المُقدّمة
في عالم توصيل الأغذية المحلي اليوم سريع الخطى، يعد ضمان رضا العملاء أمرًا أساسيًا للشركات. يهيمن اللاعبون الرئيسيون مثل Zomato وSwiggy على هذه الصناعة. يتوقع العملاء الطعام الطازج. إذا حصلوا على عناصر مدللة، فإنهم يقدرون استرداد الأموال أو قسيمة الخصم. ومع ذلك، فإن تحديد مدى نضارة الطعام يدويًا يعد أمرًا مرهقًا للعملاء وموظفي الشركة. أحد الحلول هو أتمتة هذه العملية باستخدام نماذج التعلم العميق. يمكن لهذه النماذج التنبؤ بمدى نضارة الطعام، مما يسمح فقط للموظفين بمراجعة الشكاوى التي تم الإبلاغ عنها للتحقق من صحتها بشكل نهائي. إذا أكد النموذج نضارة الطعام، فيمكنه رفض الشكوى تلقائيًا. سنقوم في هذه المقالة ببناء جهاز كشف جودة الأغذية باستخدام التعلم العميق.
ويقدم التعلم العميق، وهو مجموعة فرعية من الذكاء الاصطناعي، فائدة كبيرة في هذا السياق. على وجه التحديد، يمكن استخدام شبكات CNN (الشبكات العصبية التلافيفية) لتدريب النماذج باستخدام صور الطعام لتمييز نضارتها. تعتمد دقة نموذجنا بالكامل على جودة مجموعة البيانات. ومن الناحية المثالية، فإن دمج صور الطعام الحقيقية من شكاوى روبوتات الدردشة للمستخدمين في تطبيقات توصيل الطعام المحلية للغاية من شأنه أن يعزز الدقة بشكل كبير. ومع ذلك، نظرًا لافتقارنا إلى إمكانية الوصول إلى مثل هذه البيانات، فإننا نعتمد على مجموعة بيانات مستخدمة على نطاق واسع تُعرف باسم "مجموعة بيانات التصنيف الجديدة والعفنة"، والتي يمكن الوصول إليها على Kaggle. لاستكشاف كود التعلم العميق الكامل، ما عليك سوى النقر فوق الزر "نسخ وتحرير" المتوفر هنا.
أهداف التعلم
- التعرف على أهمية جودة الغذاء في رضا العملاء ونمو الأعمال.
- اكتشف كيف يساعد التعلم العميق في بناء كاشف جودة الأغذية.
- اكتساب الخبرة العملية من خلال تنفيذ هذا النموذج خطوة بخطوة.
- فهم التحديات والحلول التي ينطوي عليها تنفيذها.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
فهم استخدام التعلم العميق في كاشف جودة الأغذية
تعلم عميق، مجموعة فرعية من الذكاء الاصطناعي، يستخدم في المقام الأول مجموعات البيانات المكانية لبناء النماذج. تُستخدم الشبكات العصبية ضمن التعلم العميق لتدريب هذه النماذج، ومحاكاة وظائف الدماغ البشري.
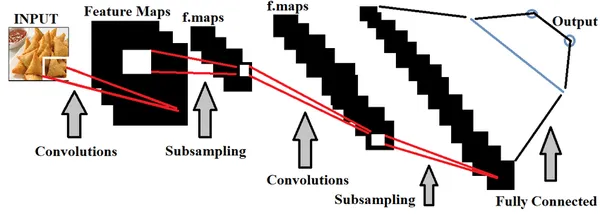
في سياق الكشف عن جودة الأغذية، يعد تدريب نماذج التعلم العميق باستخدام مجموعات واسعة من صور الطعام أمرًا ضروريًا للتمييز الدقيق بين المواد الغذائية ذات الجودة الجيدة والسيئة. يمكننا القيام به ضبط فرط المعلمة بناءً على البيانات التي يتم تغذيتها، وذلك لجعل النموذج أكثر دقة.
