
圖片作者
全球領先的人工智慧研究公司之一 Mistral AI 最近發布了 米斯特拉爾 7B v0.2.
這種開源語言模型在 23 年 2024 月 XNUMX 日該公司的黑客馬拉鬆活動期間揭曉。
Mistral 7B 模型擁有 7.3 億個參數,使其功能極為強大。它們在幾乎所有基準測試中都優於 Llama 2 13B 和 Llama 1 34B。最新的 V0.2 模型引入了 32k 上下文視窗以及其他改進,增強了其處理和生成文字的能力。
此外,最近宣布的版本是去年稍早發布的指令調整變體「Mistral-7B-Instruct-V0.2」的基礎模型。
在本教程中,我將向您展示如何在 Hugging Face 上存取和微調此語言模式。
我們將使用 Hugging Face 的 AutoTrain 功能對 Mistral 7B-v0.2 基礎模型進行微調。
擁抱臉 以實現機器學習模型的民主化而聞名,使日常用戶能夠開發先進的人工智慧解決方案。
AutoTrain 是 Hugging Face 的功能,可自動執行模型訓練流程,使其易於存取且高效。
它可以幫助使用者在微調模型時選擇最佳參數和訓練技術,否則這是一項艱鉅且耗時的任務。
以下是微調 Mistral-5B 模型的 7 個步驟:
1.搭建環境
您必須先建立 Hugging Face 帳戶,然後建立模型儲存庫。
要實現此目的,只需按照本中提供的步驟操作即可 鏈接 然後回到本教學。
我們將用 Python 訓練模型。在選擇筆記本環境進行培訓時,您可以使用 Kaggle 筆記本 or 谷歌合作實驗室,兩者都提供對 GPU 的免費存取。
如果訓練過程花費的時間太長,您可能需要切換到 AWS Sagemaker 或 Azure ML 等雲端平台。
最後,在開始按照本教學進行編碼之前,請執行以下 pip 安裝:
!pip install -U autotrain-advanced
!pip install datasets transformers2. 準備資料集
在本教程中,我們將使用 羊駝資料集 在擁抱臉上,看起來像這樣:
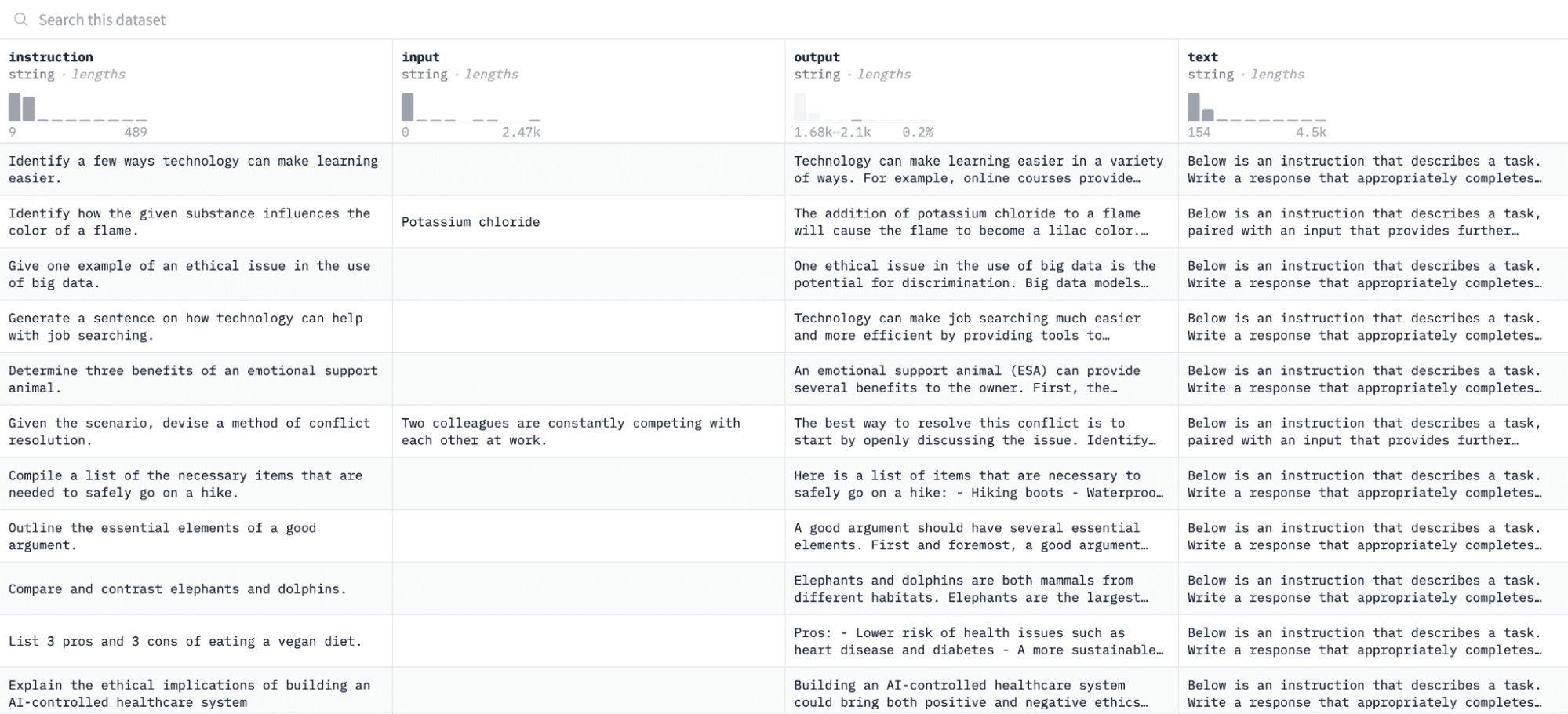
我們將根據指令和輸出對模型進行微調,並評估其在評估過程中響應給定指令的能力。
若要存取並準備此資料集,請執行以下程式碼行:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")第一個函數將使用「datasets」庫載入 Alpaca 資料集並清理它以確保我們不包含任何空指令。第二個函數以 AutoTrain 可以理解的格式建構資料。
