簡介
隨著大型語言模式的出現(法學碩士),它們已經滲透到許多應用中,取代了較小的變壓器模型,例如 BERT 或許多基於規則的模型 自然語言處理(NLP) 任務。法學碩士用途廣泛,由於其廣泛的預訓練,能夠處理文本分類、摘要、情感分析和主題建模等任務。然而,儘管法學碩士擁有廣泛的能力,但與規模較小的同行相比,法學碩士在準確性方面往往落後。
為了解決這一限制,一種有效的策略是對預先訓練的法學碩士進行微調,使其在特定任務中表現出色。微調大型模型經常會產生最佳結果。值得注意的是,Google的 Gemini 以及其他大型模型現在為用戶提供了使用自己的訓練資料來微調這些模型的能力。在本指南中,我們將逐步介紹針對特定問題微調 Gemini 模型的流程,以及如何使用 HuggingFace 的資源來整理資料集。
學習目標
- 了解 Google Gemini 模型的效能。
- 了解 Gemini 模型微調的資料集準備。
- 配置 Gemini 模型微調的參數。
- 監控微調進度和指標。
- 在新數據上測試 Gemini 模型的效能。
- 探索 PII 屏蔽的 Gemini 模型應用。

這篇文章是作為 數據科學博客馬拉松。
目錄
谷歌宣布調整 Gemini
Gemini 有兩個版本:Pro 和 Ultra。 Pro版中,有Gemini 1.0 Pro和全新的Gemini 1.5 Pro。這些來自 Google 的模型與 ChatGPT 和 Claude 等其他先進模型競爭。每個人都可以透過 AI Studio UI 和免費 API 輕鬆存取 Gemini 模型。
近日,Google宣布了 Gemini 機型的一項新功能:微調。這意味著任何人都可以調整 Gemini 模型以滿足自己的需求。您可以使用 AI Studio UI 或其 API 來微調 Gemini。微調是指我們將自己的資料提供給 Gemini,以便它能夠以我們想要的方式運作。 Google 使用參數高效調整 (PET) 來快速調整 Gemini 模型的幾個重要部分,使其適用於不同的任務。
準備數據集
在開始微調模型之前,我們將從安裝必要的程式庫開始。順便說一句,我們將與 Colab 合作編寫本指南。
安裝必要的庫
以下是入門所需的 Python 模組:
!pip install -q google-generativeai datasets- 谷歌生成ai: 它是 Google 團隊的一個庫,可讓我們存取 Google Gemini 模型。可以使用同一函式庫來微調 Gemini 模型。
- 數據集: 這是 HuggingFace 的一個函式庫,我們可以使用它從 HuggingFace 中心下載各種資料集。我們將使用該資料集庫下載 PII(個人識別資訊)資料集並將其提供給 Gemini 模型進行微調。
執行以下程式碼將在我們的 Python 環境中下載並安裝 Google Generative AI 和資料集庫。
設定 OAuth
在下一步中,我們需要為本教程設定 OAuth。 OAuth 是必要的,這樣我們傳送給 Google 微調 Gemini 的資料是安全的。若要取得 OAuth,請按照此操作 鏈接。建立 OAuth 後下載 client_secret.json。將 client_secrent.json 的內容儲存在 Colab Secrets 中的 CLIENT_SECRET 名稱下,然後執行以下程式碼:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'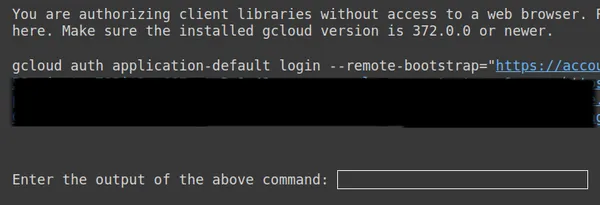
複製上面的第二個連結並將其貼上到 CMD 本地系統中並運行它。
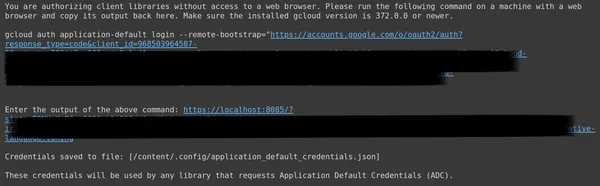
然後,您將被重新導向至 Web 瀏覽器,以使用您設定 OAuth 的電子郵件登入。登入後,在 CMD 中,我們得到一個 URL,現在將該 URL 貼到第三行,然後按 Enter。現在我們已經完成了與 Google 的 OAuth 操作。
下載並準備資料集
首先,我們將首先下載我們將使用的資料集,以將其微調到 Gemini 模型。為此,我們使用資料集庫。其代碼為:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- 這裡我們先從資料集庫匯入 load_dataset 函數。
