这篇文章是与 BigBasket 的 Santosh Waddi 和 Nanda Kishore Thatikonda 共同撰写的。
BigBasket 是印度最大的在线食品和杂货店。他们在多种电子商务渠道中运营,例如快速商务、分时段交付和每日订阅。您也可以从他们的实体店和自动售货机购买。他们提供 50,000 个品牌、超过 1,000 种产品,业务遍及 500 多个城镇。 BigBasket 为超过 10 万客户提供服务。
在这篇文章中,我们讨论 BigBasket 如何使用 亚马逊SageMaker 训练用于快速消费品 (FMCG) 产品识别的计算机视觉模型,这帮助他们减少了约 50% 的训练时间并节省了 20% 的成本。
客户挑战
如今,印度大多数超市和实体店都在收银台提供人工结账。这有两个问题:
- 随着规模的扩大,它需要额外的人力、重量标签以及对店内运营团队的重复培训。
- 在大多数商店中,收银柜台与称重柜台不同,这增加了顾客购买过程中的摩擦。顾客经常会丢失重量标签,必须返回称重柜台重新领取一张,然后才能继续结帐流程。
自助结账流程
BigBasket 在其实体店引入了人工智能驱动的结账系统,该系统使用摄像头来独特地区分商品。下图概述了结账流程。
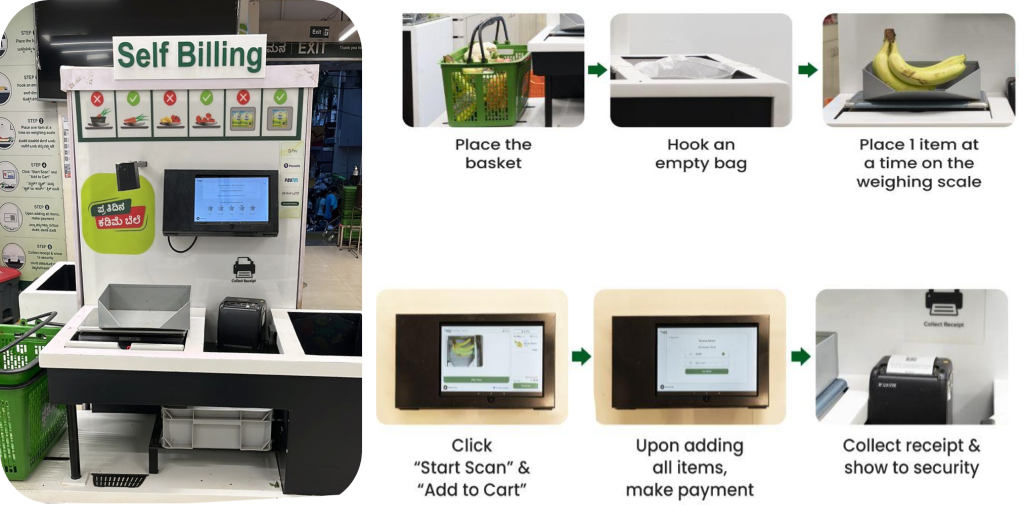
BigBasket 团队正在运行用于计算机视觉对象识别的开源内部 ML 算法,以支持其人工智能结账 新鲜 (实体)商店。我们在运营现有设置时面临以下挑战:
- 随着新产品的不断推出,计算机视觉模型需要不断融入新的产品信息。该系统需要处理超过 12,000 个库存单位 (SKU) 的大型目录,并且新的 SKU 以每月超过 600 个的速度不断添加。
- 为了跟上新产品的步伐,每个月都会使用最新的训练数据生成一个新模型。频繁训练模型以适应新产品既昂贵又耗时。
- BigBasket 还希望缩短培训周期时间以缩短上市时间。由于SKU的增加,模型所花费的时间呈线性增加,这影响了他们的上市时间,因为训练频率非常高并且花费了很长的时间。
- 用于模型训练的数据增强和手动管理完整的端到端训练周期增加了显着的开销。 BigBasket 在第三方平台上运行该程序,这产生了巨大的成本。
解决方案概述
我们建议 BigBasket 使用 SageMaker 重新构建其现有的 FMCG 产品检测和分类解决方案,以应对这些挑战。在转向全面生产之前,BigBasket 尝试在 SageMaker 上进行试点,以评估性能、成本和便利性指标。
他们的目标是微调现有的计算机视觉机器学习 (ML) 模型以进行 SKU 检测。我们使用了卷积神经网络(CNN)架构 残差网络152 用于图像分类。估计每个 SKU 包含约 300 张图像的庞大数据集用于模型训练,最终训练图像总数超过 4 万张。对于某些 SKU,我们增强了数据以涵盖更广泛的环境条件。
下图说明了解决方案体系结构。

完整的过程可以概括为以下高级步骤:
- 执行数据清理、注释和增强。
- 将数据存储在 亚马逊简单存储服务 (Amazon S3)存储桶。
- 使用 SageMaker 和 适用于Lustre的Amazon FSx 用于有效的数据增强。
- 将数据分为训练集、验证集和测试集。我们使用 FSx 进行 Lustre 和 亚马逊关系数据库服务 (Amazon RDS) 用于快速并行数据访问。
- 使用自定义 PyTorch Docker 容器包括其他开源库。
- 使用 SageMaker 分布式数据并行性 (SMDDP)用于加速分布式训练。
- 记录模型训练指标。
- 将最终模型复制到 S3 存储桶。
使用大篮子 SageMaker 笔记本 训练他们的 ML 模型,并能够轻松地将现有的开源 PyTorch 和其他开源依赖项移植到 SageMaker PyTorch 容器并无缝运行管道。这是 BigBasket 团队看到的第一个好处,因为几乎不需要对代码进行任何更改即可使其兼容在 SageMaker 环境上运行。
该模型网络由 ResNet 152 架构和全连接层组成。我们冻结了低级特征层并保留了通过 ImageNet 模型的迁移学习获得的权重。模型总参数为 66 万个,其中可训练参数为 23 万个。这种基于迁移学习的方法帮助他们在训练时使用更少的图像,并且还实现了更快的收敛并减少了总训练时间。
