برعاية المحتوى
هذا الدليل "خمس أساسيات لكل طبقة الدلالية"، يمكن أن تساعدك على فهم مدى اتساع الطبقة الدلالية الحديثة.
تجربة البيانات المدعومة بالذكاء الاصطناعي
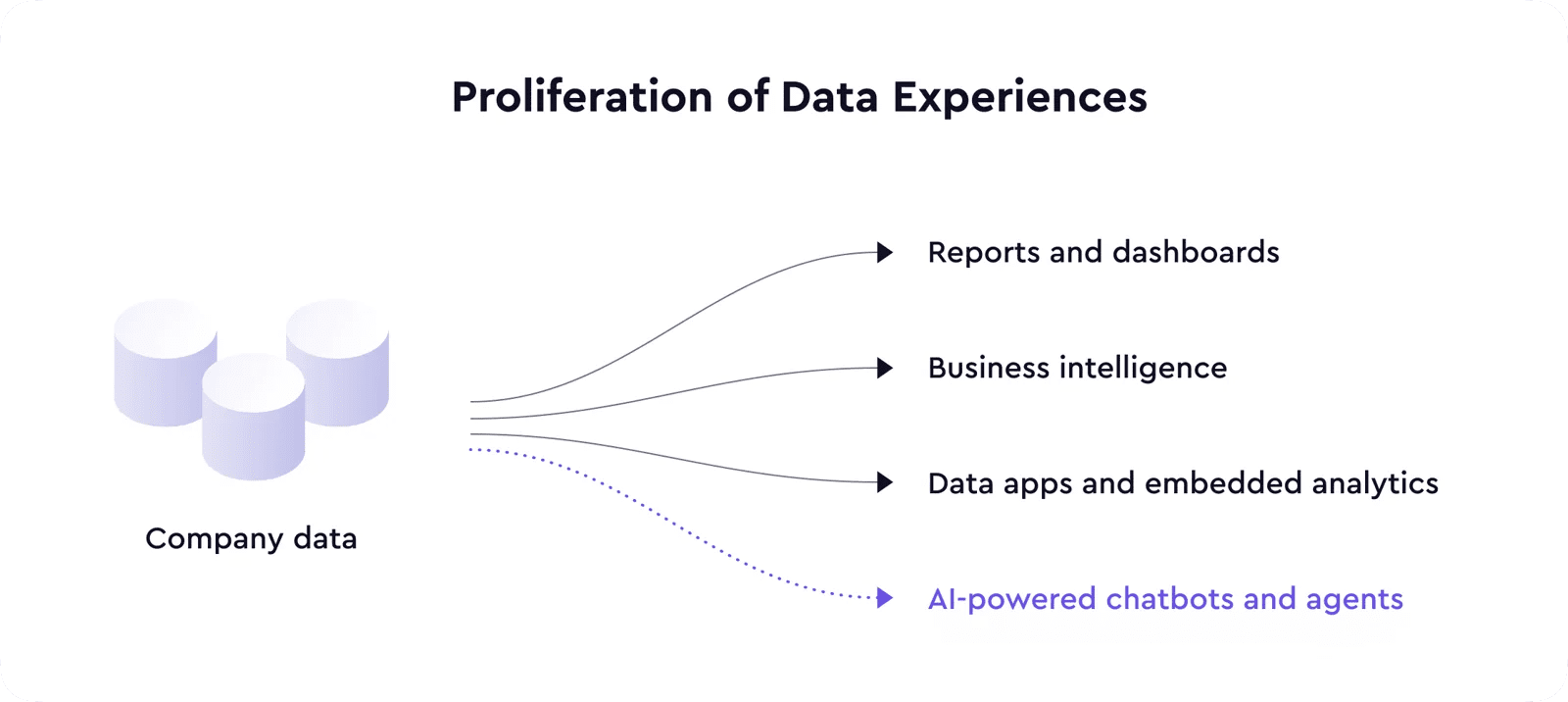
لقد أتاح تطور التقنيات الأمامية دمج تجارب التحليلات عالية الجودة مباشرة في العديد من منتجات البرمجيات، مما أدى إلى تسريع انتشار منتجات وتجارب البيانات.
والآن، مع وصول نماذج اللغات الكبيرة، فإننا نعيش خطوة أخرى من التغيير في التكنولوجيا التي ستمكن العديد من الميزات الجديدة وحتى في ظهور فئة جديدة تمامًا من المنتجات عبر حالات الاستخدام والمجالات المتعددة - بما في ذلك البيانات.
يأخذ LLMs طبقة استهلاك البيانات إلى المستوى التالي من خلال تجارب البيانات المدعومة بالذكاء الاصطناعي والتي تتراوح من روبوتات الدردشة التي تجيب على الأسئلة المتعلقة ببيانات عملك إلى وكلاء الذكاء الاصطناعي الذين يقومون بإجراءات بناءً على الإشارات والحالات الشاذة في البيانات.
الطبقة الدلالية تعطي السياق لـ LLMs
تعد ماجستير إدارة الأعمال (LLMs) بالفعل تغييرًا تدريجيًا، ولكن حتماً، كما هو الحال مع كل تقنية، تأتي مع حدودها. ماجستير في القانون يهلوس. لم تكن مشكلة القمامة في الداخل أو الخارج مشكلة أكثر من أي وقت مضى. دعونا نفكر في الأمر على هذا النحو: عندما يكون من الصعب على البشر فهم البيانات غير المتسقة وغير المنظمة، فإن LLM ببساطة ستعمل على مضاعفة هذا الارتباك لإنتاج إجابات خاطئة.
