يستمر حجم البيانات التي يتم إنشاؤها عالميًا في الارتفاع، بدءًا من الألعاب وتجارة التجزئة والتمويل إلى التصنيع والرعاية الصحية والسفر. تبحث المؤسسات عن المزيد من الطرق لاستخدام التدفق المستمر للبيانات بسرعة للابتكار لأعمالها وعملائها. يتعين عليهم التقاط البيانات ومعالجتها وتحليلها وتحميلها بشكل موثوق في عدد لا يحصى من مخازن البيانات، كل ذلك في الوقت الفعلي.
يعد Apache Kafka خيارًا شائعًا لاحتياجات البث في الوقت الفعلي. ومع ذلك، قد يكون من الصعب إعداد مجموعة Kafka جنبًا إلى جنب مع مكونات معالجة البيانات الأخرى التي يتم ضبطها تلقائيًا وفقًا لاحتياجات التطبيق الخاص بك. أنت تخاطر بالنقص في التزويد لحركة المرور القصوى، مما قد يؤدي إلى التوقف، أو الإفراط في التزويد بالحمل الأساسي، مما يؤدي إلى الهدر. تقدم AWS خدمات متعددة بدون خادم مثل Amazon Managed Streaming لأباتشي كافكا (أمازون MSK) ، خرطوم بيانات أمازون, الأمازون DynamoDBو AWS لامدا هذا المقياس تلقائيًا حسب احتياجاتك.
وفي هذه التدوينة، نوضح كيف يمكنك استخدام بعض هذه الخدمات، بما في ذلك MSK بدون خادم، لإنشاء منصة بيانات بدون خادم لتلبية احتياجاتك في الوقت الفعلي.
حل نظرة عامة
دعونا نتخيل السيناريو. أنت مسؤول عن إدارة الآلاف من أجهزة المودم لموفر خدمة الإنترنت المنتشر عبر مناطق جغرافية متعددة. تريد مراقبة جودة اتصال المودم التي لها تأثير كبير على إنتاجية العملاء ورضاهم. يتضمن النشر الخاص بك أجهزة مودم مختلفة تحتاج إلى المراقبة والصيانة لضمان الحد الأدنى من وقت التوقف عن العمل. يرسل كل جهاز آلاف السجلات بحجم 1 كيلو بايت كل ثانية، مثل استخدام وحدة المعالجة المركزية واستخدام الذاكرة والإنذار وحالة الاتصال. أنت تريد الوصول في الوقت الفعلي إلى هذه البيانات حتى تتمكن من مراقبة الأداء في الوقت الفعلي واكتشاف المشكلات وتخفيفها بسرعة. تحتاج أيضًا إلى الوصول على المدى الطويل إلى هذه البيانات لنماذج التعلم الآلي (ML) لإجراء تقييمات الصيانة التنبؤية، والعثور على فرص التحسين، والتنبؤ بالطلب.
عملاؤك الذين يجمعون البيانات في الموقع مكتوبون بلغة Python، ويمكنهم إرسال جميع البيانات كمواضيع Apache Kafka إلى Amazon MSK. للوصول إلى البيانات في الوقت الفعلي وزمن الوصول المنخفض لتطبيقك، يمكنك استخدام لامدا ودينامو دي بي. لتخزين البيانات على المدى الطويل، يمكنك استخدام خدمة الموصل المُدارة بدون خادم خرطوم بيانات أمازون لإرسال البيانات إلى بحيرة البيانات الخاصة بك.
يوضح الرسم البياني التالي كيف يمكنك إنشاء هذا التطبيق الشامل بدون خادم.
