نحن نعيش في عصر البيانات والرؤى في الوقت الفعلي، مدفوعة بتطبيقات تدفق البيانات ذات زمن الوصول المنخفض. اليوم، يتوقع الجميع تجربة شخصية في أي تطبيق، وتقوم المؤسسات باستمرار بالابتكار لزيادة سرعة العمليات التجارية واتخاذ القرارات. يتزايد حجم البيانات الحساسة للوقت التي يتم إنتاجها بسرعة، مع تقديم تنسيقات مختلفة من البيانات عبر الشركات الجديدة وحالات استخدام العملاء. ولذلك، فمن الأهمية بمكان أن تتبنى المؤسسات بنية أساسية لتدفق البيانات ذات زمن وصول منخفض وقابلة للتطوير وموثوقة لتقديم تطبيقات الأعمال في الوقت الفعلي وتجارب أفضل للعملاء.
هذا هو المنشور الأول في سلسلة مدونات تقدم أنماطًا معمارية شائعة في إنشاء البنى التحتية لتدفق البيانات في الوقت الفعلي باستخدام Kinesis Data Streams لمجموعة واسعة من حالات الاستخدام. ويهدف إلى توفير إطار عمل لإنشاء تطبيقات تدفق منخفضة الكمون على سحابة AWS باستخدام الأمازون كينسيس دفق البيانات و خدمات تحليلات البيانات المصممة لهذا الغرض من AWS.
في هذا المنشور، سنراجع الأنماط المعمارية الشائعة لحالتي استخدام: تحليل بيانات السلاسل الزمنية والخدمات الصغيرة المستندة إلى الأحداث. في المنشور التالي في سلسلتنا، سنستكشف الأنماط المعمارية في بناء خطوط التدفق للوحات معلومات ذكاء الأعمال في الوقت الفعلي، ووكيل مركز الاتصال، وبيانات دفتر الأستاذ، والتوصية الشخصية في الوقت الفعلي، وتحليلات السجل، وبيانات إنترنت الأشياء، والتقاط بيانات التغيير، والبيانات الحقيقية -بيانات التسويق الوقت. تم دمج جميع أنماط البنية هذه مع تدفقات بيانات Amazon Kinesis.
البث في الوقت الفعلي باستخدام Kinesis Data Streams
Amazon Kinesis Data Streams هي خدمة تدفق بيانات سحابية أصلية بدون خادم، مما يجعل من السهل التقاط البيانات في الوقت الفعلي ومعالجتها وتخزينها على أي نطاق. باستخدام Kinesis Data Streams، يمكنك جمع ومعالجة مئات الجيجابايت من البيانات في الثانية من مئات الآلاف من المصادر، مما يسمح لك بسهولة كتابة التطبيقات التي تعالج المعلومات في الوقت الفعلي. تتوفر البيانات المجمعة بالمللي ثانية للسماح بحالات استخدام التحليلات في الوقت الفعلي، مثل لوحات المعلومات في الوقت الفعلي، والكشف عن الحالات الشاذة في الوقت الفعلي، والتسعير الديناميكي. افتراضيًا، يتم تخزين البيانات الموجودة في Kinesis Data Stream لمدة 24 ساعة مع خيار زيادة الاحتفاظ بالبيانات إلى 365 يومًا. إذا أراد العملاء معالجة نفس البيانات في الوقت الفعلي باستخدام تطبيقات متعددة، فيمكنهم استخدام ميزة Fan-Out المحسنة (EFO). قبل هذه الميزة، كان كل تطبيق يستهلك البيانات من الدفق يشارك في إخراج 2 ميجابايت/الثانية/الجزء. من خلال تكوين مستهلكي التدفق لاستخدام التوزيع الموسع المحسّن، يتلقى كل مستهلك بيانات أنبوبًا مخصصًا يبلغ 2 ميجابايت/ثانية من إنتاجية القراءة لكل جزء لتقليل زمن الوصول في استرداد البيانات بشكل أكبر.
