المُقدّمة
هل تساءلت يومًا عن مدى روعة الدردشة باستخدام مقطع فيديو؟ بصفتي شخصًا في مدونة ، غالبًا ما أشعر بالملل لمشاهدة مقطع فيديو مدته ساعة للعثور على المعلومات ذات الصلة. في بعض الأحيان ، يبدو الأمر وكأنه وظيفة لمشاهدة مقطع فيديو للحصول على أي معلومات مفيدة منه. لذا ، فقد أنشأت روبوت محادثة يتيح لك الدردشة مع مقاطع فيديو YouTube أو أي فيديو. أصبح هذا ممكنًا بواسطة GPT-3.5-turbo و Langchain و ChromaDB و Whisper و Gradio. لذلك ، في هذه المقالة ، سأقوم بعمل تجول برمجي لبناء روبوت محادثة وظيفي لمقاطع فيديو YouTube باستخدام Langchain.
أهداف التعلم
- قم ببناء واجهة الويب باستخدام Gradio
- تعامل مع مقاطع فيديو YouTube واستخرج البيانات النصية منها باستخدام Whisper
- معالجة النصوص وتنسيقها بشكل مناسب
- إنشاء حفلات الزفاف للبيانات النصية
- تكوين Chroma DB لتخزين البيانات
- ابدأ سلسلة محادثة Langchain باستخدام وظيفة OpenAI chatGPT و ChromaDB و embeddings
- أخيرًا ، الاستعلام عن الإجابات وتدفقها إلى برنامج دردشة Gradio
قبل الدخول في جزء الترميز ، دعنا نتعرف على الأدوات والتقنيات التي سنستخدمها.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
لانغتشين
Langchain هي أداة مفتوحة المصدر مكتوبة بلغة Python تجعل بيانات نماذج اللغات الكبيرة واعية ووكيلة. إذن ، ماذا يعني ذلك؟ معظم LLMs المتاحة تجاريًا ، مثل GPT-3.5 و GPT-4 ، لها حدود على البيانات التي تم تدريبهم عليها. على سبيل المثال ، يمكن لـ ChatGPT الإجابة على الأسئلة التي شاهدها بالفعل فقط. أي شيء بعد سبتمبر 2021 غير معروف لها. هذه هي القضية الأساسية التي يحلها Langchain. سواء كان ذلك مستند Word أو أي ملف PDF شخصي ، يمكننا تغذية البيانات إلى LLM والحصول على استجابة شبيهة بالإنسان. يحتوي على أغلفة لأدوات مثل Vector DBs ونماذج الدردشة ووظائف التضمين ، مما يجعل من السهل إنشاء تطبيق AI باستخدام Langchain فقط.
يسمح لنا Langchain أيضًا ببناء Agents - LLM bots. يمكن تكوين هذه الوكلاء المستقلين للقيام بمهام متعددة ، بما في ذلك تحليل البيانات واستعلام SQL وحتى كتابة الرموز الأساسية. هناك الكثير من الأشياء التي يمكننا أتمتتها باستخدام هذه الوكلاء. هذا مفيد حيث يمكننا الاستعانة بمصادر خارجية للعمل المعرفي منخفض المستوى إلى ماجستير ، مما يوفر لنا الوقت والطاقة.
في هذا المشروع ، سنستخدم أدوات Langchain لإنشاء تطبيق دردشة لمقاطع الفيديو. لمزيد من المعلومات حول Langchain ، قم بزيارة موقعهم موقع رسمي.
همس
همس هي سلالة أخرى من OpenAI. إنه نموذج لتحويل الكلام إلى نص للأغراض العامة يمكنه تحويل الصوت أو مقاطع الفيديو إلى نص. يتم تدريبه على كمية كبيرة من الأصوات المتنوعة لأداء الترجمة متعددة اللغات والتعرف على الكلام والتصنيف.
