صورة المؤلف
هناك العديد من الدورات التدريبية والموارد المتاحة حول التعلم الآلي وعلوم البيانات، ولكن القليل جدًا منها يتعلق بهندسة البيانات. وهذا يثير بعض الأسئلة. هل هو مجال صعب؟ هل تقدم رواتب منخفضة؟ ألا تعتبر مثيرة مثل الأدوار التقنية الأخرى؟ ومع ذلك، فإن الواقع هو أن العديد من الشركات تبحث بنشاط عن المواهب في مجال هندسة البيانات وتقدم رواتب كبيرة، تتجاوز أحيانًا 200,000 دولار أمريكي. يلعب مهندسو البيانات دورًا حاسمًا كمهندسين لمنصات البيانات، حيث يقومون بتصميم وبناء الأنظمة الأساسية التي تمكن علماء البيانات وخبراء التعلم الآلي من العمل بفعالية.
ولمعالجة هذه الفجوة في الصناعة، قدم DataTalkClub معسكر تدريب تحويلي ومجاني، "Zoomcamp هندسة البيانات". تم تصميم هذه الدورة لتمكين المبتدئين أو المحترفين الذين يتطلعون إلى تغيير مهنتهم، وتزويدهم بالمهارات الأساسية والخبرة العملية في هندسة البيانات.
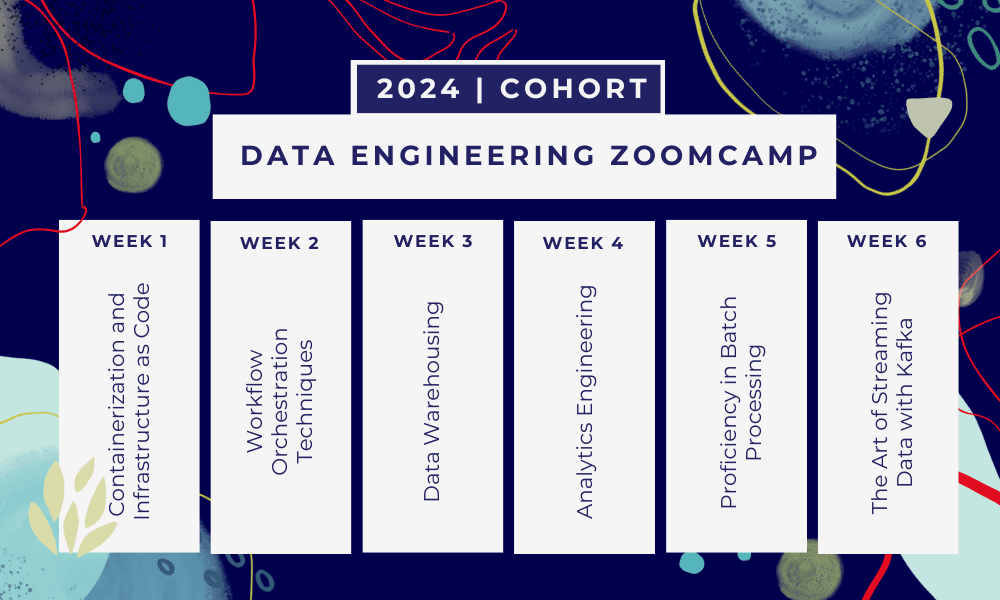
هذا هو معسكر تدريبي لمدة 6 أسابيع حيث ستتعلم من خلال دورات متعددة ومواد القراءة وورش العمل والمشاريع. في نهاية كل وحدة، سيتم إعطاؤك واجبًا منزليًا لممارسة ما تعلمته.
- الأسبوع شنومكس: مقدمة إلى GCP وDocker وPostgres وTerraform وإعداد البيئة.
- الأسبوع شنومكس: تنسيق سير العمل مع Mage.
- الأسبوع شنومكس: تخزين البيانات باستخدام BigQuery والتعلم الآلي باستخدام BigQuery.
- الأسبوع شنومكس: مهندس تحليلي مع dbt وGoogle Data Studio وMetabase.
- الأسبوع شنومكس: معالجة الدفعات باستخدام Spark.
- الأسبوع شنومكس: الجري مع كافكا.
