المُقدّمة
في عالم التكنولوجيا الذي يتقدم باستمرار اليوم، هناك تطور مثير في الأفق - الذكاء الاصطناعي التوليدي المتقدم متعدد الوسائط. تهدف هذه التكنولوجيا المتطورة إلى جعل أجهزة الكمبيوتر أكثر ابتكارًا ورائعة، وإنشاء المحتوى والفهم. تخيل مساعدًا رقميًا يعمل بسلاسة مع النصوص والصور والأصوات ويولد المعلومات. في هذه المقالة، سنلقي نظرة على كيفية عمل هذه التقنية في تطبيقاتها وأمثلة الوقت الحقيقي/العملية، كما سنقدم مقتطفات تعليمات برمجية مبسطة لجعلها متاحة ومفهومة. لذلك، دعونا نتعمق ونستكشف عالم الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم.

في الأقسام التالية، سنكشف عن الوحدات الأساسية للذكاء الاصطناعي متعدد الوسائط، بدءًا من الإدخال ووصولاً إلى الاندماج والإخراج، وسنكتسب فهمًا أوضح لكيفية تعاونهم لجعل هذه التكنولوجيا تعمل بسلاسة. بالإضافة إلى ذلك، سنستكشف أمثلة التعليمات البرمجية العملية التي توضح قدراتها وحالات الاستخدام الواقعية. الوسائط المتعددة المتقدمة الذكاء الاصطناعي التوليدي هي قفزة نحو عصر رقمي أكثر تفاعلية وإبداعًا وكفاءة حيث تفهمنا الآلات وتتواصل معنا بطرق تخيلناها.
أهداف التعلم
- افهم أساسيات الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم بعبارات بسيطة.
- اكتشف كيفية عمل الذكاء الاصطناعي متعدد الوسائط من خلال وحدات الإدخال والدمج والإخراج.
- احصل على رؤى حول الأعمال الداخلية للذكاء الاصطناعي متعدد الوسائط من خلال أمثلة التعليمات البرمجية العملية.
- اكتشاف التطبيقات الواقعية للذكاء الاصطناعي متعدد الوسائط مع حالات الاستخدام الواقعية.
- التمييز بين الذكاء الاصطناعي أحادي الوسائط ومتعدد الوسائط وإمكانياتهما.
- تعمق في هذه الأمور عند نشر الذكاء الاصطناعي متعدد الوسائط في سيناريوهات العالم الحقيقي.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
فهم الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم
تخيل أن لديك صديقًا آليًا، روبي، ذكي بشكل لا يصدق ويمكنه فهمك بعدة طرق مختلفة. عندما تريد أن تحكي لروبي قصة مضحكة عن يومك على الشاطئ، يمكنك اختيار التحدث إليه، أو رسم لوحة فنية/صورة، أو حتى إظهار صورة له. ومن ثم يصبح روبي قادرًا على فهم/الحصول على كلماتك وصورك والمزيد. هذه القدرة على الفهم واستخدام طرق مختلفة للتواصل والفهم هي جوهر "الوسائط المتعددة".
كيف يعمل الذكاء الاصطناعي متعدد الوسائط؟
تم تصميم الذكاء الاصطناعي متعدد الوسائط لفهم وإنشاء المحتوى في أوضاع بيانات مختلفة مثل النص والصور والصوت. ويحقق ذلك من خلال ثلاث وحدات رئيسية.

- وحدة الإدخال
- وحدة الانصهار
- وحدة الانتاج
دعونا نتعمق في هذه الوحدات لفهم كيفية عمل الذكاء الاصطناعي المتعدد الوسائط.
وحدة الإدخال
تشبه وحدة الإدخال الباب الذي يتم فيه إدخال أنواع مختلفة من البيانات. وإليك ما يفعله:
- بيانات النص: فهو ينظر إلى الكلمات والعبارات وكيفية ارتباطها بالجمل، مثل فهم اللغة.
- بيانات الصورة: فهو يتحقق من الصور ويكتشف ما بداخلها، مثل الأشياء أو المشاهد أو الأنماط.
- بيانات الصوت: فهو يستمع إلى الأصوات ويحولها إلى كلمات حتى يتمكن الذكاء الاصطناعي من فهمها.
