تكتسب بحيرات البيانات شعبية لتخزين كميات هائلة من البيانات من مصادر متنوعة بطريقة قابلة للتطوير وفعالة من حيث التكلفة. مع تزايد عدد مستهلكي البيانات، غالبًا ما يحتاج مسؤولو بحيرة البيانات إلى تنفيذ عناصر تحكم دقيقة في الوصول لملفات تعريف المستخدمين المختلفة. قد يحتاجون إلى تقييد الوصول إلى جداول أو أعمدة معينة اعتمادًا على نوع المستخدم الذي يقدم الطلب. كما ترغب الشركات أحيانًا في إتاحة البيانات للتطبيقات الخارجية ولكنها غير متأكدة من كيفية القيام بذلك بشكل آمن. ولمواجهة هذه التحديات، يمكن للمؤسسات اللجوء إلى GraphQL و تكوين بحيرة AWS.
GraphQL يوفر طريقة قوية وآمنة ومرنة للاستعلام عن البيانات واسترجاعها. أوس أبسينك هي خدمة لإنشاء واجهات برمجة تطبيقات GraphQL التي يمكنها الاستعلام عن قواعد بيانات وخدمات صغيرة وواجهات برمجة تطبيقات متعددة من نقطة نهاية GraphQL موحدة.
يمكن لمسؤولي بحيرة البيانات استخدام Lake Formation للتحكم في الوصول إلى بحيرات البيانات. توفر Lake Formation عناصر تحكم دقيقة في الوصول لإدارة أذونات المستخدم والمجموعة على مستوى الجدول والعمود والخلية. وبالتالي يمكنها ضمان أمن البيانات والامتثال لها. بالإضافة إلى ذلك، يتكامل Lake Formation مع خدمات AWS الأخرى، مثل أمازون أثينامما يجعلها مثالية للاستعلام عن بحيرات البيانات من خلال واجهات برمجة التطبيقات.
في هذا المنشور، نوضح كيفية إنشاء تطبيق يمكنه استخراج البيانات من بحيرة البيانات من خلال واجهة برمجة تطبيقات GraphQL وتقديم النتائج إلى أنواع مختلفة من المستخدمين بناءً على امتيازات الوصول إلى البيانات المحددة الخاصة بهم. تم إنشاء نموذج التطبيق الموضح في هذا المنشور بواسطة AWS Partner تقنيات نتسول.
حل نظرة عامة
يستخدم الحل لدينا خدمة Amazon Simple Storage (Amazon S3) لتخزين البيانات، غراء AWS كتالوج البيانات ليحتوي على مخطط البيانات، وLake Formation لتوفير الإدارة على كائنات AWS Glue Data Catalog من خلال تنفيذ الوصول المستند إلى الدور. نحن نستخدم أيضا أمازون إيفينت بريدج لالتقاط الأحداث في بحيرة البيانات الخاصة بنا وبدء العمليات النهائية. تظهر بنية الحل في الرسم البياني التالي.
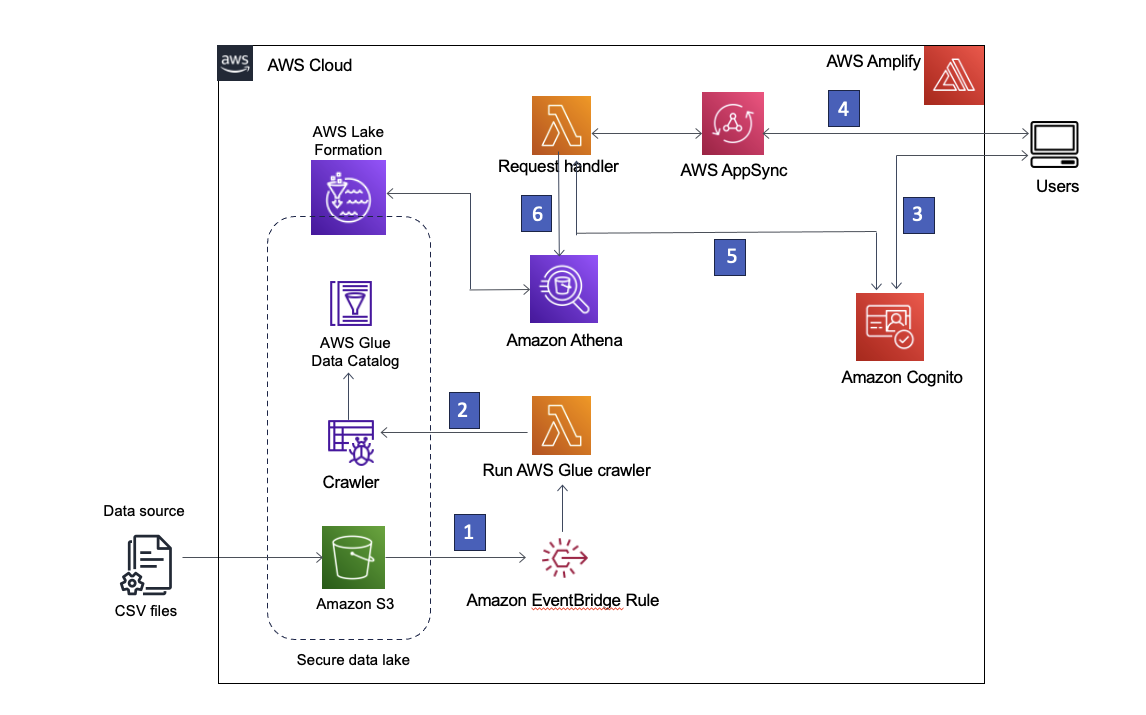
الشكل 1 - بنية الحل
وفيما يلي وصف خطوة بخطوة للحل:
- يتم إنشاء بحيرة البيانات في حاوية S3 مسجلة لدى Lake Formation. عند وصول بيانات جديدة، يتم استدعاء قاعدة EventBridge.
