تمت كتابة هذا المنشور بالاشتراك مع أندريس إنجلبريشت وسكوت تيل من Snowflake.
تتطور الأعمال باستمرار، ويواجه قادة البيانات تحديات يومية لتلبية المتطلبات الجديدة. بالنسبة للعديد من المؤسسات والمؤسسات الكبيرة، ليس من الممكن أن يكون لديك محرك معالجة واحد أو أداة واحدة للتعامل مع متطلبات العمل المختلفة. إنهم يدركون أن النهج الواحد الذي يناسب الجميع لم يعد يعمل، ويدركون قيمة اعتماد أدوات مرنة وقابلة للتطوير وتنسيقات بيانات مفتوحة لدعم قابلية التشغيل البيني في بنية بيانات حديثة لتسريع تقديم حلول جديدة.
يستخدم العملاء AWS وSnowflake لتطوير بنيات البيانات المصممة لهذا الغرض والتي توفر الأداء المطلوب لحالات استخدام التحليلات الحديثة والذكاء الاصطناعي (AI). يتطلب تنفيذ هذه الحلول مشاركة البيانات بين مخازن البيانات المخصصة لهذا الغرض. ولهذا السبب تقدم Snowflake وAWS دعمًا محسنًا لـ Apache Iceberg لتمكين وتسهيل قابلية التشغيل البيني للبيانات بين خدمات البيانات.
Apache Iceberg هو تنسيق جدول مفتوح المصدر يوفر الموثوقية والبساطة والأداء العالي لمجموعات البيانات الكبيرة مع تكامل المعاملات بين محركات المعالجة المختلفة. في هذه التدوينة نناقش ما يلي:
- مزايا جداول Iceberg لبحيرات البيانات
- نمطان معماريان لمشاركة جداول Iceberg بين AWS وSnowflake:
- قم بإدارة طاولات Iceberg الخاصة بك باستخدام غراء AWS كتالوج البيانات
- قم بإدارة طاولات Iceberg الخاصة بك باستخدام Snowflake
- عملية تحويل جداول بحيرات البيانات الموجودة إلى جداول Iceberg دون نسخ البيانات
الآن بعد أن أصبح لديك فهم عالي المستوى للموضوعات، دعنا نتعمق في كل منها بالتفصيل.
مزايا جبل اباتشي الجليدي
Apache Iceberg هو تنسيق جدول بيانات مفتوح المصدر بنسبة 2.0% وموزع وموجه من قبل المجتمع ومرخص من Apache 100 ويساعد على تبسيط معالجة البيانات على مجموعات البيانات الكبيرة المخزنة في بحيرات البيانات. يستخدم مهندسو البيانات Apache Iceberg لأنه سريع وفعال وموثوق على أي نطاق ويحتفظ بسجلات لكيفية تغير مجموعات البيانات بمرور الوقت. يقدم Apache Iceberg عمليات تكامل مع أطر عمل معالجة البيانات الشائعة مثل Apache Spark وApache Flink وApache Hive وPresto والمزيد.
تحتفظ جداول Iceberg بالبيانات التعريفية لتجريد مجموعات كبيرة من الملفات، وتوفير ميزات إدارة البيانات بما في ذلك السفر عبر الزمن، والتراجع، وضغط البيانات، وتطور المخطط الكامل، مما يقلل من أعباء الإدارة. تم تطوير Apache Iceberg في الأصل في Netflix قبل أن يكون مفتوح المصدر لمؤسسة Apache Software Foundation، وكان Apache Iceberg عبارة عن تصميم فارغ لحل تحديات بحيرة البيانات الشائعة مثل تجربة المستخدم, الموثوقية والأداء، ويدعمه الآن مجتمع قوي من المطورين الذين يركزون على التحسين المستمر وإضافة ميزات جديدة إلى المشروع، مما يخدم احتياجات المستخدمين الحقيقية ويزودهم بالخيارات.
