يهتم العديد من العملاء بتعزيز الإنتاجية في دورة حياة تطوير البرامج الخاصة بهم باستخدام الذكاء الاصطناعي التوليدي. حديثاً، أعلنت AWS عن التوفر العام لبرنامج Amazon CodeWhisperer، وهو رفيق ترميز الذكاء الاصطناعي الذي يستخدم النماذج الأساسية ضمن الغطاء لتحسين إنتاجية مطوري البرامج. مع أمازون CodeWhisperer، يمكنك قبول الاقتراح الرئيسي بسرعة، أو عرض المزيد من الاقتراحات، أو الاستمرار في كتابة التعليمات البرمجية الخاصة بك. يقلل هذا التكامل من الوقت الإجمالي المستغرق في كتابة تكامل البيانات ومنطق الاستخراج والتحويل والتحميل (ETL). كما أنه يساعد المبرمجين على مستوى المبتدئين على كتابة الأسطر الأولى من التعليمات البرمجية. أجهزة الكمبيوتر الدفترية AWS Glue Studio يسمح لك بتأليف مهام تكامل البيانات من خلال واجهة دفتر الملاحظات بدون خادم المستندة إلى الويب.
في هذا المنشور، نناقش حالات الاستخدام الواقعية لـ CodeWhisperer المدعوم من دفاتر ملاحظات AWS Glue Studio.
حل نظرة عامة
لهذا المنصب، يمكنك استخدام CSV مجموعة بيانات أرباح الرياضة الإلكترونية، متاح للتنزيل عبر Kaggle. يتم استخراج البيانات من eSportsEarnings.com، والذي يوفر معلومات عن أرباح لاعبي وفرق الرياضات الإلكترونية. الهدف هو إجراء تحويلات باستخدام دفتر ملاحظات AWS Glue Studio مع توصيات CodeWhisperer ثم إعادة كتابة البيانات إلى خدمة تخزين أمازون البسيطة (Amazon S3) بتنسيق ملف Parquet بالإضافة إلى الأمازون الأحمر.
المتطلبات الأساسية المسبقة
الحل لدينا لديه المتطلبات الأساسية التالية:
- قم بإعداد AWS Glue Studio.
- تكوين إدارة الهوية والوصول AWS دور (IAM) للتفاعل مع CodeWhisperer. قم بإرفاق السياسة التالية بدور IAM الخاص بك والمرتبط بدفتر ملاحظات AWS Glue Studio:
{ "Version": "2012-10-17", "Statement": [{ "Sid": "CodeWhispererPermissions", "Effect": "Allow", "Action": [ "codewhisperer:GenerateRecommendations" ], "Resource": "*" }]
}
- قم بتنزيل ملف CSV مجموعة بيانات أرباح الرياضة الإلكترونية وتحميل ملف CSV
highest_earning_players.csv إلى المجلد S3 الذي ستستخدمه في حالة الاستخدام هذه.
قم بإنشاء دفتر ملاحظات AWS Glue Studio
هيا بنا نبدأ. قم بإنشاء مهمة دفتر ملاحظات AWS Glue Studio جديدة من خلال إكمال الخطوات التالية:
- في وحدة تحكم AWS Glue ، اختر دفاتر مع وظائف ETL في جزء التنقل.
- أختار مفكرة Jupyter واختر إنشاء.
- في حالة اسم العمل، أدخل
CodeWhisperer-s3toJDBC.
سيتم إنشاء دفتر ملاحظات جديد باستخدام عينات الخلايا كما هو موضح في لقطة الشاشة التالية.
