تضع المنظمات أولوية عالية لتكامل البيانات ، خاصة لدعم التحليلات والتعلم الآلي (ML) وذكاء الأعمال (BI) ومبادرات تطوير التطبيقات. تتزايد البيانات بشكل كبير ويتم إنشاؤها بواسطة مصادر بيانات متنوعة بشكل متزايد. يصبح تكامل البيانات أمرًا صعبًا عند معالجة البيانات على نطاق واسع والرفع الثقيل المتأصل المرتبط بالبنية التحتية المطلوبة لإدارتها. هذا هو أحد الأسباب الرئيسية وراء بحث المؤسسات باستمرار عن حلول تكامل بيانات سهلة الاستخدام وقليلة الصيانة لنقل البيانات من موقع إلى آخر أو لتوحيد بيانات أعمالهم من عدة مصادر في موقع مركزي لاتخاذ قرارات عمل إستراتيجية .
تستخدم معظم المؤسسات Spark لتلبية احتياجات معالجة البيانات الضخمة. إذا كنت تبحث عن تبسيط تكامل البيانات ، ولا تريد متاعب تدوير الخوادم أو إدارة الموارد أو إعداد مجموعات Spark ، فلدينا الحل المناسب لك.
غراء AWS هي خدمة تكامل بيانات بدون خادم تسهل اكتشاف البيانات وإعدادها ودمجها لأغراض التحليلات والتعلم الآلي وتطوير التطبيقات. يوفر AWS Glue كلاً من الواجهات المرئية والقائمة على الكود لجعل تكامل البيانات بسيطًا ويمكن للجميع الوصول إليه.
إذا كنت تفضل تجربة قائمة على التعليمات البرمجية وترغب في تأليف وظائف تكامل البيانات بشكل تفاعلي ، فإننا نوصي بجلسات تفاعلية. الجلسات التفاعلية هي إحدى ميزات AWS Glue التي تم إطلاقها مؤخرًا والتي تتيح لك تطوير عمليات AWS Glue بشكل تفاعلي وتشغيل واختبار كل خطوة وعرض النتائج.
هناك خيارات مختلفة لاستخدام الجلسات التفاعلية. يمكنك إنشاء جلسات تفاعلية والعمل معها من خلال واجهة سطر الأوامر AWS (AWS CLI) وواجهة برمجة التطبيقات. يمكنك أيضًا استخدام أجهزة الكمبيوتر المحمولة المتوافقة مع Jupyter للتأليف المرئي واختبار البرامج النصية لدفتر ملاحظاتك. توفر الجلسات التفاعلية نواة Jupyter التي تتكامل تقريبًا في أي مكان تقوم به Jupyter ، بما في ذلك التكامل مع IDEs مثل PyCharm و IntelliJ و Visual Studio Code. يمكّنك هذا من تأليف التعليمات البرمجية في بيئتك المحلية وتشغيلها بسلاسة على الواجهة الخلفية للجلسة التفاعلية. يمكنك أيضًا بدء تشغيل جهاز كمبيوتر محمول من خلال AWS Glue Studio ؛ يتم تنفيذ جميع خطوات التكوين من أجلك حتى تتمكن من استكشاف بياناتك والبدء في تطوير نص وظيفتك بعد بضع ثوانٍ فقط. عندما يكون الرمز جاهزًا ، يمكنك تكوين وجدولة ومراقبة دفاتر المهام كمهام AWS Glue.
إذا لم تكن قد جربت جلسات AWS Glue التفاعلية من قبل ، فيوصى بشدة بهذه المشاركة. نحن نعمل من خلال سيناريو بسيط حيث قد تحتاج إلى تحميل البيانات بشكل متزايد من خدمة تخزين أمازون البسيطة (Amazon S3) إلى الأمازون الأحمر أو تحويل وإثراء بياناتك قبل تحميلها في Amazon Redshift. في هذا المنشور ، نستخدم جلسات تفاعلية داخل دفتر ملاحظات AWS Glue Studio لتحميل ملف مجموعة بيانات NYC Taxi إلى أمازون Redshift Serverless الكتلة ، والاستعلام عن مجموعة البيانات المحملة ، وحفظ دفتر Jupyter الخاص بنا كمهمة ، وجدولته للتشغيل باستخدام تعبير cron. هيا بنا نبدأ.
حل نظرة عامة
نوجهك عبر الخطوات التالية:
- قم بإعداد دفتر AWS Glue Jupyter مع جلسات تفاعلية.
- استخدم سحر دفتر الملاحظات ، بما في ذلك اتصال AWS Glue والإشارات المرجعية.
- اقرأ البيانات من Amazon S3 ، وقم بتحويلها وتحميلها إلى Redshift Serverless.
- احفظ الكمبيوتر الدفتري كمهمة AWS Glue وجدولته للتشغيل.
المتطلبات الأساسية المسبقة
لهذه الإرشادات ، يجب علينا إكمال المتطلبات الأساسية التالية:
- تحميل سجلات رحلة تاكسي يلو تاكسي و جدول بحث منطقة سيارات الأجرة مجموعات البيانات في Amazon S3. يتم سرد خطوات القيام بذلك في القسم التالي.
- جهز ما يلزم إدارة الهوية والوصول AWS (IAM) وأدوار للعمل مع دفاتر AWS Glue Studio Jupyter وجلسات تفاعلية و AWS Glue.
- أنشئ اتصال AWS Glue لـ Redshift Serverless.
تحميل مجموعات البيانات إلى Amazon S3
تحميل سجلات رحلة تاكسي يلو تاكسي و بيانات جدول بحث منطقة سيارات الأجرة لبيئتك المحلية. بالنسبة لهذا المنشور ، نقوم بتنزيل بيانات يناير 2022 لبيانات سجلات رحلة التاكسي الصفراء بتنسيق باركيه. بيانات البحث عن منطقة سيارات الأجرة بتنسيق CSV. يمكنك أيضًا تنزيل ملف قاموس البيانات لمجموعة بيانات سجل الرحلة.