運行上述程式碼後,資料集將被載入、格式化並保存在指定路徑中。當您開啟格式化資料集時,您應該會看到一個標記為「formatted_text」的欄位。
3. 設定訓練環境
現在您已成功準備好資料集,讓我們繼續設定模型訓練環境。
為此,您必須定義以下參數:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'以下是上述規格的細分:
- 您可以指定任何 項目名。這是您所有項目和培訓文件將儲存的位置。
- 型號名稱 參數是您想要微調的模型。在本例中,我指定了一個路徑 Mistral-7B v0.2 基礎模型 在擁抱的臉上。
- hf_token 變數必須設定為您的 Hugging Face 令牌,可以透過導航到取得該令牌 此鏈接.
- 您與伴侶的 倉庫 ID 必須設定為您在本教程第一步中建立的 Hugging Face 模型儲存庫。例如,我的儲存庫 ID 是 娜塔莎S/模型2。
4. 配置模型參數
在微調模型之前,我們必須定義訓練參數,這些參數控制模型行為的各個方面,例如訓練持續時間和正規化。
這些參數會影響關鍵方面,例如模型訓練的時間、如何從資料中學習以及如何避免過度擬合。
您可以為您的模型設定以下參數:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015.設定環境變數
現在讓我們透過設定一些環境變數來準備我們的訓練環境。
此步驟確保 AutoTrain 功能使用所需的設定來微調模型,例如我們的項目名稱和訓練首選項:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. 啟動模型訓練
最後,讓我們開始使用以下方法來訓練模型 自動訓練 命令。此步驟涉及指定模型、資料集和訓練配置,如下所示:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )確保更改 數據路徑 到您的訓練資料集所在的位置。
7. 評估模型
模型完成訓練後,您應該會看到目錄中出現一個資料夾,其標題與項目名稱相同。
就我而言,該資料夾的標題是“米斯特拉萊” 如下圖所示:
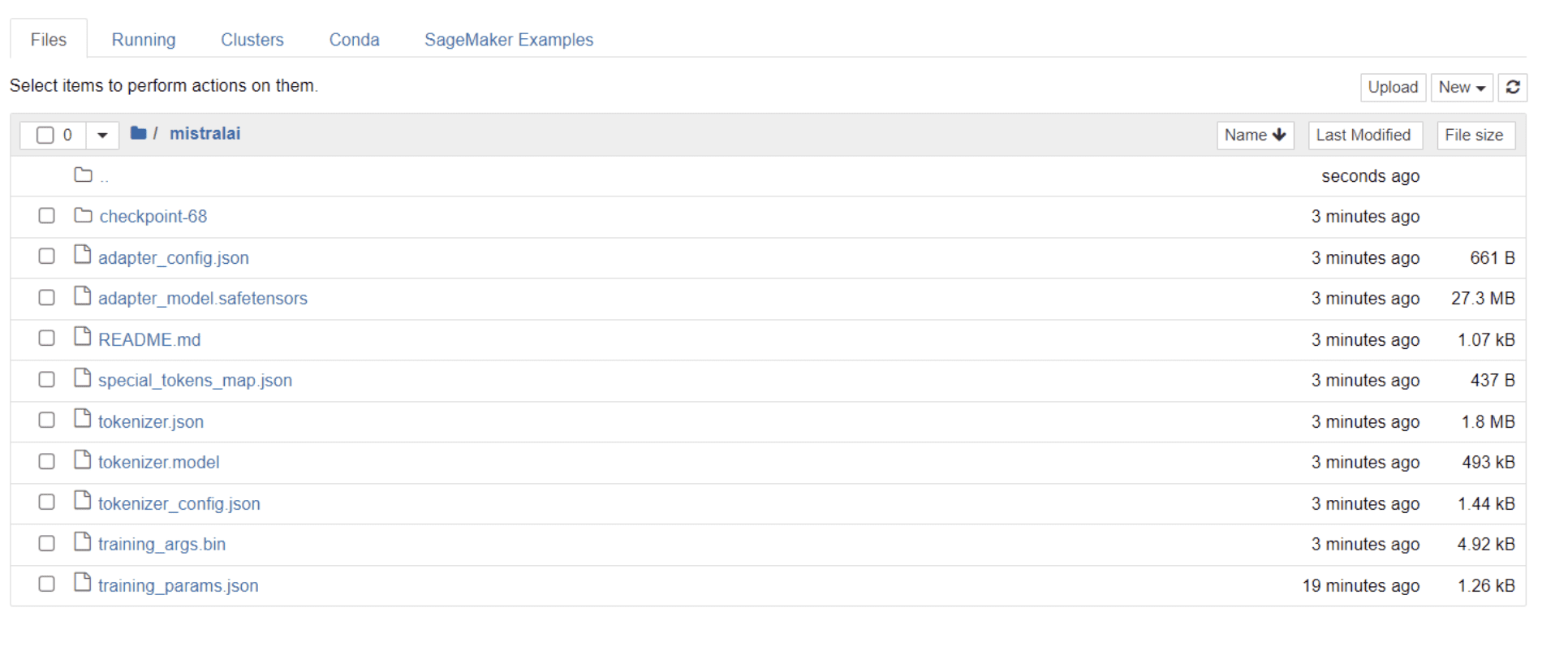
在此資料夾中,您可以找到包含模型權重、超參數和架構詳細資訊的檔案。