مستودعات بيانات المعاملات المبنية على AWS وSnowflake
توفر Snowflake العديد من عمليات التكامل لجداول Iceberg مع خيارات تخزين متعددة، بما في ذلك الأمازون S3، وخيارات كتالوج متعددة، بما في ذلك كتالوج بيانات AWS Glue و ندفة الثلج. توفر AWS عمليات تكامل لخدمات AWS المتنوعة مع جداول Iceberg أيضًا، بما في ذلك AWS Glue Data Catalog لتتبع البيانات التعريفية للجدول. يمنحك الجمع بين Snowflake وAWS خيارات متعددة لإنشاء مستودع بيانات للمعاملات لحالات الاستخدام التحليلية وغيرها مثل مشاركة البيانات والتعاون. من خلال إضافة طبقة بيانات التعريف إلى بحيرات البيانات، يمكنك الحصول على تجربة مستخدم أفضل وإدارة مبسطة وتحسين الأداء والموثوقية في مجموعات البيانات الكبيرة جدًا.
قم بإدارة جدول Iceberg الخاص بك باستخدام AWS Glue
يمكنك استخدام AWS Glue لاستيعاب البيانات وفهرستها وتحويلها وإدارتها خدمة تخزين أمازون البسيطة (أمازون إس 3). AWS Glue عبارة عن خدمة تكامل بيانات بدون خادم تتيح لك إنشاء خطوط أنابيب الاستخراج والتحويل والتحميل (ETL) وتشغيلها ومراقبتها بشكل مرئي لتحميل البيانات إلى مستودعات البيانات الخاصة بك بتنسيق Iceberg. باستخدام AWS Glue، يمكنك اكتشاف أكثر من 70 مصدرًا متنوعًا للبيانات والاتصال بها وإدارة بياناتك في كتالوج بيانات مركزي. يتكامل Snowflake مع كتالوج بيانات AWS Glue للوصول إلى كتالوج جدول Iceberg والملفات الموجودة على Amazon S3 للاستعلامات التحليلية. يؤدي هذا إلى تحسين الأداء وحساب التكلفة بشكل كبير مقارنةً بـ طاولات خارجية على Snowflakeلأن بيانات التعريف الإضافية تعمل على تحسين التنقيح في خطط الاستعلام.
يمكنك استخدام هذا التكامل نفسه للاستفادة من إمكانات مشاركة البيانات والتعاون في Snowflake. يمكن أن يكون هذا فعالاً للغاية إذا كانت لديك بيانات في Amazon S3 وتحتاج إلى تمكين مشاركة بيانات Snowflake مع وحدات الأعمال أو الشركاء أو الموردين أو العملاء الآخرين.
يوفر مخطط البنية التالي نظرة عامة عالية المستوى على هذا النمط.
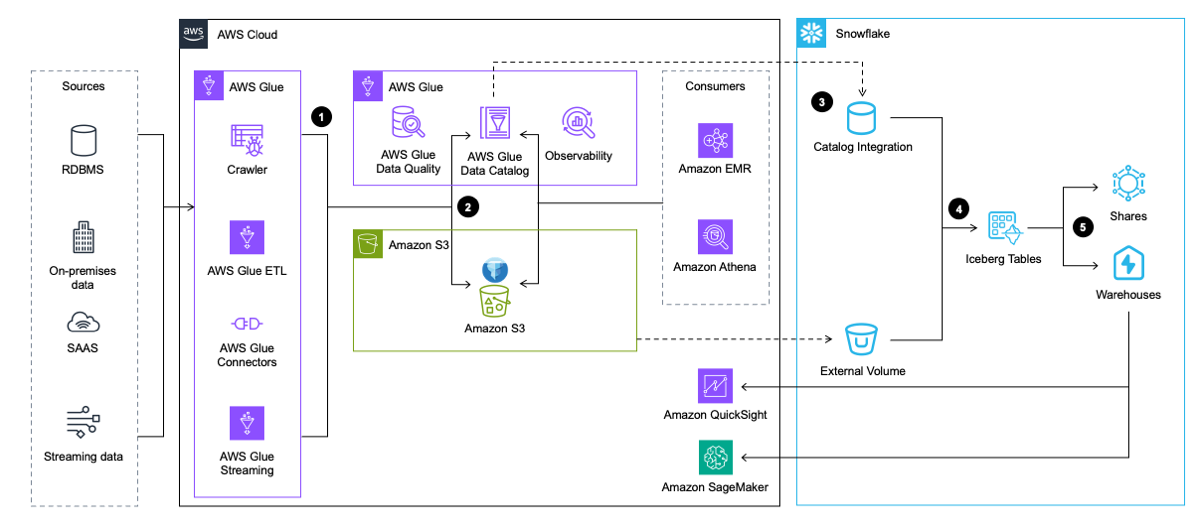
يتضمن سير العمل الخطوات التالية:
- يستخرج AWS Glue البيانات من التطبيقات وقواعد البيانات ومصادر التدفق. يقوم AWS Glue بعد ذلك بتحويله وتحميله إلى مستودع البيانات في Amazon S3 بتنسيق جدول Iceberg، أثناء إدراج وتحديث البيانات التعريفية حول جدول Iceberg في AWS Glue Data Catalog.
