نظرًا لأن المؤسسات تقوم بجمع كميات متزايدة من البيانات من مصادر مختلفة، فغالبًا ما يحتاج هيكل تلك البيانات وتنظيمها إلى التغيير بمرور الوقت لتلبية الاحتياجات التحليلية المتطورة. ومع ذلك، قد يكون تغيير أقسام المخطط والجدول في بحيرات البيانات التقليدية مهمة مزعجة وتستغرق وقتًا طويلاً، مما يتطلب إعادة تسمية أو إعادة إنشاء الجداول بأكملها وإعادة معالجة مجموعات البيانات الكبيرة. وهذا يعيق خفة الحركة والوقت للبصيرة.
يتيح تطور المخطط إضافة الأعمدة أو حذفها أو إعادة تسميتها أو تعديلها دون الحاجة إلى إعادة كتابة البيانات الموجودة. يعد هذا أمرًا بالغ الأهمية للمؤسسات سريعة الحركة لزيادة هياكل البيانات لدعم حالات الاستخدام الجديدة. على سبيل المثال، قد تقوم شركة التجارة الإلكترونية بإضافة سمات ديموغرافية جديدة للعملاء أو علامات حالة الطلب لإثراء التحليلات. اباتشي فيض يدير تغييرات المخطط هذه بطريقة متوافقة مع الإصدارات السابقة من خلال بنية تطور جدول البيانات الوصفية المبتكرة.
وبالمثل، يسمح تطور الأقسام بإضافة الأقسام أو إسقاطها أو تقسيمها بسلاسة. على سبيل المثال، قد يقوم سوق التجارة الإلكترونية في البداية بتقسيم بيانات الطلب حسب اليوم. عندما تتراكم الطلبات، ويصبح الاستعلام اليومي غير فعال، فقد تنقسم إلى قسم اليوم وقسم معرف العميل. يقوم تقسيم الجدول بتنظيم مجموعات البيانات الكبيرة بكفاءة أكبر لأداء الاستعلام. يمنح Iceberg المؤسسات المرونة اللازمة لضبط الأقسام بشكل متزايد بدلاً من المطالبة بإجراءات إعادة البناء المملة. يمكن إضافة أقسام جديدة بطريقة متوافقة تمامًا دون توقف أو الحاجة إلى إعادة كتابة ملفات البيانات الموجودة.
يوضح هذا المنشور كيف يمكنك تسخير Iceberg، خدمة تخزين أمازون البسيطة (Amazon S3) ، غراء AWS, تكوين بحيرة AWSو إدارة الهوية والوصول AWS (IAM) لتنفيذ بحيرة بيانات المعاملات التي تدعم التطور السلس. من خلال السماح بإجراء تعديلات غير مؤلمة على المخططات والأقسام مع تطور رؤى البيانات، يمكنك الاستفادة من المرونة المستقبلية اللازمة لنجاح الأعمال.
نظرة عامة على الحل
في مثالنا لحالة الاستخدام، تقوم شركة تجارة إلكترونية كبيرة خيالية بمعالجة آلاف الطلبات كل يوم. عند استلام الطلبات أو تحديثها أو إلغائها أو شحنها أو تسليمها أو إرجاعها، يتم إجراء التغييرات في نظامها المحلي، ويجب نسخ هذه التغييرات إلى بحيرة بيانات S3 حتى يتمكن محللو البيانات من تشغيل الاستعلامات من خلال أمازون أثينا. يمكن أن تحتوي التغييرات على تحديثات المخطط أيضًا. نظرًا للمتطلبات الأمنية للمؤسسات المختلفة، فإنها تحتاج إلى إدارة التحكم الدقيق في الوصول للمحللين من خلال Lake Formation.
يوضح الرسم البياني التالي بنية الحل.
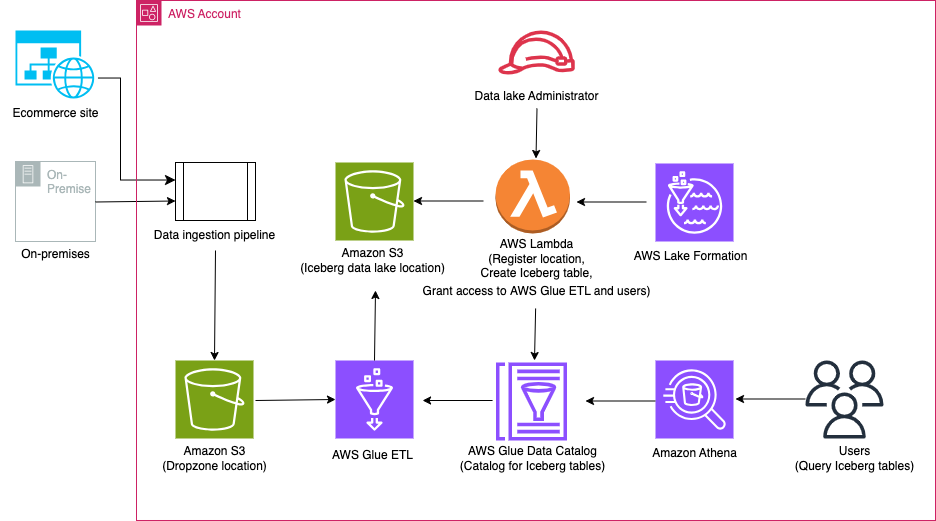
يتضمن سير عمل الحل الخطوات الأساسية التالية:
- استوعب البيانات من مكان العمل إلى موقع Dropzone باستخدام مسار استيعاب البيانات.
- قم بدمج البيانات من موقع Dropzone في Iceberg باستخدام AWS Glue.
- الاستعلام عن البيانات باستخدام أثينا.
المتطلبات الأساسية المسبقة
في هذا الدليل ، يجب أن يكون لديك المتطلبات الأساسية التالية:
قم بإعداد البنية التحتية باستخدام AWS CloudFormation
لإنشاء البنية التحتية الخاصة بك باستخدام تكوين سحابة AWS القالب، أكمل الخطوات التالية:
- قم بتسجيل الدخول كمسؤول إلى حساب AWS الخاص بك.
- افتح وحدة تحكم AWS CloudFormation.
- اختار قم بتشغيل Stack:

- في حالة اسم المكدس، أدخل اسمًا (لهذا المنشور، Icebergdemo1).
- اختار التالى.
- توفير معلومات عن المعلمات التالية:
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- اختار التالى.
- اختار التالي مرة أخرى.
- في مجلة التقيم القسم، قم بمراجعة القيم التي أدخلتها.
- أختار أقر بأن AWS CloudFormation قد تنشئ موارد IAM بأسماء مخصصة واختر تقدم.
في غضون دقائق قليلة، ستتغير حالة المكدس إلى CREATE_COMPLETE.
يمكنك الذهاب إلى علامة التبويب "المخرجات". من المكدس لرؤية كافة الموارد التي تم توفيرها. الموارد مسبوقة باسم المكدس الذي قدمته (لهذا المنشور، icebergdemo1).
قم بإنشاء جدول Iceberg باستخدام Lambda ومنح حق الوصول باستخدام Lake Formation
لإنشاء جدول Iceberg ومنح حق الوصول إليه، أكمل الخطوات التالية:
- انتقل إلى الموارد علامة التبويب الخاصة بمكدس CloudFormation Icebergdemo1 وابحث عن المعرف المنطقي المسمى
LambdaFunctionIceberg. - اختر الارتباط التشعبي للمعرف الفعلي المرتبط.
ستتم إعادة توجيهك إلى وظيفة Lambda icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- على الاعداد علامة التبويب، اختر متغيرات البيئة في الجزء الأيمن.

- على رمز علامة التبويب، يمكنك فحص رمز الوظيفة.
تستخدم الدالة AWS SDK لـ Python (Boto3) واجهات برمجة التطبيقات لتوفير الموارد. ويتولى دور مسؤول بحيرة البيانات المتوفر لتنفيذ المهام التالية:
- منحة DATA_LOCATION_ACCESS الوصول إلى دور مسؤول بحيرة البيانات في موقع بحيرة البيانات المسجل
- إنشاء علامات تشكيل البحيرة (علامات LF)
- أنشئ قاعدة بيانات في كتالوج بيانات AWS Glue باستخدام AWS Glue create_database API
- تعيين علامات LF لقاعدة البيانات
- امنح الوصول إلى DESCRIBE إلى قاعدة البيانات باستخدام علامات LF لمستخدم IAM لمستودع البيانات ودور AWS Glue ETL IAM
- قم بإنشاء جدول Iceberg باستخدام AWS Glue اصنع جدول API:
- قم بتعيين علامات LF إلى الجدول
- قم بمنح الوصف والتحديد في جدول Iceberg LF-Tags لمستخدم IAM لبحيرة البيانات
- منح الوصول ALL، وDESCRIBE، وSELECT، وINSERT، وDELETE، وALTER في جدول Iceberg LF-Tags إلى دور AWS Glue ETL IAM
- على اختبار علامة التبويب، اختر اختبار لتشغيل الوظيفة.

