مستودعات بيانات مدعومة من AWS، مدعومة بتوفر لا مثيل له لـ خدمة تخزين أمازون البسيطة (Amazon S3)، يمكنه التعامل مع الحجم والسرعة والمرونة المطلوبة للجمع بين أساليب البيانات والتحليلات المختلفة. ومع نمو حجم بحيرات البيانات ونضج استخدامها، يمكن بذل قدر كبير من الجهد للحفاظ على اتساق البيانات مع أحداث الأعمال. لضمان تحديث الملفات بطريقة متسقة للمعاملات، يستخدم عدد متزايد من العملاء تنسيقات جداول المعاملات مفتوحة المصدر مثل اباتشي فيض, اباتشي هوديو مؤسسة لينكس دلتا ليك التي تساعدك على تخزين البيانات بمعدلات ضغط عالية، والتفاعل بشكل أصلي مع التطبيقات والأطر الخاصة بك، وتبسيط معالجة البيانات المتزايدة في مستودعات البيانات المبنية على Amazon S3. تعمل هذه التنسيقات على تمكين معاملات ACID (الذرية، والاتساق، والعزل، والمتانة)، وعمليات النشر والحذف، والميزات المتقدمة مثل السفر عبر الزمن واللقطات التي كانت متوفرة سابقًا فقط في مستودعات البيانات. ينفذ كل تنسيق تخزين هذه الوظيفة بطرق مختلفة قليلاً؛ للمقارنة، راجع اختيار تنسيق جدول مفتوح لمستودع بيانات المعاملات الخاص بك على AWS.
في 2023، أعلنت AWS عن التوفر العام لـ Apache Iceberg وApache Hudi وLinux Foundation Delta Lake في أمازون أثينا لأباتشي سبارك، مما يلغي الحاجة إلى تثبيت موصل منفصل أو التبعيات المرتبطة به وإدارة الإصدارات، ويبسط خطوات التكوين المطلوبة لاستخدام أطر العمل هذه.
في هذه التدوينة، نوضح لك كيفية استخدام Spark SQL في أمازون أثينا دفاتر الملاحظات والعمل مع تنسيقات الجداول Iceberg وHudi وDelta Lake. نعرض العمليات الشائعة مثل إنشاء قواعد البيانات والجداول، وإدراج البيانات في الجداول، والاستعلام عن البيانات، والنظر في لقطات الجداول في Amazon S3 باستخدام Spark SQL في Athena.
المتطلبات الأساسية المسبقة
أكمل المتطلبات الأساسية التالية:
قم بتنزيل واستيراد نماذج دفاتر الملاحظات من Amazon S3
للمتابعة، قم بتنزيل دفاتر الملاحظات التي تمت مناقشتها في هذا المنشور من المواقع التالية:
بعد تنزيل دفاتر الملاحظات، قم باستيرادها إلى بيئة Athena Spark الخاصة بك عن طريق اتباع التعليمات التالية: لاستيراد دفتر ملاحظات القسم إدارة ملفات دفتر الملاحظات.
انتقل إلى قسم تنسيق الجدول المفتوح المحدد
إذا كنت مهتمًا بتنسيق جدول Iceberg، فانتقل إلى العمل مع جداول Apache Iceberg والقسم الخاص به.
إذا كنت مهتمًا بتنسيق جدول Hudi، فانتقل إلى العمل مع جداول أباتشي هودي والقسم الخاص به.
إذا كنت مهتمًا بتنسيق جدول Delta Lake، فانتقل إلى العمل مع جداول Delta Lake الخاصة بمؤسسة Linux والقسم الخاص به.
العمل مع جداول Apache Iceberg
عند استخدام دفاتر ملاحظات Spark في Athena، يمكنك تشغيل استعلامات SQL مباشرةً دون الحاجة إلى استخدام PySpark. نقوم بذلك عن طريق استخدام سحر الخلية، وهي عبارة عن رؤوس خاصة في خلية دفترية تعمل على تغيير سلوك الخلية. بالنسبة لـ SQL، يمكننا إضافة %%sql السحر، والذي سوف يفسر محتويات الخلية بأكملها على أنها عبارة SQL ليتم تشغيلها على Athena.
في هذا القسم، نعرض كيف يمكنك استخدام SQL على Apache Spark لـ Athena لإنشاء جداول Apache Iceberg وتحليلها وإدارتها.
