جزء 1 وصفت هذه السلسلة المكونة من جزأين كيفية إنشاء خدمة الأسماء المستعارة التي تحول سمات بيانات النص العادي إلى اسم مستعار أو العكس. توفر خدمة الأسماء المستعارة المركزية بنية فريدة ومعترف بها عالميًا لإنشاء أسماء مستعارة. وبالتالي، يمكن للمؤسسة تحقيق عملية قياسية للتعامل مع البيانات الحساسة عبر جميع الأنظمة الأساسية. بالإضافة إلى ذلك، يؤدي هذا إلى إزالة أي تعقيد وخبرة مطلوبة لفهم وتنفيذ متطلبات الامتثال المختلفة من فرق التطوير والمستخدمين التحليليين، مما يسمح لهم بالتركيز على نتائج أعمالهم.
إن اتباع نهج قائم على الخدمة المنفصلة يعني أنك، كمؤسسة، غير متحيز تجاه استخدام أي تقنيات محددة لحل مشاكل عملك. بغض النظر عن التكنولوجيا التي تفضلها الفرق الفردية، فإنها قادرة على الاتصال بخدمة الأسماء المستعارة لتسمية البيانات الحساسة.
في هذا المنشور، نركز على أنماط استهلاك الاستخراج والتحويل والتحميل الشائعة (ETL) التي يمكنها استخدام خدمة الأسماء المستعارة. نناقش كيفية استخدام خدمة الأسماء المستعارة في وظائف ETL الخاصة بك على أمازون EMR (باستخدام أمازون EMR على EC2) لحالات الاستخدام المتدفق والدفعي. بالإضافة إلى ذلك، يمكنك العثور على أمازون أثينا و غراء AWS نمط الاستهلاك القائم في جيثب ريبو من الحل.
حل نظرة عامة
يصف الرسم البياني التالي بنية الحل.

يستضيف الحساب الموجود على اليمين خدمة الاسم المستعار، والتي يمكنك نشرها باستخدام الإرشادات المتوفرة في الجزء الأول من هذه السلسلة.
الحساب الموجود على اليسار هو الذي قمت بإعداده كجزء من هذا المنشور، والذي يمثل منصة ETL المستندة إلى Amazon EMR باستخدام خدمة الأسماء المستعارة.
يمكنك نشر خدمة الأسماء المستعارة ومنصة ETL على نفس الحساب.
يمكّنك Amazon EMR من إنشاء أطر عمل للبيانات الضخمة وتشغيلها وتوسيع نطاقها مثل Apache Spark بسرعة وفعالية من حيث التكلفة.
في هذا الحل نوضح كيفية استهلاك خدمة الاسم المستعار على أمازون EMR مع أباتشي سبارك لحالات الاستخدام الدفعي والتدفق. يقرأ التطبيق الدفعي البيانات من ملف خدمة تخزين أمازون البسيطة (Amazon S3)، ويستهلك تطبيق البث السجلات من الأمازون كينسيس دفق البيانات.
كود PySpark المستخدم في المهام الدفعية والتدفقية
يستخدم كلا التطبيقين وظيفة أداة مساعدة مشتركة تقوم باستدعاءات HTTP POST مقابل بوابة API المرتبطة بالأسماء المستعارة AWS لامدا وظيفة. يتم إجراء استدعاءات REST API لكل قسم Spark باستخدام Spark RDD MapPartitions وظيفة. يحتوي نص طلب POST على قائمة القيم الفريدة لعمود إدخال معين. تحتوي استجابة طلب POST على القيم ذات الأسماء المستعارة المقابلة. يقوم الكود بتبديل القيم الحساسة مع القيم ذات الأسماء المستعارة لمجموعة بيانات معينة. يتم حفظ النتيجة في Amazon S3 و غراء AWS كتالوج البيانات، باستخدام أباتشي ايسيبيرع تنسيق الجدول.
Iceberg هو تنسيق جدول مفتوح يدعم معاملات ACID وتطور المخطط واستعلامات السفر عبر الزمن. يمكنك استخدام هذه الميزات لتنفيذ الحق في أن تنسى (أو محو البيانات) الحلول باستخدام عبارات SQL أو واجهات البرمجة. يتم دعم Iceberg بواسطة Amazon EMR بدءًا من الإصدار 6.5.0 وAWS Glue وAthena. تستخدم أنماط الدُفعات والتدفق Iceberg كتنسيق مستهدف لها. للحصول على نظرة عامة حول كيفية إنشاء بحيرة بيانات متوافقة مع ACID باستخدام Iceberg، راجع قم ببناء بحيرة بيانات متطورة عالية الأداء ومتوافقة مع ACID باستخدام Apache Iceberg على Amazon EMR.
المتطلبات الأساسية المسبقة
يجب أن تكون لديك المتطلبات الأساسية التالية:
- An حساب AWS.
- An إدارة الهوية والوصول AWS (IAM) الرئيسي مع امتيازات نشر تكوين سحابة AWS المكدس والموارد ذات الصلة.
- • واجهة سطر الأوامر AWS (AWS CLI) مثبت على جهاز التطوير أو النشر الذي ستستخدمه لتشغيل البرامج النصية المتوفرة.
- حاوية S3 في نفس الحساب ومنطقة AWS حيث سيتم نشر الحل.
- Python3 المثبتة في الجهاز المحلي حيث يتم تشغيل الأوامر.
- بييامل مثبتة باستخدام بذرة.
- محطة bash لتشغيل البرامج النصية bash التي تنشر مكدسات CloudFormation.
- مجموعة S3 إضافية تحتوي على مجموعة بيانات الإدخال في ملفات Parquet (فقط للتطبيقات المجمعة). انسخ ال عينة مجموعة البيانات إلى دلو S3.
- نسخة من أحدث مستودع التعليمات البرمجية في الجهاز المحلي باستخدام
git cloneأو خيار التحميل
افتح محطة bash جديدة وانتقل إلى المجلد الجذر للمستودع المستنسخ.
يمكن العثور على الكود المصدري للأنماط المقترحة في المستودع المستنسخ. ويستخدم المعلمات التالية:
- ARTEFACT_S3_BUCKET - حاوية S3 حيث سيتم تخزين رمز البنية التحتية. يجب إنشاء المجموعة في نفس الحساب والمنطقة التي يوجد بها الحل.
- AWS_REGION – المنطقة التي سيتم نشر الحل فيها.
- AWS_PROFILE - ملف التعريف المسمى الذي سيتم تطبيقه على أمر AWS CLI. يجب أن يحتوي هذا على بيانات اعتماد لمدير IAM مع امتيازات لنشر مكدس CloudFormation للموارد ذات الصلة.
- SUBNET_ID - معرف الشبكة الفرعية حيث سيتم تشغيل مجموعة EMR. الشبكة الفرعية موجودة مسبقًا ولأغراض العرض التوضيحي، نستخدم معرف الشبكة الفرعية الافتراضي لـ VPC الافتراضي.
- EP_URL – عنوان URL لنقطة النهاية لخدمة الأسماء المستعارة. استرجع هذا من الحل المنشور كـ جزء 1 من هذه السلسلة.