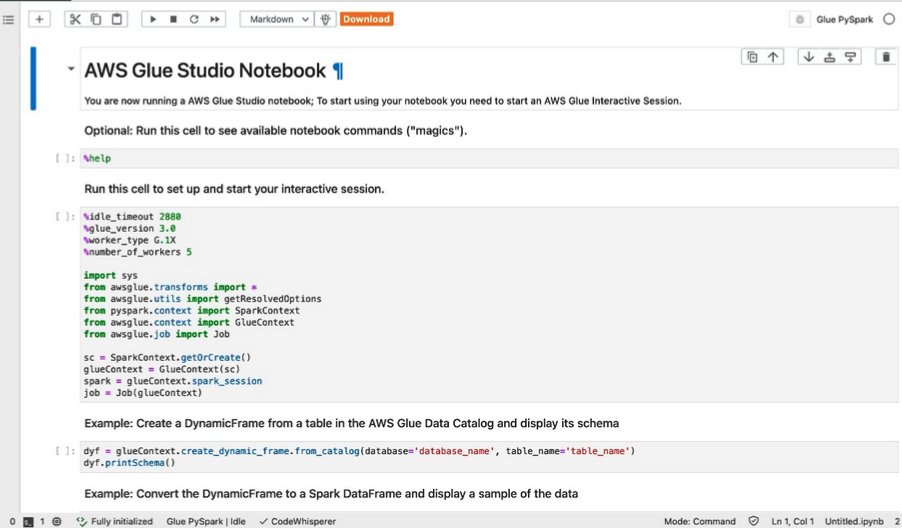
نستخدم الخلية الثانية في الوقت الحالي، حتى تتمكن من إزالة كافة الخلايا الأخرى.
- في الخلية الثانية، قم بتحديث تكوين الجلسة التفاعلية عن طريق تعيين ما يلي:
- نوع العامل إلى G.1X
- عدد العمال إلى 3
- إصدار AWS الغراء إلى 4.0
- علاوة على ذلك، قم باستيراد
DynamicFrame وحدة و current_timestamp تعمل على النحو التالي:
from pyspark.sql.functions import current_timestamp
from awsglue.dynamicframe import DynamicFrame
بعد إجراء هذه التغييرات، يجب أن يبدو دفتر الملاحظات مثل لقطة الشاشة التالية.

الآن، دعونا نتأكد من أن CodeWhisperer يعمل على النحو المنشود. في أسفل اليمين ستجد الشفرة الخيار بجانب الغراء PySpark الحالة، كما هو موضح في لقطة الشاشة التالية.
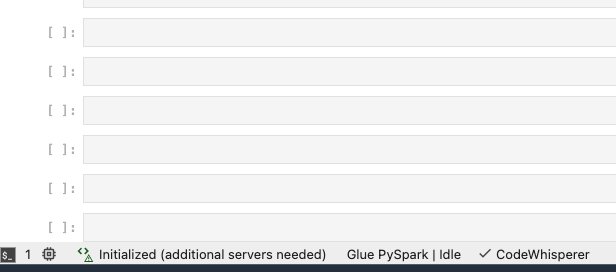
يمكنك اختيار الشفرة لعرض الخيارات المستخدمة الاقتراحات التلقائية.
قم بتطوير التعليمات البرمجية الخاصة بك باستخدام CodeWhisperer في دفتر ملاحظات AWS Glue Studio
في هذا القسم، نعرض كيفية تطوير مهمة دفتر ملاحظات AWS Glue لـ Amazon S3 كمصدر بيانات ومصادر بيانات JDBC كهدف. بالنسبة لحالة الاستخدام الخاصة بنا، نحتاج إلى التأكد من تمكين الاقتراحات التلقائية. اكتب توصيتك باستخدام CodeWhisperer باتباع الخطوات التالية:
- اكتب تعليقًا باللغة الطبيعية (باللغة الإنجليزية) لقراءة ملفات Parquet من حاوية S3 الخاصة بك:
بعد إدخال التعليق السابق ثم اضغط أدخل، سيظهر زر CodeWhisperer الموجود في نهاية الصفحة أنه قيد التشغيل لكتابة التوصية. سيظهر مخرج توصية CodeWhisperer في السطر التالي ويتم اختيار الرمز بعد الضغط عليه علامة التبويب. يمكنك معرفة المزيد في إجراءات المستخدم.