قم بإعداد جلسة دفتر الملاحظات
لاستخدام Apache Iceberg في Athena، أثناء إنشاء جلسة أو تحريرها، حدد اباتشي فيض الخيار من خلال توسيع خصائص أباتشي سبارك قسم. سيتم ملء الخصائص مسبقًا كما هو موضح في لقطة الشاشة التالية.
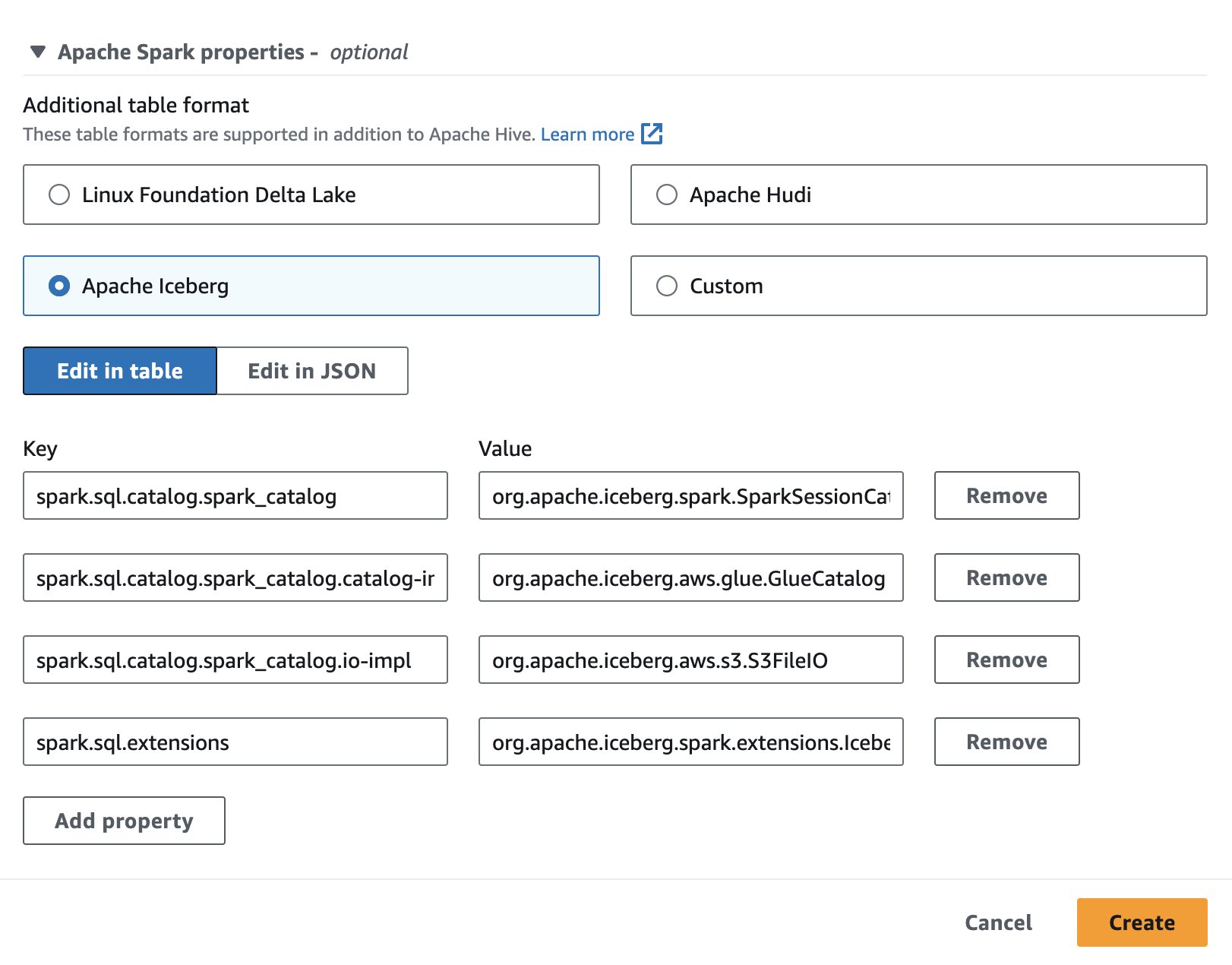
لمعرفة الخطوات، انظر تحرير تفاصيل الجلسة or إنشاء دفتر الملاحظات الخاص بك.
