تساعد المعالجة الذكية للمستندات (IDP) مع AWS على أتمتة استخراج المعلومات من المستندات ذات الأنواع والتنسيقات المختلفة ، بسرعة وبدقة عالية ، دون الحاجة إلى مهارات التعلم الآلي (ML). يمكن أن يساعدك استخراج المعلومات بشكل أسرع وبدقة عالية في اتخاذ قرارات تجارية عالية الجودة في الوقت المحدد ، مع تقليل التكاليف الإجمالية. لمزيد من المعلومات ، يرجى الرجوع إلى معالجة المستندات بذكاء مع خدمات AWS AI: الجزء 1.
ومع ذلك ، ينشأ التعقيد عند تنفيذ سيناريوهات العالم الحقيقي. غالبًا ما يتم إرسال المستندات خارج الترتيب ، أو قد يتم إرسالها كحزمة مدمجة مع أنواع نماذج متعددة. يجب إنشاء خطوط أنابيب التنسيق لتقديم منطق الأعمال ، وأيضًا حساب تقنيات المعالجة المختلفة اعتمادًا على نوع النموذج الذي تم إدخاله. يتم تضخيم هذه التحديات فقط عندما تتعامل الفرق مع كميات كبيرة من المستندات.
في هذا المنشور ، نوضح كيفية حل هذه التحديات باستخدام تُنشئ Amazon Textract IDP CDK، مجموعة من بنيات IDP سابقة البناء ، لتسريع تطوير خطوط أنابيب معالجة المستندات في العالم الحقيقي. بالنسبة لحالة الاستخدام الخاصة بنا ، نقوم بمعالجة مستند تأمين Acord لتمكين المعالجة المباشرة ، ولكن يمكنك توسيع هذا الحل ليشمل أي حالة استخدام ، والتي نناقشها لاحقًا في المنشور.
معالجة مستندات Acord على نطاق واسع
المعالجة المباشرة (STP) هي مصطلح يستخدم في الصناعة المالية لوصف أتمتة المعاملة من البداية إلى النهاية دون الحاجة إلى تدخل يدوي. تستخدم صناعة التأمين STP لتبسيط عملية الاكتتاب والمطالبات. يتضمن ذلك الاستخراج التلقائي للبيانات من مستندات التأمين مثل التطبيقات ووثائق البوليصة ونماذج المطالبات. قد يكون تنفيذ STP أمرًا صعبًا نظرًا لكمية البيانات الكبيرة وتنوع تنسيقات المستندات المعنية. وثائق التأمين متنوعة بطبيعتها. تقليديًا ، تتضمن هذه العملية مراجعة كل مستند يدويًا وإدخال البيانات في نظام ، الأمر الذي يستغرق وقتًا طويلاً وعرضة للأخطاء. هذا النهج اليدوي ليس فقط غير فعال ولكن يمكن أن يؤدي أيضًا إلى أخطاء يمكن أن يكون لها تأثير كبير على عملية الاكتتاب والمطالبات. هذا هو المكان الذي يأتي فيه IDP على AWS.
لتحقيق سير عمل أكثر كفاءة ودقة ، يمكن لشركات التأمين دمج IDP على AWS في عملية الاكتتاب والمطالبات. مع أمازون تيكستراك و فهم الأمازون، يمكن لشركات التأمين قراءة الخط اليدوي وتنسيقات النماذج المختلفة ، مما يسهل استخراج المعلومات من أنواع مختلفة من مستندات التأمين. من خلال تنفيذ IDP على AWS في العملية ، يصبح تحقيق STP أسهل ، مما يقلل الحاجة إلى التدخل اليدوي ويسرع العملية الشاملة.
يسمح خط الأنابيب هذا لشركات التأمين بمعالجة معاملات التأمين التجارية الخاصة بهم بسهولة وكفاءة ، مما يقلل الحاجة إلى التدخل اليدوي ويحسن تجربة العملاء بشكل عام. نوضح كيفية استخدام Amazon Textract و Amazon Comprehend لاستخراج البيانات تلقائيًا من مستندات التأمين التجاري ، مثل Acord 140 و Acord 125 وإفادة ملكية المنزل و Acord 126 ، وتحليل البيانات المستخرجة لتسهيل عملية الاكتتاب. يمكن أن تساعد هذه الخدمات شركات التأمين على تحسين دقة وسرعة عمليات STP الخاصة بهم ، مما يوفر في النهاية تجربة أفضل لعملائهم.