- 對於這個 load_dataset() 函數,我們傳入我們想要下載的資料集。在我們的範例中,它是“ai4privacy/pii-masking-200k”,其中包含 200k 行屏蔽和未屏蔽的 PII 資料。
- 然後我們列印資料集。

我們看到數據集包含 209261 行訓練數據,沒有測試數據。每行包含不同的列,例如 masked_text、unmasked_text、privacy_mask、span_labels、bio_labels 和 tokenized_text。樣本資料如下:
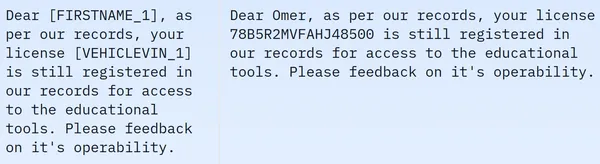
在顯示的圖像中,我們觀察到屏蔽和未屏蔽的句子。具體來說,在屏蔽句子中,某些元素(例如人名和車號)被特定標籤掩蓋。為了準備資料以進行進一步處理,我們現在需要進行一些資料預處理。以下是此預處理步驟的程式碼:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- 首先,我們從資料集中取出訓練部分的資料(我們下載的資料集只包含訓練部分)。然後我們將其轉換為 Pandas Dataframe。
- 這裡為了微調 Gemini,我們只需要 unmasked_text 和 masked_text 列,所以我們只取這兩個。
- 然後我們取得前 2000 行資料。我們將使用前 2000 行來微調 Gemini。
- 然後,我們將列名稱從 unmasked_text 和 masked_text 編輯為輸入列和輸出列,因為當我們將包含 PII(個人識別資訊)的輸入文字資料提供給 Gemini 模型時,我們期望它會產生輸出文字數據,其中 PII被屏蔽了。
格式化資料以微調 Gemini
下一步是格式化我們的資料。為此,我們將建立一個格式化程式函數:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- 這裡我們定義了一個函數格式化程序,它接受 x,我們的資料行。
- 然後它定義一個帶有 f 字串的變數文本,我們在其中提供上下文,後面是來自資料幀的輸入資料。
- 最後,我們返回格式化的文字。
- 最後一行將格式化程式函數套用到我們透過 apply() 函數所建立的資料幀的每一行。
- axis=1 表示函數將套用於資料幀的每一行。
運行程式碼將建立一個名為「train」的新列,其中包含每行(包括輸入欄位)的格式化文字。讓我們嘗試觀察資料幀的元素之一:
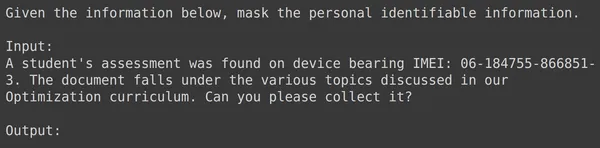
將數據劃分為訓練集和測試集
我們可以看到,text_input 包含數據,其中每行包含數據開始時的上下文,告知要屏蔽 PII,然後是輸入數據,最後是單字輸出,模型需要在其中產生輸出。現在我們需要將資料幀分為訓練和測試:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- 我們首先過濾數據,使其包含 text_input 和輸出列。這些是 Google Fine-Tune 庫期望訓練 Gemini 的列
- Gemini 將取得 text_input 並學習編寫輸出
- 我們將資料分割為 df_train,其中包含 1900 行原始數據
- 和一個 df_test 包含大約 100 行原始數據
- 我們在 df_train 上訓練 Gemini,然後透過從 df_test 中取得 3-4 個範例來測試它,以查看它產生的輸出
因此運行程式碼將過濾我們的資料並將其分為訓練和測試。最後,我們完成了資料預處理部分。
微調雙子座模型
請依照以下步驟微調您的雙子座模型:
設定調諧參數
在本節中,我們將介紹調整 Gemini 模型的過程。為此,我們將使用以下程式碼:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- 匯入 google.generativeai 庫:該庫提供用於與 Google 產生 AI 服務互動的 API。
- 提供基本模型名稱:這是我們想要用作微調模型起點的預訓練模型的名稱。目前,唯一可調整的模型是 models/gemini-1.0-pro-001,我們將其儲存在變數 bm_name 中。
- 提供微調模型的名稱:這是我們要為微調模型指定的名稱。這裡我們將其命名為「pii-model」。
- 建立調優模型操作物件:此物件表示建立調優模型的操作。它需要以下參數:
- source_model:基礎模型的名稱