- API_SECRET - أ بوابة أمازون API مفتاح التي سيتم تخزينها في مدير أسرار AWS. يتم إنشاء مفتاح واجهة برمجة التطبيقات (API) من النشر الموضح في جزء 1 من هذه السلسلة.
- S3_INPUT_PATH - يشير URI الخاص بـ S3 إلى المجلد الذي يحتوي على مجموعة بيانات الإدخال كملفات Parquet.
- KINESIS_DATA_STREAM_NAME - تم نشر اسم دفق بيانات Kinesis مع مكدس CloudFormation.
- حجم الدفعة - عدد السجلات التي سيتم دفعها إلى دفق البيانات لكل دفعة.
- THREADS_NUM - عدد الخيوط المتوازية المستخدمة في الجهاز المحلي لتحميل البيانات إلى دفق البيانات. المزيد من المواضيع تتوافق مع حجم رسالة أعلى.
- EMR_CLUSTER_ID - معرف مجموعة EMR حيث سيتم تشغيل التعليمات البرمجية (تم إنشاء مجموعة EMR بواسطة مكدس CloudFormation).
- STACK_NAME - اسم مكدس CloudFormation، الذي تم تعيينه في البرنامج النصي للنشر.
خطوات نشر الدفعة
كما هو موضح في المتطلبات الأساسية، قبل نشر الحل، قم بتحميل ملفات Parquet الخاصة بـ مجموعة بيانات الاختبار إلى أمازون S3. ثم قم بتوفير مسار S3 للمجلد الذي يحتوي على الملفات كمعلمة <S3_INPUT_PATH>.
نقوم بإنشاء موارد الحل عبر AWS CloudFormation. يمكنك نشر الحل عن طريق تشغيل Deploy_1.sh البرنامج النصي الموجود داخل deployment_scripts المجلد.
بعد استيفاء متطلبات النشر الأساسية، أدخل الأمر التالي لنشر الحل:
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
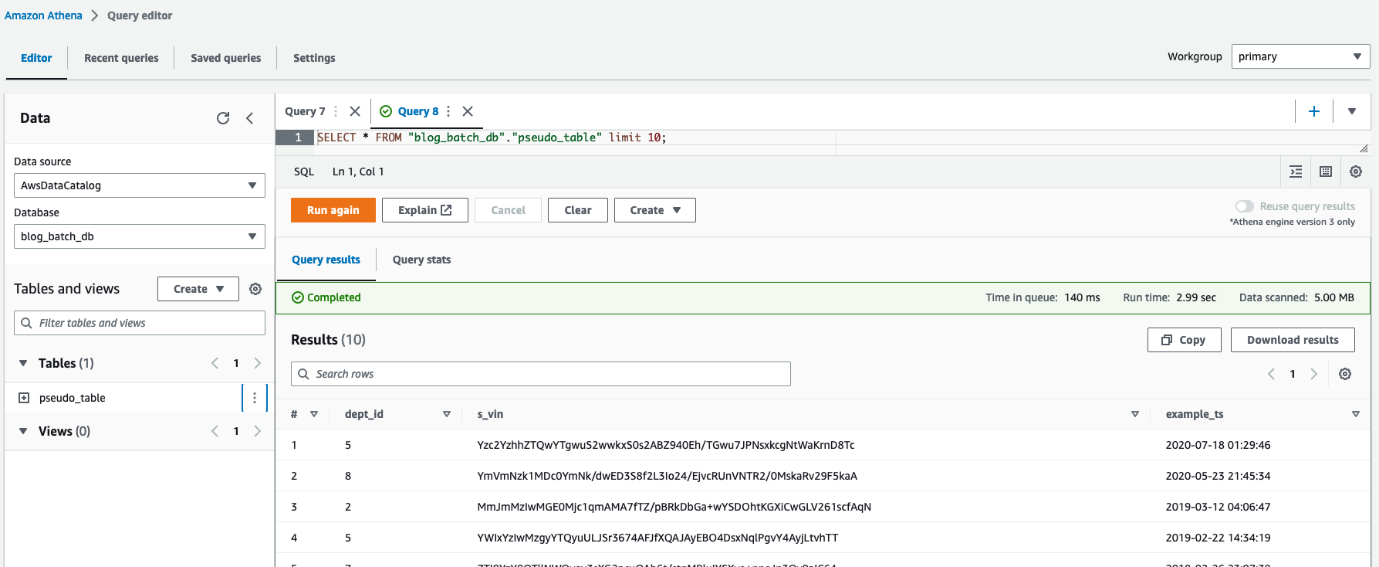
-i <S3_INPUT_PATH>يجب أن يبدو الإخراج مثل لقطة الشاشة التالية.

تتم طباعة المعلمات المطلوبة لأمر التنظيف في نهاية تشغيل البرنامج deploy_1.sh النصي. تأكد من تدوين هذه القيم.
اختبار الحل الدفعي
في قالب CloudFormation الذي تم نشره باستخدام deploy_1.sh البرنامج النصي، خطوة EMR التي تحتوي على تطبيق دفعة شرارة تتم إضافته في نهاية إعداد مجموعة EMR.
للتحقق من النتائج، تحقق من مجموعة S3 المحددة في مخرجات مكدس CloudFormation باستخدام المتغير SparkOutputLocation.

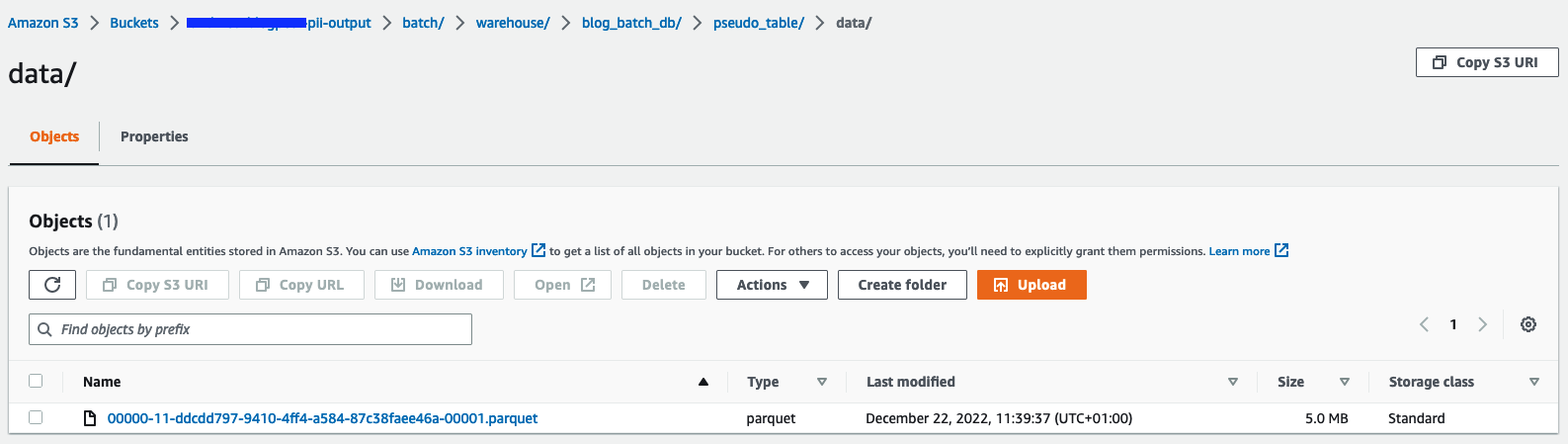
يمكنك أيضًا استخدام أثينا ل الاستعلام عن الجدول pseudo_table في قاعدة البيانات blog_batch_db.