حل نظرة عامة
الحل مبني باستخدام مجموعة تطوير سحابة AWS (AWS CDK) ، ويتكون من Amazon Comprehend لتصنيف المستندات ، و Amazon Textract لاستخراج المستندات ، الأمازون DynamoDB للتخزين، AWS لامدا لمنطق التطبيق ، و وظائف خطوة AWS لتنسيق خط أنابيب سير العمل.
يتكون خط الأنابيب من المراحل التالية:
- قسّم حزم المستندات وتصنيف كل نوع نموذج باستخدام Amazon Comprehend.
- قم بتشغيل خطوط أنابيب المعالجة لكل نوع نموذج أو صفحة من النموذج باستخدام Amazon Textract API المناسب (اكتشاف التوقيع أو استخراج الجدول أو استخراج النماذج أو الاستعلامات).
- قم بإجراء المعالجة اللاحقة لمخرجات Amazon Textract في تنسيق يمكن قراءته آليًا.
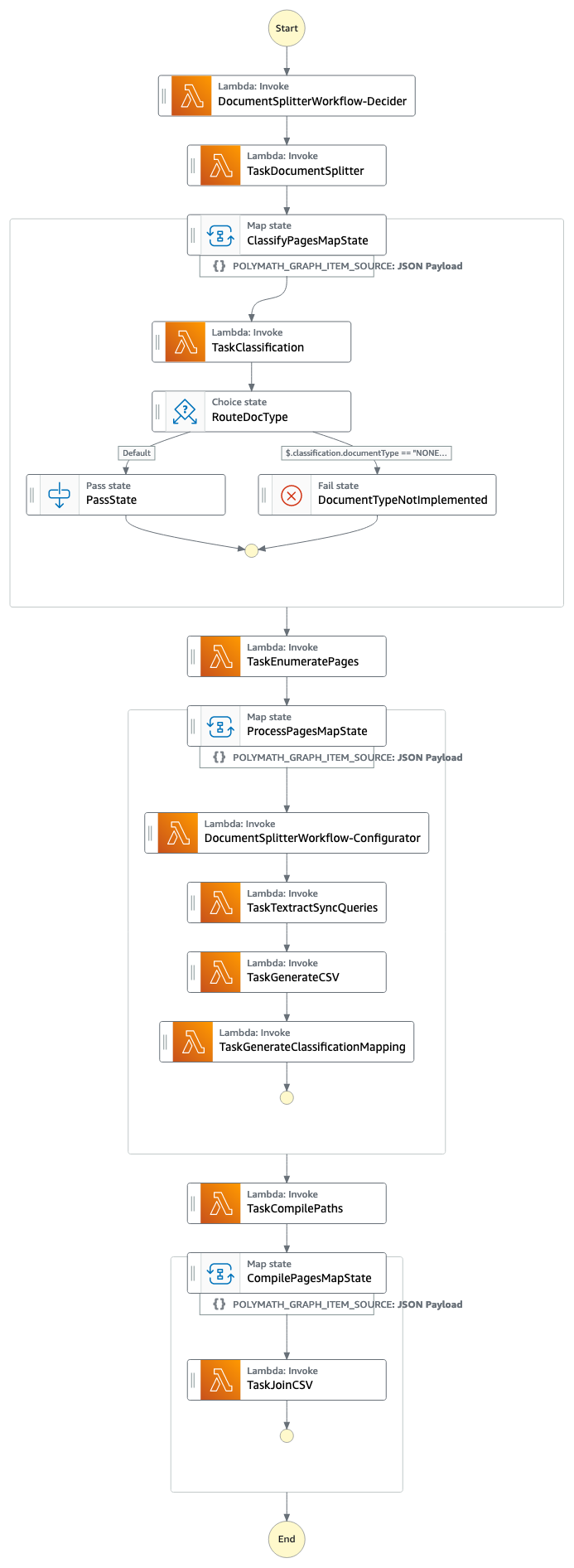
توضح لقطة الشاشة التالية لسير عمل Step Functions خط الأنابيب.