أهمية جودة الغذاء في التوصيل المحلي
يوفر دمج هذه الميزة في خدمة توصيل الطعام المحلية الفائقة العديد من الفوائد. يتجنب النموذج التحيز تجاه عملاء محددين ويتنبأ بدقة، مما يقلل من وقت حل الشكوى. بالإضافة إلى ذلك، يمكننا استخدام هذه الميزة أثناء عملية تعبئة الطلب لفحص جودة الطعام قبل التسليم، مما يضمن حصول العملاء على طعام طازج باستمرار.

تطوير جهاز كشف جودة الأغذية
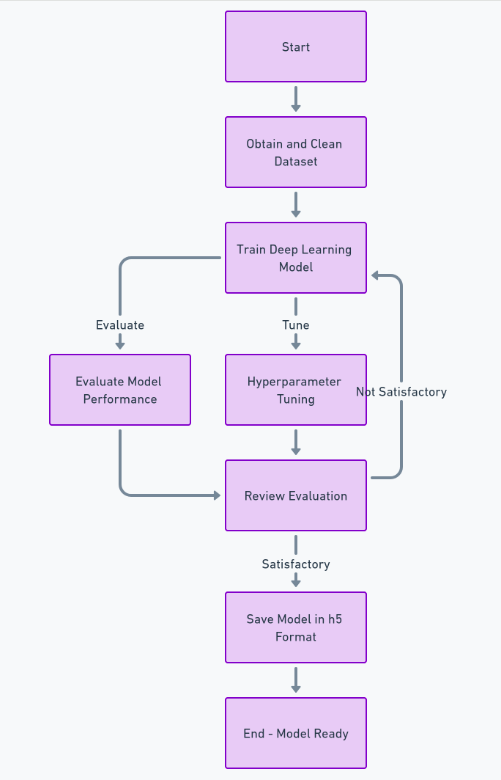
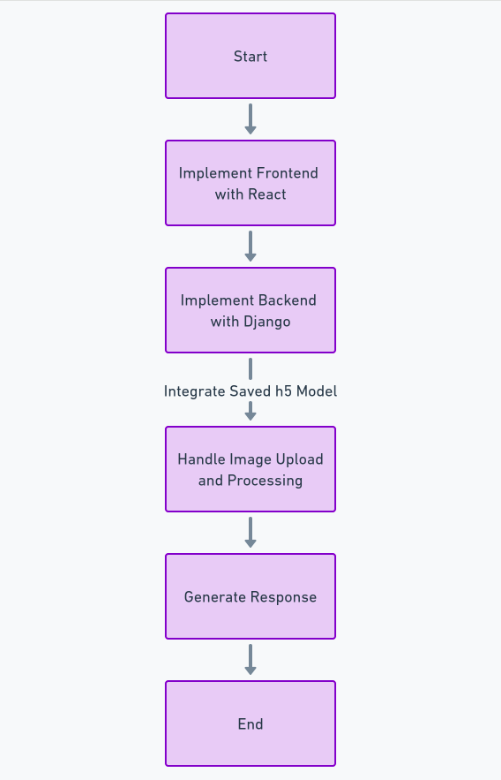
من أجل بناء هذه الميزة بشكل كامل، نحتاج إلى اتباع الكثير من الخطوات مثل الحصول على مجموعة البيانات وتنظيفها، وتدريب نموذج التعلم العميق، وتقييم الأداء وضبط المعلمات الفائقة، وأخيرًا حفظ النموذج في h5 شكل. بعد ذلك، يمكننا تنفيذ الواجهة الأمامية باستخدام رد فعلوالواجهة الخلفية باستخدام إطار عمل بايثون جانغو. سوف نستخدم Django للتعامل مع تحميل الصور ومعالجتها.
حول مجموعة البيانات
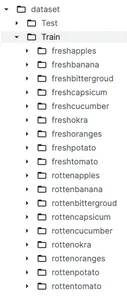
قبل التعمق في المعالجة المسبقة للبيانات وبناء النماذج، من المهم فهم مجموعة البيانات. كما ناقشنا سابقًا، سنستخدم مجموعة بيانات من Kaggle اسمها تصنيف الأغذية الطازجة والفاسدة. يتم تقسيم مجموعة البيانات هذه إلى فئتين رئيسيتين مسماتين قطار و اختبار التي يتم استخدامها لأغراض التدريب والاختبار على التوالي. تحت مجلد القطار لدينا 9 مجلدات فرعية للفواكه الطازجة والخضروات الطازجة و9 مجلدات فرعية للفواكه والخضروات الفاسدة.