بعد إدخال التعليق السابق، سيقوم CodeWhisperer بإنشاء مقتطف تعليمات برمجية مشابه لما يلي:
df = (spark.read.format("csv") .option("header", "true") .option("inferSchema", "true") .load("s3://<bucket>/<path>/highest_earning_players.csv"))
لاحظ أنك بحاجة إلى تحديث المسارات لتتوافق مع مجموعة S3 التي تستخدمها بدلاً من مجموعة CodeWhisperer.
من مقتطف التعليمات البرمجية السابق، استخدم CodeWhisperer Spark DataFrames لقراءة ملفات CSV.
- يمكنك الآن تجربة بعض إعادة الصياغة للحصول على اقتراح باستخدام وظائف DynamicFrame:
# Read CSV file from S3 with the header format option using DynamicFrame"
الآن سيقوم CodeWhisperer بإنشاء مقتطف تعليمات برمجية قريب مما يلي:
dyF = glueContext.create_dynamic_frame.from_options( connection_type="s3", connection_options={ "paths": ["s3://<bucket>/<path>/highest_earning_players.csv"], "recurse": True, }, format="csv", format_options={ "withHeader": True, }, transformation_ctx="dyF")
إعادة صياغة الجمل المكتوبة الآن أثبتت أنه بعد بعض التعديلات على التعليقات التي كتبناها، حصلنا على التوصية الصحيحة من CodeWhisperer.
- بعد ذلك، استخدم CodeWhisperer لطباعة مخطط AWS Glue DynamicFrame السابق باستخدام التعليق التالي:
# Print the schema of the above DynamicFrame
سيقوم CodeWhisperer بإنشاء مقتطف تعليمات برمجية قريب مما يلي:
نحصل على الناتج التالي.

نستخدم الآن CodeWhisperer لإنشاء بعض وظائف التحويل التي يمكنها معالجة AWS Glue DynamicFrame الذي تمت قراءته مسبقًا. نبدأ بإدخال الرمز في خلية جديدة.
- أولاً، اختبر ما إذا كان بإمكان CodeWhisperer استخدام وظائف سياق AWS Glue الصحيحة مثل خيار الحل:
# Convert the "PlayerId" type from string to integer
أوصى CodeWhisperer بمقتطف تعليمات برمجية مشابه لما يلي:
dyF = dyF.resolveChoice(specs=[('PlayerId', 'cast:long')])
dyF.printSchema()
لا يمثل مقتطف الشفرة السابق التعليق الذي أدخلناه بدقة.
- يمكنك تطبيق إعادة صياغة الجملة وتبسيطها من خلال تقديم التعليقات الثلاثة التالية. كل واحد لديه سؤال مختلف ونحن نستخدم withColumn طريقة Spark Frame والتي تستخدم في صب أنواع الأعمدة:
# Convert the DynamicFrame to spark data frame
# Cast the 'PlayerId' column from string to Integer using WithColumn function # Convert the spark frame back to DynamicFrame and print the schema
سوف يلتقط CodeWhisperer الأوامر السابقة ويوصي بمقتطف التعليمات البرمجية التالي بالتسلسل:
df = dyF.toDF()
df = df.withColumn("PlayerId", df["PlayerId"].cast("integer"))
dyF = DynamicFrame.fromDF(df, glueContext, "dyF")
dyF.printSchema()
يؤكد الإخراج التالي PlayerId يتم تغيير العمود من السلسلة إلى عدد صحيح.