- يقوم زاحف AWS Glue بإنشاء البيانات التعريفية لجدول Iceberg وتحديثها ويخزنها في AWS Glue Data Catalog لجداول Iceberg الحالية في مستودع بيانات S3.
- يتكامل Snowflake مع AWS Glue Data Catalog لاسترداد موقع اللقطة.
- في حالة وجود استعلام، يستخدم Snowflake موقع اللقطة من AWS Glue Data Catalog لقراءة بيانات جدول Iceberg في Amazon S3.
- يمكن لـ Snowflake الاستعلام عبر تنسيقات الجداول Iceberg وSnowflake. أنت تستطيع مشاركة البيانات للتعاون مع حساب واحد أو أكثر في نفس منطقة Snowflake. يمكنك أيضًا استخدام البيانات في Snowflake لـ التصور استخدام أمازون QuickSight، أو استخدامه ل أغراض التعلم الآلي (ML) والذكاء الاصطناعي (AI). مع الأمازون SageMaker.
قم بإدارة طاولة Iceberg الخاصة بك باستخدام Snowflake
يوفر النمط الثاني أيضًا إمكانية التشغيل البيني عبر AWS وSnowflake، ولكنه ينفذ مسارات هندسة البيانات لاستيعابها وتحويلها إلى Snowflake. في هذا النمط، يتم تحميل البيانات إلى جداول Iceberg بواسطة Snowflake من خلال عمليات التكامل مع خدمات AWS مثل AWS Glue أو من خلال مصادر أخرى مثل Snowpipe. تقوم Snowflake بعد ذلك بكتابة البيانات مباشرة إلى Amazon S3 بتنسيق Iceberg للوصول إلى المراحل النهائية بواسطة Snowflake وخدمات AWS المتنوعة، وتدير Snowflake كتالوج Iceberg الذي يتتبع مواقع اللقطات عبر الجداول لتتمكن خدمات AWS من الوصول إليها.
مثل النمط السابق، يمكنك استخدام جداول Iceberg التي تديرها Snowflake مع مشاركة بيانات Snowflake، ولكن يمكنك أيضًا استخدام S3 لمشاركة مجموعات البيانات في الحالات التي لا يتمتع فيها أحد الأطراف بإمكانية الوصول إلى Snowflake.
يوفر الرسم التخطيطي التالي للبنية نظرة عامة على هذا النمط من خلال جداول Iceberg المُدارة بواسطة Snowflake.