للحصول على مستوى عالٍ من التوفر والمتانة، تحقق Kinesis Data Streams متانة عالية من خلال النسخ المتزامن للبيانات المتدفقة عبر ثلاث مناطق توافر خدمات في منطقة AWS وتمنحك خيار الاحتفاظ بالبيانات لمدة تصل إلى 365 يومًا. من أجل الأمان، توفر Kinesis Data Streams تشفيرًا من جانب الخادم حتى تتمكن من تلبية متطلبات إدارة البيانات الصارمة عن طريق تشفير بياناتك أثناء الراحة ونقاط نهاية واجهة Amazon Virtual Private Cloud (VPC) للحفاظ على خصوصية حركة المرور بين Amazon VPC وKinesis Data Streams.
يحتوي Kinesis Data Streams على عمليات تكامل أصلية مع خدمات AWS الأخرى مثل غراء AWS و أمازون إيفينت بريدج لبناء تطبيقات البث في الوقت الحقيقي على AWS. راجع عمليات تكامل Amazon Kinesis Data Streams للحصول على تفاصيل إضافية.
بنية حديثة لتدفق البيانات مع تدفقات بيانات Kinesis
يمكن تصميم بنية بيانات متدفقة حديثة مع Kinesis Data Streams كمجموعة من خمس طبقات منطقية؛ تتكون كل طبقة من مكونات متعددة مصممة خصيصًا لتلبية متطلبات محددة، كما هو موضح في الرسم البياني التالي:

تتكون البنية من المكونات الرئيسية التالية:
- مصادر التدفق – يتضمن مصدر تدفق البيانات مصادر البيانات مثل بيانات النقر، وأجهزة الاستشعار، ووسائل التواصل الاجتماعي، وأجهزة إنترنت الأشياء (IoT)، وملفات السجل التي تم إنشاؤها باستخدام تطبيقات الويب والهاتف المحمول، وأجهزة الهاتف المحمول التي تولد بيانات شبه منظمة وغير منظمة كتدفقات مستمرة بسرعة عالية.
- استيعاب الدفق – طبقة استيعاب الدفق مسؤولة عن إدخال البيانات في طبقة تخزين الدفق. فهو يوفر القدرة على جمع البيانات من عشرات الآلاف من مصادر البيانات واستيعابها في الوقت الفعلي. يمكنك استخدام ال كينيسيس SDK لاستيعاب البيانات المتدفقة من خلال واجهات برمجة التطبيقات، فإن مكتبة منتج الحركية لبناء منتجي بث مباشر عالي الأداء وطويل الأمد، أو أ وكيل الحركية لجمع مجموعة من الملفات واستيعابها في Kinesis Data Streams. بالإضافة إلى ذلك، يمكنك استخدام العديد من عمليات التكامل السابقة للإنشاء مثل خدمة ترحيل قاعدة بيانات AWS (AWS DMS), الأمازون DynamoDBو AWS إنترنت الأشياء الأساسية لاستيعاب البيانات بطريقة بدون كود. يمكنك أيضًا استيعاب البيانات من منصات خارجية مثل Apache Spark وApache Kafka Connect
- تخزين الدفق – توفر تدفقات بيانات Kinesis وضعين لدعم إنتاجية البيانات: عند الطلب والمقدمة. يمكن للوضع عند الطلب، وهو الخيار الافتراضي الآن، أن يتوسع بشكل مرن لاستيعاب معدلات الإنتاجية المتغيرة، بحيث لا يحتاج العملاء إلى القلق بشأن إدارة السعة والدفع من خلال إنتاجية البيانات. يعمل الوضع عند الطلب تلقائيًا على زيادة سعة الدفق إلى ضعفين مقارنة بأقصى استيعاب تاريخي للبيانات لتوفير سعة كافية للارتفاعات غير المتوقعة في استيعاب البيانات. وبدلاً من ذلك، يمكن للعملاء الذين يريدون التحكم الدقيق في موارد التدفق استخدام الوضع المقدم وتوسيع نطاق عدد الأجزاء بشكل استباقي لأعلى ولأسفل لتلبية متطلبات الإنتاجية الخاصة بهم. بالإضافة إلى ذلك، يمكن لـ Kinesis Data Streams تخزين بيانات التدفق لمدة تصل إلى 2 ساعة بشكل افتراضي، ولكن يمكن أن تمتد إلى 24 أيام أو 7 يومًا حسب حالات الاستخدام. يمكن لتطبيقات متعددة أن تستهلك نفس الدفق.