عند اكتمال الوظيفة، ستظهر لك الرسالة "جاري تنفيذ الوظيفة: نجح".
تساعدك Lake Formation على إدارة البيانات مركزيًا وتأمينها ومشاركتها عالميًا للتحليلات والتعلم الآلي. باستخدام Lake Formation، يمكنك إدارة التحكم الدقيق في الوصول لبيانات مستودع البيانات الخاصة بك على Amazon S3 وبيانات التعريف الخاصة به في كتالوج البيانات.
لإضافة موقع Amazon S3 كمخزن Iceberg في مستودع البيانات الخاص بك، تسجيل الموقع مع تكوين البحيرة. يمكنك بعد ذلك استخدام أذونات Lake Formation للتحكم الدقيق في الوصول إلى كائنات كتالوج البيانات التي تشير إلى هذا الموقع، وإلى البيانات الأساسية في الموقع.
قام مكدس CloudFormation بتسجيل موقع بحيرة البيانات.

أذونات موقع البيانات في Lake Formation، يمكّن مديري المدارس من إنشاء وتغيير موارد كتالوج البيانات التي تشير إلى مواقع Amazon S3 المسجلة والمحددة. تعمل أذونات موقع البيانات بالإضافة إلى Lake Formation أذونات البيانات لتأمين المعلومات في بحيرة البيانات الخاصة بك.
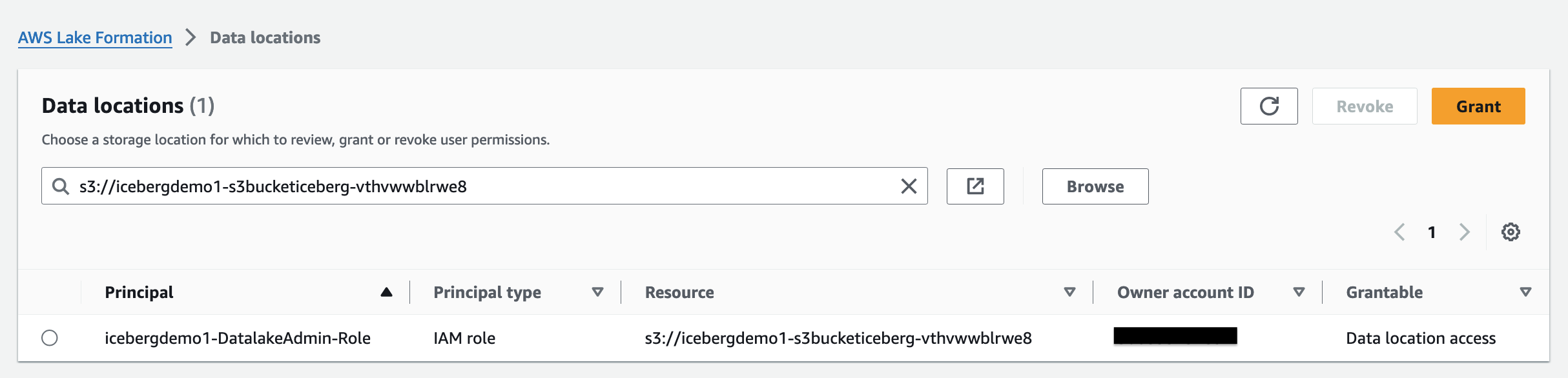
التحكم في الوصول المستند إلى علامة Lake Formation (LF-TBAC) هي استراتيجية ترخيص تحدد الأذونات بناءً على السمات. في تكوين البحيرة، تسمى هذه السمات علامات LF. يمكنك إرفاق علامات LF بموارد كتالوج البيانات ومبادئ Lake Formation وأعمدة الجدول. يمكنك تعيين وإلغاء الأذونات على موارد Lake Formation باستخدام علامات LF هذه. يسمح Lake Formation بالعمليات على تلك الموارد عندما تتطابق علامة المدير مع علامة المورد.
تحقق من جدول Iceberg من وحدة تحكم Lake Formation
للتحقق من جدول Iceberg، أكمل الخطوات التالية:
- في وحدة التحكم Lake Formation ، اختر قواعد بيانات في جزء التنقل.
- افتح صفحة التفاصيل الخاصة بـ
icebergdb1.
يمكنك رؤية قاعدة البيانات المرتبطة LF-Tags.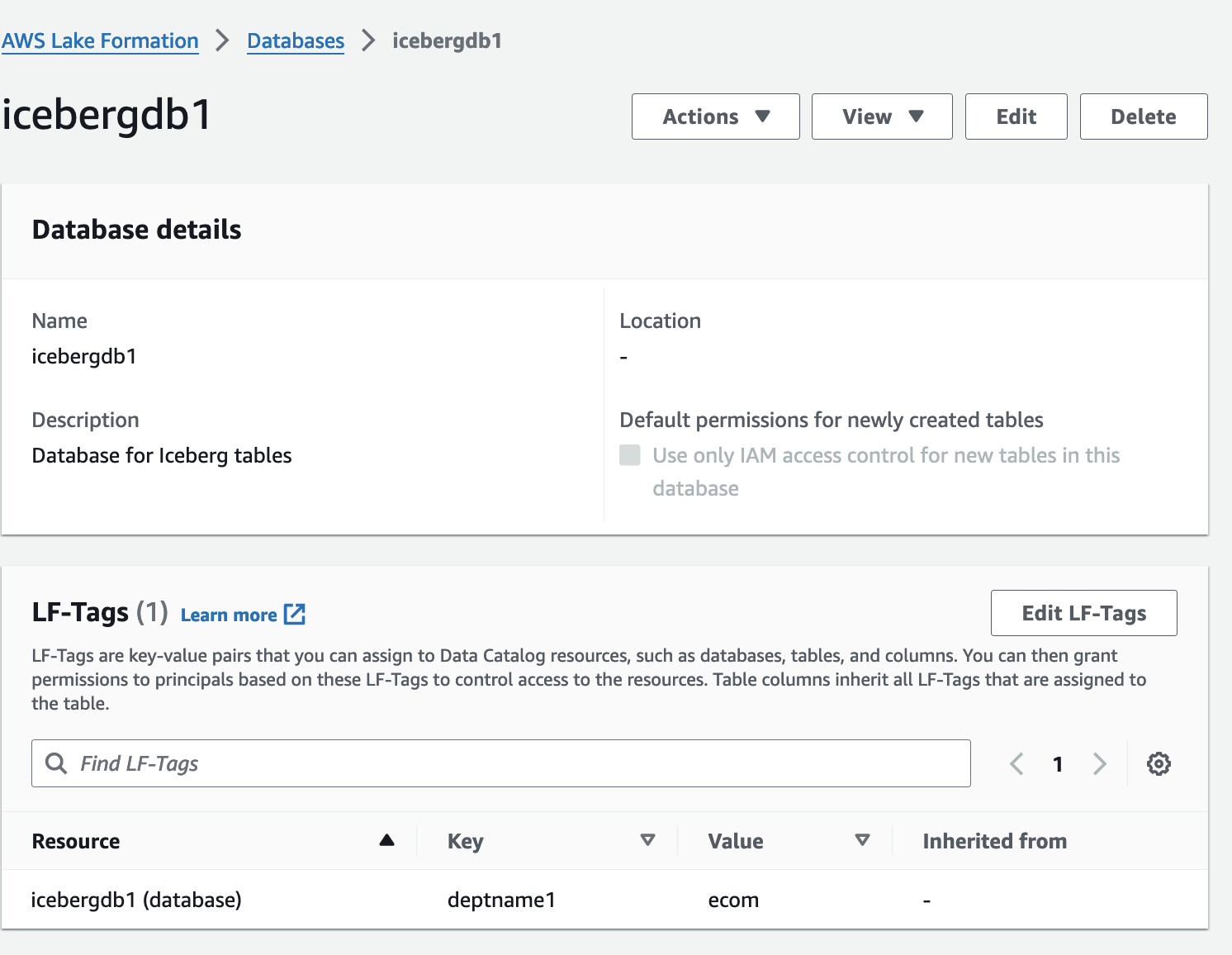
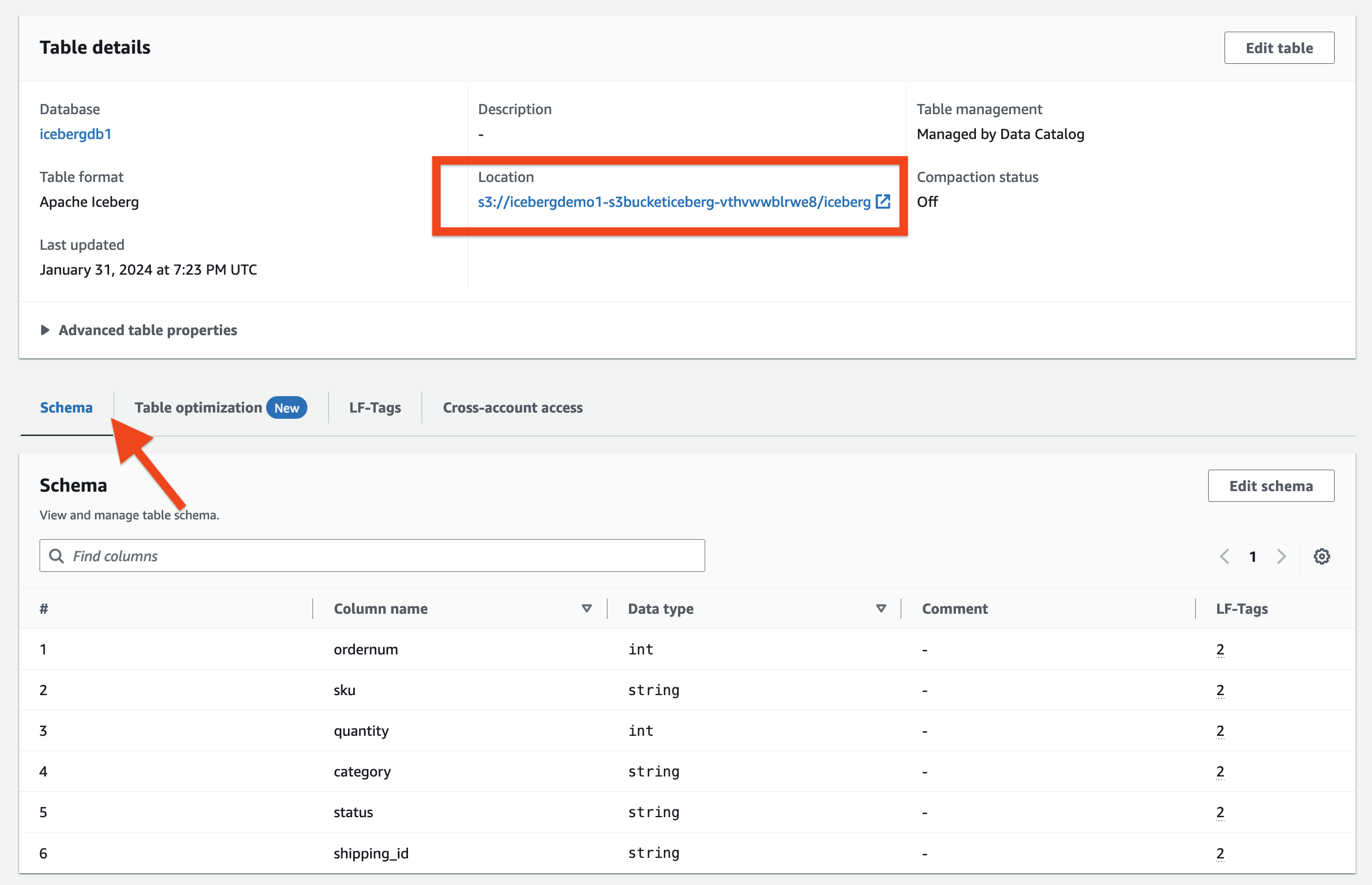