تنظيف موارد الدفعة
لتدمير الموارد التي تم إنشاؤها كجزء من هذا التمرين،
في محطة bash، انتقل إلى المجلد الجذر للمستودع المستنسخ. أدخل أمر التنظيف الموضح كمخرج للتشغيل السابق Deploy_1.sh النصي:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>يجب أن يبدو الإخراج مثل لقطة الشاشة التالية.

خطوات النشر المتدفقة
نقوم بإنشاء موارد الحل عبر AWS CloudFormation. يمكنك نشر الحل عن طريق تشغيل Deploy_2.sh البرنامج النصي الموجود داخل deployment_scripts مجلد. يتوفر قالب مكدس CloudFormation لهذا النمط في جيثب ريبو.
بعد استيفاء متطلبات النشر الأساسية، أدخل الأمر التالي لنشر الحل:
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>يجب أن يبدو الإخراج مثل لقطة الشاشة التالية.
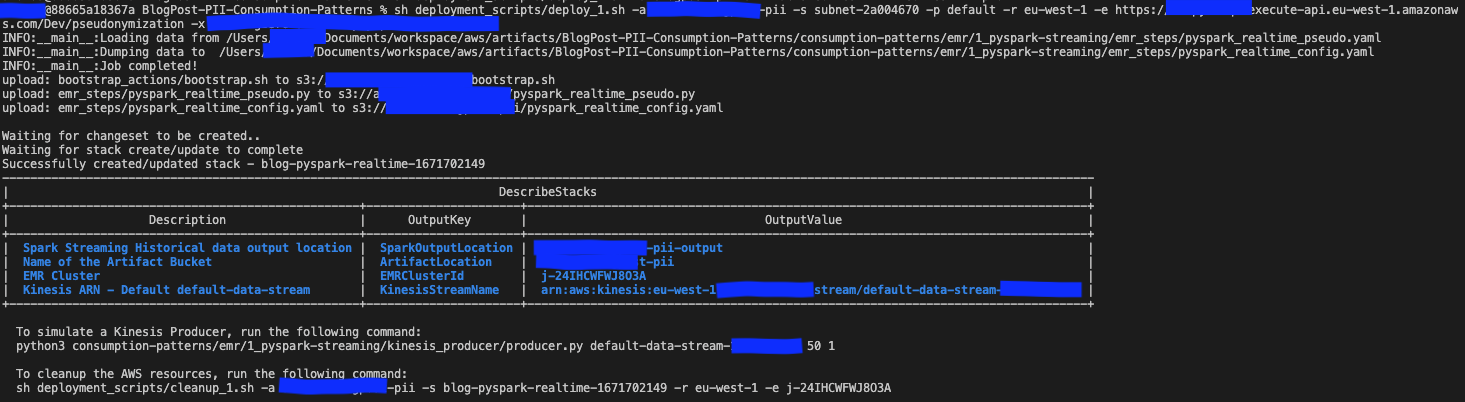
تتم طباعة المعلمات المطلوبة لأمر التنظيف في نهاية إخراج الملف Deploy_2.sh النصي. تأكد من حفظ هذه القيم لاستخدامها لاحقًا.
اختبر حل التدفق
في قالب CloudFormation الذي تم نشره باستخدام deploy_2.sh البرنامج النصي، خطوة EMR التي تحتوي على تطبيق تدفق شرارة تتم إضافته في نهاية إعداد مجموعة EMR. لاختبار المسار الشامل، تحتاج إلى دفع السجلات إلى دفق بيانات Kinesis المنشور. باستخدام الأوامر التالية في محطة bash، يمكنك تنشيط منتج Kinesis الذي سيضع السجلات بشكل مستمر في الدفق، حتى يتم إيقاف العملية يدويًا. يمكنك التحكم في حجم رسالة المنتج عن طريق تعديل BATCH_SIZE و THREADS_NUM المتغيرات.


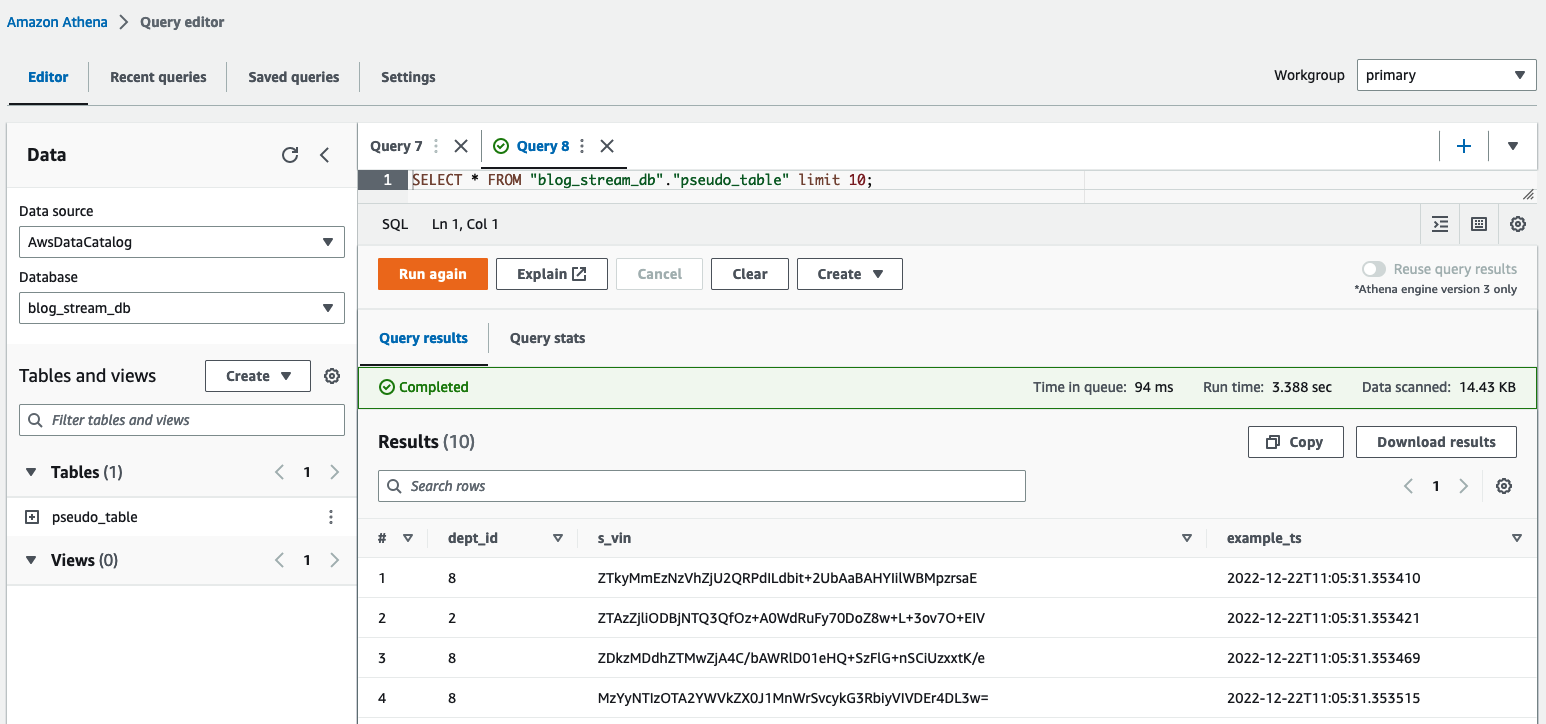
في محرر استعلام Athena، تحقق من النتائج عن طريق الاستعلام عن table pseudo_table في قاعدة البيانات blog_stream_db.
