مع النمو الهائل للبيانات، تتعامل الشركات مع كميات ضخمة ومجموعة واسعة من البيانات بما في ذلك معلومات التعريف الشخصية (PII). PII هو مصطلح قانوني يتعلق بالمعلومات التي يمكنها تحديد هوية شخص واحد أو الاتصال به أو تحديد موقعه. أصبح تحديد وحماية البيانات الحساسة على نطاق واسع معقدًا ومكلفًا ويستغرق وقتًا طويلاً. يتعين على المؤسسات الالتزام بخصوصية البيانات والامتثال والمتطلبات التنظيمية مثل GDPR و CCPA، ومن المهم تحديد وحماية معلومات تحديد الهوية الشخصية (PII) للحفاظ على الامتثال. تحتاج إلى تحديد البيانات الحساسة، بما في ذلك معلومات تحديد الهوية الشخصية (PII) مثل الاسم ورقم الضمان الاجتماعي (SSN) والعنوان والبريد الإلكتروني ورخصة القيادة والمزيد. حتى بعد تحديد الهوية، يكون من الصعب تنفيذ تنقيح أو إخفاء أو تشفير البيانات الحساسة على نطاق واسع.
تقوم العديد من الشركات بتحديد وتصنيف معلومات تحديد الهوية الشخصية (PII) من خلال دليل يدوي، وهو ما يستغرق وقتًا طويلاً وعرضة للخطأ ارآء العملاء قواعد بياناتهم ومستودعات البيانات وبحيرات البيانات الخاصة بهم، مما يجعل بياناتهم الحساسة غير محمية وعرضة للعقوبات التنظيمية وحوادث الانتهاك.
في هذا المنشور، نقدم حلاً آليًا لاكتشاف بيانات تحديد الهوية الشخصية (PII) فيها الأمازون الأحمر استخدام غراء AWS.
حل نظرة عامة
باستخدام هذا الحل، نكتشف معلومات تحديد الهوية الشخصية (PII) في البيانات الموجودة في مستودع بيانات Redshift الخاص بنا حتى نتمكن من أخذ البيانات وحمايتها. نحن نستخدم الخدمات التالية:
- الأمازون الأحمر هي خدمة تخزين بيانات سحابية تستخدم SQL لتحليل البيانات المنظمة وشبه المنظمة عبر مستودعات البيانات وقواعد البيانات التشغيلية وبحيرات البيانات، باستخدام الأجهزة المصممة من قبل AWS والتعلم الآلي (ML) لتقديم أفضل سعر/أداء على أي نطاق. بالنسبة للحل الذي نقدمه، نستخدم Amazon Redshift لتخزين البيانات.
- غراء AWS هي خدمة تكامل بيانات بدون خادم تجعل من السهل اكتشاف البيانات وإعدادها ودمجها للتحليلات وتعلم الآلة وتطوير التطبيقات. نحن نستخدم AWS Glue لاكتشاف بيانات PII المخزنة في Amazon Redshift.
- خدمات التخزين البسيطة من أمازون (Amazon S3) هي خدمة تخزين توفر قابلية التوسع وتوافر البيانات والأمان والأداء الرائدة في الصناعة.
يوضح الرسم البياني التالي بنية الحلول لدينا.
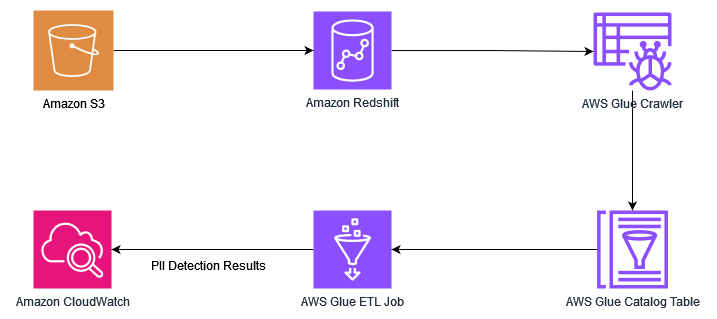
يتضمن الحل الخطوات عالية المستوى التالية:
- قم بإعداد البنية التحتية باستخدام تكوين سحابة AWS قالب.
- قم بتحميل البيانات من Amazon S3 إلى مستودع بيانات Redshift.
- قم بتشغيل زاحف AWS Glue لملء كتالوج بيانات AWS Glue بالجداول.