تأخذ وحدة الإدخال كل هذه البيانات وتحولها إلى لغة يستطيع الذكاء الاصطناعي فهمها. فهو يعثر على العناصر المهمة ويجهزها للخطوة التالية.
وحدة الانصهار
وحدة الاندماج هي المكان الذي تجتمع فيه الأشياء معًا.
- دمج النص والصورة: فهو يجمع الكلمات والصور. وهذا يساعدنا على فهم المصطلحات وما هو موجود في الصور، مما يجعل كل شيء منطقيًا.
- دمج النص والصوت: مع الأصوات يشكل الكلمات. ويساعد ذلك في التقاط أشياء مثل الطريقة التي يتحدث بها شخص ما أو الحالة المزاجية، والتي تفتقدها بمجرد الصوت.
- دمج الصورة والصوت: يربط هذا الجزء ما تراه بما تسمعه. إنه مفيد لوصف ما يحدث أو جعل أشياء مثل مقاطع الفيديو أكثر استرخاءً.
تعمل وحدة Fusion Module على تجميع كل هذه المعلومات معًا وتسهيل الحصول عليها.
وحدة الانتاج
تشبه وحدة الإخراج جزء التحدث مرة أخرى. يقول أشياء بناءً على ما تعلمه. إليك الطريقة:
- توليد النص: يستخدم الكلمات لتكوين الجمل، بدءًا من الإجابة على الأسئلة وحتى تأليف قصص رائعة.
- إنشاء الصورة: فهو يصنع صورًا تتطابق مع ما يحدث، مثل المشاهد أو الأشياء.
- توليد الكلام: إنه يتحدث باستخدام الكلمات ويبدو وكأنه شخص طبيعي، لذلك من السهل فهمه.
تضمن وحدة الإخراج أن تكون إجابات الذكاء الاصطناعي دقيقة ومنطقية مع ما تسمعه.
باختصار، يجمع الذكاء الاصطناعي المتعدد الوسائط البيانات من أماكن مختلفة في وحدة الإدخال، ويحصل على الصورة الكبيرة في وحدة الاندماج، ويقول الأشياء التي تتناسب مع ما تعلمته في وحدة الإخراج. وهذا يساعد الذكاء الاصطناعي على فهمنا والتحدث إلينا بشكل أفضل، بغض النظر عن البيانات التي يحصل عليها.
# Import the Multimodal AI library
from multimodal_ai import MultimodalAI # Initialize the Multimodal AI model
model = MultimodalAI() # Input data for each modality
text_data = "A cat chasing a ball."
image_data = load_image("cat_chasing_ball.jpg")
audio_data = load_audio("cat_sound.wav") # Process each modality separately
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Combine information from different modalities
combined_embedding = model.combine_modalities(text_embedding, image_embedding, audio_embedding) # Generate a response based on the combined information
response = model.generate_response(combined_embedding) # Print the generated response
print(response)
يوضح هذا الكود كيف يمكن للذكاء الاصطناعي المتعدد الوسائط معالجة المعلومات ودمجها من العديد من الأساليب المختلفة لتوليد استجابة ذات معنى. إنه مثال مبسط لمساعدتك على فهم المفهوم دون تعقيد غير ضروري.
العمل الداخلي
هل أنت فضولي لفهم الأعمال الداخلية؟ دعونا نلقي نظرة على قطاعات مختلفة منه:

المدخلات المتعددة الوسائط
يمكن أن تكون المدخلات نصًا أو صورًا أو صوتًا، أو حتى هذه النماذج يمكنها قبول مجموعة من هذه العناصر. ويتم تحقيق ذلك من خلال معالجة كل طريقة من خلال شبكات فرعية مخصصة مع السماح بالتفاعلات فيما بينها.
from multimodal_generative_ai import MultiModalModel # Initialize a Multi-Modal Model
model = MultiModalModel() # Input data in the form of text, image, and audio
text_data = "A beautiful sunset at the beach."
image_data = load_image("beach_sunset.jpg")
audio_data = load_audio("ocean_waves.wav") # Process each modality through dedicated sub-networks
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Allow interactions between modalities
output = model.generate_multi_modal_output(text_embedding, image_embedding, audio_embedding)في هذا الكود، قمنا بتطوير نموذج متعدد الوسائط قادر على التعامل مع المدخلات المتنوعة مثل النص والصور والصوت.