- على وحدة تحكم Amazon S3 ، إنشاء دلو تسمى
my-first-aws-glue-is-project-<random number>في الus-east-1منطقة لتخزين البيانات.يجب أن تكون أسماء حاويات S3 فريدة عبر جميع حسابات AWS في جميع المناطق. - إنشاء المجلدات
nyc_yellow_taxiوtaxi_zone_lookupفي الحاوية التي أنشأتها للتو وقم بتحميل الملفات التي قمت بتنزيلها.
يجب أن تبدو هياكل المجلدات الخاصة بك مثل لقطات الشاشة التالية.

إعداد سياسات IAM ودورها
دعنا نجهز سياسات ودور IAM الضروريين للعمل مع دفاتر AWS Glue Studio Jupyter وجلسات تفاعلية. لبدء استخدام أجهزة الكمبيوتر المحمولة في AWS Glue Studio ، يرجى الرجوع إلى بدء استخدام أجهزة الكمبيوتر المحمولة في AWS Glue Studio.
قم بإنشاء سياسات IAM لدور دفتر ملاحظات AWS Glue
قم بإنشاء السياسة AWSGlueInteractiveSessionPassRolePolicy بالأذونات التالية:
تسمح هذه السياسة لدور دفتر ملاحظات AWS Glue بالتمرير إلى الجلسات التفاعلية بحيث يمكن استخدام نفس الدور في كلا المكانين. لاحظ أن AWSGlueServiceRole-GlueIS هو الدور الذي أنشأناه لدفتر AWS Glue Studio Jupyter في خطوة لاحقة. بعد ذلك ، قم بإنشاء السياسة AmazonS3Access-MyFirstGlueISProject بالأذونات التالية:
تسمح هذه السياسة لدور دفتر ملاحظات AWS Glue بالوصول إلى البيانات الموجودة في حاوية S3.
أنشئ دور IAM لدفتر AWS Glue
أنشئ دور AWS Glue جديدًا يسمى AWSGlueServiceRole-GlueIS مع السياسات التالية المرفقة به:
أنشئ اتصال AWS Glue لـ Redshift Serverless
نحن الآن جاهزون لذلك تكوين مجموعة أمان Redshift Serverless للتواصل مع مكونات AWS Glue.
- في وحدة التحكم Redshift Serverless ، افتح مجموعة العمل التي تستخدمها.
يمكنك العثور على جميع مساحات الأسماء ومجموعات العمل على لوحة القيادة Redshift Serverless. - تحت الدخول الى البيانات، اختر الشبكة والأمن.
- اختر الارتباط لمجموعة أمان Redshift Serverless VPC.
 تتم إعادة توجيهك إلى الأمازون الحوسبة المرنة السحابية (Amazon EC2).
تتم إعادة توجيهك إلى الأمازون الحوسبة المرنة السحابية (Amazon EC2). - في تفاصيل مجموعة الأمان Redshift Serverless ، ضمن قواعد الداخل، اختر تحرير القواعد الواردة.
- أضف قاعدة مرجعية ذاتية للسماح لمكونات AWS Glue بالتواصل:
- في حالة النوع، اختر كل TCP.
- في حالة بروتوكول، اختر TCP.
- في حالة نطاق المنفذ ، تشمل جميع المنافذ.
- في حالة مصدر، استخدم نفس مجموعة الأمان مثل معرف المجموعة.

- وبالمثل ، أضف القواعد الصادرة التالية:
- قاعدة مرجعية ذاتية مع النوع as كل TCP, بروتوكول as TCP, نطاق المنفذ بما في ذلك جميع المنافذ و الرحلات كمجموعة الأمان نفسها مثل معرف المجموعة.
- قاعدة HTTPS للوصول إلى Amazon S3. ال
s3-prefix-list-idالقيمة مطلوبة في قاعدة مجموعة الأمان للسماح بحركة المرور من VPC إلى نقطة نهاية Amazon S3 VPC.
إذا لم يكن لديك نقطة نهاية Amazon S3 VPC ، فيمكنك إنشاء واحدة على سحابة أمازون الافتراضية الخاصة (Amazon VPC).

يمكنك التحقق من قيمة s3-prefix-list-id على قوائم البادئات المُدارة صفحة على وحدة تحكم Amazon VPC.