تنظيف موارد التدفق
لتدمير الموارد التي تم إنشاؤها كجزء من هذا التمرين، أكمل الخطوات التالية:
- أوقف منتج Python Kinesis الذي تم إطلاقه في محطة bash في القسم السابق.
- أدخل الأمر التالي:
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>يجب أن يبدو الإخراج مثل لقطة الشاشة التالية.

تفاصيل الأداء
قد تختلف حالات الاستخدام في المتطلبات فيما يتعلق بحجم البيانات وسعة الحوسبة والتكلفة. لقد قدمنا بعض المعايير والعوامل التي قد تؤثر على الأداء؛ ومع ذلك، فإننا ننصحك بشدة بالتحقق من صحة الحل في البيئات الأقل لمعرفة ما إذا كان يلبي متطلباتك الخاصة.
يمكنك التأثير على أداء الحل المقترح (الذي يهدف إلى الاسم المستعار لمجموعة بيانات باستخدام Amazon EMR) من خلال الحد الأقصى لعدد المكالمات المتوازية لخدمة الاسم المستعار وحجم الحمولة لكل مكالمة. فيما يتعلق بالمكالمات الموازية، فإن العوامل التي يجب مراعاتها هي حد مكالمات GetSecretValue من Secrets Manager (10.000 في الثانية، الحد الأقصى) وتوازي التزامن الافتراضي Lambda (1,000 افتراضيًا؛ يمكن زيادته عن طريق طلب الحصة النسبية). يمكنك التحكم في الحد الأقصى للتوازي من خلال ضبط عدد المنفذين وعدد الأقسام التي تتكون منها مجموعة البيانات وتكوين المجموعة (عدد العقد ونوعها). فيما يتعلق بحجم الحمولة لكل مكالمة، فإن العوامل التي يجب مراعاتها هي: الحد الأقصى لحجم الحمولة النافعة لبوابة API (6 ميجابايت) والحد الأقصى لوقت التشغيل لوظيفة Lambda (15 دقيقة). يمكنك التحكم في حجم الحمولة النافعة ووقت تشغيل وظيفة Lambda عن طريق ضبط قيمة حجم الدُفعة، وهي معلمة للبرنامج النصي PySpark التي تحدد عدد العناصر التي سيتم تسميتها بأسماء مستعارة لكل استدعاء لواجهة برمجة التطبيقات. لالتقاط تأثير كل هذه العوامل وتقييم أداء أنماط الاستهلاك باستخدام Amazon EMR، قمنا بتصميم ومراقبة السيناريوهات التالية.
أداء نمط استهلاك الدفعة
لتقييم أداء نمط استهلاك الدُفعات، قمنا بتشغيل تطبيق الأسماء المستعارة بثلاث مجموعات بيانات مدخلة مكونة من 1 و10 و100 ملف باركيه يبلغ حجم كل منها 97.7 ميجابايت. لقد أنشأنا ملفات الإدخال باستخدام ملف dataset_generator.py النصي.
كانت عقد سعة الكتلة عبارة عن عقدة أساسية واحدة (m1xlarge) و 5.4 نواة (m15d.5xlarge). ظل تكوين المجموعة هذا كما هو بالنسبة لجميع السيناريوهات الثلاثة، وسمح لتطبيق Spark باستخدام ما يصل إلى 8 منفذ. ال batch_size، والذي كان أيضًا هو نفسه بالنسبة للسيناريوهات الثلاثة، تم تعيينه على 900 رقم VIN لكل استدعاء لواجهة برمجة التطبيقات (API)، وكان الحد الأقصى لحجم VIN هو 5 بايت.
يلتقط الجدول التالي معلومات السيناريوهات الثلاثة.
| معرف التنفيذ | إعادة تقسيم | حجم مجموعة البيانات | عدد المنفذين | النوى لكل منفذ | ذاكرة المنفذ | وقت التشغيل |
| A | 800 | 9.53 جيجا بايت | 100 | 4 | 4 GiB | دقائق 11 ، 10 ثانية |
| B | 80 | 0.95 جيجا بايت | 10 | 4 | 4 GiB | دقائق 8 ، 36 ثانية |
| C | 8 | 0.09 جيجا بايت | 1 | 4 | 4 GiB | دقائق 7 ، 56 ثانية |
كما نرى، فإن موازنة المكالمات بشكل صحيح مع خدمة الأسماء المستعارة لدينا تمكننا من التحكم في وقت التشغيل الإجمالي.
في الأمثلة التالية، نقوم بتحليل ثلاثة مقاييس Lambda مهمة لخدمة الأسماء المستعارة: Invocations, ConcurrentExecutionsو Duration.
الرسم البياني التالي يصور Invocations متري، مع الإحصائية SUM باللون البرتقالي و RUNNING SUM باللون الأزرق.

ومن خلال حساب الفرق بين نقطة البداية والنهاية للاستدعاءات التراكمية، يمكننا استخراج عدد الاستدعاءات التي تم إجراؤها خلال كل تشغيل.
| تشغيل معرف | حجم مجموعة البيانات | إجمالي الدعوات |
| A | 9.53 جيجا بايت | 1.467.000 - 0 = 1.467.000 |
| B | 0.95 جيجا بايت | 1.467.000 - 1.616.500 = 149.500 |
| C | 0.09 جيجا بايت | 1.616.500 - 1.631.000 = 14.500 |
كما هو متوقع، يزيد عدد الاستدعاءات بشكل متناسب بمقدار 10 مع حجم مجموعة البيانات.
ويوضح الرسم البياني التالي المجموع ConcurrentExecutions متري، مع الإحصائية MAX باللون الأزرق.