- قم بتطبيق نفس العملية على AWS Glue DynamicFrame الناتج لـ
TotalUSDPrize العمود عن طريق تحويله من السلسلة إلى فترة طويلة باستخدام withColumn وظائف Spark Frame عن طريق إدخال التعليقات التالية:
# Convert the dynamicFrame to Spark Frame
# Cast the "TotalUSDPrize" column from String to long
# Convert the spark frame back to dynamic frame and print the schema
مقتطف الشفرة الموصى به مشابه لما يلي:
df = dyF.toDF()
df = df.withColumn("TotalUSDPrize", df["TotalUSDPrize"].cast("long"))
dyF = DynamicFrame.fromDF(df, glueContext, "dyF")
dyF.printSchema()
مخطط الإخراج لمقتطف التعليمات البرمجية السابق هو كما يلي.

سنحاول الآن التوصية بمقتطف رمز يعكس متوسط الجائزة لكل لاعب وفقًا لرمز بلده.
- للقيام بذلك، ابدأ بالحصول على عدد اللاعبين في كل بلد:
# Get the count of each country code
مقتطف الشفرة الموصى به مشابه لما يلي:
country_code_count = df.groupBy("CountryCode").count()
country_code_count.show()
نحصل على الناتج التالي.

- انضم إلى DataFrame الرئيسي مع عدد رمز البلد DataFrame ثم أضف عمودًا جديدًا يحسب متوسط أعلى جائزة لكل لاعب وفقًا لرمز بلده:
# Convert the DynamicFrame (dyF) to dataframe (df)
# Join the dataframe (df) with country_code_count dataframe with respect to CountryCode column
# Convert the spark frame back to DynamicFrame and print the schema
مقتطف الشفرة الموصى به مشابه لما يلي:
df = dyF.toDF()
df = df.join(country_code_count, "CountryCode")
dyF = DynamicFrame.fromDF(df, glueContext, "dyF")
dyF.printSchema()
يؤكد إخراج المخطط الآن كلاً من DataFrames حيث تم ربطهما بشكل صحيح و Count تتم إضافة العمود إلى DataFrame الرئيسي.

- احصل على توصية الكود في مقتطف الكود لحساب المتوسط
TotalUSDPrize لكل رمز بلد وإضافته إلى عمود جديد:
# Get the sum of all the TotalUSDPrize column per countrycode
# Rename the sum column to be "SumPrizePerCountry" in the newly generated dataframe
مقتطف الشفرة الموصى به مشابه لما يلي:
country_code_sum = df.groupBy("CountryCode").sum("TotalUSDPrize")
country_code_sum = country_code_sum.withColumnRenamed("sum(TotalUSDPrize)", "SumPrizePerCountry")
country_code_sum.show()
يجب أن يبدو إخراج التعليمة البرمجية السابقة كما يلي.

- الانضمام الى
country_code_sum DataFrame مع DataFrame الرئيسي من وقت سابق واحصل على متوسط الجوائز لكل لاعب في كل بلد:
# Join the above dataframe with the main dataframe with respect to CountryCode
# Get the average Total prize in USD per player per country and add it to a new column called "AveragePrizePerPlayerPerCountry"
مقتطف الشفرة الموصى به مشابه لما يلي:
df = df.join(country_code_sum, "CountryCode")
df = df.withColumn("AveragePrizePerPlayerPerCountry", df["SumPrizePerCountry"] / df["count"])
- الجزء الأخير في مرحلة التحول هو فرز البيانات حسب أعلى متوسط جائزة لكل لاعب في كل بلد:
# sort the above dataframe descendingly according to the highest Average Prize per player country
# Show the top 5 rows
مقتطف الشفرة الموصى به مشابه لما يلي:
df = df.sort(df["AveragePrizePerPlayerPerCountry"].desc())
df.show(5)
ستكون الصفوف الخمسة الأولى مشابهة لما يلي.

بالنسبة للخطوة الأخيرة، نكتب DynamicFrame إلى Amazon S3 وAmazon Redshift.
