في المشهد المتطور للتصنيع، تتجلى القوة التحويلية للذكاء الاصطناعي والتعلم الآلي (ML)، مما يؤدي إلى ثورة رقمية تعمل على تبسيط العمليات وتعزيز الإنتاجية. ومع ذلك، فإن هذا التقدم يطرح تحديات فريدة للمؤسسات التي تتنقل في الحلول المستندة إلى البيانات. وتتعامل المنشآت الصناعية مع كميات هائلة من البيانات غير المنظمة، التي يتم الحصول عليها من أجهزة الاستشعار، وأنظمة القياس عن بعد، والمعدات المنتشرة عبر خطوط الإنتاج. تعد البيانات في الوقت الفعلي أمرًا بالغ الأهمية لتطبيقات مثل الصيانة التنبؤية والكشف عن الحالات الشاذة، ومع ذلك فإن تطوير نماذج تعلم الآلة المخصصة لكل حالة استخدام صناعي باستخدام بيانات السلاسل الزمنية هذه يتطلب وقتًا وموارد كبيرة من علماء البيانات، مما يعيق اعتمادها على نطاق واسع.
الذكاء الاصطناعي التوليدي باستخدام نماذج أساسية كبيرة مدربة مسبقًا (FMs) مثل كلود يمكنه إنشاء مجموعة متنوعة من المحتوى بسرعة بدءًا من نص المحادثة وحتى كود الكمبيوتر بناءً على مطالبات نصية بسيطة، تُعرف باسم المطالبة بالطلقة الصفرية. وهذا يلغي حاجة علماء البيانات إلى تطوير نماذج محددة لتعلم الآلة يدويًا لكل حالة استخدام، وبالتالي إضفاء الطابع الديمقراطي على الوصول إلى الذكاء الاصطناعي، مما يفيد حتى الشركات المصنعة الصغيرة. يكتسب العمال الإنتاجية من خلال الرؤى التي ينشئها الذكاء الاصطناعي، ويمكن للمهندسين اكتشاف الحالات الشاذة بشكل استباقي، ويقوم مديرو سلسلة التوريد بتحسين المخزون، وتتخذ قيادة المصنع قرارات مستنيرة تعتمد على البيانات.
ومع ذلك، تواجه مديرو الإدارة المستقلون قيودًا في التعامل مع البيانات الصناعية المعقدة مع قيود حجم السياق (عادة أقل من 200,000 رمز)، مما يشكل تحديات. لمعالجة هذه المشكلة، يمكنك استخدام قدرة FM على إنشاء تعليمات برمجية استجابة لاستعلامات اللغة الطبيعية (NLQs). وكلاء مثل الباندا حيز التنفيذ، وتشغيل هذا الرمز على بيانات سلاسل زمنية عالية الدقة ومعالجة الأخطاء باستخدام FMs. PandasAI هي مكتبة Python تضيف إمكانات الذكاء الاصطناعي التوليدية إلى Pandas، وهي الأداة الشائعة لتحليل البيانات ومعالجتها.
ومع ذلك، فإن NLQs المعقدة، مثل معالجة بيانات السلاسل الزمنية، والتجميع متعدد المستويات، وعمليات الجدول المحوري أو المشترك، قد تؤدي إلى دقة غير متسقة في برنامج Python النصي مع موجه صفري.
لتعزيز دقة إنشاء التعليمات البرمجية، نقترح البناء ديناميكيًا مطالبات متعددة الطلقات لأسئلة NLQs. توفر المطالبة باللقطات المتعددة سياقًا إضافيًا لراديو FM من خلال عرض عدة أمثلة للمخرجات المرغوبة لمطالبات مماثلة، مما يعزز الدقة والاتساق. في هذا المنشور، يتم استرداد المطالبات متعددة اللقطات من عملية تضمين تحتوي على كود Python الناجح الذي يتم تشغيله على نوع بيانات مماثل (على سبيل المثال، بيانات السلاسل الزمنية عالية الدقة من أجهزة إنترنت الأشياء). يوفر موجه اللقطات المتعددة الذي تم إنشاؤه ديناميكيًا السياق الأكثر صلة بـ FM، ويعزز قدرة FM في حساب الرياضيات المتقدم، ومعالجة بيانات السلاسل الزمنية، وفهم اختصارات البيانات. تعمل هذه الاستجابة المحسنة على تسهيل تعامل موظفي المؤسسات والفرق التشغيلية مع البيانات واستخلاص الرؤى دون الحاجة إلى مهارات واسعة النطاق في علوم البيانات.
وبعيدًا عن تحليل بيانات السلاسل الزمنية، أثبتت FMs قيمتها في التطبيقات الصناعية المختلفة. تقوم فرق الصيانة بتقييم صحة الأصول والتقاط الصور لها الأمازون إعادة الاعترافملخصات الوظائف القائمة على تحليل السبب الجذري للشذوذ باستخدام عمليات البحث الذكية الجيل المعزز الاسترداد (خرقة). ولتبسيط مسارات العمل هذه، قدمت AWS أمازون بيدروك، مما يتيح لك إنشاء وتوسيع نطاق تطبيقات الذكاء الاصطناعي التوليدية باستخدام أحدث أجهزة FM المدربة مسبقًا مثل كلود v2. مع قواعد المعرفة لأمازون بيدروك، يمكنك تبسيط عملية تطوير RAG لتوفير تحليل أكثر دقة للسبب الجذري للشذوذ للعاملين في المصنع. يعرض منشورنا مساعدًا ذكيًا لحالات الاستخدام الصناعي مدعومًا من Amazon Bedrock، ويعالج تحديات NLQ، وينشئ ملخصات الأجزاء من الصور، ويعزز استجابات FM لتشخيص المعدات من خلال نهج RAG.
حل نظرة عامة
يوضح الرسم البياني التالي بنية الحل.

