تحليلات بيانات Amazon Kinesis يجعل من السهل تحويل البيانات المتدفقة وتحليلها في الوقت الفعلي.
في هذا المنشور ، نناقش سبب توصية AWS بالانتقال من Kinesis Data Analytics لتطبيقات SQL إلى تحليلات بيانات Amazon Kinesis لـ Apache Flink للاستفادة من إمكانيات البث المتقدمة لـ Apache Flink. نعرض أيضًا كيفية استخدام Kinesis Data Analytics Studio لاختبار وضبط تحليلك قبل نشر التطبيقات التي تم ترحيلها. إذا لم يكن لديك أي تحليلات بيانات Kinesis لتطبيقات SQL ، فلا يزال هذا المنشور يوفر خلفية عن العديد من حالات الاستخدام التي ستراها في حياتك المهنية في مجال تحليل البيانات وكيف يمكن أن تساعدك خدمات Amazon Data Analytics في تحقيق أهدافك.
تحليلات بيانات Kinesis لـ Apache Flink هي خدمة Apache Flink مُدارة بالكامل. ما عليك سوى تحميل تطبيق JAR أو الملف القابل للتنفيذ ، وستقوم AWS بإدارة البنية التحتية وتنسيق مهام Flink. لتبسيط الأمور ، يعد Kinesis Data Analytics Studio بيئة دفتر ملاحظات تستخدم Apache Flink وتسمح لك بالاستعلام عن تدفقات البيانات وتطوير استعلامات SQL أو إثبات أعباء عمل المفهوم قبل توسيع نطاق تطبيقك إلى الإنتاج في دقائق.
نوصي باستخدام Kinesis Data Analytics لـ Apache Flink أو Kinesis Data Analytics Studio عبر Kinesis Data Analytics for SQL. وذلك لأن Kinesis Data Analytics لـ Apache Flink و Kinesis Data Analytics Studio يقدمان ميزات متقدمة لمعالجة تدفق البيانات ، بما في ذلك دلالات المعالجة لمرة واحدة بالضبط ، ونوافذ وقت الحدث ، وقابلية التوسع باستخدام وظائف محددة من قبل المستخدم (UDFs) والتكاملات المخصصة ، ودعم اللغة الإلزامي ، ودائم حالة التطبيق ، القياس الأفقي ، دعم مصادر البيانات المتعددة ، والمزيد. هذه ضرورية لضمان الدقة والاكتمال والاتساق والموثوقية في معالجة دفق البيانات ولا تتوفر مع Kinesis Data Analytics for SQL.
حل نظرة عامة
بالنسبة لحالة الاستخدام الخاصة بنا ، نستخدم العديد من خدمات AWS لدفق عينات بيانات مستشعرات السيارات واستيعابها وتحويلها وتحليلها في الوقت الفعلي باستخدام Kinesis Data Analytics Studio. يسمح لنا Kinesis Data Analytics Studio بإنشاء دفتر ملاحظات ، وهو بيئة تطوير قائمة على الويب. باستخدام أجهزة الكمبيوتر المحمولة ، تحصل على تجربة تطوير تفاعلية بسيطة جنبًا إلى جنب مع الإمكانات المتقدمة التي توفرها Apache Flink. يستخدم Kinesis Data Analytics Studio اباتشي زيبلين كجهاز كمبيوتر محمول ، ويستخدم اباتشي فلينك كمحرك معالجة الدفق. تجمع أجهزة الكمبيوتر المحمولة Kinesis Data Analytics Studio بسلاسة بين هذه التقنيات لجعل التحليلات المتقدمة لتدفقات البيانات في متناول المطورين من جميع مجموعات المهارات. يتم توفير أجهزة الكمبيوتر المحمولة بسرعة وتوفر لك طريقة لعرض بياناتك المتدفقة وتحليلها على الفور. يوفر Apache Zeppelin دفاتر ملاحظات Studio الخاصة بك مع مجموعة كاملة من أدوات التحليل ، بما في ذلك ما يلي:
- عرض مرئي للمعلومات
- تصدير البيانات إلى الملفات
- التحكم في تنسيق الإخراج لتسهيل التحليل
- القدرة على تحويل الكمبيوتر الدفتري إلى تطبيق إنتاج قابل للتطوير
على عكس تحليلات بيانات Kinesis لتطبيقات SQL ، يضيف Kinesis Data Analytics لـ Apache Flink ملحق بعد دعم SQL:
- ضم بيانات الدفق بين عدة تدفقات بيانات Kinesis ، أو بين دفق بيانات Kinesis و Amazon Managed Streaming لأباتشي كافكا (Amazon MSK) موضوع
- تصور في الوقت الحقيقي للبيانات المحولة في تدفق البيانات
- استخدام نصوص Python أو برامج Scala داخل نفس التطبيق
- تغيير إزاحة طبقة التدفق
ميزة أخرى لتحليلات بيانات Kinesis لـ Apache Flink هي قابلية التوسع المحسّنة للحل بمجرد نشره ، لأنه يمكنك توسيع نطاق الموارد الأساسية لتلبية الطلب. في Kinesis Data Analytics لتطبيقات SQL ، يتم إجراء القياس عن طريق إضافة المزيد من المضخات لإقناع التطبيق بإضافة المزيد من الموارد.
في حلنا ، نقوم بإنشاء دفتر ملاحظات للوصول إلى بيانات مستشعر السيارات ، وإثراء البيانات ، وإرسال المخرجات الغنية من دفتر ملاحظات Kinesis Data Analytics Studio إلى أمازون كينسيس داتا فايرهاوس تيار التسليم للتسليم إلى خدمة تخزين أمازون البسيطة (Amazon S3) بحيرة البيانات. يمكن استخدام خط الأنابيب هذا أيضًا لإرسال البيانات إلى خدمة Amazon OpenSearch أو أهداف أخرى للمعالجة الإضافية والتصور.

