تسمح لك معالجة بيانات التدفق بالعمل على البيانات في الوقت الفعلي. يمكن أن تساعدك تحليلات البيانات في الوقت الفعلي في الحصول على استجابات محسّنة في الوقت المناسب مع تحسين تجربة العملاء بشكل عام.
اباتشي فلينك هو إطار عمل حسابي موزع يسمح بمعالجة البيانات في الوقت الحقيقي. إنه يوفر مجموعة واحدة من واجهات برمجة التطبيقات (API) لبناء المهام المتدفقة والدفق ، مما يسهل على المطورين العمل مع البيانات المحدودة وغير المحدودة. يوفر Apache Flink مستويات مختلفة من التجريد لتغطية مجموعة متنوعة من حالات استخدام معالجة الأحداث.
تحليلات بيانات Amazon Kinesis هي خدمة AWS توفر بنية أساسية بدون خادم لتشغيل تطبيقات Apache Flink. هذا يجعل من السهل على المطورين إنشاء تطبيقات Apache Flink متوفرة بدرجة عالية ومتسامحة مع الأخطاء وقابلة للتطوير دون الحاجة إلى أن تصبح خبيرًا في بناء مجموعات Apache Flink وتكوينها وصيانتها على AWS.
غالبًا ما تتطلب أحمال عمل دفق البيانات إثراء البيانات الموجودة في الدفق عبر مصادر خارجية (مثل قواعد البيانات أو تدفقات البيانات الأخرى). على سبيل المثال ، افترض أنك تتلقى بيانات الإحداثيات من جهاز GPS وتحتاج إلى فهم كيفية تعيين هذه الإحداثيات مع المواقع الجغرافية المادية ؛ تحتاج إلى إثرائه ببيانات تحديد الموقع الجغرافي. يمكنك استخدام عدة طرق لإثراء بياناتك في الوقت الفعلي في تحليلات بيانات Kinesis اعتمادًا على حالة الاستخدام ومستوى تجريد Apache Flink. لكل طريقة تأثيرات مختلفة على معدل النقل وحركة مرور الشبكة واستخدام وحدة المعالجة المركزية (أو الذاكرة). في هذا المنشور ، نغطي هذه الأساليب ونناقش مزاياها وعيوبها.
أنماط إثراء البيانات
إثراء البيانات هي عملية تلحق سياق إضافي وتعزز البيانات المجمعة. غالبًا ما يتم جمع البيانات الإضافية من مجموعة متنوعة من المصادر. يمكن أن يتراوح تنسيق تحديثات البيانات وتكرارها من مرة في الشهر إلى عدة مرات في الثانية. يعرض الجدول التالي بعض الأمثلة على المصادر المختلفة ، والتنسيقات ، وتكرار التحديث.
| البيانات | شكل | تحديث التردد |
| يتراوح عنوان IP حسب البلد | CSV | مرة في الشهر |
| الهيكل التنظيمي للشركة | JSON | مرتين في السنة |
| أسماء الأجهزة بالمعرف | CSV | يوميا |
| معلومات الموظف | جدول (قاعدة بيانات علائقية) | عدة مرات في اليوم |
| معلومات العميل | جدول (قاعدة بيانات غير علائقية) | عدة مرات في الساعة |
| طلبات العملاء | جدول (قاعدة بيانات علائقية) | مرات عديدة في الثانية |
بناءً على حالة الاستخدام ، قد يكون لتطبيق إثراء البيانات الخاص بك متطلبات مختلفة من حيث زمن الوصول أو الإنتاجية أو عوامل أخرى. يتعمق الجزء المتبقي من المنشور بشكل أعمق في أنماط مختلفة لإثراء البيانات في تحليلات بيانات Kinesis ، والتي تم سردها في الجدول التالي بخصائصها الرئيسية. يمكنك اختيار أفضل نمط بناءً على مقايضة هذه الخصائص.
