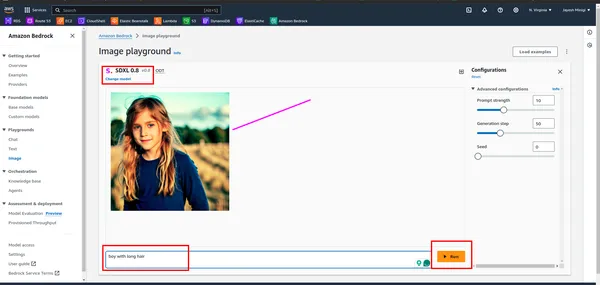
ما هو الانتشار المستقر؟
انتشار مستقر هو نموذج GenAI يقوم بإنشاء صور بناءً على إدخال المستخدم (النص). يقدم المستخدمون مطالبات نصية، ويقوم Stable Diffusion بإنتاج صور مقابلة، كما هو موضح في الجزء العملي. تم إطلاقه في عام 2022 ويستخدم تقنية الانتشار والمساحة الكامنة لإنشاء صور عالية الجودة.
بعد ظهور بنية المحولات في معالجة اللغات الطبيعية (NLP)، تم إحراز تقدم كبير. في مجال رؤية الكمبيوتر، أصبحت نماذج مثل Vision Transformer (ViT) سائدة. في حين أن البنى التقليدية مثل نموذج التشفير وفك التشفير كانت شائعة، فإن Stable Diffusion يعتمد بنية التشفير وفك التشفير باستخدام U-Net. يساهم هذا الاختيار المعماري في فعاليته في توليد صور عالية الجودة.
يعمل الانتشار المستقر عن طريق إضافة تشويش غاوسي تدريجيًا إلى الصورة حتى يبقى تشويش عشوائي فقط - وهي عملية تُعرف باسم الانتشار الأمامي. وبعد ذلك، يتم عكس هذا الضجيج لإعادة إنشاء الصورة الأصلية باستخدام جهاز توقع الضوضاء.
بشكل عام، يمثل الانتشار المستقر تقدمًا ملحوظًا في الذكاء الاصطناعي التوليدي، مما يوفر إمكانات إنشاء صور فعالة وعالية الجودة.
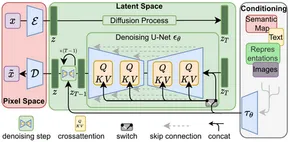
الميزات الرئيسية للانتشار المستقر
- توليد الصور: يستخدم Stable Diffusion نموذج VIT لإنشاء صور من المستخدم (النص) كمدخلات.
- التنوع: هذا النموذج متعدد الاستخدامات، لذا يمكننا استخدام هذا النموذج في المجالات المخصصة له. يمكننا إنشاء صور وGiF ومقاطع فيديو ورسوم متحركة.
- الكفاءة: تستخدم نماذج الانتشار المستقر المساحة الكامنة، مما يتطلب طاقة معالجة أقل مقارنة بنماذج إنشاء الصور الأخرى.
- قدرات صقل: يمكن للمستخدمين ضبط التوزيع المستقر لتلبية احتياجاتهم الخاصة. ومن خلال ضبط المعلمات مثل خطوات تقليل الضوضاء ومستويات الضوضاء، يمكن للمستخدمين تخصيص الإخراج وفقًا لتفضيلاتهم.
بعض الصور التي تم إنشاؤها باستخدام نموذج الانتشار المستقر


كيفية بناء انتشار مستقر؟
لإنشاء Stable Diffusion، ستحتاج إلى اتباع عدة خطوات، بما في ذلك إعداد بيئة التطوير الخاصة بك، والوصول إلى النموذج، واستدعاءه باستخدام المعلمات المناسبة.
الخطوة 1. إعداد البيئة
- خلق البيئة الافتراضية: إنشاء بيئة افتراضية باستخدام venv
conda create -p ./venv python=3.10 -y
- تفعيل البيئة الافتراضية: تفعيل البيئة الافتراضية
conda activate ./venvالخطوة 2. تثبيت حزم المتطلبات
!pip install boto3
!pip install awscliالخطوة 3: إعداد AWS CLI
- أولاً، تحتاج إلى إنشاء مستخدم في IAM ومنحه الأذونات اللازمة، مثل الوصول الإداري.
