المُقدّمة
تعتمد أنظمة الذكاء الاصطناعي في الوقت الفعلي بشكل كبير على الاستدلال السريع. تعمل واجهات برمجة التطبيقات الاستدلالية من رواد الصناعة مثل OpenAI وGoogle وAzure على تمكين اتخاذ القرار السريع. تعد تقنية وحدة معالجة اللغة (LPU) من Groq حلاً متميزًا يعزز كفاءة معالجة الذكاء الاصطناعي. تتعمق هذه المقالة في تقنية Groq المبتكرة، وتأثيرها على سرعات استدلال الذكاء الاصطناعي، وكيفية الاستفادة منها باستخدام Groq API.
أهداف التعلم
- فهم تقنية وحدة معالجة اللغة (LPU) الخاصة بشركة Groq وتأثيرها على سرعات استدلال الذكاء الاصطناعي
- تعرف على كيفية استخدام نقاط نهاية واجهة برمجة التطبيقات الخاصة بـ Groq لمهام معالجة الذكاء الاصطناعي في الوقت الفعلي وبزمن وصول منخفض
- استكشف إمكانيات نماذج Groq المدعومة، مثل Mixtral-8x7b-Instruct-v0.1 وLlama-70b، لفهم اللغة الطبيعية وإنشاءها
- مقارنة نظام LPU الخاص بـ Groq ومقارنته بواجهات برمجة التطبيقات الاستدلالية الأخرى، وفحص عوامل مثل السرعة والكفاءة وقابلية التوسع
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
ما هو جروك؟
تأسست في 2016، جروك هي شركة ناشئة متخصصة في حلول الذكاء الاصطناعي ومقرها كاليفورنيا ويقع مقرها الرئيسي في ماونتن فيو. قامت شركة Groq، المتخصصة في استدلال الذكاء الاصطناعي بزمن وصول منخفض للغاية، بتطوير أداء حوسبة الذكاء الاصطناعي بشكل ملحوظ. تعد Groq أحد المشاركين البارزين في مجال تكنولوجيا الذكاء الاصطناعي، حيث سجلت اسمها كعلامة تجارية وجمعت فريقًا عالميًا ملتزمًا بإضفاء الطابع الديمقراطي على الوصول إلى الذكاء الاصطناعي.
وحدات معالجة اللغة
تهدف وحدة معالجة اللغة (LPU) في Groq، وهي تقنية مبتكرة، إلى تحسين أداء حوسبة الذكاء الاصطناعي، خاصة بالنسبة لنماذج اللغات الكبيرة (LLMs). يسعى نظام Groq LPU إلى تقديم تجارب في الوقت الفعلي وبكمون منخفض مع أداء استدلالي استثنائي. حققت Groq أكثر من 300 رمزًا مميزًا في الثانية لكل مستخدم على نموذج Llama-2 70B الخاص بشركة Meta AI، مما يضع معيارًا صناعيًا جديدًا.
يتميز نظام Groq LPU بقدرات زمن الوصول المنخفضة للغاية والتي تعد ضرورية لتقنيات دعم الذكاء الاصطناعي. تم تصميمه خصيصًا لمعالجة لغة GenAI المتسلسلة والمكثفة للحوسبة، وهو يتفوق في الأداء على حلول وحدة معالجة الرسومات التقليدية، مما يضمن معالجة فعالة لمهام مثل إنشاء اللغة الطبيعية وفهمها.
يتميز الجيل الأول من GroqChip من Groq، وهو جزء من نظام LPU، ببنية تدفق موتر محسنة للسرعة والكفاءة والدقة والفعالية من حيث التكلفة. تتفوق هذه الشريحة على الحلول الحالية، حيث تسجل أرقامًا قياسية جديدة في سرعة LLM الأساسية التي يتم قياسها بالرموز المميزة في الثانية لكل مستخدم. ومن خلال خططها لنشر مليون شريحة استدلال للذكاء الاصطناعي في غضون عامين، تُظهر Groq التزامها بتطوير تقنيات تسريع الذكاء الاصطناعي.