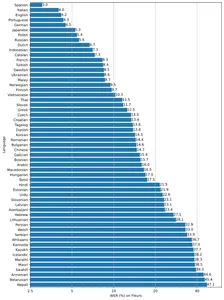
يتوفر النموذج بخمسة أحجام مختلفة صغيرة وقاعدة ومتوسطة وصغيرة وكبيرة ، مع مقايضات السرعة والدقة. يعتمد أداء النماذج أيضًا على اللغة. يوضح الشكل أدناه تفصيل WER (معدل خطأ الكلمات) حسب لغات مجموعة بيانات Fleur باستخدام نموذج الإصدار 2 الكبير.
قواعد بيانات المتجهات
لا تستطيع معظم خوارزميات التعلم الآلي معالجة البيانات الأولية غير المهيكلة مثل الصور والصوت والفيديو والنصوص. يجب تحويلها إلى مصفوفات من الزخارف المتجهية. تمثل هذه الزخارف المتجهية البيانات المذكورة في مستوى متعدد الأبعاد. للحصول على حفلات الزفاف ، نحتاج إلى نماذج عالية الكفاءة للتعلم العميق قادرة على التقاط المعنى الدلالي للبيانات. هذا مهم للغاية لإنشاء أي تطبيق AI. لتخزين هذه البيانات والاستعلام عنها ، نحتاج إلى قواعد بيانات قادرة على التعامل معها بفعالية. أدى ذلك إلى إنشاء قواعد بيانات متخصصة تسمى قواعد بيانات المتجهات. هناك العديد من قواعد البيانات مفتوحة المصدر. تعد Chroma و Milvus و Weaviate و FAISS من أشهرها.
USP آخر لمتاجر المتجهات هو أنه يمكننا إجراء عمليات بحث عالية السرعة على بيانات غير منظمة. بمجرد أن نحصل على حفلات الزفاف ، يمكننا استخدامها للتجميع والبحث والفرز والتصنيف. نظرًا لوجود نقاط البيانات في مساحة متجه ، يمكننا حساب المسافة بينها لمعرفة مدى ارتباطها الوثيق. تُستخدم خوارزميات متعددة مثل تشابه جيب التمام ، والمسافة الإقليدية ، و KNN ، و ANN (أقرب الجار التقريبي) للعثور على نقاط بيانات مماثلة.
سوف نستخدم صفاء متجر المتجهات - قاعدة بيانات موجهة مفتوحة المصدر. تتمتع Chroma أيضًا بتكامل Langchain ، والذي سيكون مفيدًا جدًا.
Gradio
الفارس الرابع لتطبيقنا Gradio هو مكتبة مفتوحة المصدر لمشاركة نماذج التعلم الآلي بسهولة. يمكن أن يساعد أيضًا في إنشاء تطبيقات ويب تجريبية بمكوناتها وأحداثها باستخدام Python.
إذا لم تكن معتادًا على Gradio و Langchain ، فاقرأ المقالات التالية قبل المضي قدمًا.
لنبدأ الآن في بنائه.
إعداد Dev Env
لإعداد بيئة التطوير ، قم بإنشاء Python بيئة افتراضية أو أنشئ بيئة تطوير محلية باستخدام Docker.
الآن قم بتثبيت كل هذه التبعيات
pytube==15.0.0
gradio == 3.27.0
openai == 0.27.4
langchain == 0.0.148
chromadb == 0.3.21
tiktoken == 0.3.3
openai-whisper==20230314 استيراد مكتبات
import os
import tempfile
import whisper
import datetime as dt
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from pytube import YouTube
from typing import TYPE_CHECKING, Any, Generator, List
إنشاء واجهة ويب
سوف نستخدم Gradio Block والمكونات لبناء الواجهة الأمامية لتطبيقنا. إذن ، إليك كيفية إنشاء الواجهة. لا تتردد في تخصيص ما تراه مناسبًا.