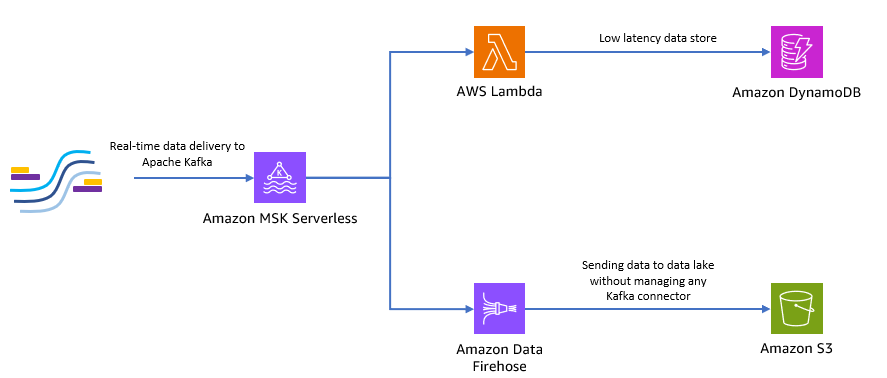
دعونا نتبع الخطوات الواردة في الأقسام التالية لتنفيذ هذه البنية.
قم بإنشاء مجموعة كافكا بدون خادم على Amazon MSK
نحن نستخدم Amazon MSK لاستيعاب بيانات القياس عن بعد في الوقت الفعلي من أجهزة المودم. يعد إنشاء مجموعة Kafka بدون خادم أمرًا سهلاً على Amazon MSK. يستغرق الأمر بضع دقائق فقط باستخدام وحدة تحكم إدارة AWS أو AWS SDK. لاستخدام وحدة التحكم، راجع الشروع في استخدام مجموعات MSK Serverless. يمكنك إنشاء مجموعة بدون خادم، إدارة الهوية والوصول AWS (IAM) الدور وجهاز العميل.
قم بإنشاء موضوع كافكا باستخدام بايثون
عندما يصبح نظام المجموعة وجهاز العميل لديك جاهزين، قم بتوصيل SSH إلى جهاز العميل الخاص بك وقم بتثبيت Kafka Python ومكتبة MSK IAM لـ Python.
- قم بتشغيل الأوامر التالية لتثبيت Kafka Python و مكتبة MSK IAM:
- إنشاء ملف جديد يسمى
createTopic.py. - انسخ الكود التالي في هذا الملف، مع استبدال
bootstrap_serversوregionالمعلومات مع تفاصيل مجموعتك. للحصول على تعليمات حول استردادbootstrap_serversمعلومات عن مجموعة MSK الخاصة بك، راجع الحصول على وسطاء التمهيد لمجموعة Amazon MSK.
- تشغيل
createTopic.pyالبرنامج النصي لإنشاء موضوع كافكا جديد يسمىmytopicعلى مجموعتك بدون خادم:
إنتاج السجلات باستخدام بايثون
لنقم بإنشاء بعض نماذج بيانات القياس عن بعد للمودم.
- إنشاء ملف جديد يسمى
kafkaDataGen.py. - انسخ الكود التالي في هذا الملف لتحديث ملف
BROKERSوregionالمعلومات مع تفاصيل مجموعتك:
- تشغيل
kafkaDataGen.pyلإنشاء بيانات عشوائية بشكل مستمر ونشرها على موضوع كافكا المحدد:
قم بتخزين الأحداث في Amazon S3
الآن يمكنك تخزين جميع بيانات الأحداث الأولية في ملف خدمة تخزين أمازون البسيطة (Amazon S3) بحيرة البيانات للتحليلات. يمكنك استخدام نفس البيانات لتدريب نماذج تعلم الآلة. ال التكامل مع Amazon Data Firehose يسمح لـ Amazon MSK بتحميل البيانات بسلاسة من مجموعات Apache Kafka الخاصة بك إلى مستودع بيانات S3. أكمل الخطوات التالية لتدفق البيانات بشكل مستمر من Kafka إلى Amazon S3، مما يلغي الحاجة إلى إنشاء تطبيقات الموصل الخاصة بك أو إدارتها:
- على وحدة تحكم Amazon S3، قم بإنشاء حاوية جديدة. يمكنك أيضًا استخدام مجموعة موجودة.