تحليلات بيانات Kinesis لتطبيقات SQL مقابل تحليلات بيانات Kinesis لـ Apache Flink
في مثالنا ، نقوم بتنفيذ الإجراءات التالية على تدفق البيانات:
- قم بالاتصال بـ الأمازون كينسيس دفق البيانات تدفق المعلومات.
- عرض بيانات الدفق.
- تحويل وإثراء البيانات.
- تعامل مع البيانات باستخدام بايثون.
- إعادة البيانات إلى تدفق توصيل Firehose.
لمقارنة تحليلات بيانات Kinesis لتطبيقات SQL مع تحليلات بيانات Kinesis لـ Apache Flink ، فلنناقش أولاً كيفية عمل تحليلات بيانات Kinesis لتطبيقات SQL.
في جذر Kinesis Data Analytics لتطبيق SQL هو مفهوم الدفق داخل التطبيق. يمكنك التفكير في الدفق داخل التطبيق كجدول يحتفظ ببيانات التدفق حتى تتمكن من تنفيذ الإجراءات عليه. يتم تعيين الدفق داخل التطبيق إلى مصدر دفق مثل دفق بيانات Kinesis. للحصول على البيانات في الدفق داخل التطبيق ، قم أولاً بإعداد مصدر في وحدة التحكم الإدارية لتحليلات بيانات Kinesis لتطبيق SQL. بعد ذلك ، قم بإنشاء مضخة تقرأ البيانات من دفق المصدر وتضعها في الجدول. يعمل استعلام المضخة بشكل مستمر ويغذي بيانات المصدر في التدفق داخل التطبيق. يمكنك إنشاء مضخات متعددة من مصادر متعددة لتغذية التدفق داخل التطبيق. ثم يتم تشغيل الاستعلامات في التدفق داخل التطبيق ، ويمكن تفسير النتائج أو إرسالها إلى وجهات أخرى لمزيد من المعالجة أو التخزين.
يوضح SQL التالي إعداد دفق ومضخة داخل التطبيق:
CREATE OR REPLACE STREAM "TEMPSTREAM" ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)); CREATE OR REPLACE PUMP "SAMPLEPUMP" AS INSERT INTO "TEMPSTREAM" ("column1", "column2", "column3") SELECT STREAM inputcolumn1, inputcolumn2, inputcolumn3
FROM "INPUTSTREAM";يمكن قراءة البيانات من التدفق داخل التطبيق باستخدام استعلام SQL SELECT:
SELECT *
FROM "TEMPSTREAM"عند إنشاء نفس الإعداد في Kinesis Data Analytics Studio ، فإنك تستخدم بيئة Apache Flink الأساسية للاتصال بمصدر التدفق ، وإنشاء دفق البيانات في عبارة واحدة باستخدام موصل. يوضح المثال التالي الاتصال بالمصدر نفسه الذي استخدمناه من قبل ، ولكن باستخدام Apache Flink:
CREATE TABLE `MY_TABLE` ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)
) WITH ( 'connector' = 'kinesis', 'stream' = sample-kinesis-stream', 'aws.region' = 'aws-kinesis-region', 'scan.stream.initpos' = 'LATEST', 'format' = 'json' );MY_TABLE هو الآن دفق بيانات سيستقبل البيانات باستمرار من نموذجنا لبيانات Kinesis. يمكن الاستعلام عنها باستخدام عبارة SQL SELECT:
SELECT column1, column2, column3
FROM MY_TABLE;على الرغم من أن تحليلات بيانات Kinesis لتطبيقات SQL تستخدم ملف مجموعة فرعية من معيار SQL: 2008 مع ملحقات لتمكين العمليات على تدفق البيانات ، دعم SQL Apache Flink مبني على اباتشي كالسيتالتي تطبق معيار SQL.
من المهم أيضًا الإشارة إلى أن Kinesis Data Analytics Studio يدعم PyFlink و Scala جنبًا إلى جنب مع SQL في نفس الكمبيوتر المحمول. يتيح لك ذلك تنفيذ طرق معقدة وبرمجية على بياناتك المتدفقة غير الممكنة باستخدام SQL.
المتطلبات الأساسية المسبقة
خلال هذا التمرين ، قمنا بإعداد موارد AWS المختلفة وإجراء استعلامات التحليلات. للمتابعة ، تحتاج إلى حساب AWS مع وصول المسؤول. إذا لم يكن لديك بالفعل حساب AWS له حق وصول المسؤول ، إنشاء واحد الآن. الخدمات الموضحة في هذا المنشور قد تفرض رسومًا على حساب AWS الخاص بك. تأكد من اتباع تعليمات التنظيف في نهاية هذا المنشور.
تكوين تدفق البيانات
في مجال البث ، غالبًا ما يتم تكليفنا باستكشاف وتحويل وإثراء البيانات القادمة من مستشعرات إنترنت الأشياء (IoT). لإنشاء بيانات المستشعر في الوقت الفعلي ، نستخدم ملف محاكي جهاز AWS IoT. يعمل هذا المحاكي داخل حساب AWS الخاص بك ويوفر واجهة ويب تتيح للمستخدمين تشغيل أساطيل من الأجهزة المتصلة فعليًا من قالب يحدده المستخدم ثم محاكاتها لنشر البيانات على فترات منتظمة إلى AWS إنترنت الأشياء الأساسية. هذا يعني أنه يمكننا بناء أسطول افتراضي من الأجهزة لتوليد بيانات نموذجية لهذا التمرين.
ننشر IoT Device Simulator باستخدام ما يلي الأمازون CloudFront قالب. إنه يتولى إنشاء جميع الموارد اللازمة في حسابك.
- على حدد تفاصيل المكدس الصفحة ، قم بتعيين اسم لمجموعة الحلول الخاصة بك.
- تحت المعلمات، راجع معلمات نموذج الحل هذا وقم بتعديلها حسب الضرورة.
- في حالة البريد الالكتروني للمستخدم، أدخل بريدًا إلكترونيًا صالحًا لتلقي رابط وكلمة مرور لتسجيل الدخول إلى IoT Device Simulator UI.
- اختار التالى.
- على تكوين خيارات المكدس الصفحة ، اختر التالى.
- على التقيم الصفحة ، راجع الإعدادات وقم بتأكيدها. حدد خانات الاختيار للإقرار بإنشاء القالب إدارة الهوية والوصول AWS (IAM) الموارد.
- اختار إنشاء مكدس.
يستغرق المكدس حوالي 10 دقائق للتثبيت.
- عندما تتلقى دعوة بالبريد الإلكتروني ، اختر ارتباط CloudFront وقم بتسجيل الدخول إلى IoT Device Simulator باستخدام بيانات الاعتماد المقدمة في البريد الإلكتروني.
يحتوي الحل على عرض توضيحي للسيارات تم إنشاؤه مسبقًا والذي يمكننا استخدامه لبدء تسليم بيانات المستشعر بسرعة إلى AWS.
- على نوع الجهاز الصفحة ، اختر إنشاء نوع الجهاز.
- اختار عرض السيارات.
- الحمولة يتم ملؤها تلقائيًا. أدخل اسمًا لجهازك ، وأدخل
automotive-topicكموضوع.
- اختار حفظ.
الآن نقوم بإنشاء محاكاة.
- على المحاكاة الصفحة ، اختر إنشاء محاكاة.
- في حالة نوع المحاكاة، اختر عرض السيارات.
- في حالة حدد نوع الجهاز، اختر الجهاز التجريبي الذي قمت بإنشائه.
- في حالة الفاصل الزمني لنقل البيانات و مدة نقل البيانات، أدخل القيم التي تريدها.
يمكنك إدخال أي قيم تريدها ، ولكن استخدم ما لا يقل عن 10 أجهزة ترسل كل 10 ثوانٍ. سترغب في تعيين مدة نقل البيانات على بضع دقائق ، أو ستحتاج إلى إعادة تشغيل المحاكاة عدة مرات أثناء التمرين.
- اختار حفظ.