المتطلبات الأساسية المسبقة
لبدء استخدام الحل ، تأكد من أن لديك ما يلي:
- تم تثبيت الإصدار 2 من AWS CDK
- تثبيت Docker وتشغيله على جهازك
- الوصول المناسب إلى وظائف الخطوة ، DynamoDB ، Lambda ، خدمة Amazon Simple Queue Service (Amazon SQS) و Amazon Textract و Amazon Comprehend
استنساخ GitHub repo
ابدأ باستنساخ مستودع GitHub:
قم بإنشاء نقطة نهاية تصنيف Amazon Comprehend
نحتاج أولاً إلى توفير نقطة نهاية تصنيف Amazon Comprehend.
بالنسبة إلى هذا المنشور ، تكتشف نقطة النهاية فئات المستندات التالية (تأكد من اتساق التسمية):
acord125acord126acord140property_affidavit
يمكنك إنشاء واحد باستخدام comprehend_acord_dataset.csv عينة من مجموعة البيانات في مستودع جيثب. لتدريب وإنشاء نقطة نهاية تصنيف مخصصة باستخدام عينة مجموعة البيانات المتوفرة ، اتبع التعليمات الواردة في تدريب المصنفات المخصصة. إذا كنت ترغب في استخدام ملفات PDF الخاصة بك ، فراجع مسار العمل الأول في المنشور قم بتقسيم حزم المستندات متعددة الأشكال بذكاء باستخدام Amazon Textract و Amazon Comprehend.
بعد تدريب المصنف الخاص بك وإنشاء نقطة نهاية ، يجب أن يكون لديك ARN الخاص بنقطة نهاية التصنيف المخصص من Amazon Comprehend والذي يشبه الكود التالي:
انتقل إلى docsplitter/document_split_workflow.py وتعديل الأسطر 27-28 التي تحتوي على comprehend_classifier_endpoint. أدخل ARN نقطة النهاية الخاصة بك في خط 28.
تثبيت التبعيات
الآن تقوم بتثبيت تبعيات المشروع:
قم بتهيئة الحساب والمنطقة لـ AWS CDK. سيؤدي هذا إلى إنشاء ملف خدمة تخزين أمازون البسيطة حاويات (Amazon S3) وأدوار أداة AWS CDK لتخزين القطع الأثرية والقدرة على نشر البنية التحتية. انظر الكود التالي:
انشر مكدس AWS CDK
عندما يكون مصنف Amazon Comprehend وجدول تكوين المستندات جاهزين ، انشر الحزمة باستخدام الكود التالي:
قم بتحميل المستند
تحقق من نشر المكدس بشكل كامل.
ثم في نافذة المحطة ، قم بتشغيل aws s3 cp الأمر لتحميل المستند إلى ملف DocumentUploadLocation ل DocumentSplitterWorkflow:
لقد أنشأنا نموذجًا لحزمة مستندات مكونة من 12 صفحة تحتوي على نماذج Acord 125 و Acord 126 و Acord 140 وشهادة الملكية. تُظهر الصور التالية مقتطفًا من صفحة واحدة من كل مستند.
جميع البيانات الموجودة في النماذج اصطناعية ، وتعتبر نماذج Acord القياسية ملكًا لشركة Acord Corporation ، وتُستخدم هنا للتوضيح فقط.
قم بتشغيل سير عمل Step Functions
افتح الآن سير عمل Step Function. يمكنك الحصول على ارتباط سير عمل Step Function من ملف document_splitter_outputs.json ملف أو وحدة تحكم وظائف الخطوة أو باستخدام الأمر التالي:
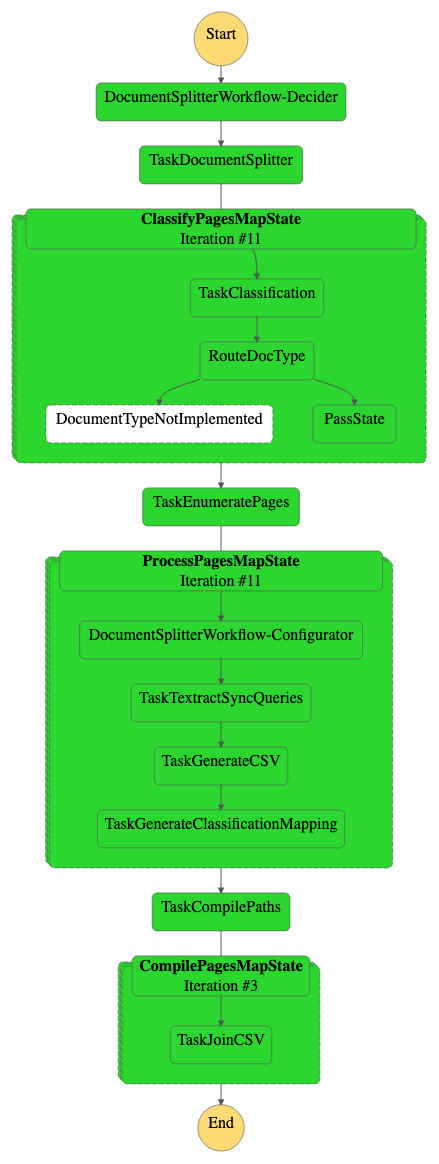
بناءً على حجم حزمة المستند ، سيختلف وقت سير العمل. يجب أن تستغرق معالجة المستند النموذجي من دقيقة إلى دقيقتين. يوضح الرسم البياني التالي سير عمل Step Functions.