- بعد ذلك، اتبع الأوامر أدناه لإعداد AWS CLI حتى تتمكن من الوصول إلى النموذج بسهولة.
- تكوين بيانات اعتماد AWS: بمجرد التثبيت، ستحتاج إلى تكوين بيانات اعتماد AWS الخاصة بك. افتح محطة أو موجه الأوامر وقم بتشغيل الأمر التالي:
aws configure- بعد تشغيل الأمر أعلاه، سترى واجهة مستخدم مشابهة لهذه.
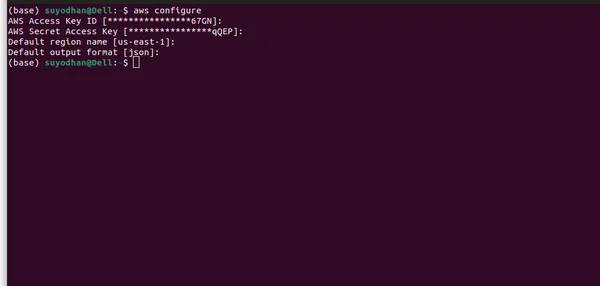
- يرجى التأكد من تقديم جميع المعلومات اللازمة واختيار المنطقة الصحيحة، حيث قد لا يكون نموذج LLM متاحًا في جميع المناطق. بالإضافة إلى ذلك، قمت بتحديد المنطقة التي يتوفر فيها نموذج LLM على AWS Bedrock.
الخطوة الأولى: استيراد المكتبات اللازمة
- قم باستيراد الحزم المطلوبة.
import boto3
import json
import base64
import os
- Boto3 هي مكتبة Python توفر واجهة سهلة الاستخدام للتفاعل مع موارد Amazon Web Services (AWS) برمجيًا.
الخطوة 5: إنشاء عميل AWS Bedrock
bedrock = boto3.client(service_name="bedrock-runtime")
الخطوة 6: تحديد معلمات الحمولة
- أولاً، لاحظ واجهة برمجة التطبيقات (API) في AWS Bedrock.
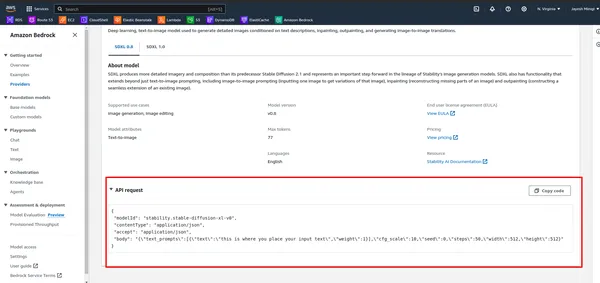
- قم بتشغيل الخلية أدناه.
# DEFINE THE USER QUERY
USER_QUERY="provide me an 4k hd image of a beach, also use a blue sky rainy season and
cinematic display"
payload_params = {
"text_prompts": [{"text": USER_QUERY, "weight": 1}],
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
الخطوة 7: تحديد كائن الحمولة
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body= json.dumps(payload_params),
modelId=model_id,
accept="application/json",
contentType="application/json",
)
الخطوة 8: أرسل طلبًا إلى AWS Bedrock API واحصل على نص الاستجابة
response_body = json.loads(response.get("body").read())

الخطوة 9: استخراج بيانات الصورة من الاستجابة
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
الخطوة 10: احفظ الصورة في ملف
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)

الخطوة 11: إنشاء تطبيق Streamlit
- قم أولاً بتثبيت Streamlit. لذلك افتح المحطة وتجاوزها.