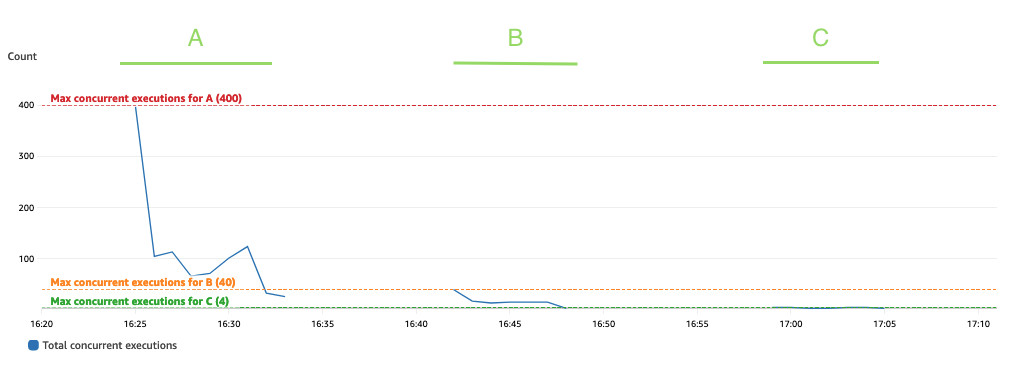
تم تصميم التطبيق بحيث يتم تحديد الحد الأقصى لعدد عمليات تشغيل وظائف Lambda المتزامنة من خلال مقدار مهام Spark (أقسام مجموعة بيانات Spark)، والتي يمكن معالجتها بالتوازي. يمكن حساب هذا الرقم كما MIN (المنفذون × executor_cores، شرارة أقسام مجموعة البيانات).
في الاختبار، قم بتشغيل 800 قسم معالج باستخدام 100 منفذ مع أربعة مراكز لكل منهما. يؤدي هذا إلى معالجة 400 مهمة بالتوازي بحيث لا يمكن أن تكون عمليات التشغيل المتزامنة لوظيفة Lambda أعلى من 400. تم تطبيق نفس المنطق على عمليات التشغيل B وC. يمكننا أن نرى هذا ينعكس في الرسم البياني السابق، حيث لا يتجاوز مقدار عمليات التشغيل المتزامنة أبدًا القيم 400 و40 و4.
لتجنب التقييد، تأكد من أن مقدار مهام Spark التي يمكن معالجتها بالتوازي لا يتجاوز الحد الأقصى لتزامن دالة Lambda. إذا كان الأمر كذلك، فيجب عليك إما زيادة حد تزامن دالة Lambda (إذا كنت ترغب في الحفاظ على الأداء) أو تقليل كمية الأقسام أو عدد المنفذين المتاحين (التأثير على أداء التطبيق).
الرسم البياني التالي يصور لامدا Duration متري، مع الإحصائية AVG باللون البرتقالي و MAX بالأخضر.
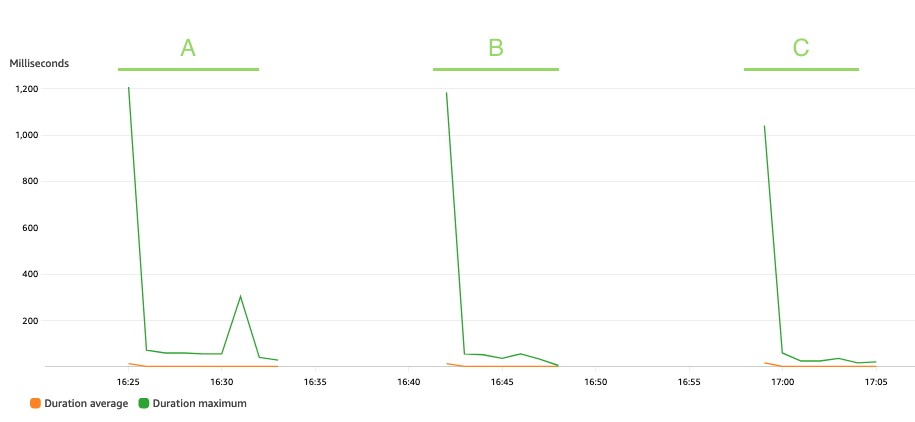
كما هو متوقع، لا يؤثر حجم مجموعة البيانات على مدة تشغيل وظيفة الاسم المستعار، والتي، بصرف النظر عن بعض الاستدعاءات الأولية التي تواجه بدايات باردة، تظل ثابتة بمتوسط 3 مللي ثانية خلال السيناريوهات الثلاثة. وذلك لأن الحد الأقصى لعدد السجلات المضمنة في كل استدعاء للأسماء المستعارة ثابت (batch_size القيمة).
تتم محاسبة Lambda بناءً على عدد الاستدعاءات والوقت الذي يستغرقه تشغيل التعليمات البرمجية (المدة). يمكنك استخدام متوسط المدة ومقاييس الاستدعاءات لتقدير تكلفة خدمة الاسم المستعار.
تدفق أداء نمط الاستهلاك
لتقييم أداء نمط استهلاك البث، قمنا بإجراء Producer.py البرنامج النصي، الذي يحدد منتج بيانات Kinesis الذي يدفع السجلات على دفعات إلى دفق بيانات Kinesis.
تم ترك تطبيق البث قيد التشغيل لمدة 15 دقيقة وتمت تهيئته باستخدام ملف batch_interval دقيقة واحدة، وهي الفترة الزمنية التي سيتم خلالها تقسيم بيانات التدفق إلى دفعات. ويلخص الجدول التالي العوامل ذات الصلة.
| إعادة تقسيم | عقد سعة الكتلة | عدد المنفذين | ذاكرة المنفذ | نافذة الدفعة | حجم الدفعة | حجم فين |
| 17 |
1 ابتدائي (m5.xlarge)، 3 النواة (m5.2xlarge) |
6 | 9 GiB | 60 ثانية | 900 رقم VIN/مكالمة API. | 5 بايت/رقم التعريف الشخصي |
توضح الرسوم البيانية التالية مقاييس تدفقات بيانات Kinesis PutRecords (باللون الأزرق) و GetRecords (باللون البرتقالي) مجمعة بفترة دقيقة واحدة وباستخدام الإحصائية SUM. يعرض الرسم البياني الأول المقياس بالبايت، والذي يصل إلى 6.8 ميجابايت في الدقيقة. يوضح الرسم البياني الثاني المقياس في عدد السجلات الذي يصل إلى 85,000 سجل في الدقيقة.