| نمط الإثراء | كمون | الإنتاجية | الدقة إذا تغيرت البيانات المرجعية | استخدام الذاكرة | تعقيد |
| تحميل البيانات المرجعية مسبقًا في ذاكرة إدارة مهام Apache Flink | منخفض | مرتفع | منخفض | مرتفع | منخفض |
| التحميل المسبق المقسم للبيانات المرجعية في حالة Apache Flink | منخفض | مرتفع | منخفض | منخفض | منخفض |
| التحميل المسبق الدوري للبيانات المرجعية في حالة Apache Flink | منخفض | مرتفع | متوسط | منخفض | متوسط |
| بحث غير متزامن لكل سجل مع خريطة غير مرتبة | متوسط | متوسط | مرتفع | منخفض | منخفض |
| بحث غير متزامن لكل سجل من نظام ذاكرة تخزين مؤقت خارجي | منخفض أو متوسط (حسب تخزين ذاكرة التخزين المؤقت والتنفيذ) | متوسط | مرتفع | منخفض | متوسط |
| إثراء التدفقات باستخدام Table API | منخفض | مرتفع | مرتفع | منخفض - متوسط (حسب عامل الانضمام المحدد) | منخفض |
إثراء تدفق البيانات عن طريق التحميل المسبق للبيانات المرجعية
عندما تكون البيانات المرجعية صغيرة الحجم وثابتة في طبيعتها (على سبيل المثال ، بيانات الدولة بما في ذلك رمز البلد واسم الدولة) ، يوصى بإثراء بياناتك المتدفقة عن طريق التحميل المسبق للبيانات المرجعية ، وهو ما يمكنك القيام به بعدة طرق.
للاطلاع على تنفيذ الكود للبيانات المرجعية التي يتم تحميلها مسبقًا بطرق مختلفة ، ارجع إلى جيثب ريبو. اتبع التعليمات الموجودة في مستودع GitHub لتشغيل الكود وفهم نموذج البيانات.
التحميل المسبق للبيانات المرجعية في ذاكرة Apache Flink Task Manager
إن أبسط وأسرع طريقة للتخصيب هي تحميل بيانات التخصيب في كل ذاكرة من ذاكرة الكومة الخاصة بمديري مهام Apache Flink. لتنفيذ هذه الطريقة ، يمكنك إنشاء فئة جديدة عن طريق توسيع الامتداد RichFlatMapFunction فئة مجردة. تقوم بتعريف متغير ثابت عام في تعريف صنفك. يمكن أن يكون المتغير من أي نوع ، والقيد الوحيد هو أنه يجب أن يمتد java.io.Serializable-فمثلا، java.util.HashMap. في حدود open() الطريقة ، يمكنك تحديد منطق يقوم بتحميل البيانات الثابتة في المتغير المحدد الخاص بك. ال open() يتم استدعاء الطريقة دائمًا أولاً ، أثناء تهيئة كل مهمة في مديري مهام Apache Flink ، والتي تتأكد من تحميل البيانات المرجعية بالكامل قبل بدء المعالجة. يمكنك تنفيذ منطق المعالجة الخاص بك عن طريق تجاوز processElement() طريقة. تقوم بتنفيذ منطق المعالجة الخاص بك والوصول إلى البيانات المرجعية من خلال مفتاحها من المتغير العام المحدد.
يوضح الرسم التخطيطي للهندسة المعمارية التالي تحميل البيانات المرجعية الكامل في كل فتحة مهمة لمدير المهام.
هذه الطريقة لها الفوائد التالية:
- سهل التنفيذ
- الكمون المنخفض
- يمكن أن تدعم الإنتاجية العالية
ومع ذلك ، فإن لها العيوب التالية:
- إذا كانت البيانات المرجعية كبيرة الحجم ، فقد تنفد ذاكرة مدير مهام Apache Flink.
- يمكن أن تصبح البيانات المرجعية قديمة خلال فترة زمنية.
- يتم تحميل نسخ متعددة من نفس البيانات المرجعية في كل فتحة مهمة في مدير المهام.