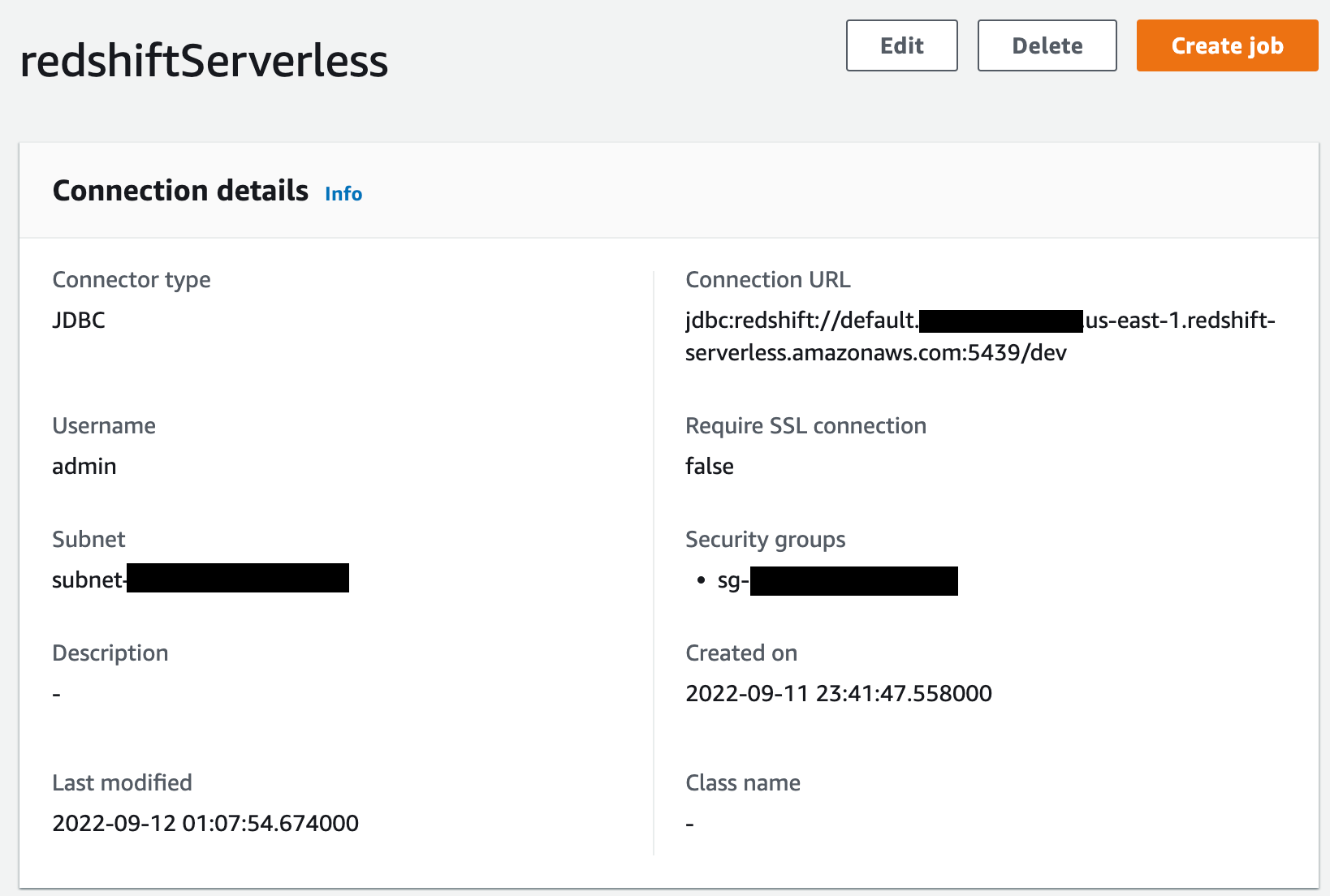
بعد ذلك ، اذهب إلى الموصلات صفحة على AWS Glue Studio و إنشاء اتصال JDBC جديد تسمى redshiftServerless إلى مجموعة Redshift Serverless الخاصة بك (ما لم تكن موجودة بالفعل). يمكنك العثور على تفاصيل نقطة نهاية Redshift Serverless ضمن مجموعة العمل الخاصة بك معلومات عامة الجزء. يبدو إعداد الاتصال مثل لقطة الشاشة التالية.
اكتب رمزًا تفاعليًا على كمبيوتر محمول AWS Glue Studio Jupyter مدعوم بجلسات تفاعلية
يمكنك الآن البدء في كتابة تعليمات برمجية تفاعلية باستخدام دفتر AWS Glue Studio Jupyter المدعوم بجلسات تفاعلية. لاحظ أنه من الممارسات الجيدة الاستمرار في حفظ الكمبيوتر الدفتري على فترات منتظمة أثناء العمل من خلاله.
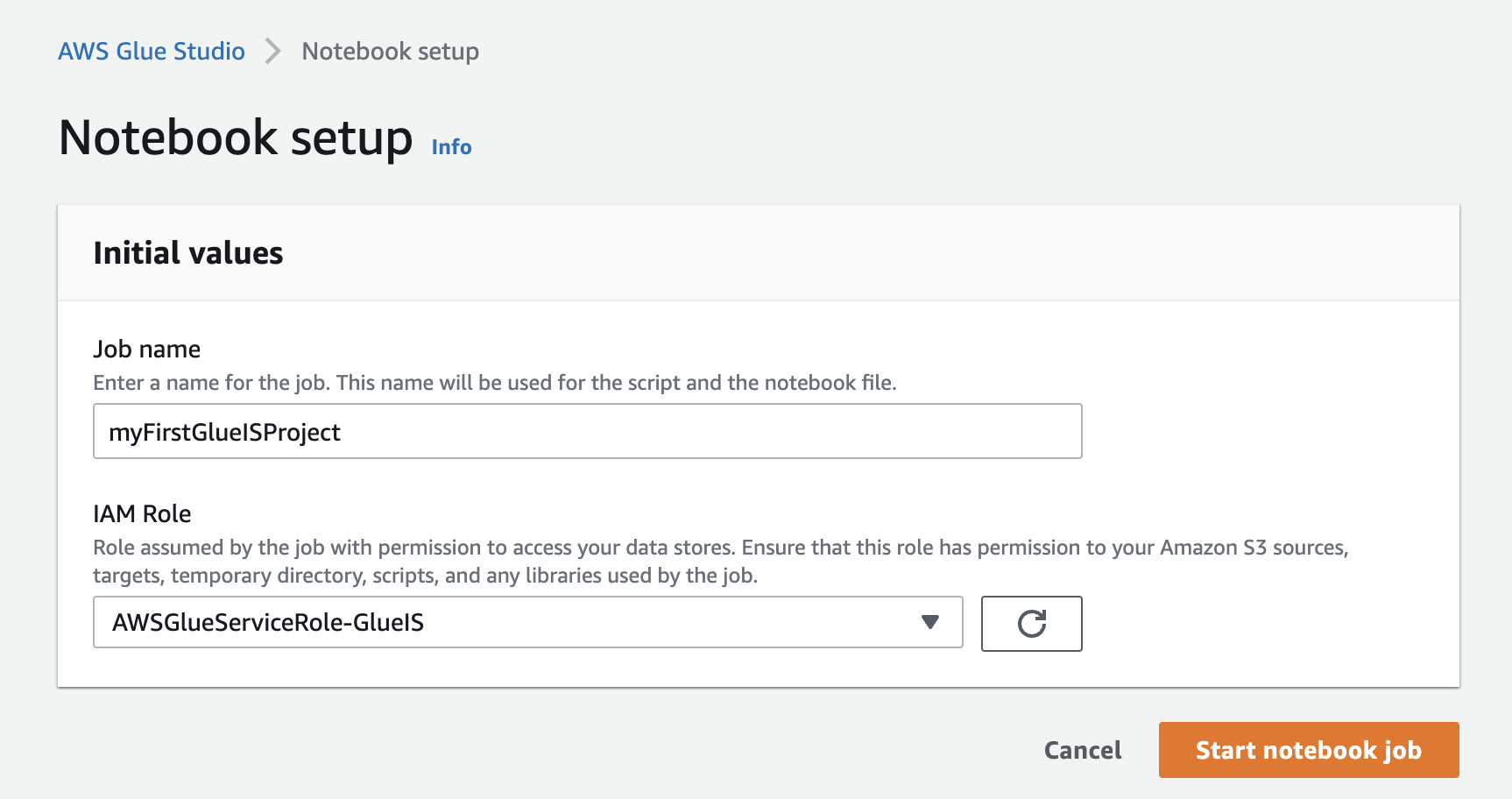
- في وحدة تحكم AWS Glue Studio ، أنشئ وظيفة جديدة.