- Training_data:我們剛剛創建的微調模型的訓練數據,即 df_train
- id:微調模型的 ID/名稱
- epoch_count:訓練時期的數量。對於這個例子,我們將使用 2 個紀元
- batch_size:訓練的批次大小。對於本例,我們將使用值 4
- Learning_rate:訓練的學習率。這裡我們為其提供的值為 0.001
- 我們已經完成了參數的提供。運行此程式碼將創建一個經過微調的模型物件。現在我們需要開始訓練雙子座法學碩士的過程。為此,我們使用以下程式碼。
我們已經完成參數設定。運行此程式碼將建立一個調整後的模型物件。現在我們需要開始訓練雙子座法學碩士的過程。為此,我們使用以下程式碼:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)建立調整模型
在這裡,我們使用 genai 庫中的 .get_tuned_model() 函數,傳遞我們定義的模型名稱,開始訓練過程。然後,我們列印模型,如下圖所示:
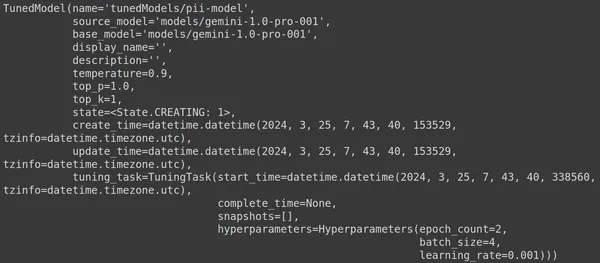
此模型的類型為 TunedModel。在這裡我們可以觀察我們定義的模型的不同參數。他們是:
- name:此變數包含我們為調整後的模型提供的名稱
- source_model:這是我們正在微調的來源模型,在我們的範例中是 models/gemini-1.0-pro
- base_model:這又是我們正在微調的基本模型,在我們的範例中是 models/Gemini-1.0-pro。基礎模型甚至可以是之前微調過的模型。在這裡我們對兩者都是一樣的
- display_name:調整模型的顯示名稱
- 描述:它包含我們模型的任何描述以及模型的內容
- 溫度:數值越高,大語言模型產生的答案越有創意。這裡預設為0.9
- top_p:定義產生文字時標記選擇的最高機率。 top_p 越多,選擇的標記就越多,也就是從更大的資料樣本中選擇標記
- top_k:它指示在每一步中從 k 個最可能的下一個標記中進行取樣。這裡top_k為1,這意味著最有可能的下一個標記就是將被選擇的標記,即機率最高的標記將始終被選擇
- state:狀態正在創建,表示模型目前正在微調
- create_time:模型建立的時間
- update_time:模型最後一次調優的時間
- tuning_task:包含我們為調整定義的參數,其中包括溫度、時期和批次大小
啟動培訓流程
我們甚至可以透過以下程式碼來取得調整後模型的狀態和元資料:
print(operation.metadata)
這裡顯示的是總步數,即 950 步,這是可以預測的。因為在我們的範例中,我們有 1900 行訓練資料。在每個步驟中,我們接收一批 4 行,即 4 行,因此對於一個完整的 epoch,我們有 1900/4,即 475 個步驟。我們設定了 2 個 epoch 進行訓練,這意味著 2*475 = 950 個步驟。
監控培訓進度
下面的程式碼建立一個狀態欄,告知訓練已完成的百分比以及完成整個訓練過程所需的時間:
import time
for status in operation.wait_bar():
time.sleep(30)
上面的程式碼創建了一個進度條,完成後意味著我們的調整過程已經結束。
可視化訓練表現
操作對象甚至包含訓練的快照。它將包含評估指標,例如每個時期的mean_loss。我們可以用下面的程式碼來視覺化這一點:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- 這裡我們從 operation.result() 中得到最終的調整後的模型
- 當我們訓練模型時,模型會定期拍攝快照。這些快照包含諸如mean_loss之類的資料。因此,我們透過呼叫 model.tuning_task.snapshots 來提取調整模型的快照
- 我們透過將快照傳遞給 pd.DataFrame 並將它們儲存在 snapshots 變數中,從這些快照建立一個資料幀
- 最後,我們根據提取的快照資料創建線圖
運行程式碼將得到下圖:
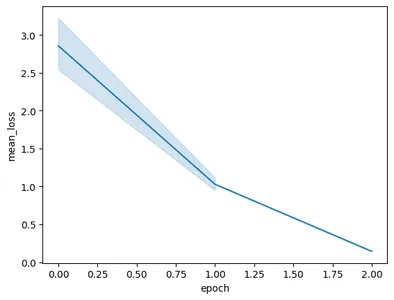
在這張圖中,我們可以看到,在短短 3 個 epoch 的訓練中,我們就將損失從 0.5 減少到了 2 以下。最後,我們完成了 Gemini 模型的訓練
測試微調的 Gemini 模型
