لبناء أي تطبيق ذكاء اصطناعي توليدي، يعد إثراء نماذج اللغات الكبيرة (LLMs) ببيانات جديدة أمرًا ضروريًا. وهنا يأتي دور تقنية الجيل المعزز للاسترجاع (RAG). RAG عبارة عن بنية للتعلم الآلي (ML) تستخدم مستندات خارجية (مثل ويكيبيديا) لزيادة معرفتها وتحقيق أحدث النتائج في المهام كثيفة المعرفة. . لاستيعاب مصادر البيانات الخارجية هذه، تطورت قواعد بيانات المتجهات، والتي يمكنها تخزين التضمينات المتجهة لمصدر البيانات والسماح بالبحث عن التشابه.
في هذا المنشور، نعرض كيفية إنشاء خط أنابيب استيعاب RAG لاستخراج وتحويل وتحميل (ETL) لاستيعاب كميات كبيرة من البيانات في ملف خدمة Amazon OpenSearch الكتلة والاستخدام Amazon Relational Database Service (Amazon RDS) لـ PostgreSQL مع ملحق pgvector كمخزن بيانات متجه. تطبق كل خدمة خوارزميات k-أقرب جار (k-NN) أو خوارزميات أقرب جار تقريبي (ANN) ومقاييس المسافة لحساب التشابه. نحن نقدم التكامل شعاع في آلية استرجاع المستندات السياقية الخاصة بـ RAG. راي هي مكتبة حوسبة موزعة مفتوحة المصدر، بايثون، للأغراض العامة. فهو يسمح بمعالجة البيانات الموزعة لإنشاء وتخزين التضمينات لكمية كبيرة من البيانات، بالتوازي عبر وحدات معالجة الرسومات المتعددة. نحن نستخدم مجموعة Ray مع وحدات معالجة الرسومات هذه لتشغيل الاستيعاب والاستعلام المتوازي لكل خدمة.
في هذه التجربة، نحاول تحليل الجوانب التالية لخدمة OpenSearch وامتداد pgvector على Amazon RDS:
- كمخزن متجه، القدرة على توسيع نطاق مجموعة بيانات كبيرة والتعامل معها مع عشرات الملايين من السجلات لـ RAG
- الاختناقات المحتملة في مسار استيعاب RAG
- كيفية تحقيق الأداء الأمثل في أوقات الاستيعاب والاستعلام لخدمة OpenSearch Service وAmazon RDS
لفهم المزيد حول مخازن البيانات المتجهة ودورها في بناء تطبيقات الذكاء الاصطناعي التوليدية، راجع دور مخازن البيانات المتجهة في تطبيقات الذكاء الاصطناعي التوليدية.
نظرة عامة على خدمة البحث المفتوح
خدمة OpenSearch هي خدمة مُدارة للتحليل الآمن والبحث وفهرسة بيانات الأعمال والبيانات التشغيلية. تدعم خدمة OpenSearch بيانات بحجم بيتابايت مع القدرة على إنشاء فهارس متعددة على البيانات النصية والمتجهة. مع التكوين الأمثل، فإنه يهدف إلى استدعاء عالية للاستعلامات. تدعم خدمة OpenSearch خدمة ANN بالإضافة إلى بحث k-NN الدقيق. تدعم خدمة OpenSearch مجموعة مختارة من الخوارزميات من نمسليب, فايسو لوسين المكتبات لتشغيل بحث k-NN. لقد أنشأنا فهرس ANN للبحث المفتوح باستخدام خوارزمية العالم الصغير الهرمي القابل للملاحة (HNSW) لأنه يعتبر طريقة بحث أفضل لمجموعات البيانات الكبيرة. لمزيد من المعلومات حول اختيار خوارزمية الفهرس، راجع اختر خوارزمية k-NN لحالة استخدامك على نطاق مليار مع OpenSearch.
نظرة عامة على Amazon RDS لـ PostgreSQL مع pgvector
يضيف ملحق pgvector بحثًا عن تشابه المتجهات مفتوح المصدر إلى PostgreSQL. من خلال استخدام ملحق pgvector، يمكن لـ PostgreSQL إجراء عمليات بحث تشابه على تضمينات المتجهات، مما يوفر للشركات حلاً سريعًا وفعالاً. يوفر pgvector نوعين من عمليات البحث عن تشابه المتجهات: أقرب جار بالضبط، والذي ينتج عنه استدعاء بنسبة 100%، وأقرب جار تقريبي (ANN)، والذي يوفر أداء أفضل من البحث الدقيق مع مقايضة عند الاستدعاء. بالنسبة لعمليات البحث عبر الفهرس، يمكنك اختيار عدد المراكز التي سيتم استخدامها في البحث، مع توفر المزيد من المراكز استدعاء أفضل مع مقايضة الأداء.
