亞馬遜SageMaker Studio 為資料科學家提供完全託管的解決方案,以互動方式建構、訓練和部署機器學習 (ML) 模型。在處理機器學習任務的過程中,資料科學家通常會透過發現相關資料來源並連接到它們來開始工作流程。然後,他們使用 SQL 來探索、分析、視覺化和整合來自各種來源的數據,然後將其用於 ML 訓練和推理。以前,資料科學家經常發現自己在工作流程中使用多種工具來支援 SQL,這降低了工作效率。
我們很高興地宣布,SageMaker Studio 中的 JupyterLab 筆記本現在內建了對 SQL 的支援。資料科學家現在可以:
- 連接到流行的數據服務,包括 亞馬遜雅典娜, 亞馬遜Redshift, 亞馬遜數據區,以及直接在筆記本中的 Snowflake
- 瀏覽和搜尋資料庫、模式、表格和視圖,並在筆記本介面中預覽數據
- 在同一個筆記本中混合 SQL 和 Python 程式碼,以便有效地探索和轉換資料以在 ML 專案中使用
- 使用 SQL 命令完成、程式碼格式化說明和語法突出顯示等開發人員生產力功能來幫助加速程式碼開發並提高開發人員的整體生產力
此外,管理員可以安全地管理與這些資料服務的連接,使資料科學家無需手動管理憑證即可存取授權資料。
在這篇文章中,我們將指導您在 SageMaker Studio 中設定此功能,並引導您了解此功能的各種功能。然後,我們將展示如何使用高級大語言模型 (LLM) 提供的文字到 SQL 功能來增強筆記本中的 SQL 體驗,以使用自然語言文字作為輸入來編寫複雜的 SQL 查詢。最後,為了讓更廣泛的使用者能夠從筆記本中的自然語言輸入產生 SQL 查詢,我們向您展示如何使用以下命令部署這些文字到 SQL 模型 亞馬遜SageMaker 端點。
解決方案概述
借助 SageMaker Studio JupyterLab 筆記本的 SQL 集成,您現在可以連接到流行的資料來源,例如 Snowflake、Athena、Amazon Redshift 和 Amazon DataZone。這項新功能使您能夠執行各種功能。
例如,您可以直接從 JupyterLab 生態系統直觀地探索資料庫、表格和架構等資料來源。如果您的筆記本環境在 SageMaker Distribution 1.6 或更高版本上運行,請在 JupyterLab 介面的左側尋找新的小工具。此新增增強了開發環境中的資料可存取性和管理。