الآن يمكننا تشغيل المحاكاة.
- على المحاكاة الصفحة ، حدد المحاكاة المطلوبة ، واختر ابدأ المحاكاة.
بدلاً من ذلك ، اختر المزيد بجوار المحاكاة التي تريد تشغيلها ، ثم اختر آبدأ لتشغيل المحاكاة.
- لعرض المحاكاة ، اختر المزيد بجوار المحاكاة التي تريد عرضها.
إذا كانت المحاكاة قيد التشغيل ، فيمكنك عرض خريطة بمواقع الأجهزة وما يصل إلى 100 رسالة من أحدث الرسائل المرسلة إلى موضوع إنترنت الأشياء.
يمكننا الآن التحقق للتأكد من أن جهاز المحاكاة الخاص بنا يرسل بيانات المستشعر إلى AWS IoT Core.
- انتقل إلى وحدة التحكم AWS IoT Core.
تأكد من أنك في نفس المنطقة التي قمت بنشر جهاز IoT Device Simulator فيها.
- في جزء التنقل ، اختر عميل اختبار MQTT.
- أدخل مرشح الموضوع
automotive-topicواختر اشتراك.
طالما أن المحاكاة قيد التشغيل ، فسيتم عرض الرسائل التي يتم إرسالها إلى موضوع إنترنت الأشياء.