with gr.Blocks() as demo: with gr.Row(): # with gr.Group(): with gr.Column(scale=0.70): api_key = gr.Textbox(placeholder='Enter OpenAI API key', show_label=False, interactive=True).style(container=False) with gr.Column(scale=0.15): change_api_key = gr.Button('Change Key') with gr.Column(scale=0.15): remove_key = gr.Button('Remove Key') with gr.Row(): with gr.Column(): chatbot = gr.Chatbot(value=[]).style(height=650) query = gr.Textbox(placeholder='Enter query here', show_label=False).style(container=False) with gr.Column(): video = gr.Video(interactive=True,) start_video = gr.Button('Initiate Transcription') gr.HTML('OR') yt_link = gr.Textbox(placeholder='Paste a YouTube link here', show_label=False).style(container=False) yt_video = gr.HTML(label=True) start_ytvideo = gr.Button('Initiate Transcription') gr.HTML('Please reset the app after being done with the app to remove resources') reset = gr.Button('Reset App') if __name__ == "__main__": demo.launch() ستظهر الواجهة هكذا

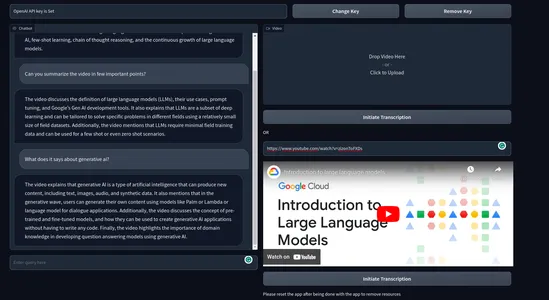
هنا ، لدينا مربع نصي يأخذ مفتاح OpenAI كمدخل. وأيضًا مفتاحان لتغيير مفتاح API وحذف المفتاح. لدينا أيضًا واجهة مستخدم دردشة على اليسار ومربع لعرض مقاطع الفيديو المحلية على اليمين. أسفل مربع الفيديو مباشرة ، لدينا مربع يطلب رابط YouTube والأزرار التي تقول "بدء النسخ".
أحداث Gradio
الآن سنحدد الأحداث لجعل التطبيق تفاعليًا. أضف الرموز أدناه في نهاية gr.Blocks ().
start_video.click(fn=lambda :(pause, update_yt), outputs=[start2, yt_video]).then( fn=embed_video, inputs=, outputs=).success( fn=lambda:resume, outputs=[start2]) start_ytvideo.click(fn=lambda :(pause, update_video), outputs=[start1,video]).then( fn=embed_yt, inputs=[yt_link], outputs = [yt_video, chatbot]).success( fn=lambda:resume, outputs=[start1]) query.submit(fn=add_text, inputs=[chatbot, query], outputs=[chatbot]).success( fn=QuestionAnswer, inputs=[chatbot,query,yt_link,video], outputs=[chatbot,query]) api_key.submit(fn=set_apikey, inputs=api_key, outputs=api_key)
change_api_key.click(fn=enable_api_box, outputs=api_key) remove_key.click(fn = remove_key_box, outputs=api_key)
reset.click(fn = reset_vars, outputs=[chatbot,query, video, yt_video, ])- بداية_فيديو: عند النقر عليه ، سيتم تشغيل عملية الحصول على نصوص من الفيديو وإنشاء سلسلة محادثة.
- start_ytvideo: عند النقر عليه ، سيفعل الشيء نفسه ولكن الآن من فيديو YouTube ، وعند الانتهاء سيعرض فيديو YouTube أسفله مباشرة.
- الاستعلام: مسؤول عن دفق الاستجابة من LLM إلى واجهة مستخدم الدردشة.
بقية الأحداث مخصصة للتعامل مع مفتاح واجهة برمجة التطبيقات وإعادة تعيين التطبيق.
لقد حددنا الأحداث ولكننا لم نحدد الوظائف المسؤولة عن إطلاق الأحداث.
الخلفية
حتى لا نجعل الأمر معقدًا وفوضويًا ، سنحدد العمليات التي سنتعامل معها في الخلفية.
- التعامل مع مفاتيح API.
- التعامل مع الفيديو المحمّل.
- نسخ مقاطع الفيديو للحصول على نصوص.
- قم بإنشاء أجزاء من نصوص الفيديو.