- اكتب DynamicFrame إلى Amazon S3 باستخدام الكود التالي:
# Convert the data frame to DynamicFrame
# Write the DynamicFrame to S3 in glueparquet format
تشبه توصية CodeWhisperer مقتطف التعليمات البرمجية التالي:
dyF = DynamicFrame.fromDF(df, glueContext, "dyF") glueContext.write_dynamic_frame.from_options(
frame=dyF,
connection_type="s3",
connection_options={ "path": "s3://<enter your own>/", "partitionKeys": [],
},
format = "glueparquet",
)
نحتاج إلى تصحيح مقتطف الشفرة الذي تم إنشاؤه بعد التوصية لأنه لا يحتوي على مفاتيح القسم. وكما أشرنا، partitionkeys فارغ، لذا يمكننا الحصول على اقتراح آخر لكتلة التعليمات البرمجية لتعيينه partitionkey ثم اكتبه إلى موقع Amazon S3 المستهدف. وأيضًا وفقًا لأحدث التحديثات المتعلقة بكتابة DynamicFrames إلى Amazon S3 باستخدام glueparquet, format = "glueparquet" لم يعد يستخدم. بدلا من ذلك، تحتاج إلى استخدام نوع الباركيه مع useGlueParquetWriter تمكين.
بعد التحديثات، يبدو الكود الخاص بنا مشابهًا لما يلي:
dyF = DynamicFrame.fromDF(df, glueContext, "dyF") glueContext.write_dynamic_frame.from_options(
frame=dyF,
connection_type="s3",
connection_options={ "path": "s3://<enter your own>/",
},
format = "parquet", format_options={ "useGlueParquetWriter": True, },
)
هناك خيار آخر يتمثل في كتابة الملفات إلى Amazon Redshift باستخدام اتصال JDBC.
- أولاً، أدخل الأمر التالي للتحقق مما إذا كان CodeWhisperer سيفهم التعليق في جملة واحدة ويستخدم الوظائف الصحيحة أم لا:
# Write the DynamicFrame to Redshift
# Select only the following 3 columns in the DynamicFrame to write to redshift: CountryCode, TotalUSDPrize, NameFirst, NameLast, AveragePrizePerPlayerPerCountr
يشبه إخراج التعليق مقتطف التعليمات البرمجية التالي:
dyF = dyF.select_fields(["CountryCode", "TotalUSDPrize", "NameFirst","NameLast","AveragePrizePerPlayerPerCountry"])
glueContext.write_dynamic_frame.from_options( frame=dyF, connection_type="redshift", connection_options={ "url": "jdbc:redshift://omarglueblog.cjzxbkzmhwqm.us-east-1.redshift.amazonaws.com:5439/omarglueblog", "user": "omarglueblog", "password": "omarglueblog", "dbtable": "highest_earning_players_redshift", "driver": "com.amazon.redshift.jdbc42.Driver", "preactions": "truncate table highest_earning_players_redshift", "redshiftTmpDir": "s3://awsgluetest/tmp/", "aws_iam_role": "0000000000000000000000000:role/glue-role", }, format = "redshift", transformation_ctx="dyF" )
وكما نرى، قام CodeWhisperer بتفسير التعليق بشكل صحيح عن طريق تحديد الأعمدة المحددة فقط للكتابة إلى Amazon Redshift.