- تعمل قاعدة EventBridge على تشغيل AWS لامدا وظيفة لبدء زاحف AWS Glue لاكتشاف البيانات الجديدة وتحديث أي تغييرات في المخطط بحيث يمكن الاستعلام عن أحدث البيانات.
ملاحظة: يمكن أيضًا تشغيل برامج زحف AWS Glue مباشرة من أحداث Amazon S3، كما هو موضح في هذا بلوق وظيفة. - تضخيم AWS يسمح للمستخدمين بتسجيل الدخول باستخدام أمازون كوجنيتو كمزود هوية. يقوم Cognito بمصادقة بيانات اعتماد المستخدم وإرجاع رموز الوصول.
- يقوم المستخدمون المعتمدون باستدعاء واجهة برمجة تطبيقات AWS AppSync GraphQL من خلال Amplify، وجلب البيانات من مستودع البيانات. يتم تشغيل وظيفة Lambda للتعامل مع الطلب.
- تقوم وظيفة Lambda باسترداد تفاصيل المستخدم من Cognito وتفترض إدارة الهوية والوصول (IAM) AWS الدور المرتبط بمجموعة مستخدمي Cognito الخاصة بالمستخدم الطالب.
- تقوم وظيفة Lambda بعد ذلك بتشغيل استعلام Athena مقابل جداول مستودع البيانات وإرجاع النتائج إلى AWS AppSync، الذي يقوم بعد ذلك بإرجاع النتائج إلى المستخدم.
المتطلبات الأساسية المسبقة
لنشر هذا الحل، يجب عليك أولاً القيام بما يلي:
قم بإعداد أذونات تكوين البحيرة
تسجيل الدخول إلى وحدة تحكم LakeFormation وأضف نفسك كمسؤول. إذا كنت تقوم بتسجيل الدخول إلى Lake Formation لأول مرة، فيمكنك القيام بذلك عن طريق تحديد إضافة نفسي على شاشة مرحبًا بك في Lake Formation واختيار البدء كما هو موضح في الشكل 2.

الشكل 2 - أضف نفسك كمسؤول Lake Formation
بخلاف ذلك، يمكنك اختيار الأدوار والمهام الإدارية في شريط التنقل الأيسر واختيار إدارة المسؤولين لإضافة نفسك. من المفترض أن ترى اسم مستخدم IAM الخاص بك ضمن مسؤولي Data Lake مع حق الوصول الكامل عند الانتهاء.
حدد إعدادات كتالوج البيانات في شريط التنقل الأيسر وتأكد من عدم تحديد مربعي التحكم في الوصول إلى IAM، كما هو موضح في الشكل 3. تريد Lake Formation، وليس IAM، للتحكم في الوصول إلى قواعد البيانات الجديدة.