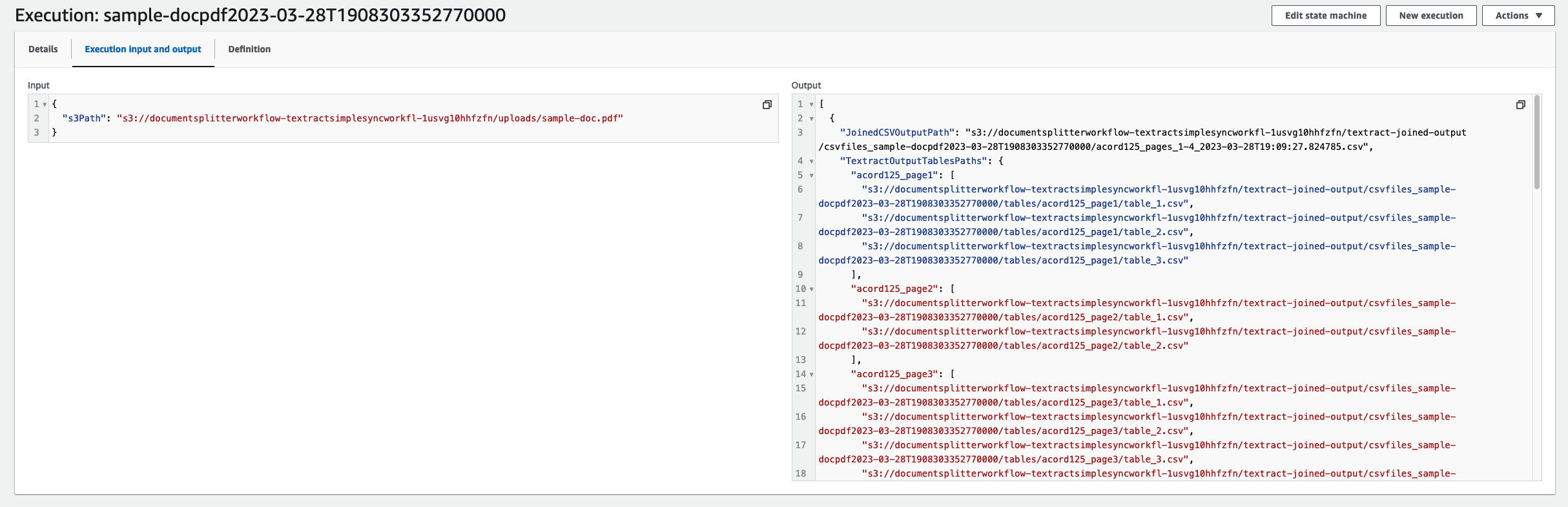
عندما تكتمل مهمتك ، انتقل إلى كود الإدخال والإخراج. من هنا سترى ملفات CSV القابلة للقراءة آليًا لكل نموذج من النماذج المعنية.
