大型語言模型 (LLM) 通常在與領域無關的大型公開資料集上進行訓練。例如, 梅塔的羊駝 模型在資料集上進行訓練,例如 普通爬行, C4、維基百科和 的arXiv。這些數據集涵蓋廣泛的主題和領域。儘管最終的模型對於文字生成和實體識別等一般任務產生了令人驚訝的良好結果,但有證據表明,使用特定領域資料集訓練的模型可以進一步提高 LLM 效能。例如,訓練資料用於 彭博GPT 51% 是特定領域文檔,包括財經新聞、備案和其他財務資料。在針對特定金融任務進行測試時,所得的法學碩士優於在非特定領域資料集上訓練的法學碩士。的作者 彭博GPT 得出的結論是,他們的模型優於針對五項財務任務中的四項測試的所有其他模型。當針對 Bloomberg 的內部財務任務進行測試時,模型提供了更好的效能,大幅提升了 60 個百分點(滿分為 100 分)。雖然您可以在 紙,以下樣本捕獲自 彭博GPT 論文可以讓您了解使用金融領域特定數據培訓法學碩士的好處。如範例所示,BloombergGPT 模型提供了正確的答案,而其他非特定領域模型則陷入困境:
這篇文章提供了專門針對金融領域的法學碩士培訓指南。我們涵蓋以下關鍵領域:
- 數據收集和準備 – 為有效的模型訓練採購和整理相關財務資料的指南
- 持續預訓練與微調 – 何時使用每種技術來優化法學碩士的表現
- 高效率的持續預訓練 – 簡化持續預訓練流程的策略,節省時間和資源
這篇文章匯集了 Amazon Finance Technology 內的應用科學研究團隊和全球金融業 AWS 全球專家團隊的專業知識。部分內容基於論文 用於建立特定領域大語言模型的高效持續預訓練.
收集和準備財務數據
領域持續預訓練需要大規模、高品質、特定領域的資料集。以下是域資料集管理的主要步驟:
- 識別數據源 – 領域語料庫的潛在資料來源包括開放網路、維基百科、書籍、社群媒體和內部文件。
- 域資料過濾器 – 由於最終目標是管理領域語料庫,因此您可能需要應用額外的步驟來過濾掉與目標領域無關的樣本。這減少了用於持續預訓練的無用語料,降低了訓練成本。
- 前處理 – 您可以考慮採取一系列預處理步驟來提高資料品質和訓練效率。例如,某些資料來源可能包含相當數量的雜訊標記;重複資料刪除被認為是提高資料品質和降低訓練成本的有用步驟。
要開發金融法學碩士,您可以使用兩個重要的資料來源:News CommonCrawl 和 SEC 文件。 SEC 備案是提交給美國證券交易委員會 (SEC) 的財務報表或其他正式文件。上市公司需要定期提交各種文件。多年來,這創建了大量文件。 News CommonCrawl是CommonCrawl於2016年發布的資料集。它包含來自世界各地新聞網站的新聞文章。
新聞 CommonCrawl 可用來 亞馬遜簡單存儲服務 (亞馬遜 S3) commoncrawl 桶在 crawl-data/CC-NEWS/。您可以使用以下命令來取得文件列表 AWS命令行界面 (AWS CLI) 和以下命令:
In 用於建立特定領域大語言模型的高效持續預訓練中,作者使用 URL 和基於關鍵字的方法從一般新聞中過濾財經新聞文章。具體來說,作者維護了一份重要財經新聞媒體的清單以及一組與財經新聞相關的關鍵字。如果一篇文章來自財經新聞媒體或 URL 中出現任何關鍵字,我們會將其識別為財經新聞。這種簡單而有效的方法使您不僅可以識別來自財經新聞媒體的財經新聞,還可以識別來自通用新聞媒體的財經部分的財經新聞。
SEC 備案可透過 SEC 的 EDGAR(電子資料收集、分析和檢索)資料庫線上取得,該資料庫提供開放資料存取。您可以直接從 EDGAR 抓取文件,或使用 API 亞馬遜SageMaker 只需幾行程式碼,即可針對任何時間段和大量代碼(即 SEC 分配的識別碼)。要了解更多信息,請參閱 SEC 文件檢索.