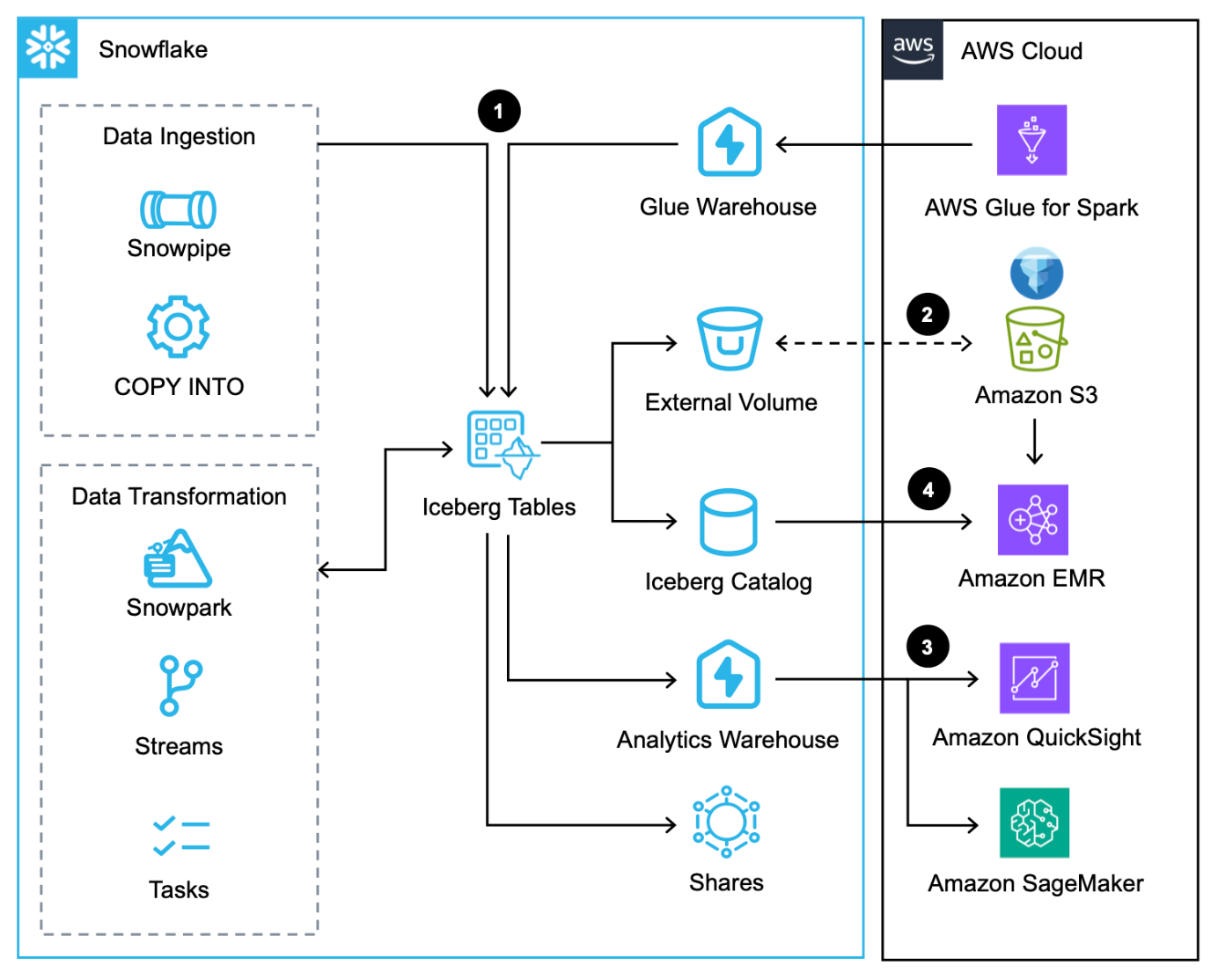
يتكون سير العمل هذا من الخطوات التالية:
- بالإضافة إلى تحميل البيانات عبر أمر COPY, انبوب الثلجو موصل Snowflake الأصلي لـ AWS Glueيمكنك دمج البيانات عبر Snowflake تبادل البيانات.
- تكتب Snowflake جداول Iceberg إلى Amazon S3 وتقوم بتحديث البيانات التعريفية تلقائيًا مع كل معاملة.
- يتم الاستعلام عن جداول Iceberg في Amazon S3 بواسطة Snowflake لأعباء العمل التحليلية وتعلم الآلة باستخدام خدمات مثل QuickSight وSageMaker.
- يمكن لخدمات Apache Spark على AWS أن تفعل ذلك الوصول إلى مواقع اللقطات من Snowflake عبر Snowflake Iceberg Catalog SDK وقم بمسح ملفات جدول Iceberg مباشرة في Amazon S3.