يتضمن سير العمل ثلاث حالات استخدام متميزة:
حالة الاستخدام 1: NLQ مع بيانات السلاسل الزمنية
يتكون سير العمل لـ NLQ مع بيانات السلاسل الزمنية من الخطوات التالية:
- نحن نستخدم نظامًا لمراقبة الحالة مزودًا بقدرات تعلم الآلة لاكتشاف الحالات الشاذة، مثل أمازون مونترون، لمراقبة صحة المعدات الصناعية. Amazon Monitron قادر على اكتشاف أعطال المعدات المحتملة من خلال قياسات اهتزاز ودرجة حرارة المعدات.
- نقوم بجمع بيانات السلاسل الزمنية عن طريق المعالجة أمازون مونترون البيانات من خلال الأمازون كينسيس دفق البيانات و خرطوم بيانات أمازونوتحويله إلى تنسيق CSV جدولي وحفظه في ملف خدمة تخزين أمازون البسيطة دلو (أمازون S3).
- يمكن للمستخدم النهائي بدء الدردشة مع بيانات السلاسل الزمنية الخاصة به في Amazon S3 عن طريق إرسال استعلام باللغة الطبيعية إلى تطبيق Streamlit.
- يقوم تطبيق Streamlit بإعادة توجيه استعلامات المستخدم إلى نموذج تضمين النص Amazon Bedrock Titan لتضمين هذا الاستعلام، وإجراء بحث تشابه داخل ملف خدمة Amazon OpenSearch الفهرس، الذي يحتوي على NLQs السابقة ورموز الأمثلة.
- بعد البحث عن التشابه، يتم إدراج أهم الأمثلة المشابهة، بما في ذلك أسئلة NLQ ومخطط البيانات وأكواد Python، في موجه مخصص.
- ترسل PandasAI هذه المطالبة المخصصة إلى نموذج Amazon Bedrock Claude v2.
- يستخدم التطبيق وكيل PandasAI للتفاعل مع نموذج Amazon Bedrock Claude v2، وإنشاء كود Python لتحليل بيانات Amazon Monitron واستجابات NLQ.
- بعد أن يقوم نموذج Amazon Bedrock Claude v2 بإرجاع رمز Python، يقوم PandasAI بتشغيل استعلام Python على بيانات Amazon Monitron التي تم تحميلها من التطبيق، وجمع مخرجات التعليمات البرمجية ومعالجة أي عمليات إعادة محاولة ضرورية لعمليات التشغيل الفاشلة.
- يقوم تطبيق Streamlit بجمع الاستجابة عبر PandasAI، ويوفر المخرجات للمستخدمين. إذا كانت النتيجة مُرضية، فيمكن للمستخدم وضع علامة عليها كمفيدة، وحفظ كود Python الذي أنشأه NLQ وClaude في خدمة OpenSearch.
حالة الاستخدام 2: إنشاء ملخص للأجزاء المعطوبة
تتكون حالة استخدام إنشاء الملخص لدينا من الخطوات التالية:
- بعد أن يعرف المستخدم أي الأصول الصناعية تظهر سلوكًا شاذًا، يمكنه تحميل صور للجزء المعطل لتحديد ما إذا كان هناك خطأ ماديًا في هذا الجزء وفقًا للمواصفات الفنية وحالة التشغيل.
- يمكن للمستخدم استخدام واجهة برمجة تطبيقات DetectText للتعرف على أمازون لاستخراج البيانات النصية من هذه الصور.
- يتم تضمين البيانات النصية المستخرجة في المطالبة الخاصة بنموذج Amazon Bedrock Claude v2، مما يمكّن النموذج من إنشاء ملخص مكون من 200 كلمة للجزء المعطل. يمكن للمستخدم استخدام هذه المعلومات لإجراء مزيد من الفحص للجزء.
حالة الاستخدام 3: تشخيص السبب الجذري
تتكون حالة استخدام تشخيص السبب الجذري لدينا من الخطوات التالية:
- يحصل المستخدم على بيانات المؤسسة بتنسيقات مستندات مختلفة (PDF، وTXT، وما إلى ذلك) المرتبطة بالأصول المعطوبة، ويقوم بتحميلها إلى حاوية S3.
- يتم إنشاء قاعدة معرفية لهذه الملفات في Amazon Bedrock باستخدام نموذج تضمينات النص Titan ومخزن المتجهات الافتراضي لخدمة OpenSearch Service.
- يطرح المستخدم أسئلة تتعلق بتشخيص السبب الجذري للمعدات المعطلة. يتم إنشاء الإجابات من خلال قاعدة معارف Amazon Bedrock باستخدام نهج RAG.
المتطلبات الأساسية المسبقة
لمتابعة هذا المنشور، يجب أن تستوفي المتطلبات الأساسية التالية:
انشر البنية التحتية للحل
لإعداد موارد الحل، أكمل الخطوات التالية:
- انشر ملف تكوين سحابة AWS قالب opensearchsagemaker.yml، الذي يقوم بإنشاء مجموعة وفهرس خدمة OpenSearch، الأمازون SageMaker مثيل دفتر الملاحظات، ودلو S3. يمكنك تسمية مكدس AWS CloudFormation هذا على النحو التالي:
genai-sagemaker. - افتح مثيل دفتر ملاحظات SageMaker في JupyterLab. سوف تجد ما يلي جيثب ريبو تم تنزيله بالفعل على هذا المثيل: إطلاق العنان لإمكانات توليد الذكاء الاصطناعي في العمليات الصناعية.
- قم بتشغيل دفتر الملاحظات من الدليل التالي في هذا المستودع: فتح إمكانات التوليد في العمليات الصناعية/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. سيقوم هذا الكمبيوتر المحمول بتحميل فهرس خدمة OpenSearch باستخدام دفتر ملاحظات SageMaker لتخزين أزواج قيمة المفتاح من ملف 23 أمثلة NLQ الموجودة.
- تحميل المستندات من مجلد البيانات assetpartdoc في مستودع GitHub إلى مجموعة S3 المدرجة في مخرجات مكدس CloudFormation.

بعد ذلك، يمكنك إنشاء قاعدة المعرفة للمستندات الموجودة في Amazon S3.
- في وحدة تحكم Amazon Bedrock، اختر قاعدة المعرفة في جزء التنقل.
- اختار إنشاء قاعدة المعرفة.