- إنشاء حفلات الزفاف من النصوص.
- تخزين ناقلات الزفاف في متجر ناقلات ChromaDB.
- قم بإنشاء سلسلة استرداد محادثة باستخدام Langchain.
- أرسل المستندات ذات الصلة إلى نموذج دردشة OpenAI (gpt-3.5-turbo).
- أحضر الإجابة ودفقها على واجهة مستخدم الدردشة.
سنفعل كل هذه الأشياء جنبًا إلى جنب مع بعض الاستثناءات.
حدد بعض متغيرات البيئة.
chat_history = []
result = None
chain = None
run_once_flag = False
call_to_load_video = 0 enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set', interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) pause = gr.Button.update(interactive=False)
resume = gr.Button.update(interactive=True)
update_video = gr.Video.update(value = None) update_yt = gr.HTML.update(value=None) التعامل مع مفاتيح API
عندما يرسل المستخدم مفتاحًا ، يتم تعيينه كمتغير البيئة ، وسنقوم أيضًا بتعطيل مربع النص من الإدخال الإضافي. الضغط على مفتاح التغيير سيجعله قابل للتغيير مرة أخرى. سيؤدي النقر فوق مفتاح الإزالة إلى إزالة المفتاح.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box
def enable_api_box(): return enable_box
def remove_key_box(): os.environ['OPENAI_API_KEY'] = '' return remove_boxالتعامل مع مقاطع الفيديو
بعد ذلك ، سنتعامل مع مقاطع الفيديو التي تم تحميلها وروابط YouTube. سيكون لدينا وظيفتان مختلفتان تتعاملان مع كل حالة. بالنسبة إلى روابط YouTube ، سننشئ رابط تضمين iframe. لكل حالة ، سوف ندعو وظيفة أخرى صنع_سلسلة () مسؤول عن إنشاء السلاسل.
يتم تشغيل هذه الوظائف عندما يقوم شخص ما بتحميل مقطع فيديو أو يوفر رابطًا على YouTube ويضغط على زر النسخ.
def embed_yt(yt_link: str): # This function embeds a YouTube video into the page. # Check if the YouTube link is valid. if not yt_link: raise gr.Error('Paste a YouTube link') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Set the global variable `call_to_load_video` to 0. # This is used to keep track of how many times the function has been called. call_to_load_video = 0 # Create a chain using the YouTube link. make_chain(url=yt_link) # Get the URL of the YouTube video. url = yt_link.replace('watch?v=', '/embed/') # Create the HTML code for the embedded YouTube video. embed_html = f"""<iframe width="750" height="315" src="{url}" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>""" # Return the HTML code and an empty list. return embed_html, [] def embed_video(video=str | None): # This function embeds a video into the page. # Check if the video is valid. if not video: raise gr.Error('Upload a Video') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Create a chain using the video. make_chain(video=video) # Return the video and an empty list. return video, []إنشاء سلسلة
هذه واحدة من أهم الخطوات على الإطلاق. يتضمن ذلك إنشاء متجر Chroma vector وسلسلة Langchain. سوف نستخدم سلسلة استرجاع محادثة لحالة الاستخدام الخاصة بنا. سنستخدم حفلات زفاف OpenAI ، ولكن في عمليات النشر الفعلية ، سنستخدم أي نماذج تضمين مجانية مثل ترميز جملة Huggingface ، وما إلى ذلك.
def make_chain(url=None, video=None) -> (ConversationalRetrievalChain | Any | None): global chain, run_once_flag # Check if a YouTube link or video is provided if not url and not video: raise gr.Error('Please provide a YouTube link or Upload a video') if not run_once_flag: run_once_flag = True # Get the title from the YouTube link or video title = get_title(url, video).replace(' ','-') # Process the text from the video grouped_texts, time_list = process_text(url=url) if url else process_text(video=video) # Convert time_list to metadata format time_list = [{'source': str(t.time())} for t in time_list] # Create vector stores from the processed texts with metadata vector_stores = Chroma.from_texts(texts=grouped_texts, collection_name='test', embedding=OpenAIEmbeddings(), metadatas=time_list) # Create a ConversationalRetrievalChain from the vector stores chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.0), retriever= vector_stores.as_retriever( search_kwargs={"k": 5}), return_source_documents=True) return chain
- احصل على النصوص والبيانات الوصفية من عنوان URL على YouTube أو من ملف الفيديو.