- يجب أن تكون البيانات المرجعية صغيرة لتلائم الذاكرة المخصصة لفتحة مهمة واحدة. في Kinesis Data Analytics ، تحتوي كل وحدة معالجة Kinesis (KPU) على 4 غيغابايت من الذاكرة ، منها 3 غيغابايت يمكن استخدامها لذاكرة الكومة. إذا
ParallelismPerKPUفي Kinesis Data Analytics مضبوطًا على 1 ، ويتم تشغيل فتحة مهمة واحدة في كل مدير مهام ، ويمكن أن تستخدم فتحة المهام مساحة 3 غيغابايت بالكامل من ذاكرة الكومة. إذاParallelismPerKPUتم تعيينه على قيمة أكبر من 1 ، ويتم توزيع 3 غيغابايت من ذاكرة الكومة عبر فتحات مهام متعددة في مدير المهام. إذا كنت تنشر Apache Flink بتنسيق أمازون EMR أو في وضع الإدارة الذاتية ، يمكنك الضبطtaskmanager.memory.task.heap.sizeلزيادة ذاكرة الكومة الخاصة بمدير المهام.
التحميل المسبق المقسم للبيانات المرجعية في حالة Apache Flink
في هذا النهج ، يتم تحميل البيانات المرجعية والاحتفاظ بها في مخزن حالة Apache Flink في بداية تطبيق Apache Flink. لتحسين استخدام الذاكرة ، يتم أولاً تقسيم تدفق البيانات الرئيسي على حقل محدد عبر keyBy() عامل عبر جميع فتحات المهام. علاوة على ذلك ، يتم تحميل جزء البيانات المرجعية الذي يتوافق مع كل فتحة مهمة فقط في مخزن الحالة.
يتم تحقيق ذلك في Apache Flink عن طريق إنشاء الفصل PartitionPreLoadEnrichmentData، تمديد RichFlatMapFunction فئة مجردة. ضمن الطريقة المفتوحة ، يمكنك تجاوز ValueStateDescriptor طريقة لإنشاء مقبض الحالة. في المثال المشار إليه ، تم تسمية الواصف locationRefData، ونوع مفتاح الحالة هو String ، ونوع القيمة هو Location. في هذا الرمز ، نستخدم ValueState مقارنة MapState لأننا نحتفظ فقط ببيانات مرجع الموقع لمفتاح معين. على سبيل المثال ، عندما نستعلم عن Amazon S3 للحصول على بيانات مرجع الموقع ، فإننا نستعلم عن الدور المحدد ونحصل على موقع معين كقيمة.
في Apache Flink ، ValueState يستخدم للاحتفاظ بقيمة محددة لمفتاح ، بينما MapState يستخدم لعقد مجموعة من أزواج القيمة الرئيسية.
هذه التقنية مفيدة عندما يكون لديك مجموعة بيانات ثابتة كبيرة يصعب وضعها في الذاكرة ككل لكل قسم.
يوضح الرسم التخطيطي للهندسة المعمارية التالي تحميل البيانات المرجعية للمفتاح المحدد لكل قسم من أقسام الدفق.
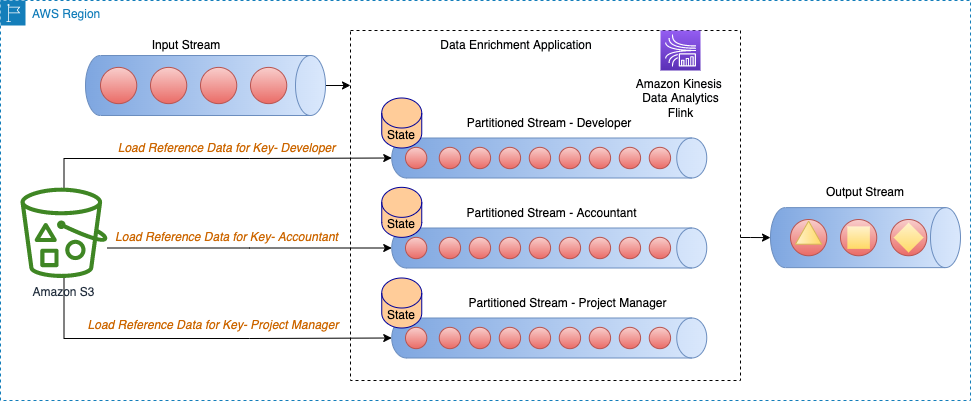
على سبيل المثال ، تحتوي بياناتنا المرجعية في نموذج كود GitHub على أدوار معينة لكل مبنى. نظرًا لأن الدفق مقسم حسب الأدوار ، يلزم تحميل معلومات البناء المحددة لكل دور فقط لكل قسم كبيانات مرجعية.