- في حالة اسم قاعدة المعرفة، إدخال اسم.
- في حالة دور وقت التشغيل، حدد إنشاء دور خدمة جديد واستخدامه.
- في حالة اسم مصدر البيانات، أدخل اسم مصدر بياناتك.
- في حالة S3 URI، أدخل مسار S3 للحاوية حيث قمت بتحميل مستندات السبب الجذري.
- اختار التالى.
 يتم تحديد نموذج تضمينات Titan تلقائيًا.
يتم تحديد نموذج تضمينات Titan تلقائيًا. - أختار إنشاء متجر ناقلات جديد بسرعة.
- راجع إعداداتك وقم بإنشاء قاعدة المعرفة عن طريق الاختيار إنشاء قاعدة المعرفة.
- بعد إنشاء قاعدة المعرفة بنجاح، اختر مزامنة لمزامنة مجموعة S3 مع قاعدة المعرفة.

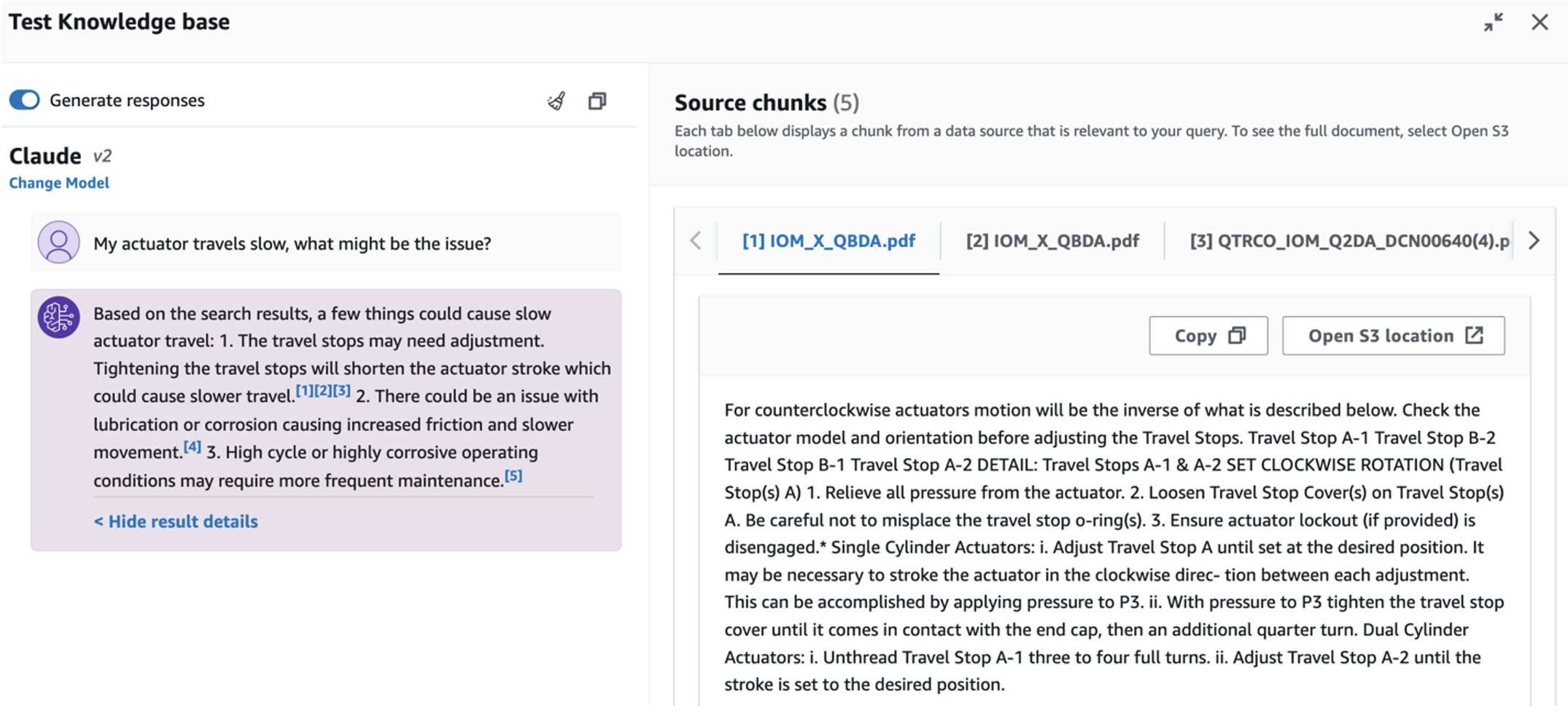
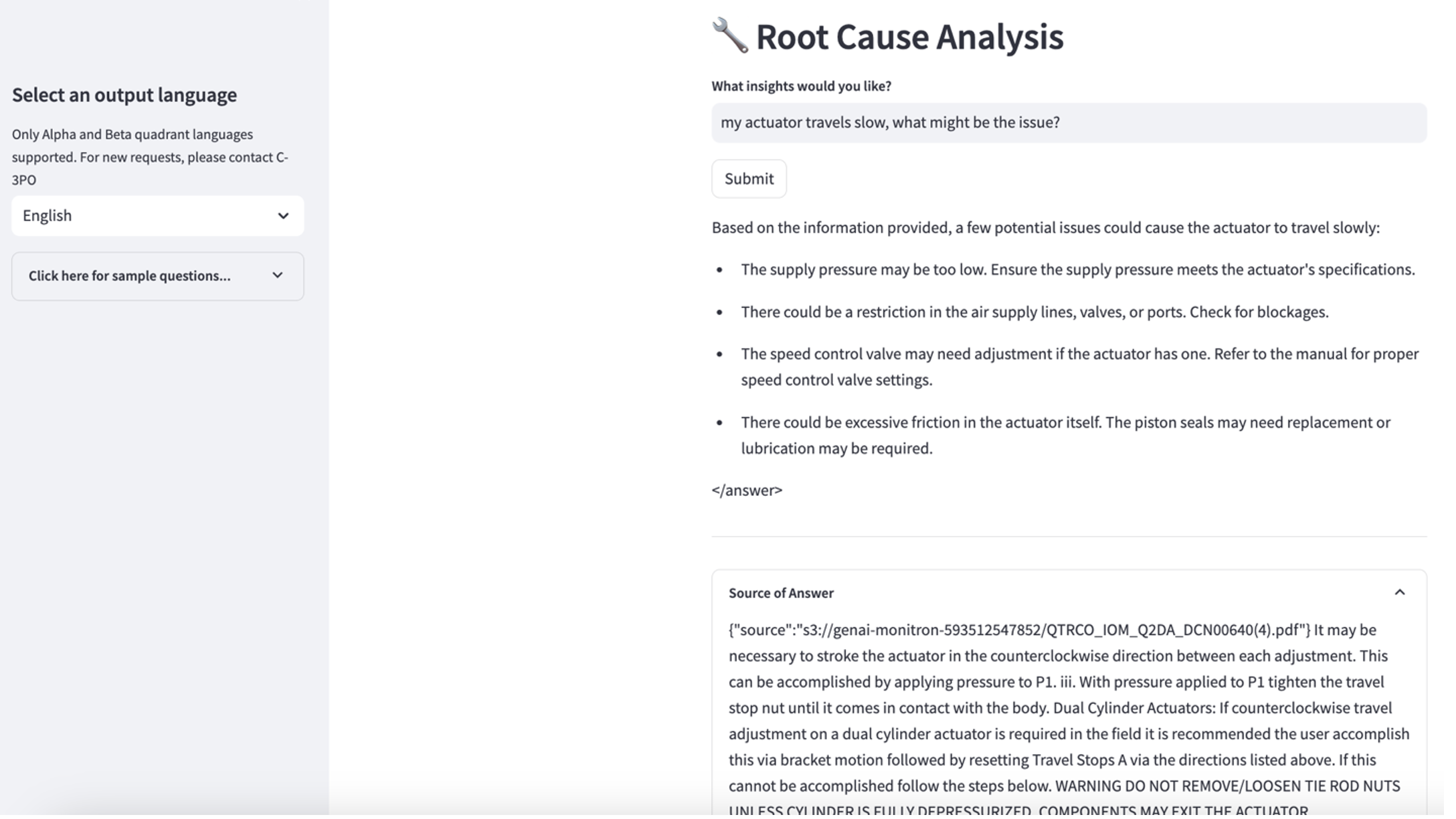
- بعد إعداد قاعدة المعرفة، يمكنك اختبار نهج RAG لتشخيص السبب الجذري عن طريق طرح أسئلة مثل "محركي يتحرك ببطء، ما هي المشكلة؟"
الخطوة التالية هي نشر التطبيق مع حزم المكتبة المطلوبة إما على جهاز الكمبيوتر الخاص بك أو على مثيل EC2 (Ubuntu Server 22.04 LTS).
- قم بإعداد بيانات اعتماد AWS الخاصة بك باستخدام AWS CLI على جهاز الكمبيوتر المحلي الخاص بك. للتبسيط، يمكنك استخدام نفس دور المسؤول الذي استخدمته لنشر مكدس CloudFormation. إذا كنت تستخدم Amazon EC2، قم بإرفاق دور IAM مناسب للمثيل.
- استنساخ جيثب ريبو:
- قم بتغيير الدليل إلى
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcوتشغيلsetup.shالبرنامج النصي الموجود في هذا المجلد لتثبيت الحزم المطلوبة، بما في ذلك LangChain وPandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - قم بتشغيل تطبيق Streamlit باستخدام الأمر التالي:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
