這篇文章是與 LSEG 低延遲小組的 Pramod Nayak、LakshmiKanth Mannem 和 Vivek Aggarwal 共同撰寫的。
交易成本分析 (TCA) 被交易者、投資組合經理和經紀商廣泛用於交易前和交易後分析,幫助他們衡量和優化交易成本及其交易策略的有效性。在這篇文章中,我們分析了選擇權買賣價差 LSEG 變動歷史 – PCAP 數據集使用 適用於 Apache Spark 的亞馬遜雅典娜。我們向您展示如何存取資料、定義應用於資料的自訂函數、查詢和過濾資料集以及視覺化分析結果,所有這些都無需擔心設定基礎架構或配置 Spark,即使對於大型資料集也是如此。
背景
選擇權價格報告局 (OPRA) 是一個重要的證券資訊處理機構,負責收集、整合和傳播美國選擇權的最新銷售報告、報價和相關資訊。 OPRA 擁有 18 個活躍的美國期權交易所和超過 1.5 萬份合格合約,在提供全面的市場數據方面發揮關鍵作用。
5 年 2024 月 48 日,證券業自動化公司 (SIAC) 計劃將 OPRA 來源從 96 個多播通道升級到 37.3 個。此增強功能旨在優化符號分佈和線路容量利用率,以應對美國期權市場不斷升級的交易活動和波動性。 SIAC 建議各公司為高達每秒 XNUMX GB 的峰值資料速率做好準備。
儘管升級不會立即改變已發布資料的總量,但它使 OPRA 能夠以明顯更快的速度傳播資料。這種轉變對於滿足動態選擇權市場的需求至關重要。
OPRA 是數量最多的 Feed 之一,在 150.4 年第三季達到單日 3 億條訊息的峰值,並且單日的容量空間需求為 2023 億條訊息。捕捉每個訊息對於交易成本分析、市場流動性監控、交易策略評估和市場研究至關重要。
關於數據
LSEG 變動歷史 – PCAP 是一個基於雲端的儲存庫,超過 30 PB,容納超高品質的全球市場數據。這些資料是在交換資料中心內直接擷取的,採用策略性地位於全球主要主要和備份交換資料中心的冗餘擷取流程。 LSEG 的捕獲技術可確保無損資料捕獲,並使用 GPS 時間源實現奈秒時間戳精度。此外,還採用複雜的資料套利技術來無縫填補任何資料缺口。捕獲後,數據經過細緻的處理和仲裁,然後使用以下方法將其標準化為 Parquet 格式: LSEG 的即時超直接 (RTUD) 飼料處理機。
規範化過程是準備分析資料不可或缺的一部分,每天產生多達 6 TB 的壓縮 Parquet 檔案。大量資料歸因於 OPRA 的包容性,跨越多個交易所,並具有眾多具有不同屬性的選擇權合約。市場波動性的增加和期權交易所的做市活動進一步增加了 OPRA 上發布的數據量。
Tick History – PCAP 的屬性使公司能夠進行各種分析,包括以下內容:
- 交易前分析 – 評估潛在的貿易影響並根據歷史資料探索不同的執行策略
- 交易後評估 – 根據基準衡量實際執行成本,以評估執行策略的績效
- 優化 執行 – 根據歷史市場模式微調執行策略,以盡量減少市場影響並降低整體交易成本
- 風險管理 – 識別滑點模式、識別異常值並主動管理與交易活動相關的風險
- 績效歸因 – 在分析投資組合表現時將交易決策與投資決策的影響分開
LSEG Tick History – PCAP 資料集可在 AWS數據交換 並且可以訪問 AWS Marketplace。 同 適用於 Amazon S3 的 AWS 資料交換,您可以直接從 LSEG 存取 PCAP 數據 亞馬遜簡單存儲服務 (Amazon S3) 儲存桶,企業無需儲存自己的資料副本。這種方法簡化了數據管理和存儲,使客戶能夠立即存取高品質的 PCAP 或標準化數據,並且易於使用、整合和 節省大量資料存儲.