- قم بإنشاء متجر Chroma vector من النصوص والبيانات الوصفية.
- قم ببناء سلسلة باستخدام OpenAI gpt-3.5-turbo و chroma vector store.
- سلسلة الإرجاع.
نصوص العملية
في هذه الخطوة ، سنقوم بالتقطيع المناسب للنصوص من مقاطع الفيديو وأيضًا إنشاء كائن البيانات الوصفية الذي استخدمناه في عملية بناء السلسلة أعلاه.
def process_text(video=None, url=None) -> tuple[list, list[dt.datetime]]: global call_to_load_video if call_to_load_video == 0: print('yes') # Call the process_video function based on the given video or URL result = process_video(url=url) if url else process_video(video=video) call_to_load_video += 1 texts, start_time_list = [], [] # Extract text and start time from each segment in the result for res in result['segments']: start = res['start'] text = res['text'] start_time = dt.datetime.fromtimestamp(start) start_time_formatted = start_time.strftime("%H:%M:%S") texts.append(''.join(text)) start_time_list.append(start_time_formatted) texts_with_timestamps = dict(zip(texts, start_time_list)) # Convert the timestamp strings to datetime objects formatted_texts = { text: dt.datetime.strptime(str(timestamp), '%H:%M:%S') for text, timestamp in texts_with_timestamps.items() } grouped_texts = [] current_group = '' time_list = [list(formatted_texts.values())[0]] previous_time = None time_difference = dt.timedelta(seconds=30) # Group texts based on time difference for text, timestamp in formatted_texts.items(): if previous_time is None or timestamp - previous_time <= time_difference: current_group += text else: grouped_texts.append(current_group) time_list.append(timestamp) current_group = text previous_time = time_list[-1] # Append the last group of texts if current_group: grouped_texts.append(current_group) return grouped_texts, time_list
- تأخذ الدالة process_text إما عنوان URL أو مسار فيديو. ثم يتم نسخ هذا الفيديو في وظيفة process_video ، ونحصل على النصوص النهائية.
- ثم نحصل على وقت بدء كل جملة (من Whisper) ونجمعها في 30 ثانية.
- نعيد أخيرًا النصوص المجمعة ووقت بدء كل مجموعة.
معالجة الفيديو
في هذه الخطوة ، نقوم بنسخ ملفات الفيديو أو الصوت والحصول على النصوص. سوف نستخدم نموذج قاعدة Whisper للنسخ.
def process_video(video=None, url=None) -> dict[str, str | list]: if url: file_dir = load_video(url) else: file_dir = video print('Transcribing Video with whisper base model') model = whisper.load_model("base") result = model.transcribe(file_dir) return resultبالنسبة لمقاطع فيديو YouTube ، نظرًا لأنه لا يمكننا معالجتها بشكل مباشر ، فسيتعين علينا التعامل معها بشكل منفصل. سنستخدم مكتبة تسمى Pytube لتنزيل الصوت أو الفيديو لفيديو YouTube. إذن ، إليك كيف يمكنك القيام بذلك.
def load_video(url: str) -> str: # This function downloads a YouTube video and returns the path to the downloaded file. # Create a YouTube object for the given URL. yt = YouTube(url) # Get the target directory. target_dir = os.path.join('/tmp', 'Youtube') # If the target directory does not exist, create it. if not os.path.exists(target_dir): os.mkdir(target_dir) # Get the audio stream of the video. stream = yt.streams.get_audio_only() # Download the audio stream to the target directory. print('----DOWNLOADING AUDIO FILE----') stream.download(output_path=target_dir) # Get the path of the downloaded file. path = target_dir + '/' + yt.title + '.mp4' # Return the path of the downloaded file. return path
- قم بإنشاء كائن YouTube لعنوان URL المحدد.