باختصار، يمثل نظام وحدة معالجة اللغة من Groq تقدمًا كبيرًا في تكنولوجيا حوسبة الذكاء الاصطناعي، حيث يقدم أداءً وكفاءة متميزين لنماذج اللغات الكبيرة مع دفع الابتكار في الذكاء الاصطناعي.
اقرأ أيضا: بناء نموذج ML في AWS SageMaker
الشروع في العمل مع جروك
في الوقت الحالي، توفر Groq نقاط نهاية API مجانية الاستخدام لنماذج اللغات الكبيرة التي تعمل على Groq LPU – وحدة معالجة اللغة. للبدء، قم بزيارة هذا صفحة وانقر على تسجيل الدخول. تبدو الصفحة مثل الصفحة أدناه:
انقر فوق تسجيل الدخول واختر إحدى الطرق المناسبة لتسجيل الدخول إلى Groq. ثم يمكننا إنشاء واجهة برمجة تطبيقات جديدة مثل تلك الموجودة أدناه من خلال النقر على زر إنشاء مفتاح واجهة برمجة التطبيقات
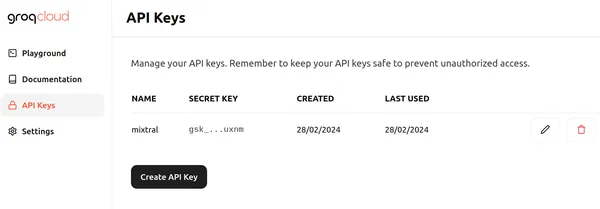
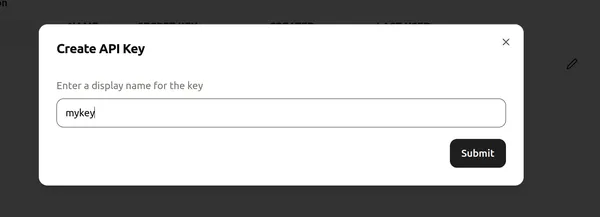
بعد ذلك، قم بتعيين اسم لمفتاح API وانقر فوق "إرسال" لإنشاء مفتاح API جديد. انتقل الآن إلى أي محرر أكواد/Colab وقم بتثبيت المكتبات المطلوبة لبدء استخدام Groq.
!pip install groqيقوم هذا الأمر بتثبيت مكتبة Groq، مما يسمح لنا باستنتاج نماذج اللغات الكبيرة التي تعمل على وحدات Groq LPUs.
الآن، دعونا نتابع التعليمات البرمجية.
تنفيذ التعليمات البرمجية
# Importing Necessary Libraries
import os
from groq import Groq
# Instantiation of Groq Client
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)يقوم مقتطف التعليمات البرمجية هذا بإنشاء كائن عميل Groq للتفاعل مع واجهة برمجة تطبيقات Groq. يبدأ باسترداد مفتاح API من متغير بيئة يسمى GROQ_API_KEY ويمرره إلى الوسيطة api_key. بعد ذلك، يقوم مفتاح API بتهيئة كائن عميل Groq، مما يتيح استدعاءات API لنماذج اللغات الكبيرة داخل خوادم Groq.
تحديد LLM لدينا
llm = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful AI Assistant. You explain ever
topic the user asks as if you are explaining it to a 5 year old"
},
{
"role": "user",
"content": "What are Black Holes?",
}
],
model="mixtral-8x7b-32768",
)
print(llm.choices[0].message.content)- يقوم السطر الأول بتهيئة كائن llm، مما يتيح التفاعل مع نموذج اللغة الكبير، المشابه لـ OpenAI Chat Completion API.
- يقوم الكود التالي بإنشاء قائمة بالرسائل التي سيتم إرسالها إلى LLM، المخزنة في متغير الرسائل.