Apache Spark 的 Athena
對於分析工作, Apache Spark 的 Athena 提供可透過 Athena 控制台或 Athena API 存取的簡化筆記本體驗,讓您建立互動式 Apache Spark 應用程式。當借助優化的 Spark 運行時,Athena 透過在不到一秒的時間內動態擴展 Spark 引擎的數量來幫助分析 PB 級資料。此外,pandas 和 NumPy 等常用 Python 庫無縫集成,允許創建複雜的應用程式邏輯。這種靈活性也延伸到了在筆記本中使用的自訂庫的導入。 Athena for Spark 可容納大多數開放資料格式,並與 AWS膠水 數據目錄。
數據集
在本次分析中,我們使用了 17 年 2023 月 XNUMX 日的 LSEG Tick History – PCAP OPRA 資料集。此資料集包含以下組成部分:
- 最佳買價和賣價(BBO) – 報告給定交易所證券的最高出價和最低要價
- 全國最佳買入價和賣出價(NBBO) – 報告所有交易所中證券的最高出價和最低要價
- 交易 – 記錄所有交易所已完成的交易
此資料集涉及以下資料量:
- 交易 – 160 MB 分佈在大約 60 個壓縮的 Parquet 檔案中
- BBO – 2.4 TB 分佈在大約 300 個壓縮 Parquet 檔案中
- NBBO – 2.8 TB 分佈在大約 200 個壓縮 Parquet 檔案中
分析概覽
分析 OPRA 報價歷史資料以進行交易成本分析 (TCA) 涉及仔細審查特定交易事件的市場報價和交易。我們使用以下指標作為本研究的一部分:
- 報價點差 (QS) – 計算為 BBO 賣價和 BBO 買價之間的差額
- 有效價差 (ES) – 計算為交易價格與 BBO 中點之間的差額(BBO 買價 +(BBO 賣價 – BBO 買價)/2)
- 有效/報價價差 (EQF) – 計算公式為 (ES / QS) * 100
我們在交易前以及交易後的四個時間間隔(交易後、1 秒、10 秒和 60 秒)計算這些點差。
為 Apache Spark 配置 Athena
若要為 Apache Spark 設定 Athena,請完成下列步驟:
- 在 Athena 控制台上,在 開始, 選擇 使用 PySpark 和 Spark SQL 分析數據.
- 如果這是您第一次使用 Athena Spark,請選擇 創建工作組.

- 為 工作組名稱¸ 輸入工作小組的名稱,例如
tca-analysis.
- 在 分析引擎 部分,選擇 Apache Spark.
- 在 附加配置 部分,您可以選擇 使用默認值 或提供自訂 AWS身份和訪問管理 (IAM) 角色和計算結果的 Amazon S3 位置。
- 選擇 創建工作組.
- 建立工作群組後,導覽至 筆記本 標籤並選擇 創建筆記本.
- 輸入筆記本的名稱,例如
tca-analysis-with-tick-history.
- 選擇 創建 創建你的筆記本。
啟動你的筆記本
如果您已經建立了 Spark 工作小組,請選擇 啟動筆記本編輯器 下 開始.
建立筆記本後,您將被重定向到互動筆記本編輯器。

現在我們可以將以下程式碼新增到我們的筆記本中並運行。
創建分析
完成以下步驟來建立分析:
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
bbo_quote = spark.read.parquet(f"s3://<bucket>/mt=bbo_quote/f=opra/dt=2023-05-17/*")
bbo_quote.createOrReplaceTempView("bbo_quote")
nbbo_quote = spark.read.parquet(f"s3://<bucket>/mt=nbbo_quote/f=opra/dt=2023-05-17/*")
nbbo_quote.createOrReplaceTempView("nbbo_quote")
trades = spark.read.parquet(f"s3://<bucket>/mt=trade/f=opra/dt=2023-05-17/29_1.parquet")
trades.createOrReplaceTempView("trades")
filtered_trades = spark.sql("select Product, Price,Quantity, ReceiptTimestamp, MarketParticipant from trades")
我們得到以下輸出:
+---------------------+---------------------+---------------------+-------------------+-----------------+
|Product |Price |Quantity |ReceiptTimestamp |MarketParticipant|
+---------------------+---------------------+---------------------+-------------------+-----------------+
|QQQ 230518C00329000|1.1700000000000000000|10.0000000000000000000|1684338565538021907,NYSEArca|