- معالجة الدفق – تعد طبقة معالجة التدفق مسؤولة عن تحويل البيانات إلى حالة قابلة للاستهلاك من خلال التحقق من صحة البيانات وتنظيفها وتطبيعها وتحويلها وإثرائها. تتم قراءة سجلات البث بالترتيب الذي تم إنتاجها به، مما يسمح بإجراء تحليلات في الوقت الفعلي، أو إنشاء تطبيقات تعتمد على الأحداث أو تدفق ETL (الاستخراج والتحويل والتحميل). يمكنك استخدام خدمة أمازون المُدارة لـ Apache Flink لمعالجة بيانات التدفق المعقدة، AWS لامدا لمعالجة بيانات الدفق عديمة الحالة، و غراء AWS & أمازون EMR للحسابات في الوقت الفعلي تقريبًا. يمكنك أيضًا إنشاء تطبيقات مخصصة للمستهلك باستخدام مكتبة المستهلك كينيسيس, والتي ستتولى العديد من المهام المعقدة المرتبطة بالحوسبة الموزعة.
- المكان المقصود - تشبه طبقة الوجهة الوجهة المصممة لهذا الغرض اعتمادًا على حالة الاستخدام الخاصة بك. يمكنك دفق البيانات مباشرة إلى الأمازون الأحمر لتخزين البيانات وAmazon EventBridge لإنشاء تطبيقات تعتمد على الأحداث. تستطيع ايضا استخذام أمازون كينسيس داتا فايرهاوس لتكامل الدفق حيث يمكنك معالجة الدفق الخفيف باستخدام AWS Lambda، ثم تقديم الدفق المعالج إلى وجهات مثل الأمازون S3 بحيرة البيانات، وخدمة OpenSearch للتحليلات التشغيلية، ومستودع بيانات Redshift، وقواعد بيانات No-SQL مثل Amazon DynamoDB، وقواعد البيانات العلائقية مثل أمازون RDS لاستهلاك التدفقات في الوقت الفعلي في تطبيقات الأعمال. يمكن أن تكون الوجهة عبارة عن تطبيق قائم على الأحداث للوحات المعلومات في الوقت الفعلي، والقرارات التلقائية المستندة إلى بيانات التدفق المعالجة، والتغيير في الوقت الفعلي، والمزيد.
بنية التحليلات في الوقت الحقيقي للسلاسل الزمنية
بيانات السلاسل الزمنية هي سلسلة من نقاط البيانات المسجلة خلال فترة زمنية لقياس الأحداث التي تتغير بمرور الوقت. ومن الأمثلة على ذلك أسعار الأسهم بمرور الوقت، وتدفقات النقر على صفحة الويب، وسجلات الجهاز بمرور الوقت. يمكن للعملاء استخدام بيانات السلاسل الزمنية لمراقبة التغييرات بمرور الوقت، حتى يتمكنوا من اكتشاف الحالات الشاذة وتحديد الأنماط وتحليل كيفية تأثير متغيرات معينة بمرور الوقت. عادةً ما يتم إنشاء بيانات السلاسل الزمنية من مصادر متعددة بكميات كبيرة، ويجب جمعها بطريقة فعالة من حيث التكلفة في الوقت الفعلي تقريبًا.
عادة، هناك ثلاثة أهداف أساسية يرغب العملاء في تحقيقها في معالجة بيانات السلاسل الزمنية:
- احصل على رؤى في الوقت الفعلي حول أداء النظام واكتشف الحالات الشاذة
- فهم سلوك المستخدم النهائي لتتبع الاتجاهات والاستعلام/إنشاء تصورات من هذه الأفكار
- احصل على حل تخزين متين لاستيعاب وتخزين كل من البيانات الأرشيفية والبيانات التي يتم الوصول إليها بشكل متكرر.
باستخدام Kinesis Data Streams، يمكن للعملاء التقاط تيرابايت من بيانات السلاسل الزمنية بشكل مستمر من آلاف المصادر للتنظيف والإثراء والتخزين والتحليل والتصور.