- قم بتشغيل مهمة AWS Glue لاكتشاف بيانات تحديد الهوية الشخصية (PII).
- تحليل الإخراج باستخدام الأمازون CloudWatch.
المتطلبات الأساسية المسبقة
تفترض الموارد التي تم إنشاؤها في هذا المنشور وجود VPC مع شبكة فرعية خاصة ومعرفاتها. وهذا يضمن أننا لا نغير بشكل كبير تكوين VPC والشبكة الفرعية. لذلك، نريد إعداد نقاط نهاية VPC الخاصة بنا استنادًا إلى VPC والشبكة الفرعية التي نختار عرضها فيها.
قبل البدء، قم بإنشاء الموارد التالية كمتطلبات أساسية:
- VPC موجود
- شبكة فرعية خاصة في VPC تلك
- نقطة نهاية S3 لبوابة VPC
- نقطة نهاية بوابة VPC STS
قم بإعداد البنية التحتية باستخدام AWS CloudFormation
لإنشاء البنية الأساسية الخاصة بك باستخدام قالب CloudFormation، أكمل الخطوات التالية:
- افتح وحدة تحكم AWS CloudFormation في حساب AWS الخاص بك.
- اختار قم بتشغيل Stack:

- اختار التالى.
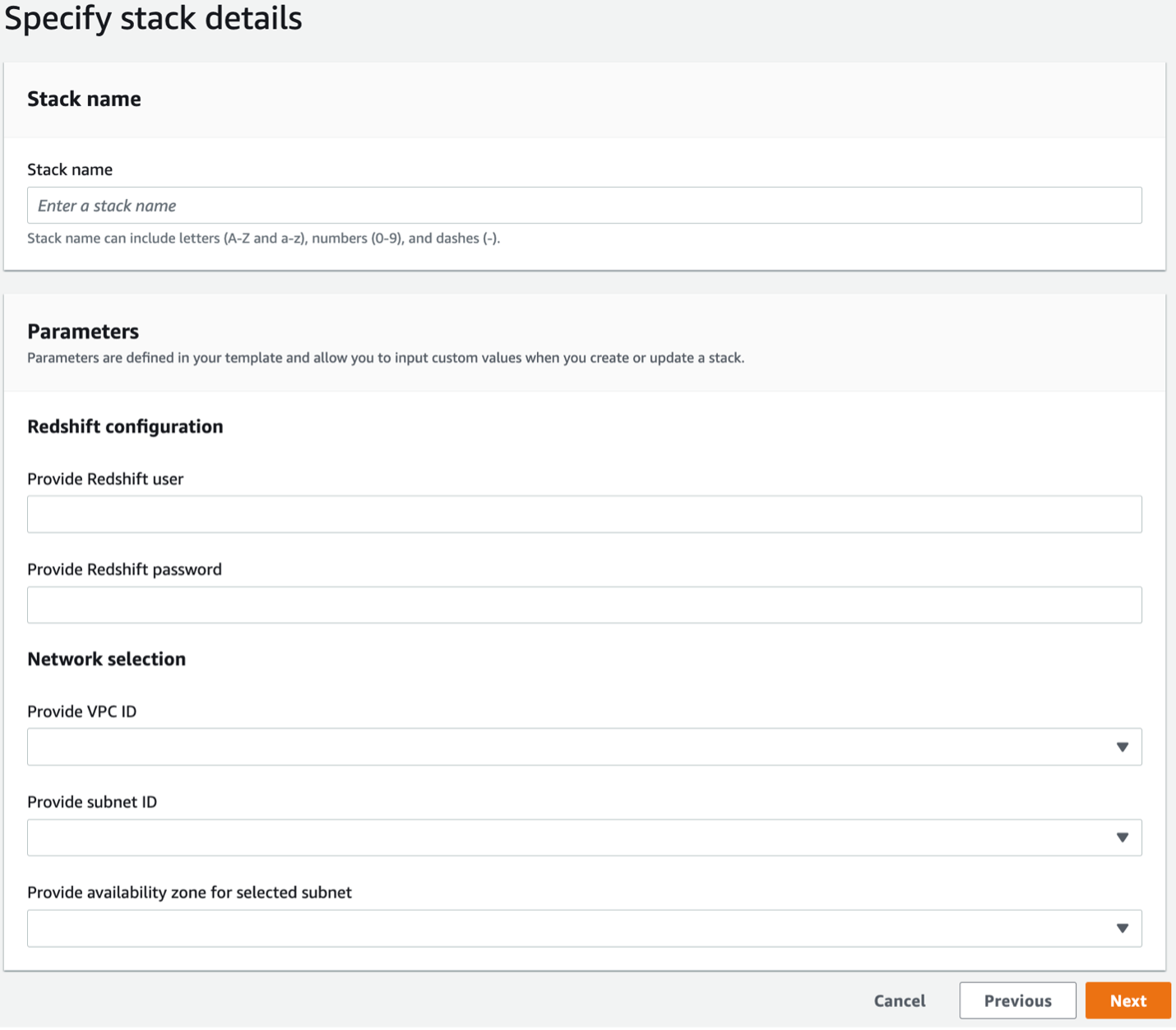
- وفر المعلومات التالية:
- اسم المكدس
- اسم مستخدم Amazon Redshift
- كلمة مرور أمازون Redshift
- معرف VPC
- معرف الشبكة الفرعية
- مناطق توافر الخدمات لمعرف الشبكة الفرعية
- اختار التالى.