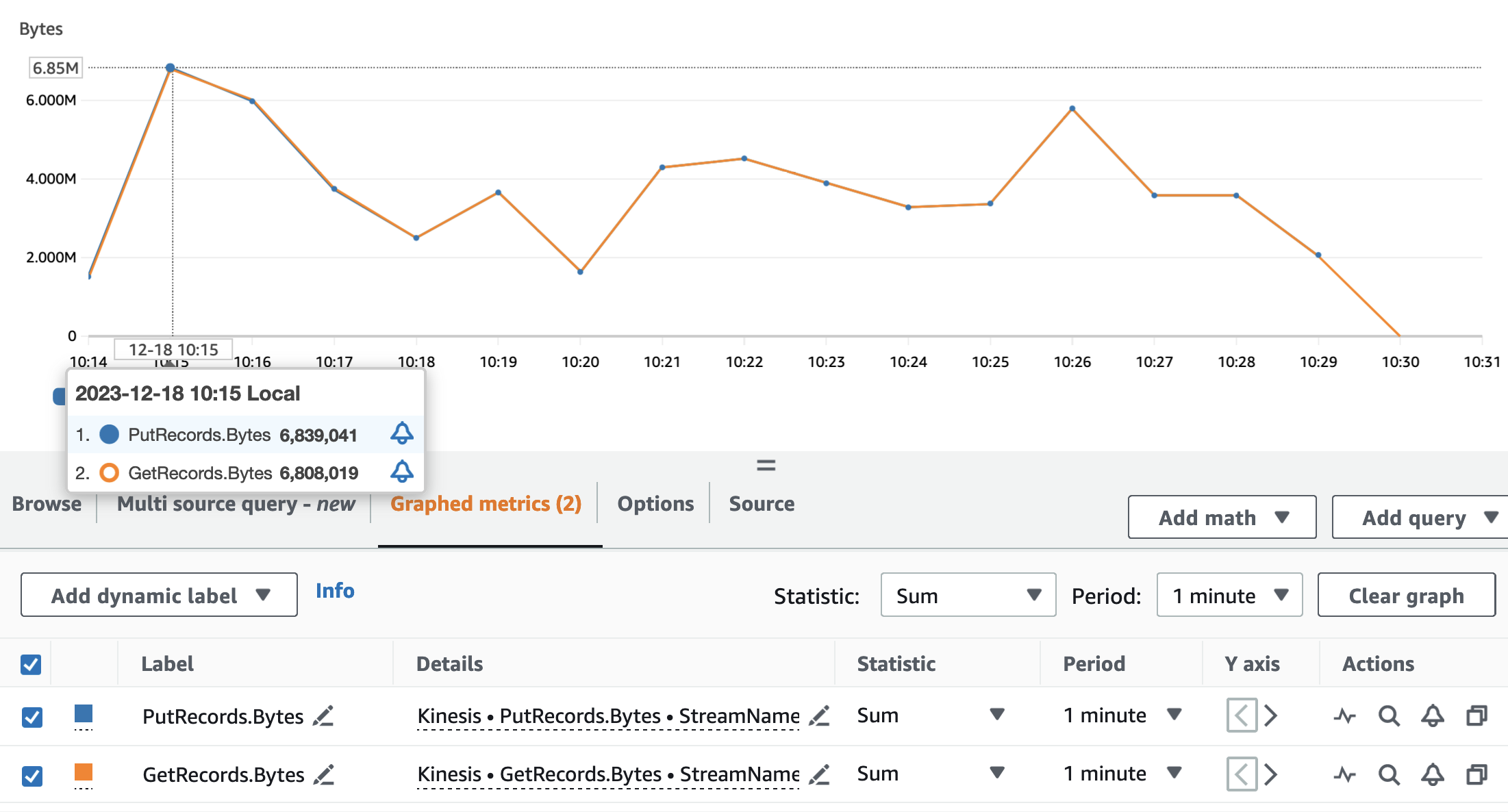

يمكننا أن نرى أن المقاييس GetRecords و PutRecords تحتوي على قيم متداخلة لتشغيل التطبيق بالكامل تقريبًا. وهذا يعني أن تطبيق البث كان قادرًا على مواكبة تحميل الدفق.
بعد ذلك، نقوم بتحليل مقاييس Lambda ذات الصلة لخدمة الأسماء المستعارة: Invocations, ConcurrentExecutionsو Duration.
الرسم البياني التالي يصور Invocations متري، مع الإحصائية SUM (باللون البرتقالي) و RUNNING SUM باللون الأزرق.
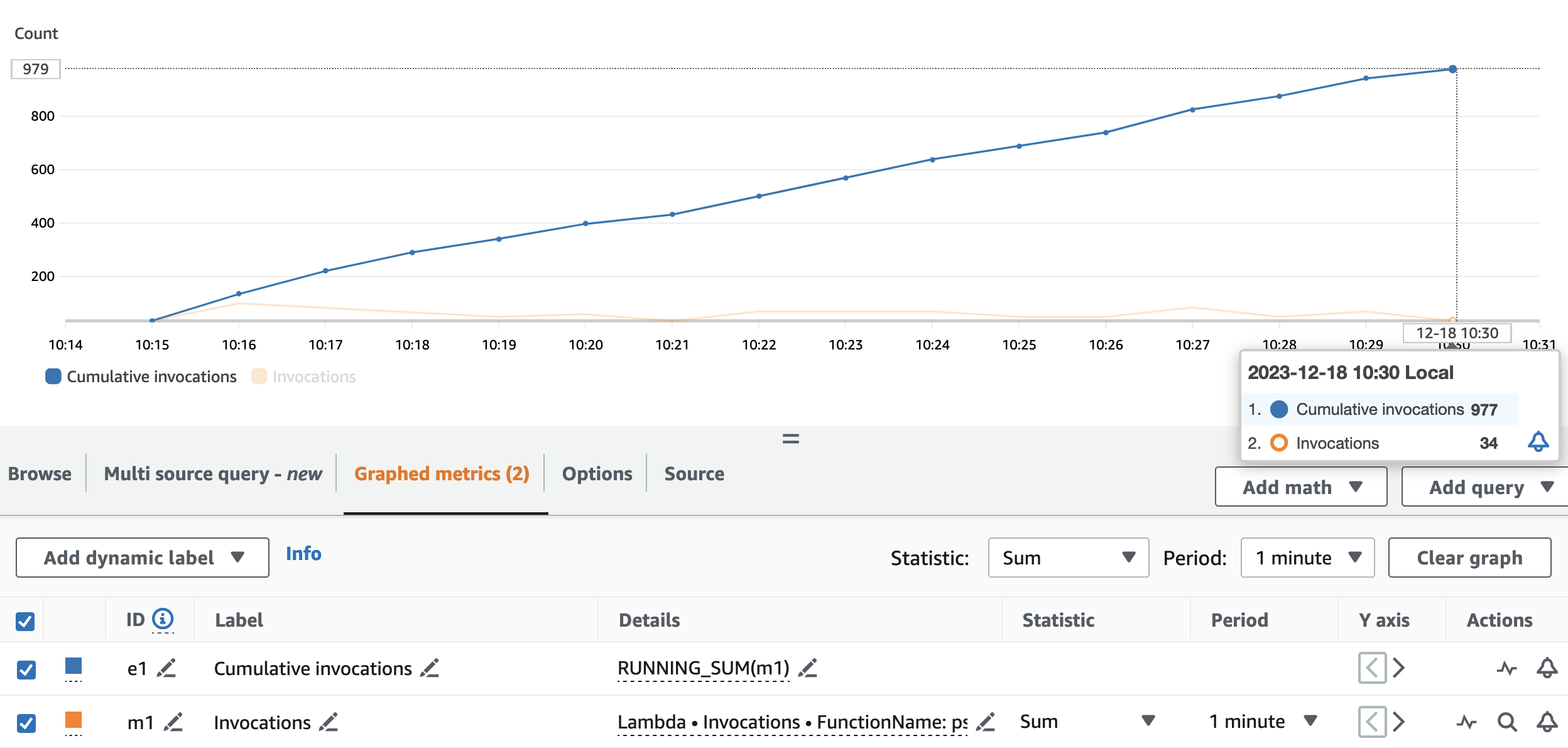
من خلال حساب الفرق بين نقطة البداية والنهاية للاستدعاءات التراكمية، يمكننا استخراج عدد الاستدعاءات التي تم إجراؤها أثناء التشغيل. على وجه التحديد، خلال 15 دقيقة، استدعى تطبيق البث واجهة برمجة تطبيقات الأسماء المستعارة 977 مرة، أي حوالي 65 مكالمة في الدقيقة.