الكود المستخدم في هذا القسم متاح في SparkSQL_iceberg.ipynb الملف للمتابعة.
إنشاء قاعدة بيانات وجدول Iceberg
أولاً، نقوم بإنشاء قاعدة بيانات في AWS Glue Data Catalog. باستخدام SQL التالي، يمكننا إنشاء قاعدة بيانات تسمى icebergdb:
التالي في قاعدة البيانات icebergdb، نقوم بإنشاء جدول Iceberg يسمى noaa_iceberg الإشارة إلى موقع في Amazon S3 حيث سنقوم بتحميل البيانات. قم بتشغيل العبارة التالية واستبدل الموقع s3://<your-S3-bucket>/<prefix>/ مع مجموعة S3 الخاصة بك والبادئة:
أدخل البيانات في الجدول
لتعبئة ملف noaa_iceberg جدول جبل الجليد، نقوم بإدراج البيانات من جدول الباركيه sparkblogdb.noaa_pq التي تم إنشاؤها كجزء من المتطلبات الأساسية. يمكنك القيام بذلك باستخدام إدراج في بيان في سبارك:
بدلا من ذلك ، يمكنك استخدام إنشاء جدول حسب التحديد باستخدام جملة USING Iceberg لإنشاء جدول Iceberg وإدراج البيانات من جدول مصدر في خطوة واحدة:
الاستعلام عن جدول Iceberg
الآن بعد أن تم إدراج البيانات في جدول Iceberg، يمكننا البدء في تحليلها. لنقم بتشغيل Spark SQL للعثور على الحد الأدنى لدرجة الحرارة المسجلة حسب العام لـ 'SEATTLE TACOMA AIRPORT, WA US' موقع:
نحصل على الإخراج التالي.

تحديث البيانات في جدول Iceberg
دعونا نلقي نظرة على كيفية تحديث البيانات في جدولنا. نريد تحديث اسم المحطة 'SEATTLE TACOMA AIRPORT, WA US' إلى 'Sea-Tac'. باستخدام Spark SQL، يمكننا تشغيل ملف قم بيان ضد طاولة جبل الجليد:
يمكننا بعد ذلك تشغيل استعلام SELECT السابق للعثور على الحد الأدنى لدرجة الحرارة المسجلة لـ 'Sea-Tac' موقع:
نحصل على الناتج التالي.

ملفات البيانات المدمجة
تعمل تنسيقات الجداول المفتوحة مثل Iceberg عن طريق إنشاء تغييرات دلتا في تخزين الملفات، وتتبع إصدارات الصفوف من خلال ملفات البيان. يؤدي المزيد من ملفات البيانات إلى تخزين المزيد من البيانات التعريفية في ملفات البيان، وغالبًا ما تتسبب ملفات البيانات الصغيرة في كمية غير ضرورية من البيانات التعريفية، مما يؤدي إلى استعلامات أقل كفاءة وارتفاع تكاليف الوصول إلى Amazon S3. تشغيل جبل الجليد rewrite_data_files سيؤدي الإجراء في Spark for Athena إلى ضغط ملفات البيانات، ودمج العديد من ملفات تغيير دلتا الصغيرة في مجموعة أصغر من ملفات Parquet المحسنة للقراءة. يؤدي ضغط الملفات إلى تسريع عملية القراءة عند الاستعلام عنها. لتشغيل الضغط على طاولتنا، قم بتشغيل Spark SQL التالي:
يقدم rewrite_data_files خيارات لتحديد إستراتيجية الفرز الخاصة بك، والتي يمكن أن تساعد في إعادة تنظيم البيانات وضغطها.