التفاهم عبر الوسائط
إحدى السمات الرئيسية هي قدرة النموذج على فهم العلاقات بين الطرائق المختلفة. على سبيل المثال، يمكنه وصف صورة بناءً على وصف نصي أو إنشاء صور ذات صلة من تنسيق نص.
from multimodal_generative_ai import CrossModalModel # Initialize a Cross-Modal Model
model = CrossModalModel() # Input textual description and image
description = "A cabin in the snowy woods."
image_data = load_image("snowy_cabin.jpg") # Generating text based on the image
generated_text = model.generate_text_from_image(image_data)
generated_image = model.generate_image_from_text(description)في هذا الكود، نعمل مع نموذج متعدد الوسائط يتفوق في فهم وإنشاء المحتوى عبر طرائق مختلفة. كما يمكن وصف صورة بناءً على إدخال نصي مثل "مقصورة في الغابة الثلجية". وبدلاً من ذلك، يمكنه إنشاء صورة من وصف نصي، مما يجعله أداة مهمة جدًا لمهام مثل التعليق على الصورة أو إنشاء المحتوى.
الوعي السياقي
تتفوق أنظمة الذكاء الاصطناعي هذه في التقاط السياق. إنهم يفهمون الفروق الدقيقة ويمكنهم إنشاء محتوى ذي صلة بالسياق. يعد هذا الوعي السياقي ثمينًا في إنشاء المحتوى ومهام أنظمة التوصية.
from multimodal_generative_ai import ContextualModel # Initialize a Contextual Model
model = ContextualModel() # Input contextual data
context = "In a bustling city street, people rush to respective homes." # Generate contextually relevant content
generated_content = model.generate_contextual_content(context)يعرض هذا الرمز نموذجًا سياقيًا مصممًا لالتقاط السياق بشكل فعال. يتطلب الأمر مدخلات مثل السياق = "في أحد شوارع المدينة المزدحمة، يهرع الناس إلى منازلهم." ويقوم بإنشاء محتوى يتوافق مع السياق المقدم. تعد هذه القدرة على إنتاج محتوى ذي صلة بالسياق مفيدة في مهام مثل إنشاء المحتوى وأنظمة التوصية، حيث يكون فهم السياق أمرًا بالغ الأهمية لتوليد الاستجابات المناسبة.
بيانات التدريب
يجب أن تتطلب هذه النماذج بيانات تدريب متعددة الوسائط ويجب أن تكون بيانات التدريب ثقيلة وأكثر. يتضمن ذلك النص المقترن بالصور، والصوت المقترن بالفيديو، ومجموعات أخرى، مما يسمح للنموذج بتعلم تمثيلات ذات معنى عبر الوسائط.
from multimodal_generative_ai import MultiModalTrainer # Initialize a Multi-Modal Trainer
trainer = MultiModalTrainer() # Load multimodal training data (text paired with images, audio paired with video, etc.)
training_data = load_multi_modal_data() # Train the Multi-Modal Model
model = trainer.train_model(training_data)يعرض هذا المثال الرمزي مدربًا متعدد الوسائط يسهل تدريب النموذج متعدد الوسائط باستخدام بيانات التدريب المتنوعة.
تطبيقات العالم الحقيقي
يحتاج الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم إلى كمية كبيرة ويساعد في العديد من الاستخدامات العملية في العديد من المجالات المختلفة. دعنا نستكشف بعض الأمثلة البسيطة لكيفية تطبيق هذه التقنية، بالإضافة إلى مقتطفات التعليمات البرمجية والشروحات.
جيل المحتوى
تخيل نظامًا يمكنه إنشاء محتوى مثل المقالات والصور وحتى الصوت بناءً على وصف مختصر. يمكن أن يغير هذا قواعد اللعبة في إنتاج المحتوى والإعلان والصناعات الإبداعية. إليك مقتطف التعليمات البرمجية:
from multimodal_generative_ai import ContentGenerator # Initialize the Content Generator
generator = ContentGenerator() # Input a description
description = "A beautiful sunset at the beach." # Generate content
generated_text = generator.generate_text(description)
generated_image = generator.generate_image(description)
generated_audio = generator.generate_audio(description)في هذا المثال، يأخذ منشئ المحتوى وصفًا كمدخل ويقوم بإنشاء نص وصور ومحتوى صوتي مرتبط بهذا الوصف.