ويوضح الرسم البياني التالي المجموع ConcurrentExecutions متري، مع الإحصائية MAX باللون الأزرق.
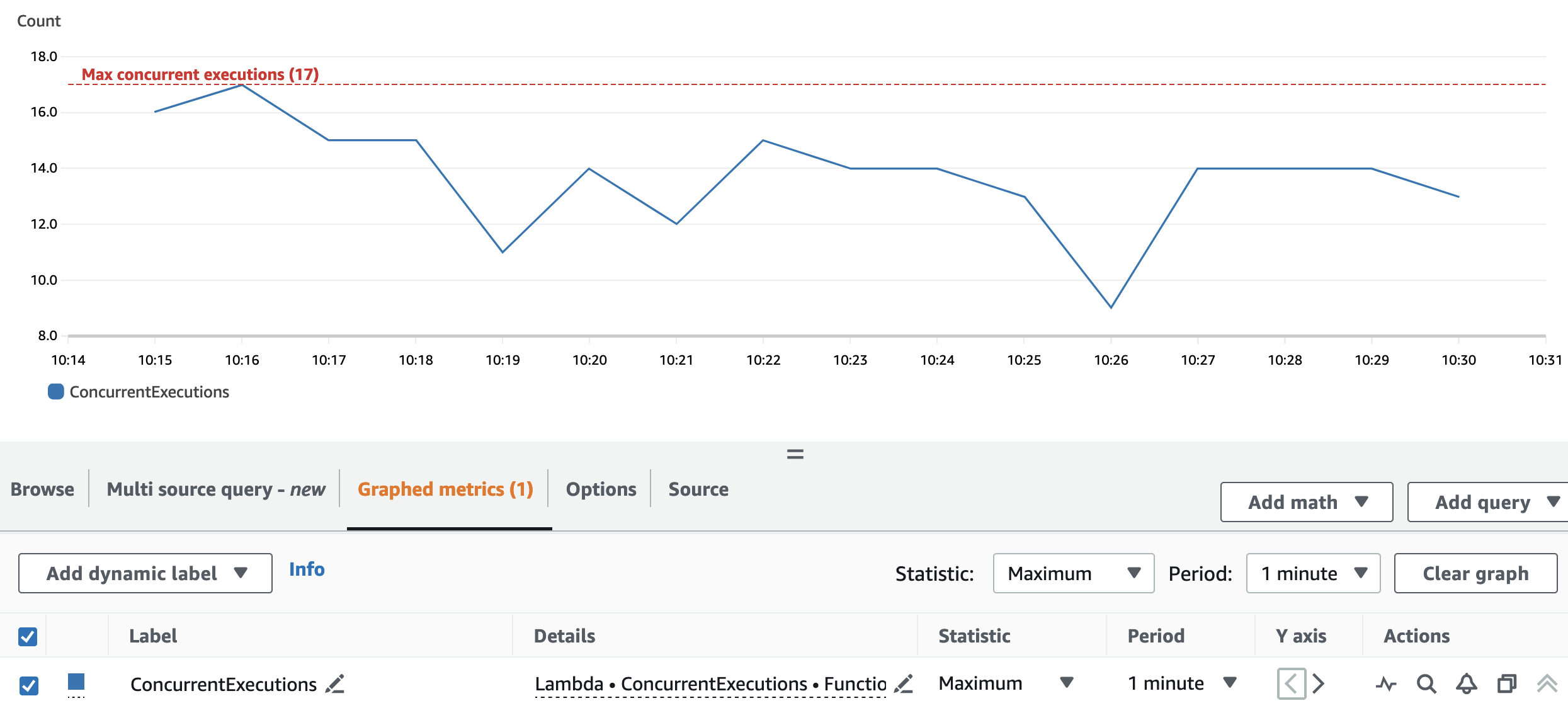
تسمح عملية إعادة التقسيم وتكوين المجموعة للتطبيق بمعالجة كافة أقسام Spark RDD بالتوازي. ونتيجة لذلك، تكون عمليات التشغيل المتزامنة لدالة Lambda دائمًا مساوية لرقم إعادة التقسيم أو أقل منه، وهو 17.
لتجنب التقييد، تأكد من أن مقدار مهام Spark التي يمكن معالجتها بالتوازي لا يتجاوز الحد الأقصى لتزامن دالة Lambda. بالنسبة لهذا الجانب، فإن نفس الاقتراحات الخاصة بحالة الاستخدام الدفعي صالحة.
الرسم البياني التالي يصور لامدا Duration متري، مع الإحصائية AVG باللون الأزرق و MAX باللون البرتقالي.
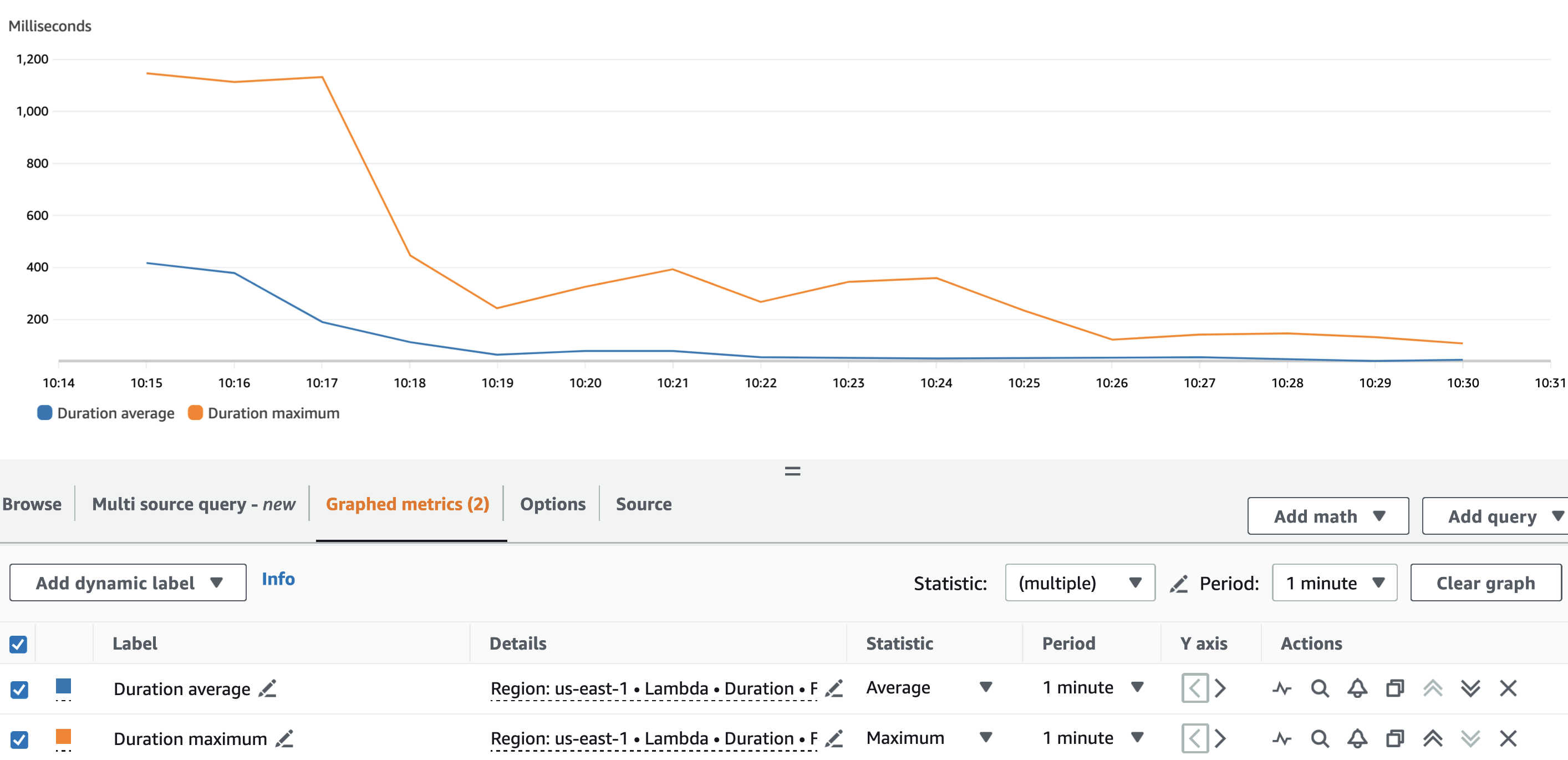
كما هو متوقع، بصرف النظر عن البداية الباردة لوظيفة Lambda، كان متوسط مدة وظيفة الاسم المستعار ثابتًا إلى حد ما طوال التشغيل. وذلك لأن batch_size تم ضبط القيمة، التي تحدد عدد أرقام VIN المراد تغيير اسمها المستعار لكل مكالمة، على 900 وظلت ثابتة.
يعد معدل استيعاب دفق بيانات Kinesis ومعدل استهلاك تطبيق البث الخاص بنا من العوامل التي تؤثر على عدد مكالمات واجهة برمجة التطبيقات (API) التي يتم إجراؤها مقابل خدمة الأسماء المستعارة وبالتالي التكلفة ذات الصلة.
الرسم البياني التالي يصور لامدا Invocations متري، مع الإحصائية SUM باللون البرتقالي، وتدفقات بيانات Kinesis GetRecords.Records متري، مع الإحصائية SUM باللون الأزرق. يمكننا أن نرى أن هناك ارتباطًا بين كمية السجلات المستردة من الدفق في الدقيقة وكمية استدعاءات دالة Lambda، مما يؤثر على تكلفة تشغيل الدفق.

بالإضافة إلى batch_interval، يمكننا التحكم في معدل استهلاك تطبيق البث باستخدام خصائص تدفق الشرارة مثل spark.streaming.receiver.maxRate و spark.streaming.blockInterval. لمزيد من التفاصيل ، يرجى الرجوع إلى شرارة الجري + التكامل الحركي و دليل برمجة Spark Streaming.
وفي الختام
قد يكون التنقل عبر القواعد واللوائح الخاصة بقوانين خصوصية البيانات أمرًا صعبًا. يُعد الاسم المستعار لسمات معلومات تحديد الهوية الشخصية إحدى النقاط العديدة التي يجب مراعاتها أثناء التعامل مع البيانات الحساسة.