يوضح نمط البنية التالي كيف يمكن تحقيق التحليلات في الوقت الفعلي لبيانات السلاسل الزمنية باستخدام تدفقات بيانات Kinesis:
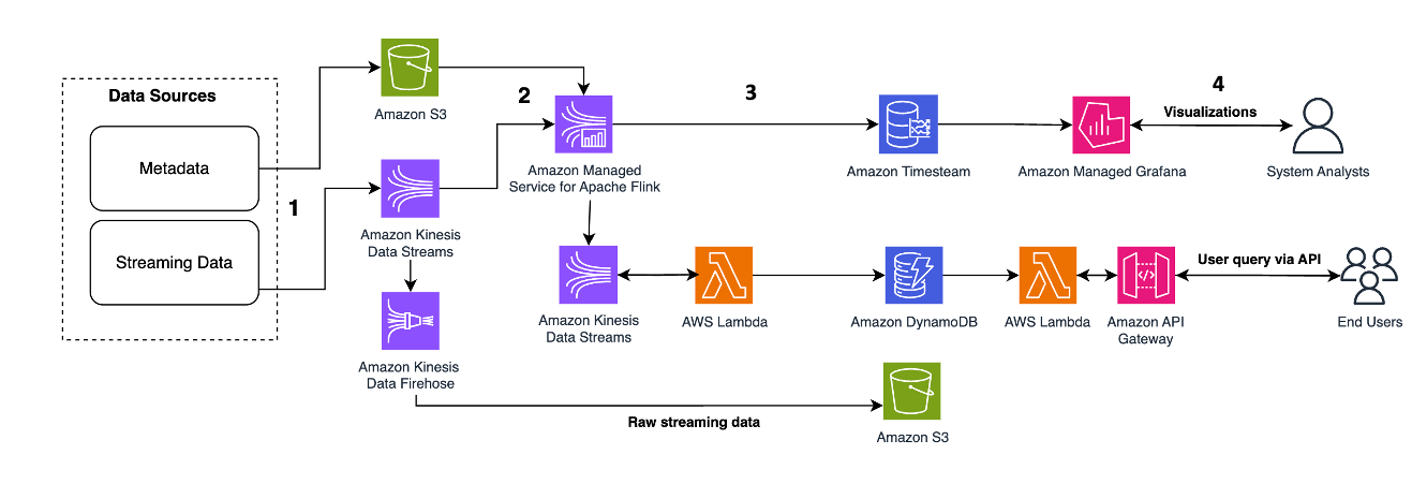
خطوات سير العمل كالتالي:
- استيعاب البيانات وتخزينها – يمكن لـ Kinesis Data Streams التقاط وتخزين تيرابايت من البيانات بشكل مستمر من آلاف المصادر.
- معالجة الدفق – تطبيق تم إنشاؤه باستخدام خدمة أمازون المُدارة لـ Apache Flink يمكنه قراءة السجلات من تدفق البيانات لاكتشاف أي أخطاء في بيانات السلاسل الزمنية وتنظيفها وإثراء البيانات ببيانات وصفية محددة لتحسين التحليلات التشغيلية. يوفر استخدام دفق البيانات في المنتصف ميزة استخدام بيانات السلاسل الزمنية في عمليات وحلول أخرى في نفس الوقت. يتم بعد ذلك استدعاء دالة Lambda مع هذه الأحداث، ويمكنها إجراء حسابات السلاسل الزمنية في الذاكرة.
- وجهات – بعد التنظيف والإثراء، يمكن دفق بيانات السلاسل الزمنية المعالجة إلى توقيت أمازون قاعدة بيانات للوحة المعلومات والتحليل في الوقت الفعلي، أو مخزنة في قواعد بيانات مثل DynamoDB لاستعلام المستخدم النهائي. يمكن دفق البيانات الأولية إلى Amazon S3 للأرشفة.
- التصور واكتساب الأفكار – يمكن للعملاء الاستعلام عن التنبيهات وتصورها وإنشاءها باستخدام خدمة أمازون المُدارة لـ Grafana. يدعم Grafana مصادر البيانات التي تمثل واجهات تخزين خلفية لبيانات السلاسل الزمنية. للوصول إلى بياناتك من Timestream، تحتاج إلى تثبيت البرنامج الإضافي Timestream لـ Grafana. يمكن للمستخدمين النهائيين الاستعلام عن البيانات من جدول DynamoDB باستخدام بوابة أمازون API بمثابة وكيل.
