大型语言模型(LLM)是人工智能革命背后的驱动力,但游戏的情节发生了重大转折。 Databricks DBRX,一个突破性的开源 LLM,是为了挑战现状。 DBRX 超越现有模型并与行业领导者展开激烈竞争,拥有卓越的性能和效率。深入探讨法学硕士的世界,探索 DBRX 如何重写规则手册,让您一睹法学硕士令人兴奋的未来 自然语言处理。

目录
了解法学硕士和开源法学硕士
大型语言模型 (LLM) 是先进的自然语言处理模型,可以理解和生成类似人类的文本。这些模型在语言理解、编程和数学等各种应用中变得越来越重要。
开源法学硕士在自然语言处理技术的发展和进步中发挥着至关重要的作用。它们为开放社区和企业提供尖端语言模型的访问权限,使他们能够针对特定应用程序和用例构建和定制模型。
什么是 Databricks DBRX?
Databricks DBRX 是 Databricks 开发的开放式通用大型语言模型 (LLM)。它为已建立的开放法学硕士树立了新的最先进水平,超越了 GPT-3.5 并与 Gemini 1.0 Pro 相媲美。 DBRX 在各种基准测试中表现出色,包括语言理解、编程和数学。它使用下一个令牌预测和细粒度专家混合 (MoE) 架构进行训练,从而显着提高训练和推理性能。
该模型可通过 API 供 Databricks 客户使用,并且可以进行预训练或微调。其训练和推理性能凸显其效率,超越其他已建立的模型,同时大小约为同类模型的 40%。 DBRX 是 Databricks 下一代 GenAI 产品的关键组件,旨在增强企业和开放社区的能力。
Databricks DBRX 的 MoE 架构
Databricks 的 DBRX 作为开源通用大型语言模型 (LLM) 脱颖而出,具有独特的效率架构。以下是其主要功能的详细介绍:
- 细粒度专家组合 (MoE): 这种创新架构总共使用 132 亿个参数,每个输入仅包含 36 亿个有效参数。与其他模型相比,这种对主动参数的关注显着提高了效率。
- 专家力量: DBRX 聘请了 16 名专家,并为每项任务选择 4 名专家,提供了惊人的 65 倍可能的专家组合,从而实现了卓越的模型质量。
- 先进技术: 该模型利用旋转位置编码 (RoPE)、门控线性单元 (GLU) 和分组查询注意力 (GQA) 等尖端技术,进一步提高其性能。
- 效率冠军: DBRX 的推理速度高达 LLaMA2-70B 的两倍。此外,它还具有紧凑的尺寸,总参数数和活动参数数均比 Grok-40 小约 1%。
- 真实世界的表现: 当托管在 Mosaic AI Model Serving 上时,DBRX 可提供每用户每秒高达 150 个令牌的文本生成速度。
- 培训效率领先者: DBRX 的训练过程证明了计算效率的显着提高。与训练相同水平的最终质量的密集模型相比,它大约需要一半的 FLOP(浮点运算)。
训练DBRX
培训像 DBRX 这样强大的法学硕士并非没有障碍。下面详细介绍一下训练过程:
- 面临的挑战: 开发像 DBRX 这样的混合专家模型存在重大的科学和性能障碍。 Databricks 需要克服这些挑战,创建一个能够有效训练 DBRX 级模型的强大管道。
- 效率突破: DBRX 的训练过程在计算效率方面取得了显着的提高。以 DBRX MoE-B 为例,它是 DBRX 系列中较小的模型,与其他模型相比,在 Databricks LLM Gauntlet 上达到 1.7% 的分数所需的 FLOP(浮点运算)次数减少了 45.5 倍。
- 效率领导者: 这一成就凸显了 DBRX 训练过程的有效性。它将 DBRX 定位为开源模型中的领导者,甚至可以在 RAG 任务上与 GPT-3.5 Turbo 相媲美,同时拥有卓越的效率。