مقارنة الحلول
يسلط هذان النمطان الضوء على الخيارات المتاحة لشخصيات البيانات اليوم لزيادة قابلية التشغيل البيني لبياناتهم إلى أقصى حد بين Snowflake وAWS باستخدام Apache Iceberg. ولكن ما هو النمط المثالي لحالة الاستخدام الخاصة بك؟ إذا كنت تستخدم بالفعل AWS Glue Data Catalog ولا تحتاج إلا إلى Snowflake لاستعلامات القراءة، فيمكن للنمط الأول دمج Snowflake مع AWS Glue وAmazon S3 للاستعلام عن جداول Iceberg. إذا كنت لا تستخدم بالفعل AWS Glue Data Catalog وتتطلب من Snowflake إجراء عمليات القراءة والكتابة، فمن المحتمل أن يكون النمط الثاني حلاً جيدًا يسمح بتخزين البيانات والوصول إليها من AWS.
مع الأخذ في الاعتبار أن عمليات القراءة والكتابة ستعمل على الأرجح على أساس كل جدول بدلاً من بنية البيانات بأكملها، فمن المستحسن استخدام مزيج من كلا النمطين.
قم بترحيل مستودعات البيانات الموجودة إلى مستودع بيانات المعاملات باستخدام Apache Iceberg
يمكنك تحويل جداول مستودعات البيانات الحالية المستندة إلى Parquet وORC وAvro على Amazon S3 إلى تنسيق Iceberg لجني فوائد تكامل المعاملات مع تحسين الأداء وتجربة المستخدم. هناك العديد من خيارات ترحيل جدول Iceberg (لمحة, يهاجرو إضافة ملفات) لترحيل جداول مستودع البيانات الموجودة في مكانها إلى تنسيق Iceberg، وهو الأفضل لإعادة كتابة كافة ملفات البيانات الأساسية - وهو جهد مكلف ويستغرق وقتًا طويلاً مع مجموعات البيانات الكبيرة. في هذا القسم، نركز على ADD_FILES، لأنه مفيد لعمليات الترحيل المخصصة.
بالنسبة لخيارات ADD_FILES، يمكنك استخدام AWS Glue لإنشاء بيانات تعريف وإحصائيات Iceberg لجدول بحيرة بيانات موجود وإنشاء جداول Iceberg جديدة في AWS Glue Data Catalog للاستخدام المستقبلي دون الحاجة إلى إعادة كتابة البيانات الأساسية. للحصول على إرشادات حول إنشاء بيانات تعريف وإحصائيات Iceberg باستخدام AWS Glue، راجع قم بترحيل بحيرة بيانات موجودة إلى بحيرة بيانات المعاملات باستخدام Apache Iceberg or قم بتحويل جداول مستودع بيانات Amazon S3 الحالية إلى جداول Snowflake Unmanaged Iceberg باستخدام AWS Glue.
يتطلب هذا الخيار إيقاف مسارات البيانات مؤقتًا أثناء تحويل الملفات إلى جداول Iceberg، وهي عملية مباشرة في AWS Glue لأن الوجهة تحتاج فقط إلى التغيير إلى جدول Iceberg.
وفي الختام
في هذا المنشور، رأيت نموذجي البنية لتنفيذ Apache Iceberg في بحيرة بيانات لتحسين إمكانية التشغيل البيني عبر AWS وSnowflake. لقد قدمنا أيضًا إرشادات حول ترحيل جداول بحيرة البيانات الحالية إلى تنسيق Iceberg.
الاشتراك في يوم AWS Dev يوم 10 أبريل للتدريب العملي ليس فقط على Apache Iceberg، ولكن أيضًا على تدفق البيانات عبر خطوط الأنابيب خرطوم بيانات أمازون و تدفق أنابيب الثلجوتطبيقات الذكاء الاصطناعي التوليدية مع Streamlit في ندفة الثلج و أمازون بيدروك.