- أختار مفكرة Jupyter وحدد قم بإنشاء دفتر ملاحظات جديد من البداية.
- اختار إنشاء.

- في حالة اسم العمل، أدخل اسمًا (على سبيل المثال ،
myFirstGlueISProject). - في حالة دور IAM ، اختر الدور الذي قمت بإنشائه (
AWSGlueServiceRole-GlueIS). - اختار ابدأ مهمة الكمبيوتر المحمول.
 بعد تهيئة دفتر الملاحظات ، يمكنك رؤية بعض العناصر السحرية المتاحة وخلية برمز معياري. لعرض جميع العناصر السحرية للجلسات التفاعلية ، قم بتشغيل
بعد تهيئة دفتر الملاحظات ، يمكنك رؤية بعض العناصر السحرية المتاحة وخلية برمز معياري. لعرض جميع العناصر السحرية للجلسات التفاعلية ، قم بتشغيل %helpفي خلية لطباعة قائمة كاملة. فيما عدا%%sql، فإن تشغيل خلية من العناصر السحرية فقط لا يؤدي إلى بدء الجلسة ، ولكنه يحدد التكوين للجلسة التي تبدأ عند تشغيل الخلية الأولى من التعليمات البرمجية. بالنسبة لهذا المنشور ، قمنا بتكوين AWS Glue بالإصدار 3.0 ، وثلاثة عمال G.1X ، ومهلة الخمول ، واتصال Amazon Redshift بمساعدة العناصر السحرية المتاحة.
بالنسبة لهذا المنشور ، قمنا بتكوين AWS Glue بالإصدار 3.0 ، وثلاثة عمال G.1X ، ومهلة الخمول ، واتصال Amazon Redshift بمساعدة العناصر السحرية المتاحة. - دعنا ندخل العناصر السحرية التالية في خليتنا الأولى ونشغلها:
حصلنا على الرد التالي:
- لنقم بتشغيل خلية الكود الأولى (رمز معياري) لبدء جلسة دفتر ملاحظات تفاعلية في غضون ثوانٍ قليلة:
حصلنا على الرد التالي:
- بعد ذلك ، اقرأ بيانات سيارة الأجرة الصفراء في مدينة نيويورك من حاوية S3 في إطار AWS Glue الديناميكي:
دعنا نحسب عدد الصفوف ، ونلقي نظرة على المخطط وبعض صفوف مجموعة البيانات.
- عد الصفوف بالكود التالي:
حصلنا على الرد التالي:
- اعرض المخطط مع الكود التالي:
حصلنا على الرد التالي:
- اعرض بضعة صفوف من مجموعة البيانات بالشفرة التالية:
حصلنا على الرد التالي:
- الآن ، اقرأ بيانات البحث عن منطقة سيارات الأجرة من حاوية S3 في إطار AWS Glue الديناميكي:
دعنا نحسب عدد الصفوف ، ونلقي نظرة على المخطط وبعض صفوف مجموعة البيانات.
- عد الصفوف بالكود التالي:
حصلنا على الرد التالي:
- اعرض المخطط مع الكود التالي:
حصلنا على الرد التالي:
- اعرض بعض الصفوف بالكود التالي:
حصلنا على الرد التالي:
- استنادًا إلى قاموس البيانات ، يتيح إعادة معايرة أنواع بيانات السمات في الإطارات الديناميكية المقابلة لكلا الإطارات الديناميكية:
- الآن دعنا نتحقق من مخططهم:
حصلنا على الرد التالي:
حصلنا على الرد التالي:
- دعونا نضيف العمود
trip_durationلحساب مدة كل رحلة بالدقائق إلى الإطار الديناميكي لرحلة التاكسي:دعنا نحسب عدد الصفوف ، ونلقي نظرة على المخطط وعدد قليل من صفوف مجموعة البيانات بعد تطبيق التحويل أعلاه.
- احصل على عدد السجلات مع الكود التالي:
حصلنا على الرد التالي:
- اعرض المخطط مع الكود التالي:
حصلنا على الرد التالي:
- اعرض بعض الصفوف بالكود التالي:
حصلنا على الرد التالي:
- بعد ذلك ، قم بتحميل كل من الإطارات الديناميكية في مجموعة Amazon Redshift Serverless الخاصة بنا:
الآن دعنا نتحقق من صحة البيانات التي تم تحميلها في مجموعة Amazon Redshift Serverless عن طريق تشغيل بعض الاستعلامات في محرر استعلام Amazon Redshift v2. يمكنك أيضًا استخدام محرر الاستعلام المفضل لديك.