pip install streamlit
- قم بإنشاء برنامج Python Script لتطبيق Streamlit
import streamlit as st
import boto3
import json
import base64
import os
def generate_image(prompt_text):
prompt_template = [{"text": prompt_text, "weight": 1}]
bedrock = boto3.client(service_name="bedrock-runtime")
payload = {
"text_prompts": prompt_template,
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
body = json.dumps(payload)
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
# Save image to a file in the output directory.
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)
return file_name
def main():
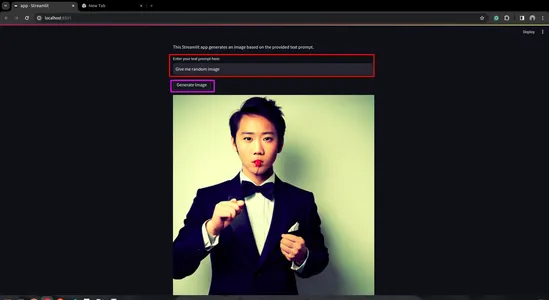
st.title("Generated Image")
st.write("This Streamlit app generates an image based on the provided text prompt.")
# Text input field for user prompt
prompt_text = st.text_input("Enter your text prompt here:")
if st.button("Generate Image") and prompt_text:
image_file = generate_image(prompt_text)
st.image(image_file, caption="Generated Image", use_column_width=True)
elif st.button("Generate Image") and not prompt_text:
st.error("Please enter a text prompt.")
if __name__ == "__main__":
main()
- قم بتشغيل تطبيق Streamlit
streamlit run app.py
ما هو لاما 2؟
ينتمي LLaMA 2، أو نموذج اللغة الكبير للعديد من التطبيقات، إلى فئة نماذج اللغات الكبيرة (LLM). قام Facebook (Meta) بتطوير هذا النموذج لاستكشاف نطاق واسع من تطبيقات معالجة اللغة الطبيعية (NLP). في السلسلة السابقة، كان نموذج "LAMA" هو الوجه الأول للتطوير، لكنه استخدم أساليب قديمة.
الملامح الرئيسية للاما 2
- التنوع: يعد LLaMA 2 نموذجًا قويًا قادرًا على التعامل مع المهام المتنوعة بدقة وكفاءة عالية
- الفهم السياقي: في التعلم من تسلسل إلى تسلسل، نستكشف الصوتيات والمورفيمات والمفردات وبناء الجملة والسياق. يتيح LLaMA 2 فهمًا أفضل للفروق الدقيقة في السياق.
- نقل التعلم: LLaMA 2 هو نموذج قوي يستفيد من التدريب المكثف على مجموعة بيانات كبيرة. يسهل نقل التعلم قدرته على التكيف السريع مع مهام محددة.
- المصدر المفتوح: في علم البيانات، الجانب الرئيسي هو المجتمع. تتيح النماذج مفتوحة المصدر للباحثين والمطورين والمجتمعات استكشافها وتكييفها ودمجها في مشاريعهم.
استخدم حالات
- يمكن أن يساعد LLaMA 2 في ذلك إنشاء توليد النص المهام ، مثل كتابة القصة، إنشاء المحتوى، الخ.
- نحن نعلم أهمية التعلم الصفري. لذلك، يمكننا استخدام LLaMA 2 للإجابة على الأسئلة مهام مشابهة لـ ChatGPT. ويقدم استجابات ذات صلة ودقيقة.
- بالنسبة لترجمة اللغات، لدينا في السوق واجهات برمجة التطبيقات (APIs)، لكننا بحاجة إلى الاشتراك. لكن يوفر LLaMA 2 ترجمة لغوية مجانًا، مما يجعلها سهلة الاستخدام.
- LLaMA 2 سهل الاستخدام وخيار ممتاز للتطوير chatbots.
كيفية بناء لاما 2
لبناء LLaMA 2، ستحتاج إلى اتباع عدة خطوات، بما في ذلك إعداد بيئة التطوير الخاصة بك، والوصول إلى النموذج، واستدعاءه باستخدام المعلمات المناسبة.