- في الصفحة التالية ، اختر التالى.
- راجع التفاصيل وحدد أقر بأن AWS CloudFormation قد تنشئ موارد IAM.
- اختار إنشاء مكدس.
- لاحظ قيم
S3BucketNameوRedshiftRoleArnعلى المكدس النواتج علامة التبويب.
قم بتحميل البيانات من Amazon S3 إلى مستودع بيانات Redshift
مع أمر COPY، يمكننا تحميل البيانات من الملفات الموجودة في واحدة أو أكثر من مجموعات S3. نستخدم جملة FROM للإشارة إلى كيفية قيام أمر COPY بتحديد موقع الملفات في Amazon S3. يمكنك توفير مسار الكائن إلى ملفات البيانات كجزء من عبارة FROM، أو يمكنك توفير موقع ملف البيان الذي يحتوي على قائمة مسارات كائنات S3. تستخدم النسخة من Amazon S3 اتصال HTTPS.
في هذا المنشور، نستخدم عينة من الصحة الشخصية بيانات. قم بتحميل البيانات بالخطوات التالية:
- في وحدة تحكم Amazon S3، انتقل إلى حاوية S3 التي تم إنشاؤها من قالب CloudFormation وتحقق من مجموعة البيانات.
- اتصل بمستودع بيانات Redshift باستخدام محرر الاستعلام الإصدار 2 عن طريق إنشاء اتصال بقاعدة البيانات التي تقوم بإنشائها باستخدام مكدس CloudFormation بالإضافة إلى اسم المستخدم وكلمة المرور.
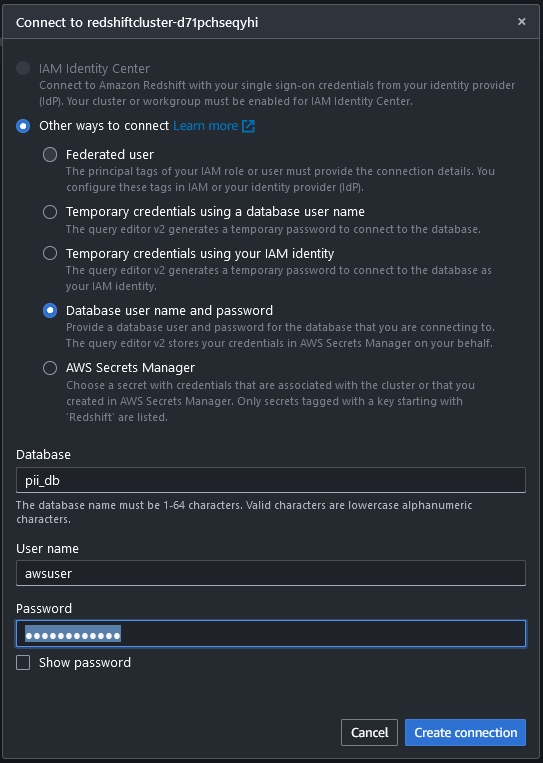
بعد الاتصال، يمكنك استخدام الأوامر التالية لإنشاء الجدول في مستودع بيانات Redshift ونسخ البيانات.