- قم بإنشاء مجلد جديد في مجموعة S3 الخاصة بك يسمى
streamingDataLake. - في وحدة تحكم Amazon MSK، اختر مجموعة MSK Serverless الخاصة بك.
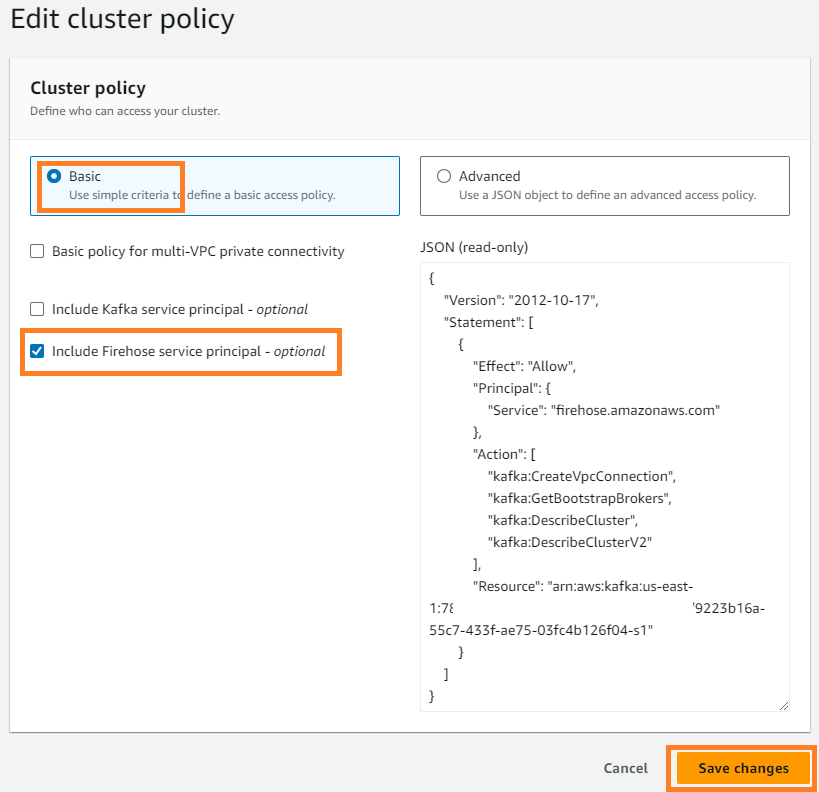
- على الإجراءات القائمة، اختر تحرير نهج الكتلة.

- أختار تضمين مدير خدمة Firehose واختر حفظ التغييرات.
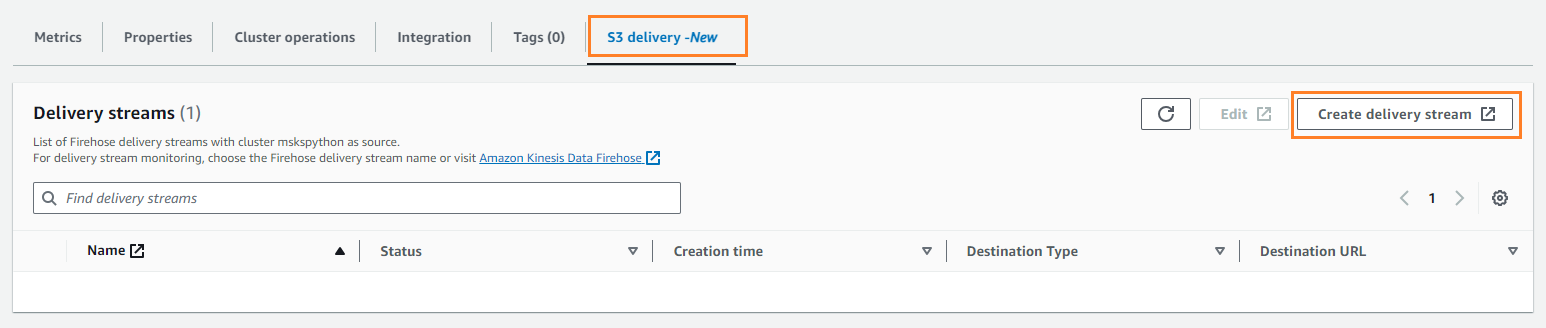
- على تسليم S3 علامة التبويب، اختر إنشاء دفق التسليم.