في هذه السلسلة المكونة من جزأين، اكتشفنا كيف يمكنك إنشاء واستخدام خدمة الأسماء المستعارة باستخدام خدمات AWS المتنوعة مع ميزات لمساعدتك في بناء نظام أساسي قوي للبيانات. في جزء 1، قمنا ببناء الأساس من خلال توضيح كيفية بناء خدمة الأسماء المستعارة. في هذا المنشور، عرضنا الأنماط المختلفة لاستخدام خدمة الاسم المستعار بطريقة فعالة من حيث التكلفة وفعالة. تفحص ال GitHub جيثب: مستودع لأنماط الاستهلاك الإضافية.
حول المؤلف
 إدفين هالفاكشو هو مهندس أمن عالمي أقدم مع خدمات AWS الاحترافية وهو متحمس للأمن السيبراني والأتمتة. يساعد العملاء على بناء حلول آمنة ومتوافقة في السحابة. خارج العمل يحب السفر والرياضة.
إدفين هالفاكشو هو مهندس أمن عالمي أقدم مع خدمات AWS الاحترافية وهو متحمس للأمن السيبراني والأتمتة. يساعد العملاء على بناء حلول آمنة ومتوافقة في السحابة. خارج العمل يحب السفر والرياضة.
 راهول شوريا هو مهندس رئيسي للبيانات الضخمة في خدمات AWS الاحترافية. إنه يساعد العملاء ويعمل بشكل وثيق معهم في بناء منصات البيانات والتطبيقات التحليلية على AWS. خارج العمل، يحب راهول المشي لمسافات طويلة مع كلبه بارني.
راهول شوريا هو مهندس رئيسي للبيانات الضخمة في خدمات AWS الاحترافية. إنه يساعد العملاء ويعمل بشكل وثيق معهم في بناء منصات البيانات والتطبيقات التحليلية على AWS. خارج العمل، يحب راهول المشي لمسافات طويلة مع كلبه بارني.
 أندريا مونتاناري هو أحد كبار مهندسي البيانات الضخمة في خدمات AWS الاحترافية. إنه يدعم العملاء والشركاء بنشاط في بناء حلول التحليلات على نطاق واسع على AWS.
أندريا مونتاناري هو أحد كبار مهندسي البيانات الضخمة في خدمات AWS الاحترافية. إنه يدعم العملاء والشركاء بنشاط في بناء حلول التحليلات على نطاق واسع على AWS.
 ماريا جويرا هو مهندس بيانات كبير مع خدمات AWS الاحترافية. ماريا لديها خلفية في تحليلات البيانات والهندسة الميكانيكية. تساعد العملاء في تصميم أعباء العمل المتعلقة بالبيانات وتطويرها في السحابة.
ماريا جويرا هو مهندس بيانات كبير مع خدمات AWS الاحترافية. ماريا لديها خلفية في تحليلات البيانات والهندسة الميكانيكية. تساعد العملاء في تصميم أعباء العمل المتعلقة بالبيانات وتطويرها في السحابة.
 Pushpraj سينغ هو مهندس بيانات أول في خدمات AWS الاحترافية. إنه شغوف بهندسة البيانات وDevOps. إنه يساعد العملاء على بناء تطبيقات تعتمد على البيانات على نطاق واسع.
Pushpraj سينغ هو مهندس بيانات أول في خدمات AWS الاحترافية. إنه شغوف بهندسة البيانات وDevOps. إنه يساعد العملاء على بناء تطبيقات تعتمد على البيانات على نطاق واسع.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