الرعاية الصحية المساعدة
في مجال الرعاية الصحية، يمكن للذكاء الاصطناعي متعدد الوسائط تحليل بيانات المريض السابقة والحالية، بما في ذلك النصوص والصور الطبية والملاحظات الصوتية ومجموعة من هذه الثلاثة. ويمكن أن يساعد في تشخيص الأمراض، ووضع خطط العلاج، وحتى التنبؤ بالنتائج المستقبلية للمريض من خلال أخذ جميع البيانات ذات الصلة.
from multimodal_generative_ai import HealthcareAssistant # Initialize the Healthcare Assistant
assistant = HealthcareAssistant() # Input a patient record
patient_record = { "text": "Patient complains of persistent cough and fatigue.", "images": ["xray1.jpg", "mri_scan.jpg"], "audio_notes": ["heartbeat.wav", "breathing_pattern.wav"]
} # Analyze the patient record
diagnosis = assistant.diagnose(patient_record)
treatment_plan = assistant.create_treatment_plan(patient_record)
predicted_outcome = assistant.predict_outcome(patient_record)يوضح هذا الرمز كيف يمكن لمساعد الرعاية الصحية معالجة سجل المريض، والجمع بين النصوص والصور والصوت للمساعدة في التشخيص الطبي وتخطيط العلاج.
روبوتات الدردشة التفاعلية
أصبحت Chatbots أكثر جاذبية وإفادة بفضل إمكانات الذكاء الاصطناعي متعدد الوسائط. يمكنهم فهم كل من النصوص والصور، مما يجعل التفاعل مع المستخدمين أكثر طبيعية وفعالية. إليك مقتطف التعليمات البرمجية:
from multimodal_generative_ai import Chatbot # Initialize the Chatbot
chatbot = Chatbot() # User input
user_message = "Show me images of cute cats." # Engage with the user
response = chatbot.interact(user_message)يوضح هذا الرمز كيف يمكن لـ Chatbot، المدعوم بالذكاء الاصطناعي متعدد الوسائط، الاستجابة بشكل فعال لإدخال المستخدم الذي يتضمن طلبات النص والصور.
المحتوى الاعتدال
يمكن للذكاء الاصطناعي متعدد الوسائط تحسين اكتشاف المحتوى غير المناسب والإشراف عليه على منصات الإنترنت من خلال تحليل العناصر النصية والعناصر المرئية أو السمعية. إليك مقتطف التعليمات البرمجية:
from multimodal_generative_ai import ContentModerator # Initialize the Content Moderator
moderator = ContentModerator() # User-generated content
user_content = { "text": "Inappropriate text message.", "image": "inappropriate_image.jpg", "audio": "offensive_audio.wav"
} # Moderate the user-generated content
moderated = moderator.moderate_content(user_content)في هذا المثال، يمكن لمشرف المحتوى تحليل المحتوى الذي ينشئه المستخدم، مما يضمن بيئة أكثر أمانًا عبر الإنترنت من خلال مراعاة جميع الأساليب المتعددة.
توضح هذه الأمثلة العملية التطبيقات الواقعية للذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم. تتمتع هذه التكنولوجيا بإمكانيات في العديد من الصناعات من خلال فهم وإنشاء المحتوى عبر أنماط مختلفة من البيانات.
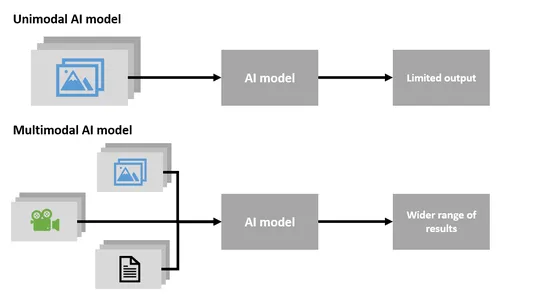
أحادية الوسائط مقابل الوسائط المتعددة

الذكاء الاصطناعي متعدد الوسائط
- يعد الذكاء الاصطناعي متعدد الوسائط تقنية فريدة ومهمة جدًا يمكنها التعامل مع أنواع مختلفة من البيانات في وقت واحد، بما في ذلك النصوص والصور والصوت.