- في حالة مصدر، اختر أمازون MSK.
- في حالة الرحلات، اختر الأمازون S3.

- في حالة اتصال مجموعة Amazon MSK، حدد وسطاء التمهيد الخاصين.
- في حالة موضوع، أدخل اسم الموضوع (لهذه المشاركة،
mytopic).
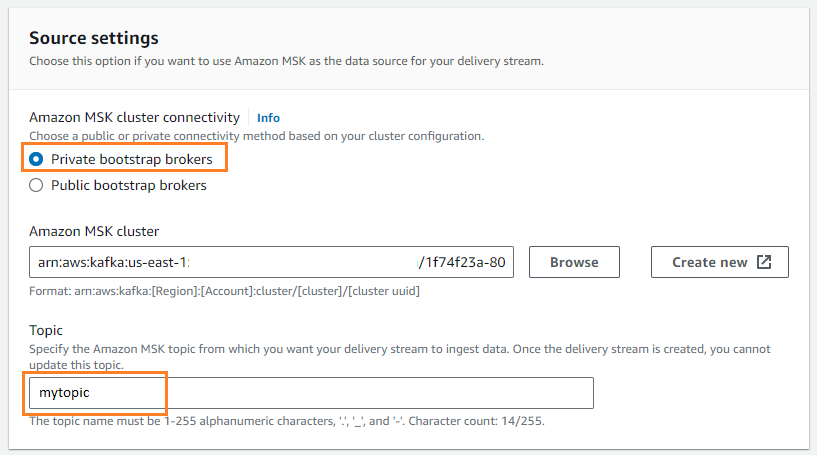
- في حالة دلو S3، اختر تصفح واختر دلو S3 الخاص بك.
- أدخل
streamingDataLakeكبادئة دلو S3 الخاصة بك. - أدخل
streamingDataLakeErrكبادئة إخراج خطأ دلو S3 الخاص بك.

- اختار إنشاء دفق التسليم.
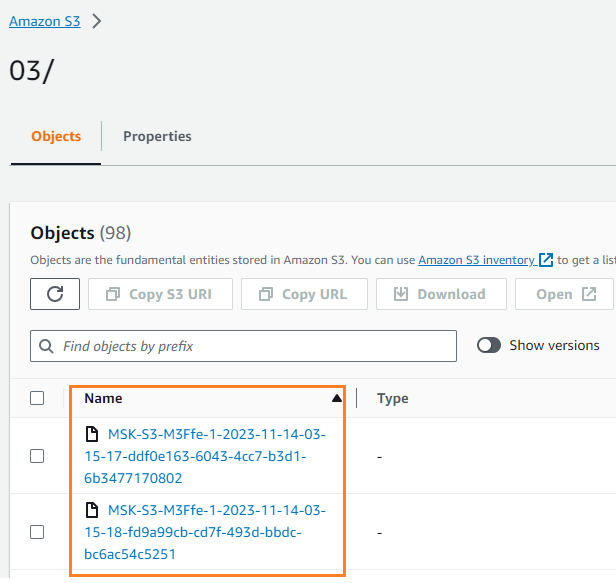
يمكنك التحقق من كتابة البيانات في حاوية S3 الخاصة بك. يجب أن ترى أن streamingDataLake تم إنشاء الدليل ويتم تخزين الملفات في الأقسام.