- الآن، استخدم CodeWhisperer لكتابة DynamicFrame إلى Amazon Redshift. نحن نستخدم ال قبل الحدث المعلمة لتشغيل استعلام SQL لتحديد أعمدة معينة فقط ليتم كتابتها إلى Amazon Redshift:
# Write the resultant DynamicFrame to Redshift # using preaction that selects only the following columns: CountryCode, TotalUSDPrize, NameFirst, NameLast, AveragePrizePerPlayerPerCountry
تشبه توصية CodeWhisperer مقتطف التعليمات البرمجية التالي:
glueContext.write_dynamic_frame.from_options( frame = dyf, connection_type = "redshift", connection_options = { "url": "jdbc:redshift://awsgluetest.cjw8y5zdqmhz.us-east-1.redshift.amazonaws.com:5439/dev", "user": "awsuser", "password": "awsuser", "dbtable": "players", "preactions": "SELECT CountryCode, TotalUSDPrize, NameFirst, NameLast, AveragePrizePerPlayerPerCountry FROM highest_earning_player", "redshiftTmpDir": "s3://awsgluetest/tmp/" }, format = "glueparquet", transformation_ctx = "write_dynamic_frame")
بعد التحقق من مقتطف الشفرة السابق، يمكنك ملاحظة وجود خطأ في مكانه format، والتي يمكنك إزالتها. يمكنك أيضًا إضافة iam_role كمدخل في connection_options. يمكنك أيضًا ملاحظة أن CodeWhisperer قد افترض تلقائيًا أن عنوان URL الخاص بـ Redshift يحمل نفس اسم مجلد S3 الذي استخدمناه. لذلك، تحتاج إلى تغيير عنوان URL وحاوية الدليل المؤقت لـ S3 لتعكس المعلمات الخاصة بك وإزالة معلمة كلمة المرور. يجب أن يكون مقتطف الشفرة النهائي مشابهًا لما يلي:
glueContext.write_dynamic_frame.from_options(
frame=dyF,
connection_type="redshift",
connection_options={ "url": "jdbc:redshift://<enter your own>.cjwjn5pzxbhx.us-east-1.redshift.amazonaws.com:5439/<enter your own>", "user": "<enter your own>", "dbtable": "<enter your own>", "driver": "com.amazon.redshift.jdbc42.Driver", "preactions": "SELECT CountryCode, TotalUSDPrize, NameFirst, NameLast, AveragePrizePerPlayerPerCountry FROM <enter your table>", "redshiftTmpDir": "<enter your own>", "aws_iam_role": "<enter your own>",
}
)
فيما يلي الكود الكامل ومقتطفات التعليق:
%idle_timeout 2880
%glue_version 4.0
%worker_type G.1X
%number_of_workers 3 import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import current_timestamp
from awsglue.DynamicFrame import DynamicFrame sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext) # Read CSV files from S3
dyF = glueContext.create_dynamic_frame.from_options( connection_type="s3", connection_options={ "paths": ["s3://<bucket>/<path>/highest_earning_players.csv"], "recurse": True, }, format="csv", format_options={ "withHeader": True, }, transformation_ctx="dyF") # Print the schema of the above DynamicFrame
dyF.printSchema() # Convert the DynamicFrame to spark data frame
# Cast the 'PlayerId' column from string to Integer using WithColumn function
# Convert the spark frame back to DynamicFrame and print the schema
df = dyF.toDF()
df = df.withColumn("PlayerId", df["PlayerId"].cast("integer"))
dyF = DynamicFrame.fromDF(df, glueContext, "dyF")
dyF.printSchema() # Convert the dynamicFrame to Spark Frame
# Cast the "TotalUSDPrize" column from String to long
# Convert the spark frame back to dynamic frame and print the schema
df = dyF.toDF()
df = df.withColumn("TotalUSDPrize", df["TotalUSDPrize"].cast("long"))
dyF = DynamicFrame.fromDF(df, glueContext, "dyF")
dyF.printSchema() # Get the count of each country code
country_code_count = df.groupBy("CountryCode").count()
country_code_count.show() # Convert the DynamicFrame (dyF) to dataframe (df)
# Join the dataframe (df) with country_code_count dataframe with respect to CountryCode column
# Convert the spark frame back to DynamicFrame and print the schema
df = dyF.toDF()