如果您目前未使用建議的 SageMaker 發行版(1.5 或更低版本)或自訂環境,請參閱附錄以了解更多資訊。
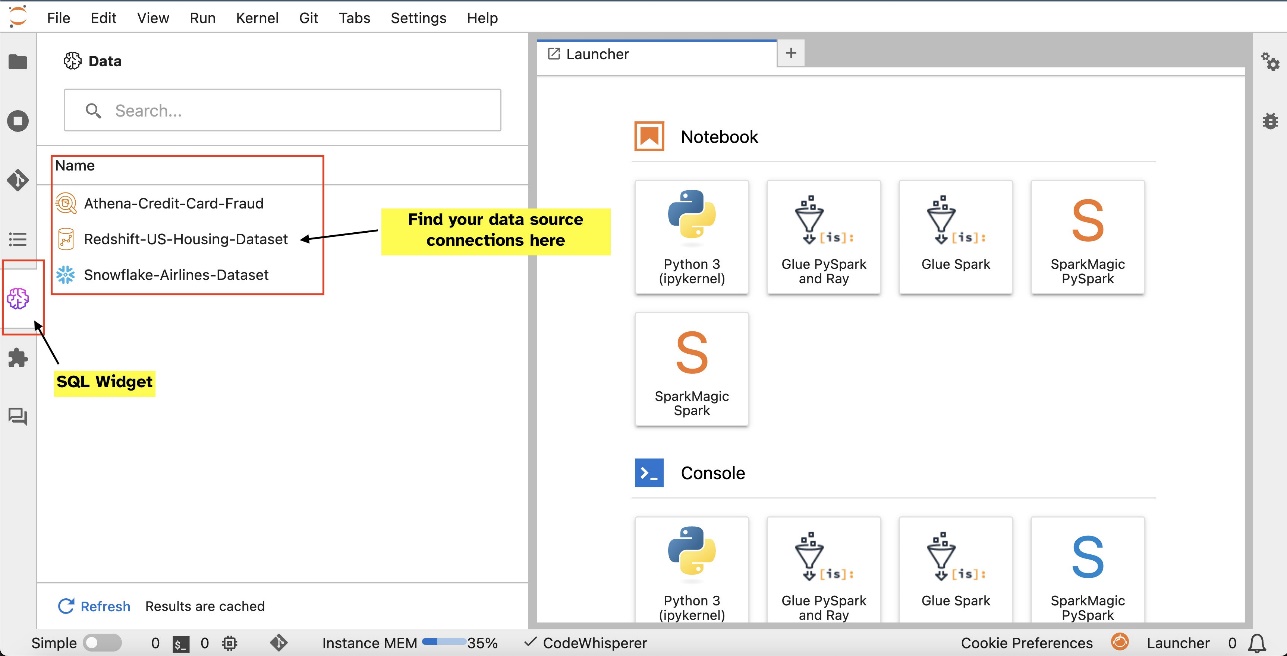
設定連線(在下一節中說明)後,您可以列出資料連線、瀏覽資料庫和表格以及檢查架構。
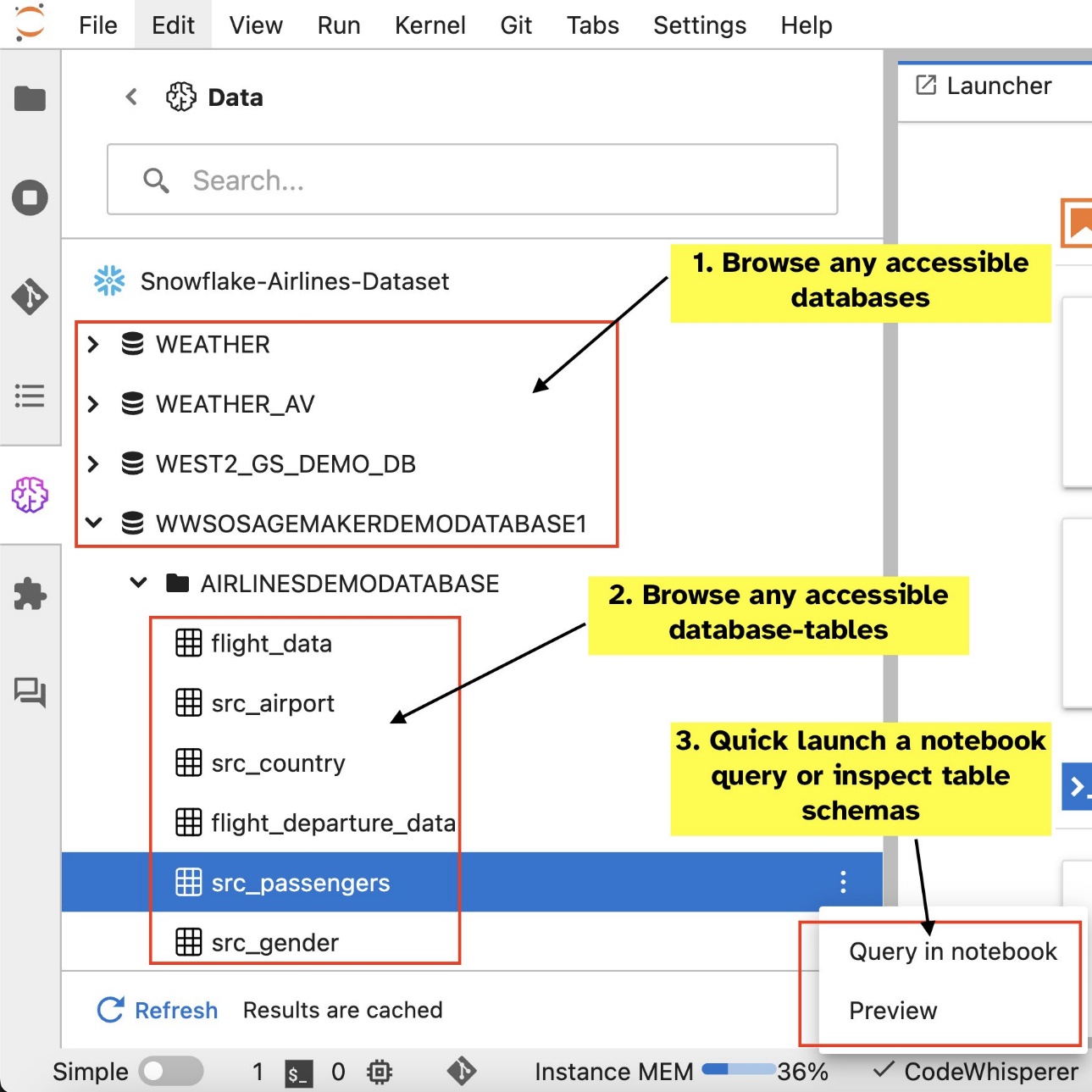
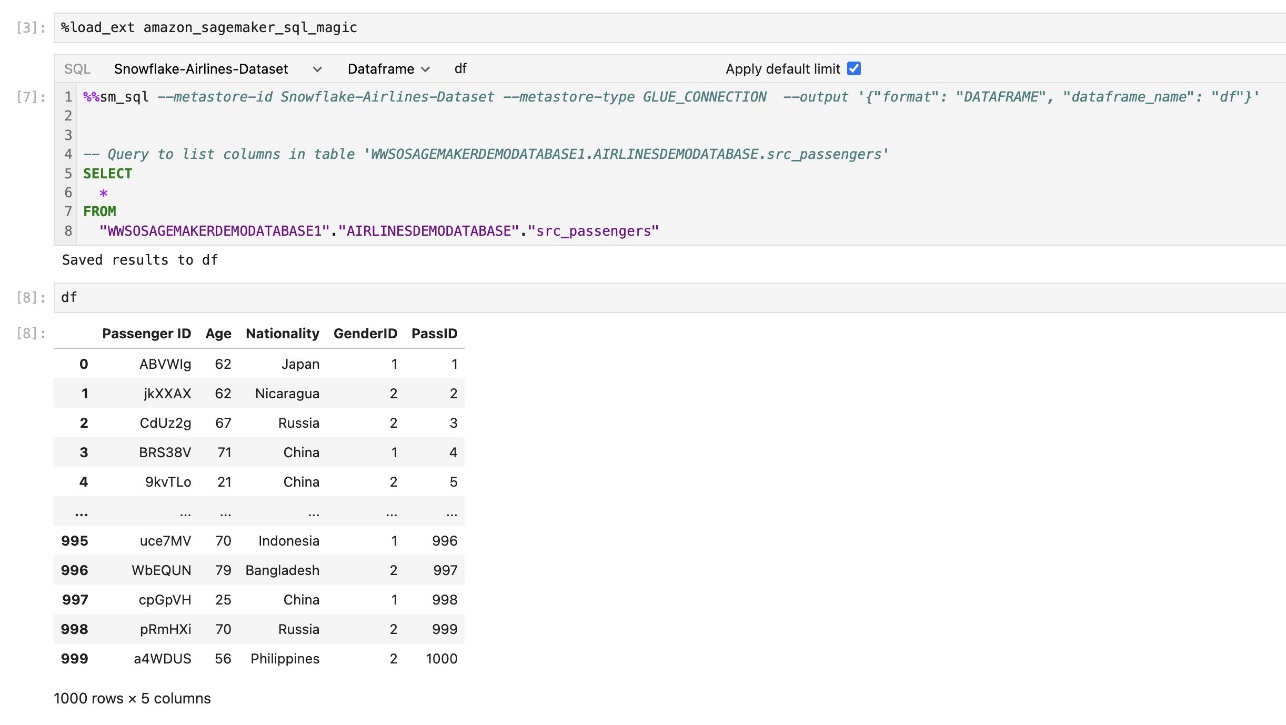
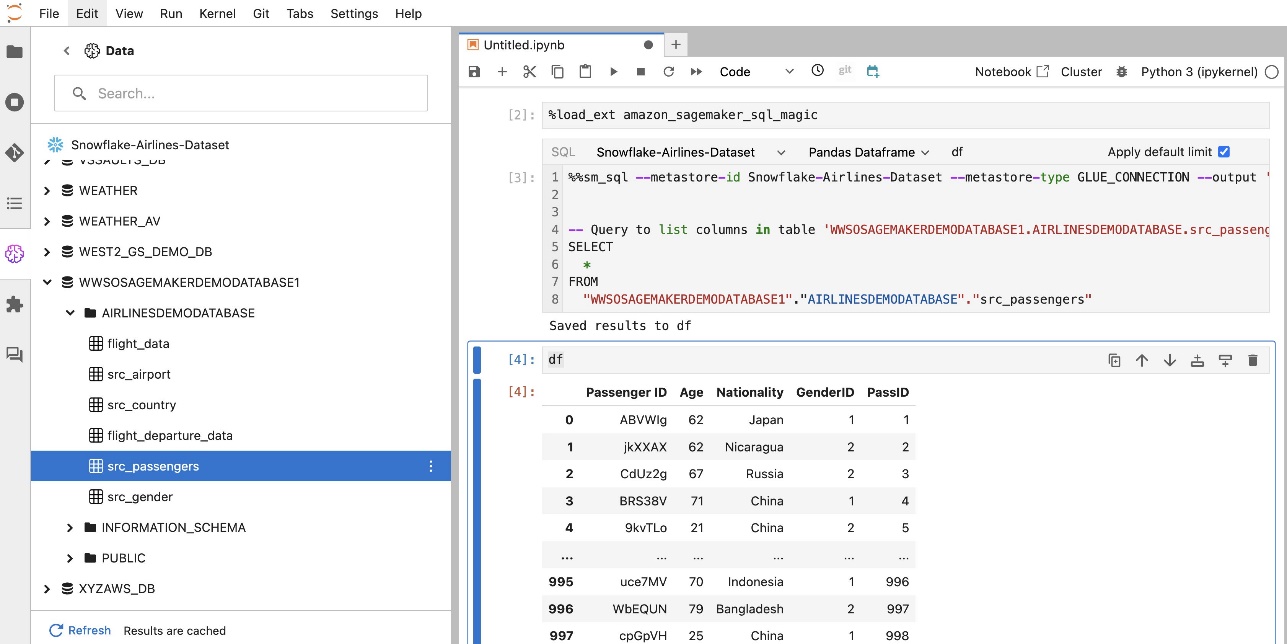
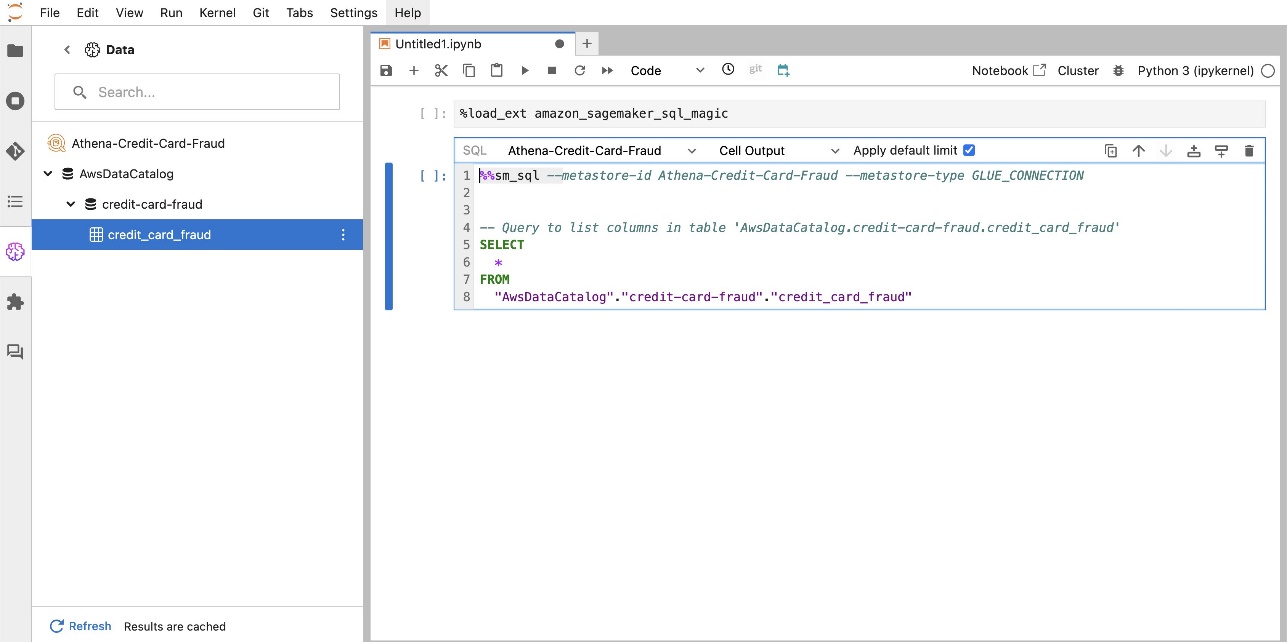
SageMaker Studio JupyterLab 內建 SQL 擴充功能還可讓您直接從筆記本執行 SQL 查詢。 Jupyter 筆記本可以使用以下指令區分 SQL 和 Python 程式碼 %%sm_sql magic 指令,必須放置在任何包含 SQL 程式碼的儲存格的頂部。此命令向 JupyterLab 發出訊號,表示以下指令是 SQL 命令而不是 Python 程式碼。查詢的輸出可以直接顯示在筆記本中,從而促進資料分析中 SQL 和 Python 工作流程的無縫整合。
查詢的輸出可以直觀地顯示為 HTML 表,如以下螢幕截圖所示。

它們也可以寫入 熊貓資料框.
條件:
確保您符合以下先決條件才能使用 SageMaker Studio 筆記型電腦 SQL 體驗:
- SageMaker Studio V2 – 確保您執行的是最新版本的 SageMaker Studio 網域和使用者設定檔。如果您目前使用的是 SageMaker Studio Classic,請參閱 從 Amazon SageMaker Studio Classic 遷移.
- IAM角色 – SageMaker 需要 AWS身份和訪問管理 若要指派給 SageMaker Studio 網域或使用者設定檔的 (IAM) 角色,以有效管理權限。可能需要更新執行角色才能引入資料瀏覽和 SQL 運行功能。以下範例策略使用戶能夠授予、列出和運行 AWS膠水,雅典娜, 亞馬遜簡單存儲服務 (Amazon S3), AWS機密管理器和 Amazon Redshift 資源:
- JupyterLab空間 – 您需要存取更新的 SageMaker Studio 和 JupyterLab Space SageMaker 發行版 v1.6 或更高版本的鏡像版本。如果您使用的是JupyterLab Spaces 或較早版本的SageMaker Distribution(v1.5 或更低版本)的自訂映像,請參閱附錄,了解安裝必要的軟體包和模組以在您的環境中啟用此功能的說明。要了解有關 SageMaker Studio JupyterLab Spaces 的更多信息,請參閱 提升 Amazon SageMaker Studio 的工作效率:JupyterLab Spaces 與生成式 AI 工具簡介.
- 資料來源存取憑證 – 此 SageMaker Studio 筆電功能需要使用者名稱和密碼才能存取 Snowflake 和 Amazon Redshift 等資料來源。如果您還沒有這些資料來源,請建立基於使用者名稱和密碼的存取權限。截至撰寫本文時,基於 OAuth 的 Snowflake 存取尚不受支援。
- 載入 SQL 魔法 – 在從 Jupyter Notebook 單元執行 SQL 查詢之前,必須載入 SQL magics 擴充功能。使用命令
%load_ext amazon_sagemaker_sql_magic啟用此功能。此外,您還可以運行%sm_sql?命令查看支援從 SQL 單元查詢的選項的完整清單。這些選項包括將預設查詢限制設為 1,000、運行完整提取以及注入查詢參數等。此設定允許直接在筆記本環境中進行靈活高效的 SQL 資料操作。
建立資料庫連接
AWS Glue 連線增強了 SageMaker Studio 的內建 SQL 瀏覽和執行功能。 AWS Glue 連線是一個 AWS Glue 資料目錄對象,用於儲存特定資料儲存的登入憑證、URI 字串和虛擬私有雲 (VPC) 資訊等基本資料。 AWS Glue 爬網程式、作業和開發終端節點使用這些連線來存取各種類型的資料儲存。您可以將這些連接用於來源資料和目標數據,甚至可以在多個爬網程式或提取、轉換和載入 (ETL) 作業中重複使用相同的連線。
要在 SageMaker Studio 的左側窗格中探索 SQL 資料來源,您首先需要建立 AWS Glue 連線物件。這些連接有助於存取不同的資料來源,並允許您探索其原理圖資料元素。
在以下部分中,我們將逐步介紹建立特定於 SQL 的 AWS Glue 連接器的過程。這將使您能夠存取、查看和探索各種資料儲存中的資料集。有關 AWS Glue 連接的更多詳細信息,請參閱 連接到數據.