هذه الطريقة لها الفوائد التالية:
- قليل من الكمون.
- يمكن أن تدعم الإنتاجية العالية.
- يتم تحميل البيانات المرجعية لقسم معين في حالة المفتاح.
- في Kinesis Data Analytics ، يكون مخزن الحالة الافتراضي الذي تم تكوينه هو RocksDB. يمكن لـ RocksDB استخدام جزء كبير من 1 غيغابايت من الذاكرة المدارة و 50 غيغابايت من مساحة القرص التي توفرها كل KPU. يوفر هذا مساحة كافية لنمو البيانات المرجعية.
ومع ذلك ، فإن لها العيوب التالية:
- يمكن أن تصبح البيانات المرجعية قديمة خلال فترة زمنية
التحميل المسبق الدوري للبيانات المرجعية في حالة Apache Flink
هذا النهج هو ضبط دقيق للتقنية السابقة ، حيث يتم إعادة تحميل كل بيانات مرجعية مقسمة على أساس دوري لتحديث البيانات المرجعية. هذا مفيد إذا كانت بياناتك المرجعية تتغير من حين لآخر.
يُظهر مخطط البنية التالي الحمل الدوري للبيانات المرجعية للمفتاح المحدد لكل قسم من أقسام الدفق.

في هذا النهج ، الطبقة PeriodicPerPartitionLoadEnrichmentData تم إنشاؤه ، لتوسيع نطاق KeyedProcessFunction صف دراسي. على غرار النمط السابق ، في سياق مثال GitHub ، ValueState يوصى به هنا لأن كل قسم يقوم بتحميل قيمة واحدة فقط للمفتاح. بنفس الطريقة كما ذكرنا سابقًا ، في open الطريقة ، يمكنك تحديد ValueStateDescriptor للتعامل مع حالة القيمة وتحديد سياق وقت التشغيل للوصول إلى الحالة.
ضمن processElement الطريقة ، قم بتحميل حالة القيمة وإرفاق البيانات المرجعية (في مثال GitHub المشار إليه ، buildingNo لبيانات العميل). قم أيضًا بتسجيل خدمة المؤقت ليتم استدعاؤها عندما يمر وقت المعالجة بالوقت المحدد. في نموذج التعليمات البرمجية ، تمت جدولة خدمة المؤقت ليتم استدعاؤها بشكل دوري (على سبيل المثال ، كل 60 ثانية). في ال onTimer الطريقة ، قم بتحديث الحالة عن طريق إجراء مكالمة لإعادة تحميل البيانات المرجعية للدور المحدد.
هذه الطريقة لها الفوائد التالية:
- قليل من الكمون.
- يمكن أن تدعم الإنتاجية العالية.
- يتم تحميل البيانات المرجعية لأقسام معينة في حالة المفاتيح.
- يتم تحديث البيانات المرجعية بشكل دوري.
- في Kinesis Data Analytics ، يكون مخزن الحالة الافتراضي الذي تم تكوينه هو RocksDB. أيضًا ، توفر كل KPU مساحة 50 جيجابايت على القرص. يوفر هذا مساحة كافية لنمو البيانات المرجعية.
ومع ذلك ، فإن لها العيوب التالية:
- إذا تغيرت البيانات المرجعية بشكل متكرر ، فلا يزال التطبيق يحتوي على بيانات قديمة اعتمادًا على مدى تكرار إعادة تحميل الحالة
- يمكن أن يواجه التطبيق ارتفاعات في التحميل أثناء إعادة تحميل البيانات المرجعية
إثراء تدفق البيانات باستخدام البحث لكل سجل
على الرغم من أن التحميل المسبق للبيانات المرجعية يوفر زمن انتقال منخفضًا وإنتاجية عالية ، فقد لا يكون مناسبًا لأنواع معينة من أحمال العمل ، مثل ما يلي:
- تحديثات البيانات المرجعية عالية التردد
- يحتاج Apache Flink إلى إجراء مكالمة خارجية لحساب منطق الأعمال
- تعد دقة المخرجات مهمة ويجب ألا يستخدم التطبيق بيانات قديمة
عادةً ، بالنسبة لهذه الأنواع من حالات الاستخدام ، يقوم المطورون بمقايضة الإنتاجية العالية والكمون المنخفض من أجل دقة البيانات. في هذا القسم ، ستتعرف على عدد قليل من التطبيقات الشائعة لإثراء البيانات لكل سجل وفوائدها وعيوبها.