- إنه يتفوق في فهم وإنشاء المحتوى الذي يجمع بين أنواع البيانات المتنوعة هذه.
- يمكن للذكاء الاصطناعي متعدد الوسائط إنشاء نص بناءً على الصور أو إنشاء صور من أوصاف النص، مما يجعله قابلاً للتكيف بدرجة كبيرة.
- هذه التكنولوجيا قادرة على معالجة وفهم مجموعة واسعة من المعلومات.
الذكاء الاصطناعي أحادي الوسائط
- يتخصص الذكاء الاصطناعي أحادي الوسائط في العمل مع نوع واحد فقط من البيانات، مثل النص أو الصور.
- ولا يمكنه التعامل مع أنواع بيانات متعددة في وقت واحد أو إنشاء محتوى يجمع بين طرائق مختلفة.
- يقتصر الذكاء الاصطناعي أحادي الوسائط على نوع البيانات المحدد ويفتقر إلى القدرة على التكيف مع الذكاء الاصطناعي متعدد الوسائط.
باختصار، يمكن للذكاء الاصطناعي متعدد الوسائط العمل مع أنواع متعددة من البيانات في وقت واحد، مما يجعله أكثر تنوعًا وقدرة على فهم وإنشاء المحتوى بطرق مختلفة. من ناحية أخرى، يتخصص الذكاء الاصطناعي أحادي الوسائط في نوع بيانات واحد ولا يمكنه التعامل مع تنوع الذكاء الاصطناعي متعدد الوسائط.
الاعتبارات الأخلاقية
مخاوف الخصوصية
- ضمان التعامل السليم مع بيانات المستخدم الحساسة، وخاصة في تطبيقات الرعاية الصحية.
- تنفيذ تقنيات قوية لتشفير البيانات وإخفاء الهوية لحماية خصوصية المستخدم.
التحيز والإنصاف
- معالجة التحيزات المحتملة في بيانات التدريب لمنع النتائج غير العادلة.
- قم بمراجعة النموذج وتحديثه بانتظام لتقليل التحيزات في إنشاء المحتوى.
المحتوى الاعتدال
- انشر الإشراف الفعال على المحتوى لتصفية المحتوى غير المناسب أو الضار الناتج عن الذكاء الاصطناعي.
- وضع مبادئ توجيهية وسياسات واضحة للمستخدمين للالتزام بالمعايير الأخلاقية.
الشفافية
- اجعل المحتوى الذي ينشئه الذكاء الاصطناعي مميزًا عن المحتوى الذي ينشئه الإنسان للحفاظ على الشفافية.
- توفير معلومات واضحة للمستخدمين حول مشاركة الذكاء الاصطناعي في إنشاء المحتوى.
المساءلة
- تحديد المسؤوليات المتعلقة باستخدام ونشر الذكاء الاصطناعي متعدد الوسائط، مع ضمان المساءلة عن أفعاله.
- إنشاء آليات لمعالجة المشكلات أو الأخطاء التي قد تنشأ عن المحتوى الناتج عن الذكاء الاصطناعي.
الموافقة المستنيرة
- اطلب موافقة المستخدم عند جمع بياناته واستخدامها للتدريب وتحسين نموذج الذكاء الاصطناعي.
- قم بتوصيل كيفية استخدام بيانات المستخدم بوضوح لبناء الثقة مع المستخدمين.
إمكانية الوصول
- تأكد من أن المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي متاح للمستخدمين ذوي الإعاقة من خلال الالتزام بمعايير إمكانية الوصول.
- تنفيذ ميزات مثل قارئات الشاشة للمستخدمين ضعاف البصر.
المراقبة المستمرة
- مراقبة المحتوى الناتج عن الذكاء الاصطناعي بانتظام للتأكد من امتثاله للمبادئ التوجيهية الأخلاقية.
- تكييف نموذج الذكاء الاصطناعي وتحسينه ليتوافق مع المعايير الأخلاقية المتطورة.