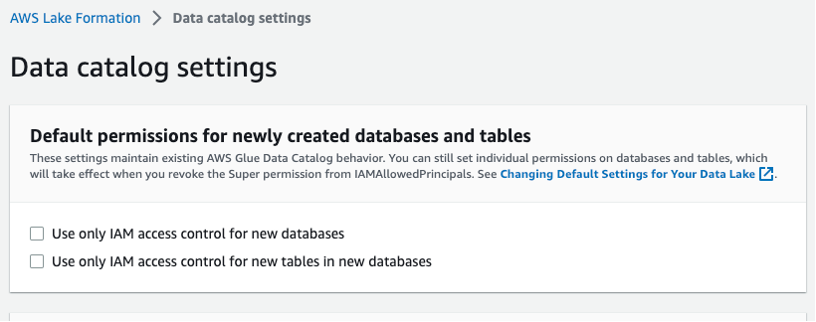
الشكل 3 - إعدادات كتالوج بيانات Lake Formation
انشر الحل
لإنشاء الحل في بيئة AWS الخاصة بك، قم بتشغيل مكدس AWS CloudFormation التالي: ![]()
سيتم إطلاق الموارد التالية من خلال قالب CloudFormation:
- Amazon VPC ومكونات الشبكات (الشبكات الفرعية ومجموعات الأمان وبوابة NAT)
- أدوار IAM
- تحتوي Lake Formation على دلو S3 وزاحف AWS Glue وقاعدة بيانات AWS Glue
- وظائف لامدا
- تجمع مستخدمي Cognito
- واجهة برمجة تطبيقات AWS AppSync GraphQL
- قواعد EventBridge
بعد نشر الموارد المطلوبة من مكدس CloudFormation، يجب عليك إنشاء وظيفتي Lambda وتحميل مجموعة البيانات إلى Amazon S3. ستتحكم Lake Formation في بحيرة البيانات المخزنة في حاوية S3.
إنشاء وظائف لامدا
كلما تم وضع ملف جديد في حاوية S3 المخصصة، يتم استدعاء قاعدة EventBridge، والتي تقوم بتشغيل وظيفة Lambda لبدء زاحف AWS Glue. يقوم الزاحف بتحديث كتالوج بيانات AWS Glue ليعكس أي تغييرات في المخطط.
عندما يقوم التطبيق بإجراء استعلام عن البيانات من خلال واجهة برمجة تطبيقات GraphQL، يتم استدعاء وظيفة Lambda لمعالج الطلب لمعالجة الاستعلام وإرجاع النتائج.
لإنشاء وظيفتي Lambda هاتين، تابع على النحو التالي.
- قم بتسجيل الدخول إلى وحدة تحكم Lambda.
- حدد وظيفة معالج الطلب Lambda المسماة
dl-dev-crawlerLambdaFunction. - ابحث عن ملف وظيفة Lambda الزاحف في ملف
lambdas/crawler-lambdaالمجلد الموجود في git repo الذي قمت باستنساخه على جهازك المحلي. - انسخ الكود الموجود في هذا الملف والصقه في قسم الكود في ملف
dl-dev-crawlerLambdaFunctionفي وحدة تحكم Lambda الخاصة بك. ثم اختر نشر لنشر الوظيفة.
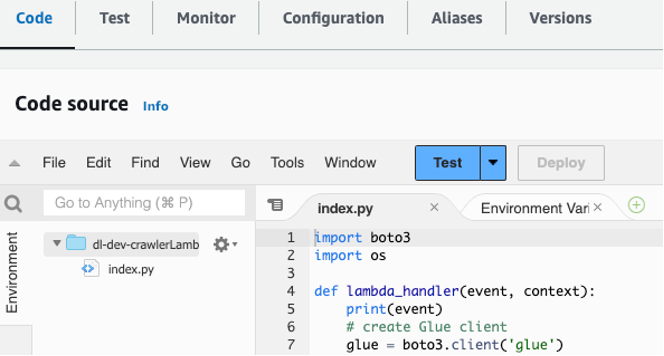
الشكل 4 - انسخ الكود والصقه في وظيفة Lambda
- كرر الخطوات من 2 إلى 4 لوظيفة معالج الطلب المسماة
dl-dev-requestHandlerLambdaFunctionباستخدام الكود فيlambdas/request-handler-lambda.
قم بإنشاء طبقة لمعالج الطلب Lambda
يجب عليك الآن تحميل بعض أكواد المكتبة الإضافية التي تحتاجها وظيفة Lambda لمعالج الطلبات.
- أختار طبقات في القائمة اليسرى واختر إنشاء طبقة.
- أدخل اسمًا مثل
appsync-lambda-layer. - تحميل هذا ملف مضغوط لطبقة الحزمة إلى جهازك المحلي.
- قم بتحميل ملف ZIP باستخدام تحميل زر على إنشاء طبقة .
- اختار بيثون 3.7 كوقت التشغيل للطبقة.
- اختار إنشاء.
- أختار وظائف في القائمة اليسرى وحدد ملف
dl-dev-requestHandlerدالة لامدا. - انتقل لأسفل إلى طبقات قسم واختيار أضف طبقة.
- إختار ال طبقات مخصصة الخيار ثم حدد الطبقة التي قمت بإنشائها أعلاه.
- انقر أضف.