- أولاً ، نحسب عدد السجلات ونحدد بضعة صفوف في كلا الجدولين الهدف (
f_nyc_yellow_taxi_tripوd_nyc_taxi_zone_lookup):
عدد السجلات في
f_nyc_yellow_taxi_trip(2,463,931) وd_nyc_taxi_zone_lookup(265) تطابق عدد السجلات في إطار الإدخال الديناميكي الخاص بنا. هذا يؤكد أن جميع السجلات من الملفات في Amazon S3 قد تم تحميلها بنجاح في Amazon Redshift.يمكنك عرض بعض السجلات لكل جدول بالأوامر التالية:


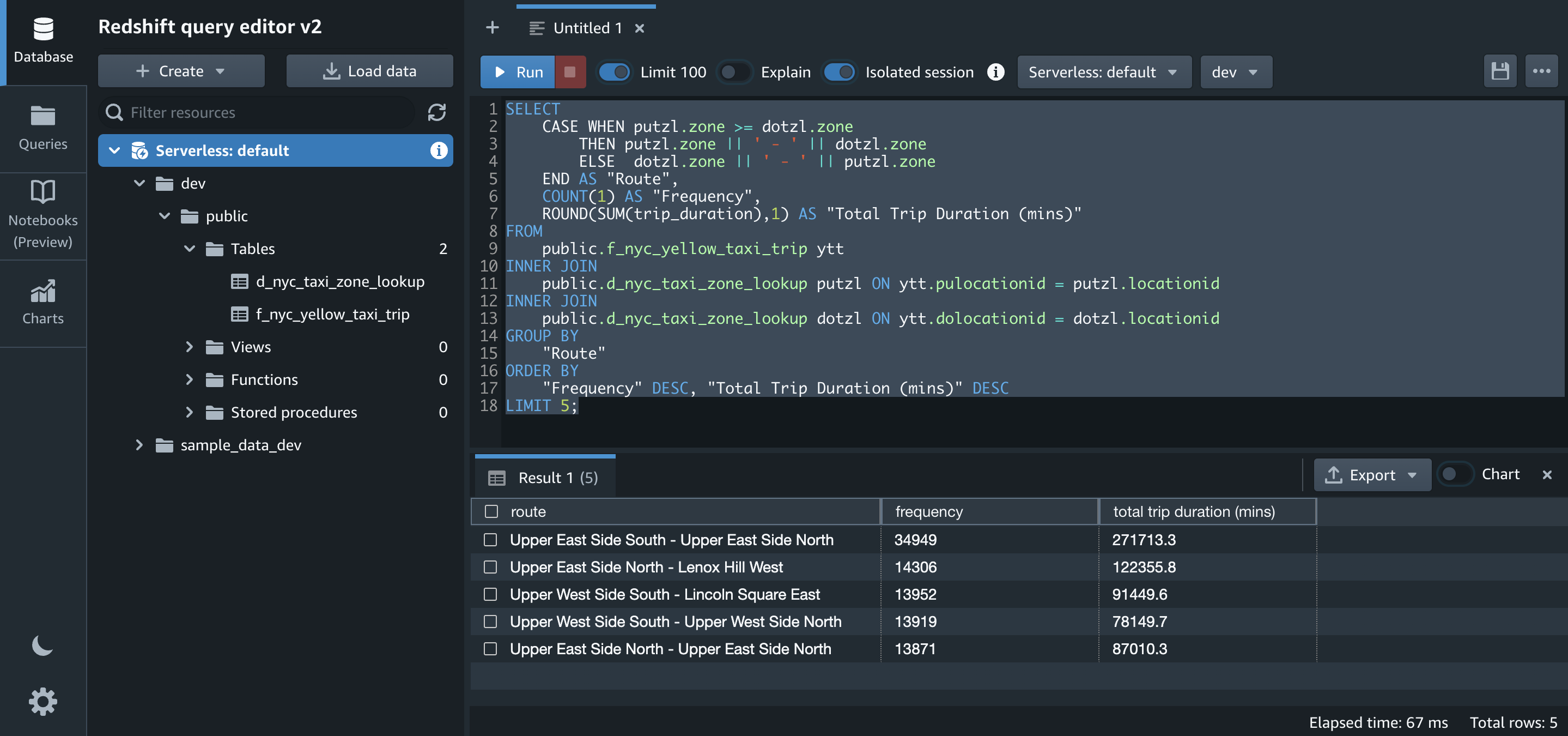
- تتمثل إحدى الأفكار التي نرغب في تكوينها من مجموعات البيانات في الحصول على أفضل خمسة مسارات مع مدة رحلتهم. لنقم بتشغيل SQL لذلك على Amazon Redshift:
قم بتحويل الكمبيوتر الدفتري إلى مهمة AWS Glue وجدولتها
الآن بعد أن قمنا بتأليف الكود واختبرنا وظائفه ، دعنا نحفظه كوظيفة ونقوم بجدولته.
دعونا أولا تمكين إشارات مرجعية للوظيفة. تساعد الإشارات المرجعية للوظائف AWS Glue في الحفاظ على معلومات الحالة ومنع إعادة معالجة البيانات القديمة. باستخدام الإشارات المرجعية للوظائف ، يمكنك معالجة البيانات الجديدة عند إعادة التشغيل في فترة زمنية مجدولة.
- أضف الأمر السحري التالي بعد الخلية الأولى التي تحتوي على أوامر سحرية أخرى تمت تهيئتها أثناء تأليف الكود:
لتهيئة الإشارات المرجعية للوظيفة ، نقوم بتشغيل الكود التالي باسم الوظيفة كمتغير افتراضي (
myFirstGlueISProjectلهذا المنصب). إشارات مرجعية للوظيفة تخزن الولايات لوظيفة ما. يجب أن يكون لديك دائمًاjob.init()في بداية البرنامج النصي وjob.commit()في نهاية البرنامج النصي. يتم استخدام هاتين الوظيفتين لتهيئة خدمة الإشارات المرجعية وتحديث تغيير الحالة إلى الخدمة. لن تعمل الإشارات المرجعية دون الاتصال بها. - أضف الجزء التالي من الكود بعد الكود المعياري:
- ثم قم بالتعليق على جميع أسطر الكود التي تم تأليفها للتحقق من النتيجة المرجوة وليست ضرورية للوظيفة لتحقيق غرضها:
- احفظ دفتر الملاحظات.