لا يمكننا تغذية LLM بمخطط قاعدة البيانات ونتوقع منه إنشاء SQL الصحيح. للعمل بشكل صحيح وتنفيذ إجراءات جديرة بالثقة، فإنه يحتاج إلى سياق ودلالات كافية حول البيانات التي يستهلكها؛ يجب أن يفهم المقاييس والأبعاد والكيانات والجوانب الارتباطية للبيانات التي يتم تشغيلها من خلالها. في الأساس، يحتاج LLM إلى طبقة دلالية.
تقوم الطبقة الدلالية بتنظيم البيانات في تعريفات أعمال ذات معنى ثم تسمح بالاستعلام عن هذه التعريفات - بدلاً من الاستعلام عن قاعدة البيانات مباشرة.
يعد تطبيق "الاستعلام" بنفس أهمية تطبيق "التعريفات" لأنه يفرض LLM للاستعلام عن البيانات من خلال الطبقة الدلالية، مما يضمن صحة الاستعلامات والبيانات التي يتم إرجاعها. وبذلك تحل الطبقة الدلالية مشكلة الهلوسة في LLM.

علاوة على ذلك، فإن الجمع بين ماجستير إدارة الأعمال والطبقات الدلالية يمكن أن يؤدي إلى تمكين جيل جديد من تجارب البيانات المدعومة بالذكاء الاصطناعي. في Cube، شهدنا بالفعل العديد من المؤسسات تقوم ببناء تطبيقات داخلية مخصصة مدعومة بـ LLM، والشركات الناشئة، مثل Delphi، تبني حلولًا خارج الصندوق فوق الطبقة الدلالية لـ Cube (عرض توضيحي هنا).
على حافة هذه الطليعة التطويرية، نرى أن Cube جزء لا يتجزأ من مجموعة تقنيات الذكاء الاصطناعي الحديثة حيث أنها تقع على رأس مستودعات البيانات، مما يوفر السياق لوكلاء الذكاء الاصطناعي ويعمل كواجهة للاستعلام عن البيانات.

يوفر نموذج بيانات Cube البنية والتعريفات المستخدمة كسياق لـ LLM لفهم البيانات وإنشاء الاستعلامات الصحيحة. لا تحتاج LLM إلى التنقل بين حسابات الصلات والمقاييس المعقدة لأن Cube يلخصها ويوفر واجهة بسيطة تعمل على المصطلحات على مستوى الأعمال بدلاً من أسماء جداول وأعمدة SQL. يساعد هذا التبسيط LLM على أن يكون أقل عرضة للخطأ ويتجنب الهلوسة.
على سبيل المثال، سيقوم التطبيق المستند إلى الذكاء الاصطناعي أولاً بقراءة نقطة نهاية واجهة برمجة التطبيقات التعريفية الخاصة بـ Cube، وتنزيل جميع تعريفات الطبقة الدلالية وتخزينها كتضمينات في قاعدة بيانات متجهة. لاحقًا، عندما يرسل المستخدم استعلامًا، سيتم استخدام هذه التضمينات في المطالبة إلى LLM لتوفير سياق إضافي. سوف تستجيب LLM بعد ذلك باستعلام تم إنشاؤه إلى Cube، وسيقوم التطبيق بتنفيذه. يمكن تكرار هذه العملية عدة مرات للإجابة على الأسئلة المعقدة أو إنشاء تقارير موجزة.
الأداء
فيما يتعلق بأوقات الاستجابة - عند العمل على استعلامات ومهام معقدة، قد يحتاج نظام الذكاء الاصطناعي إلى الاستعلام عن الطبقة الدلالية عدة مرات، مع تطبيق مرشحات مختلفة.
لذلك، لضمان أداء معقول، يجب تخزين هذه الاستعلامات مؤقتًا وعدم دفعها دائمًا إلى مستودعات البيانات الأساسية. يوفر Cube محرك ذاكرة تخزين مؤقت علائقي لإنشاء تجميعات مسبقة أعلى البيانات الأولية وتنفيذ الوعي التجميعي لتوجيه الاستعلامات إلى هذه التجميعات عندما يكون ذلك ممكنًا.
حماية
وأخيرا، لا ينبغي أبدا أن يكون الأمن والتحكم في الوصول فكرة لاحقة عند بناء التطبيقات القائمة على الذكاء الاصطناعي. كما ذكرنا سابقًا، قد يؤدي إنشاء لغة SQL أولية وتنفيذها في مستودع بيانات إلى نتائج خاطئة.
ومع ذلك، يشكل الذكاء الاصطناعي خطرًا إضافيًا: نظرًا لأنه لا يمكن التحكم فيه وقد يؤدي إلى إنشاء لغة SQL عشوائية، فإن الوصول المباشر بين الذكاء الاصطناعي ومخازن البيانات الأولية يمكن أن يكون أيضًا ثغرة أمنية كبيرة. بدلاً من ذلك، يمكن أن يؤدي إنشاء SQL من خلال الطبقة الدلالية إلى ضمان تطبيق سياسات التحكم في الوصول الدقيقة.
وأكثر من ذلك ...
لدينا الكثير من عمليات التكامل المثيرة مع النظام البيئي للذكاء الاصطناعي في متجرنا ولا يمكننا الانتظار لمشاركتها معك. وفي الوقت نفسه، إذا كنت تعمل على تطبيق مدعوم بالذكاء الاصطناعي، فكر في اختبار Cube Cloud مجانًا.
تنزيل الدليل "خمس ميزات أساسية لكل طبقة دلالية" لتعلم المزيد.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/10/cube-semantic-layer-backbone-aipowered-data-experiences?utm_source=rss&utm_medium=rss&utm_campaign=semantic-layer-the-backbone-of-ai-powered-data-experiences

