بناء بحيرة بيانات على خدمة تخزين أمازون البسيطة (Amazon S3) يوفر مزايا عديدة للمؤسسة. يتيح لك الوصول إلى مصادر البيانات المتنوعة ، وبناء لوحات معلومات الأعمال ، وبناء نماذج الذكاء الاصطناعي والتعلم الآلي (ML) لتوفير تجارب مخصصة للعملاء ، وتسريع تنظيم مجموعات البيانات الجديدة للاستهلاك من خلال اعتماد هندسة البيانات الحديثة or شبكة البيانات هندسة معمارية.
ومع ذلك ، فإن العديد من حالات الاستخدام ، مثل إجراء التقاط بيانات التغيير (CDC) من قاعدة البيانات العلائقية المنبع إلى بحيرة البيانات المستندة إلى Amazon S3 ، تتطلب معالجة البيانات على مستوى قياسي. يتطلب إجراء عملية مثل إدراج سجلات فردية من مجموعة بيانات وتحديثها وحذفها من محرك المعالجة قراءة جميع الكائنات (الملفات) وإجراء التغييرات وإعادة كتابة مجموعات البيانات بأكملها كملفات جديدة. علاوة على ذلك ، غالبًا ما يؤدي إتاحة البيانات في بحيرة البيانات في الوقت الفعلي تقريبًا إلى تجزئة البيانات على العديد من الملفات الصغيرة ، مما يؤدي إلى ضعف أداء الاستعلام وصيانة الضغط.
في 2022، ونحن أعلن أنه يمكنك فرض سياسات التحكم في الوصول الدقيقة باستخدام تكوين بحيرة AWS والاستعلام عن البيانات المخزنة في أي تنسيق ملف مدعوم باستخدام تنسيقات الجدول مثل اباتشي فيضو Apache Hudi والمزيد باستخدام ملفات أمازون أثينا استفسارات. يمكنك الحصول على المرونة في اختيار الجدول وتنسيق الملف الأنسب لحالة الاستخدام الخاصة بك والاستفادة من إدارة البيانات المركزية لتأمين الوصول إلى البيانات عند استخدام Athena.
في هذا المنشور ، نوضح لك كيفية تكوين Lake Formation باستخدام تنسيقات Iceberg Table. نشرح أيضًا كيفية الارتقاء والدمج في بحيرة بيانات S3 باستخدام إطار عمل Iceberg وتطبيق التحكم في الوصول إلى Lake Formation باستخدام Athena.
Iceberg هو تنسيق جدول مفتوح لمجموعات البيانات التحليلية الكبيرة جدًا. يدير Iceberg مجموعات كبيرة من الملفات كجداول ، ويدعم عمليات بحيرة البيانات التحليلية الحديثة مثل إدراج مستوى السجل ، والتحديث ، والحذف ، واستعلامات السفر عبر الزمن. تتيح مواصفات Iceberg تطورًا سلسًا للجدول مثل تطور المخطط والقسم ، كما تم تحسين تصميمه للاستخدام على Amazon S3. يساعد Iceberg أيضًا على ضمان صحة البيانات في ظل سيناريوهات الكتابة المتزامنة.
حل نظرة عامة
لشرح هذا الإعداد ، نقدم البنية التالية ، التي تدمج Amazon S3 لبحيرة البيانات (تنسيق جدول Iceberg) ، و Lake Formation للتحكم في الوصول ، و AWS Glue لـ ETL (الاستخراج ، والتحويل ، والتحميل) ، و Athena للاستعلام عن أحدث بيانات الجرد من جداول Iceberg باستخدام لغة SQL القياسية.
![]()
يتكون سير عمل الحل من الخطوات التالية ، بما في ذلك استيعاب البيانات (الخطوات 1-3) ، وإدارة البيانات (الخطوة 4) ، والوصول إلى البيانات (الخطوة 5):
- نستخدم خدمة ترحيل قاعدة بيانات AWS (AWS DMS) أو أداة مماثلة للاتصال بمصدر البيانات ونقل البيانات الإضافية (CDC) إلى Amazon S3 بتنسيق CSV.
- An غراء AWS تقرأ وظيفة PySpark البيانات المتزايدة من حاوية إدخال S3 وتقوم بإلغاء تكرار السجلات.
- تستدعي الوظيفة بعد ذلك عبارات Iceberg's MERGE لدمج البيانات مع حاوية S3 المستهدفة.
- نستخدم كتالوج بيانات AWS Glue كتالوج مركزي ، يتم استخدامه بواسطة AWS Glue و Athena. تم دمج برنامج تتبع الارتباطات AWS Glue أعلى حاويات S3 لاكتشاف المخطط تلقائيًا. يسمح لك Lake Formation بإدارة الأذونات والتحكم في الوصول مركزيًا لموارد كتالوج البيانات في بحيرة بيانات S3. يمكنك استخدام التحكم في الوصول الدقيق في Lake Formation لتقييد الوصول إلى البيانات في نتائج الاستعلام.
- نستخدم Athena المدمجة مع Lake Formation للاستعلام عن البيانات من جدول Iceberg باستخدام SQL القياسي والتحقق من صحة الوصول على مستوى الجدول والعمود في جداول Iceberg.