現在讓我們檢查這個經過微調的模型是否能夠準確地回應資料集中的問題。為此,我們首先需要執行以下程式碼行,從資料集中產生 5 個樣本輸入和輸出:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")您應該會看到如下所示的回應,其中顯示 5 個範例資料點:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.我們將在模型中輸入上述指令之一,並檢查它是否產生準確的輸出。這是一個向模型提供指令並從中獲取響應的函數:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer最後,在該函數中輸入一個問題,如下所示:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)您的模型應產生與其在訓練資料集中的相應輸出相同的響應,如下所示:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business and請注意,由於我們指定的令牌數量,回應可能看起來不完整或被切斷。請隨意調整“max_length”值以允許更長的回應。
如果您已經走到這一步,恭喜您!
您已經成功地微調了最先進的語言模型,利用了 Mistral 7B v-0.2 的強大功能以及 Hugging Face 的功能。
但旅程並沒有就此結束。
下一步,我建議嘗試不同的資料集或調整某些訓練參數以優化模型效能。大規模微調模型將增強其實用性,因此請嘗試更大的資料集或不同的格式,例如 PDF 和文字檔案。
當處理組織中的真實資料時,這種經驗變得非常寶貴,這些資料通常是混亂且非結構化的。
娜塔莎·塞爾瓦拉吉 是一位自學成才的資料科學家,對寫作充滿熱情。 Natassha 撰寫與資料科學相關的所有內容,是所有資料主題的真正大師。您可以透過以下方式與她聯繫 LinkedIn 或看看她 YouTube頻道.
- SEO 支持的內容和 PR 分發。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 賦予自己力量。 訪問這裡。
- 柏拉圖愛流。 Web3 智能。 知識放大。 訪問這裡。
- 柏拉圖ESG。 碳, 清潔科技, 能源, 環境, 太陽能, 廢物管理。 訪問這裡。
- 柏拉圖健康。 生物技術和臨床試驗情報。 訪問這裡。
- 資源: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