قم بتحميل البيانات إلى Amazon S3
انتقل إلى الدليل الجذر لمستودع git المستنسخ وقم بتشغيل الأوامر التالية لتحميل نموذج مجموعة البيانات. استبدل bucket_name عنصر نائب مع مجموعة S3 المتوفرة باستخدام قالب CloudFormation. يمكنك الحصول على اسم الحاوية من وحدة تحكم CloudFormation بالانتقال إلى النواتج علامة التبويب مع المفتاح datalakes3bucketName كما هو موضح في الصورة أدناه.

الشكل 5 - اسم حاوية S3 الموضح في علامة التبويب مخرجات CloudFormation
أدخل الأوامر التالية في مجلد المشروع الخاص بك على جهازك المحلي لتحميل مجموعة البيانات إلى حاوية S3.
الآن دعونا نلقي نظرة على القطع الأثرية المنتشرة.
بحيرة البيانات
تحتوي مجموعة S3 على بيانات نموذجية لكيانين: الشركات وأصحابها. يتم تسجيل الجرافة في Lake Formation، كما هو موضح في الشكل 6. وهذا يمكّن Lake Formation من إنشاء كتالوجات البيانات وإدارتها وإدارة الأذونات على البيانات.

الشكل 6 - وحدة تحكم Lake Formation توضح موقع بحيرة البيانات
يتم إنشاء قاعدة بيانات للاحتفاظ بمخطط البيانات الموجود في Amazon S3. يتم استخدام زاحف AWS Glue لتحديث أي تغيير في المخطط في حاوية S3. تم منح هذا الزاحف إذنًا لإنشاء الجداول وتعديلها وإسقاطها في قاعدة البيانات باستخدام Lake Formation.
تطبيق ضوابط الوصول إلى بحيرة البيانات
تم إنشاء دورين IAM، dl-us-east-1-developer و dl-us-east-1-business-analyst، تم تعيين كل منها لمجموعة مستخدمين مختلفة لـ Cognito. يتم تعيين تراخيص مختلفة لكل دور من خلال Lake Formation. يتمتع دور المطور بإمكانية الوصول إلى كل عمود في بحيرة البيانات، بينما يُمنح دور محلل الأعمال فقط إمكانية الوصول إلى أعمدة المعلومات غير الشخصية (PII).
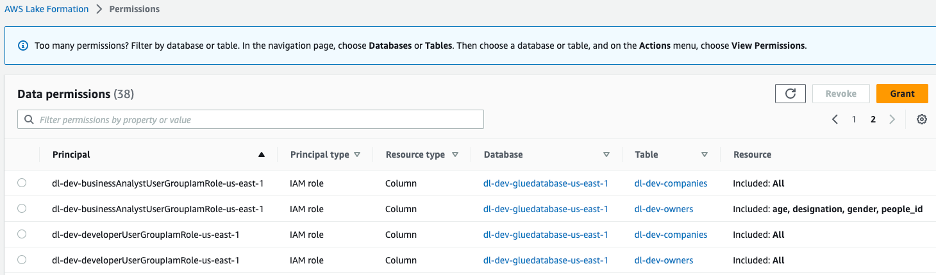
الشكل 7 – أذونات بحيرة بيانات وحدة تحكم تكوين البحيرة المخصصة لأدوار المجموعة
مخطط GraphQL
يمكن عرض واجهة برمجة تطبيقات GraphQL من وحدة تحكم AWS AppSync. ال Companies يتضمن النوع عدة سمات تصف أصحاب الشركات.