- اختار طاولات الطعام في جزء التنقل.
- افتح صفحة التفاصيل الخاصة بـ
ecomorders.
في مجلة تفاصيل الجدول القسم، يمكنك ملاحظة ما يلي:
- تنسيق الجدول يظهر على شكل اباتشي فيض
- إدارة الجدول يظهر على شكل تدار بواسطة كتالوج البيانات
- الموقع الجغرافي يسرد موقع بحيرة البيانات لجدول Iceberg
في مجلة LF- العلامات القسم، يمكنك رؤية الجدول المرتبط LF-Tags.
في مجلة تفاصيل الجدول قسم ، توسيع خصائص الجدول المتقدمة لعرض ما يلي:
metadata_locationيشير إلى موقع ملف البيانات التعريفية لجدول Icebergtable_typeيظهر على شكلICEBERG
على مخطط علامة التبويب، يمكنك عرض الأعمدة المحددة في جدول Iceberg.
قم بدمج Iceberg مع AWS Glue Data Catalog وAmazon S3
يتتبع Iceberg ملفات البيانات الفردية في جدول بدلاً من الدلائل. عندما يكون هناك التزام صريح على الطاولة، يقوم Iceberg بإنشاء ملفات بيانات وإضافتها إلى الجدول. يحافظ Iceberg على حالة الجدول في ملفات البيانات التعريفية. يؤدي أي تغيير في حالة الجدول إلى إنشاء ملف بيانات تعريف جديد يحل محل البيانات التعريفية القديمة تلقائيًا. تقوم ملفات البيانات التعريفية بتتبع مخطط الجدول وتكوين التقسيم والخصائص الأخرى.
يتطلب Iceberg أن تكون أنظمة الملفات التي تدعم العمليات متوافقة مع مخازن الكائنات مثل Amazon S3.
يقوم Iceberg بإنشاء لقطات لمحتويات الجدول. كل لقطة هي مجموعة كاملة من ملفات البيانات في الجدول في وقت ما. يتم تخزين ملفات البيانات في اللقطات في واحد أو أكثر من ملفات البيان التي تحتوي على صف لكل ملف بيانات في الجدول وبيانات القسم الخاصة به ومقاييسه.
ويوضح الرسم البياني التالي هذا التسلسل الهرمي.
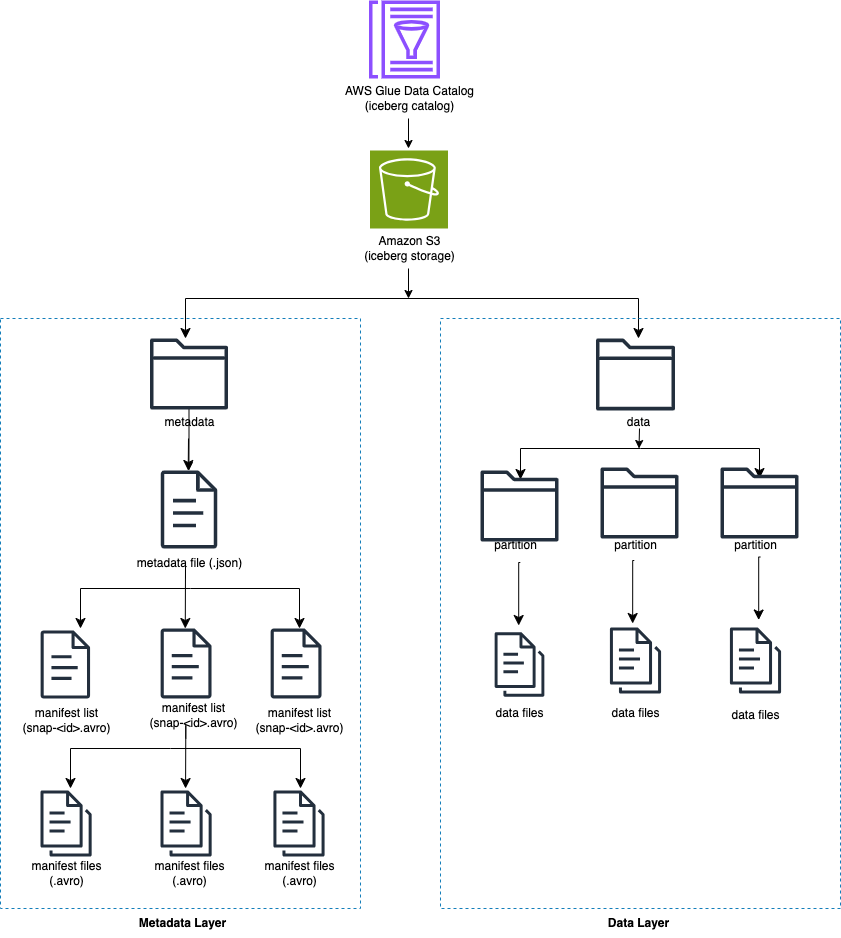
عندما تقوم بإنشاء جدول Iceberg، فإنه يقوم بإنشاء مجلد البيانات التعريفية أولاً وملف البيانات التعريفية في مجلد البيانات التعريفية. يتم إنشاء مجلد البيانات عند تحميل البيانات إلى جدول Iceberg.