在本節中,我們將在測試數據上測試我們的模型。現在,為了使用調整後的模型,我們使用以下程式碼:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')上面的程式碼將載入我們剛剛使用個人識別資訊資料訓練的調整後的模型。現在我們將使用我們擱置的測試資料中的一些範例來測試該模型。為此,讓我們列印測試集中的隨機 text_input 及其對應的輸出:
print(df_test['text_input'][1900])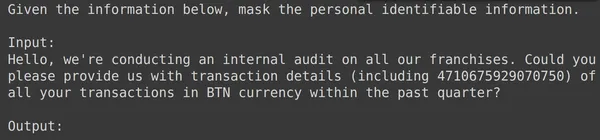
df_test['output'][1900]
上面我們可以看到一個隨機的 text_input 和從測試集中取得的輸出。現在我們將這個 text_input 傳遞給模型並觀察產生的輸出:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
我們看到該模型成功地屏蔽了給定 text_input 的個人識別訊息,並且模型生成的輸出與測試集的輸出完全匹配。現在讓我們再舉幾個例子來嘗試:
print(df_test['text_input'][1969])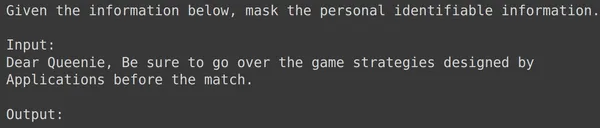
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])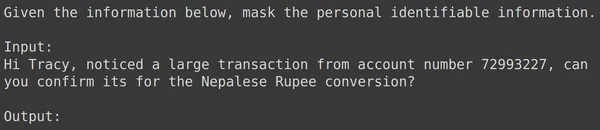
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])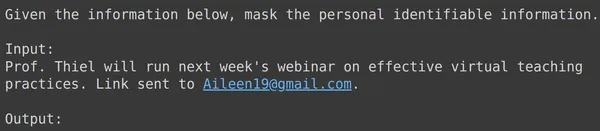
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
對於上面的所有範例,我們看到經過微調的模型性能良好。該模型能夠從給定的訓練資料中學習並正確應用屏蔽來隱藏敏感的個人資訊。因此,我們從頭到尾都看到瞭如何創建用於微調的資料集以及如何在資料集上微調 Gemini 模型,我們看到的結果對於微調模型來說非常有希望
結論
總而言之,本指南提供了有關微調 Google 旗艦 Gemini 模型以屏蔽個人識別資訊 (PII) 的全面演練。我們首先探索了 Google 關於 Gemini 模型微調功能的部落格文章,強調了微調這些模型以實現特定於任務的準確性的必要性。透過指南中概述的實際步驟,包括資料集準備、微調 Gemini 模型以及測試其效能,使用者可以利用大型語言模型的強大功能來執行 PII 屏蔽任務。
以下是本指南的主要要點:
- Gemini 模型提供了強大的微調庫,允許使用者透過參數高效調整 (PET) 對其進行自訂以適應特定任務,其中包括 PII 屏蔽
- 資料集準備是至關重要的一步,包括安裝必要的模組、啟動OAuth以確保資料安全以及格式化資料以進行訓練
- 微調過程包括提供基本模型、曆元計數、批量大小和學習率等參數,以在準備好的資料集上訓練 Gemini 模型
- 透過狀態更新和指標視覺化(例如每個時期的平均損失)可以促進監控訓練進度
- 在單獨的測試資料集上測試微調模型,驗證其在準確屏蔽 PII 方面的效能,同時保持資料的完整性
- 提供的範例展示了經過微調的 Gemini 模型在成功屏蔽敏感個人資訊方面的有效性,這表明在實際應用中取得了有希望的結果
常見問題
A. 參數高效調優(PET)是微調技術之一,僅微調模型的一小部分參數。 Google 使用它來快速微調 Gemini 模型中的重要層。它有效地使模型適應用戶的數據,提高其特定任務的性能
答:調整 Gemini 模型涉及提供基本模型名稱、Epoch 計數、批次大小和學習率等參數。這些參數會影響訓練過程並最終影響模型的性能
A. 使用者可以透過狀態更新、每輪平均損失等指標的視覺化以及觀察訓練過程的快照來監控微調的 Gemini 模型的訓練進度
A. 在微調 Gemini 模型之前,使用者需要安裝必要的函式庫,例如 google-generativeai 和 datasets。此外,啟動 OAuth 以確保資料安全並格式化資料集以進行訓練也是重要的步驟
A. 經過微調的 Gemini 模型可以應用於需要 PII 屏蔽的不同領域,例如資料匿名化、NLP 應用程式中的隱私保護以及遵守 GDPR 等資料保護法規
本文所示的媒體不屬於 Analytics Vidhya 所有,其使用由作者自行決定。