صورة من DataTalksClub / data-engineering-zoomcamp
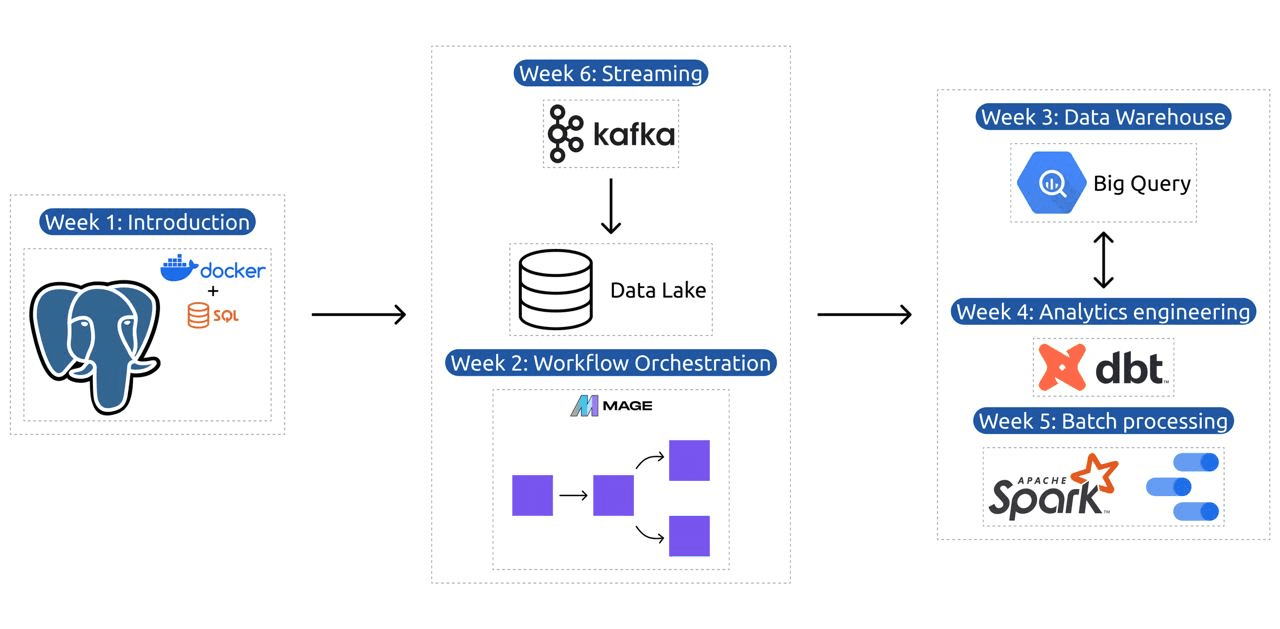
يحتوي المنهج على 6 وحدات وورشتي عمل ومشروع يغطي كل ما يلزم لتصبح مهندس بيانات محترفًا.
الوحدة 1: إتقان استخدام الحاويات والبنية التحتية كرمز
في هذه الوحدة، ستتعرف على Docker وPostgres، بدءًا من الأساسيات والتقدم من خلال البرامج التعليمية التفصيلية حول إنشاء خطوط أنابيب البيانات، وتشغيل Postgres مع Docker، والمزيد.
تغطي الوحدة أيضًا الأدوات الأساسية مثل pgAdmin وDocker-compose وموضوعات تجديد SQL، مع محتوى اختياري على شبكة Docker وإرشادات خاصة لمستخدمي نظام Linux الفرعي لنظام Windows. في النهاية، تقدم لك الدورة التدريبية GCP وTerraform، مما يوفر فهمًا شاملاً للنقل بالحاويات والبنية التحتية كرمز أساسي للبيئات السحابية الحديثة.
الوحدة 2: تقنيات تنسيق سير العمل
تقدم الوحدة استكشافًا متعمقًا لـ Mage، وهو إطار هجين مبتكر مفتوح المصدر لتحويل البيانات وتكاملها. تبدأ هذه الوحدة بأساسيات تنسيق سير العمل، والتقدم إلى التدريبات العملية مع Mage، بما في ذلك إعدادها عبر Docker وبناء خطوط أنابيب ETL من API إلى Postgres وGoogle Cloud Storage (GCS)، ثم إلى BigQuery.
يضمن مزيج الوحدة من مقاطع الفيديو والموارد والمهام العملية تجربة تعليمية شاملة، وتزويد المتعلمين بالمهارات اللازمة لإدارة سير عمل البيانات المتطورة باستخدام Mage.
ورشة العمل 1: استراتيجيات استيعاب البيانات
في ورشة العمل الأولى، ستتقن بناء خطوط أنابيب فعالة لاستيعاب البيانات. تركز ورشة العمل على المهارات الأساسية مثل استخراج البيانات من واجهات برمجة التطبيقات والملفات، وتطبيع البيانات وتحميلها، وتقنيات التحميل المتزايد. بعد الانتهاء من ورشة العمل هذه، ستتمكن من إنشاء خطوط بيانات فعالة مثل مهندس بيانات كبير.
الوحدة 3: تخزين البيانات
الوحدة عبارة عن استكشاف متعمق لتخزين البيانات وتحليلها، مع التركيز على تخزين البيانات باستخدام BigQuery. ويغطي المفاهيم الأساسية مثل التقسيم والتجميع، ويتعمق في أفضل ممارسات BigQuery. تتقدم الوحدة إلى موضوعات متقدمة، لا سيما تكامل التعلم الآلي (ML) مع BigQuery، وتسليط الضوء على استخدام SQL لتعلم الآلة، وتوفير الموارد حول ضبط المعلمات الفائقة، والمعالجة المسبقة للميزات، ونشر النموذج.
الوحدة 4: هندسة التحليلات
تركز وحدة هندسة التحليلات على بناء مشروع باستخدام dbt (أداة بناء البيانات) مع مستودع بيانات موجود، إما BigQuery أو PostgreSQL.