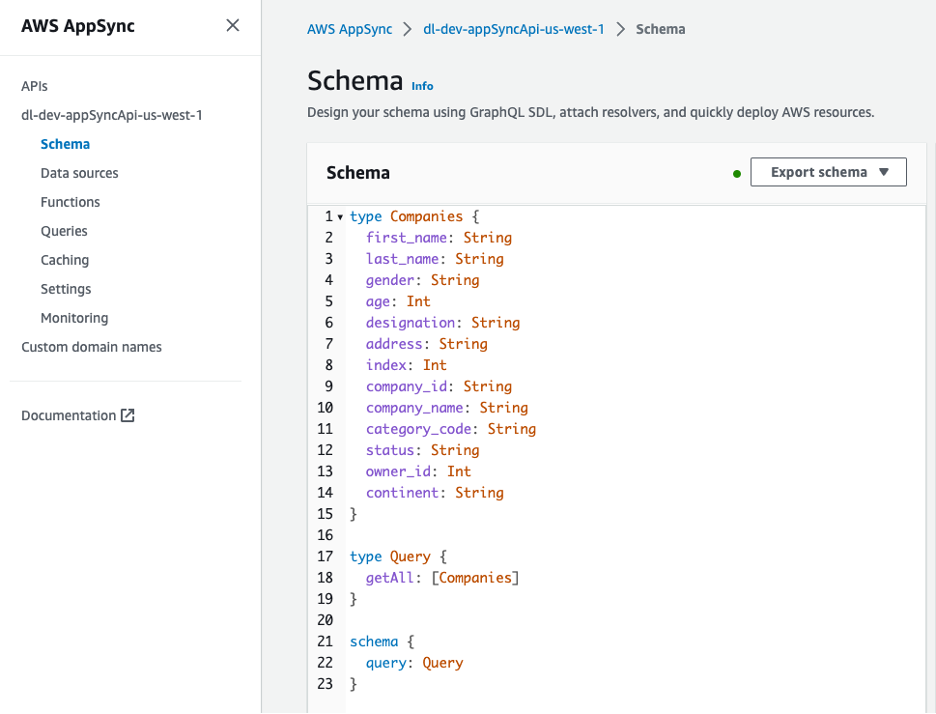
الشكل 8 - مخطط واجهة برمجة تطبيقات GraphQL
مصدر البيانات لواجهة برمجة تطبيقات GraphQL هو وظيفة Lambda، التي تعالج الطلبات.
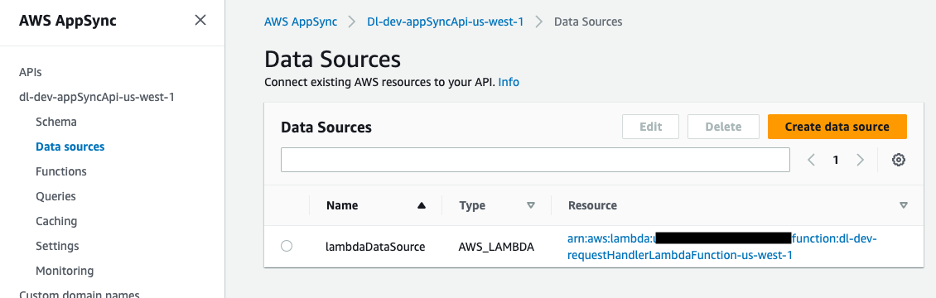
الشكل 9 - تم تعيين مصدر بيانات AWS AppSync لوظيفة Lambda
التعامل مع طلبات GraphQL API
تقوم وظيفة Lambda لمعالج طلبات GraphQL API باسترداد معرف مجمع مستخدمي Cognito من متغيرات البيئة. باستخدام مكتبة boto3، يمكنك إنشاء عميل Cognito واستخدام ملف get_group طريقة للحصول على دور IAM المرتبط بمجموعة مستخدمي Cognito.
يمكنك استخدام وظيفة مساعدة في وظيفة Lambda للحصول على الدور.
باستخدام خدمة AWS Security Token (AWS STS) من خلال عميل boto3، يمكنك تولي دور IAM والحصول على بيانات الاعتماد المؤقتة التي تحتاجها لتشغيل استعلام Athena.
نقوم بتمرير بيانات الاعتماد المؤقتة كمعلمات عند إنشاء عميل Boto3 Amazon Athena الخاص بنا.
athena_client = boto3.client('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)يتم تمرير العميل والاستعلام إلى وظيفة مساعد استعلام Athena الخاصة بنا والتي تقوم بتنفيذ الاستعلام وإرجاع معرف الاستعلام. باستخدام معرف الاستعلام، يمكننا قراءة النتائج من S3 وتجميعها كقاموس Python ليتم إرجاعها في الاستجابة.
تمكين الوصول من جانب العميل إلى بحيرة البيانات
على جانب العميل، تم تكوين AWS Amplify مع مجمع مستخدمي Amazon Cognito للمصادقة. سننتقل إلى وحدة تحكم Amazon Cognito لعرض تجمع المستخدمين والمجموعات التي تم إنشاؤها.