أخيرًا ، يمكننا تعيين قاعدة لتوجيه رسائل إنترنت الأشياء إلى تدفق بيانات Kinesis. سيوفر هذا الدفق بيانات المصدر الخاصة بنا لدفتر Kinesis Data Analytics Studio.
- في وحدة تحكم AWS IoT Core ، اختر توجيه الرسائل و قوانيـن.
- أدخل اسمًا للقاعدة ، مثل
automotive_route_kinesis، ثم اختر التالى.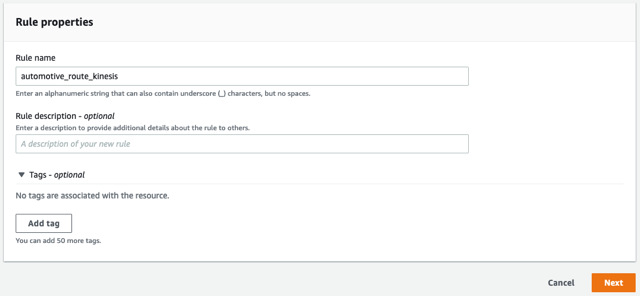
- قم بتوفير جملة SQL التالية. سيحدد SQL هذا جميع أعمدة الرسائل من ملف
automotive-topicيقوم IoT Device Simulator بنشر:
- اختار التالى.
- تحت إجراءات القاعدة، حدد تيار Kinesis كمصدر.
- اختار إنشاء دفق Kinesis جديد.
هذا يفتح نافذة جديدة.
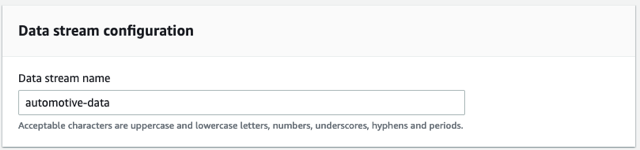
- في حالة اسم دفق البيانات، أدخل
automotive-data.
نحن نستخدم دفقًا متوفرًا لهذا التمرين.
- اختار إنشاء دفق البيانات.
يمكنك الآن إغلاق هذه النافذة والعودة إلى وحدة تحكم AWS IoT Core.
- اختر زر التحديث بجوار اسم الدفق، واختر ملف
automotive-dataتيار.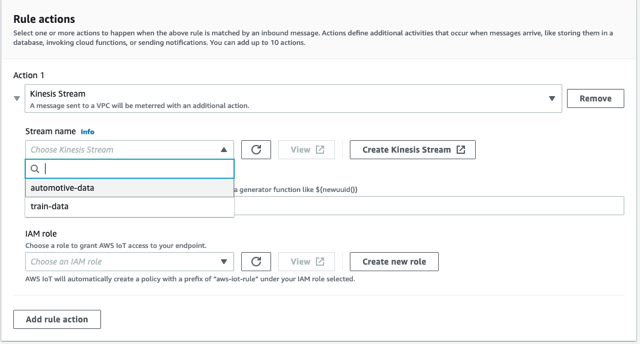
- اختار أنشئ دورًا جديدًا وتسمية الدور
automotive-role. - اختار التالى.
- راجع خصائص القاعدة واختر إنشاء.
تبدأ القاعدة في توجيه البيانات على الفور.
قم بإعداد Kinesis Data Analytics Studio
الآن وبعد أن أصبح لدينا بياناتنا تتدفق عبر AWS IoT Core وفي تدفق بيانات Kinesis ، يمكننا إنشاء دفتر ملاحظات Kinesis Data Analytics Studio الخاص بنا.
- في وحدة تحكم Amazon Kinesis ، اختر تطبيقات التحليلات في جزء التنقل.
- على استوديو علامة التبويب، اختر إنشاء دفتر الاستوديو.
- يترك إنشاء سريع مع نموذج التعليمات البرمجية المحدد.
- اسم دفتر الملاحظات
automotive-data-notebook.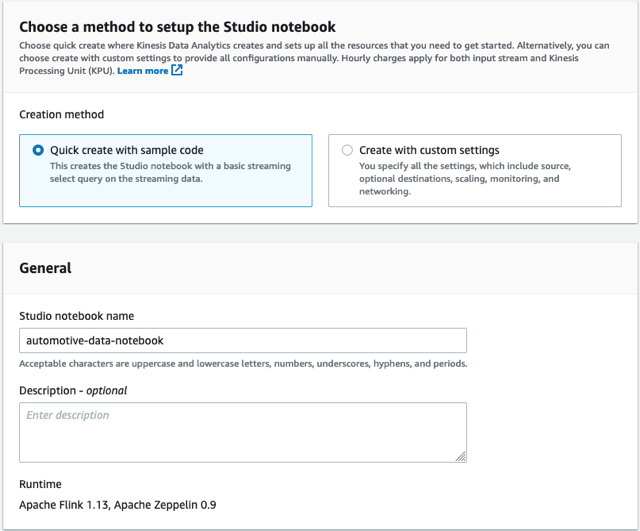
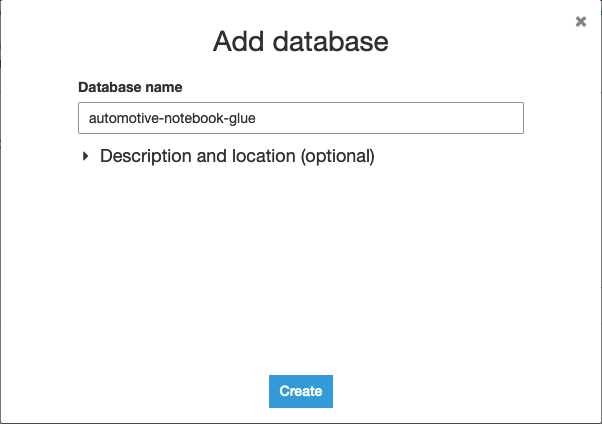
- اختار إنشاء لإنشاء جديد غراء AWS قاعدة بيانات في نافذة جديدة.
- اختار أضف قاعدة البيانات.

- قم بتسمية قاعدة البيانات
automotive-notebook-glue. - اختار إنشاء.
- العودة إلى إنشاء دفتر الاستوديو والقسم الخاص به.
- اختر تحديث واختر قاعدة بيانات AWS Glue الجديدة.
- اختار إنشاء دفتر الاستوديو.

- لبدء تشغيل دفتر Studio ، اختر يجري وتأكيد.

- بمجرد تشغيل الكمبيوتر الدفتري ، اختر دفتر الملاحظات واختر فتح في Apache Zeppelin.
- اختار مذكرة استيراد.
- اختار أضف من URL.

- أدخل عنوان URL التالي:
https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/BDB-2461/auto-notebook.ipynb. - اختار مذكرة استيراد.

- افتح الملاحظة الجديدة.
قم بإجراء تحليل تيار
في تطبيق Kinesis Data Analytics لتطبيق SQL ، نضيف الدورة التدريبية الخاصة بنا عبر وحدة التحكم الإدارية ، ثم نحدد دفقًا داخل التطبيق ونضخه لدفق البيانات من دفق بيانات Kinesis الخاص بنا. يعمل الدفق داخل التطبيق كجدول للاحتفاظ بالبيانات وإتاحتها لنا للاستعلام عنها. تأخذ المضخة البيانات من مصدرنا وتدفقها إلى دفقنا داخل التطبيق. يمكن بعد ذلك تشغيل الاستعلامات مقابل التدفق داخل التطبيق باستخدام SQL ، تمامًا كما كنا نستعلم عن أي جدول SQL. انظر الكود التالي:
CREATE OR REPLACE STREAM "AUTOSTREAM" ( `trip_id` CHAR(36), `VIN` CHAR(17), `brake` FLOAT, `steeringWheelAngle` FLOAT, `torqueAtTransmission` FLOAT, `engineSpeed` FLOAT, `vehicleSpeed` FLOAT, `acceleration` FLOAT, `parkingBrakeStatus` BOOLEAN, `brakePedalStatus` BOOLEAN, `transmissionGearPosition` VARCHAR(10), `gearLeverPosition` VARCHAR(10), `odometer` FLOAT, `ignitionStatus` VARCHAR(4), `fuelLevel` FLOAT, `fuelConsumedSinceRestart` FLOAT, `oilTemp` FLOAT, `location` VARCHAR(100), `timestamp` TIMESTAMP(3)); CREATE OR REPLACE PUMP "MYPUMP" AS INSERT INTO "AUTOSTREAM" ("trip_id", "VIN", "brake", "steeringWheelAngle", "torqueAtTransmission", "engineSpeed", "vehicleSpeed", "acceleration", "parkingBrakeStatus", "brakePedalStatus", "transmissionGearPosition", "gearLeverPosition", "odometer", "ignitionStatus", "fuelLevel", "fuelConsumedSinceRestart", "oilTemp", "location", "timestamp")
SELECT VIN, brake, steeringWheelAngle, torqueAtTransmission, engineSpeed, vehicleSpeed, acceleration, parkingBrakeStatus, brakePedalStatus, transmissionGearPosition, gearLeverPosition, odometer, ignitionStatus, fuelLevel, fuelConsumedSinceRestart, oilTemp, location, timestamp
FROM "INPUT_STREAM"
لترحيل تدفق ومضخة داخل التطبيق من Kinesis Data Analytics لتطبيق SQL إلى Kinesis Data Analytics Studio ، نقوم بتحويل هذا إلى عبارة CREATE واحدة عن طريق إزالة تعريف المضخة وتحديد kinesis الموصل. تنشئ الفقرة الأولى في دفتر Zeppelin موصلًا يتم تقديمه كجدول. يمكننا تحديد أعمدة لجميع العناصر في الرسالة الواردة ، أو مجموعة فرعية.

قم بتشغيل العبارة ، وستظهر نتيجة النجاح في دفتر ملاحظاتك. يمكننا الآن الاستعلام عن هذا الجدول باستخدام SQL ، أو يمكننا إجراء عمليات برمجية باستخدام هذه البيانات باستخدام PyFlink أو Scala.
قبل إجراء التحليلات في الوقت الفعلي على تدفق البيانات ، دعنا نلقي نظرة على كيفية تنسيق البيانات حاليًا. للقيام بذلك ، نقوم بتشغيل استعلام Flink SQL بسيط على الجدول الذي أنشأناه للتو. إن SQL المستخدم في تطبيق البث الخاص بنا مطابق لما يتم استخدامه في تطبيق SQL.

لاحظ أنه إذا لم تشاهد السجلات بعد بضع ثوانٍ ، فتأكد من أن IoT Device Simulator لا يزال قيد التشغيل.
إذا كنت تقوم أيضًا بتشغيل Kinesis Data Analytics لرمز SQL ، فقد ترى مجموعة نتائج مختلفة قليلاً. هذا هو عامل تمييز رئيسي آخر في Kinesis Data Analytics لـ Apache Flink ، لأن الأخير لديه مفهوم التسليم مرة واحدة بالضبط. إذا تم نشر هذا التطبيق في الإنتاج وتمت إعادة تشغيله أو في حالة حدوث إجراءات القياس ، يضمن Kinesis Data Analytics لـ Apache Flink أنك تتلقى كل رسالة مرة واحدة فقط ، بينما في Kinesis Data Analytics لتطبيق SQL ، تحتاج إلى مزيد من معالجة الدفق الوارد لضمان تتجاهل الرسائل المتكررة التي قد تؤثر على نتائجك.
يمكنك إيقاف الفقرة الحالية عن طريق اختيار أيقونة الإيقاف المؤقت. قد ترى خطأ معروضًا في دفتر ملاحظاتك عند إيقاف الاستعلام ، ولكن يمكن تجاهله. إنه فقط لإعلامك بإلغاء العملية.

يقوم Flink SQL بتنفيذ معيار SQL ، ويوفر طريقة سهلة لإجراء العمليات الحسابية على بيانات الدفق تمامًا كما تفعل عند الاستعلام عن جدول قاعدة بيانات. تتمثل إحدى المهام الشائعة أثناء إثراء البيانات في إنشاء حقل جديد لتخزين عملية حسابية أو تحويل (مثل من فهرنهايت إلى درجة مئوية) ، أو إنشاء بيانات جديدة لتقديم استعلامات أبسط أو تصورات محسنة في اتجاه مجرى النهر. قم بتشغيل الفقرة التالية لترى كيف يمكننا إضافة قيمة منطقية مسماة accelerating، والتي يمكننا استخدامها بسهولة في الحوض الخاص بنا لمعرفة ما إذا كانت السيارة تتسارع حاليًا في الوقت الذي تمت فيه قراءة المستشعر. لا تختلف العملية هنا بين تحليلات بيانات Kinesis لـ SQL و Kinesis Data Analytics لـ Apache Flink.

يمكنك إيقاف تشغيل الفقرة عند فحص العمود الجديد ، ومقارنة القيمة المنطقية الجديدة الخاصة بنا مع FLOAT acceleration العمود.
عادةً ما تكون البيانات التي يتم إرسالها من جهاز استشعار مضغوطة لتحسين زمن الوصول والأداء. يمكن أن تكون القدرة على إثراء دفق البيانات بالبيانات الخارجية وإثراء التدفق ، مثل معلومات السيارة الإضافية أو بيانات الطقس الحالية ، مفيدة للغاية. في هذا المثال ، لنفترض أننا نريد جلب البيانات المخزنة حاليًا في ملف CSV في Amazon S3 ، وإضافة عمود مسمى اللون يعكس نطاق سرعة المحرك الحالي.
يوفر Apache Flink SQL عدة ملفات موصلات المصدر لخدمات AWS والمصادر الأخرى. يتيح إنشاء جدول جديد كما فعلنا في الفقرة الأولى ولكن استخدام موصل نظام الملفات بدلاً من ذلك يسمح لـ Flink بالاتصال مباشرةً بـ Amazon S3 وقراءة بيانات المصدر الخاصة بنا. سابقًا في Kinesis Data Analytics لتطبيقات SQL ، لم يكن بإمكانك إضافة مراجع جديدة مضمنة. بدلا منك بيانات مرجعية محددة S3 وإضافته إلى تكوين التطبيق الخاص بك ، والذي يمكنك استخدامه كمرجع في SQL JOIN.
ملاحظة: إذا كنت لا تستخدم منطقة us-east-1 ، فيمكنك ذلك قم بتنزيل ملف csv وضع العنصر في حاوية S3 الخاصة بك. قم بالإشارة إلى ملف csv كـ s3a://<bucket-name>/<key-name>

بناءً على الاستعلام الأخير ، تقوم الفقرة التالية بتنفيذ SQL JOIN على بياناتنا الحالية وجدول مصدر البحث الجديد الذي أنشأناه.

الآن بعد أن أصبح لدينا دفق بيانات غنيًا ، نعيد بث هذه البيانات. في سيناريو العالم الحقيقي ، لدينا العديد من الخيارات بشأن ما يجب فعله ببياناتنا ، مثل إرسال البيانات إلى بحيرة بيانات S3 ، أو تدفق بيانات Kinesis آخر لمزيد من التحليل ، أو تخزين البيانات في خدمة البحث المفتوح للتصور. من أجل التبسيط ، نرسل البيانات إلى Kinesis Data Firehose ، والتي تقوم بتدفق البيانات إلى دلو S3 يعمل بمثابة بحيرة البيانات الخاصة بنا.
يمكن لـ Kinesis Data Firehose دفق البيانات إلى Amazon S3 ، خدمة البحث المفتوح ، الأمازون الأحمر مستودعات البيانات ، و Splunk ببضع نقرات.
قم بإنشاء تدفق توصيل Kinesis Data Firehose
لإنشاء تدفق التسليم الخاص بنا ، أكمل الخطوات التالية:
- في وحدة التحكم Kinesis Data Firehose ، اختر إنشاء دفق التسليم.
- اختار وضع مباشر لمصدر الدفق و الأمازون S3 كهدف.

- اسم تيار التسليم الخاص بك خرطوم السيارات.