تغطي الوحدة إعداد dbt في كل من البيئات السحابية والمحلية، وإدخال مفاهيم الهندسة التحليلية، وETL مقابل ELT، ونمذجة البيانات. كما أنه يغطي ميزات dbt المتقدمة مثل النماذج الإضافية والعلامات والخطافات واللقطات.
في النهاية، تقدم الوحدة تقنيات لتصور البيانات المحولة باستخدام أدوات مثل Google Data Studio وMetabase، وتوفر موارد لاستكشاف الأخطاء وإصلاحها وتحميل البيانات بكفاءة.
الوحدة 5: الكفاءة في معالجة الدفعات
تغطي هذه الوحدة معالجة الدُفعات باستخدام Apache Spark، بدءًا من مقدمات لمعالجة الدُفعات وSpark، إلى جانب تعليمات التثبيت لأنظمة التشغيل Windows وLinux وMacOS.
يتضمن استكشاف Spark SQL وDataFrames، وإعداد البيانات، وتنفيذ عمليات SQL، وفهم الأجزاء الداخلية لـ Spark. وأخيرًا، يتم الانتهاء من تشغيل Spark في السحابة ودمج Spark مع BigQuery.
الوحدة 6: فن تدفق البيانات مع كافكا
تبدأ الوحدة بمقدمة لمفاهيم معالجة التدفق، يتبعها استكشاف متعمق لـ Kafka، بما في ذلك أساسياتها، والتكامل مع Confluent Cloud، والتطبيقات العملية التي تشمل المنتجين والمستهلكين.
تغطي الوحدة أيضًا تكوين Kafka وتدفقاته، وتتناول موضوعات مثل انضمام الدفق والاختبار والنوافذ واستخدام Kafka ksqldb & Connect. بالإضافة إلى ذلك، فهو يوسع نطاق تركيزه ليشمل بيئات Python وJVM، ويضم Faust for Python لمعالجة التدفق، وPyspark – Streaming Streaming، وأمثلة Scala لـ Kafka Streams.
ورشة العمل الثانية: معالجة التدفق باستخدام SQL
سوف تتعلم كيفية معالجة وإدارة البيانات المتدفقة باستخدام RisingWave، الذي يوفر حلاً فعالاً من حيث التكلفة مع تجربة بأسلوب PostgreSQL لتمكين تطبيقات معالجة التدفق لديك.
المشروع: تطبيق هندسة البيانات في العالم الحقيقي
الهدف من هذا المشروع هو تنفيذ جميع المفاهيم التي تعلمناها في هذه الدورة لبناء خط بيانات شامل. ستقوم بالإنشاء لإنشاء لوحة معلومات تتكون من مربعين عن طريق تحديد مجموعة بيانات، وإنشاء خط أنابيب لمعالجة البيانات وتخزينها في بحيرة بيانات، وبناء خط أنابيب لنقل البيانات المعالجة من بحيرة البيانات إلى مستودع بيانات، وتحويل البيانات الموجودة في مستودع البيانات وإعدادها للوحة المعلومات، وأخيرًا بناء لوحة معلومات لعرض البيانات بشكل مرئي.
تفاصيل الفوج 2024
- التسجيل: التسجيل أونلاين
- تاريخ البدء: 15 يناير 2024 الساعة 17:00 بتوقيت وسط أوروبا
- التعلم الذاتي مع الدعم الموجه
- مجلد المجموعة مع الواجبات المنزلية والمواعيد النهائية
- تفاعلي مجتمع سلاك للتعلم من الأقران
المتطلبات الأساسية المسبقة
- مهارات البرمجة وسطر الأوامر الأساسية
- الأساس في SQL
- بايثون: مفيدة ولكنها ليست إلزامية
مدربون خبراء يقودون رحلتك
- أنكوش خانا
- فيكتوريا بيريز مولا
- أليكسي جريجوريف
- مات بالمر
- لويس اوليفيرا
- مايكل شوميكر
انضم إلى مجموعة 2024 وابدأ التعلم مع مجتمع هندسة البيانات المذهل. من خلال التدريب الذي يقوده الخبراء، والخبرة العملية، والمناهج الدراسية المصممة خصيصًا لتلبية احتياجات الصناعة، لا يزودك هذا المعسكر التدريبي بالمهارات اللازمة فحسب، بل يضعك أيضًا في طليعة المسار الوظيفي المربح والمطلوب. سجل اليوم وحوّل طموحاتك إلى واقع!
عابد علي عوان (@ 1abidaliawan) هو عالم بيانات متخصص محترف يحب بناء نماذج التعلم الآلي. يركز حاليًا على إنشاء المحتوى وكتابة مدونات تقنية حول تقنيات التعلم الآلي وعلوم البيانات. عابد حاصل على درجة الماجستير في إدارة التكنولوجيا ودرجة البكالوريوس في هندسة الاتصالات. تتمثل رؤيته في بناء منتج للذكاء الاصطناعي باستخدام شبكة عصبية بيانية للطلاب الذين يعانون من مرض عقلي.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer