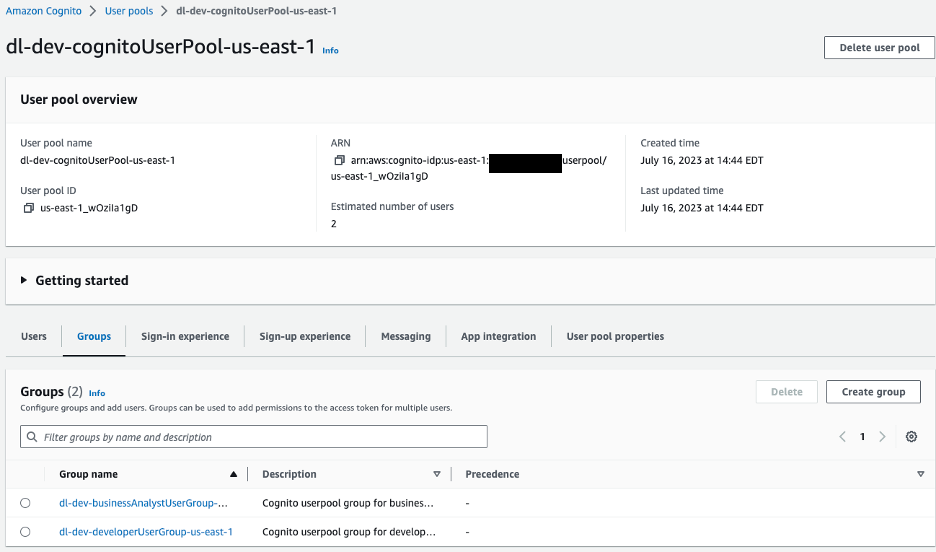
الشكل 10 – تجمعات مستخدمي Amazon Cognito
بالنسبة لتطبيقنا النموذجي، لدينا مجموعتان في تجمع المستخدمين لدينا:
dl-dev-businessAnalystUserGroup- محللو الأعمال بأذونات محدودة.dl-dev-developerUserGroup- المطورين مع الأذونات الكاملة.
إذا استكشفت هذه المجموعات، فسترى دور IAM مرتبطًا بكل منها. هذا هو دور IAM الذي يتم تعيينه للمستخدم عند المصادقة. تتولى أثينا هذا الدور عند الاستعلام عن بحيرة البيانات.
إذا قمت بعرض الأذونات الخاصة بدور IAM هذا، فستلاحظ أنه لا يتضمن عناصر التحكم في الوصول أسفل مستوى الجدول. أنت بحاجة إلى طبقة الإدارة الإضافية التي توفرها Lake Formation لإضافة تحكم دقيق في الوصول.
بعد التحقق من المستخدم ومصادقته بواسطة Cognito، يستخدم Amplify رموز الوصول لاستدعاء واجهة برمجة تطبيقات AWS AppSync GraphQL وجلب البيانات. استنادًا إلى مجموعة المستخدم، تتولى وظيفة Lambda دور مجموعة مستخدمي Cognito المقابل. باستخدام الدور المفترض، يتم تشغيل استعلام Athena ويتم إرجاع النتيجة إلى المستخدم.
إنشاء مستخدمين للاختبار
أنشئ مستخدمين، أحدهما للمطور والآخر لمحلل الأعمال، وأضفهما إلى مجموعات المستخدمين.
- انتقل إلى Cognito وحدد تجمع المستخدمين،
dl-dev-cognitoUserPool، تم إنشاؤه. - اختار خلق المستخدم وتقديم التفاصيل لإنشاء مستخدم محلل أعمال جديد. يمكن أن يكون اسم المستخدم محلل بيز. اترك عنوان البريد الإلكتروني فارغًا، وأدخل كلمة المرور.
- إختار ال المستخدمين علامة التبويب وحدد المستخدم الذي قمت بإنشائه للتو.
- أضف هذا المستخدم إلى مجموعة محللي الأعمال عن طريق اختيار إضافة المستخدم إلى المجموعة .
- اتبع نفس الخطوات لإنشاء مستخدم آخر باسم المستخدم المطور وإضافة المستخدم إلى مجموعة المطورين.
اختبر المحلول
لاختبار الحل الخاص بك، قم بتشغيل تطبيق React على جهازك المحلي.
- في دليل المشروع المستنسخ، انتقل إلى ملف
react-appالدليل. - تثبيت تبعيات المشروع.
- تثبيت تضخيم CLI:
- إنشاء ملف جديد يسمى
.envعن طريق تشغيل الأوامر التالية ثم استخدم محرر النصوص لتحديث قيم متغيرات البيئة في الملف.
استخدم النواتج علامة تبويب مكدس وحدة التحكم CloudFormation للحصول على القيم المطلوبة من المفاتيح كما يلي:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- أضف المتغيرات السابقة إلى بيئتك.
- قم بإنشاء الكود المطلوب للتفاعل مع واجهة برمجة التطبيقات (API) باستخدام تضخيم CodeGen. في علامة تبويب المخرجات بوحدة تحكم Cloudformation، ابحث عن معرف AWS Appsync API الخاص بك بجوار
appsyncApiIdالرئيسية.
اقبل كافة الخيارات الافتراضية للأمر أعلاه بالضغط أدخل في كل موجه.
- ابدأ التطبيق.