- إنشاء مسار دليل هدف مؤقت
- تحقق مما إذا كان المسار موجودًا وإلا قم بإنشاء الدليل
- قم بتنزيل الملف الصوتي للملف.
- احصل على دليل مسار الفيديو
كانت هذه هي العملية التصاعدية من الحصول على نصوص من مقاطع الفيديو إلى إنشاء السلسلة. الآن ، كل ما تبقى هو تكوين chatbot.
تكوين Chatbot
كل ما نحتاجه الآن هو إرسال استعلام و chat_history إليه لجلب إجاباتنا. لذلك ، سنحدد وظيفة لا يتم تشغيلها إلا عند تقديم استعلام.
def add_text(history, text): if not text: raise gr.Error('enter text') history = history + [(text,'')] return history def QuestionAnswer(history, query=None, url=None, video=None) -> Generator[Any | None, Any, None]: # This function answers a question using a chain of models. # Check if a YouTube link or a local video file is provided. if video and url: # Raise an error if both a YouTube link and a local video file are provided. raise gr.Error('Upload a video or a YouTube link, not both') elif not url and not video: # Raise an error if no input is provided. raise gr.Error('Provide a YouTube link or Upload a video') # Get the result of processing the video. result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) # Add the question and answer to the chat history. chat_history += [(query, result["answer"])] # For each character in the answer, append it to the last element of the history. for char in result['answer']: history[-1][-1] += char yield history, ''
نحن نقدم محفوظات الدردشة مع الاستعلام للحفاظ على سياق المحادثة. أخيرًا ، نقوم بدفق الإجابة مرة أخرى إلى chatbot. ولا تنس تحديد وظيفة إعادة التعيين لإعادة تعيين جميع القيم.
لذلك ، كان هذا كل شيء عن ذلك. الآن ، قم بتشغيل التطبيق الخاص بك وابدأ الدردشة مع مقاطع الفيديو.
هكذا يبدو المنتج النهائي
عرض الفيديو:
[المحتوى جزءا لا يتجزأ]
حالات الاستخدام الواقعية
يمكن أن يحتوي التطبيق الذي يسمح للمستخدم النهائي بالدردشة مع أي فيديو أو صوت على مجموعة واسعة من حالات الاستخدام. فيما يلي بعض حالات الاستخدام الواقعية لروبوت الدردشة هذا.
- التعليم: غالبًا ما يحضر الطلاب محاضرات فيديو مدتها ساعات. يمكن أن يساعد روبوت المحادثة هذا الطلاب في التعلم من مقاطع فيديو المحاضرات واستخراج المعلومات المفيدة بسرعة ، مما يوفر الوقت والطاقة. سيؤدي ذلك إلى تحسين تجربة التعلم بشكل كبير.
- القانونية: غالبًا ما يمر المحترفون القانونيون بإجراءات وإفادات قانونية مطولة لتحليل القضية أو إعداد المستندات أو البحث أو مراقبة الامتثال. يمكن لروبوت الدردشة مثل هذا أن يقطع شوطًا طويلاً في إلغاء مثل هذه المهام.
- تلخيص المحتوى: يمكن لهذا التطبيق تحليل محتوى الفيديو وإنشاء إصدارات نصية ملخصة. يتيح ذلك للمستخدم التعرف على أهم مقاطع الفيديو دون مشاهدته بالكامل.
- التفاعل مع العملاء: يمكن للعلامات التجارية دمج ميزة chatbot عبر الفيديو لمنتجاتها أو خدماتها. يمكن أن يكون هذا مفيدًا للشركات التي تبيع المنتجات أو الخدمات عالية التذكرة أو التي تتطلب الكثير من الشرح.
- ترجمة الفيديو: يمكننا ترجمة مجموعة النصوص إلى لغات أخرى. يمكن أن يسهل هذا التواصل عبر اللغات أو تعلم اللغة أو إمكانية الوصول لغير الناطقين بها.