تخزين الأحداث في DynamoDB
بالنسبة للخطوة الأخيرة، تقوم بتخزين أحدث بيانات المودم في DynamoDB. يتيح ذلك لتطبيق العميل الوصول إلى حالة المودم والتفاعل مع المودم عن بعد من أي مكان، مع زمن وصول منخفض وتوافر عالي. تعمل Lambda بسلاسة مع Amazon MSK. تستقصي Lambda داخليًا الرسائل الجديدة من مصدر الحدث، ثم تستدعي وظيفة Lambda المستهدفة بشكل متزامن. تقرأ Lambda الرسائل على دفعات وتوفرها لوظيفتك كحمولة للحدث.
لنقم أولاً بإنشاء جدول في DynamoDB. تشير إلى أذونات DynamoDB API: مرجع الإجراءات والموارد والشروط للتحقق من أن جهاز العميل الخاص بك لديه الأذونات اللازمة.
- إنشاء ملف جديد يسمى
createTable.py. - انسخ الكود التالي في الملف، وقم بتحديث ملف
regionالمعلومات:
- تشغيل
createTable.pyالبرنامج النصي لإنشاء جدول يسمىdevice_statusفي دينامو دي بي:
الآن دعونا نقوم بتكوين وظيفة Lambda.
- في وحدة تحكم لامدا ، اختر وظائف في جزء التنقل.
- اختار خلق وظيفة.
- أختار مؤلف من الصفر.
- في حالة اسم وظيفة¸ أدخل اسمًا (على سبيل المثال ،
my-notification-kafka). - في حالة وقت التشغيل، اختر بيثون 3.11.
- في حالة أذونات، حدد استخدم دورًا موجودًا واختيار دور مع أذونات القراءة من مجموعتك.
- قم بإنشاء الوظيفة.
في صفحة تكوين وظيفة Lambda، يمكنك الآن تكوين المصادر والوجهات ورمز التطبيق الخاص بك.
- اختار إضافة الزناد.
- في حالة تكوين الزناد، أدخل
MSKلتكوين Amazon MSK كمشغل لوظيفة مصدر Lambda. - في حالة كتلة MSK، أدخل
myCluster. - إلغاء تنشيط الزناد، لأنك لم تقم بتكوين وظيفة Lambda الخاصة بك بعد.
- في حالة حجم الدفعة، أدخل
100. - في حالة وضع البداية، اختر الأحدث.
- في حالة اسم الموضوع¸ أدخل اسمًا (على سبيل المثال ،
mytopic). - اختار أضف.
- في صفحة تفاصيل وظيفة Lambda، على رمز علامة التبويب ، أدخل الرمز التالي:
- نشر وظيفة لامدا.
- على الاعداد علامة التبويب، اختر تعديل لتحرير الزناد.
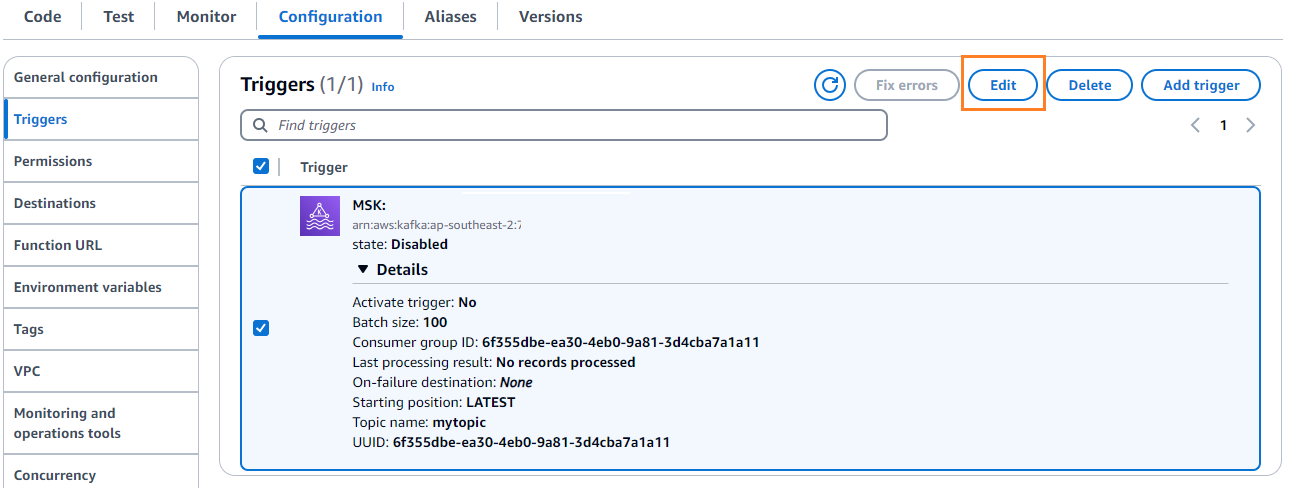
- حدد المشغل، ثم اختر حفظ.