قم بتوفير مجموعة خدمة OpenSearch Service ARN التي قمت بإنشائها في Amazon Bedrock من الخطوة السابقة.
تحدث مع مساعد صحة الأصول الخاص بك
بعد إكمال النشر الشامل، يمكنك الوصول إلى التطبيق عبر المضيف المحلي على المنفذ 8501، الذي يفتح نافذة متصفح مع واجهة الويب. إذا قمت بنشر التطبيق على مثيل EC2، السماح بالوصول إلى المنفذ 8501 عبر القاعدة الواردة لمجموعة الأمان. يمكنك الانتقال إلى علامات تبويب مختلفة لحالات الاستخدام المختلفة.
استكشاف حالة الاستخدام 1
لاستكشاف حالة الاستخدام الأولى، اختر رؤية البيانات والرسم البياني. ابدأ بتحميل بيانات السلاسل الزمنية الخاصة بك. إذا لم يكن لديك ملف بيانات سلاسل زمنية موجود لاستخدامه، فيمكنك تحميل ما يلي عينة من ملف CSV مع بيانات مشروع Amazon Monitron مجهولة المصدر. إذا كان لديك بالفعل مشروع Amazon Monitron، فارجع إلى أنشئ رؤى قابلة للتنفيذ لإدارة الصيانة التنبؤية باستخدام Amazon Monitron و Amazon Kinesis لدفق بيانات Amazon Monitron الخاصة بك إلى Amazon S3 واستخدام بياناتك مع هذا التطبيق.
عند اكتمال التحميل، أدخل استعلامًا لبدء محادثة مع بياناتك. يقدم الشريط الجانبي الأيسر مجموعة من الأمثلة على الأسئلة لراحتك. توضح لقطات الشاشة التالية الاستجابة وكود Python الذي تم إنشاؤه بواسطة FM عند إدخال سؤال مثل "أخبرني بالعدد الفريد لأجهزة الاستشعار لكل موقع يظهر كتحذير أو إنذار على التوالي؟" (سؤال صعب) أو "بالنسبة لأجهزة الاستشعار التي تظهر إشارة درجة الحرارة على أنها غير صحية، هل يمكنك حساب المدة الزمنية بالأيام لكل جهاز استشعار يظهر إشارة اهتزاز غير طبيعية؟" (سؤال على مستوى التحدي). سوف يجيب التطبيق على سؤالك، وسيعرض أيضًا برنامج Python النصي لتحليل البيانات الذي تم إجراؤه للحصول على مثل هذه النتائج.