بحث غير متزامن لكل سجل مع خريطة غير مرتبة
في تطبيق بحث متزامن لكل سجل ، يتعين على تطبيق Apache Flink الانتظار حتى يتلقى الاستجابة بعد إرسال كل طلب. يؤدي هذا إلى بقاء المعالج خاملاً لفترة طويلة من وقت المعالجة. بدلاً من ذلك ، يمكن للتطبيق إرسال طلب لعناصر أخرى في الدفق أثناء انتظار استجابة العنصر الأول. بهذه الطريقة ، يتم إطفاء وقت الانتظار عبر طلبات متعددة وبالتالي يزيد من معدل نقل البيانات. يوفر Apache Flink ملفات I / O غير متزامن للوصول إلى البيانات الخارجية. أثناء استخدام هذا النمط ، عليك أن تقرر بين unorderedWait (حيث ترسل النتيجة إلى المشغل التالي بمجرد تلقي الاستجابة ، بغض النظر عن ترتيب العنصر في الدفق) و orderedWait (حيث ينتظر حتى تكتمل جميع عمليات الإدخال / الإخراج على متن الطائرة ، ثم يرسل النتائج إلى المشغل التالي بنفس ترتيب وضع العناصر الأصلية في الدفق). عادة ، عندما يتجاهل مستهلكو المصب ترتيب العناصر في الدفق ، unorderedWait يوفر إنتاجية أفضل ووقت خمول أقل. يزور قم بإثراء تدفق البيانات بشكل غير متزامن باستخدام تحليلات بيانات Kinesis لـ Apache Flink لمعرفة المزيد عن هذا النمط.
يوضح الرسم التخطيطي للهندسة المعمارية التالي كيف يقوم تطبيق Apache Flink في Kinesis Data Analytics بإجراء استدعاءات غير متزامنة لمحرك قاعدة بيانات خارجي (على سبيل المثال الأمازون DynamoDB) لكل حدث في البث الرئيسي.
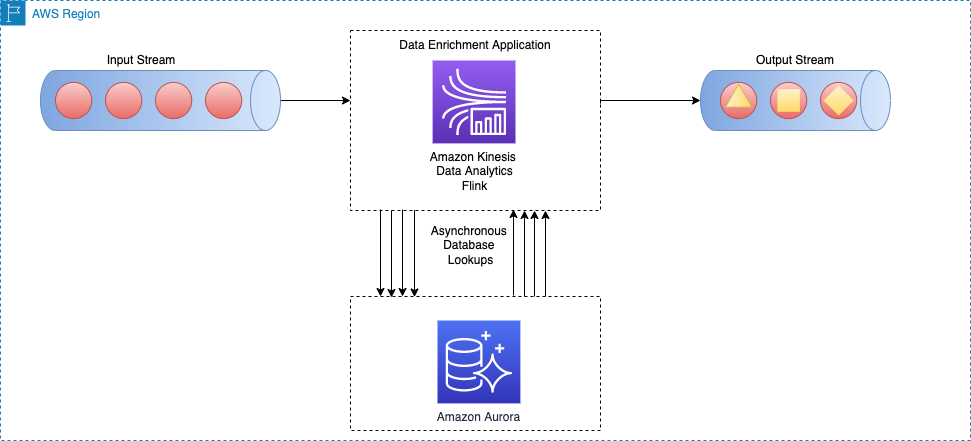
هذه الطريقة لها الفوائد التالية:
- لا يزال بسيطًا إلى حد معقول وسهل التنفيذ
- يقرأ أحدث البيانات المرجعية
ومع ذلك ، فإن لها العيوب التالية:
- يقوم بإنشاء حمل قراءة ثقيل للنظام الخارجي (على سبيل المثال ، محرك قاعدة بيانات أو واجهة برمجة تطبيقات خارجية) الذي يستضيف البيانات المرجعية
- بشكل عام ، قد لا يكون مناسبًا للأنظمة التي تتطلب إنتاجية عالية مع زمن انتقال منخفض
بحث غير متزامن لكل سجل من نظام ذاكرة تخزين مؤقت خارجي
تتمثل إحدى طرق تحسين النمط السابق في استخدام نظام ذاكرة التخزين المؤقت لتحسين وقت القراءة لكل مكالمة إدخال / إخراج بحث. يمكنك استخدام أمازون ElastiCache For التخزين المؤقت، والذي يعمل على تسريع أداء التطبيق وقواعد البيانات ، أو كمخزن بيانات أساسي لحالات الاستخدام التي لا تتطلب متانة مثل مخازن الجلسات ولوحات المتصدرين للألعاب والبث والتحليلات. ElastiCache متوافق مع Redis و Memcached.