محتويات ملف البيانات التعريفية Iceberg
يحتوي ملف البيانات التعريفية Iceberg على الكثير من المعلومات، بما في ذلك ما يلي:
- نسخة التنسيق -نسخة من جدول جبل الجليد
- الموقع الجغرافي - موقع Amazon S3 للجدول
- المخططات - اسم ونوع البيانات لجميع الأعمدة في الجدول
- مواصفات التقسيم - أعمدة مقسمة
- أوامر الفرز - ترتيب الأعمدة
- HAS – خصائص الجدول
- معرف اللقطة الحالية - لقطة الحالية
- الحكام - مراجع الجدول
- لقطات - قائمة اللقطات، تحتوي كل منها على المعلومات التالية:
- رقم التسلسل – العدد التسلسلي للقطات بالترتيب الزمني (أعلى رقم يمثل اللقطة الحالية، 1 لللقطة الأولى)
- معرف اللقطة - معرف اللقطة
- الطابع الزمني مللي ثانية - الطابع الزمني الذي تم فيه التقاط اللقطة
- ملخص – ملخص التغييرات المرتكبة
- قائمة البيان - قائمة البيانات؛ يبدأ اسم الملف هذا بـ snap-< snapshot-id >
- معرف المخطط – الرقم التسلسلي للمخطط بالترتيب الزمني (أعلى رقم يمثل المخطط الحالي)
- سجل لقطة – قائمة اللقطات بالترتيب الزمني
- سجل البيانات الوصفية – قائمة ملفات البيانات الوصفية بالترتيب الزمني
يحتوي ملف البيانات التعريفية على كافة التغييرات التاريخية التي تم إجراؤها على بيانات الجدول ومخططه. قد تكون مراجعة محتويات ملف التعريف مباشرةً مهمة تستغرق وقتًا طويلاً. ولحسن الحظ، يمكنك الاستعلام عن البيانات الوصفية لجبل الجليد باستخدام أثينا.
إطار Iceberg في AWS Glue
يدعم AWS Glue 4.0 جداول Iceberg المسجلة لدى Lake Formation. في وظائف AWS Glue ETL، تحتاج إلى الكود التالي للقيام بذلك تمكين إطار جبل الجليد:
للوصول للقراءة/الكتابة إلى البيانات الأساسية، بالإضافة إلى أذونات Lake Formation، تم منح دور AWS Glue IAM لتشغيل مهام AWS Glue ETL تكوين البحيرة: GetDataAccess إذن الوصول. وبهذا الإذن، تمنح Lake Formation طلب الحصول على بيانات اعتماد مؤقتة للوصول إلى البيانات.
قامت مجموعة CloudFormation بتوفير وظائف AWS Glue ETL الأربع لك. يبدأ اسم كل مهمة باسم المكدس الخاص بك (icebergdemo1). أكمل الخطوات التالية لعرض الوظائف:
- قم بتسجيل الدخول كمسؤول إلى حساب AWS الخاص بك.
- في وحدة تحكم AWS Glue ، اختر وظائف ETL في جزء التنقل.
- ابحث عن وظائف مع
icebergdemo1باسم.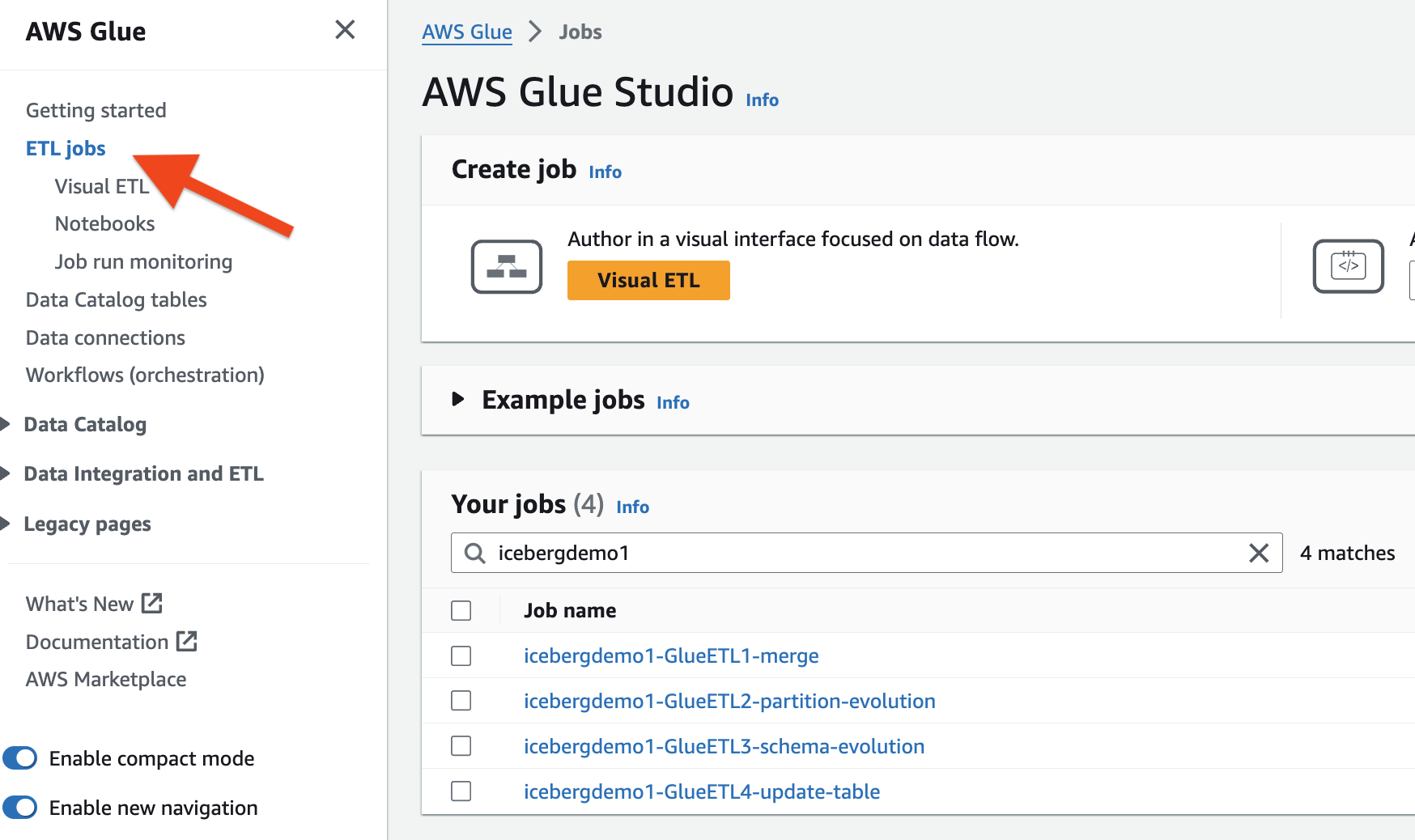
دمج البيانات من Dropzone في جدول Iceberg
بالنسبة لحالة الاستخدام الخاصة بنا، تقوم الشركة بإدخال بيانات طلبات التجارة الإلكترونية الخاصة بها يوميًا من موقعها الداخلي إلى موقع Amazon S3 Dropzone. قام مكدس CloudFormation بتحميل ثلاثة ملفات مع نماذج أوامر لمدة 3 أيام، كما هو موضح في الأشكال التالية. ترى البيانات في موقع Dropzone s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
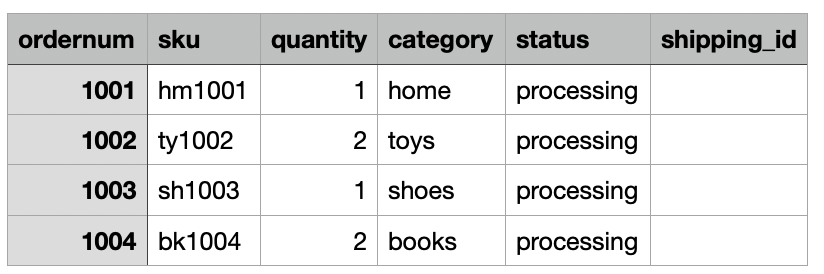


وظيفة AWS Glue ETL icebergdemo1-GlueETL1-merge سيتم تشغيله يوميًا لدمج البيانات في جدول Iceberg. يحتوي على المنطق التالي لإضافة أو تحديث البيانات على Iceberg:
- قم بإنشاء Spark DataFrame من البيانات المدخلة:
- لطلب جديد، قم بإضافته إلى الجدول
- إذا كان الجدول يحتوي على ترتيب مطابق، فقم بتحديث الحالة و
shipping_id:
أكمل الخطوات التالية لتشغيل مهمة دمج AWS Glue:
- في وحدة تحكم AWS Glue ، اختر وظائف ETL في جزء التنقل.