- تحت إعدادات الوجهةأو إنشاء حاوية جديدة أو استخدام حاوية موجودة.
- قم بتدوين عنوان URL الخاص بحاوية S3.
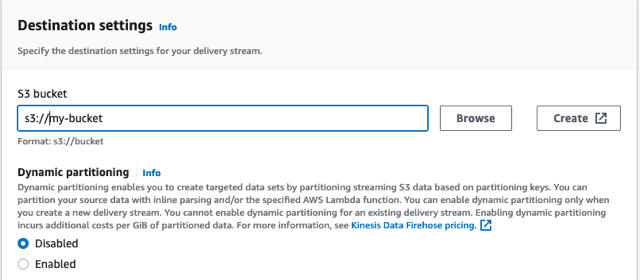
- اختار إنشاء دفق التسليم.
يستغرق الدفق بضع ثوانٍ لإنشائه.
- ارجع إلى وحدة تحليلات بيانات Kinesis واختر تطبيقات الجري.
- على استوديو علامة التبويب ، واختر دفتر الاستوديو الخاص بك.

- اختر الارتباط الموجود أسفل دور IAM.

- في نافذة IAM ، اختر أضف أذونات و إرفاق السياسات.
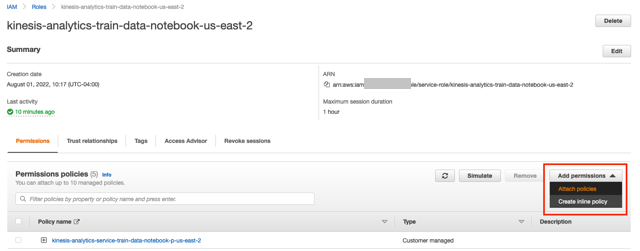
- ابحث عن AmazonKinesisFullAccess و CloudWatchFullAccess وحددهما ، ثم اختر إرفاق السياسة.
- يمكنك العودة إلى دفتر Zeppelin الخاص بك.
دفق البيانات إلى Kinesis Data Firehose
اعتبارًا من Apache Flink v1.15 ، يعمل إنشاء الموصل إلى تدفق توصيل Firehose بشكل مشابه لإنشاء موصل لأي تدفق بيانات Kinesis. لاحظ أن هناك اختلافين: الموصل هو firehose، وتصبح سمة الدفق delivery-stream.

بعد إنشاء الموصل ، يمكننا الكتابة إلى الموصل مثل أي جدول SQL.

للتحقق من أننا نحصل على البيانات من خلال تدفق التسليم ، افتح وحدة تحكم Amazon S3 وتأكد من أنك ترى الملفات قيد الإنشاء. افتح الملف لتفقد البيانات الجديدة.
في Kinesis Data Analytics لتطبيقات SQL ، كنا سننشئ وجهة جديدة في لوحة معلومات تطبيق SQL. لترحيل وجهة حالية ، يمكنك إضافة عبارة SQL إلى دفتر ملاحظاتك الذي يحدد الوجهة الجديدة مباشرةً في التعليمات البرمجية. يمكنك الاستمرار في الكتابة إلى الوجهة الجديدة كما تفعل مع INSERT أثناء الرجوع إلى اسم الجدول الجديد.
بيانات الوقت
هناك عملية شائعة أخرى يمكنك إجراؤها في دفاتر Kinesis Data Analytics Studio وهي التجميع عبر نافذة زمنية. يمكن استخدام هذا النوع من البيانات لإرسالها إلى تدفق بيانات Kinesis آخر لتحديد الحالات الشاذة أو إرسال التنبيهات أو تخزينها لمزيد من المعالجة. تحتوي الفقرة التالية على استعلام SQL يستخدم نافذة متقلبة ويجمع إجمالي الوقود المستهلك لأسطول السيارات لمدة 30 ثانية. مثل مثالنا الأخير ، يمكننا الاتصال بدفق بيانات آخر وإدخال هذه البيانات لمزيد من التحليل.

Scala و PyFlink
هناك أوقات تكون فيها الوظيفة التي تؤديها في دفق البيانات لديك مكتوبة بشكل أفضل بلغة برمجة بدلاً من لغة SQL ، من أجل البساطة والصيانة. تتضمن بعض الأمثلة العمليات الحسابية المعقدة التي لا تدعمها وظائف SQL محليًا ، ومعالجات معينة في السلاسل ، وتقسيم البيانات إلى تدفقات متعددة ، والتفاعل مع خدمات AWS الأخرى (مثل ترجمة النص أو تحليل المشاعر). تحليلات بيانات Kinesis لـ Apache Flink لديها القدرة على استخدام عدة ملفات مترجمين فلينك داخل دفتر Zeppelin ، وهو غير متوفر في تحليلات بيانات Kinesis لتطبيقات SQL.
إذا كنت تولي اهتمامًا وثيقًا لبياناتنا ، فسترى أن حقل الموقع عبارة عن سلسلة JSON. في Kinesis Data Analytics for SQL ، يمكننا استخدام وظائف السلسلة وتحديد ملف وظيفة SQL وكسر سلسلة JSON. هذا نهج هش يعتمد على استقرار بيانات الرسالة ، ولكن يمكن تحسين ذلك باستخدام العديد من وظائف SQL. يتبع بناء الجملة الخاص بإنشاء دالة في Kinesis Data Analytics for SQL هذا النمط:
CREATE FUNCTION ''<function_name>'' ( ''<parameter_list>'' ) RETURNS ''<data type>'' LANGUAGE SQL [ SPECIFIC ''<specific_function_name>'' | [NOT] DETERMINISTIC ] CONTAINS SQL [ READS SQL DATA ] [ MODIFIES SQL DATA ] [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ] RETURN ''<SQL-defined function body>''
في Kinesis Data Analytics for Apache Flink ، قامت AWS مؤخرًا بترقية بيئة Apache Flink إلى الإصدار 1.15 ، مما يوسع جدول SQL في Apache Flink SQL ليشمل إضافة وظائف JSON التي تشبه بنية مسار JSON. هذا يسمح لنا بالاستعلام عن سلسلة JSON مباشرة في SQL الخاصة بنا. انظر الكود التالي:
%flink.ssql(type=update)
SELECT JSON_STRING(location, ‘$.latitude) AS latitude,
JSON_STRING(location, ‘$.longitude) AS longitude
FROM my_tableبدلاً من ذلك ، ومطلوب قبل Apache Flink v1.15 ، يمكننا استخدام Scala أو PyFlink في دفتر ملاحظاتنا لتحويل الحقل وإعادة تدفق البيانات. توفر كلتا اللغتين معالجة قوية لسلسلة JSON.
يحدد كود PyFlink التالي اثنين وظائف محددة من قبل المستخدم، والتي تستخرج خطوط الطول والعرض من حقل موقع رسالتنا. يمكن بعد ذلك استدعاء هذه UDFs من استخدام Flink SQL. نشير إلى متغير البيئة st_env. ينشئ PyFlink ملفات ستة متغيرات لك في دفتر Zeppelin الخاص بك. يكشف زيبلين أيضًا عن أ سياق الكلام بالنسبة لك كمتغير z.