قائمة لقطات الجدول
تؤدي كل عملية كتابة وتحديث وحذف وإدخال وضغط على جدول Iceberg إلى إنشاء لقطة جديدة للجدول مع الاحتفاظ بالبيانات القديمة وبيانات التعريف لعزل اللقطة والسفر عبر الزمن. لسرد لقطات جدول Iceberg، قم بتشغيل عبارة Spark SQL التالية:
انتهاء صلاحية اللقطات القديمة
يوصى بانتهاء صلاحية اللقطات بانتظام لحذف ملفات البيانات التي لم تعد هناك حاجة إليها، وللحفاظ على حجم بيانات تعريف الجدول صغيرًا. لن يقوم أبدًا بإزالة الملفات التي لا تزال مطلوبة بواسطة لقطة غير منتهية الصلاحية. في Spark for Athena، قم بتشغيل SQL التالي لانتهاء صلاحية لقطات الجدول icebergdb.noaa_iceberg التي تكون أقدم من طابع زمني محدد:
لاحظ أنه تم تحديد قيمة الطابع الزمني كسلسلة بالتنسيق yyyy-MM-dd HH:mm:ss.fff. سيعطي الإخراج عددًا لعدد ملفات البيانات والبيانات التعريفية المحذوفة.
قم بإسقاط الجدول وقاعدة البيانات
يمكنك تشغيل Spark SQL التالي لتنظيف جداول Iceberg والبيانات المرتبطة بها في Amazon S3 من هذا التمرين:
قم بتشغيل Spark SQL التالي لإزالة قاعدة البيانات Icebergdb:
لمعرفة المزيد حول جميع العمليات التي يمكنك إجراؤها على جداول Iceberg باستخدام Spark for Athena، راجع استعلامات شرارة و إجراءات الشرارة في وثائق جبل الجليد.
العمل مع جداول أباتشي هودي
بعد ذلك، نعرض كيف يمكنك استخدام SQL على Spark for Athena لإنشاء جداول Apache Hudi وتحليلها وإدارتها.
قم بإعداد جلسة دفتر الملاحظات
لاستخدام Apache Hudi في Athena، أثناء إنشاء جلسة أو تحريرها، حدد اباتشي هودي الخيار من خلال توسيع خصائص أباتشي سبارك والقسم الخاص به.
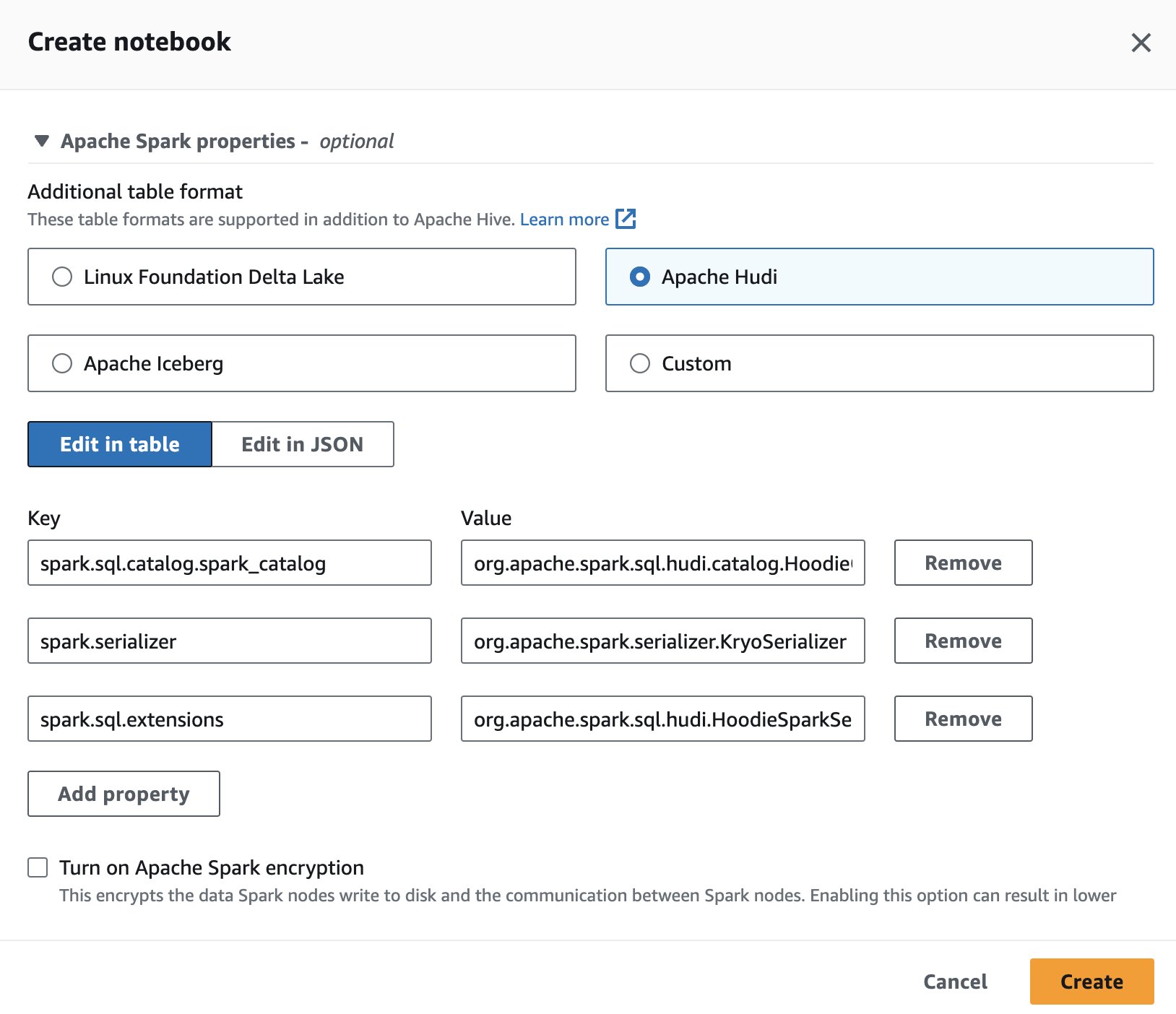
لمعرفة الخطوات، انظر تحرير تفاصيل الجلسة or إنشاء دفتر الملاحظات الخاص بك.