下表總結了兩個資料來源的關鍵詳細資訊。
| . | 新聞 CommonCrawl | SEC備案 |
| 覆蓋 | 2016-2022 | 1993-2022 |
| 尺寸 | 25.8億字 | 5.1億字 |
在將資料輸入訓練演算法之前,作者會執行一些額外的預處理步驟。首先,我們觀察到,由於刪除了表格和圖形,SEC 文件中包含嘈雜的文本,因此作者刪除了被視為表格或圖形標籤的短句。其次,我們應用局部敏感雜湊演算法來刪除新文章和檔案的重複資料。對於 SEC 備案,我們在章節層級而不是文件層級進行重複資料刪除。最後,我們將文件連接成一個長字串,對其進行標記,並將標記化分成要訓練的模型支援的最大輸入長度的片段。這提高了持續預訓練的吞吐量並降低了訓練成本。
持續預訓練與微調
大多數可用的法學碩士都是通用目的,缺乏特定領域的能力。領域法學碩士在醫學、金融或科學領域展現了可觀的表現。對於法學碩士來說,獲取特定領域知識有四種方法:從頭開始訓練、持續預訓練、針對領域任務進行指令微調以及檢索增強生成(RAG)。
在傳統模型中,微調通常用於為某個領域創建特定於任務的模型。這意味著為多個任務維護多個模型,例如實體提取、意圖分類、情緒分析或問題回答。隨著法學碩士的出現,透過使用上下文學習或提示等技術,維護單獨模型的需要已經過時。這節省了維護相關但不同任務的模型堆疊所需的工作量。
直觀地說,您可以使用特定領域的資料從頭開始訓練法學碩士。儘管創建領域法學碩士的大部分工作都集中在從頭開始的培訓上,但其成本卻高得令人望而卻步。例如,GPT-4模型的成本 超過$ 100百萬 培訓。這些模型是在開放域資料和域資料的混合上進行訓練的。持續的預訓練可以幫助模型獲取特定領域的知識,而不會產生從頭開始預訓練的成本,因為您僅在領域資料上預先訓練現有的開放領域 LLM。
透過對任務進行指令微調,您無法使模型獲取領域知識,因為LLM僅獲取指令微調資料集中包含的領域資訊。除非使用非常大的資料集進行指令微調,否則不足以獲取領域知識。取得高品質的教學資料集通常具有挑戰性,這也是為什麼首先使用法學碩士的原因。此外,一項任務的指令微調可能會影響其他任務的效能(如 本文)。然而,指令微調比任何一種預訓練替代方案都更具成本效益。
下圖比較了傳統的針對特定任務的微調。與法學碩士的情境學習典範比較。
 RAG 是指導法學碩士產生基於某個領域的答案的最有效方法。雖然它可以透過提供領域事實作為輔助資訊來指導模型產生回應,但它不會獲得特定領域的語言,因為 LLM 仍然依賴非領域語言風格來產生回應。
RAG 是指導法學碩士產生基於某個領域的答案的最有效方法。雖然它可以透過提供領域事實作為輔助資訊來指導模型產生回應,但它不會獲得特定領域的語言,因為 LLM 仍然依賴非領域語言風格來產生回應。
持續預訓練是預訓練和指令微調之間的中間立場,在成本方面是獲得特定領域知識和風格的強大替代方案。它可以提供一個通用模型,可以在該模型上對有限的指令資料執行進一步的指令微調。對於下游任務集很大或未知且標記指令調整資料有限的專業領域,持續預訓練可能是一種經濟有效的策略。在其他場景中,指令微調或 RAG 可能更合適。