حل نظرة عامة
يوضح الرسم البياني التالي بنية الحل.

دعونا نلقي نظرة على المكونات الرئيسية بمزيد من التفصيل.
بيانات
نحن نستخدم بيانات OSCAR باعتبارها مجموعتنا ومجموعة بيانات SQUAD لتقديم نماذج من الأسئلة. يتم تحويل مجموعات البيانات هذه أولاً إلى ملفات باركيه. ثم نستخدم مجموعة Ray لتحويل بيانات الباركيه إلى زخارف. يتم استيعاب التضمينات التي تم إنشاؤها في خدمة OpenSearch وAmazon RDS باستخدام pgvector.
OSCAR (مجموعة مجمعة زاحفة مفتوحة كبيرة الحجم) عبارة عن مجموعة ضخمة متعددة اللغات يتم الحصول عليها عن طريق تصنيف اللغة وتصفية الزحف المشترك الجسم باستخدام غير ورقي بنيان. يتم توزيع البيانات حسب اللغة في كل من الشكل الأصلي والمكرر. تبلغ مجموعة بيانات Oscar Corpus حوالي 609 مليون سجل وتستهلك حوالي 4.5 تيرابايت كملفات JSONL أولية. يتم بعد ذلك تحويل ملفات JSONL إلى تنسيق Parquet، مما يقلل الحجم الإجمالي إلى 1.8 تيرابايت. وقمنا أيضًا بتقليص حجم مجموعة البيانات إلى 25 مليون سجل لتوفير الوقت أثناء الاستيعاب.
SQuAD (مجموعة بيانات الإجابة على الأسئلة في جامعة ستانفورد) هي مجموعة بيانات لفهم القراءة تتكون من أسئلة يطرحها العاملون في الحشود على مجموعة من مقالات ويكيبيديا، حيث تكون الإجابة على كل سؤال عبارة عن جزء من النص، أو امتداد، من مقطع القراءة المقابل، أو قد يكون السؤال غير قابل للإجابة. نحن نستخدم فرقة، مرخص ك CC-BY-SA 4.0، لتقديم أسئلة عينة. يحتوي على ما يقرب من 100,000 سؤال مع أكثر من 50,000 سؤال غير قابل للإجابة كتبها العاملون في الحشود لتبدو مشابهة للإجابة عليها.
مجموعة الأشعة للابتلاع وإنشاء عمليات تضمين المتجهات
في اختباراتنا، وجدنا أن وحدات معالجة الرسومات لها التأثير الأكبر على الأداء عند إنشاء التضمينات. لذلك، قررنا استخدام مجموعة Ray لتحويل النص الخام الخاص بنا وإنشاء التضمينات. شعاع هو إطار عمل موحد مفتوح المصدر يمكّن مهندسي تعلم الآلة ومطوري بايثون من توسيع نطاق تطبيقات بايثون وتسريع أعباء عمل تعلم الآلة. تتكون مجموعتنا من 5 g4dn.12xlarge الأمازون الحوسبة المرنة السحابية (أمازون EC2) مثيلات. تم تكوين كل مثيل باستخدام 4 وحدات معالجة رسوميات NVIDIA T4 Tensor Core و48 وحدة معالجة مركزية افتراضية و192 جيجا بايت من الذاكرة. بالنسبة لسجلاتنا النصية، انتهى بنا الأمر إلى تقسيم كل منها إلى 1,000 قطعة مع تداخل 100 قطعة. هذا ينقسم إلى حوالي 200 لكل سجل. بالنسبة للنموذج المستخدم لإنشاء التضمينات، فقد استقرنا عليه جميع mpnet-base-v2 لإنشاء مساحة متجهة ذات 768 بُعدًا.
إعداد البنية التحتية
استخدمنا أنواع مثيلات RDS التالية وتكوينات مجموعة خدمة OpenSearch لإعداد بنيتنا التحتية.