يجب أن يكون الرمز المستخدم في هذا القسم متاحًا في SparkSQL_hudi.ipynb الملف للمتابعة.
إنشاء قاعدة بيانات وجدول Hudi
أولا نقوم بإنشاء قاعدة بيانات تسمى hudidb سيتم تخزينها في كتالوج بيانات AWS Glue متبوعًا بإنشاء جدول Hudi:
نقوم بإنشاء جدول Hudi يشير إلى موقع في Amazon S3 حيث سنقوم بتحميل البيانات. لاحظ أن الجدول من نسخ على الكتابة يكتب. يتم تعريفه بواسطة type= 'cow' في الجدول DDL. لقد حددنا المحطة والتاريخ كمفاتيح أساسية متعددة وpreCombinedField بالسنة. كما أن الجدول مقسم على أساس سنوي. قم بتشغيل العبارة التالية واستبدل الموقع s3://<your-S3-bucket>/<prefix>/ مع مجموعة S3 الخاصة بك والبادئة:
أدخل البيانات في الجدول
كما هو الحال مع Iceberg، نستخدم إدراج في بيان لملء الجدول من خلال قراءة البيانات من sparkblogdb.noaa_pq الجدول الذي تم إنشاؤه في المشاركة السابقة:
الاستعلام عن جدول هدى
الآن وبعد إنشاء الجدول، لنجري استعلامًا للعثور على الحد الأقصى لدرجة الحرارة المسجلة لـ 'SEATTLE TACOMA AIRPORT, WA US' موقع:
تحديث البيانات في جدول Hudi
دعونا نغير اسم المحطة 'SEATTLE TACOMA AIRPORT, WA US' إلى 'Sea–Tac'. يمكننا تشغيل بيان UPDATE على Spark لـ Athena تحديث سجلات noaa_hudi الجدول:
نقوم بتشغيل استعلام SELECT السابق للعثور على الحد الأقصى لدرجة الحرارة المسجلة لـ 'Sea-Tac' موقع:
تشغيل استعلامات السفر عبر الزمن
يمكننا استخدام استعلامات السفر عبر الزمن في SQL على Athena لتحليل لقطات البيانات السابقة. على سبيل المثال:
يتحقق هذا الاستعلام من بيانات درجة حرارة مطار سياتل اعتبارًا من وقت محدد في الماضي. يتيح لنا شرط الطابع الزمني العودة دون تغيير البيانات الحالية. لاحظ أنه تم تحديد قيمة الطابع الزمني كسلسلة بالتنسيق yyyy-MM-dd HH:mm:ss.fff.