要了解有關微調、RAG 和模型訓練的更多信息,請參閱 微調基礎模型, 檢索增強生成 (RAG)和 使用 Amazon SageMaker 訓練模型, 分別。在這篇文章中,我們將重點放在高效的持續預訓練。
高效持續預訓練的方法論
持續預訓練包括以下方法:
- 領域自適應持續預訓練(DACP) – 在論文中 用於建立特定領域大語言模型的高效持續預訓練,作者不斷在金融語料庫上預先訓練 Pythia 語言模型套件,使其適應金融領域。目標是透過將整個金融領域的資料輸入開源模型來創建金融法學碩士。由於訓練語料庫包含該領域的所有精選資料集,因此產生的模型應該獲得金融特定的知識,從而成為各種金融任務的通用模型。這會產生 FinPythia 模型。
- 任務自適應持續預訓練 (TACP) – 作者根據標記和未標記的任務資料進一步對模型進行預訓練,以針對特定任務自訂它們。在某些情況下,開發人員可能更喜歡在一組域內任務上提供更好效能的模型,而不是域通用模型。 TACP 被設計為持續預訓練,旨在提高目標任務的效能,而不需要標記資料。具體來說,作者不斷地在任務標記(沒有標籤)上預先訓練開源模型。 TACP 的主要限制在於建立特定於任務的 LLM,而不是基礎 LLM,因為僅使用未標記的任務資料進行訓練。儘管 DACP 使用更大的語料庫,但其成本卻高得令人望而卻步。為了平衡這些限制,作者提出了兩種方法,旨在建立特定領域的基礎法學碩士,同時保持目標任務的卓越性能:
- 高效任務類似 DACP (ETS-DACP) – 作者建議使用嵌入相似性選擇與任務資料高度相似的金融語料庫子集。此子集用於持續預訓練,使其更有效率。具體來說,作者不斷在從金融語料庫中提取的小型語料庫上對開源法學碩士進行預訓練,該語料庫接近分發中的目標任務。這可以幫助提高任務效能,因為儘管不需要標記數據,我們仍採用該模型來分配任務令牌。
- 高效的任務無關 DACP (ETA-DACP) – 作者建議使用困惑度和令牌類型熵等指標,這些指標不需要任務資料來從金融語料庫中選擇樣本以進行高效的持續預訓練。這種方法旨在處理任務資料不可用或更廣泛領域更通用的領域模型首選的場景。作者採用兩個維度來選擇對於從預訓練領域資料子集中獲取領域資訊很重要的資料樣本:新穎性和多樣性。新穎性,以目標模型記錄的困惑度來衡量,是指LLM以前從未見過的資訊。新穎性高的數據顯示法學碩士知識新穎,此類數據被認為更難學習。這會在持續的預培訓期間用密集的領域知識更新通用法學碩士。另一方面,多樣性捕捉了領域語料庫中標記類型分佈的多樣性,這已被記錄為語言建模課程學習研究中的有用特徵。
下圖比較了 ETS-DACP(左)與 ETA-DACP(右)的範例。

我們採用兩種採樣方案從精選的金融語料庫中主動選擇資料點:硬採樣和軟採樣。前者首先根據相應的指標對金融語料庫進行排序,然後選擇前k個樣本,其中k是根據訓練預算預先決定的。對於後者,作者根據度量值為每個資料點分配採樣權重,然後隨機採樣 k 個資料點以滿足訓練預算。