لكي يعمل هذا النمط ، يجب عليك تنفيذ نمط التخزين المؤقت لملء البيانات في تخزين ذاكرة التخزين المؤقت. يمكنك الاختيار بين نهج استباقي أو تفاعلي وفقًا لأهداف التطبيق ومتطلبات زمن الوصول. لمزيد من المعلومات ، يرجى الرجوع إلى أنماط التخزين المؤقت.
يوضح الرسم التخطيطي للهندسة المعمارية التالي كيف يستدعي تطبيق Apache Flink قراءة البيانات المرجعية من وحدة تخزين خارجية للتخزين المؤقت (على سبيل المثال ، Amazon ElastiCache لـ Redis). يجب نسخ تغييرات البيانات من قاعدة البيانات الرئيسية (على سبيل المثال ، أمازون أورورا) إلى ذاكرة التخزين المؤقت من خلال تنفيذ أحد ملفات أنماط التخزين المؤقت.
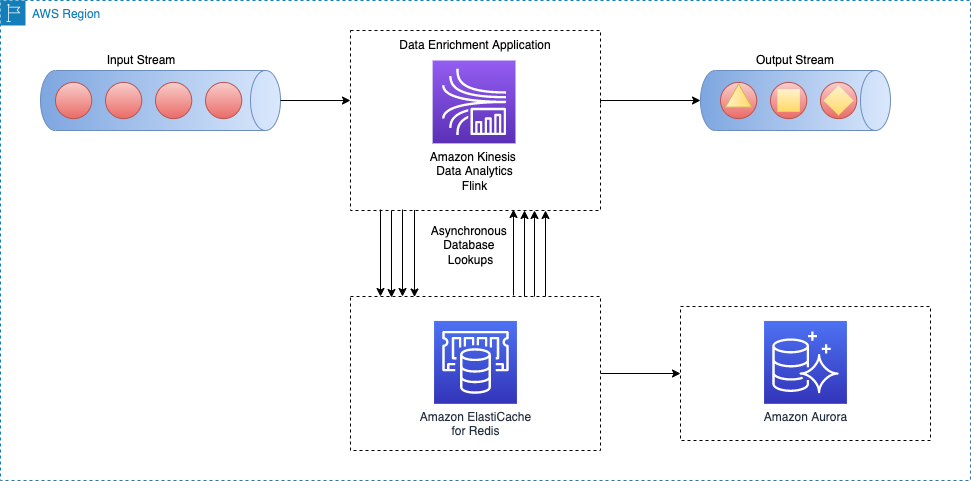
يشبه تنفيذ نمط إثراء البيانات هذا نمط البحث غير المتزامن لكل سجل ؛ الاختلاف الوحيد هو أن تطبيق Apache Flink يقوم بإجراء اتصال بتخزين ذاكرة التخزين المؤقت ، بدلاً من الاتصال بقاعدة البيانات الأساسية.