فيما يلي خصائص نوع مثيل RDS الخاص بنا:
- نوع المثيل: db.r7g.12xlarge
- مساحة التخزين المخصصة: 20 تيرابايت
- متعدد من الألف إلى الياء: صحيح
- التخزين المشفر: صحيح
- تمكين رؤى الأداء: صحيح
- الاحتفاظ برؤى الأداء: 7 أيام
- نوع التخزين: gp3
- IOPS المتوفرة: 64,000
- نوع الفهرس: التلقيح الصناعي
- عدد القوائم: 5,000
- وظيفة المسافة: L2
فيما يلي خصائص مجموعة خدمة OpenSearch الخاصة بنا:
- الإصدار: 2.5
- عقد البيانات: 10
- نوع مثيل عقدة البيانات: r6g.4xlarge
- العقد الأساسية: 3
- نوع مثيل العقدة الأساسية: r6g.xlarge
- الفهرس: محرك HNSW:
nmslib - الفاصل الزمني للتحديث: 30 ثانية
ef_construction: 256- م: 16
- وظيفة المسافة: L2
لقد استخدمنا تكوينات كبيرة لكل من مجموعة خدمة OpenSearch Service ومثيلات RDS لتجنب أي اختناقات في الأداء.
نحن ننشر الحل باستخدام مجموعة تطوير سحابة AWS (أوس سي دي كيه) كومة، كما هو موضح في القسم التالي.
انشر مكدس AWS CDK
يتيح لنا مكدس AWS CDK اختيار خدمة OpenSearch أو Amazon RDS لاستيعاب البيانات.
المتطلبات المسبقة
قبل متابعة التثبيت، ضمن cdk وbin وsrc.tc، قم بتغيير القيم المنطقية لـ Amazon RDS وOpenSearch Service إلى true أو false حسب تفضيلاتك.
أنت أيضا بحاجة إلى خدمة مرتبطة إدارة الهوية والوصول AWS دور (IAM) لمجال خدمة OpenSearch. لمزيد من التفاصيل، راجع مكتبة بناء خدمة البحث المفتوح في أمازون. يمكنك أيضًا تشغيل الأمر التالي لإنشاء الدور:
سيقوم مكدس AWS CDK بنشر البنية التحتية التالية:
- VPC
- مضيف الانتقال (داخل VPC)
- مجموعة خدمة OpenSearch (في حالة استخدام خدمة OpenSearch للعرض)
- مثيل RDS (في حالة استخدام Amazon RDS للعرض)
- An مدير أنظمة AWS وثيقة لنشر مجموعة راي
- An خدمة تخزين أمازون البسيطة (Amazon S3) دلو
- An غراء AWS مهمة لتحويل ملفات JSONL لمجموعة بيانات OSCAR إلى ملفات Parquet
- الأمازون CloudWatch لوحات
قم بتنزيل البيانات
قم بتشغيل الأوامر التالية من مضيف الانتقال:
قبل استنساخ git repo، تأكد من أن لديك ملف تعريف Hugging Face وإمكانية الوصول إلى مجموعة بيانات OSCAR. تحتاج إلى استخدام اسم المستخدم وكلمة المرور لاستنساخ بيانات OSCAR:
تحويل ملفات JSONL إلى Parquet
أنشأ مكدس AWS CDK مهمة AWS Glue ETL oscar-jsonl-parquet لتحويل بيانات OSCAR من تنسيق JSONL إلى تنسيق Parquet.
بعد تشغيل ملف oscar-jsonl-parquet المهمة، يجب أن تكون الملفات بتنسيق Parquet متاحة ضمن مجلد parquet في حاوية S3.
تحميل الاسئلة
من مضيف الانتقال الخاص بك، قم بتنزيل بيانات الأسئلة وتحميلها إلى حاوية S3 الخاصة بك:
قم بإعداد مجموعة راي
كجزء من نشر مكدس AWS CDK، قمنا بإنشاء مستند Systems Manager يسمى CreateRayCluster.
لتشغيل المستند، أكمل الخطوات التالية:
- على وحدة تحكم إدارة الأنظمة، ضمن الوثائق في جزء التنقل ، اختر التي يملكها لي.
- فتح
CreateRayClusterوثيقة. - اختار يجري.
ستحتوي صفحة أمر التشغيل على القيم الافتراضية للمجموعة.
يطلب التكوين الافتراضي 5 g4dn.12xlarge. تأكد من أن حسابك له حدود لدعم ذلك. حد الخدمة ذات الصلة هو تشغيل مثيلات G وVT عند الطلب. الإعداد الافتراضي لهذا هو 64، لكن هذا التكوين يتطلب 240 وحدة معالجة مركزية.