- تقوم الرسالة الأولى بتعيين الدور كـ "نظام" وتحدد السلوك المطلوب لـ LLM لشرح الموضوعات كما هو الحال لطفل يبلغ من العمر 5 سنوات.
- الرسالة الثانية تحدد دور "المستخدم" وتتضمن سؤالاً حول الثقوب السوداء.
- يحدد السطر التالي LLM الذي سيتم استخدامه لإنشاء الاستجابة، وتم ضبطه على "mixtral-8x7b-32768"، وهو سياق 32 كيلو بايت Mixtral-8x7b-Instruct-v0.1 نموذج لغة كبير يمكن الوصول إليه عبر Groq API.
- سيكون ناتج هذا الكود عبارة عن رد من LLM يشرح الثقوب السوداء بطريقة مناسبة لفهم طفل يبلغ من العمر 5 سنوات.
- يتبع الوصول إلى المخرجات أسلوبًا مشابهًا للعمل مع نقطة نهاية OpenAI.
الناتج
يظهر أدناه الإخراج الناتج عن نموذج اللغة الكبير Mixtral-8x7b-Instruct-v0.1:

• الإكمال.إنشاء () يمكن للكائن أن يأخذ معلمات إضافية مثل درجة الحرارة, top_pو max_tokens.
توليد الاستجابة
دعنا نحاول إنشاء استجابة باستخدام هذه المعلمات:
llm = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful AI Assistant. You explain ever
topic the user asks as if you are explaining it to a 5 year old"
},
{
"role": "user",
"content": "What is Global Warming?",
}
],
model="mixtral-8x7b-32768",
temperature = 1,
top_p = 1,
max_tokens = 256,
)- درجة الحرارة: التحكم في عشوائية الاستجابات. تؤدي درجة الحرارة المنخفضة إلى مخرجات أكثر قابلية للتنبؤ بها، بينما تؤدي درجة الحرارة المرتفعة إلى مخرجات أكثر تنوعًا وأحيانًا أكثر إبداعًا
- max_tokens: الحد الأقصى لعدد الرموز المميزة التي يمكن للنموذج معالجتها في استجابة واحدة. يضمن هذا الحد الكفاءة الحسابية وإدارة الموارد
- top_p: طريقة لإنشاء النص تحدد الرمز المميز التالي من التوزيع الاحتمالي للرموز المميزة الأكثر احتمالية. وهذا يوازن بين الاستكشاف والاستغلال أثناء التوليد
الناتج

يوجد أيضًا خيار لبث الاستجابات الناتجة من Groq Endpoint. نحتاج فقط إلى تحديد تيار = صحيح الخيار في الإكمال.إنشاء () كائن للنموذج لبدء دفق الاستجابات.
جروك في لانجشين
Groq متوافق أيضًا مع LangChain. لبدء استخدام Groq في LangChain، قم بتنزيل المكتبة:
!pip install langchain-groqسيؤدي ما ورد أعلاه إلى تثبيت مكتبة Groq للتوافق مع LangChain. الآن دعونا نجرب ذلك بالكود:
# Import the necessary libraries.
from langchain_core.prompts import ChatPromptTemplate
from langchain_groq import ChatGroq
# Initialize a ChatGroq object with a temperature of 0 and the "mixtral-8x7b-32768" model.
llm = ChatGroq(temperature=0, model_name="mixtral-8x7b-32768")الكود أعلاه يقوم بما يلي:
- يقوم بإنشاء كائن ChatGroq جديد باسم llm
- يضبط درجة الحرارة المعلمة إلى 0، مما يشير إلى أن الاستجابات يجب أن تكون أكثر قابلية للتنبؤ بها
- يضبط اسم النموذج المعلمة "ميكسترال-8x7b-32768"، مع تحديد نموذج اللغة المراد استخدامه
# تحديد رسالة النظام للتعريف بقدرات مساعد الذكاء الاصطناعي.
# Define the system message introducing the AI assistant's capabilities.
system = "You are an expert Coding Assistant."