- قم بإنشاء جدول بالاستعلام التالي:
- قم بتحميل البيانات من حاوية S3:
توفير قيم للعناصر النائبة التالية:
- RedshiftRoleArn - حدد موقع ARN على مكدس CloudFormation النواتج علامة التبويب
- الاسم - استبدل باسم الجرافة من مكدس CloudFormation
- منطقة أوس - قم بالتغيير إلى المنطقة التي قمت بنشر قالب CloudFormation فيها
- للتحقق من تحميل البيانات، قم بتشغيل الأمر التالي:

قم بتشغيل زاحف AWS Glue لملء كتالوج البيانات بالجداول
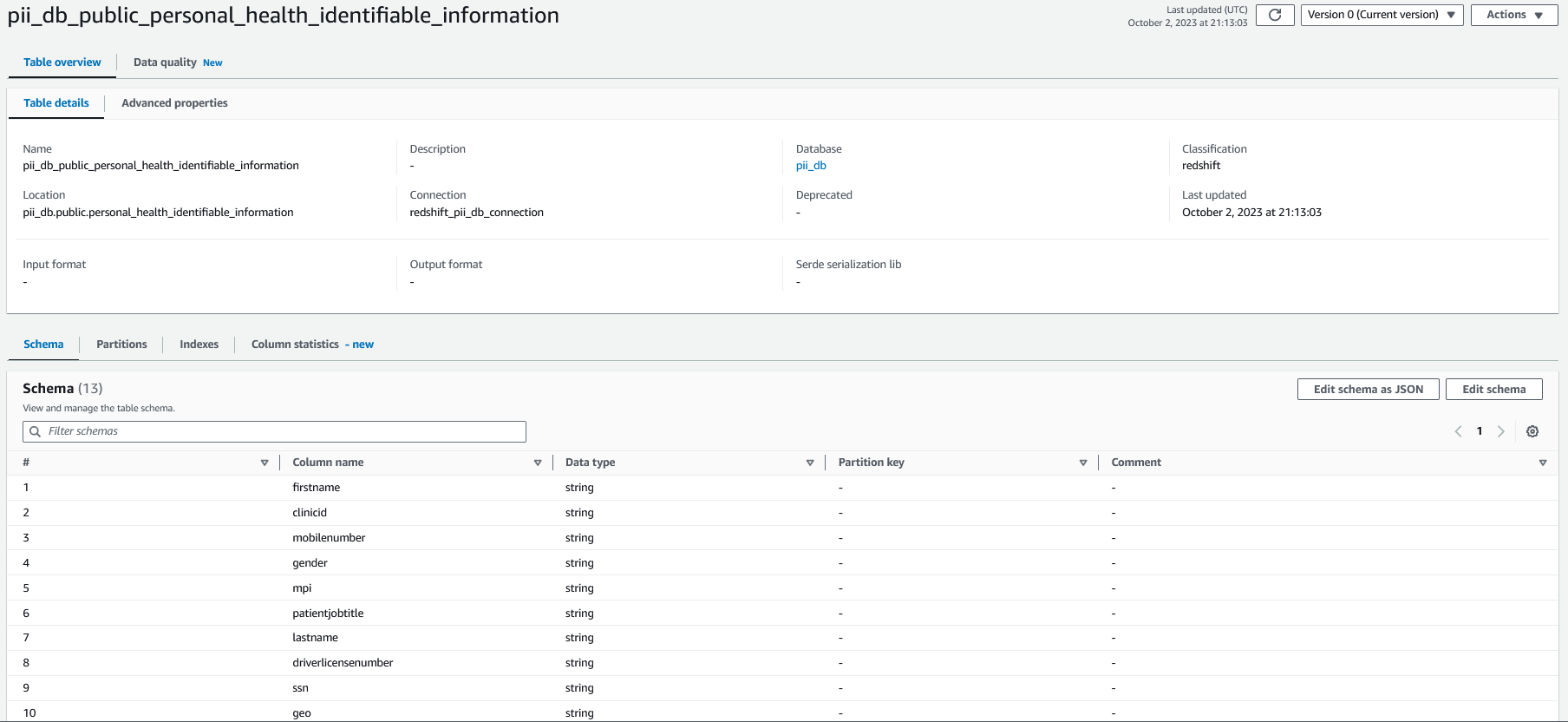
في وحدة تحكم AWS Glue، حدد الزاحف الذي قمت بنشره كجزء من حزمة CloudFormation بالاسم crawler_pii_db، ثم اختر تشغيل الزاحف.