يمكنك التأكد من تشغيل التطبيق من خلال زيارة http://localhost:3000 وتسجيل الدخول كمستخدم المطور الذي قمت بإنشائه مسبقًا.
الآن بعد أن أصبح التطبيق قيد التشغيل، دعنا نلقي نظرة على كيفية تقديم كل دور من companies نقطة النهاية.
أولاً، التوقيع هو دور المطور، الذي لديه حق الوصول إلى جميع الحقول، وتقديم طلب واجهة برمجة التطبيقات (API) إلى نقطة نهاية الشركات. لاحظ الحقول التي يمكنك الوصول إليها.
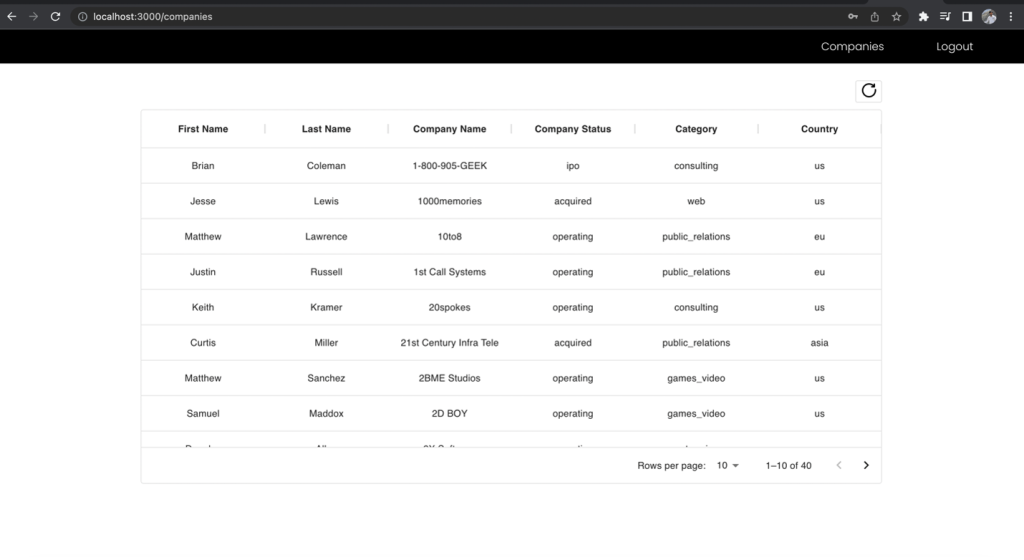
الشكل 11 – نتائج دور المطور
الآن، قم بتسجيل الدخول كمستخدم محلل الأعمال وقم بتقديم الطلب إلى نفس نقطة النهاية وقارن بين الحقول المضمنة.
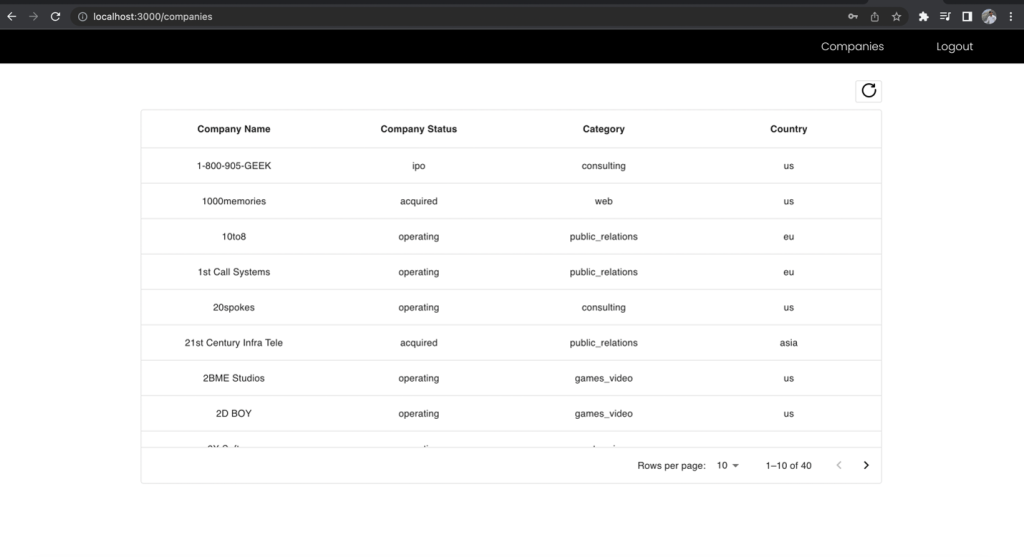
الشكل 12 – نتائج دور محلل الأعمال
يتم استبعاد عمودي الاسم الأول واسم العائلة في قائمة الشركات في طريقة عرض محلل الأعمال على الرغم من قيامك بتقديم الطلب إلى نفس نقطة النهاية. يوضح هذا قوة استخدام نقطة نهاية GraphQL موحدة مع عدة أدوار IAM لمجموعة مستخدمي Cognito المعينة لأذونات Lake Formation لإدارة الوصول المستند إلى الدور إلى بياناتك.