DBRX 与其他法学硕士

指标和结果
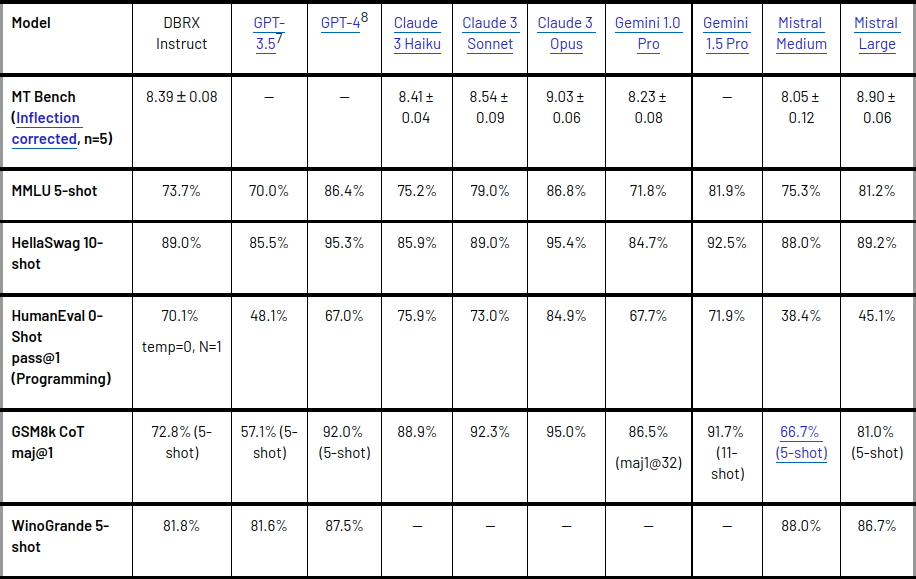
- DBRX 已针对语言理解任务上已建立的开源模型进行了衡量。
- 已经超越了GPT-3.5,与Gemini 1.0 Pro具有竞争力。
- 该模型已在各种基准测试中展示了其功能,包括复合基准测试、编程、数学和 MMLU。
- 它在标准基准测试中的表现优于所有聊天或指令微调模型,在 Hugging Face Open LLM Leaderboard 和 Databricks Model Gauntlet 等综合基准测试中得分最高。
- 此外,DBRX Instruct 在长上下文任务和 RAG 上表现出了卓越的性能,在所有上下文长度和序列的所有部分上都优于 GPT-3.5 Turbo。
与其他模型相比的优点和缺点
DBRX Instruct 展示了其在编程和数学方面的实力,在 HumanEval 和 GSM8k 等基准测试中得分高于其他开放模型。它还表现出了与 Gemini 1.0 Pro 和 Mistral Medium 竞争的性能,在多项基准测试中超越了 Gemini 1.0 Pro。然而,值得注意的是,模型质量和推理效率通常是矛盾的,虽然 DBRX 在质量方面表现出色,但较小的模型推理效率更高。尽管如此,DBRX 已被证明可以在模型质量和推理效率之间实现比密集模型通常实现的更好的权衡。
DBRX 的关键创新
DBRX 由 Databricks 开发,引入了多项关键创新,使其有别于现有的开源和专有模型。该模型采用细粒度专家混合 (MoE) 架构,共有 132B 个参数,其中 36B 对任何输入都有效。
这种架构使 DBRX 能够提供强大而高效的训练过程,在 SQL 等应用程序中超越了 GPT-3.5 Turbo 并挑战了 GPT-4 Turbo。此外,DBRX 聘请了 16 名专家并选择了 4 名,提供了 65 倍以上可能的专家组合,从而提高了模型质量。
该模型还结合了旋转位置编码 (RoPE)、门控线性单元 (GLU) 和分组查询注意 (GQA),从而实现了卓越的性能。
DBRX 相对于现有开源和专有模型的优势
与现有的开源和专有模型相比,DBRX 具有多种优势。它超越了 GPT-3.5,与 Gemini 1.0 Pro 具有竞争力,展示了其在各种基准测试中的能力,包括复合基准测试、编程、数学和 MMLU。
- 此外,DBRX Instruct(DBRX 的一种变体)在常识、常识推理、编程和数学推理方面优于 GPT-3.5。
- 它在长上下文任务中也表现出色,在所有上下文长度和序列的所有部分上都优于 GPT-3.5 Turbo。
- 此外,DBRX Instruct 与 Gemini 1.0 Pro 和 Mistral Medium 具有竞争力,在多项基准测试中超过了 Gemini 1.0 Pro。
该模型的训练和推理性能凸显了其效率,超越了其他已建立的模型,同时其规模约为同类模型的 40%。 DBRX 的细粒度 MoE 架构和训练过程已证明计算效率有显着提高,在相同的最终模型质量下,其 FLOP 效率比训练密集模型高出约 2 倍。
另请参阅: Claude 与 GPT:哪个是更好的 LLM?
结论
Databricks DBRX 凭借其创新的专家混合架构,超越了 GPT-3.5,并在语言理解方面与 Gemini 1.0 Pro 竞争。其细粒度的 MoE、先进的技术和卓越的计算效率使其成为企业和开放社区引人注目的解决方案,有望在自然语言处理领域取得突破性进展。在 DBRX 的引领下,法学硕士的未来更加光明。