عند اكتمال الزاحف، الجداول الموجودة في قاعدة البيانات بالاسم pii_db يتم ملؤها في كتالوج بيانات AWS Glue، ويبدو مخطط الجدول مثل لقطة الشاشة التالية.
قم بتشغيل مهمة AWS Glue لاكتشاف بيانات PII وإخفاء الأعمدة المقابلة في Amazon Redshift
في وحدة تحكم AWS Glue ، اختر وظائف إي تي إل في جزء التنقل وحدد موقع مهمة كشف بيانات pii لفهم تكوينها. يتم تكوين الخصائص الأساسية والمتقدمة باستخدام قالب CloudFormation.
الخصائص الأساسية هي كما يلي:
- النوع - شرارة
- نسخة الغراء - الغراء 4.0
- اللغة - بايثون
ولأغراض العرض التوضيحي، تم تعطيل خيار الإشارات المرجعية للوظيفة، بالإضافة إلى ميزة القياس التلقائي.

نقوم أيضًا بتكوين الخصائص المتقدمة فيما يتعلق بالاتصالات ومعلمات الوظيفة.
للوصول إلى البيانات الموجودة في Amazon Redshift، قمنا بإنشاء اتصال AWS Glue الذي يستخدم اتصال JDBC.
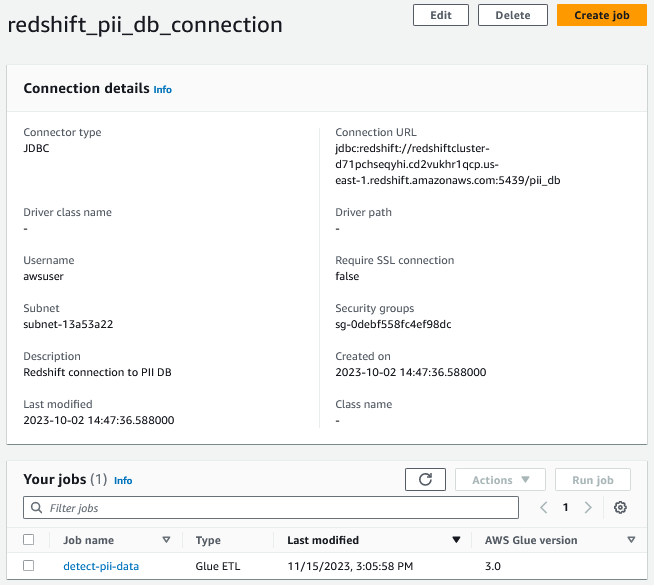
نحن نقدم أيضًا معلمات مخصصة كأزواج ذات قيمة رئيسية. في هذا المنشور، قمنا بتقسيم معلومات تحديد الهوية الشخصية (PII) إلى خمس فئات اكتشاف مختلفة:
- بالمذيب -
PERSON_NAME,EMAIL,CREDIT_CARD - HIPAA -
PERSON_NAME,PHONE_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT,USA_DRIVING_LICENSE,USA_HCPCS_CODE,USA_NATIONAL_DRUG_CODE,USA_NATIONAL_PROVIDER_IDENTIFIER,USA_DEA_NUMBER,USA_HEALTH_INSURANCE_CLAIM_NUMBER,USA_MEDICARE_BENEFICIARY_IDENTIFIER - الشبكات -
IP_ADDRESS,MAC_ADDRESS - الولايات المتحدة -
PHONE_NUMBER,USA_PASSPORT_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT - على - الإحداثيات
إذا كنت تجرب هذا الحل من بلدان أخرى، فيمكنك تحديد حقول PII المخصصة باستخدام الفئة المخصصة، لأنه يتم إنشاء هذا الحل استنادًا إلى مناطق الولايات المتحدة.
لأغراض العرض التوضيحي، نستخدم جدولًا واحدًا ونمرره كمعلمة التالية:
--table_name: table_nameفي هذه التدوينة، قمنا بتسمية الجدول personal_health_identifiable_information.

يمكنك تخصيص هذه المعلمات بناءً على حالة استخدام الأعمال الفردية.
قم بتشغيل المهمة وانتظر Success الحالة.