يمكنك التحقق من البرنامج النصي المقابل على ملف سيناريو علامة التبويب.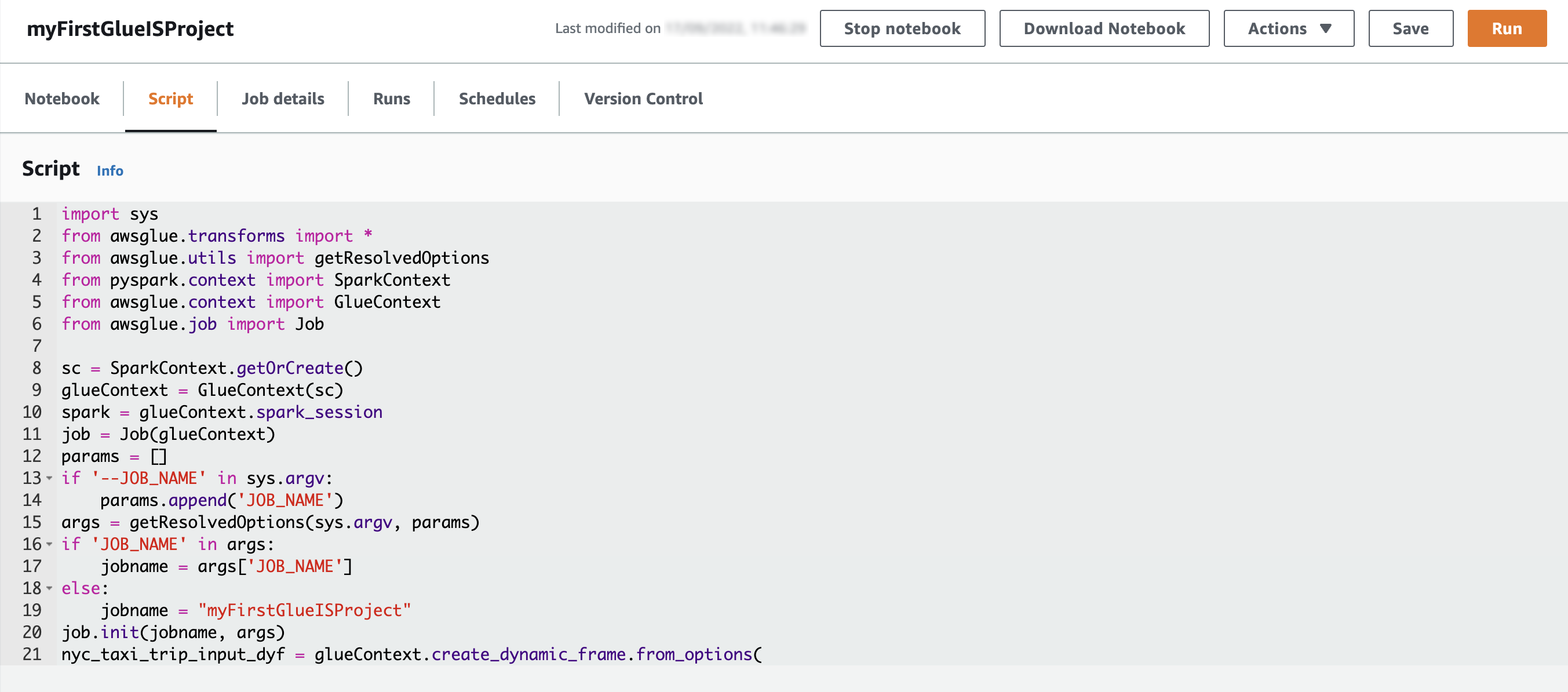 نلاحظ أن
نلاحظ أن job.commit()تتم إضافته تلقائيًا في نهاية البرنامج النصي ، فلنقم بتشغيل دفتر الملاحظات كوظيفة. - أولاً ، اقتطاع
f_nyc_yellow_taxi_tripوd_nyc_taxi_zone_lookupالجداول في Amazon Redshift باستخدام محرر الاستعلام v2 حتى لا يكون لدينا تكرارات في كلا الجدولين: - اختار يجري لتشغيل الوظيفة.
 يمكنك التحقق من حالته على أشواط علامة التبويب.
يمكنك التحقق من حالته على أشواط علامة التبويب. اكتملت المهمة في أقل من 5 دقائق مع G1.x 3 DPU.
اكتملت المهمة في أقل من 5 دقائق مع G1.x 3 DPU. - دعنا نتحقق من عدد السجلات في
f_nyc_yellow_taxi_tripوd_nyc_taxi_zone_lookupالجداول في Amazon Redshift:
مع تمكين الإشارات المرجعية للوظائف ، حتى إذا قمت بتشغيل الوظيفة مرة أخرى بدون وجود ملفات جديدة في المجلدات المقابلة في حاوية S3 ، فإنها لا تعالج نفس الملفات مرة أخرى. تُظهر لقطة الشاشة التالية مهمة لاحقة يتم تشغيلها في بيئتي ، والتي اكتملت في أقل من دقيقتين نظرًا لعدم وجود ملفات جديدة لمعالجتها.