|QQQ 230518C00329000|1.1700000000000000000|20.0000000000000000000|1684338576071397557,NASDAQOMXPHLX|
|QQQ 230518C00329000|1.1600000000000000000|1.0000000000000000000|1684338579104713924,ISE|
|QQQ 230518C00329000|1.1400000000000000000|1.0000000000000000000|1684338580263307057,NASDAQOMXBX_Options|
|QQQ 230518C00329000|1.1200000000000000000|1.0000000000000000000|1684338581025332599,ISE|
+---------------------+---------------------+---------------------+-------------------+-----------------+
我們使用突出顯示的未來交易資訊來表示交易產品 (tp)、交易價格 (tpr) 和交易時間 (tt)。
def calculate_es_qs_eqf(df, trade_price):
df['BidPrice'] = df['BidPrice'].astype('double')
df['AskPrice'] = df['AskPrice'].astype('double')
df["ES"] = ((df["AskPrice"]-df["BidPrice"])/2) - trade_price
df["QS"] = df["AskPrice"]-df["BidPrice"]
df["EQF"] = (df["ES"]/df["QS"])*100
return df
def get_trade_before_n_seconds(trade_time, df, seconds=0, groupby_col = None):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] < nseconds].groupby(groupby_col).last()
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
ret_df = ret_df.reset_index()
return ret_df
def get_trade_after_n_seconds(trade_time, df, seconds=0, groupby_col = None):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] > nseconds].groupby(groupby_col).first()
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
ret_df = ret_df.reset_index()
return ret_df
def get_nbbo_trade_before_n_seconds(trade_time, df, seconds=0):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] < nseconds].iloc[-1:]
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
return ret_df
def get_nbbo_trade_after_n_seconds(trade_time, df, seconds=0):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] > nseconds].iloc[:1]
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
return ret_df
- 在以下函數中,我們建立包含交易前後所有報價的資料集。 Athena Spark 會自動決定要啟動多少個 DPU 來處理我們的資料集。
def get_tca_analysis_via_df_single_query(trade_product, trade_price, trade_time):
# BBO quotes
bbos = spark.sql(f"SELECT Product, ReceiptTimestamp, AskPrice, BidPrice, MarketParticipant FROM bbo_quote where Product = '{trade_product}';")
bbos = bbos.toPandas()
bbo_just_before = get_trade_before_n_seconds(trade_time, bbos, seconds=0, groupby_col='MarketParticipant')
bbo_just_after = get_trade_after_n_seconds(trade_time, bbos, seconds=0, groupby_col='MarketParticipant')