بالنسبة لهذا الحل ، نفترض أن ملفات البيانات الأولية متوفرة بالفعل في Amazon S3 ، ونركز على معالجة البيانات باستخدام AWS Glue مع تنسيق جدول Iceberg. نستخدم بيانات عنصر نموذجية لها السمات التالية:
- op - هذا يمثل العملية على تسجيلة المصدر. يوضح هذا القيم I لتمثيل عمليات الإدراج ، و U لتمثيل التحديثات ، و D لتمثيل عمليات الحذف. تحتاج إلى التأكد من تضمين هذه السمة في بيانات CDC الإضافية الخاصة بك قبل كتابتها إلى Amazon S3. تأكد من التقاط هذه السمة ، بحيث يمكن لمنطق ETL الخاص بك اتخاذ الإجراء المناسب أثناء دمجها.
- معرف المنتج - هذا هو عمود المفتاح الأساسي في جدول البيانات المصدر.
- الفئة - يمثل هذا العمود فئة العنصر.
- اسم المنتج - هذا اسم المنتج.
- الكمية متاحة - هذه هي الكمية المتوفرة في المخزون. عندما نعرض البيانات الإضافية لـ UPSERT أو MERGE ، فإننا نخفض الكمية المتاحة للمنتج لعرض الوظائف.
- آخر_تحديث_وقت - هذا هو الوقت الذي تم فيه تحديث تسجيلة المادة في البيانات المصدر.
نوضح تنفيذ الحل بالخطوات التالية:
- قم بإنشاء حاوية S3 لبيانات الإدخال والإخراج.
- قم بإنشاء جداول الإدخال والإخراج باستخدام أثينا.
- أدخل البيانات في جدول Iceberg من أثينا.
- استعلم عن جدول Iceberg باستخدام Athena.
- تحميل البيانات التزايدية (CDC) لمزيد من المعالجة.
- قم بتشغيل مهمة AWS Glue مرة أخرى لمعالجة الملفات المتزايدة.
- استعلم عن جدول Iceberg مرة أخرى باستخدام أثينا.
- تحديد سياسات تكوين البحيرة.
المتطلبات الأساسية المسبقة
لاستعلامات Athena ، نحتاج إلى تكوين مجموعة عمل Athena بإصدار المحرك 3 لدعم تنسيق جدول Iceberg.
![]()
للتحقق من صحة الوصول عبر الحسابات من خلال Lake Formation for Iceberg table ، استخدمنا في هذا المنشور حسابين (أساسي وثانوي).
الآن دعنا نتعمق في خطوات التنفيذ.
قم بإنشاء حاوية S3 لبيانات الإدخال والإخراج
قبل أن نقوم بتشغيل وظيفة AWS Glue ، يتعين علينا تحميل عينة ملفات CSV إلى حاوية الإدخال ومعالجتها باستخدام كود AWS Glue PySpark للإخراج.
لإنشاء حاوية S3 ، أكمل الخطوات التالية:
- في وحدة تحكم Amazon S3 ، اختر الدلاء في جزء التنقل.
- اختار إنشاء دلو.
- حدد اسم المستودع كـ
iceberg-blogواترك الحقول المتبقية كافتراضي.
أسماء حاويات S3 فريدة بشكل عام. أثناء تنفيذ الحل ، قد تحصل على خطأ يفيد بأن اسم الحاوية موجود بالفعل. تأكد من توفير اسم فريد واستخدم نفس الاسم أثناء تنفيذ باقي خطوات التنفيذ. تنسيق اسم الحاوية كـ<Bucket-Name>-${AWS_ACCOUNT_ID}-${AWS_REGION_CODE}قد تساعدك في الحصول على اسم فريد.
- في صفحة تفاصيل الحاوية ، اختر إنشاء مجلد.
- قم بإنشاء مجلدين فرعيين. لهذا المنشور ، نحن نخلق
iceberg-blog/raw-csv-inputوiceberg-blog/iceberg-output.
- تحميل
LOAD00000001.csvملف فيraw-csv-inputالمجلد.
توفر لقطة الشاشة التالية عينة من مجموعة بيانات الإدخال.![]()
إنشاء جداول الإدخال والإخراج باستخدام أثينا
لإنشاء جداول Iceberg للإدخال والإخراج في AWS Glue Data Catalog ، افتح محرر استعلام Athena وقم بتشغيل الاستعلامات التالية بالتسلسل:
كما أوضحنا لاحقًا في هذا المنشور ، من الضروري تسجيل مواقع البيانات عند دمج عناصر التحكم في الوصول إلى Lake Formation.
بدلاً من ذلك ، يمكنك استخدام زاحف AWS Glue لإنشاء تعريف الجدول لملفات الإدخال.
أدخل البيانات في جدول Iceberg من أثينا
اختياريًا ، يمكننا إدخال البيانات في جدول Iceberg من خلال Athena باستخدام الكود التالي:
بالنسبة لهذا المنشور ، نقوم بتحميل البيانات باستخدام وظيفة AWS Glue. أكمل الخطوات التالية لإنشاء الوظيفة:
- في وحدة تحكم AWS Glue ، اختر المشــاريــع في جزء التنقل.
- اختار خلق وظيفة.
- أختار مرئي مع أ قماش بيضاء.
- اختار إنشاء.