إذا كنت راضيًا عن الإجابة، يمكنك وضع علامة عليها كـ مفيد، مع حفظ كود Python الذي أنشأه NLQ وClaude في فهرس خدمة OpenSearch.

استكشاف حالة الاستخدام 2
لاستكشاف حالة الاستخدام الثانية، اختر ملخص الصورة الملتقطة علامة التبويب في تطبيق Streamlit. يمكنك تحميل صورة للأصول الصناعية الخاصة بك، وسيقوم التطبيق بإنشاء ملخص مكون من 200 كلمة للمواصفات الفنية وحالة التشغيل بناءً على معلومات الصورة. تعرض لقطة الشاشة التالية الملخص الذي تم إنشاؤه من صورة محرك الحزام. لاختبار هذه الميزة، إذا لم تكن لديك صورة مناسبة، يمكنك استخدام ما يلي مثال على الصورة.
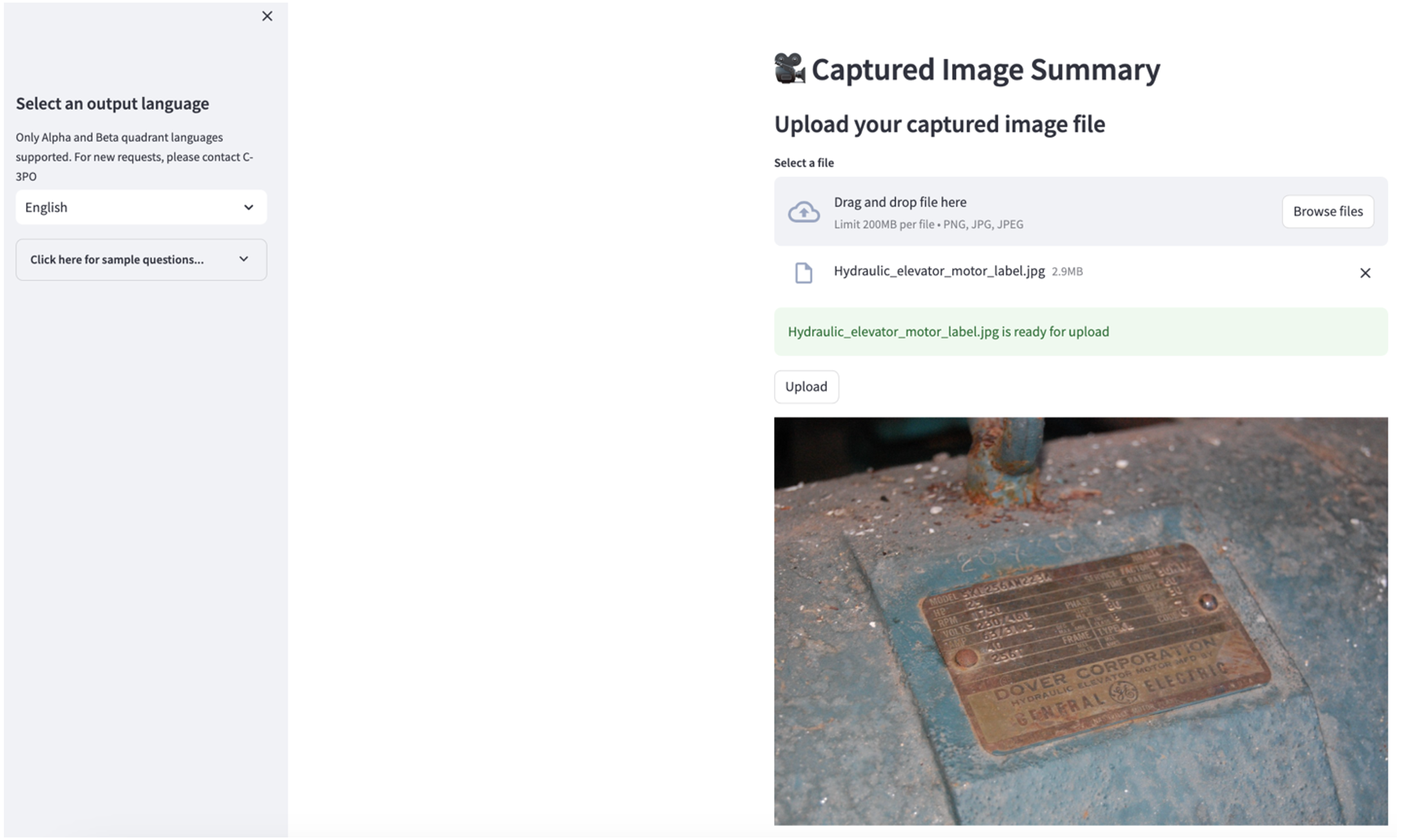
ملصق محرك المصعد الهيدروليكي"بقلم كلارنس ريشر مرخص بموجب CC BY-SA 2.0.

استكشاف حالة الاستخدام 3
لاستكشاف حالة الاستخدام الثالثة، اختر تشخيص السبب الجذري فاتورة غير مدفوعة. أدخل استعلامًا يتعلق بأصولك الصناعية المعطلة، مثل "محركي يتحرك ببطء، ما هي المشكلة؟" كما هو موضح في لقطة الشاشة التالية، يقدم التطبيق استجابة مع مقتطف المستند المصدر المستخدم لإنشاء الإجابة.
حالة الاستخدام 1: تفاصيل التصميم
في هذا القسم، نناقش تفاصيل تصميم سير عمل التطبيق لحالة الاستخدام الأولى.
بناء سريع مخصص
يأتي الاستعلام باللغة الطبيعية للمستخدم بمستويات صعبة مختلفة: السهل والصعب والتحدي.
قد تتضمن الأسئلة المباشرة الطلبات التالية:
- حدد القيم الفريدة
- عد الأرقام الإجمالية
- فرز القيم
بالنسبة لهذه الأسئلة، يمكن لـ PandasAI التفاعل مباشرة مع FM لإنشاء نصوص Python للمعالجة.