- بعد مراجعة تكوين المجموعة، حدد مضيف الانتقال كهدف لأمر التشغيل.
سيقوم هذا الأمر بتنفيذ الخطوات التالية:
- انسخ ملفات مجموعة Ray
- قم بإعداد مجموعة راي
- قم بإعداد فهارس خدمة OpenSearch
- قم بإعداد جداول RDS
يمكنك مراقبة إخراج الأوامر الموجودة على وحدة تحكم Systems Manager. ستستغرق هذه العملية من 10 إلى 15 دقيقة للإطلاق الأولي.
تشغيل الابتلاع
من مضيف الانتقال، اتصل بمجموعة Ray:
عند الاتصال بالمضيف لأول مرة، قم بتثبيت المتطلبات. يجب أن تكون هذه الملفات موجودة بالفعل على العقدة الرئيسية.
بالنسبة لأي من طريقتي العرض، إذا حصلت على خطأ مثل ما يلي، فهذا يتعلق ببيانات الاعتماد منتهية الصلاحية. الحل الحالي (حتى كتابة هذه السطور) هو وضع ملفات بيانات الاعتماد في عقدة رأس Ray. لتجنب المخاطر الأمنية، لا تستخدم مستخدمي IAM للمصادقة عند تطوير برامج مصممة لهذا الغرض أو العمل مع البيانات الحقيقية. بدلاً من ذلك، استخدم الاتحاد مع موفر هوية مثل AWS IAM Identity Center (خلفًا لـ AWS Single Sign-On).
عادة، يتم تخزين بيانات الاعتماد في الملف ~/.aws/credentials على أنظمة Linux وmacOS، و %USERPROFILE%.awscredentials على نظام التشغيل Windows، ولكنها بيانات اعتماد قصيرة المدى مع رمز مميز للجلسة. لا يمكنك أيضًا تجاوز ملف بيانات الاعتماد الافتراضي، ولذلك تحتاج إلى إنشاء بيانات اعتماد طويلة المدى بدون الرمز المميز للجلسة باستخدام مستخدم IAM جديد.
لإنشاء بيانات اعتماد طويلة المدى، تحتاج إلى إنشاء مفتاح وصول AWS ومفتاح وصول سري لـ AWS. يمكنك القيام بذلك من وحدة تحكم IAM. للحصول على التعليمات، راجع المصادقة باستخدام بيانات اعتماد مستخدم IAM.
بعد إنشاء المفاتيح، اتصل بمضيف الانتقال باستخدام مدير الدورة، إحدى إمكانيات مدير الأنظمة، وقم بتشغيل الأمر التالي:
يمكنك الآن إعادة تنفيذ خطوات العرض.
استيعاب البيانات في خدمة OpenSearch
إذا كنت تستخدم خدمة OpenSearch، فقم بتشغيل البرنامج النصي التالي لاستيعاب الملفات:
عند اكتماله، قم بتشغيل البرنامج النصي الذي يقوم بتشغيل الاستعلامات المحاكاة:
استيعاب البيانات في Amazon RDS
إذا كنت تستخدم Amazon RDS، فقم بتشغيل البرنامج النصي التالي لاستيعاب الملفات:
عند اكتماله، تأكد من تشغيل فراغ كامل على مثيل RDS.
ثم قم بتشغيل البرنامج النصي التالي لتشغيل الاستعلامات المحاكاة:
قم بإعداد لوحة تحكم راي
قبل إعداد لوحة تحكم Ray، يجب عليك تثبيت واجهة سطر الأوامر AWS (AWS CLI) على جهازك المحلي. للحصول على التعليمات، راجع قم بتثبيت أو تحديث أحدث إصدار من AWS CLI.
أكمل الخطوات التالية لإعداد لوحة المعلومات:
- تثبيت البرنامج المساعد لإدارة الجلسة لـ AWS CLI.
- في حساب Isengard، انسخ بيانات الاعتماد المؤقتة لـ bash/zsh وقم بتشغيلها في المحطة المحلية لديك.
- قم بإنشاء ملف session.sh في جهازك وانسخ المحتوى التالي إلى الملف:
- قم بتغيير الدليل إلى حيث يتم تخزين ملف session.sh هذا.
- قم بتشغيل الأمر
Chmod +xلإعطاء إذن قابل للتنفيذ للملف. - قم بتشغيل الأمر التالي:
فمثلا:
ستظهر لك رسالة مثل ما يلي:
افتح علامة تبويب جديدة في متصفحك وأدخل localhost:8265.