- اختار تعديل سيناريو.

- استبدل البرنامج النصي بالنص التالي:
- على تفاصيل الوظيفة علامة التبويب ، حدد اسم الوظيفة (
iceberg-lf). - في حالة دور IAM، قم بتعيين ملف إدارة الهوية والوصول AWS (IAM) الذي لديه الأذونات المطلوبة لتشغيل مهمة AWS Glue والقراءة والكتابة في حاوية S3.
- في حالة نسخة الغراء، اختر الغراء 4.0 (الغراء 3.0 مدعوم أيضًا).
- في حالة اللغة ، اختر بيثون 3.
- تأكد مرجعية الوظيفة القيمة الافتراضية تفعيل.

- في حالة معلمات الوظيفة، أضف ما يلي:
- أضف المفتاح
--datalake-formatsمع القيمةiceberg. - أضف المفتاح
--iceberg_job_catalog_warehouseمع القيمة كمسار S3 الخاص بك (s3://<bucket-name>/<iceberg-warehouse-path>).
- أضف المفتاح
- اختار حفظ وثم يجري، والتي يجب أن تكتب بيانات الإدخال إلى جدول Iceberg مع عبارة MERGE.
استعلم عن جدول Iceberg باستخدام Athena
بعد أن تقوم بتشغيل مهمة AWS Glue بنجاح ، يمكنك التحقق من صحة المخرجات في Athena باستخدام استعلام SQL التالي:
يجب أن يتطابق إخراج الاستعلام مع الإدخال ، مع اختلاف واحد: لا يحتوي جدول إخراج Iceberg علىopالعمود.![]()
تحميل البيانات التزايدية (CDC) لمزيد من المعالجة
بعد أن نقوم بمعالجة ملف التحميل الأولي الكامل ، فلنقم بتحميل ملف ملف تزايدي.![]()
يتضمن هذا الملف سجلات محدثة على عنصرين.![]()
قم بتشغيل مهمة AWS Glue مرة أخرى لمعالجة الملفات المتزايدة
نظرًا لأن وظيفة AWS Glue بها إشارات مرجعية ممكّنة ، فإن الوظيفة تلتقط الملف التزايدي الجديد وتنفذ عملية MERGE على جدول Iceberg.
لتشغيل الوظيفة مرة أخرى ، أكمل الخطوات التالية:
- في وحدة تحكم AWS Glue ، اختر المشــاريــع في جزء التنقل.
- حدد الوظيفة واختر يجري.
بالنسبة لهذا المنشور ، نقوم بتشغيل الوظيفة يدويًا ، ولكن يمكنك تكوين مهام AWS Glue للتشغيل كجزء من ملف سير عمل AWS Glue أو عن طريق وظائف خطوة AWS (لمزيد من المعلومات، راجع إدارة وظائف AWS Glue من خلال وظائف الخطوة).
استعلم عن جدول Iceberg باستخدام Athena بعد معالجة البيانات الإضافية
عند اكتمال معالجة البيانات التزايدية ، يمكنك تشغيل نفس عبارة SELECT مرة أخرى والتحقق من تحديث قيمة الكمية للبندين 200 و 201.
تظهر لقطة الشاشة التالية الإخراج.![]()
تحديد سياسات تكوين البحيرة
لحوكمة البيانات ، نستخدم Lake Formation. Lake Formation هي خدمة مُدارة بالكامل تعمل على تبسيط إعداد بحيرة البيانات ، وتدعم إدارة الأمان المركزية ، وتوفر وصولاً للمعاملات أعلى بحيرة البيانات الخاصة بك. علاوة على ذلك ، فإنه يتيح مشاركة البيانات عبر الحسابات والمؤسسات. هناك طريقتان لمشاركة موارد البيانات في Lake Formation: التحكم في الوصول إلى الموارد المسماة (NRAC) والتحكم في الوصول المستند إلى العلامات (TBAC). يستخدم NRAC مدير الوصول إلى موارد AWS (AWS RAM) لمشاركة موارد البيانات عبر الحسابات باستخدام Lake Formation V3. تلك التي يتم استهلاكها عبر روابط الموارد التي تستند إلى مشاركات الموارد التي تم إنشاؤها. تشكيل البحيرة التحكم في الوصول المستند إلى العلامات (LF-TBAC) هي طريقة أخرى لمشاركة موارد البيانات في Lake Formation ، والتي تحدد الأذونات بناءً على السمات. تسمى هذه السمات علامات LF.
في هذا المثال ، نقوم بإنشاء قواعد بيانات في الحساب الأساسي. تتم مشاركة قاعدة بيانات NRAC الخاصة بنا مع مجال بيانات عبر AWS RAM. سيتم التعامل مع الوصول إلى جداول البيانات التي نسجلها في قاعدة البيانات هذه من خلال NRAC.
تكوين ضوابط الوصول في الحساب الأساسي
في الحساب الأساسي ، أكمل الخطوات التالية لإعداد ضوابط الوصول باستخدام Lake Formation:
- في وحدة التحكم Lake Formation ، اختر مواقع بحيرة البيانات في جزء التنقل.
- اختار تسجيل الموقع.
- قم بتحديث مسار موقع Iceberg Amazon S3 الموضح في لقطة الشاشة التالية.