- حدد وظيفة ETL
icebergdemo1-GlueETL1-merge. - على الإجراءات القائمة المنسدلة، اختر تشغيل مع المعلمات.
- على تشغيل المعلمات الصفحة ، انتقل إلى معلمات الوظيفة.
- بالنسبة
--dropzone_pathالمعلمة، قم بتوفير موقع S3 لبيانات الإدخال (icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - قم بتشغيل المهمة لإضافة كافة الأوامر: 1001، 1002، 1003، و1004.
- بالنسبة
--dropzone_path parameter، قم بتغيير موقع S3 إلىicebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - قم بتشغيل المهمة مرة أخرى لإضافة الأوامر 2001 و2002، وتحديث الأوامر 1001، و1002، و1003.
- بالنسبة
--dropzone_pathالمعلمة، قم بتغيير موقع S3 إلىicebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - قم بتشغيل المهمة مرة أخرى لإضافة الأمر 3001 وتحديث الأوامر 1001 و1003 و2001 و2002.
انتقل إلى مجلد البيانات بالجدول لرؤية ملفات البيانات التي كتبها Iceberg عندما قمت بدمج البيانات في الجدول باستخدام مهمة Glue ETL icebergdemo1-GlueETL1-merge.

الاستعلام عن Iceberg باستخدام Athena
قام مكدس CloudFormation بإنشاء مستخدم IAM Iceberguser1، الذي لديه حق الوصول للقراءة على جدول Iceberg باستخدام LF-Tags. للاستعلام عن Iceberg باستخدام Athena عبر هذا المستخدم، أكمل الخطوات التالية:
- سجل دخول
iceberguser1إلى وحدة تحكم إدارة AWS. - في وحدة تحكم أثينا ، اختر مجموعات العمل في جزء التنقل.
- حدد موقع مجموعة العمل التي قام CloudFormation بتوفيرها (
icebergdemo1-workgroup) - التحقق من إصدار محرك أثينا 3.