結果與分析
作者評估了一系列金融任務的金融法學碩士,以調查持續預先培訓的有效性:
- 金融短語庫 – 財經新聞的情緒分類任務。
- 品質保證協會 – 基於財經新聞和頭條新聞的基於方面的情感分類任務。
- 標題 – 關於金融實體的標題是否包含某些資訊的二元分類任務。
- NER – 基於 SEC 報告信用風險評估部分的金融命名實體提取任務。此任務中的單字以 PER、LOC、ORG 和 MISC 進行註釋。
由於金融法學碩士是經過指令微調的,因此為了穩健性,作者在每項任務的 5 次設定中評估模型。平均而言,FinPythia 6.9B 在四項任務中的表現比 Pythia 6.9B 高出 10%,證明了特定領域持續預訓練的有效性。對於 1B 模型,改進不太明顯,但性能仍然平均提高了 2%。
下圖說明了兩種型號上 DACP 之前和之後的性能差異。

下圖展示了 Pythia 6.9B 和 FinPythia 6.9B 產生的兩個定性範例。對於有關投資者經理和財務術語的兩個財務相關問題,Pythia 6.9B 無法理解該術語或識別該名稱,而 FinPythia 6.9B 可以正確產生詳細答案。定性範例表明,持續的預培訓使法學碩士能夠在此過程中獲得領域知識。

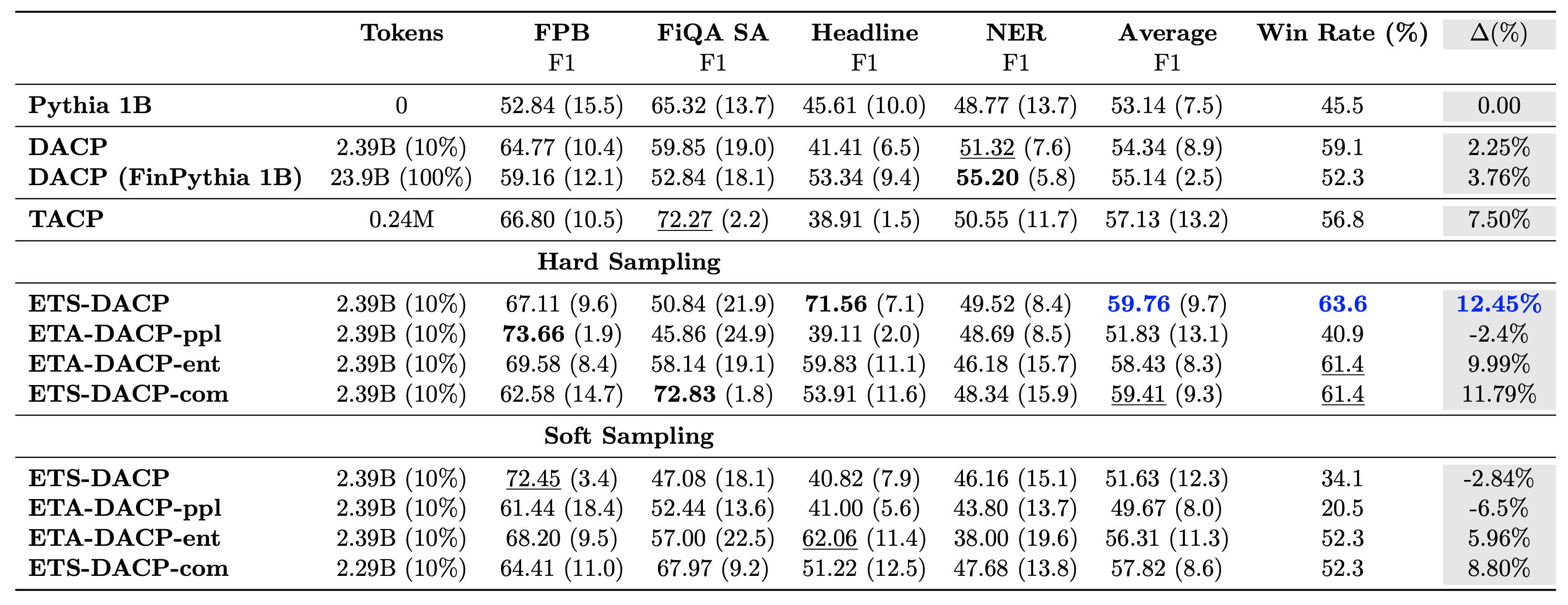
下表比較了各種有效的持續預訓練方法。 ETA-DACP-ppl是基於困惑度(新穎性)的ETA-DACP,而ETA-DACP-ent是基於熵(多樣性)的。 ETS-DACP-com 與 DACP 類似,透過對所有三個指標進行平均來選擇資料。以下是結果的一些要點:
- 數據選擇方法高效 – 僅用 10% 的訓練資料就超越了標準的持續預訓練。高效率的持續預訓練,包括任務相似DACP (ETS-DACP)、基於熵的任務無關DACP (ESA-DACP-ent) 和基於所有三個指標的任務相似DACP (ETS-DACP-com),其性能優於標準DACP平均而言,儘管他們只接受了 10% 的金融語料庫的訓練。
- 任務感知資料選擇最適合小語言模型研究 – ETS-DACP 記錄了所有方法中最好的平均性能,並且基於所有三個指標,記錄了第二好的任務性能。這表明對於法學碩士來說,使用未標記的任務數據仍然是提高任務績效的有效方法。
- 與任務無關的數據選擇緊隨其後 – ESA-DACP-ent 遵循任務感知資料選擇方法的效能,這意味著我們仍然可以透過主動選擇與特定任務無關的高品質樣本來提高任務效能。這為在整個領域建立金融法學碩士鋪平了道路,同時實現了卓越的任務績效。
關於持續預訓練的一個關鍵問題是它是否會對非領域任務的表現產生負面影響。作者還在四個廣泛使用的通用任務上評估了持續預訓練的模型:ARC、MMLU、TruthQA 和 HellaSwag,這些任務衡量回答問題、推理和完成的能力。作者發現持續的預訓練不會對非領域表現產生不利影響。如欲了解更多詳情,請參閱 用於建立特定領域大語言模型的高效持續預訓練.