الوظيفة لها هدفان. الهدف الأول هو تحديد الأعمدة المرتبطة ببيانات PII في جدول Redshift وإنشاء قائمة بأسماء الأعمدة هذه. الهدف الثاني هو تشويش البيانات في تلك الأعمدة المحددة في الجدول المستهدف. وكجزء من الهدف الثاني، فإنه يقرأ بيانات الجدول، ويطبق وظيفة التقنيع المعرفة من قبل المستخدم على تلك الأعمدة المحددة، ويحدث البيانات في الجدول الهدف باستخدام جدول التدريج Redshift (stage_personal_health_identifiable_information) للظهور.
وبدلاً من ذلك، يمكنك أيضًا استخدام إخفاء البيانات الديناميكي (DDM) في Amazon Redshift لحماية البيانات الحساسة في مستودع البيانات الخاص بك.
تحليل الإخراج باستخدام CloudWatch
عند اكتمال المهمة، فلنراجع سجلات CloudWatch لفهم كيفية تشغيل مهمة AWS Glue. يمكننا الانتقال إلى سجلات CloudWatch عن طريق الاختيار سجلات الإخراج في صفحة تفاصيل المهمة على وحدة تحكم AWS Glue.

حددت المهمة كل عمود يحتوي على بيانات PII، بما في ذلك الحقول المخصصة التي تم تمريرها باستخدام حقول الكشف عن البيانات الحساسة لمهمة AWS Glue.

تنظيف
لتنظيف البنية التحتية وتجنب الرسوم الإضافية ، أكمل الخطوات التالية:
- إفراغ دلاء S3.
- احذف نقاط النهاية التي قمت بإنشائها.
- احذف مكدس CloudFormation عبر وحدة تحكم AWS CloudFormation لحذف الموارد المتبقية.

وفي الختام
باستخدام هذا الحل، يمكنك فحص البيانات الموجودة في مجموعات Redshift تلقائيًا باستخدام مهمة AWS Glue، وتحديد معلومات تحديد الهوية الشخصية (PII)، واتخاذ الإجراءات اللازمة. يمكن أن يساعد ذلك مؤسستك في ميزات الأمان والامتثال والحوكمة وحماية البيانات، والتي تساهم في أمن البيانات وإدارة البيانات.
حول المؤلف
 مانيكانتا جونا هو مهندس بيانات و ML في AWS Professional Services. انضم إلى AWS في عام 2021 ويتمتع بخبرة تزيد عن 6 سنوات في مجال تكنولوجيا المعلومات. في AWS ، يركز على تطبيقات Data Lake والبحث وأعباء العمل التحليلية باستخدام Amazon OpenSearch Service. في أوقات فراغه ، يحب البستنة والمشي لمسافات طويلة وركوب الدراجات مع زوجها.
مانيكانتا جونا هو مهندس بيانات و ML في AWS Professional Services. انضم إلى AWS في عام 2021 ويتمتع بخبرة تزيد عن 6 سنوات في مجال تكنولوجيا المعلومات. في AWS ، يركز على تطبيقات Data Lake والبحث وأعباء العمل التحليلية باستخدام Amazon OpenSearch Service. في أوقات فراغه ، يحب البستنة والمشي لمسافات طويلة وركوب الدراجات مع زوجها.
 دينيس نوفيكوف هو أحد كبار مهندسي Data Lake مع فريق الخدمات الاحترافية في Amazon Web Services. وهو متخصص في تصميم وتنفيذ التحليلات وإدارة البيانات وأنظمة البيانات الضخمة لعملاء المؤسسات.
دينيس نوفيكوف هو أحد كبار مهندسي Data Lake مع فريق الخدمات الاحترافية في Amazon Web Services. وهو متخصص في تصميم وتنفيذ التحليلات وإدارة البيانات وأنظمة البيانات الضخمة لعملاء المؤسسات.
 أنجان موخيرجي هو مهندس Data Lake في AWS، وهو متخصص في حلول البيانات الضخمة والتحليلات. إنه يساعد العملاء على بناء تطبيقات قابلة للتطوير وموثوقة وآمنة وعالية الأداء على منصة AWS.
أنجان موخيرجي هو مهندس Data Lake في AWS، وهو متخصص في حلول البيانات الضخمة والتحليلات. إنه يساعد العملاء على بناء تطبيقات قابلة للتطوير وموثوقة وآمنة وعالية الأداء على منصة AWS.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/automatically-detect-personally-identifiable-information-in-amazon-redshift-using-aws-glue/