منح الوصول إلى قاعدة البيانات للحساب الثانوي
لمنح الوصول إلى قاعدة البيانات للحساب الخارجي (الثانوي) ، أكمل الخطوات التالية:
- في وحدة التحكم Lake Formation ، انتقل إلى قاعدة البيانات الخاصة بك.
- على الإجراءات القائمة، اختر منحة.

- اختار الحسابات الخارجية وأدخل رقم الحساب الثانوي.
- أختار موارد كتالوج البيانات المسماة.
- تحقق من اسم قاعدة البيانات.
يجب أن تكون المنحة الأولى على مستوى قاعدة البيانات ، وتكون المنحة الثانية على مستوى الجدول.
- في حالة أذونات قاعدة البيانات، حدد أذوناتك (لهذه المشاركة ، نختار وصف).
- اختار منحة.

أنت الآن بحاجة إلى منح أذونات على مستوى الجدول.
- أختار الحسابات الخارجية وأدخل رقم الحساب الثانوي.
- أختار موارد كتالوج البيانات المسماة.
- تحقق من اسم الجدول.
- في حالة أذونات الجدول، حدد الأذونات التي تريد منحها. لهذا المنشور ، نختار أختار و وصف.
- اختار منحة.

إذا رأيت الخطأ التالي ، فيجب عليك إبطالIAMAllowedPrincipalsمن أذونات بحيرة البيانات.![]()
للقيام بذلك ، حدد IAMAllowedPrincipals واختر سحب او إبطال.![]()
اختار سحب او إبطال مرة أخرى للتأكيد.![]()
بعد إبطال أذونات البيانات ، يجب أن تظهر الأذونات كما هو موضح في لقطة الشاشة التالية.![]()
أضف أذونات دور AWS Glue IAM
نظرًا لإلغاء دور IAM الرئيسي ، يجب إضافة دور AWS Glue IAM الذي تم استخدامه في مهمة AWS Glue حصريًا لمنح الوصول كما هو موضح في لقطة الشاشة التالية.![]()
تحتاج إلى تكرار هذه الخطوات لدور AWS Glue IAM على مستوى الجدول.![]()
تحقق من الأذونات الممنوحة لدور AWS Glue IAM في وحدة تحكم Lake Formation.![]()
منح حق الوصول إلى Iceberg table للحساب الخارجي
في الحساب الثانوي ، أكمل الخطوات التالية لمنح حق الوصول إلى جدول Iceberg لحساب خارجي.
- في وحدة تحكم AWS RAM ، اختر مشاركات الموارد في جزء التنقل.
- اختر دعوة مشاركات المورد المرسلة من الحساب الأساسي.