df = df.join(country_code_count, "CountryCode")
df.printSchema() # Get the sum of all the TotalUSDPrize column per countrycode
# Rename the sum column to be "SumPrizePerCountry"
country_code_sum = df.groupBy("CountryCode").sum("TotalUSDPrize")
country_code_sum = country_code_sum.withColumnRenamed("sum(TotalUSDPrize)", "SumPrizePerCountry")
country_code_sum.show() # Join the above dataframe with the main dataframe with respect to CountryCode
# Get the average Total prize in USD per player per country and add it to a new column called "AveragePrizePerPlayerPerCountry"
df.join(country_code_sum, "CountryCode")
df = df.withColumn("AveragePrizePerPlayerPerCountry", df["SumPrizePerCountry"] / df["count"]) # sort the above dataframe descendingly according to the highest Average Prize per player country
# Show the top 5 rows
df = df.sort(df["AveragePrizePerPlayerPerCountry"].desc())
df.show(5) # Convert the data frame to DynamicFrame
# Write the DynamicFrame to S3 in glueparquet format
dyF = DynamicFrame.fromDF(df, glueContext, "dyF") glueContext.write_dynamic_frame.from_options(
frame=dyF,
connection_type="s3",
connection_options={ "path": "s3://<enter your own>/",
},
format = "parquet", format_options={ "useGlueParquetWriter": True, },
) # Write the resultant DynamicFrame to Redshift # using preaction that selects only the following columns: CountryCode, TotalUSDPrize, NameFirst, NameLast, AveragePrizePerPlayerPerCountry
glueContext.write_dynamic_frame.from_options(
frame=dyF,
connection_type="redshift",
connection_options={ "url": "jdbc:redshift://<enter your own>.cjwjn5pzxbhx.us-east-1.redshift.amazonaws.com:5439/<enter your own>", "user": "<enter your own>", "dbtable": "<enter your own>", "driver": "com.amazon.redshift.jdbc42.Driver", "preactions": "SELECT CountryCode, TotalUSDPrize, NameFirst, NameLast, AveragePrizePerPlayerPerCountry FROM <enter your table>", "redshiftTmpDir": "<enter your own>", "aws_iam_role": "<enter your own>",
}
)
وفي الختام
في هذا المنشور، أظهرنا حالة استخدام واقعية حول كيفية قيام تكامل دفتر الملاحظات AWS Glue Studio مع CodeWhisperer بمساعدتك في إنشاء مهام تكامل البيانات بشكل أسرع. يمكنك البدء في استخدام دفتر ملاحظات AWS Glue Studio مع CodeWhisperer لتسريع إنشاء مهام تكامل البيانات الخاصة بك.
لمعرفة المزيد حول استخدام دفاتر ملاحظات AWS Glue Studio وCodeWhisperer، راجع ما يلي الفيديو.
عن المؤلفين
 ايشان جور يعمل كمهندس أول لسحابة البيانات الكبيرة (ETL) متخصص في AWS Glue. إنه متحمس لمساعدة العملاء على إنشاء أعباء عمل ETL موزعة وقابلة للتطوير وخطوط أنابيب التحليلات على AWS.
ايشان جور يعمل كمهندس أول لسحابة البيانات الكبيرة (ETL) متخصص في AWS Glue. إنه متحمس لمساعدة العملاء على إنشاء أعباء عمل ETL موزعة وقابلة للتطوير وخطوط أنابيب التحليلات على AWS.
 عمر الخربوتلي هو Glue SME الذي يعمل كمهندس دعم Big Data Cloud 2 (DIST). وهو مكرس لمساعدة العملاء في حل المشكلات المتعلقة بأعباء عمل ETL الخاصة بهم وإنشاء خطوط أنابيب قابلة للتطوير لمعالجة البيانات والتحليلات على AWS.
عمر الخربوتلي هو Glue SME الذي يعمل كمهندس دعم Big Data Cloud 2 (DIST). وهو مكرس لمساعدة العملاء في حل المشكلات المتعلقة بأعباء عمل ETL الخاصة بهم وإنشاء خطوط أنابيب قابلة للتطوير لمعالجة البيانات والتحليلات على AWS.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- BlockOffsets. تحديث ملكية الأوفست البيئية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/explore-real-world-use-cases-for-amazon-codewhisperer-powered-by-aws-glue-studio-notebooks/