結論
這篇文章提供了金融領域法學碩士培訓的數據收集和持續預培訓策略的見解。您可以開始使用以下方法培訓您自己的法學碩士以完成財務任務 亞馬遜 SageMaker 培訓 or 亞馬遜基岩 今天。
關於作者
 謝勇 是亞馬遜金融科技的應用科學家。他專注於開發大型語言模型和金融領域的生成式人工智慧應用。
謝勇 是亞馬遜金融科技的應用科學家。他專注於開發大型語言模型和金融領域的生成式人工智慧應用。
 卡蘭·阿加瓦爾 是 Amazon FinTech 的高級應用科學家,專注於金融用例的生成人工智慧。 Karan 在時間序列分析和 NLP 方面擁有豐富的經驗,尤其對從有限的標記資料中學習感興趣
卡蘭·阿加瓦爾 是 Amazon FinTech 的高級應用科學家,專注於金融用例的生成人工智慧。 Karan 在時間序列分析和 NLP 方面擁有豐富的經驗,尤其對從有限的標記資料中學習感興趣
 艾札茲艾哈邁德 是亞馬遜的應用科學經理,他領導一個科學家團隊建立機器學習和產生人工智慧在金融領域的各種應用程式。他的研究興趣是自然語言處理、生成人工智慧和法學碩士代理。他在德州農工大學獲得了電機工程博士學位。
艾札茲艾哈邁德 是亞馬遜的應用科學經理,他領導一個科學家團隊建立機器學習和產生人工智慧在金融領域的各種應用程式。他的研究興趣是自然語言處理、生成人工智慧和法學碩士代理。他在德州農工大學獲得了電機工程博士學位。
 李慶偉 是 Amazon Web Services 的機器學習專家。他獲得了博士學位。在他破壞了導師的研究資助帳戶並未能兌現他承諾的諾貝爾獎後,他獲得了運籌學博士學位。目前,他幫助金融服務客戶在 AWS 上建立機器學習解決方案。
李慶偉 是 Amazon Web Services 的機器學習專家。他獲得了博士學位。在他破壞了導師的研究資助帳戶並未能兌現他承諾的諾貝爾獎後,他獲得了運籌學博士學位。目前,他幫助金融服務客戶在 AWS 上建立機器學習解決方案。
 拉夫文德·阿尼 領導 AWS 產業內的客戶加速團隊 (CAT)。 CAT 是一個由面向客戶的雲端架構師、軟體工程師、資料科學家以及 AI/ML 專家和設計師組成的全球跨職能團隊,透過高級原型設計推動創新,並透過專業技術知識推動雲端營運卓越。
拉夫文德·阿尼 領導 AWS 產業內的客戶加速團隊 (CAT)。 CAT 是一個由面向客戶的雲端架構師、軟體工程師、資料科學家以及 AI/ML 專家和設計師組成的全球跨職能團隊,透過高級原型設計推動創新,並透過專業技術知識推動雲端營運卓越。