الميزات الرئيسية لمجموعة البيانات
- تنوع الصور: تحتوي مجموعة البيانات هذه على الكثير من صور الطعام مع الكثير من التنوع من حيث الزاوية والخلفية وظروف الإضاءة. وهذا يساعد النموذج على ألا يكون متحيزًا وأن يكون أكثر دقة.
- صور عالية الجودة: تحتوي مجموعة البيانات هذه على صور عالية الجودة تم التقاطها بواسطة كاميرات احترافية مختلفة.
تحميل البيانات وإعدادها
في هذا القسم، سنقوم أولاً بتحميل الصور باستخدام "Tensorflow.keras.preprocessing.image.تحميل_imgوظيفة وتصور الصور باستخدام مكتبة matplotlib. تعد المعالجة المسبقة لهذه الصور للتدريب على النماذج أمرًا مهمًا حقًا. يتضمن ذلك تنظيف الصور وتنظيمها لجعلها مناسبة للنموذج.
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)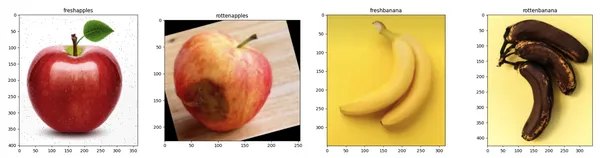
لنقم الآن بتحميل صور التدريب والاختبار إلى متغيرات. سنقوم بتغيير حجم جميع الصور إلى نفس الارتفاع والعرض 180.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
بناء نموذج
الآن دعونا نبني نموذج التعلم العميق باستخدام الخوارزمية التسلسلية من "tensorflow.keras". سنضيف ثلاث طبقات تلافيفية ومُحسِّن Adam. قبل الخوض في الجزء العملي، دعونا أولاً نفهم ما هي المصطلحاتالنموذج المتسلسل''ادم اوبتيمايزر"و"طبقة الالتفاف' يقصد.
النموذج المتسلسل
يتكون النموذج المتسلسل من مجموعة من الطبقات، مما يوفر بنية أساسية في Keras. إنها مثالية للسيناريوهات التي تتميز فيها شبكتك العصبية بموتر إدخال واحد وموتر إخراج واحد. يمكنك إضافة طبقات بالترتيب التسلسلي للتنفيذ، مما يجعلها مناسبة لإنشاء نماذج مباشرة ذات طبقات مكدسة. هذه البساطة تجعل النموذج المتسلسل مفيدًا للغاية وأسهل في التنفيذ.
ادم اوبتيمايزر
اختصار Adam هو "تقدير اللحظة التكيفية". إنه بمثابة خوارزمية تحسين بديلة للنزول التدرج العشوائي، وتحديث أوزان الشبكة بشكل متكرر. يعد Adam Optimizer مفيدًا لأنه يحافظ على معدل التعلم (LR) لكل وزن للشبكة، وهو أمر مفيد في التعامل مع الضوضاء في البيانات.