الخطوة 1: استيراد المكتبات
- في الخلية الأولى من دفتر الملاحظات، قم باستيراد المكتبات الضرورية:
import boto3
import json
الخطوة 2: تحديد Prompt وعميل AWS Bedrock
- في الخلية التالية، حدد المطالبة بإنشاء القصيدة وقم بإنشاء عميل للوصول إلى AWS Bedrock API:
prompt_data = """
Act as a Shakespeare and write a poem on Generative AI
"""
bedrock = boto3.client(service_name="bedrock-runtime")
الخطوة 3: تحديد الحمولة واستدعاء النموذج
- أولاً، لاحظ واجهة برمجة التطبيقات (API) في AWS Bedrock.
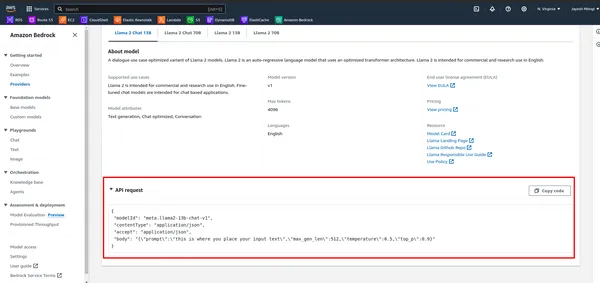
- حدد الحمولة باستخدام الموجه والمعلمات الأخرى، ثم قم باستدعاء النموذج باستخدام عميل AWS Bedrock:
payload = {
"prompt": "[INST]" + prompt_data + "[/INST]",
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
response_text = response_body['generation']
print(response_text)
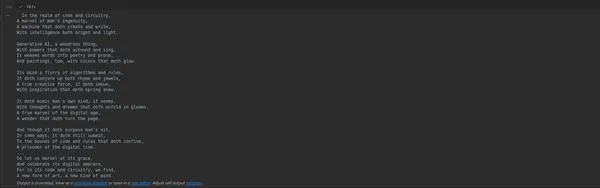
الخطوة 4: قم بتشغيل دفتر الملاحظات
- قم بتنفيذ الخلايا في دفتر الملاحظات واحدة تلو الأخرى بالضغط على Shift + Enter. سيعرض إخراج الخلية الأخيرة القصيدة التي تم إنشاؤها.
الخطوة 5: إنشاء تطبيق Streamlit
- إنشاء برنامج نصي Python: إنشاء برنامج نصي Python جديد (على سبيل المثال، llama2_app.py) وافتحه في محرر التعليمات البرمجية المفضل لديك
import streamlit as st
import boto3
import json
# Define AWS Bedrock client
bedrock = boto3.client(service_name="bedrock-runtime")
# Streamlit app layout
st.title('LLama2 Model App')
# Text input for user prompt
user_prompt = st.text_area('Enter your text prompt here:', '')
# Button to trigger model invocation
if st.button('Generate Output'):
payload = {
"prompt": user_prompt,
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
generation = response_body['generation']
st.text('Generated Output:')
st.write(generation)
- قم بتشغيل تطبيق Streamlit:
- احفظ نص Python الخاص بك وقم بتشغيله باستخدام أمر Streamlit في جهازك الطرفي:
streamlit run llama2_app.py
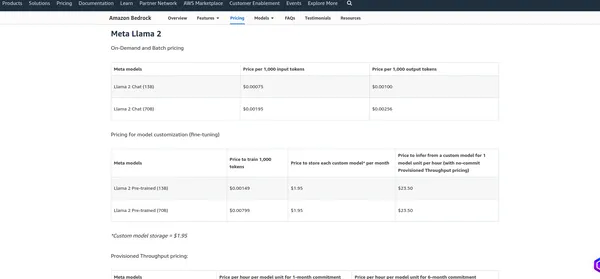
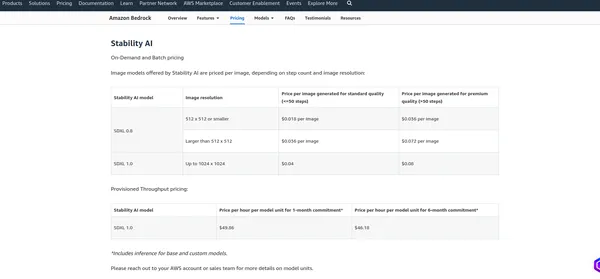
تسعير AWS Bedrock
• تسعير AWS Bedrock يعتمد على عوامل مختلفة والخدمات التي تستخدمها، مثل استضافة النماذج وطلبات الاستدلال وتخزين البيانات ونقل البيانات. عادةً ما تفرض AWS رسومًا على أساس الاستخدام، مما يعني أنك تدفع فقط مقابل ما تستخدمه. أوصي بمراجعة صفحة التسعير الرسمية لأن AWS قد تغير هيكل التسعير الخاص بها. يمكنني تزويدك بالرسوم الحالية، ولكن من الأفضل التحقق من المعلومات الموجودة على الصفحة الرسمية للحصول على التفاصيل الأكثر دقة.