bbo_1s_after = get_trade_after_n_seconds(trade_time, bbos, seconds=1, groupby_col='MarketParticipant')
bbo_10s_after = get_trade_after_n_seconds(trade_time, bbos, seconds=10, groupby_col='MarketParticipant')
bbo_60s_after = get_trade_after_n_seconds(trade_time, bbos, seconds=60, groupby_col='MarketParticipant')
all_bbos = pd.concat([bbo_just_before, bbo_just_after, bbo_1s_after, bbo_10s_after, bbo_60s_after], ignore_index=True, sort=False)
bbos_calculated = calculate_es_qs_eqf(all_bbos, trade_price)
#NBBO quotes
nbbos = spark.sql(f"SELECT Product, ReceiptTimestamp, AskPrice, BidPrice, BestBidParticipant, BestAskParticipant FROM nbbo_quote where Product = '{trade_product}';")
nbbos = nbbos.toPandas()
nbbo_just_before = get_nbbo_trade_before_n_seconds(trade_time,nbbos, seconds=0)
nbbo_just_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=0)
nbbo_1s_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=1)
nbbo_10s_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=10)
nbbo_60s_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=60)
all_nbbos = pd.concat([nbbo_just_before, nbbo_just_after, nbbo_1s_after, nbbo_10s_after, nbbo_60s_after], ignore_index=True, sort=False)
nbbos_calculated = calculate_es_qs_eqf(all_nbbos, trade_price)
calc = pd.concat([bbos_calculated, nbbos_calculated], ignore_index=True, sort=False)
return calc
- 現在讓我們使用所選交易的資訊來呼叫 TCA 分析函數:
tp = "QQQ 230518C00329000"
tpr = 1.16
tt = 1684338579104713924
c = get_tca_analysis_via_df_single_query(tp, tpr, tt)
視覺化分析結果
現在讓我們建立用於視覺化的資料框。每個資料框包含每個資料來源的五個時間間隔之一的報價(BBO、NBBO):
bbo = c[c['MarketParticipant'].isin(['BBO'])]
bbo_bef = bbo[bbo['ReceiptTimestamp'] < tt]
bbo_aft_0 = bbo[bbo['ReceiptTimestamp'].between(tt,tt+1000000000)]
bbo_aft_1 = bbo[bbo['ReceiptTimestamp'].between(tt+1000000000,tt+10000000000)]
bbo_aft_10 = bbo[bbo['ReceiptTimestamp'].between(tt+10000000000,tt+60000000000)]
bbo_aft_60 = bbo[bbo['ReceiptTimestamp'] > (tt+60000000000)]
nbbo = c[~c['MarketParticipant'].isin(['BBO'])]
nbbo_bef = nbbo[nbbo['ReceiptTimestamp'] < tt]
nbbo_aft_0 = nbbo[nbbo['ReceiptTimestamp'].between(tt,tt+1000000000)]
nbbo_aft_1 = nbbo[nbbo['ReceiptTimestamp'].between(tt+1000000000,tt+10000000000)]
nbbo_aft_10 = nbbo[nbbo['ReceiptTimestamp'].between(tt+10000000000,tt+60000000000)]
nbbo_aft_60 = nbbo[nbbo['ReceiptTimestamp'] > (tt+60000000000)]