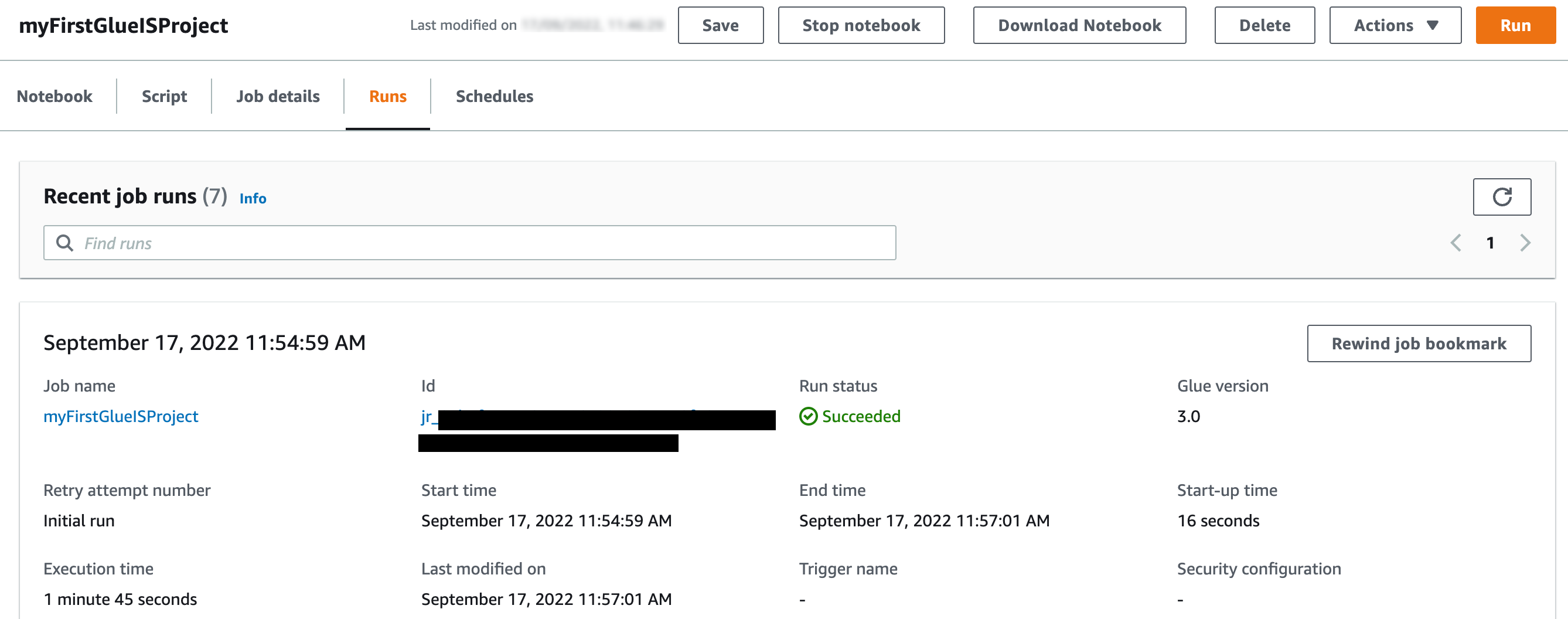
الآن دعنا نحدد الوظيفة.
- على جداول علامة التبويب، اختر إنشاء جدول.

- في حالة الاسم¸ أدخل اسمًا (على سبيل المثال ،
myFirstGlueISProject-testSchedule). - في حالة تردد، اختر Custom.
- أدخل تعبير cron حتى يتم تشغيل الوظيفة كل يوم اثنين الساعة 6:00 صباحًا.
- أضف وصفًا اختياريًا.
- اختار إنشاء جدول.

تم حفظ الجدول الزمني وتفعيله. يمكنك تعديل الجدول أو إيقافه مؤقتًا أو استئنافه أو حذفه من ملف الإجراءات القائمة.
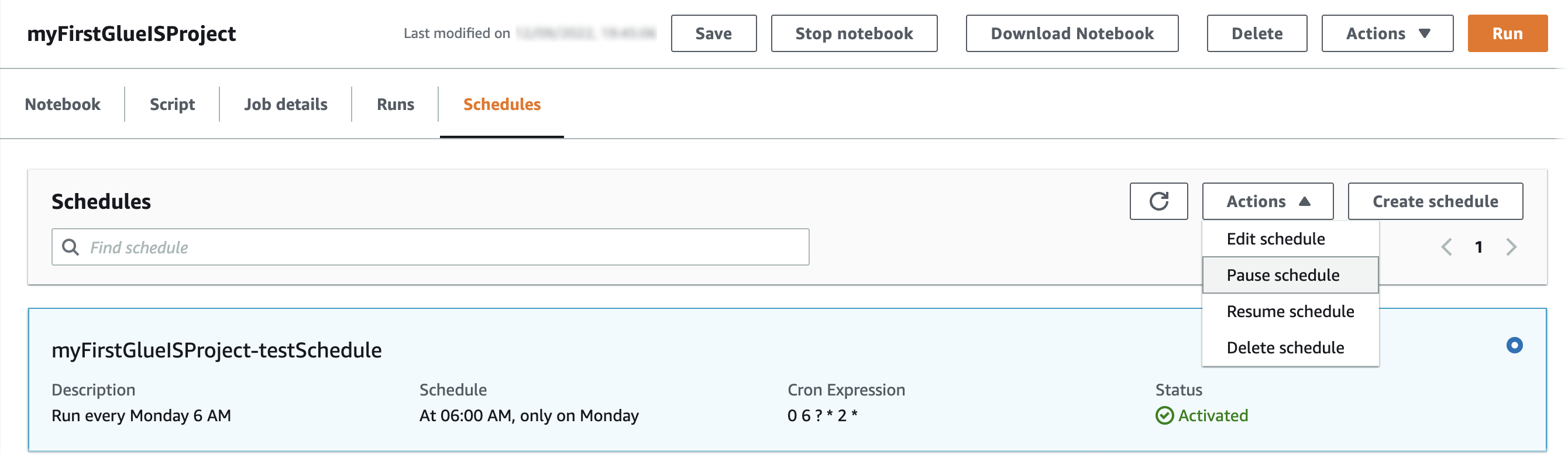
تنظيف
لتجنب تكبد رسوم في المستقبل ، احذف موارد AWS التي أنشأتها.