# Define a placeholder for the user's input.
human = "{text}"
# Create a chat prompt consisting of the system and human messages.
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", human)])
# Invoke the chat chain with the user's input.
chain = prompt | llm
response = chain.invoke({"text": "Write a simple code to generate Fibonacci numbers in Rust?"})
# Print the Response.
print(response.content)- يقوم الكود بإنشاء موجه الدردشة باستخدام فئة ChatPromptTemplate.
- تتكون المطالبة من رسالتين: واحدة من "النظام" (مساعد الذكاء الاصطناعي) وواحدة من "الإنسان" (المستخدم).
- تعرض رسالة النظام مساعد الذكاء الاصطناعي باعتباره مساعد ترميز خبيرًا.
- تعمل الرسالة البشرية كعنصر نائب لإدخال المستخدم.
- تستدعي طريقة llm سلسلة llm لإنتاج استجابة بناءً على الموجه المقدم ومدخلات المستخدم.
الناتج
فيما يلي المخرجات التي تم إنشاؤها بواسطة نموذج اللغة الكبير Mixtral:

يقوم برنامج Mixtral LLM باستمرار بإنشاء الاستجابات ذات الصلة. يؤكد اختبار الكود في Rust Playground على وظائفه. تُعزى الاستجابة السريعة إلى وحدة معالجة اللغة الأساسية (LPU).
Groq مقابل واجهات برمجة تطبيقات الاستدلال الأخرى
يهدف نظام وحدة معالجة اللغة (LPU) الخاص بـ Groq إلى توفير سرعات استدلال فائقة السرعة لنماذج اللغات الكبيرة (LLMs)، متجاوزًا واجهات برمجة التطبيقات الاستدلالية الأخرى مثل تلك التي توفرها OpenAI وAzure. يوفر نظام LPU الخاص بـ Groq، المُحسّن خصيصًا لـ LLMs، إمكانات زمن وصول منخفضة للغاية ضرورية لتقنيات مساعدة الذكاء الاصطناعي. فهو يعالج الاختناقات الأساسية في LLMs، بما في ذلك كثافة الحساب وعرض النطاق الترددي للذاكرة، مما يتيح إنشاء تسلسلات نصية بشكل أسرع.
بالمقارنة مع واجهات برمجة التطبيقات الاستدلالية الأخرى، يعد نظام LPU الخاص بـ Groq أسرع، مع القدرة على إنشاء أداء استدلالي أسرع بما يصل إلى 18 مرة على لوحة LLMPerf Leaderboard الخاصة بـ Anyscale مقارنة بكبار موفري الخدمات السحابية الآخرين. يعد نظام LPU الخاص بـ Groq أكثر كفاءة أيضًا، مع بنية أساسية واحدة وشبكات متزامنة يتم الحفاظ عليها في عمليات النشر واسعة النطاق، مما يتيح التجميع التلقائي لـ LLMs والوصول الفوري إلى الذاكرة.

تعرض الصورة أعلاه معايير لنماذج 70B. يتضمن حساب إنتاجية الرموز المميزة للإخراج حساب متوسط عدد الرموز المميزة للإخراج التي يتم إرجاعها في الثانية. يقوم كل مزود استدلال LLM بمعالجة 150 طلبًا لجمع النتائج، ويتم حساب متوسط إنتاجية الرموز المميزة للمخرجات باستخدام هذه الطلبات. تتم الإشارة إلى الأداء المحسن لموفر استدلال LLM من خلال إنتاجية أعلى لرموز الإخراج. من الواضح أن رموز الإخراج الخاصة بـ Groq في الثانية تتفوق على العديد من موفري الخدمات السحابية المعروضين.