سترى لوحة تحكم Ray وإحصائيات الوظائف والمجموعة قيد التشغيل. يمكنك تتبع المقاييس من هنا.
على سبيل المثال، يمكنك استخدام لوحة معلومات Ray لمراقبة التحميل على المجموعة. كما هو موضح في لقطة الشاشة التالية، أثناء الاستيعاب، تعمل وحدات معالجة الرسومات على ما يقرب من 100٪ من الاستخدام.
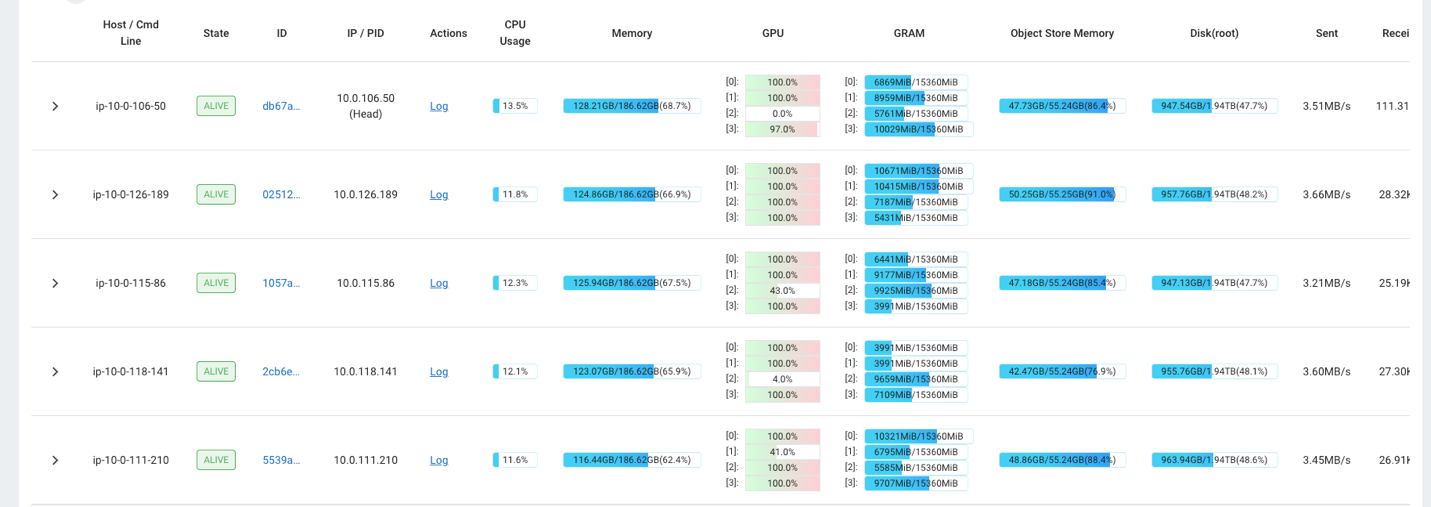
يمكنك أيضا استخدام RAG_Benchmarks لوحة تحكم CloudWatch لمعرفة معدل الاستيعاب وأوقات استجابة الاستعلام.
اتساع الحل
يمكنك توسيع هذا الحل لتوصيل AWS أو متاجر متجهة أخرى تابعة لجهات خارجية. بالنسبة لكل مخزن متجه جديد، ستحتاج إلى إنشاء برامج نصية لتكوين مخزن البيانات بالإضافة إلى استيعاب البيانات. ويمكن إعادة استخدام بقية خط الأنابيب حسب الحاجة.
وفي الختام
في هذا المنشور، شاركنا مسار ETL الذي يمكنك استخدامه لوضع بيانات RAG الموجهة في كل من خدمة OpenSearch Service وكذلك Amazon RDS بامتداد pgvector كمخازن بيانات متجهة. استخدم الحل مجموعة Ray لتوفير التوازي اللازم لاستيعاب مجموعة كبيرة من البيانات. يمكنك استخدام هذه المنهجية لدمج أي قاعدة بيانات متجهة من اختيارك لإنشاء خطوط أنابيب RAG.