الرجوع إلى معالجة قريبة من الوقت الفعلي باستخدام Amazon Kinesis وAmazon Timestream وGrafana عرض خط أنابيب دفق بدون خادم لمعالجة وتخزين بيانات IoT للقياس عن بعد للجهاز في مخزن بيانات مُحسّن لسلسلة زمنية مثل Amazon Timestream.
إثراء البيانات وإعادة تشغيلها في الوقت الفعلي للخدمات الصغيرة الخاصة بمصادر الأحداث
الخدمات المصغرة هي منهج معماري وتنظيمي لتطوير البرمجيات حيث يتكون البرنامج من خدمات مستقلة صغيرة تتواصل عبر واجهات برمجة التطبيقات المحددة جيدًا. عند إنشاء خدمات صغيرة تعتمد على الأحداث، يرغب العملاء في تحقيق 1. قابلية عالية للتوسع للتعامل مع حجم الأحداث الواردة و2. موثوقية معالجة الأحداث والحفاظ على وظائف النظام في مواجهة حالات الفشل.
يستخدم العملاء أنماط بنية الخدمات الصغيرة لتسريع الابتكار ووقت التسويق للميزات الجديدة، لأنها تجعل التطبيقات أسهل في التوسع وأسرع في التطوير. ومع ذلك، من الصعب إثراء البيانات وإعادة تشغيلها في مكالمة شبكة إلى خدمة صغيرة أخرى لأنها يمكن أن تؤثر على موثوقية التطبيق وتجعل من الصعب تصحيح الأخطاء وتتبعها. لحل هذه المشكلة، يُعد تحديد مصادر الأحداث نمطًا تصميميًا فعالاً يقوم بتجميع السجلات التاريخية لجميع تغييرات الحالة من أجل الإثراء وإعادة التشغيل، ويفصل القراءة عن أعباء عمل الكتابة. يمكن للعملاء استخدام Kinesis Data Streams كمخزن أحداث مركزي للخدمات الصغيرة الخاصة بمصادر الأحداث، لأن KDS يمكنه 1/ التعامل مع غيغابايت من إنتاجية البيانات في الثانية لكل تدفق ودفق البيانات بالمللي ثانية، لتلبية متطلبات قابلية التوسع العالية وفي الوقت الفعلي تقريبًا زمن الوصول، 2/ التكامل مع Flink وS3 لإثراء البيانات وتحقيقها مع فصلها تمامًا عن الخدمات الصغيرة، و3/ السماح بإعادة المحاولة والقراءة غير المتزامنة في وقت لاحق، لأن KDS يحتفظ بسجل البيانات لمدة افتراضية تبلغ 24 ساعة، واختياريًا ما يصل إلى 365 يوما.
يعد النمط المعماري التالي توضيحًا عامًا لكيفية استخدام تدفقات بيانات Kinesis للخدمات الصغيرة الخاصة بمصادر الأحداث:
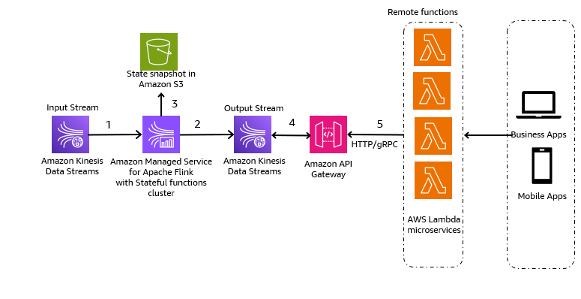
الخطوات في سير العمل هي كما يلي:
- استيعاب البيانات وتخزينها - يمكنك تجميع المدخلات من الخدمات الصغيرة الخاصة بك إلى تدفقات بيانات Kinesis للتخزين.
- معالجة التدفق - وظائف أباتشي فلينك ذات الحالة يبسط بناء التطبيقات الموزعة المستندة إلى الأحداث. يمكنه تلقي الأحداث من دفق بيانات Kinesis المدخلات وتوجيه الدفق الناتج إلى دفق بيانات الإخراج. يمكنك إنشاء مجموعة وظائف ذات حالة باستخدام Apache Flink استنادًا إلى منطق أعمال التطبيق الخاص بك.
- لقطة الحالة في Amazon S3 – يمكنك تخزين لقطة الحالة في Amazon S3 للتتبع.
- تيارات الإخراج - يمكن استهلاك تدفقات الإخراج من خلال وظائف Lambda البعيدة من خلال بروتوكول HTTP/gRPC من خلال بوابة API.