تتطلب الأسئلة الصعبة عملية تجميع أساسية أو تحليل السلاسل الزمنية، مثل ما يلي:
- حدد القيمة أولاً وقم بتجميع النتائج بشكل هرمي
- إجراء الإحصائيات بعد اختيار السجل الأولي
- عدد الطابع الزمني (على سبيل المثال، الحد الأدنى والحد الأقصى)
بالنسبة للأسئلة الصعبة، يساعد القالب السريع الذي يحتوي على تعليمات مفصلة خطوة بخطوة مديري المرافق في تقديم إجابات دقيقة.
تحتاج الأسئلة على مستوى التحدي إلى حسابات رياضية متقدمة ومعالجة السلاسل الزمنية، مثل ما يلي:
- حساب مدة الشذوذ لكل جهاز استشعار
- حساب أجهزة استشعار الشذوذ للموقع على أساس شهري
- قارن قراءات المستشعر في ظل التشغيل العادي والظروف غير الطبيعية
بالنسبة لهذه الأسئلة، يمكنك استخدام لقطات متعددة في موجه مخصص لتحسين دقة الاستجابة. تُظهر هذه اللقطات المتعددة أمثلة على معالجة السلاسل الزمنية المتقدمة وحسابات الرياضيات، وستوفر سياقًا لـ FM لإجراء الاستدلال ذي الصلة في تحليل مماثل. يمكن أن يشكل إدراج الأمثلة الأكثر صلة بشكل ديناميكي من بنك أسئلة NLQ في الموجه تحديًا. أحد الحلول هو إنشاء عمليات التضمين من نماذج أسئلة NLQ الموجودة وحفظ هذه التضمينات في مخزن متجه مثل OpenSearch Service. عند إرسال سؤال إلى تطبيق Streamlit، سيتم توجيه السؤال بواسطة BedrockEmbeddings. يتم استرداد التضمينات الأكثر صلة بهذا السؤال باستخدام N opensearch_vector_search.similarity_search وإدراجها في قالب المطالبة كمطالبة متعددة اللقطات.
يوضح الرسم البياني التالي سير العمل هذا.
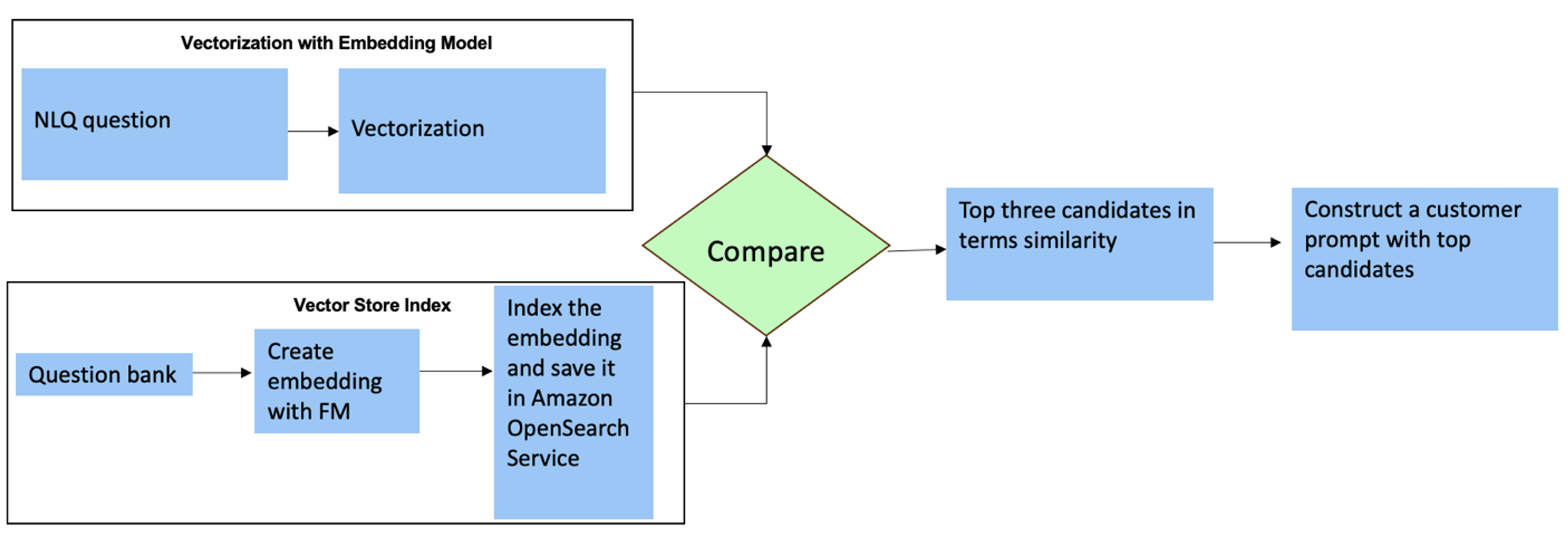
يتم إنشاء طبقة التضمين باستخدام ثلاث أدوات رئيسية:
- نموذج التضمين - نستخدم Amazon Titan Embeddings المتاحة من خلال Amazon Bedrock (amazon.titan-embed-text-v1) لإنشاء تمثيلات رقمية للمستندات النصية.
- متجر المتجهات - بالنسبة لمتجر المتجهات الخاص بنا، نستخدم خدمة OpenSearch عبر إطار عمل LangChain، مما يؤدي إلى تبسيط تخزين التضمينات التي تم إنشاؤها من أمثلة NLQ في هذا الدفتر.
- فهرس – يلعب فهرس خدمة البحث المفتوح دورًا محوريًا في مقارنة تضمينات المدخلات مع تضمينات المستندات وتسهيل استرجاع المستندات ذات الصلة. نظرًا لأنه تم حفظ رموز أمثلة Python كملف JSON، فقد تمت فهرستها في خدمة OpenSearch كمتجهات عبر OpenSearchVevtorSearch.fromtexts استدعاء API.