- اختار قبول حصة الموارد.
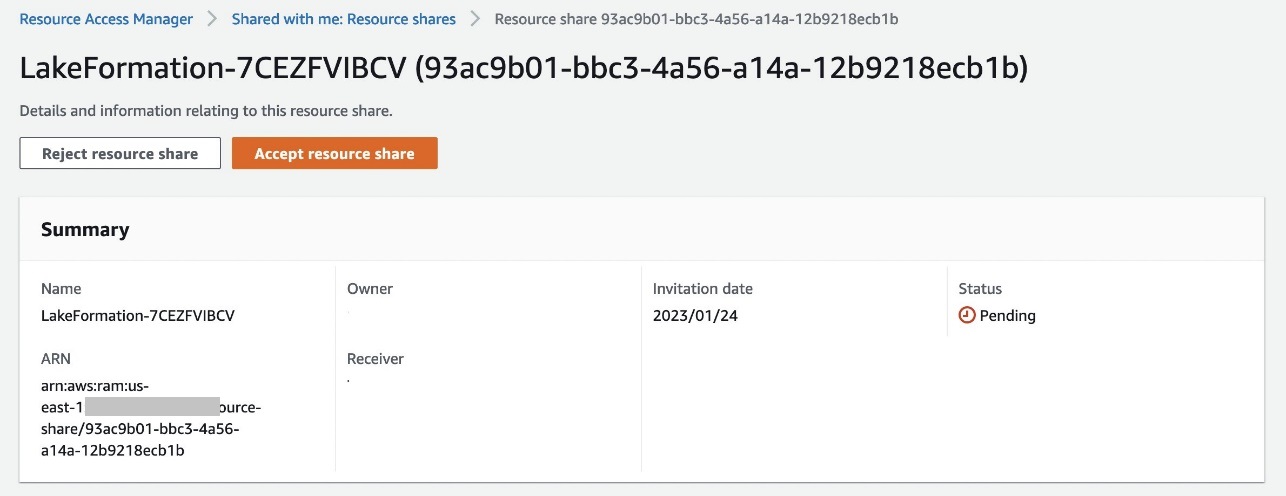
يجب أن تكون حالة المورد نشطة الآن.![]()
بعد ذلك ، تحتاج إلى إنشاء رابط مورد لجدول Iceberg المشترك والوصول إليه من خلال Athena.
- في وحدة التحكم Lake Formation ، اختر طاولات الطعام في جزء التنقل.
- حدد جدول Iceberg (مشترك من الحساب الأساسي).
- على الإجراءات القائمة، اختر إنشاء ارتباط الموارد.

- في حالة اسم ارتباط المورد، أدخل اسمًا (لهذه المشاركة ،
iceberg_table_lf_demo). - في حالة قاعدة البيانات، اختر قاعدة البيانات الخاصة بك وتحقق من ملء الجدول وقاعدة البيانات المشتركين تلقائيًا.
- اختار إنشاء.

- حدد الجدول الخاص بك وعلى الإجراءات القائمة، اختر عرض البيانات.

تتم إعادة توجيهك إلى وحدة تحكم Athena ، حيث يمكنك الاستعلام عن البيانات.![]()
منح حق الوصول المستند إلى العمود في الحساب الأساسي
للوصول المقيد على مستوى العمود ، تحتاج إلى منح حق الوصول على مستوى العمود في جدول Iceberg. أكمل الخطوات التالية:
- في وحدة التحكم Lake Formation ، انتقل إلى قاعدة البيانات الخاصة بك.
- على الإجراءات القائمة، اختر منحة.
- أختار الحسابات الخارجية وأدخل رقم الحساب الثانوي.
- أختار موارد كتالوج البيانات المسماة.
- تحقق من اسم الجدول.
- في حالة أذونات الجدول، اختر الأذونات التي تريد منحها. لهذا المنشور ، نختار أختار.
- تحت أذونات البيانات، اختر الوصول المستند إلى العمود.
- أختار قم بتضمين الأعمدة واختر فلاتر الإذن (لهذا المنشور ،
CategoryوQuantity_available). - اختار منحة.