هذه الطريقة لها الفوائد التالية:
- إنتاجية أفضل لأن التخزين المؤقت يمكنه تسريع أداء التطبيق وقاعدة البيانات
- يحمي مصدر البيانات الأساسي من حركة مرور القراءة التي تم إنشاؤها بواسطة تطبيق معالجة الدفق
- يمكن أن توفر وقت استجابة أقل للقراءة لكل مكالمة بحث
- بشكل عام ، قد لا يكون مناسبًا لأنظمة الإنتاجية المتوسطة إلى العالية التي ترغب في تحسين حداثة البيانات
ومع ذلك ، فإن لها العيوب التالية:
- تعقيد إضافي لتنفيذ نمط ذاكرة التخزين المؤقت لملء البيانات ومزامنتها بين قاعدة البيانات الأساسية وتخزين ذاكرة التخزين المؤقت
- هناك فرصة لتطبيق معالجة دفق Apache Flink لقراءة البيانات المرجعية التي لا معنى لها اعتمادًا على نمط التخزين المؤقت الذي يتم تنفيذه
- اعتمادًا على نمط ذاكرة التخزين المؤقت المختار (استباقي أو تفاعلي) ، قد يختلف وقت الاستجابة لكل إدخال / إخراج تخصيب ، وبالتالي قد يكون وقت المعالجة الإجمالي للدفق غير متوقع
بدلاً من ذلك ، يمكنك تجنب هذه التعقيدات باستخدام موصل Apache Flink JDBC لواجهات برمجة تطبيقات Flink SQL. نناقش بيانات دفق الإثراء عبر Flink SQL APIs بمزيد من التفاصيل لاحقًا في هذا المنشور.
إثراء دفق البيانات عبر دفق آخر
في هذا النمط ، يتم إثراء البيانات الموجودة في الدفق الرئيسي بالبيانات المرجعية في دفق بيانات آخر. هذا النمط مفيد لحالات الاستخدام التي يتم فيها تحديث البيانات المرجعية بشكل متكرر ومن الممكن إجراء التقاط بيانات التغيير (CDC) ونشر الأحداث إلى خدمة دفق البيانات مثل Apache Kafka أو الأمازون كينسيس دفق البيانات. هذا النمط مفيد في حالات الاستخدام التالية ، على سبيل المثال:
- يتم نشر أوامر الشراء الخاصة بالعميل في تدفق بيانات Kinesis ، ثم الانضمام إلى معلومات فوترة العميل في ملف تيار DynamoDB
- يجب إثراء أحداث البيانات التي تم التقاطها من أجهزة إنترنت الأشياء بالبيانات المرجعية في جدول بتنسيق خدمة قاعدة بيانات الأمازون (أمازون آر دي إس)
- يجب إثراء أحداث سجل الشبكة باسم الجهاز على عناوين IP المصدر (والوجهة)
يوضح الرسم التخطيطي للهندسة المعمارية التالي كيف يقوم تطبيق Apache Flink في Kinesis Data Analytics بدمج البيانات في الدفق الرئيسي مع بيانات CDC في دفق DynamoDB.

لإثراء دفق البيانات من دفق آخر ، نستخدم دفقًا مشتركًا لدفق أنماط الانضمام ، والتي نوضحها في الأقسام التالية.
إثراء التدفقات باستخدام Table API
توفر واجهات برمجة تطبيقات Apache Flink Table تجريدًا أعلى للعمل مع أحداث البيانات. مع واجهات برمجة تطبيقات الجدول، يمكنك تحديد دفق البيانات الخاص بك كجدول وإرفاق مخطط البيانات به.
في هذا النمط ، يمكنك تحديد جداول لكل دفق بيانات ثم ضم هذه الجداول لتحقيق أهداف إثراء البيانات. دعم واجهات برمجة تطبيقات Apache Flink Table أنواع مختلفة من شروط الانضمام، مثل الصلة الداخلية والرابط الخارجي. ومع ذلك ، فأنت تريد تجنب ذلك إذا كنت تتعامل مع تدفقات غير محدودة لأنها تتطلب موارد كثيرة. للحد من استخدام الموارد وتشغيل الصلات بشكل فعال ، يجب عليك استخدام الصلات الفاصلة أو المؤقتة. تتطلب صلة الفاصل الزمني مسندًا واحدًا للوصلة المتساوية وشرطًا للربط يحد الوقت على كلا الجانبين. لفهم كيفية تنفيذ صلة الفاصل الزمني بشكل أفضل ، راجع ابدأ مع Apache Flink SQL APIs في Kinesis Data Analytics Studio.