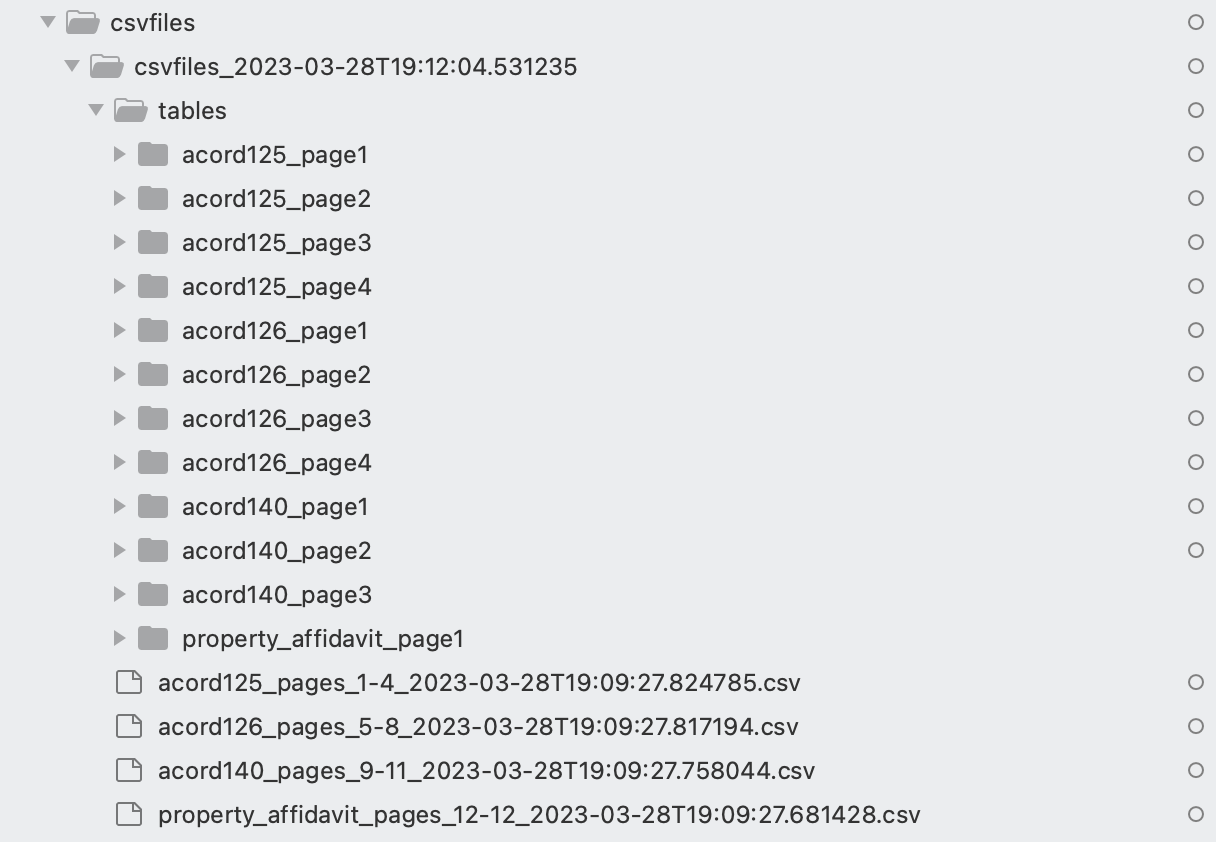
لتنزيل هذه الملفات ، افتح getfiles.py. قم بتعيين الملفات لتكون القائمة التي يتم إخراجها بواسطة تشغيل جهاز الحالة. يمكنك تشغيل هذه الوظيفة عن طريق التشغيل python3 getfiles.py. سيؤدي هذا إلى إنشاء ملف csvfiles_<TIMESTAMP> المجلد ، كما هو موضح في لقطة الشاشة التالية.
تهانينا ، لقد نفذت الآن سير عمل معالجة شاملة لتطبيق التأمين التجاري.
تمديد الحل لأي نوع من الأشكال
في هذا المنشور ، أوضحنا كيف يمكننا استخدام Amazon Textract IDP CDK Constructs لحالة استخدام التأمين التجاري. ومع ذلك ، يمكنك توسيع هذه البنى لأي نوع نموذج. للقيام بذلك ، نقوم أولاً بإعادة تدريب مصنف Amazon Comprehend الخاص بنا لحساب نوع النموذج الجديد ، وضبط الكود كما فعلنا سابقًا.
لكل نوع من أنواع النماذج التي قمت بتدريبها ، يجب أن نحدد استعلاماتها و textract_features في ال create_csv.py ملف. يؤدي هذا إلى تخصيص مسار معالجة كل نوع نموذج باستخدام واجهة برمجة تطبيقات Amazon Textract المناسبة.