ميتا لاما 2
الاستقرار AI
وفي الختام
تعمقت هذه المدونة في عالم الذكاء الاصطناعي التوليدي، مع التركيز بشكل خاص على نموذجين قويين من LLM: Stable Diffusion وLLamV2. لقد استكشفنا أيضًا AWS Bedrock كمنصة لإنشاء واجهات برمجة التطبيقات لنموذج LLM. باستخدام واجهات برمجة التطبيقات هذه، أوضحنا كيفية كتابة التعليمات البرمجية للتفاعل مع النماذج. بالإضافة إلى ذلك، استخدمنا ملعب AWS Bedrock لممارسة وتقييم قدرات النماذج.
في البداية، سلطنا الضوء على أهمية اختيار المنطقة الصحيحة داخل AWS Bedrock، حيث قد لا تكون هذه النماذج متاحة في جميع المناطق. للمضي قدمًا، قدمنا استكشافًا عمليًا لكل نموذج LLM، بدءًا من إنشاء دفاتر ملاحظات Jupyter ثم الانتقال إلى تطوير تطبيقات Streamlit.
أخيرًا، ناقشنا هيكل تسعير AWS Bedrock، مع التأكيد على ضرورة فهم التكاليف المرتبطة والرجوع إلى صفحة التسعير الرسمية للحصول على معلومات دقيقة.
الوجبات السريعة الرئيسية
- يوفر Stable Diffusion وLLAMV2 على AWS Bedrock وصولاً سهلاً إلى إمكانات الذكاء الاصطناعي القوية التوليدية.
- يوفر AWS Bedrock واجهة بسيطة ووثائق شاملة للتكامل السلس.
- تحتوي هذه النماذج على ميزات رئيسية مختلفة وحالات استخدام عبر مجالات مختلفة.
- تذكر أن تختار المنطقة المناسبة للوصول إلى النماذج المطلوبة على AWS Bedrock.
- يوفر التنفيذ العملي لنماذج الذكاء الاصطناعي التوليدية مثل Stable Diffusion وLLAMv2 الكفاءة على AWS Bedrock.
الأسئلة المتكررة
ج: الذكاء الاصطناعي التوليدي هو مجموعة فرعية من الذكاء الاصطناعي تركز على إنشاء محتوى جديد، مثل الصور أو النصوص أو التعليمات البرمجية، بدلاً من مجرد تحليل البيانات الموجودة.
A. Stable Diffusion هو نموذج توليدي للذكاء الاصطناعي ينتج صورًا واقعية من النص ومطالبات الصور باستخدام تقنية النشر والمساحة الكامنة.
ج. يوفر AWS Bedrock واجهات برمجة التطبيقات لإدارة النماذج وتدريبها ونشرها، مما يسمح للمستخدمين بالوصول إلى نماذج اللغات الكبيرة مثل LLAMv2 لمختلف التطبيقات.
ج. يمكنك الوصول إلى نماذج LLM على AWS Bedrock باستخدام واجهات برمجة التطبيقات المتوفرة، مثل استدعاء النموذج بمعلمات محددة وتلقي المخرجات التي تم إنشاؤها.
A. يمكن لـ Stable Diffusion إنشاء صور عالية الجودة من المطالبات النصية، ويعمل بكفاءة باستخدام المساحة الكامنة، ويمكن الوصول إليه من قبل مجموعة واسعة من المستخدمين.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/02/building-end-to-end-generative-ai-models-with-aws-bedrock/