- وظائف لامدا عن بعد - يمكن أن تعمل وظائف Lambda كخدمات صغيرة لمختلف التطبيقات ومنطق الأعمال لخدمة تطبيقات الأعمال وتطبيقات الهاتف المحمول.
للتعرف على كيفية قيام العملاء الآخرين ببناء خدماتهم الصغيرة المستندة إلى الأحداث باستخدام Kinesis Data Streams، راجع ما يلي:
الاعتبارات الرئيسية وأفضل الممارسات
فيما يلي الاعتبارات وأفضل الممارسات التي يجب وضعها في الاعتبار:
- يجب أن يكون اكتشاف البيانات هو خطوتك الأولى في بناء تطبيقات تدفق البيانات الحديثة. يجب عليك تحديد قيمة الأعمال ثم تحديد مصادر بيانات البث وشخصيات المستخدم لتحقيق نتائج الأعمال المطلوبة.
- اختر أداة استيعاب البيانات المتدفقة الخاصة بك استنادًا إلى مصدر البيانات المتدفق لديك. على سبيل المثال، يمكنك استخدام كينيسيس SDK لاستيعاب البيانات المتدفقة من خلال واجهات برمجة التطبيقات، فإن مكتبة منتج الحركية لبناء منتجي بث مباشر عالي الأداء وطويل الأمد، أ وكيل الحركية لتجميع مجموعة من الملفات واستيعابها في Kinesis Data Streams، أوس دي إم إس لحالات استخدام تدفق CDC، و AWS إنترنت الأشياء الأساسية لاستيعاب بيانات جهاز إنترنت الأشياء في Kinesis Data Streams. يمكنك استيعاب البيانات المتدفقة مباشرة في Amazon Redshift لإنشاء تطبيقات تدفق ذات زمن وصول منخفض. يمكنك أيضًا استخدام مكتبات الجهات الخارجية مثل Apache Spark وApache Kafka لاستيعاب البيانات المتدفقة في Kinesis Data Streams.
- يتعين عليك اختيار خدمات معالجة البيانات المتدفقة الخاصة بك بناءً على حالة الاستخدام المحددة ومتطلبات العمل. على سبيل المثال، يمكنك استخدام Amazon Kinesis Managed Service لـ Apache Flink لحالات استخدام البث المتقدمة مع وجهات بث متعددة ومعالجة تدفق معقدة أو إذا كنت تريد مراقبة مقاييس الأعمال في الوقت الفعلي (مثل كل ساعة). تعتبر Lambda جيدة للمعالجة القائمة على الأحداث وعديمة الحالة. يمكنك استخدام أمازون EMR لمعالجة البيانات المتدفقة لاستخدام أطر البيانات الضخمة مفتوحة المصدر المفضلة لديك. يعد AWS Glue مفيدًا لمعالجة البيانات المتدفقة في الوقت الفعلي تقريبًا لحالات الاستخدام مثل دفق ETL.
- يتم شحن وضع Kinesis Data Streams عند الطلب حسب الاستخدام ويزيد تلقائيًا من سعة الموارد، لذا فهو جيد لأحمال عمل البث المتدفقة والصيانة بدون استخدام اليدين. يتم فرض رسوم على الوضع المتوفر حسب السعة ويتطلب إدارة استباقية للسعة، لذا فهو جيد لأحمال عمل البث التي يمكن التنبؤ بها.
- يمكنك استخدام حاسبة كينيسيس المشتركة لحساب عدد القطع المطلوبة للوضع المخصص. لا داعي للقلق بشأن القطع في الوضع عند الطلب.
- عند منح الأذونات، عليك أن تقرر من الذي يحصل على الأذونات وموارد Kinesis Data Streams. يمكنك تمكين إجراءات محددة تريد السماح بها على تلك الموارد. ولذلك، يجب عليك منح الأذونات المطلوبة لتنفيذ المهمة فقط. يمكنك أيضًا تشفير البيانات غير النشطة باستخدام المفتاح المُدار لعميل KMS (CMK).
- اطلع على تحديث فترة الاحتفاظ عبر وحدة تحكم Kinesis Data Streams أو باستخدام زيادة فترة الاحتفاظ بالبث و تقليل فترة الاحتفاظ بالبث العمليات بناءً على حالات الاستخدام المحددة الخاصة بك.