Queries هي قائمة من الاستفسارات. على سبيل المثال ، "ما هو عنوان البريد الإلكتروني الأساسي؟" في الصفحة 2 من نموذج المستند. لمزيد من المعلومات، راجع الاستعلامات.
textract_features هي قائمة بميزات Amazon Textract التي تريد استخراجها من المستند. يمكن أن تكون جداول أو استمارات أو استعلامات أو توقيعات. لمزيد من المعلومات، راجع أنواع الميزات.
انتقل إلى generate_csv.py. يحتاج كل نوع مستند إلى ملف classification, queriesو textract_features تم تكوينه عن طريق إنشاء CSVRow الحالات.
على سبيل المثال لدينا أربعة أنواع من المستندات: acord125, acord126, acord140و property_affidavit. في ما يلي ، نريد استخدام ميزات النماذج والجداول في مستندات acord ، وميزات الاستعلامات والتوقيعات لشهادة الملكية.
ارجع إلى مستودع GitHub للتعرف على كيفية القيام بذلك لعينة مستندات التأمين التجاري.
تنظيف
لإزالة الحل ، قم بتشغيل cdk destroy يأمر. سيُطلب منك بعد ذلك تأكيد حذف سير العمل. سيؤدي حذف سير العمل إلى حذف جميع الموارد التي تم إنشاؤها.
وفي الختام
في هذا المنشور ، أوضحنا كيف يمكنك البدء في إنشاءات Amazon Textract IDP CDK من خلال تنفيذ سيناريو معالجة مباشر لمجموعة من نماذج Acord التجارية. لقد أوضحنا أيضًا كيف يمكنك توسيع الحل ليشمل أي نوع من النماذج من خلال تغييرات التكوين البسيطة. نحن نشجعك على تجربة الحل مع المستندات الخاصة بك. الرجاء رفع طلب سحب إلى جيثب ريبو لأي طلبات ميزات قد تكون لديك. لمعرفة المزيد حول IDP على AWS ، راجع وثائقنا.
حول المؤلف
 راج باتاك مهندس حلول وتقني أول متخصص في الخدمات المالية (التأمين ، البنوك ، أسواق رأس المال) والتعلم الآلي. وهو متخصص في معالجة اللغات الطبيعية (NLP) ونماذج اللغات الكبيرة (LLM) والبنية التحتية للتعلم الآلي ومشاريع العمليات (MLOps).
راج باتاك مهندس حلول وتقني أول متخصص في الخدمات المالية (التأمين ، البنوك ، أسواق رأس المال) والتعلم الآلي. وهو متخصص في معالجة اللغات الطبيعية (NLP) ونماذج اللغات الكبيرة (LLM) والبنية التحتية للتعلم الآلي ومشاريع العمليات (MLOps).
 أديتي راجنيش هو طالب هندسة برمجيات في السنة الثانية بجامعة واترلو. تشمل اهتماماتها رؤية الكمبيوتر ومعالجة اللغة الطبيعية والحوسبة المتطورة. كما أنها شغوفة بالتوعية والتوعية المجتمعية في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM). في أوقات فراغها ، يمكن أن تجدها تتسلق الصخور أو تعزف على البيانو أو تتعلم كيفية خبز الكعك المثالي.
أديتي راجنيش هو طالب هندسة برمجيات في السنة الثانية بجامعة واترلو. تشمل اهتماماتها رؤية الكمبيوتر ومعالجة اللغة الطبيعية والحوسبة المتطورة. كما أنها شغوفة بالتوعية والتوعية المجتمعية في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM). في أوقات فراغها ، يمكن أن تجدها تتسلق الصخور أو تعزف على البيانو أو تتعلم كيفية خبز الكعك المثالي.
 انزو ستاتون مهندس حلول لديه شغف بالعمل مع الشركات لزيادة معرفتهم السحابية. يعمل عن كثب كمستشار موثوق به ومتخصص في الصناعة مع العملاء في جميع أنحاء البلاد.
انزو ستاتون مهندس حلول لديه شغف بالعمل مع الشركات لزيادة معرفتهم السحابية. يعمل عن كثب كمستشار موثوق به ومتخصص في الصناعة مع العملاء في جميع أنحاء البلاد.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/build-end-to-end-document-processing-pipelines-with-amazon-textract-idp-cdk-constructs/