在以下部分中,我們提供範例程式碼來建立不同的視覺化效果。
交易前繪製 QS 和 NBBO
使用以下程式碼繪製交易前的報價點差和 NBBO:
fig = px.bar(title="Quoted Spread Before The Trade",
x=bbo_bef.MarketParticipant,
y=bbo_bef['QS'],
labels={'x': 'Market', 'y':'Quoted Spread'})
fig.add_hline(y=nbbo_bef.iloc[0]['QS'],
line_width=1, line_dash="dash", line_color="red",
annotation_text="NBBO", annotation_font_color="red")
%plotly fig

繪製每個市場的 QS 和交易後的 NBBO
使用以下程式碼在交易後立即繪製每個市場和 NBBO 的報價點差:
fig = px.bar(title="Quoted Spread After The Trade",
x=bbo_aft_0.MarketParticipant,
y=bbo_aft_0['QS'],
labels={'x': 'Market', 'y':'Quoted Spread'})
fig.add_hline(
y=nbbo_aft_0.iloc[0]['QS'],
line_width=1, line_dash="dash", line_color="red",
annotation_text="NBBO", annotation_font_color="red")
%plotly fig

繪製 BBO 每個時間間隔和每個市場的 QS
使用以下程式碼繪製 BBO 每個時間間隔和每個市場的報價點差:
fig = go.Figure(data=[
go.Bar(name="before trade", x=bbo_bef.MarketParticipant.unique(), y=bbo_bef['QS']),
go.Bar(name="0s after trade", x=bbo_aft_0.MarketParticipant.unique(), y=bbo_aft_0['QS']),
go.Bar(name="1s after trade", x=bbo_aft_1.MarketParticipant.unique(), y=bbo_aft_1['QS']),
go.Bar(name="10s after trade", x=bbo_aft_10.MarketParticipant.unique(), y=bbo_aft_10['QS']),
go.Bar(name="60s after trade", x=bbo_aft_60.MarketParticipant.unique(), y=bbo_aft_60['QS'])])
fig.update_layout(barmode='group',title="BBO Quoted Spread Per Market/TimeFrame",
xaxis={'title':'Market'},
yaxis={'title':'Quoted Spread'})
%plotly fig

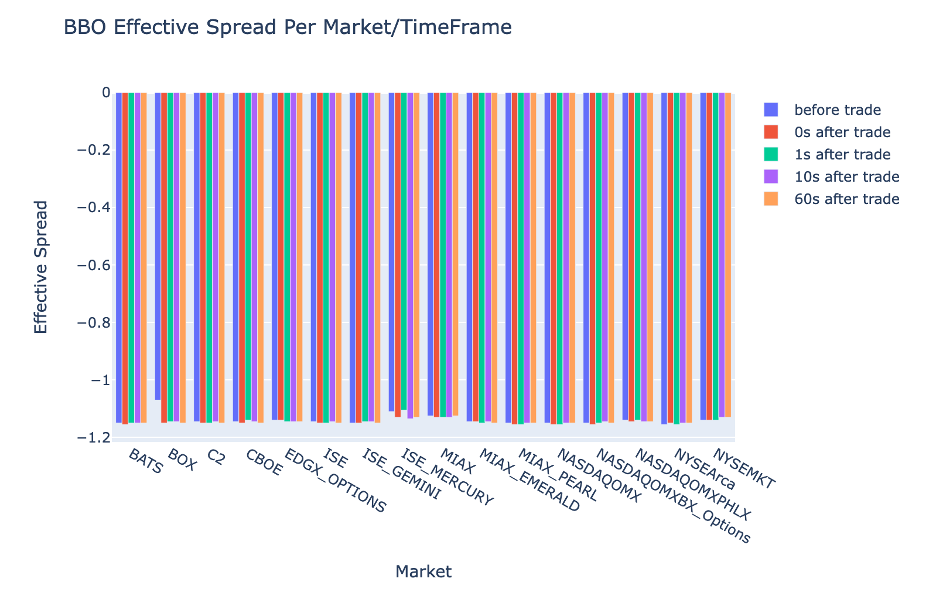
繪製每個時間間隔的 ES 和 BBO 的市場
使用以下程式碼繪製 BBO 每個時間間隔和市場的有效點差:
fig = go.Figure(data=[
go.Bar(name="before trade", x=bbo_bef.MarketParticipant.unique(), y=bbo_bef['ES']),
go.Bar(name="0s after trade", x=bbo_aft_0.MarketParticipant.unique(), y=bbo_aft_0['ES']),
go.Bar(name="1s after trade", x=bbo_aft_1.MarketParticipant.unique(), y=bbo_aft_1['ES']),
go.Bar(name="10s after trade", x=bbo_aft_10.MarketParticipant.unique(), y=bbo_aft_10['ES']),
go.Bar(name="60s after trade", x=bbo_aft_60.MarketParticipant.unique(), y=bbo_aft_60['ES'])])
fig.update_layout(barmode='group',title="BBO Effective Spread Per Market/TimeFrame",
xaxis={'title':'Market'},
yaxis={'title':'Effective Spread'})
%plotly fig
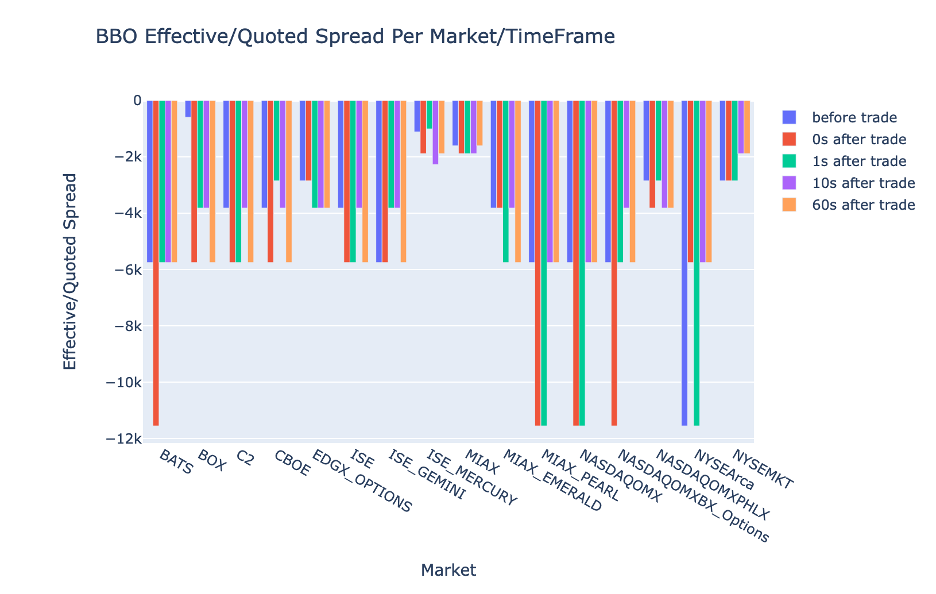
繪製 BBO 每個時間間隔和市場的 EQF
使用以下程式碼繪製 BBO 每個時間間隔和市場的有效/報價點差:
fig = go.Figure(data=[
go.Bar(name="before trade", x=bbo_bef.MarketParticipant.unique(), y=bbo_bef['EQF']),