يدعم إصدار محرك أثينا 3 تنسيقات ملفات جبل الجليد، بما في ذلك الباركيه، وORC، وأفرو.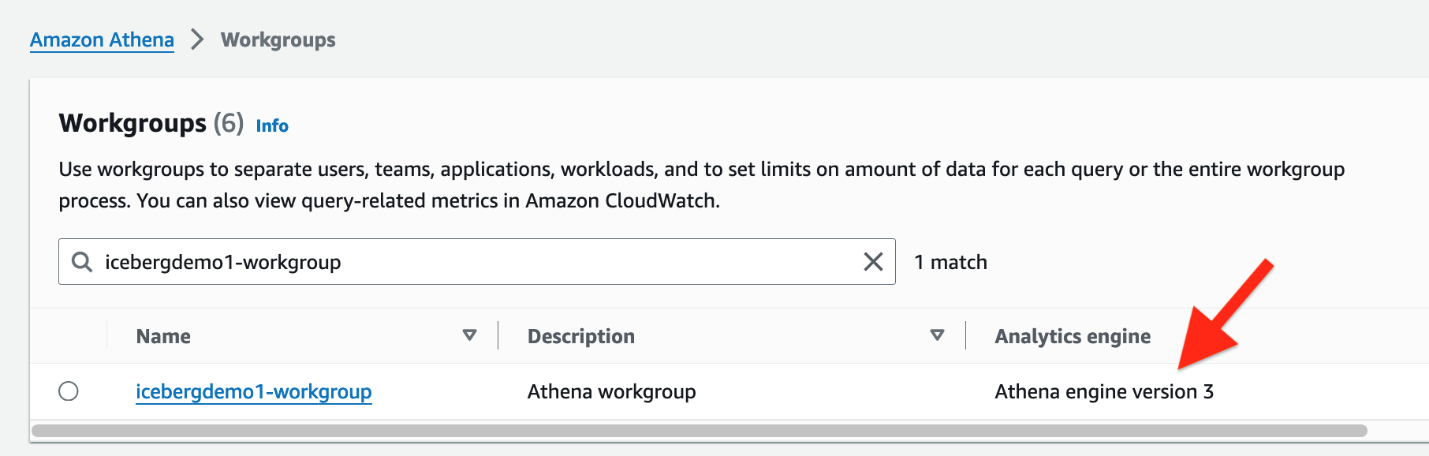
- انتقل إلى محرر استعلام أثينا.
- اختر مجموعة العمل Icebergdemo1-workgroup من القائمة المنسدلة.
- في حالة قاعدة البيانات، اختر
icebergdb1. سترى الجدولecomorders. - قم بتشغيل الاستعلام التالي لرؤية البيانات في جدول Iceberg:
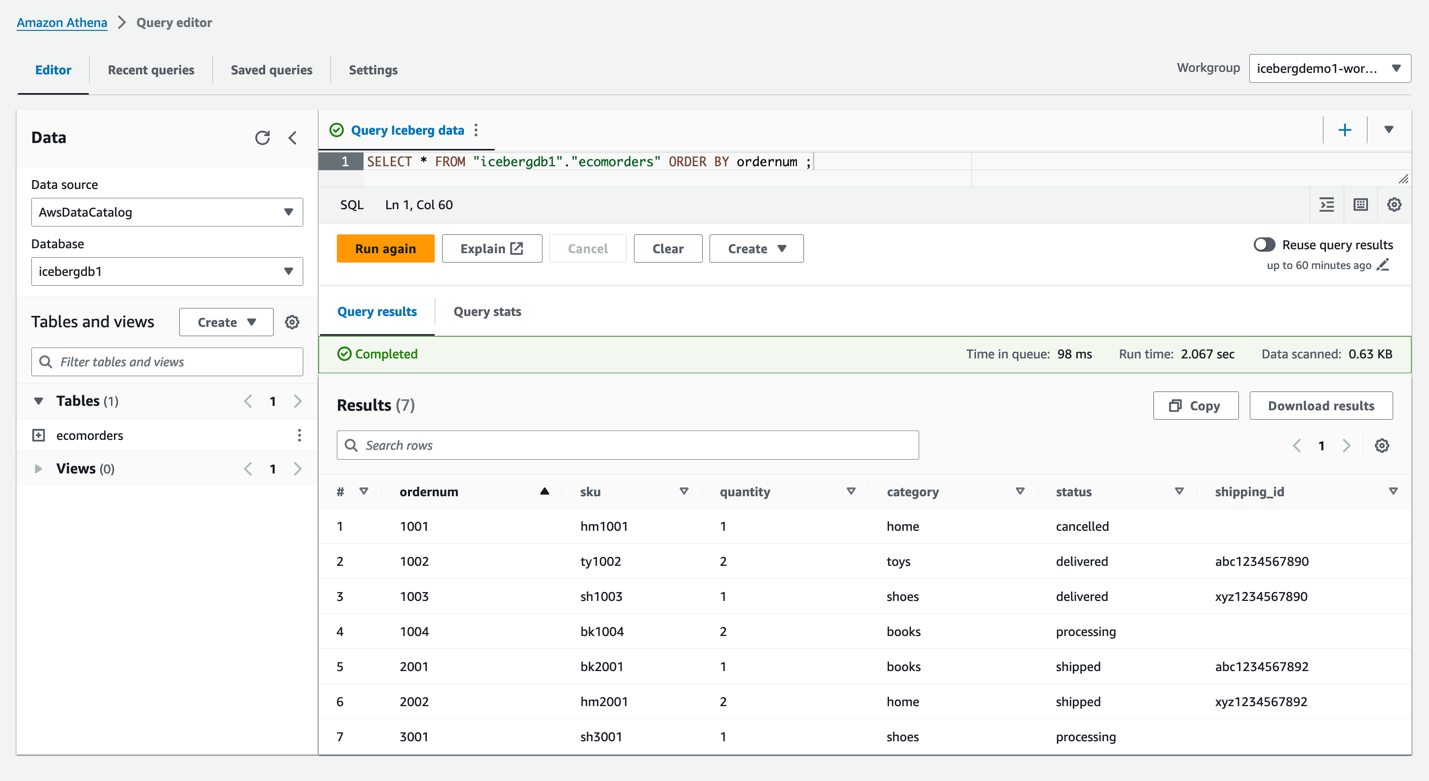
- قم بتشغيل الاستعلام التالي لرؤية أقسام الجدول الحالية:
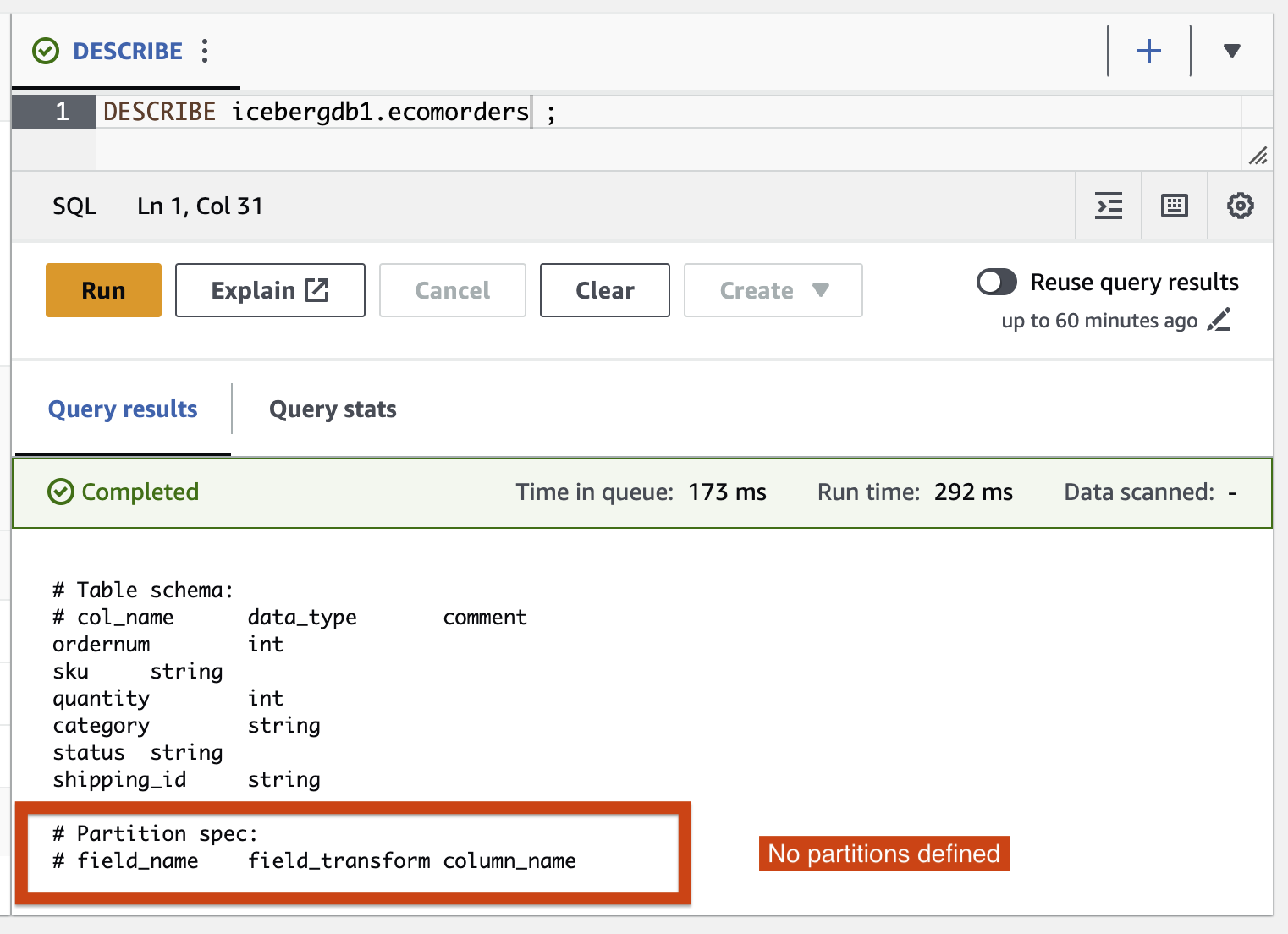
تصف مواصفات التقسيم كيفية تقسيم الجدول. في هذا المثال، لا توجد حقول مقسمة لأنك لم تحدد أي أقسام في الجدول.
تطور تقسيم جبل الجليد
قد تحتاج إلى تغيير بنية القسم الخاص بك؛ على سبيل المثال، بسبب تغيرات الاتجاه في أنماط الاستعلام الشائعة في التحليلات النهائية. يعد تغيير بنية الأقسام للجداول التقليدية عملية مهمة تتطلب نسخة كاملة من البيانات.
يجعل جبل الجليد هذا الأمر واضحًا ومباشرًا. عند تغيير بنية القسم على Iceberg، لا يتطلب الأمر إعادة كتابة ملفات البيانات. تظل البيانات القديمة المكتوبة باستخدام الأقسام السابقة دون تغيير. تتم كتابة البيانات الجديدة باستخدام المواصفات الجديدة في تخطيط جديد. يتم الاحتفاظ بالبيانات التعريفية لكل إصدار من إصدارات القسم بشكل منفصل.
لنقم بإضافة فئة حقل القسم إلى جدول Iceberg باستخدام مهمة AWS Glue ETL icebergdemo1-GlueETL2-partition-evolution:
على وحدة تحكم AWS Glue، قم بتشغيل مهمة ETL icebergdemo1-GlueETL2-partition-evolution. عند اكتمال المهمة، يمكنك الاستعلام عن الأقسام باستخدام Athena.