建立 AWS Glue 連接
將資料來源引入 SageMaker Studio 的唯一方法是使用 AWS Glue 連線。您需要建立具有特定連線類型的 AWS Glue 連線。截至撰寫本文時,創建這些連接的唯一受支援的機制是使用 AWS命令行界面 (AWS CLI)。
連接定義 JSON 文件
在 AWS Glue 中連接到不同資料來源時,您必須先建立定義連接屬性的 JSON 檔案 - 稱為 連線定義檔。該檔案對於建立 AWS Glue 連線至關重要,並且應詳細說明存取資料來源所需的所有配置。為了實現安全最佳實踐,建議使用 Secrets Manager 安全儲存密碼等敏感資訊。同時,其他連線屬性可以直接透過 AWS Glue 連線進行管理。此方法可確保敏感憑證受到保護,同時仍使連線配置可存取和管理。
以下是連線定義 JSON 的範例:
為資料來源設定 AWS Glue 連線時,需要遵循一些重要準則以提供功能和安全性:
- 屬性的字串化 – 在
PythonPropertieskey,確保所有屬性都是 字串化的鍵值對。在必要時使用反斜線 () 字元正確轉義雙引號至關重要。這有助於維護正確的格式並避免 JSON 中的語法錯誤。 - 處理敏感資訊 – 儘管可以包含所有連線屬性
PythonProperties,建議不要直接在這些屬性中包含密碼等敏感詳細資訊。相反,請使用 Secrets Manager 來處理敏感資訊。這種方法透過將敏感資料儲存在遠離主設定檔的受控和加密環境中來保護您的敏感資料。
使用 AWS CLI 建立 AWS Glue 連接
在連線定義 JSON 檔案中包含所有必要欄位後,您就可以使用 AWS CLI 和下列命令為資料來源建立 AWS Glue 連線:
此命令根據 JSON 檔案中詳細說明的規範啟動新的 AWS Glue 連線。以下是命令元件的快速細分:
- -地區 – 這會指定將在其中建立 AWS Glue 連線的 AWS 區域。選擇資料來源和其他服務所在的區域至關重要,以最大限度地減少延遲並遵守資料駐留要求。
- –cli-input-json 檔案:///path/to/file/connection/definition/file.json – 此參數指示 AWS CLI 從包含 JSON 格式的連線定義的本機檔案讀取輸入配置。
您應該能夠從 Studio JupyterLab 終端機使用上述 AWS CLI 命令建立 AWS Glue 連線。上 文件 菜單,選擇 全新 和 終端.

如果 create-connection 命令成功運行後,您應該會看到 SQL 瀏覽器窗格中列出了您的資料來源。如果您沒有看到列出的資料來源,請選擇 刷新 更新快取。

創建雪花連接
在本節中,我們將重點放在 Snowflake 資料來源與 SageMaker Studio 的整合。建立 Snowflake 帳戶、資料庫和倉庫不屬於本文的討論範圍。要開始使用 Snowflake,請參閱 雪花使用者指南。在本文中,我們將重點放在如何建立 Snowflake 定義 JSON 檔案並使用 AWS Glue 建立 Snowflake 資料來源連線。
建立 Secrets Manager 金鑰
您可以使用使用者 ID 和密碼或使用私鑰連接到您的 Snowflake 帳戶。若要使用使用者 ID 和密碼進行連接,您需要將憑證安全地儲存在 Secrets Manager 中。如前所述,儘管可以將此資訊嵌入 PythonProperties 下,但不建議以純文字格式儲存敏感資訊。始終確保敏感資料得到安全處理,以避免潛在的安全風險。
若要將資訊儲存在 Secrets Manager 中,請完成下列步驟:
- 在Secrets Manager控制台上,選擇 儲存新秘密.
- 為 保密型選擇 其他類型的秘密.
- 對於鍵值對,選擇 純文本 並輸入以下內容:
- 輸入您的秘密的名稱,例如
sm-sql-snowflake-secret. - 將其他設定保留為預設設定或根據需要進行自訂。
- 創造秘密。
為 Snowflake 建立 AWS Glue 連接
如前所述,AWS Glue 連線對於從 SageMaker Studio 存取任何連線至關重要。您可以找到以下列表 Snowflake 所有支援的連線屬性。以下是 Snowflake 的範例連接定義 JSON。將佔位符值替換為適當的值,然後再將其儲存到磁碟:
若要為 Snowflake 資料來源建立 AWS Glue 連接對象,請使用下列命令:
此命令在 SQL 瀏覽器窗格中建立一個可瀏覽的新 Snowflake 資料來源連接,您可以從 JupyterLab 筆記本單元對其執行 SQL 查詢。
創建 Amazon Redshift 連接
Amazon Redshift 是一項完全託管的 PB 級資料倉儲服務,可簡化使用標準 SQL 分析所有資料的流程並降低成本。建立 Amazon Redshift 連接的過程與 Snowflake 連接的過程非常相似。
建立 Secrets Manager 金鑰
與 Snowflake 設定類似,若要使用使用者 ID 和密碼連接到 Amazon Redshift,您需要將金鑰資訊安全地儲存在 Secrets Manager 中。完成以下步驟:
- 在Secrets Manager控制台上,選擇 儲存新秘密.
- 為 保密型選擇 Amazon Redshift 叢集的憑證.
- 輸入用於登入以存取 Amazon Redshift 作為資料來源的憑證。
- 選擇與金鑰關聯的 Redshift 叢集。
- 輸入秘密的名稱,例如