وفي الختام
في الختام، يبرز نظام وحدة معالجة اللغة (LPU) الخاص بشركة Groq كتقنية ثورية في عالم حوسبة الذكاء الاصطناعي، حيث يوفر سرعة وكفاءة غير مسبوقتين للتعامل مع نماذج اللغات الكبيرة (LLMs) ويقود الابتكار في مجال الذكاء الاصطناعي. من خلال الاستفادة من إمكانات زمن الوصول المنخفض للغاية والهندسة المعمارية المحسنة، تضع Groq معايير جديدة لسرعات الاستدلال، وتتفوق على حلول GPU التقليدية وواجهات برمجة التطبيقات الاستدلالية الرائدة الأخرى في الصناعة. بفضل التزامها بإضفاء الطابع الديمقراطي على الوصول إلى الذكاء الاصطناعي وتركيزها على التجارب في الوقت الفعلي ذات الكمون المنخفض، تستعد Groq لإعادة تشكيل مشهد تقنيات تسريع الذكاء الاصطناعي.
الوجبات السريعة الرئيسية
- يوفر نظام وحدة معالجة اللغة (LPU) من Groq سرعة وكفاءة لا مثيل لهما لاستدلال الذكاء الاصطناعي، خاصة بالنسبة لنماذج اللغات الكبيرة (LLMs)، مما يتيح تجارب في الوقت الفعلي وبزمن وصول منخفض
- يتميز نظام Groq's LPU، الذي يتميز بـ GroqChip، بقدرات زمن الوصول المنخفضة للغاية الضرورية لتقنيات دعم الذكاء الاصطناعي، متفوقًا على حلول GPU التقليدية
- من خلال خطط لنشر مليون شريحة استدلال للذكاء الاصطناعي في غضون عامين، تُظهر Groq تفانيها في تطوير تقنيات تسريع الذكاء الاصطناعي وإضفاء الطابع الديمقراطي على الوصول إلى الذكاء الاصطناعي.
- توفر Groq نقاط نهاية API مجانية الاستخدام لنماذج اللغات الكبيرة التي تعمل على Groq LPU، مما يجعلها في متناول المطورين لدمجها في مشاريعهم
- يعمل توافق Groq مع LangChain وLlamaIndex على توسيع قابليته للاستخدام، مما يوفر تكاملًا سلسًا للمطورين الذين يسعون إلى الاستفادة من تقنية Groq في مهام معالجة اللغة الخاصة بهم
الأسئلة المتكررة
تتخصص شركة A. Groq في استدلال الذكاء الاصطناعي بزمن وصول منخفض للغاية، خاصة بالنسبة لنماذج اللغات الكبيرة (LLMs)، بهدف إحداث ثورة في أداء حوسبة الذكاء الاصطناعي.
A. تم تصميم نظام LPU الخاص بـ Groq، والذي يتميز بـ GroqChip، خصيصًا للطبيعة الحسابية المكثفة لمعالجة لغة GenAI، مما يوفر سرعة وكفاءة ودقة فائقة مقارنة بحلول GPU التقليدية.
A. يدعم Groq مجموعة من النماذج لاستدلال الذكاء الاصطناعي، بما في ذلك Mixtral-8x7b-Instruct-v0.1 وLlama-70b.
ج: نعم، Groq متوافق مع LangChain وLlamaIndex، مما يوسع قابليته للاستخدام ويقدم تكاملًا سلسًا للمطورين الذين يسعون إلى الاستفادة من تقنية Groq في مهام معالجة اللغة الخاصة بهم.
A. يتفوق نظام LPU الخاص بـ Groq على واجهات برمجة التطبيقات الاستدلالية الأخرى من حيث السرعة والكفاءة، مما يوفر سرعات استدلال أسرع بما يصل إلى 18 مرة وأداء فائق، كما يتضح من المعايير الموجودة على لوحة LLMPerf Leaderboard من Anyscale.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/03/getting-started-with-groq-api/