تحسين سرعة الاستعلام من خلال التجميع
لتحسين أداء الاستعلام، يمكنك تنفيذ المجموعات على جداول Hudi باستخدام SQL في Spark for Athena:
طاولات مدمجة
الضغط عبارة عن خدمة جدول تستخدمها Hudi على وجه التحديد في جداول الدمج عند القراءة (MOR) لدمج التحديثات من ملفات السجل المستندة إلى الصفوف إلى الملف الأساسي القائم على العمود المقابل بشكل دوري لإنتاج إصدار جديد من الملف الأساسي. لا ينطبق الضغط على جداول النسخ عند الكتابة (COW) وينطبق فقط على جداول MOR. يمكنك تشغيل الاستعلام التالي في Spark for Athena لإجراء الضغط على جداول MOR:
قم بإسقاط الجدول وقاعدة البيانات
قم بتشغيل Spark SQL التالي لإزالة جدول Hudi الذي قمت بإنشائه والبيانات المرتبطة به من موقع Amazon S3:
قم بتشغيل Spark SQL التالي لإزالة قاعدة البيانات hudidb:
للتعرف على جميع العمليات التي يمكنك إجراؤها على جداول Hudi باستخدام Spark for Athena، راجع SQL DDL و الإجراءات في توثيق الهدى.
العمل مع جداول Delta Lake الخاصة بمؤسسة Linux
بعد ذلك، نعرض كيف يمكنك استخدام SQL على Spark for Athena لإنشاء جداول Delta Lake وتحليلها وإدارتها.
قم بإعداد جلسة دفتر الملاحظات
لاستخدام Delta Lake في Spark for Athena، أثناء إنشاء جلسة أو تحريرها، حدد مؤسسة لينكس دلتا ليك من خلال توسيع خصائص أباتشي سبارك والقسم الخاص به.

لمعرفة الخطوات، انظر تحرير تفاصيل الجلسة or إنشاء دفتر الملاحظات الخاص بك.
يجب أن يكون الرمز المستخدم في هذا القسم متاحًا في SparkSQL_delta.ipynb الملف للمتابعة.
إنشاء قاعدة بيانات وجدول Delta Lake
في هذا القسم، نقوم بإنشاء قاعدة بيانات في AWS Glue Data Catalog. باستخدام SQL التالية، يمكننا إنشاء قاعدة بيانات تسمى deltalakedb:
التالي في قاعدة البيانات deltalakedb، نقوم بإنشاء جدول دلتا ليك يسمى noaa_delta الإشارة إلى موقع في Amazon S3 حيث سنقوم بتحميل البيانات. قم بتشغيل العبارة التالية واستبدل الموقع s3://<your-S3-bucket>/<prefix>/ مع مجموعة S3 الخاصة بك والبادئة:
أدخل البيانات في الجدول
نحن نستخدم ملف إدراج في بيان لملء الجدول من خلال قراءة البيانات من sparkblogdb.noaa_pq الجدول الذي تم إنشاؤه في المشاركة السابقة:
يمكنك أيضًا استخدام CREATE TABLE AS SELECT لإنشاء جدول Delta Lake وإدراج البيانات من جدول مصدر في استعلام واحد.
الاستعلام عن جدول دلتا ليك
الآن بعد أن تم إدراج البيانات في جدول دلتا ليك، يمكننا البدء في تحليلها. لنقم بتشغيل Spark SQL للعثور على الحد الأدنى لدرجة الحرارة المسجلة لـ 'SEATTLE TACOMA AIRPORT, WA US' موقع:
تحديث البيانات في جدول بحيرة الدلتا
دعونا نغير اسم المحطة 'SEATTLE TACOMA AIRPORT, WA US' إلى 'Sea–Tac'. يمكننا تشغيل قم بيان على Spark لـ Athena لتحديث سجلات noaa_delta الجدول:
يمكننا تشغيل استعلام SELECT السابق للعثور على الحد الأدنى لدرجة الحرارة المسجلة لـ 'Sea-Tac' الموقع، ويجب أن تكون النتيجة هي نفسها السابقة:
ملفات البيانات المدمجة
في Spark for Athena، يمكنك تشغيل OPTIMIZE على جدول Delta Lake، والذي سيعمل على ضغط الملفات الصغيرة إلى ملفات أكبر، بحيث لا يتم تحميل الاستعلامات بأعباء الملفات الصغيرة. لإجراء عملية الضغط، قم بتشغيل الاستعلام التالي:
الرجوع إلى تحسينات في وثائق Delta Lake للتعرف على الخيارات المختلفة المتاحة أثناء تشغيل OPTIMIZE.