sm-sql-redshift-secret. - 將其他設定保留為預設設定或根據需要進行自訂。
- 創造秘密。
透過執行這些步驟,您可以確保安全地處理您的連線憑證,並使用 AWS 強大的安全功能有效管理敏感資料。
為 Amazon Redshift 建立 AWS Glue 連接
若要使用 JSON 定義設定與 Amazon Redshift 的連接,請填寫必要的欄位並將下列 JSON 設定儲存到磁碟:
若要為 Redshift 資料來源建立 AWS Glue 連接對象,請使用下列 AWS CLI 命令:
此命令在 AWS Glue 中建立連結到您的 Redshift 資料來源的連線。如果命令成功運行,您將能夠在 SageMaker Studio JupyterLab 筆記本中看到 Redshift 資料來源,準備好執行 SQL 查詢和執行資料分析。

建立 Athena 連接
Athena 是 AWS 提供的完全託管的 SQL 查詢服務,支援使用標準 SQL 分析 Amazon S3 中儲存的資料。若要將 Athena 連線設定為 JupyterLab 筆記本的 SQL 瀏覽器中的資料來源,您需要建立 Athena 範例連線定義 JSON。以下 JSON 結構配置連接到 Athena 所需的詳細信息,指定資料目錄、S3 暫存目錄和區域:
若要為 Athena 資料來源建立 AWS Glue 連接對象,請使用下列 AWS CLI 命令:
如果命令成功,您將能夠直接從 SageMaker Studio JupyterLab 筆記本中的 SQL 瀏覽器存取 Athena 資料目錄和表格。
查詢多個來源的數據
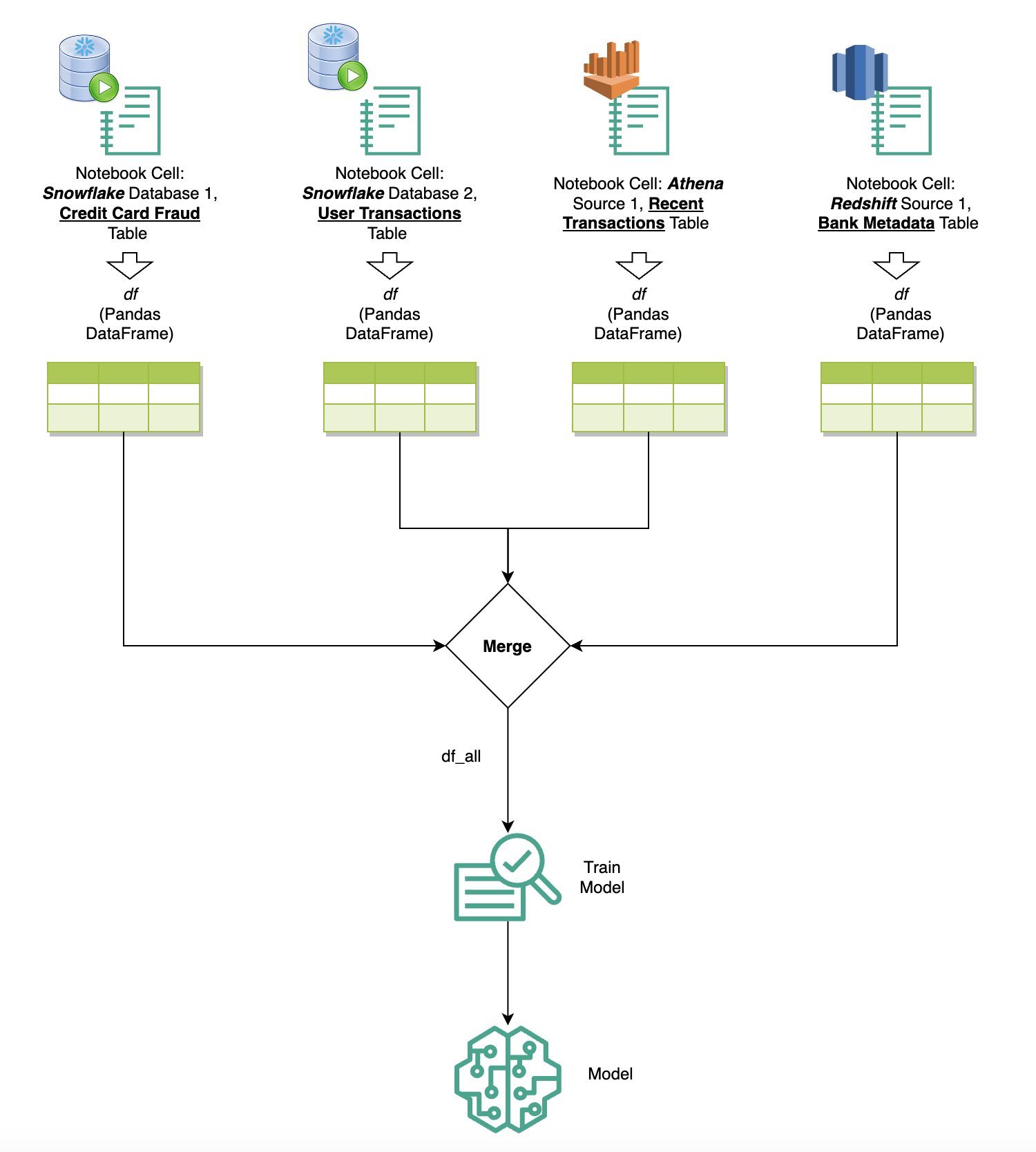
如果您透過內建 SQL 瀏覽器和筆記型電腦 SQL 功能將多個資料來源整合到 SageMaker Studio 中,則可以快速執行查詢並輕鬆在筆記型電腦內後續單元中的資料來源後端之間切換。此功能允許在分析工作流程期間在不同資料庫或資料來源之間無縫轉換。
您可以對各種資料來源後端集合執行查詢,並將結果直接帶入 Python 空間以進行進一步分析或視覺化。這是由 %%sm_sql SageMaker Studio 筆記本中提供 magic 指令。要將 SQL 查詢的結果輸出到 pandas DataFrame 中,有兩個選項:
- 從筆記本儲存格工具列中選擇輸出類型 數據框 並命名您的 DataFrame 變數
- 將以下參數附加到您的
%%sm_sql命令:
下圖說明了此工作流程,並展示瞭如何輕鬆地在後續筆記本單元中跨各種來源運行查詢,以及如何使用訓練作業或直接在筆記本中使用本地計算來訓練 SageMaker 模型。此外,該圖還突出顯示了 SageMaker Studio 的內建 SQL 整合如何簡化直接在熟悉的 JupyterLab 筆記本單元環境中提取和建置的過程。
文字到 SQL:使用自然語言增強查詢創作
SQL 是一種複雜的語言,需要了解資料庫、表格、語法和元資料。如今,生成式人工智慧 (AI) 可以讓您編寫複雜的 SQL 查詢,而無需深入的 SQL 經驗。法學碩士的進步極大地影響了基於自然語言處理 (NLP) 的 SQL 生成,允許從自然語言描述創建精確的 SQL 查詢——一種稱為「文本到 SQL」的技術。然而,必須承認人類語言和 SQL 之間的固有差異。人類語言有時可能含糊不清或不精確,而 SQL 是結構化的、明確的且明確的。彌合這一差距並將自然語言準確地轉換為 SQL 查詢可能會帶來巨大的挑戰。當提供適當的提示時,法學碩士可以透過理解人類語言背後的意圖並相應地產生準確的 SQL 查詢來幫助彌合這一差距。
隨著 SageMaker Studio 筆記本內 SQL 查詢功能的發布,SageMaker Studio 可以輕鬆檢查資料庫和架構,以及編寫、運行和偵錯 SQL 查詢,而無需離開 Jupyter 筆記本 IDE。本節探討高級法學碩士的文本到 SQL 功能如何促進在 Jupyter Notebook 中使用自然語言產生 SQL 查詢。我們採用最先進的文字到 SQL 模型 defog/sqlcoder-7b-2 與專為 Jupyter Notebook 設計的生成式 AI 助理 Jupyter AI 結合使用,可以從自然語言建立複雜的 SQL 查詢。透過使用此進階模型,我們可以使用自然語言輕鬆且有效率地建立複雜的 SQL 查詢,從而增強我們在筆記本中的 SQL 體驗。
使用 Hugging Face Hub 進行筆記本原型設計
要開始原型設計,您需要以下內容:
- GitHub代碼 – 本節提供的程式碼可在以下位置找到 GitHub回購 並透過引用 示例筆記本.
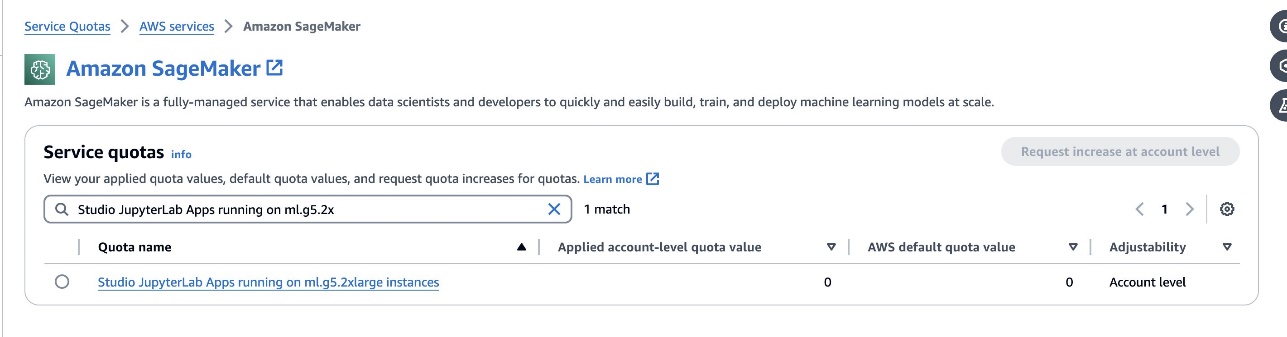
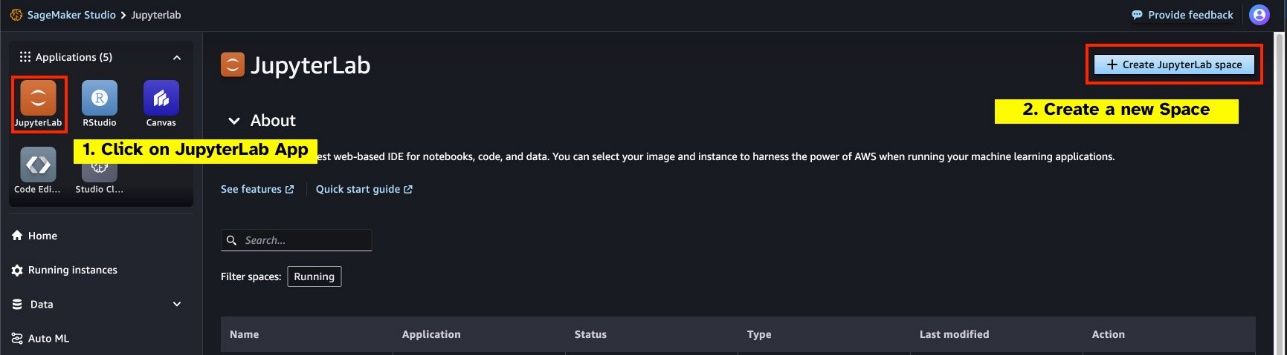
- JupyterLab空間 – 存取由基於 GPU 的執行個體支援的 SageMaker Studio JupyterLab Space 至關重要。為了
defog/sqlcoder-7b-2模型,7B參數模型,建議使用ml.g5.2xlarge實例。替代方案如defog/sqlcoder-70b-alph一個或defog/sqlcoder-34b-alpha對於自然語言到 SQL 的轉換也是可行的,但原型設計可能需要更大的實例類型。確保您有配額啟動 GPU 支援的實例,方法是導航到服務配額控制台,搜尋 SageMaker,然後搜尋Studio JupyterLab Apps running on <instance type>.