تعتبر هذه الاعتبارات الأخلاقية ضرورية للتطوير المسؤول ونشر الذكاء الاصطناعي المتقدم متعدد الوسائط، مما يضمن أنه يفيد المجتمع مع الحفاظ على المعايير الأخلاقية وحقوق المستخدم.
وفي الختام
بينما نتنقل في المشهد المعقد للتكنولوجيا الحديثة، يلوح الأفق بتطور رائع: الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم. تعد هذه التكنولوجيا الرائدة بإحداث ثورة في الطريقة التي تنتج بها أجهزة الكمبيوتر المحتوى وفهم عالمنا متعدد الأوجه. تصور مساعدًا رقميًا يعمل بسلاسة مع النصوص والصور والأصوات، ويتواصل بلغات متعددة وصياغة محتوى مبتكر. آمل أن يأخذك هذا المقال في رحلة عبر تعقيدات الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم، واستكشاف تطبيقاته العملية، ومقتطفات التعليمات البرمجية من أجل الوضوح، وقدرته على إعادة تشكيل تفاعلاتنا الرقمية.
"الذكاء الاصطناعي متعدد الوسائط هو الجسر الذي يساعد أجهزة الكمبيوتر على فهم ومعالجة النصوص والصور والصوت، مما يحدث ثورة في كيفية تفاعلنا مع الآلات."
الوجبات السريعة الرئيسية
- يعد الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم بمثابة تغيير جذري في التكنولوجيا، حيث يمكّن أجهزة الكمبيوتر من فهم وإنشاء المحتوى عبر النصوص والصور والصوت.
- تعمل الوحدات الأساسية الثلاث، الإدخال، والانصهار، والإخراج، معًا بسلاسة لمعالجة المعلومات وتوليدها بشكل فعال.
- يمكن للذكاء الاصطناعي متعدد الوسائط العثور على تطبيقات في مجال إنشاء المحتوى، والمساعدة في الرعاية الصحية، وروبوتات الدردشة التفاعلية، والإشراف على المحتوى، مما يجعله متعدد الاستخدامات وعمليًا.
- يعد الفهم متعدد الوسائط والوعي السياقي وبيانات التدريب المكثفة من الجوانب المحورية التي تعزز قدراتها.
- يتمتع الذكاء الاصطناعي متعدد الوسائط بالقدرة على إحداث ثورة في الصناعات من خلال تقديم طريقة جديدة للتفاعل مع الآلات وإنشاء محتوى أكثر إبداعًا.
- تعمل قدرتها على الجمع بين أوضاع البيانات المتعددة على تعزيز قدرتها على التكيف وسهولة الاستخدام في العالم الحقيقي.
الأسئلة المتكررة
ج: يتميز الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم بقدرته على فهم وإنشاء المحتوى باستخدام أنواع مختلفة من البيانات، مثل النصوص والصور والصوت، بينما يركز الذكاء الاصطناعي التقليدي غالبًا على نوع واحد من البيانات.
ج: يتميز الذكاء الاصطناعي التوليدي المتعدد الوسائط المتقدم بقدرته على فهم المحتوى وإنشاءه باستخدام أنواع بيانات متنوعة، بما في ذلك النصوص والصور والصوت، في حين يتخصص الذكاء الاصطناعي التقليدي عادةً في نوع بيانات واحد.
ج: يعمل الذكاء الاصطناعي متعدد الوسائط ببراعة بلغات متعددة من خلال معالجة النص وفهمه باللغة المطلوبة.
ج: نعم، الذكاء الاصطناعي متعدد الوسائط قادر على إنتاج محتوى إبداعي يعتمد على الأوصاف النصية أو المطالبات، بما في ذلك النص والصور والصوت.
ج. يوفر الذكاء الاصطناعي متعدد الوسائط فوائد عبر مجموعة واسعة من المجالات، بما في ذلك إنشاء المحتوى، والرعاية الصحية، وروبوتات الدردشة، والإشراف على المحتوى، وذلك نظرًا لكفاءته في فهم وإنشاء المحتوى عبر أوضاع البيانات المتنوعة.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/10/exploring-the-advanced-multi-modal-generative-ai/