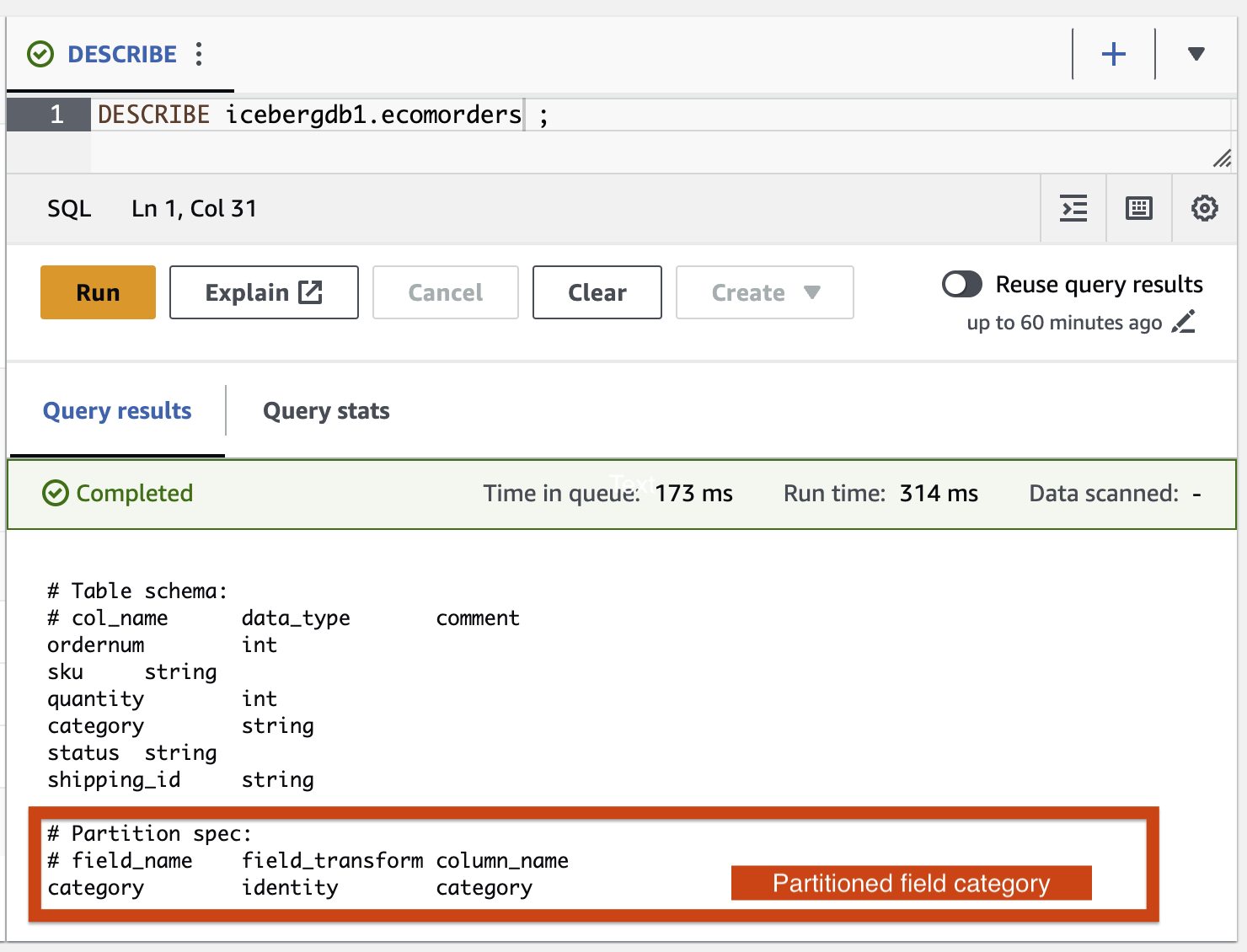
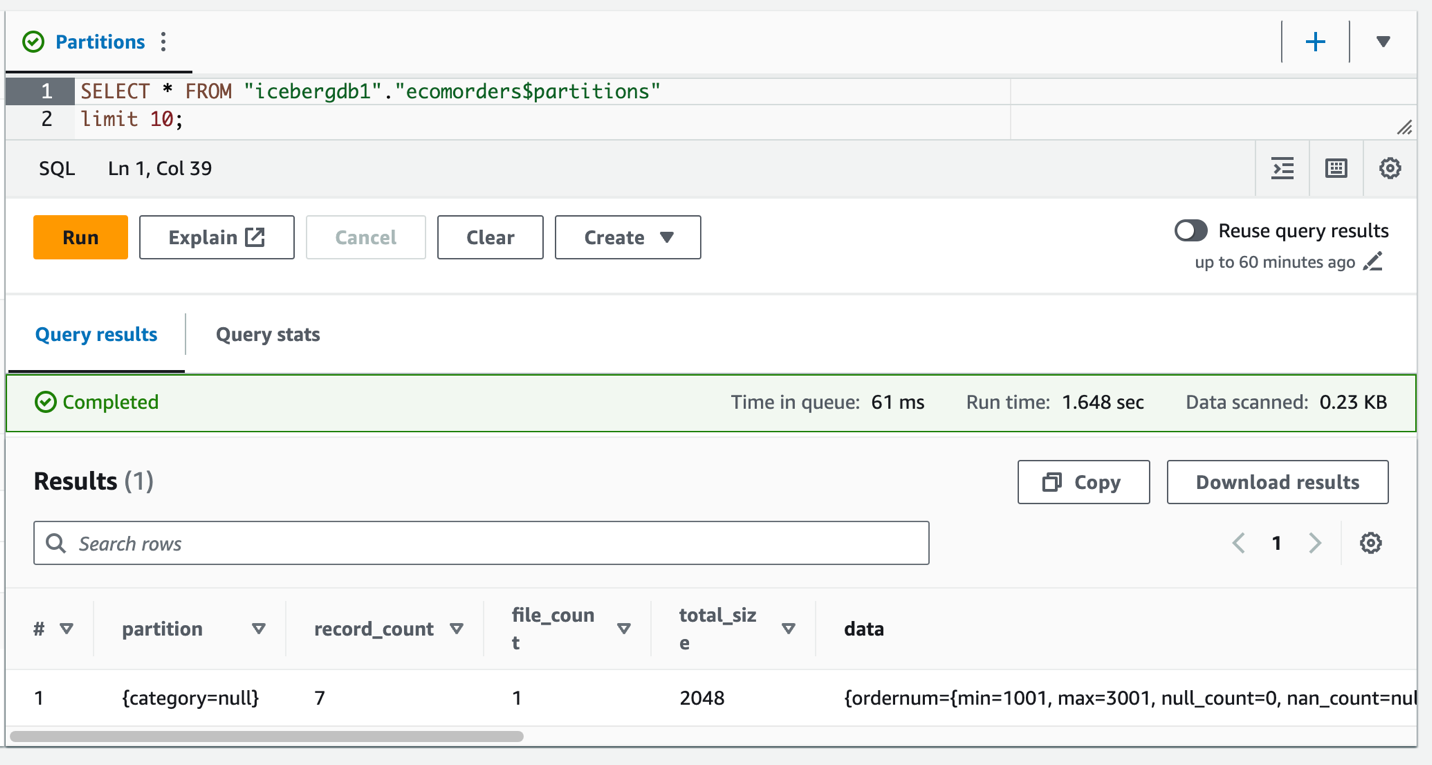
يمكنك رؤية فئة حقل القسم، لكن قيم القسم فارغة. لا توجد ملفات بيانات جديدة في مجلد البيانات، لأن تطور القسم هو عملية بيانات تعريف ولا يعيد كتابة ملفات البيانات. عند إضافة أو تحديث البيانات، سترى قيم القسم المقابلة التي تم ملؤها.
تطور مخطط جبل الجليد
يدعم Iceberg تطور الجدول في مكانه. أنت تستطيع تطوير مخطط الجدول تماما مثل SQL. تحديثات مخطط Iceberg عبارة عن تغييرات في البيانات التعريفية، لذلك لا يلزم إعادة كتابة ملفات البيانات لتنفيذ تطور المخطط.
لاستكشاف تطور مخطط Iceberg، قم بتشغيل مهمة ETL icebergdemo1-GlueETL3-schema-evolution عبر وحدة تحكم AWS Glue. تقوم المهمة بتشغيل عبارات SparkSQL التالية:
في محرر استعلام Athena، قم بتشغيل الاستعلام التالي:

يمكنك التحقق من تغييرات المخطط في جدول Iceberg:
- تمت إضافة عمود جديد يسمى
shipping_carrier - العمود
shipping_idتمت إعادة تسمية إلىtracking_number - نوع بيانات العمود
ordernumلقد تغير من int إلى bigint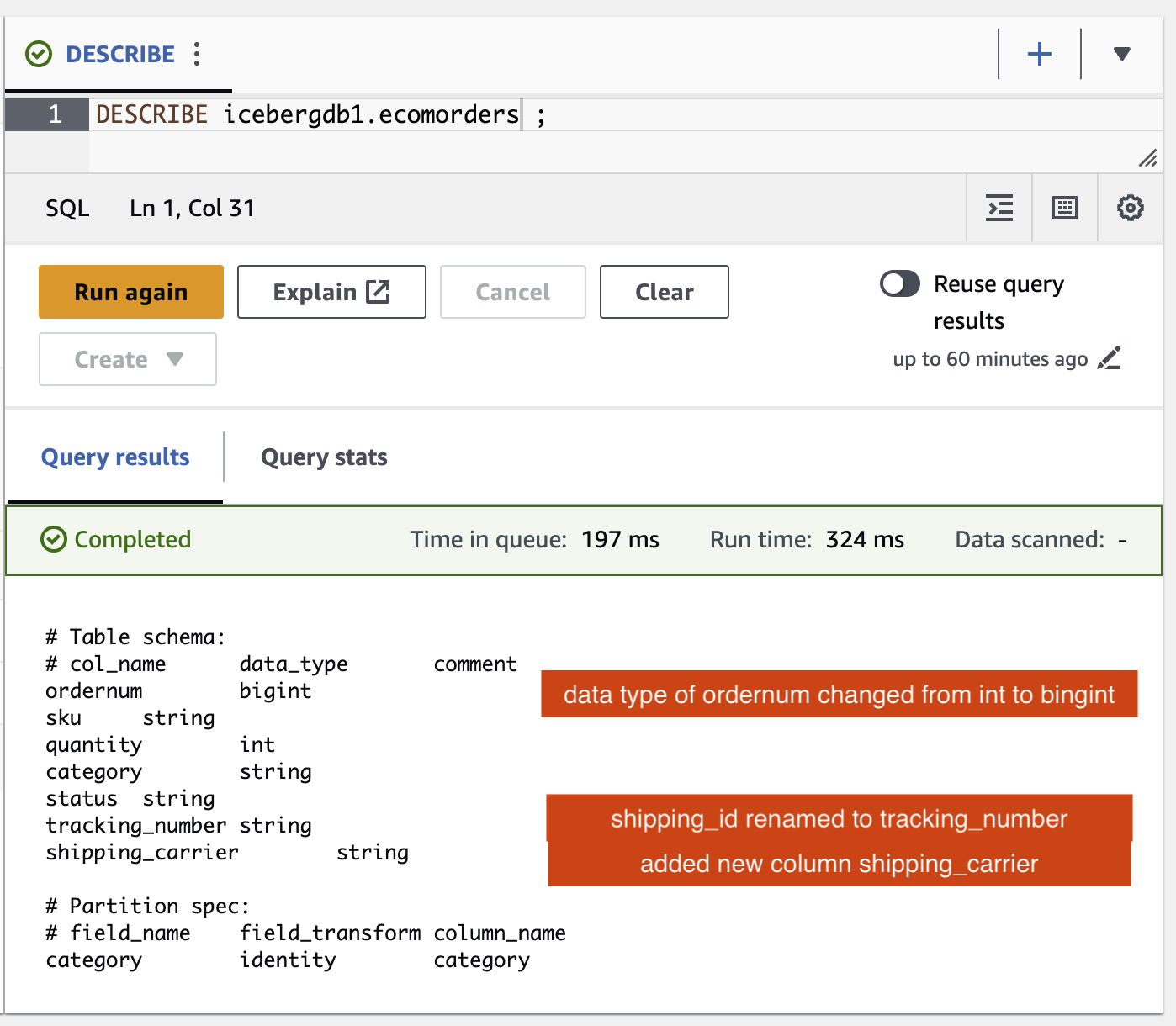
التحديث الموضعي
البيانات في tracking_number يحتوي على شركة الشحن المرتبطة برقم التتبع. لنفترض أننا نريد تقسيم هذه البيانات من أجل الحفاظ على شركة الشحن في shipping_carrier الحقل ورقم التتبع في tracking_number الميدان.