從 SageMaker Studio 啟動新的 GPU 支援的 JupyterLab Space。建議創建一個至少 75 GB 的新 JupyterLab 空間 Amazon Elastic Block商店 (Amazon EBS) 7B 參數模型的儲存。

- 抱臉樞紐 – 如果您的 SageMaker Studio 網域有權從下列位置下載模型 抱臉樞紐,你可以使用
AutoModelForCausalLM班級來自 擁抱臉/變形金剛 自動下載模型並將其固定到本機 GPU。模型權重將儲存在本機的快取中。請看下面的程式碼:
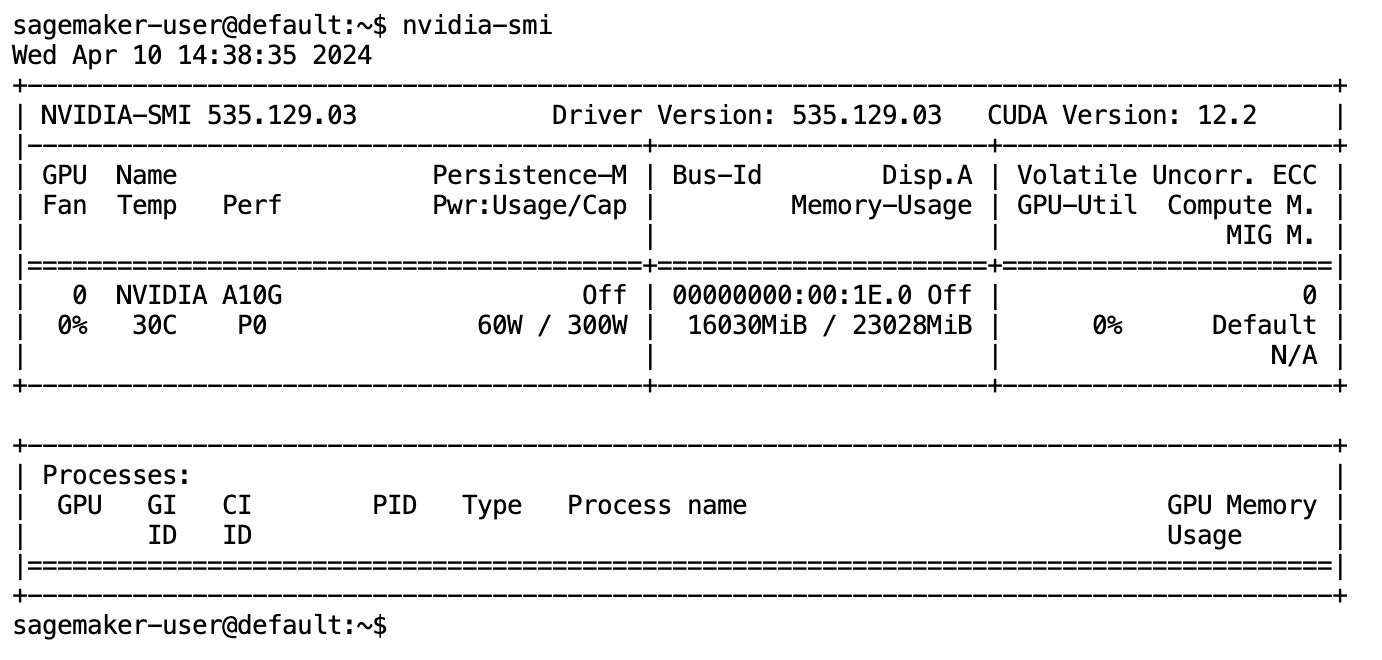
模型完全下載並載入到記憶體後,您應該會觀察到本機電腦上的 GPU 利用率增加。這表明該模型正在積極使用 GPU 資源來執行運算任務。您可以透過運行在您自己的 JupyterLab 空間中驗證這一點 nvidia-smi (用於一次性顯示)或 nvidia-smi —loop=1 (每秒重複一次)從 JupyterLab 終端。
文字到 SQL 模型擅長理解使用者請求的意圖和上下文,即使使用的語言是會話式的或模稜兩可的。這個過程涉及將自然語言輸入轉換為正確的資料庫模式元素,例如表名、列名和條件。然而,現成的文字到 SQL 模型本身並不知道資料倉儲的結構、特定的資料庫模式,或無法僅根據列名稱準確地解釋表的內容。為了有效地使用這些模型從自然語言產生實用且高效的 SQL 查詢,有必要使 SQL 文字產生模型適應您的特定倉庫資料庫模式。這種適應是透過使用來促進的 LLM提示。以下是defog/sqlcoder-7b-2 Text-to-SQL模型的建議提示模板,分為四個部分:
- 任務 – 本節應指定模型要完成的高階任務。它應包括資料庫後端的類型(例如 Amazon RDS、PostgreSQL 或 Amazon Redshift),以使模型了解可能影響最終 SQL 查詢產生的任何細微語法差異。
- 說明 – 本節應定義模型的任務邊界和領域感知,並可能包括少量範例來指導模型產生微調的 SQL 查詢。
- 數據庫架構 – 本節應詳細介紹您的倉庫資料庫模式,概述表格和欄位之間的關係,以幫助模型理解資料庫結構。
- 回答 – 此部分保留用於模型輸出對自然語言輸入的 SQL 查詢回應。
本節中使用的資料庫模式和提示的範例可在 GitHub回購.