هذه بعض حالات الاستخدام المحتملة التي يمكنني التفكير فيها. يمكن أن يكون هناك الكثير من التطبيقات المفيدة لروبوت الدردشة لمقاطع الفيديو.
وفي الختام
لذلك ، كان هذا كله يتعلق بإنشاء تطبيق ويب تجريبي عملي لروبوت محادثة لمقاطع الفيديو. لقد غطينا الكثير من المفاهيم في جميع أنحاء المقال. فيما يلي النقاط الرئيسية من المقال.
- لقد تعلمنا عن Langchain - أداة شائعة لإنشاء تطبيقات AI بسهولة.
- Whisper هو نموذج قوي لتحويل الكلام إلى نص بواسطة OpenAI. نموذج مفتوح المصدر يمكنه تحويل الصوت والفيديو إلى نص.
- لقد تعلمنا كيف تسهل قواعد بيانات المتجهات التخزين الفعال والاستعلام عن زخارف المتجهات.
- لقد أنشأنا تطبيق ويب وظيفيًا بالكامل من البداية باستخدام نماذج Langchain و Chroma و OpenAI.
- ناقشنا أيضًا حالات الاستخدام الواقعية المحتملة لبرنامج الدردشة الآلي الخاص بنا.
كان هذا كل شيء عن ذلك ، آمل أن تكون قد أحببت ذلك ، وفكر في متابعتي تويتر لمزيد من الأشياء المتعلقة بالتنمية.
مستودع جيثب: sunilkumardash9 / chatgpt-for-videos. إذا وجدت هذا مفيدًا ، فافعل ⭐ المستودع.
الأسئلة المتكررة
A. LangChain هو إطار عمل مفتوح المصدر يبسط عملية إنشاء التطبيقات باستخدام نماذج اللغات الكبيرة. يمكن استخدامه في مجموعة متنوعة من المهام ، بما في ذلك روبوتات المحادثة ، وتحليل المستندات ، وتحليل الكود ، والإجابة على الأسئلة ، والمهام التوليفية.
A. السلاسل هي سلسلة من الخطوات التي يتم تنفيذها بالترتيب. يتم استخدامها لتحديد مهمة أو عملية معينة. على سبيل المثال ، يمكن استخدام سلسلة لتلخيص مستند أو الإجابة عن سؤال أو إنشاء نص إبداعي.
الوكلاء أكثر تعقيدًا من السلاسل. يمكنهم اتخاذ قرارات بشأن الخطوات التي يجب تنفيذها ، ويمكنهم أيضًا التعلم من تجاربهم. غالبًا ما يتم استخدام الوكلاء في المهام التي تتطلب الكثير من الإبداع أو التفكير المنطقي ، على سبيل المثال ، تحليل البيانات وإنشاء الكود.
أ. 1. الإجراء: يقرر وكلاء العمل إجراءً ما لاتخاذ هذا الإجراء وتنفيذه خطوة واحدة في كل مرة. إنها أكثر تقليدية ومناسبة للمهام الصغيرة.
2. يقوم وكلاء التخطيط والتنفيذ أولاً بتحديد خطة العمل التي يجب اتخاذها ثم تنفيذ تلك الإجراءات واحدًا تلو الآخر. فهي أكثر تعقيدًا ومناسبة للمهام التي تتطلب المزيد من التخطيط والمرونة.
A. Langchain قادرة على دمج نماذج LLM والمحادثة. LLMs هي نماذج تأخذ إدخال سلسلة وتعيد استجابة سلسلة. تأخذ نماذج الدردشة قائمة برسائل الدردشة كإدخال وإخراج رسالة دردشة.
ج: نعم ، Lagchain هي أداة مجانية الاستخدام مفتوحة المصدر ، ولكن تتطلب معظم العمليات مفتاح OpenAI API الذي يفرض رسومًا.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون السيارات / المركبات الكهربائية ، كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- BlockOffsets. تحديث ملكية الأوفست البيئية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/06/build-a-chatgpt-for-youtube-videos-with-langchain/