حول المؤلف
 راندي ديفو هو مهندس الحلول الرئيسي الأول في AWS. وهو حاصل على ماجستير الهندسة المعمارية من جامعة ميشيغان، حيث عمل على الرؤية الحاسوبية للمركبات ذاتية القيادة. وهو حاصل أيضًا على ماجستير إدارة الأعمال من جامعة ولاية كولورادو. شغل راندي مجموعة متنوعة من المناصب في مجال التكنولوجيا، بدءًا من هندسة البرمجيات وحتى إدارة المنتجات. دخل مجال البيانات الضخمة في عام 2013 ويواصل استكشاف هذا المجال. وهو يعمل بنشاط على مشاريع في مجال تعلم الآلة وقد قدم عروضًا في العديد من المؤتمرات، بما في ذلك Strata وGlueCon.
راندي ديفو هو مهندس الحلول الرئيسي الأول في AWS. وهو حاصل على ماجستير الهندسة المعمارية من جامعة ميشيغان، حيث عمل على الرؤية الحاسوبية للمركبات ذاتية القيادة. وهو حاصل أيضًا على ماجستير إدارة الأعمال من جامعة ولاية كولورادو. شغل راندي مجموعة متنوعة من المناصب في مجال التكنولوجيا، بدءًا من هندسة البرمجيات وحتى إدارة المنتجات. دخل مجال البيانات الضخمة في عام 2013 ويواصل استكشاف هذا المجال. وهو يعمل بنشاط على مشاريع في مجال تعلم الآلة وقد قدم عروضًا في العديد من المؤتمرات، بما في ذلك Strata وGlueCon.
 ديفيد كريستيان هو مهندس الحلول الرئيسي ومقره في جنوب كاليفورنيا. حصل على درجة البكالوريوس في أمن المعلومات ولديه شغف بالأتمتة. مجالات تركيزه هي ثقافة DevOps والتحول، والبنية التحتية كرمز، والمرونة. قبل انضمامه إلى AWS، شغل مناصب في مجال الأمان وDevOps وهندسة الأنظمة وإدارة بيئات سحابية خاصة وعامة واسعة النطاق.
ديفيد كريستيان هو مهندس الحلول الرئيسي ومقره في جنوب كاليفورنيا. حصل على درجة البكالوريوس في أمن المعلومات ولديه شغف بالأتمتة. مجالات تركيزه هي ثقافة DevOps والتحول، والبنية التحتية كرمز، والمرونة. قبل انضمامه إلى AWS، شغل مناصب في مجال الأمان وDevOps وهندسة الأنظمة وإدارة بيئات سحابية خاصة وعامة واسعة النطاق.
 براشي كولكارني هو مهندس حلول أول في AWS. تخصصها هو التعلم الآلي، وهي تعمل بنشاط على تصميم الحلول باستخدام عروض AWS ML والبيانات الضخمة والتحليلات المتنوعة. تتمتع براتشي بخبرة في مجالات متعددة، بما في ذلك الرعاية الصحية والمزايا وتجارة التجزئة والتعليم، وعملت في مجموعة من المناصب في هندسة المنتجات والهندسة المعمارية والإدارة ونجاح العملاء.
براشي كولكارني هو مهندس حلول أول في AWS. تخصصها هو التعلم الآلي، وهي تعمل بنشاط على تصميم الحلول باستخدام عروض AWS ML والبيانات الضخمة والتحليلات المتنوعة. تتمتع براتشي بخبرة في مجالات متعددة، بما في ذلك الرعاية الصحية والمزايا وتجارة التجزئة والتعليم، وعملت في مجموعة من المناصب في هندسة المنتجات والهندسة المعمارية والإدارة ونجاح العملاء.
 ريشا جوبتا هو مهندس الحلول في AWS. إنها متحمسة لتصميم الحلول الشاملة للعملاء. تخصصها هو التعلم الآلي وكيف يمكن استخدامه لبناء حلول جديدة تؤدي إلى التميز التشغيلي وزيادة إيرادات الأعمال. قبل انضمامها إلى AWS، عملت كمهندسة برمجيات ومهندس حلول، حيث قامت ببناء حلول لمشغلي الاتصالات الكبار. خارج العمل، تحب استكشاف أماكن جديدة وتحب أنشطة المغامرة.
ريشا جوبتا هو مهندس الحلول في AWS. إنها متحمسة لتصميم الحلول الشاملة للعملاء. تخصصها هو التعلم الآلي وكيف يمكن استخدامه لبناء حلول جديدة تؤدي إلى التميز التشغيلي وزيادة إيرادات الأعمال. قبل انضمامها إلى AWS، عملت كمهندسة برمجيات ومهندس حلول، حيث قامت ببناء حلول لمشغلي الاتصالات الكبار. خارج العمل، تحب استكشاف أماكن جديدة وتحب أنشطة المغامرة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