على وحدة تحكم AWS Glue، قم بتشغيل مهمة ETL icebergdemo1-GlueETL4-update-table. تقوم الوظيفة بتشغيل عبارة SparkSQL التالية لتحديث الجدول:
الاستعلام عن جدول Iceberg للتحقق من البيانات المحدثة tracking_number و shipping_carrier.
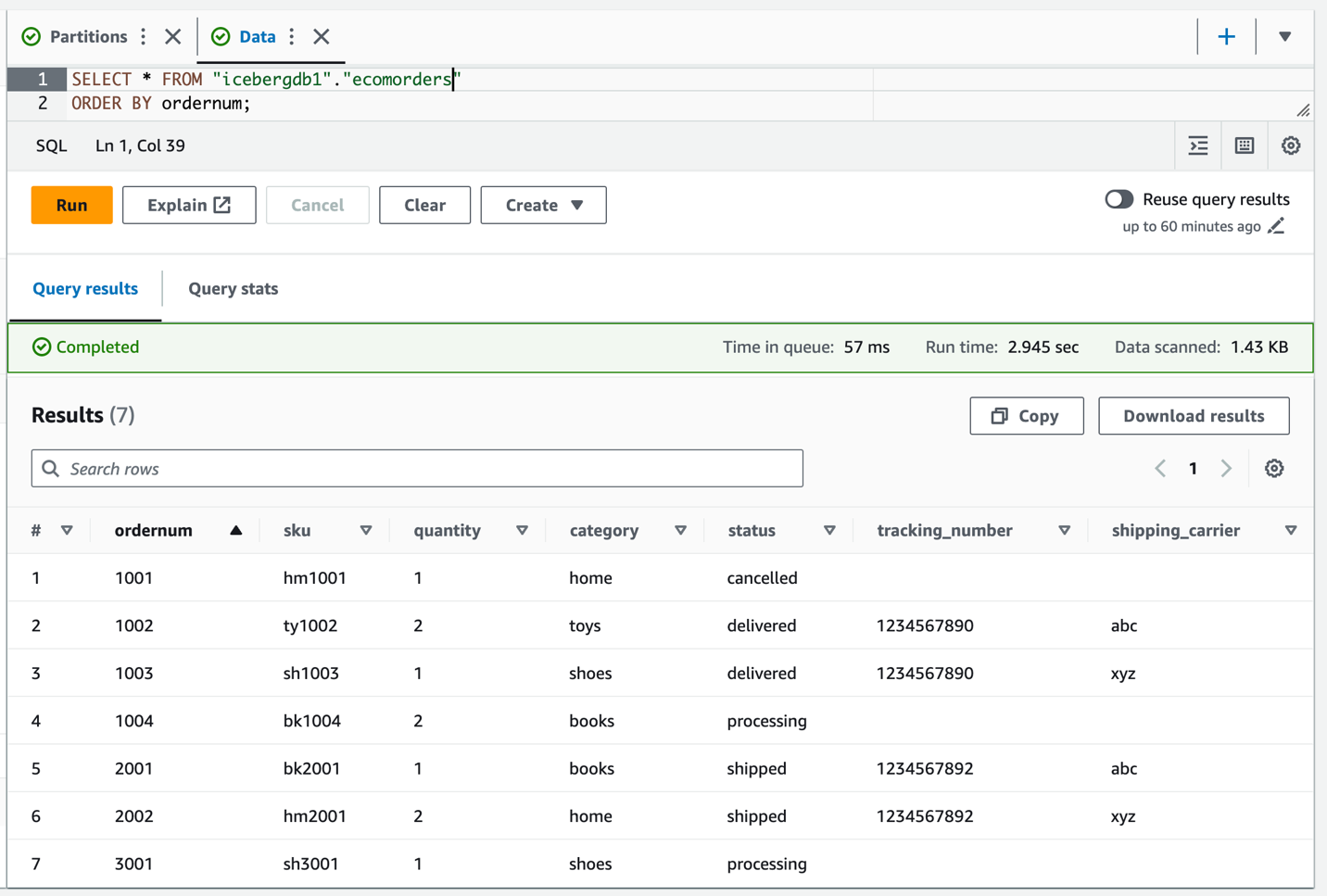
الآن بعد أن تم تحديث البيانات في الجدول، يجب أن تشاهد قيم القسم المملوءة للفئة:

تنظيف
لتجنب تكبد رسوم مستقبلية، قم بتنظيف الموارد التي قمت بإنشائها:
- في وحدة تحكم Lambda، افتح صفحة التفاصيل الخاصة بالوظيفة
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - في مجلة متغيرات البيئة القسم، اختر المفتاح
Task_To_Performوتحديث القيمة إلىCLEANUP. - قم بتشغيل الوظيفة، التي تقوم بإسقاط قاعدة البيانات والجدول وعلامات LF المرتبطة بهما.
- في وحدة تحكم AWS CloudFormation، احذف المكدس Icebergdemo1.
وفي الختام
في هذا المنشور، قمت بإنشاء جدول Iceberg باستخدام AWS Glue API واستخدمت Lake Formation للتحكم في الوصول إلى جدول Iceberg في مستودع بيانات المعاملات. باستخدام مهام AWS Glue ETL، يمكنك دمج البيانات في جدول Iceberg، وتنفيذ تطور المخطط وتطوير الأقسام دون إعادة كتابة جدول Iceberg أو إعادة إنشائه. مع Athena، قمت بالاستعلام عن بيانات Iceberg والبيانات الوصفية.
استنادًا إلى المفاهيم والعروض التوضيحية الواردة في هذا المنشور، يمكنك الآن إنشاء مستودع بيانات للمعاملات في مؤسسة باستخدام Iceberg وAWS Glue وLake Formation وAmazon S3.
عن المؤلف
 ساتيا أديمولا هو مهندس بيانات أول في AWS ومقرها في بوسطن. بفضل أكثر من عقدين من الخبرة في مجال البيانات والتحليلات، يساعد ساتيا المؤسسات على استخلاص رؤى الأعمال من بياناتها على نطاق واسع.
ساتيا أديمولا هو مهندس بيانات أول في AWS ومقرها في بوسطن. بفضل أكثر من عقدين من الخبرة في مجال البيانات والتحليلات، يساعد ساتيا المؤسسات على استخلاص رؤى الأعمال من بياناتها على نطاق واسع.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