الطبقة التلافيفية (Conv2D)
وهو المكون الرئيسي للشبكات العصبية التلافيفية (CNNs). يتم استخدامه بشكل أساسي لمعالجة مجموعات البيانات المكانية مثل الصور. تطبق هذه الطبقة وظيفة أو عملية ملتوية على المدخلات ثم تمرر النتيجة إلى الطبقة التالية.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)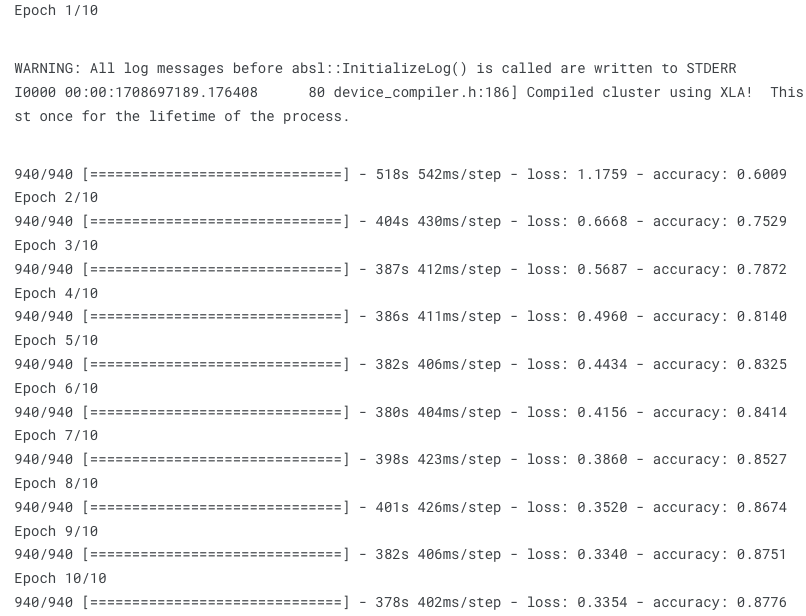
اختبار كاشف جودة الأغذية
الآن دعونا نختبر النموذج من خلال إعطائه صورة غذائية جديدة ولنرى مدى دقة تصنيفه إلى طعام طازج وطعام فاسد.
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
وكما نرى فقد تنبأ النموذج بشكل صحيح. كما قدمنا com.rottenorange الصورة كمدخل وقد تنبأ بها النموذج بشكل صحيح فاسد.
بالنسبة إلى كود الواجهة الأمامية (React) والواجهة الخلفية (Django)، يمكنك رؤية الكود الكامل الخاص بي على GitHub هنا: لينك
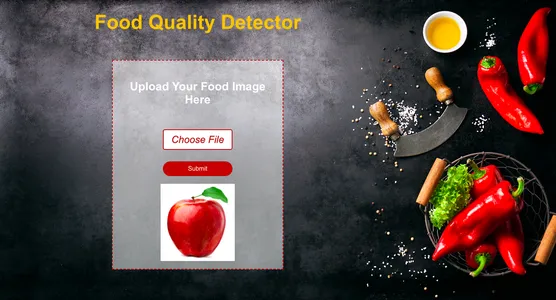
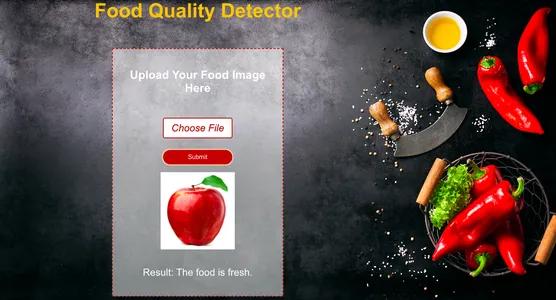
وفي الختام
في الختام، لأتمتة شكاوى جودة الأغذية في تطبيقات Hyperlocal Delivery، نقترح بناء نموذج تعلم عميق متكامل مع تطبيق ويب. ومع ذلك، نظرًا لبيانات التدريب المحدودة، قد لا يكتشف النموذج بدقة كل صورة غذائية. يعد هذا التنفيذ بمثابة خطوة تأسيسية نحو حل أكبر. إن الوصول إلى الصور التي تم تحميلها بواسطة المستخدم في الوقت الفعلي داخل هذه التطبيقات من شأنه أن يعزز بشكل كبير من دقة نموذجنا.
الوجبات السريعة الرئيسية
- تلعب جودة الغذاء دورًا حاسمًا في تحقيق رضا العملاء في سوق توصيل الطعام المحلي.
- يمكنك الاستفادة من تقنية التعلم العميق لتدريب جهاز تنبؤ دقيق بجودة الطعام.
- لقد اكتسبت خبرة عملية من خلال هذا الدليل التفصيلي خطوة بخطوة لإنشاء تطبيق الويب.
- لقد فهمت أهمية جودة مجموعة البيانات لبناء نموذج دقيق.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/