go.Bar(name="0s after trade", x=bbo_aft_0.MarketParticipant.unique(), y=bbo_aft_0['EQF']),
go.Bar(name="1s after trade", x=bbo_aft_1.MarketParticipant.unique(), y=bbo_aft_1['EQF']),
go.Bar(name="10s after trade", x=bbo_aft_10.MarketParticipant.unique(), y=bbo_aft_10['EQF']),
go.Bar(name="60s after trade", x=bbo_aft_60.MarketParticipant.unique(), y=bbo_aft_60['EQF'])])
fig.update_layout(barmode='group',title="BBO Effective/Quoted Spread Per Market/TimeFrame",
xaxis={'title':'Market'},
yaxis={'title':'Effective/Quoted Spread'})
%plotly fig
Athena Spark 運算效能
當您執行程式碼區塊時,Athena Spark 會自動決定完成運算需要多少 DPU。在最後一個程式碼區塊中,我們調用 tca_analysis 函數中,我們實際上是在指示 Spark 處理數據,然後將生成的 Spark 資料幀轉換為 Pandas 資料幀。這是分析中最密集的處理部分,當 Athena Spark 運行此區塊時,它會顯示進度條、經過的時間以及目前有多少 DPU 正在處理資料。例如,在以下計算中,Athena Spark 使用 18 個 DPU。

配置 Athena Spark 筆記本時,您可以選擇設定它可以使用的最大 DPU 數量。預設值為 20 個 DPU,但我們使用 10、20 和 40 個 DPU 測試了此計算,以演示 Athena Spark 如何自動擴展以運行我們的分析。我們觀察到,Athena Spark 線性擴展,當筆記本配置最多15 個DPU 時,耗時21 分10 秒;當筆記本配置8 個DPU 時,耗時23 分20 秒;當筆記本配置最大DPU 時,耗時4分44 秒。配置40個DPU。由於 Athena Spark 根據 DPU 使用情況進行收費,以每秒為粒度,因此這些計算的成本類似,但如果您設定更高的最大 DPU 值,Athena Spark 可以更快地傳回分析結果。有關 Athena Spark 定價的更多詳細信息,請點擊 点击這裡.
結論
在這篇文章中,我們示範如何使用來自 LSEG 的 Tick History-PCAP 的高保真 OPRA 數據,透過 Athena Spark 執行交易成本分析。及時提供 OPRA 數據,輔以適用於 Amazon S3 的 AWS Data Exchange 的可訪問性創新,可以策略性地縮短那些希望為關鍵交易決策創建可行見解的公司的分析時間。 OPRA 每天產生約 7 TB 的標準化 Parquet 數據,管理基礎設施以提供基於 OPRA 數據的分析具有挑戰性。
Athena 在處理 Tick History – PCAP for OPRA 資料的大規模資料處理方面具有可擴展性,使其成為在 AWS 中尋求快速且可擴展的分析解決方案的組織的絕佳選擇。這篇文章展示了 AWS 生態系統和 Tick History-PCAP 資料之間的無縫交互,以及金融機構如何利用這種協同作用來推動關鍵交易和投資策略的資料驅動決策。
關於作者
 普拉莫德·納亞克 是 LSEG 低延遲團隊的產品管理總監。 Pramod 在金融科技產業擁有超過 10 年的經驗,專注於軟體開發、分析和資料管理。 Pramod 是一名前軟體工程師,對市場數據和量化交易充滿熱情。
普拉莫德·納亞克 是 LSEG 低延遲團隊的產品管理總監。 Pramod 在金融科技產業擁有超過 10 年的經驗,專注於軟體開發、分析和資料管理。 Pramod 是一名前軟體工程師,對市場數據和量化交易充滿熱情。
 拉克希米·坎特·曼內姆 是 LSEG 低延遲組的產品經理。他專注於低延遲市場數據產業的數據和平台產品。 LakshmiKanth 幫助客戶建立滿足其市場數據需求的最佳解決方案。
拉克希米·坎特·曼內姆 是 LSEG 低延遲組的產品經理。他專注於低延遲市場數據產業的數據和平台產品。 LakshmiKanth 幫助客戶建立滿足其市場數據需求的最佳解決方案。
 維韋克·阿加瓦爾 是 LSEG 低延遲小組的高級資料工程師。 Vivek 致力於開發和維護資料管道,以處理和交付捕獲的市場資料來源和參考資料來源。
維韋克·阿加瓦爾 是 LSEG 低延遲小組的高級資料工程師。 Vivek 致力於開發和維護資料管道,以處理和交付捕獲的市場資料來源和參考資料來源。
 阿爾克特·梅穆沙吉 是 AWS 金融服務市場開發團隊的首席架構師。 Alket 負責技術策略,與合作夥伴和客戶合作,將最嚴苛的資本市場工作負載部署到 AWS 雲端。
阿爾克特·梅穆沙吉 是 AWS 金融服務市場開發團隊的首席架構師。 Alket 負責技術策略,與合作夥伴和客戶合作,將最嚴苛的資本市場工作負載部署到 AWS 雲端。