حول المؤلف
 أندريس إنجلبريخت هو مهندس حلول شريك رئيسي في Snowflake ويعمل مع شركاء استراتيجيين. يشارك بنشاط مع شركاء استراتيجيين مثل AWS الذي يدعم تكامل المنتجات والخدمات بالإضافة إلى تطوير حلول مشتركة مع الشركاء. يتمتع Andries بخبرة تزيد عن 20 عامًا في مجال البيانات والتحليلات.
أندريس إنجلبريخت هو مهندس حلول شريك رئيسي في Snowflake ويعمل مع شركاء استراتيجيين. يشارك بنشاط مع شركاء استراتيجيين مثل AWS الذي يدعم تكامل المنتجات والخدمات بالإضافة إلى تطوير حلول مشتركة مع الشركاء. يتمتع Andries بخبرة تزيد عن 20 عامًا في مجال البيانات والتحليلات.
 دينباندو براساد هو أحد كبار المتخصصين في التحليلات في AWS، وهو متخصص في خدمات البيانات الضخمة. إنه متحمس لمساعدة العملاء على بناء بنيات بيانات حديثة على سحابة AWS. لقد ساعد العملاء من جميع الأحجام على تنفيذ حلول إدارة البيانات ومستودع البيانات وبحيرة البيانات.
دينباندو براساد هو أحد كبار المتخصصين في التحليلات في AWS، وهو متخصص في خدمات البيانات الضخمة. إنه متحمس لمساعدة العملاء على بناء بنيات بيانات حديثة على سحابة AWS. لقد ساعد العملاء من جميع الأحجام على تنفيذ حلول إدارة البيانات ومستودع البيانات وبحيرة البيانات.
 بريان دولان انضم إلى أمازون كمدير للعلاقات العسكرية في عام 2012 بعد مسيرته المهنية الأولى كطيار بحري. في عام 2014، انضم براين إلى Amazon Web Services، حيث ساعد العملاء الكنديين من الشركات الناشئة إلى المؤسسات على استكشاف AWS Cloud. في الآونة الأخيرة، كان براين عضوًا في فريق تطوير الأعمال غير العلائقية باعتباره متخصصًا في السوق في Amazon DynamoDB وAmazon Keyspaces قبل الانضمام إلى منظمة Analytics Worldwide Specialist في عام 2022 كمتخصص في السوق في AWS Glue.
بريان دولان انضم إلى أمازون كمدير للعلاقات العسكرية في عام 2012 بعد مسيرته المهنية الأولى كطيار بحري. في عام 2014، انضم براين إلى Amazon Web Services، حيث ساعد العملاء الكنديين من الشركات الناشئة إلى المؤسسات على استكشاف AWS Cloud. في الآونة الأخيرة، كان براين عضوًا في فريق تطوير الأعمال غير العلائقية باعتباره متخصصًا في السوق في Amazon DynamoDB وAmazon Keyspaces قبل الانضمام إلى منظمة Analytics Worldwide Specialist في عام 2022 كمتخصص في السوق في AWS Glue.
 نيدهي جوبتا هو مهندس الحلول الشريك الأول في AWS. تقضي أيامها في العمل مع العملاء والشركاء لحل التحديات المعمارية. إنها شغوفة بتكامل البيانات وتنسيقها، ومعالجة البيانات الكبيرة بدون خادم، والتعلم الآلي. يتمتع Nidhi بخبرة واسعة في قيادة التصميم المعماري وإصدار الإنتاج وعمليات النشر لأحمال عمل البيانات.
نيدهي جوبتا هو مهندس الحلول الشريك الأول في AWS. تقضي أيامها في العمل مع العملاء والشركاء لحل التحديات المعمارية. إنها شغوفة بتكامل البيانات وتنسيقها، ومعالجة البيانات الكبيرة بدون خادم، والتعلم الآلي. يتمتع Nidhi بخبرة واسعة في قيادة التصميم المعماري وإصدار الإنتاج وعمليات النشر لأحمال عمل البيانات.
 سكوت تيل هو قائد تسويق المنتجات في Snowflake ويركز على بحيرات البيانات والتخزين والحوكمة.
سكوت تيل هو قائد تسويق المنتجات في Snowflake ويركز على بحيرات البيانات والتخزين والحوكمة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