即時工程不僅僅是提出問題或陳述;而是提出問題。這是一門微妙的藝術和科學,會顯著影響與人工智慧模型互動的品質。您製作提示的方式可以深刻地影響人工智慧回應的性質和有用性。這項技能對於最大限度地發揮人工智慧互動的潛力至關重要,尤其是在需要專業理解和詳細回應的複雜任務中。
能夠快速建立和測試模型對給定提示的響應並根據響應優化提示非常重要。 JupyterLab 筆記本能夠從本地計算上運行的模型接收即時模型回饋,並優化提示並進一步調整模型的回應或完全更改模型。在本文中,我們使用由 ml.g5.2xlarge 的 NVIDIA A10G 24 GB GPU 支援的 SageMaker Studio JupyterLab 筆記本在筆記本上運行文本到 SQL 模型推理,並以交互方式構建模型提示,直到模型的響應充分調整以提供可在JupyterLab 的SQL 單元中直接執行的回應。為了運行模型推理並同時串流模型響應,我們結合使用 model.generate 和 TextIteratorStreamer 如以下程式碼所定義:
模型的輸出可以使用 SageMaker SQL magic 進行修飾 %%sm_sql ...,它允許 JupyterLab 筆記本將該單元識別為 SQL 單元。
將文字到 SQL 模型託管為 SageMaker 端點
在原型設計階段結束時,我們選擇了首選的文字到 SQL LLM、有效的提示格式以及用於託管模型的適當執行個體類型(單 GPU 或多 GPU)。 SageMaker 透過使用 SageMaker 端點促進自訂模型的可擴充託管。這些端點可以根據特定標準進行定義,從而允許將 LLM 部署為端點。此功能可讓您將解決方案擴展到更廣泛的受眾,允許使用者使用自訂託管的 LLM 從自然語言輸入來產生 SQL 查詢。下圖說明了這種架構。

若要將 LLM 作為 SageMaker 端點託管,您需要產生多個工件。
第一個工件是模型權重。 SageMaker 深度 Java 函式庫 (DJL) 服務 容器可讓您透過元設定配置 服務.properties 文件,它使您能夠指導模型的來源方式 - 直接從 Hugging Face Hub 或透過從 Amazon S3 下載模型工件。如果您指定 model_id=defog/sqlcoder-7b-2,DJL Serving 將嘗試直接從 Hugging Face Hub 下載此型號。但是,每次部署或彈性擴展端點時,您可能會產生網路入口/出口費用。為了避免這些費用並可能加快模型工件的下載速度,建議跳過使用 model_id in serving.properties 並將模型權重儲存為 S3 工件,並且僅指定它們 s3url=s3://path/to/model/bin.
只需幾行程式碼即可將模型(及其標記產生器)儲存到磁碟並將其上傳到 Amazon S3:
您也可以使用資料庫提示檔案。在此設定中,資料庫提示由以下部分組成 Task, Instructions, Database Schema和 Answer sections。對於目前的架構,我們為每個資料庫模式指派一個單獨的提示檔。但是,可以靈活地擴展此設定以在每個提示檔案中包含多個資料庫,從而允許模型在同一伺服器上跨資料庫運行複合聯接。在原型設計階段,我們將資料庫提示儲存為名為的文字文件 <Database-Glue-Connection-Name>.prompt,其中 Database-Glue-Connection-Name 對應於 JupyterLab 環境中可見的連接名稱。例如,這篇文章引用了一個名為的 Snowflake 連接 Airlines_Dataset,所以資料庫提示檔案命名為 Airlines_Dataset.prompt。然後,該檔案儲存在 Amazon S3 上,隨後由我們的模型服務邏輯讀取和快取。
此外,該架構允許該端點的任何授權使用者定義、儲存和產生 SQL 查詢的自然語言,而無需多次重新部署模型。我們使用以下 資料庫提示範例 示範文字到 SQL 功能。
接下來,您產生自訂模型服務邏輯。在本節中,您將概述名為的自訂推理邏輯 模型。該腳本旨在優化我們的文字到 SQL 服務的效能和整合:
- 定義資料庫提示檔案快取邏輯 – 為了最大限度地減少延遲,我們實現了用於下載和快取資料庫提示檔案的自訂邏輯。此機制可確保提示隨時可用,從而減少與頻繁下載相關的開銷。
- 定義自訂模型推理邏輯 – 為了提高推理速度,我們的文字到 SQL 模型以 float16 精度格式加載,然後轉換為 DeepSpeed 模型。此步驟允許更有效的計算。此外,在此邏輯中,您可以指定使用者在推理呼叫期間可以調整哪些參數,以根據他們的需求自訂功能。
- 定義自訂輸入和輸出邏輯 – 建立清晰且客製化的輸入/輸出格式對於與下游應用程式的順利整合至關重要。 JupyterAI 就是這樣的一個應用程序,我們將在後續部分中討論它。
此外,我們還包括一個 serving.properties 文件,它充當使用 DJL 服務託管的模型的全域設定檔。欲了解更多信息,請參閱 配置和設置.
最後,您還可以添加一個 requirements.txt 檔案來定義推理所需的附加模組,並將所有內容打包到 tarball 中以供部署。
請參見以下代碼:
將您的端點與 SageMaker Studio Jupyter AI 助理集成
Jupyter人工智慧 是一款開源工具,可將生成式 AI 引入 Jupyter 筆記本,為探索生成式 AI 模型提供強大且用戶友好的平台。它透過提供%%ai magic 等功能來提高JupyterLab 和Jupyter 筆記本的工作效率,這些功能用於在筆記本內創建生成式AI 遊樂場、JupyterLab 中用於作為對話助手與AI 交互的本機聊天UI,以及對來自各種法學碩士的支援供應商喜歡 亞馬遜泰坦、AI21、Anthropic、Cohere 和 Hugging Face 或託管服務,例如 亞馬遜基岩 和 SageMaker 端點。在這篇文章中,我們使用 Jupyter AI 與 SageMaker 端點的開箱即用集成,將文字到 SQL 功能引入 JupyterLab 筆記本中。 Jupyter AI 工具預先安裝在所有由以下公司支援的 SageMaker Studio JupyterLab 空間中 SageMaker 發行版影像;最終用戶無需進行任何額外配置即可開始使用 Jupyter AI 擴充功能與 SageMaker 託管端點整合。在本節中,我們將討論使用整合 Jupyter AI 工具的兩種方法。