- في وحدة تحكم DynamoDB ، اختر استكشف العناصر في جزء التنقل.
- حدد الجدول
device_status.
ستلاحظ أن Lambda تكتب الأحداث التي تم إنشاؤها في موضوع Kafka إلى DynamoDB.

نبذة عامة
يعد تدفق خطوط أنابيب البيانات أمرًا بالغ الأهمية لبناء التطبيقات في الوقت الفعلي. ومع ذلك، قد يكون إنشاء البنية التحتية وإدارتها أمرًا شاقًا. في هذا المنشور، تناولنا كيفية إنشاء مسار تدفق بدون خادم على AWS باستخدام Amazon MSK، وLambda، وDynamoDB، وAmazon Data Firehose، وخدمات أخرى. وتتمثل المزايا الرئيسية في عدم وجود خوادم يمكن إدارتها، وقابلية التوسع التلقائي للبنية الأساسية، ونموذج الدفع أولاً بأول باستخدام خدمات مُدارة بالكامل.
هل أنت مستعد لبناء خط الأنابيب الخاص بك في الوقت الفعلي؟ ابدأ اليوم باستخدام حساب AWS مجاني. بفضل قوة العمل بدون خادم، يمكنك التركيز على منطق التطبيق الخاص بك بينما تتعامل AWS مع الأحمال الثقيلة غير المتمايزة. دعونا نبني شيئًا رائعًا على AWS!
حول المؤلف
 مسعود رحمن صايم هو مهندس بيانات متدفقة في AWS. إنه يعمل مع عملاء AWS على مستوى العالم لتصميم وبناء بنيات تدفق البيانات لحل مشاكل الأعمال في العالم الحقيقي. إنه متخصص في تحسين الحلول التي تستخدم خدمات تدفق البيانات و NoSQL. سايم شغوف جدًا بالحوسبة الموزعة.
مسعود رحمن صايم هو مهندس بيانات متدفقة في AWS. إنه يعمل مع عملاء AWS على مستوى العالم لتصميم وبناء بنيات تدفق البيانات لحل مشاكل الأعمال في العالم الحقيقي. إنه متخصص في تحسين الحلول التي تستخدم خدمات تدفق البيانات و NoSQL. سايم شغوف جدًا بالحوسبة الموزعة.
 مايكل أوجويكي هو مدير المنتج لشركة Amazon MSK. إنه متحمس لاستخدام البيانات للكشف عن الرؤى التي تدفع العمل. إنه يستمتع بمساعدة العملاء من مجموعة واسعة من الصناعات على تحسين أعمالهم باستخدام تدفق البيانات. يحب مايكل أيضًا التعرف على العلوم السلوكية وعلم النفس من الكتب والبودكاست.
مايكل أوجويكي هو مدير المنتج لشركة Amazon MSK. إنه متحمس لاستخدام البيانات للكشف عن الرؤى التي تدفع العمل. إنه يستمتع بمساعدة العملاء من مجموعة واسعة من الصناعات على تحسين أعمالهم باستخدام تدفق البيانات. يحب مايكل أيضًا التعرف على العلوم السلوكية وعلم النفس من الكتب والبودكاست.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