قم بإزالة الملفات التي لم يعد يتم الرجوع إليها بواسطة جدول Delta Lake
يمكنك إزالة الملفات المخزنة في Amazon S3 والتي لم يعد يتم الرجوع إليها بواسطة جدول Delta Lake وتكون أقدم من حد الاستبقاء عن طريق تشغيل أمر VACCUM على الجدول باستخدام Spark for Athena:
الرجوع إلى قم بإزالة الملفات التي لم يعد يتم الرجوع إليها بواسطة جدول دلتا في وثائق Delta Lake للتعرف على الخيارات المتاحة مع VACUUM.
قم بإسقاط الجدول وقاعدة البيانات
قم بتشغيل Spark SQL التالي لإزالة جدول Delta Lake الذي قمت بإنشائه:
قم بتشغيل Spark SQL التالي لإزالة قاعدة البيانات deltalakedb:
يؤدي تشغيل DROP TABLE DDL على جدول Delta Lake وقاعدة البيانات إلى حذف البيانات التعريفية لهذه الكائنات، لكنه لا يحذف ملفات البيانات تلقائيًا في Amazon S3. يمكنك تشغيل تعليمات Python البرمجية التالية في خلية دفتر الملاحظات لحذف البيانات من موقع S3:
لمعرفة المزيد حول عبارات SQL التي يمكنك تشغيلها على جدول Delta Lake باستخدام Spark for Athena، راجع بداية سريعة في وثائق بحيرة دلتا.
وفي الختام
يوضح هذا المنشور كيفية استخدام Spark SQL في دفاتر ملاحظات Athena لإنشاء قواعد بيانات وجداول، وإدراج البيانات والاستعلام عنها، وتنفيذ عمليات شائعة مثل التحديثات والضغط والسفر عبر الزمن على جداول Hudi وDelta Lake وIceberg. تضيف تنسيقات الجدول المفتوح معاملات ACID وعمليات الحذف والحذف إلى مستودعات البيانات، مما يتغلب على قيود تخزين الكائنات الأولية. من خلال إزالة الحاجة إلى تثبيت موصلات منفصلة، يعمل التكامل المدمج في Spark on Athena على تقليل خطوات التكوين وتكاليف الإدارة عند استخدام أطر العمل الشائعة هذه لإنشاء مستودعات بيانات موثوقة على Amazon S3. لمعرفة المزيد حول تحديد تنسيق جدول مفتوح لأحمال عمل Data Lake، راجع اختيار تنسيق جدول مفتوح لمستودع بيانات المعاملات الخاص بك على AWS.
حول المؤلف
![]() باثيك شاه هو مهندس التحليلات الأول في Amazon Athena. انضم إلى AWS في عام 2015 وركز على مجال تحليل البيانات الضخمة منذ ذلك الحين، حيث ساعد العملاء على بناء حلول قوية وقابلة للتطوير باستخدام خدمات تحليلات AWS.
باثيك شاه هو مهندس التحليلات الأول في Amazon Athena. انضم إلى AWS في عام 2015 وركز على مجال تحليل البيانات الضخمة منذ ذلك الحين، حيث ساعد العملاء على بناء حلول قوية وقابلة للتطوير باستخدام خدمات تحليلات AWS.
![]() راج ديفناث هو مدير المنتج في AWS على Amazon Athena. إنه متحمس لبناء المنتجات التي يحبها العملاء ومساعدة العملاء على استخلاص القيمة من بياناتهم. وتتمثل خلفيته في تقديم الحلول لأسواق نهائية متعددة، مثل التمويل، وتجارة التجزئة، والمباني الذكية، وأتمتة المنازل، وأنظمة اتصالات البيانات.
راج ديفناث هو مدير المنتج في AWS على Amazon Athena. إنه متحمس لبناء المنتجات التي يحبها العملاء ومساعدة العملاء على استخلاص القيمة من بياناتهم. وتتمثل خلفيته في تقديم الحلول لأسواق نهائية متعددة، مثل التمويل، وتجارة التجزئة، والمباني الذكية، وأتمتة المنازل، وأنظمة اتصالات البيانات.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/