Jupyter AI 在筆記本中使用魔法
Jupyter AI 的 %%ai magic 指令可讓您將 SageMaker Studio JupyterLab 筆記本轉變為可重複的生成 AI 環境。要開始使用 AI magics,請確保您已載入要使用的 jupyter_ai_magics 擴充 %%ai 魔法,並額外加載 amazon_sagemaker_sql_magic 使用 %%sm_sql 魔法:
若要使用下列命令從筆電執行對 SageMaker 端點的呼叫: %%ai magic 指令,提供以下參數並建構指令如下:
- –區域名稱 – 指定部署終端的區域。這可確保請求被路由到正確的地理位置。
- –請求模式 – 包含輸入資料的模式。此架構概述了模型處理請求所需的輸入資料的預期格式和類型。
- –回應路徑 – 定義響應對象內模型輸出所在的路徑。此路徑用於從模型傳回的回應中提取相關資料。
- -f(可選) - 這是一 輸出格式化程式 指示模型傳回的輸出類型的標誌。在 Jupyter 筆記本的上下文中,如果輸出是程式碼,則應相應地設定此標誌,以將輸出格式化為 Jupyter 筆記本單元頂部的可執行程式碼,後面是用於使用者互動的自由文字輸入區域。
例如,Jupyter 筆記本單元中的命令可能類似於以下程式碼:
Jupyter AI 聊天窗口
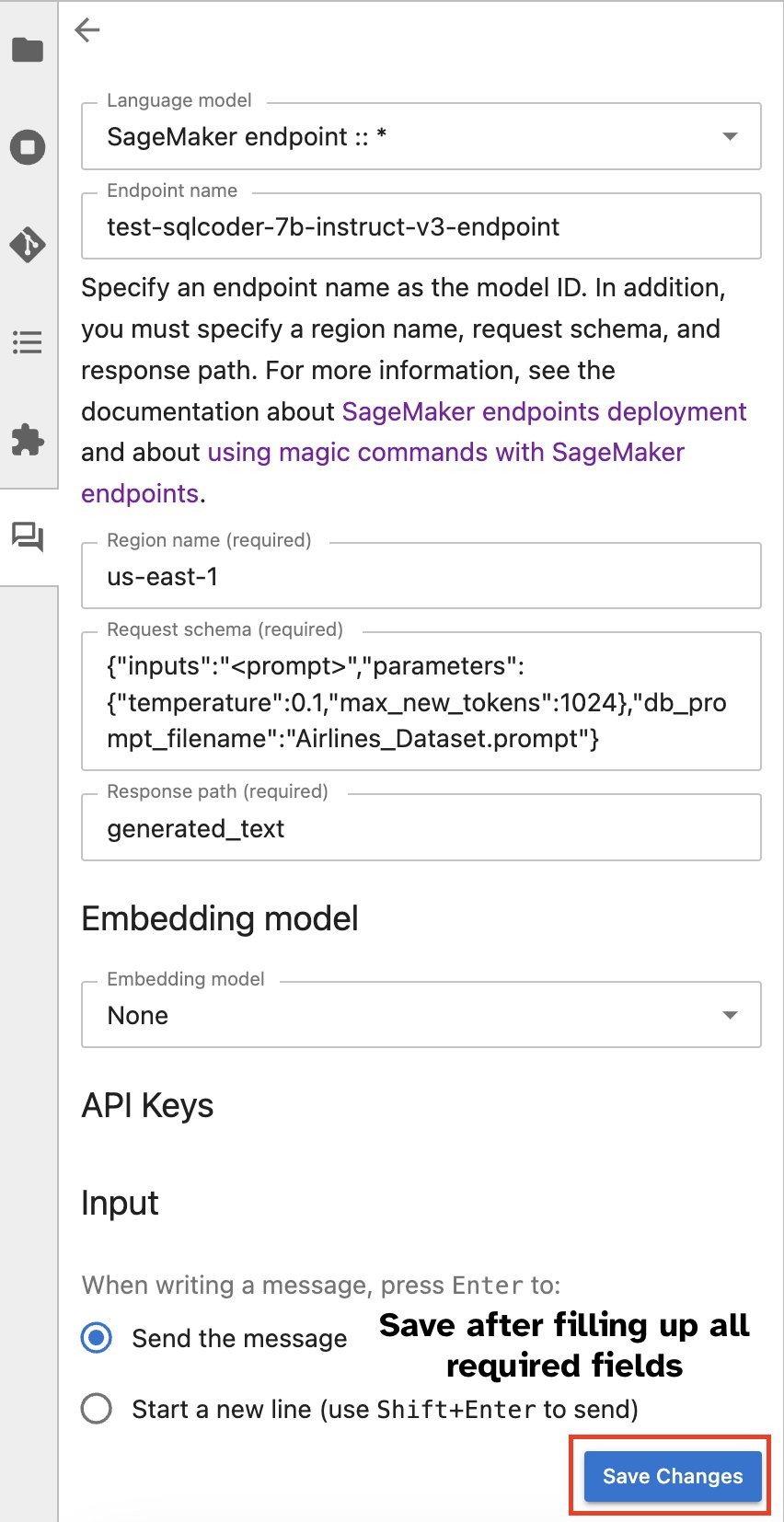
或者,您可以透過內建使用者介面與 SageMaker 端點進行交互,從而簡化產生查詢或參與對話的過程。在開始與 SageMaker 端點聊天之前,請在 Jupyter AI 中為 SageMaker 端點配置相關設置,如以下螢幕截圖所示。
 |
 |
結論
SageMaker Studio 現在透過將 SQL 支援整合到 JupyterLab 筆記本中來簡化和簡化資料科學家的工作流程。這使得資料科學家能夠專注於他們的任務,而無需管理多個工具。此外,SageMaker Studio 中新的內建 SQL 整合使資料角色能夠使用自然語言文字作為輸入輕鬆產生 SQL 查詢,從而加速其工作流程。
我們鼓勵您在 SageMaker Studio 中探索這些功能。欲了解更多信息,請參閱 在 Studio 中使用 SQL 準備數據.
附錄
在自訂環境中啟用 SQL 瀏覽器和筆記型電腦 SQL 單元
如果您不使用 SageMaker 發行版映像或使用發行版映像 1.5 或更低版本,請執行下列命令以在 JupyterLab 環境中啟用 SQL 瀏覽功能:
重新定位 SQL 瀏覽器小工具
JupyterLab 小工具允許重新定位。根據您的偏好,您可以將小工具移到 JupyterLab 小工具窗格的任一側。如果您願意,只需右鍵單擊小工具圖示並選擇,即可將 SQL 小工具的方向移至側邊欄的另一側(從右到左) 切換側邊欄.
 |
 |
關於作者
 普拉納夫·穆爾蒂 是 AWS 的 AI/ML 專家解決方案架構師。 他專注於幫助客戶建置、訓練、部署機器學習 (ML) 工作負載並將其遷移到 SageMaker。 他之前曾在半導體行業工作,開發大型電腦視覺 (CV) 和自然語言處理 (NLP) 模型,以使用最先進的 ML 技術改進半導體製程。 空閒時間,他喜歡下棋和旅行。 您可以在以下位置找到普拉納夫: LinkedIn.
普拉納夫·穆爾蒂 是 AWS 的 AI/ML 專家解決方案架構師。 他專注於幫助客戶建置、訓練、部署機器學習 (ML) 工作負載並將其遷移到 SageMaker。 他之前曾在半導體行業工作,開發大型電腦視覺 (CV) 和自然語言處理 (NLP) 模型,以使用最先進的 ML 技術改進半導體製程。 空閒時間,他喜歡下棋和旅行。 您可以在以下位置找到普拉納夫: LinkedIn.
 瓦倫·沙阿 是一名在 Amazon Web Services 的 Amazon SageMaker Studio 工作的軟體工程師。他專注於建立互動式機器學習解決方案,以簡化數據處理和數據準備過程。在業餘時間,Varun 喜歡戶外活動,包括遠足和滑雪,並且總是樂於發現新的、令人興奮的地方。
瓦倫·沙阿 是一名在 Amazon Web Services 的 Amazon SageMaker Studio 工作的軟體工程師。他專注於建立互動式機器學習解決方案,以簡化數據處理和數據準備過程。在業餘時間,Varun 喜歡戶外活動,包括遠足和滑雪,並且總是樂於發現新的、令人興奮的地方。
 蘇美達斯瓦米 是 Amazon Web Services 的首席產品經理,他領導 SageMaker Studio 團隊完成開發資料科學和機器學習首選 IDE 的使命。在過去的 15 年裡,他致力於建立基於機器學習的消費者和企業產品。
蘇美達斯瓦米 是 Amazon Web Services 的首席產品經理,他領導 SageMaker Studio 團隊完成開發資料科學和機器學習首選 IDE 的使命。在過去的 15 年裡,他致力於建立基於機器學習的消費者和企業產品。
 博斯科阿爾伯克基 是 AWS 的高級合作夥伴解決方案架構師,在使用企業數據庫供應商和雲提供商的數據庫和分析產品方面擁有 20 多年的經驗。 他曾幫助科技公司設計和實施數據分析解決方案和產品。
博斯科阿爾伯克基 是 AWS 的高級合作夥伴解決方案架構師,在使用企業數據庫供應商和雲提供商的數據庫和分析產品方面擁有 20 多年的經驗。 他曾幫助科技公司設計和實施數據分析解決方案和產品。
- SEO 支持的內容和 PR 分發。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 賦予自己力量。 訪問這裡。
- 柏拉圖愛流。 Web3 智能。 知識放大。 訪問這裡。
- 柏拉圖ESG。 碳, 清潔科技, 能源, 環境, 太陽能, 廢物管理。 訪問這裡。
- 柏拉圖健康。 生物技術和臨床試驗情報。 訪問這裡。
- 資源: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