مجموعة مستمرة من الأمثلة التي تم تدقيقها بواسطة الإنسان عبر Streamlit
في بداية تطوير التطبيق، بدأنا بـ 23 مثالًا محفوظًا فقط في فهرس خدمة OpenSearch كمضمنات. عندما يتم تشغيل التطبيق في الميدان، يبدأ المستخدمون في إدخال NLQs الخاصة بهم عبر التطبيق. ومع ذلك، نظرًا للأمثلة المحدودة المتوفرة في القالب، قد لا تجد بعض أسئلة NLQ مطالبات مماثلة. لإثراء هذه التضمينات بشكل مستمر وتقديم المزيد من مطالبات المستخدم ذات الصلة، يمكنك استخدام تطبيق Streamlit لجمع الأمثلة التي تم تدقيقها بواسطة الإنسان.
داخل التطبيق، الوظيفة التالية تخدم هذا الغرض. عندما يجد المستخدمون النهائيون أن الإخراج مفيد ويختارون مفيد، التطبيق يتبع الخطوات التالية:
- استخدم طريقة رد الاتصال من PandasAI لتجميع برنامج Python النصي.
- أعد تنسيق برنامج Python النصي وسؤال الإدخال وبيانات تعريف CSV في سلسلة.
- تحقق مما إذا كان مثال NLQ هذا موجودًا بالفعل في فهرس خدمة OpenSearch الحالي باستخدام opensearch_vector_search.similarity_search_with_score.
- إذا لم يكن هناك مثال مشابه، فسيتم إضافة NLQ إلى فهرس خدمة OpenSearch باستخدام opensearch_vector_search.add_texts.
في حالة اختيار المستخدم غير مساعد، لم يتم اتخاذ أي إجراء. تتأكد هذه العملية التكرارية من أن النظام يتحسن باستمرار من خلال دمج الأمثلة التي ساهم بها المستخدم.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
من خلال دمج التدقيق البشري، تتزايد كمية الأمثلة في خدمة OpenSearch المتاحة للتضمين الفوري مع زيادة استخدام التطبيق. تؤدي مجموعة بيانات التضمين الموسعة هذه إلى تحسين دقة البحث بمرور الوقت. على وجه التحديد، بالنسبة لأسئلة NLQ الصعبة، تصل دقة استجابة FM إلى حوالي 90% عند إدراج أمثلة مماثلة ديناميكيًا لإنشاء مطالبات مخصصة لكل سؤال NLQ. يمثل هذا زيادة ملحوظة بنسبة 28% مقارنة بالسيناريوهات التي لا تحتوي على مطالبات متعددة اللقطات.
حالة الاستخدام 2: تفاصيل التصميم
على تطبيق Streamlit ملخص الصورة الملتقطة علامة التبويب، يمكنك تحميل ملف صورة مباشرة. يؤدي هذا إلى بدء واجهة برمجة تطبيقات Amazon Rekognition (Detect_text API)، استخراج النص من ملصق الصورة الذي يوضح مواصفات الجهاز بالتفصيل. وبعد ذلك، يتم إرسال البيانات النصية المستخرجة إلى نموذج Amazon Bedrock Claude كسياق للمطالبة، مما يؤدي إلى ملخص مكون من 200 كلمة.
من منظور تجربة المستخدم، يعد تمكين وظيفة التدفق لمهمة تلخيص النص أمرًا بالغ الأهمية، مما يسمح للمستخدمين بقراءة الملخص الذي تم إنشاؤه بواسطة FM في أجزاء أصغر بدلاً من انتظار الإخراج بالكامل. تسهل Amazon Bedrock البث عبر واجهة برمجة التطبيقات (API) الخاصة بها (bedrock_runtime.invoc_model_with_response_stream).
حالة الاستخدام 3: تفاصيل التصميم
في هذا السيناريو، قمنا بتطوير تطبيق chatbot يركز على تحليل السبب الجذري، باستخدام نهج RAG. يستمد برنامج الدردشة الآلي هذا من مستندات متعددة تتعلق بمعدات التحمل لتسهيل تحليل السبب الجذري. يستخدم برنامج الدردشة الآلي لتحليل السبب الجذري القائم على RAG قواعد المعرفة لإنشاء تمثيلات نصية متجهة أو عمليات تضمين. قواعد المعرفة لـ Amazon Bedrock هي إمكانية مُدارة بالكامل تساعدك على تنفيذ سير عمل RAG بالكامل، بدءًا من الاستيعاب وحتى الاسترجاع والزيادة السريعة، دون الحاجة إلى إنشاء عمليات تكامل مخصصة لمصادر البيانات أو إدارة تدفقات البيانات وتفاصيل تنفيذ RAG.
عندما تكون راضيًا عن استجابة قاعدة المعرفة من Amazon Bedrock، يمكنك دمج استجابة السبب الجذري من قاعدة المعرفة إلى تطبيق Streamlit.
تنظيف
لتوفير التكاليف، احذف الموارد التي قمت بإنشائها في هذا المنشور:
- احذف قاعدة المعرفة من Amazon Bedrock.
- حذف فهرس خدمة OpenSearch.
- احذف مكدس CloudFormation من genai-sagemaker.
- أوقف مثيل EC2 إذا كنت تستخدم مثيل EC2 لتشغيل تطبيق Streamlit.
وفي الختام
لقد أحدثت تطبيقات الذكاء الاصطناعي التوليدية بالفعل تحولاً في العديد من العمليات التجارية، مما أدى إلى تعزيز إنتاجية العمال ومجموعات المهارات. ومع ذلك، فإن القيود المفروضة على FMs في التعامل مع تحليل بيانات السلاسل الزمنية أعاقت الاستفادة الكاملة منها من قبل العملاء الصناعيين. لقد أعاق هذا القيد تطبيق الذكاء الاصطناعي التوليدي على نوع البيانات السائد الذي تتم معالجته يوميًا.
في هذا المنشور، قدمنا حلًا إبداعيًا لتطبيقات الذكاء الاصطناعي مصممًا للتخفيف من هذا التحدي بالنسبة للمستخدمين الصناعيين. يستخدم هذا التطبيق وكيلًا مفتوح المصدر، PandasAI، لتعزيز قدرة تحليل السلاسل الزمنية لـ FM. بدلاً من إرسال بيانات السلاسل الزمنية مباشرةً إلى مديري FM، يستخدم التطبيق PandasAI لإنشاء كود Python لتحليل بيانات السلاسل الزمنية غير المنظمة. لتعزيز دقة إنشاء كود Python، تم تنفيذ سير عمل إنشاء سريع مخصص مع التدقيق البشري.