- حذف مهمة AWS Glue (
myFirstGlueISProjectلهذا المنصب). - احذف عناصر ودلو Amazon S3 (
my-first-aws-glue-is-project-<random number>لهذا المنصب). - حذف سياسات وأدوار AWS IAM (
AWSGlueInteractiveSessionPassRolePolicy,AmazonS3Access-MyFirstGlueISProjectوAWSGlueServiceRole-GlueIS). - احذف جداول Amazon Redshift (
f_nyc_yellow_taxi_tripوd_nyc_taxi_zone_lookup). - احذف اتصال AWS Glue JDBC (
redshiftServerless). - احذف أيضًا مجموعة الأمان Redshift Serverless ذات المرجع الذاتي ، ونقطة نهاية Amazon S3 (إذا قمت بإنشائها أثناء اتباع الخطوات الخاصة بهذا المنشور).
وفي الختام
في هذا المنشور ، أوضحنا كيفية القيام بما يلي:
- قم بإعداد دفتر AWS Glue Jupyter مع جلسات تفاعلية
- استخدم العناصر السحرية للكمبيوتر الدفتري ، بما في ذلك اتصال AWS Glue على متن الطائرة والإشارات المرجعية
- اقرأ البيانات من Amazon S3 ، وقم بتحويلها وتحميلها إلى Amazon Redshift Serverless
- تكوين السحر لتمكين الإشارات المرجعية للوظائف ، وحفظ دفتر الملاحظات كمهمة AWS Glue ، وجدولتها باستخدام تعبير cron
الهدف من هذا المنشور هو تزويدك بأساسيات خطوة بخطوة لمساعدتك في استخدام أجهزة الكمبيوتر المحمولة AWS Glue Studio Jupyter والجلسات التفاعلية. يمكنك إعداد دفتر AWS Glue Jupyter في دقائق ، وبدء جلسة تفاعلية في ثوانٍ ، وتحسين تجربة التطوير بشكل كبير مع وظائف AWS Glue. الجلسات التفاعلية لها حد أدنى للفواتير مدته دقيقة واحدة مع ميزات التحكم في التكلفة التي تقلل من تكلفة تطوير تطبيقات إعداد البيانات. يمكنك إنشاء واختبار التطبيقات من البيئة التي تختارها ، حتى في بيئتك المحلية ، باستخدام الواجهة الخلفية للجلسات التفاعلية.
توفر الجلسات التفاعلية طريقة أسرع وأرخص وأكثر مرونة لإنشاء تطبيقات تحضير البيانات والتحليلات وتشغيلها. لمعرفة المزيد حول الجلسات التفاعلية ، ارجع إلى تطوير الوظائف (جلسات تفاعلية)، وابدأ في استكشاف تجربة تطوير جديدة بالكامل باستخدام AWS Glue. بالإضافة إلى ذلك ، تحقق من المنشورات التالية لتصفح المزيد من الأمثلة على استخدام الجلسات التفاعلية مع خيارات مختلفة:
حول المؤلف
 فيكاس عمر هو مهندس حلول متخصص رئيسي في التحليلات في Amazon Web Services. تتمتع Vikas بخلفية قوية في التحليلات وإدارة تجربة العملاء (CEM) واستثمار البيانات ، مع أكثر من 13 عامًا من الخبرة في هذا المجال على مستوى العالم. من خلال ست شهادات AWS ، بما في ذلك تخصص التحليلات ، فهو مدافع موثوق به في مجال التحليلات لعملاء وشركاء AWS. يحب السفر ومقابلة العملاء ومساعدتهم على النجاح في ما يفعلونه.
فيكاس عمر هو مهندس حلول متخصص رئيسي في التحليلات في Amazon Web Services. تتمتع Vikas بخلفية قوية في التحليلات وإدارة تجربة العملاء (CEM) واستثمار البيانات ، مع أكثر من 13 عامًا من الخبرة في هذا المجال على مستوى العالم. من خلال ست شهادات AWS ، بما في ذلك تخصص التحليلات ، فهو مدافع موثوق به في مجال التحليلات لعملاء وشركاء AWS. يحب السفر ومقابلة العملاء ومساعدتهم على النجاح في ما يفعلونه.
 نوريتاكا سيكياما هو مهندس رئيسي للبيانات الضخمة في فريق AWS Glue. إنه يستمتع بالتعاون مع فرق مختلفة لتقديم نتائج مثل هذه المشاركة. في أوقات فراغه ، يستمتع بلعب ألعاب الفيديو مع عائلته.
نوريتاكا سيكياما هو مهندس رئيسي للبيانات الضخمة في فريق AWS Glue. إنه يستمتع بالتعاون مع فرق مختلفة لتقديم نتائج مثل هذه المشاركة. في أوقات فراغه ، يستمتع بلعب ألعاب الفيديو مع عائلته.
 غال هاين هو مدير منتج في AWS Glue ولديه أكثر من 15 عامًا من الخبرة كمدير منتج ومهندس بيانات ومهندس بيانات. إنها متحمسة لتطوير فهم عميق لاحتياجات عمل العملاء والتعاون مع المهندسين لتصميم منتجات بيانات أنيقة وقوية وسهلة الاستخدام. حصلت غال على درجة الماجستير في علوم البيانات من جامعة كاليفورنيا في بيركلي وهي تستمتع بالسفر ولعب ألعاب الطاولة والذهاب إلى الحفلات الموسيقية.
غال هاين هو مدير منتج في AWS Glue ولديه أكثر من 15 عامًا من الخبرة كمدير منتج ومهندس بيانات ومهندس بيانات. إنها متحمسة لتطوير فهم عميق لاحتياجات عمل العملاء والتعاون مع المهندسين لتصميم منتجات بيانات أنيقة وقوية وسهلة الاستخدام. حصلت غال على درجة الماجستير في علوم البيانات من جامعة كاليفورنيا في بيركلي وهي تستمتع بالسفر ولعب ألعاب الطاولة والذهاب إلى الحفلات الموسيقية.
- كوينسمارت. أفضل بورصة للبيتكوين والعملات المشفرة في أوروبا.انقر هنا لمعرفة ذلك
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/get-started-with-data-integration-from-amazon-s3-to-amazon-redshift-using-aws-glue-interactive-sessions/