- يدعم تدفقات بيانات Kinesis إعادة المشاركة. واجهة برمجة التطبيقات الموصى بها لهذه الوظيفة هي UpdateShardCount، والذي يسمح لك بتعديل عدد الأجزاء في الدفق الخاص بك للتكيف مع التغييرات في معدل تدفق البيانات عبر الدفق. عادةً ما يتم استخدام واجهات برمجة التطبيقات لإعادة التجزئة (التقسيم والدمج) للتعامل مع الأجزاء الساخنة.
وفي الختام
أظهر هذا المنشور أنماطًا معمارية مختلفة لإنشاء تطبيقات دفق منخفضة الكمون باستخدام Kinesis Data Streams. يمكنك إنشاء تطبيقات البث ذات زمن الوصول المنخفض الخاصة بك باستخدام Kinesis Data Streams باستخدام المعلومات الواردة في هذا المنشور.
للحصول على أنماط معمارية مفصلة، راجع الموارد التالية:
إذا كنت ترغب في بناء رؤية واستراتيجية للبيانات، فاطلع على كل شيء يعتمد على بيانات AWS برنامج (D2E).
حول المؤلف
 راجافاراو سوداباثينا هو مهندس الحلول الرئيسي في AWS، ويركز على تحليلات البيانات والذكاء الاصطناعي/تعلم الآلة وأمن السحابة. إنه يتفاعل مع العملاء لإنشاء حلول مبتكرة تعالج مشكلات أعمال العملاء وتسريع اعتماد خدمات AWS. في أوقات فراغه، يستمتع Raghavarao بقضاء الوقت مع عائلته، وقراءة الكتب، ومشاهدة الأفلام.
راجافاراو سوداباثينا هو مهندس الحلول الرئيسي في AWS، ويركز على تحليلات البيانات والذكاء الاصطناعي/تعلم الآلة وأمن السحابة. إنه يتفاعل مع العملاء لإنشاء حلول مبتكرة تعالج مشكلات أعمال العملاء وتسريع اعتماد خدمات AWS. في أوقات فراغه، يستمتع Raghavarao بقضاء الوقت مع عائلته، وقراءة الكتب، ومشاهدة الأفلام.
 هانغ زو هو مدير أول للمنتجات في فريق Amazon Kinesis Data Streams في Amazon Web Services. إنه متحمس لتطوير تجارب منتجات بديهية تحل مشاكل العملاء المعقدة وتمكن العملاء من تحقيق أهداف أعمالهم.
هانغ زو هو مدير أول للمنتجات في فريق Amazon Kinesis Data Streams في Amazon Web Services. إنه متحمس لتطوير تجارب منتجات بديهية تحل مشاكل العملاء المعقدة وتمكن العملاء من تحقيق أهداف أعمالهم.
 شويثا راداكريشنان هو مهندس حلول لـ AWS مع التركيز على تحليلات البيانات. لقد قامت ببناء الحلول التي تدفع اعتماد السحابة وتساعد المؤسسات على اتخاذ قرارات تعتمد على البيانات داخل القطاع العام. خارج العمل، تحب الرقص وقضاء الوقت مع الأصدقاء والعائلة والسفر.
شويثا راداكريشنان هو مهندس حلول لـ AWS مع التركيز على تحليلات البيانات. لقد قامت ببناء الحلول التي تدفع اعتماد السحابة وتساعد المؤسسات على اتخاذ قرارات تعتمد على البيانات داخل القطاع العام. خارج العمل، تحب الرقص وقضاء الوقت مع الأصدقاء والعائلة والسفر.
 بريتاني لي هو مهندس الحلول في AWS. وهي تركز على مساعدة عملاء المؤسسات في رحلة اعتماد السحابة وتحديثها ولديها اهتمام بمجال الأمن والتحليلات. خارج العمل، تحب قضاء الوقت مع كلبها ولعب كرة المخلل.
بريتاني لي هو مهندس الحلول في AWS. وهي تركز على مساعدة عملاء المؤسسات في رحلة اعتماد السحابة وتحديثها ولديها اهتمام بمجال الأمن والتحليلات. خارج العمل، تحب قضاء الوقت مع كلبها ولعب كرة المخلل.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/