بفضل الرؤى العميقة المتعلقة بصحة أصولهم، يستطيع العمال الصناعيون الاستفادة بشكل كامل من إمكانات الذكاء الاصطناعي التوليدي عبر حالات الاستخدام المختلفة، بما في ذلك تشخيص السبب الجذري وتخطيط استبدال الأجزاء. بفضل قواعد المعرفة الخاصة بـ Amazon Bedrock، يعد حل RAG سهلاً بالنسبة للمطورين للإنشاء والإدارة.
يتجه مسار إدارة بيانات المؤسسة وعملياتها بشكل لا لبس فيه نحو التكامل الأعمق مع الذكاء الاصطناعي التوليدي للحصول على رؤى شاملة حول السلامة التشغيلية. يتم تضخيم هذا التحول، الذي تقوده Amazon Bedrock، بشكل كبير من خلال القوة والإمكانات المتزايدة لمجالات LLM مثل أمازون بيدروك كلود 3 لمزيد من الارتقاء بالحلول. لمعرفة المزيد، قم بزيارة استشارة وثائق أمازون بيدروك، والتدرب على ورشة عمل أمازون بيدروك.
عن المؤلفين
 جوليا هو هو مهندس حلول الذكاء الاصطناعي/تعلم الآلة في Amazon Web Services. وهي متخصصة في الذكاء الاصطناعي التوليدي وعلوم البيانات التطبيقية وهندسة إنترنت الأشياء. وهي حاليًا جزء من فريق Amazon Q، وعضو/مرشد نشط في مجتمع المجال التقني للتعلم الآلي. وهي تعمل مع العملاء، بدءًا من الشركات الناشئة وحتى المؤسسات، لتطوير حلول AWSome التوليدية للذكاء الاصطناعي. وهي متحمسة بشكل خاص للاستفادة من نماذج اللغات الكبيرة لتحليلات البيانات المتقدمة واستكشاف التطبيقات العملية التي تعالج تحديات العالم الحقيقي.
جوليا هو هو مهندس حلول الذكاء الاصطناعي/تعلم الآلة في Amazon Web Services. وهي متخصصة في الذكاء الاصطناعي التوليدي وعلوم البيانات التطبيقية وهندسة إنترنت الأشياء. وهي حاليًا جزء من فريق Amazon Q، وعضو/مرشد نشط في مجتمع المجال التقني للتعلم الآلي. وهي تعمل مع العملاء، بدءًا من الشركات الناشئة وحتى المؤسسات، لتطوير حلول AWSome التوليدية للذكاء الاصطناعي. وهي متحمسة بشكل خاص للاستفادة من نماذج اللغات الكبيرة لتحليلات البيانات المتقدمة واستكشاف التطبيقات العملية التي تعالج تحديات العالم الحقيقي.
 سوديش ساسيدهاران هو مهندس حلول أول في AWS، ضمن فريق الطاقة. يحب Sudeesh تجربة التقنيات الجديدة وبناء حلول مبتكرة تحل تحديات الأعمال المعقدة. عندما لا يقوم بتصميم الحلول أو تعديل أحدث التقنيات، يمكنك أن تجده في ملعب التنس يعمل بضرباته الخلفية.
سوديش ساسيدهاران هو مهندس حلول أول في AWS، ضمن فريق الطاقة. يحب Sudeesh تجربة التقنيات الجديدة وبناء حلول مبتكرة تحل تحديات الأعمال المعقدة. عندما لا يقوم بتصميم الحلول أو تعديل أحدث التقنيات، يمكنك أن تجده في ملعب التنس يعمل بضرباته الخلفية.
 نيل ديساي هو مدير تنفيذي في مجال التكنولوجيا يتمتع بخبرة تزيد عن 20 عامًا في مجال الذكاء الاصطناعي (AI) وعلوم البيانات وهندسة البرمجيات وهندسة المؤسسات. في AWS، يقود فريقًا من مهندسي الحلول المتخصصين في خدمات الذكاء الاصطناعي في جميع أنحاء العالم الذين يساعدون العملاء على بناء حلول مبتكرة مدعومة بالذكاء الاصطناعي، ومشاركة أفضل الممارسات مع العملاء، وتوجيه خارطة طريق المنتج. في أدواره السابقة في Vestas وHoneywell وQuest Diagnostics، تولى نيل أدوارًا قيادية في تطوير وإطلاق المنتجات والخدمات المبتكرة التي ساعدت الشركات على تحسين عملياتها وخفض التكاليف وزيادة الإيرادات. إنه متحمس لاستخدام التكنولوجيا لحل مشاكل العالم الحقيقي وهو مفكر استراتيجي يتمتع بسجل حافل من النجاح.
نيل ديساي هو مدير تنفيذي في مجال التكنولوجيا يتمتع بخبرة تزيد عن 20 عامًا في مجال الذكاء الاصطناعي (AI) وعلوم البيانات وهندسة البرمجيات وهندسة المؤسسات. في AWS، يقود فريقًا من مهندسي الحلول المتخصصين في خدمات الذكاء الاصطناعي في جميع أنحاء العالم الذين يساعدون العملاء على بناء حلول مبتكرة مدعومة بالذكاء الاصطناعي، ومشاركة أفضل الممارسات مع العملاء، وتوجيه خارطة طريق المنتج. في أدواره السابقة في Vestas وHoneywell وQuest Diagnostics، تولى نيل أدوارًا قيادية في تطوير وإطلاق المنتجات والخدمات المبتكرة التي ساعدت الشركات على تحسين عملياتها وخفض التكاليف وزيادة الإيرادات. إنه متحمس لاستخدام التكنولوجيا لحل مشاكل العالم الحقيقي وهو مفكر استراتيجي يتمتع بسجل حافل من النجاح.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