مقارنةً بوصلات الفاصل الزمني ، لا تعمل صلات الجدول الزمني مع فترة زمنية يتم خلالها الاحتفاظ بإصدارات مختلفة من السجل. يتم دائمًا ربط السجلات من الدفق الرئيسي بالإصدار المقابل من البيانات المرجعية في الوقت المحدد بواسطة العلامة المائية. لذلك ، تبقى إصدارات أقل من البيانات المرجعية في الحالة.
لاحظ أن البيانات المرجعية قد تحتوي أو لا تحتوي على عنصر وقت مرتبط بها. إذا لم يحدث ذلك ، فقد تحتاج إلى إضافة عنصر وقت معالجة للانضمام مع الدفق المستند إلى الوقت.
في المثال التالي مقتطف الشفرة ، ملف update_time يضاف العمود إلى currency_rates الجدول المرجعي من تغيير البيانات الوصفية لالتقاط البيانات مثل Debezium. علاوة على ذلك ، يتم استخدامه لتعريف ملف العلامة المائية استراتيجية للجدول.
حول المؤلف
 علي العليمي هو مهندس حلول متخصص في البث في AWS. ينصح علي عملاء AWS بأفضل الممارسات المعمارية ويساعدهم على تصميم أنظمة بيانات تحليلات في الوقت الفعلي تكون موثوقة وآمنة وفعالة وفعالة من حيث التكلفة. يعمل بشكل رجعي من حالات استخدام العملاء ويصمم حلول البيانات لحل مشاكل أعمالهم. قبل الانضمام إلى AWS ، دعم علي العديد من عملاء القطاع العام وشركاء AWS الاستشاريين في رحلة تحديث التطبيقات الخاصة بهم والانتقال إلى السحابة.
علي العليمي هو مهندس حلول متخصص في البث في AWS. ينصح علي عملاء AWS بأفضل الممارسات المعمارية ويساعدهم على تصميم أنظمة بيانات تحليلات في الوقت الفعلي تكون موثوقة وآمنة وفعالة وفعالة من حيث التكلفة. يعمل بشكل رجعي من حالات استخدام العملاء ويصمم حلول البيانات لحل مشاكل أعمالهم. قبل الانضمام إلى AWS ، دعم علي العديد من عملاء القطاع العام وشركاء AWS الاستشاريين في رحلة تحديث التطبيقات الخاصة بهم والانتقال إلى السحابة.
 سوبهام ركشيت هو مهندس حلول متخصص في البث للتحليلات في AWS ومقره في المملكة المتحدة. يعمل مع العملاء لتصميم وبناء منصات بحث وتدفق البيانات التي تساعدهم على تحقيق أهداف أعمالهم. خارج العمل ، يستمتع بقضاء الوقت في حل ألغاز الصور المقطوعة مع ابنته.
سوبهام ركشيت هو مهندس حلول متخصص في البث للتحليلات في AWS ومقره في المملكة المتحدة. يعمل مع العملاء لتصميم وبناء منصات بحث وتدفق البيانات التي تساعدهم على تحقيق أهداف أعمالهم. خارج العمل ، يستمتع بقضاء الوقت في حل ألغاز الصور المقطوعة مع ابنته.
 د. سام مختاري هو مهندس حلول أول في AWS. مجال العمق الرئيسي له هو البيانات والتحليلات ، وقد نشر أكثر من 30 مقالة مؤثرة في هذا المجال. وهو أيضًا مستشار بيانات وتحليلات مرموق قاد العديد من مشاريع التنفيذ واسعة النطاق في مختلف الصناعات ، بما في ذلك الطاقة والصحة والاتصالات والنقل.
د. سام مختاري هو مهندس حلول أول في AWS. مجال العمق الرئيسي له هو البيانات والتحليلات ، وقد نشر أكثر من 30 مقالة مؤثرة في هذا المجال. وهو أيضًا مستشار بيانات وتحليلات مرموق قاد العديد من مشاريع التنفيذ واسعة النطاق في مختلف الصناعات ، بما في ذلك الطاقة والصحة والاتصالات والنقل.