تنظيف
بعد الانتهاء من اختبار الحل، قم بتنظيف الموارد التالية لتجنب تكبد رسوم مستقبلية:
- قم بإفراغ مجموعات S3 التي تم إنشاؤها بواسطة قالب CloudFormation.
- احذف مكدس CloudFormation لإزالة مجموعات S3 والموارد الأخرى.
وفي الختام
في هذا المنشور، أوضحنا لك كيفية تقديم البيانات بشكل آمن في بحيرة البيانات للمستخدمين المعتمدين لتطبيق React بناءً على امتيازات الوصول المستندة إلى الدور. لتحقيق ذلك، استخدمت واجهات برمجة التطبيقات GraphQL في AWS AppSync، وعناصر التحكم في الوصول الدقيقة من Lake Formation، وCognito لمصادقة المستخدمين حسب المجموعة وتعيينهم إلى أدوار IAM. لقد استخدمت أيضًا Athena للاستعلام عن البيانات.
للقراءة ذات الصلة حول هذا الموضوع، راجع تصور البيانات الضخمة باستخدام AWS AppSync وAmazon Athena وAWS Amplify و صمم بنية شبكة بيانات باستخدام AWS Lake Formation و AWS Glue.
هل ستنفذ هذا النهج لخدمة البيانات من بحيرة البيانات الخاصة بك؟ اسمحوا لنا أن نعرف في التعليقات!
حول المؤلف
 رنا دوت هو مهندس الحلول الرئيسي في Amazon Web Services. يتمتع بخلفية في تصميم منصات برمجية قابلة للتطوير للخدمات المالية والرعاية الصحية وشركات الاتصالات، وهو متحمس لمساعدة العملاء في البناء على AWS.
رنا دوت هو مهندس الحلول الرئيسي في Amazon Web Services. يتمتع بخلفية في تصميم منصات برمجية قابلة للتطوير للخدمات المالية والرعاية الصحية وشركات الاتصالات، وهو متحمس لمساعدة العملاء في البناء على AWS.
 رانجيث رايابرولو هو أحد كبار مهندسي الحلول في AWS ويعمل مع العملاء في شمال غرب المحيط الهادئ. فهو يساعد العملاء على تصميم وتشغيل حلول جيدة التصميم في AWS والتي تعالج مشكلات أعمالهم وتسريع اعتماد خدمات AWS. وهو يركز على تقنيات الأمان والشبكات لدى AWS لتطوير الحلول في السحابة عبر مختلف قطاعات الصناعة. يعيش رانجيث في منطقة سياتل ويحب الأنشطة الخارجية.
رانجيث رايابرولو هو أحد كبار مهندسي الحلول في AWS ويعمل مع العملاء في شمال غرب المحيط الهادئ. فهو يساعد العملاء على تصميم وتشغيل حلول جيدة التصميم في AWS والتي تعالج مشكلات أعمالهم وتسريع اعتماد خدمات AWS. وهو يركز على تقنيات الأمان والشبكات لدى AWS لتطوير الحلول في السحابة عبر مختلف قطاعات الصناعة. يعيش رانجيث في منطقة سياتل ويحب الأنشطة الخارجية.
 جاستن ليتو هو مهندس الحلول الأول في Amazon Web Services وهو متخصص في قواعد البيانات وتحليلات البيانات الضخمة والتعلم الآلي. شغفه هو مساعدة العملاء على اعتماد السحابة بشكل أفضل. يستمتع في أوقات فراغه بالإبحار بعيدًا عن الشاطئ والعزف على البيانو لموسيقى الجاز. يعيش في مدينة نيويورك مع زوجته وابنته الرضيعة.
جاستن ليتو هو مهندس الحلول الأول في Amazon Web Services وهو متخصص في قواعد البيانات وتحليلات البيانات الضخمة والتعلم الآلي. شغفه هو مساعدة العملاء على اعتماد السحابة بشكل أفضل. يستمتع في أوقات فراغه بالإبحار بعيدًا عن الشاطئ والعزف على البيانو لموسيقى الجاز. يعيش في مدينة نيويورك مع زوجته وابنته الرضيعة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/using-aws-appsync-and-aws-lake-formation-to-access-a-secure-data-lake-through-a-graphql-api/