يمكن الآن الاستعلام عن البيانات ذات الأعمدة المقيدة من خلال وحدة تحكم أثينا.![]()
تنظيف
لتجنب تكبد تكاليف مستمرة ، أكمل الخطوات التالية لتنظيف مواردك:
- في حسابك الثانوي ، قم بتسجيل الدخول إلى وحدة تحكم Lake Formation.
- قم بإسقاط جدول مشاركة الموارد.
- في حسابك الأساسي ، قم بتسجيل الدخول إلى وحدة تحكم Lake Formation.
- إبطال الوصول الذي قمت بتكوينه.
- قم بإسقاط جداول وقاعدة بيانات AWS Glue.
- احذف مهمة AWS Glue.
- احذف حاويات S3 وأي موارد أخرى قمت بإنشائها كجزء من المتطلبات الأساسية لهذه المشاركة.
وفي الختام
يشرح هذا المنشور كيف يمكنك استخدام إطار عمل Iceberg مع AWS Glue و Lake Formation لتحديد عناصر التحكم في الوصول عبر الحسابات والاستعلام عن البيانات باستخدام Athena. يوفر نظرة عامة على Iceberg وميزاته وأساليب التكامل ، ويشرح كيف يمكنك استيعاب البيانات ، ومنح الوصول عبر الحسابات ، والاستعلام عن البيانات من خلال دليل خطوة بخطوة.
نأمل أن يمنحك هذا نقطة انطلاق رائعة لاستخدام Iceberg لبناء منصة بحيرة البيانات الخاصة بك جنبًا إلى جنب مع خدمات تحليلات AWS لتنفيذ الحل الخاص بك.
حول المؤلف
![]() فيكرام سهاديفان مهندس مقيم أول في فريق AWS Data Lab. إنه يتمتع بالجهود التي تركز على تقديم إرشادات معمارية توجيهية ، ومشاركة أفضل الممارسات ، وإزالة العوائق التقنية من خلال التفاعلات الهندسية المشتركة بين العملاء وموارد AWS التقنية التي تسرع البيانات والتحليلات والذكاء الاصطناعي ومبادرات التعلم الآلي.
فيكرام سهاديفان مهندس مقيم أول في فريق AWS Data Lab. إنه يتمتع بالجهود التي تركز على تقديم إرشادات معمارية توجيهية ، ومشاركة أفضل الممارسات ، وإزالة العوائق التقنية من خلال التفاعلات الهندسية المشتركة بين العملاء وموارد AWS التقنية التي تسرع البيانات والتحليلات والذكاء الاصطناعي ومبادرات التعلم الآلي.
![]() سوفيندو كومار باترا يمتلك 18 عامًا من الخبرة في البنية التحتية وتصميم قواعد البيانات وهندسة البيانات ، ويشغل حاليًا منصب كبير المهندسين المقيمين في Amazon Web Services. وهو عضو في مجموعة التركيز المتخصصة ، AWS Data Lab ، وتنطوي واجباته الأساسية على العمل مع فرق القيادة التنفيذية لعملاء AWS الاستراتيجيين لتطوير خرائط طريقهم للبيانات والتحليلات والذكاء الاصطناعي / تعلم الآلة. تتعاون Suvendu بشكل وثيق مع العملاء لتنفيذ هندسة البيانات ، ومركز البيانات ، وبحيرة البيانات ، وحوكمة البيانات ، وحلول EDW ، بالإضافة إلى إستراتيجية بيانات المؤسسة وإدارة البيانات.
سوفيندو كومار باترا يمتلك 18 عامًا من الخبرة في البنية التحتية وتصميم قواعد البيانات وهندسة البيانات ، ويشغل حاليًا منصب كبير المهندسين المقيمين في Amazon Web Services. وهو عضو في مجموعة التركيز المتخصصة ، AWS Data Lab ، وتنطوي واجباته الأساسية على العمل مع فرق القيادة التنفيذية لعملاء AWS الاستراتيجيين لتطوير خرائط طريقهم للبيانات والتحليلات والذكاء الاصطناعي / تعلم الآلة. تتعاون Suvendu بشكل وثيق مع العملاء لتنفيذ هندسة البيانات ، ومركز البيانات ، وبحيرة البيانات ، وحوكمة البيانات ، وحلول EDW ، بالإضافة إلى إستراتيجية بيانات المؤسسة وإدارة البيانات.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/build-a-transactional-data-lake-using-apache-iceberg-aws-glue-and-cross-account-data-shares-using-aws-lake-formation-and-amazon-athena/