يمكن أن تحدث الأخطاء أيضًا عندما تحتوي الرسائل على بيانات غير متوقعة. توفر تحليلات بيانات Kinesis لتطبيقات SQL تدفق أخطاء في التطبيق. يمكن بعد ذلك معالجة هذه الأخطاء بشكل منفصل واستعادتها أو إسقاطها. باستخدام PyFlink في تطبيقات تدفق تحليلات البيانات الخاصة بـ Kinesis ، يمكنك كتابة استراتيجيات معقدة لمعالجة الأخطاء واستعادة البيانات على الفور ومتابعة معالجتها. عندما يتم تمرير سلسلة JSON إلى UDF ، فقد تكون مشوهة أو غير مكتملة أو فارغة. من خلال اكتشاف الخطأ في UDF ، ستعيد Python دائمًا قيمة حتى لو حدث خطأ.
يُظهر نموذج التعليمات البرمجية التالي مقتطف PyFlink آخر يقوم بعملية حسابية للقسمة على حقلين. في حالة مواجهة خطأ قسمة على صفر ، فإنه يوفر قيمة افتراضية حتى يتمكن التدفق من متابعة معالجة الرسالة.
%flink.pyflink
@udf(input_types=[DataTypes.BIGINT()], result_type=DataTypes.BIGINT())
def DivideByZero(price): try: price / 0 except: return -1
st_env.register_function("DivideByZero", DivideByZero)
الخطوات التالية
يمنحنا بناء خط أنابيب كما فعلنا في هذا المنشور الأساس لاختبار الخدمات الإضافية في AWS. أنا أشجعك على مواصلة تعلم تحليلات البث قبل هدم التدفقات التي أنشأتها. ضع في اعتبارك ما يلي:
تنظيف
لتنظيف الخدمات التي تم إنشاؤها في هذا التمرين ، أكمل الخطوات التالية:
- انتقل إلى CloudFormation Console واحذف مكدس IoT Device Simulator.
- في وحدة التحكم AWS IoT Core ، اختر توجيه الرسائل والقواعد ، واحذف القاعدة
automotive_route_kinesis. - احذف دفق بيانات Kinesis
automotive-dataفي وحدة تحكم Kinesis Data Stream. - قم بإزالة دور IAM
automotive-roleفي وحدة تحكم IAM. - في وحدة تحكم AWS Glue ، احذف ملف
automotive-notebook-glueقاعدة البيانات. - احذف دفتر ملاحظات Kinesis Data Analytics Studio
automotive-data-notebook. - حذف تدفق توصيل Firehose
automotive-firehose.
وفي الختام
نشكرك على متابعة هذا البرنامج التعليمي على Kinesis Data Analytics Studio. إذا كنت تستخدم حاليًا تطبيق Kinesis Data Analytics Studio SQL القديم ، فإنني أوصيك بالتواصل مع مدير الحساب الفني في AWS أو مهندس الحلول ومناقشة الانتقال إلى Kinesis Data Analytics Studio. يمكنك متابعة مسار التعلم الخاص بك في موقعنا دليل مطور تدفقات بيانات Amazon Kinesis، والوصول إلى عينات التعليمات البرمجية على جيثب.
عن المؤلف
 نيكولاس توني مهندس حلول شريك للقطاع العام العالمي في AWS. يعمل مع شركاء SI العالميين لتطوير بنى على AWS للعملاء في القطاعات الحكومية والرعاية الصحية غير الربحية والمرافق والتعليم.
نيكولاس توني مهندس حلول شريك للقطاع العام العالمي في AWS. يعمل مع شركاء SI العالميين لتطوير بنى على AWS للعملاء في القطاعات الحكومية والرعاية الصحية غير الربحية والمرافق والتعليم.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون السيارات / المركبات الكهربائية ، كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- BlockOffsets. تحديث ملكية الأوفست البيئية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/migrate-from-amazon-kinesis-data-analytics-for-sql-applications-to-amazon-kinesis-data-analytics-studio/