构建并训练模型 亚马逊SageMaker Studio 提供了一个集成开发环境 (IDE),其中包含准备、构建、训练和调整模型所需的一切。使用裁剪、旋转和翻转图像等技术增强训练数据有助于提高模型训练数据和模型准确性。
通过使用 SMDDP 库,模型训练速度加快了 50%,其中包括专为 AWS 基础设施设计的优化通信算法。为了提高模型训练和数据增强期间的数据读/写性能,我们使用 FSx for Lustre 来实现高性能吞吐量。
他们的起始训练数据大小超过 1.5 TB。我们用了两个 亚马逊弹性计算云 (Amazon EC2) p4d.24 大型实例 具有 8 个 GPU 和 40 GB GPU 内存。对于 SageMaker 分布式训练,实例需要位于同一 AWS 区域和可用区。此外,存储在 S3 存储桶中的训练数据需要位于同一可用区中。该架构还允许 BigBasket 更改为其他实例类型或向当前架构添加更多实例,以满足任何显着的数据增长或进一步减少训练时间。
SMDDP 库如何帮助减少培训时间、成本和复杂性
在传统的分布式数据训练中,训练框架将等级分配给 GPU(工作线程),并在每个 GPU 上创建模型的副本。在每次训练迭代期间,全局数据批次被分成多个片段(批次分片),并将一个片段分配给每个工作人员。然后,每个工作线程都会在每个 GPU 上继续执行训练脚本中定义的前向和后向传递。最后,来自不同模型副本的模型权重和梯度在迭代结束时通过称为 AllReduce 的集体通信操作进行同步。当每个工作线程和 GPU 拥有模型的同步副本后,下一次迭代就会开始。
SMDDP库是一个集体通信库,可以提高这种分布式数据并行训练过程的性能。 SMDDP 库减少了 AllReduce 等关键集体通信操作的通信开销。它的 AllReduce 实现是专为 AWS 基础设施设计的,可以通过将 AllReduce 操作与反向传递重叠来加速训练。这种方法通过优化 CPU 和 GPU 之间的内核操作,实现了近线性的扩展效率和更快的训练速度。
请注意以下计算:
- 全局批次的大小为(集群中的节点数量)*(每个节点的 GPU 数量)*(每个批次分片)
- 批次分片(小批量)是每次迭代分配给每个 GPU(工作线程)的数据集的子集
BigBasket 使用 SMDDP 库来减少总体训练时间。借助 FSx for Lustre,我们减少了模型训练和数据增强期间的数据读/写吞吐量。借助数据并行性,与其他替代方案相比,BigBasket 的训练速度提高了近 50%,成本降低了 20%,从而在 AWS 上提供了最佳性能。 SageMaker 会在完成后自动关闭训练管道。该项目成功完成,AWS 中的训练时间缩短了 50%(AWS 中为 4.5 天,而旧平台上为 9 天)。
在撰写本文时,BigBasket 已经在生产中运行完整的解决方案超过 6 个月,并通过迎合新城市来扩展系统,并且我们每个月都会添加新商店。
“我们与 AWS 就使用其 SMDDP 产品迁移到分布式训练的合作取得了巨大的胜利。它不仅将我们的培训时间减少了 50%,而且成本也降低了 20%。在我们的整个合作伙伴关系中,AWS 在客户至上和交付成果方面树立了标杆——与我们全程合作,实现承诺的利益。”
– Keshav Kumar,BigBasket 工程主管。
结论
在这篇文章中,我们讨论了 BigBasket 如何使用 SageMaker 训练其用于快速消费品产品识别的计算机视觉模型。人工智能驱动的自动自助结账系统的实施通过创新改善了零售客户体验,同时消除了结账过程中的人为错误。通过使用 SageMaker 分布式培训加速新产品入门,可减少 SKU 入门时间和成本。集成 FSx for Lustre 可实现快速并行数据访问,从而实现每月数百个新 SKU 的高效模型再训练。总体而言,这种基于人工智能的自助结账解决方案提供了增强的购物体验,并且没有前端结账错误。自动化和创新改变了他们的零售结账和入职操作。
SageMaker 提供端到端 ML 开发、部署和监控功能,例如用于编写代码、数据采集、数据标记、模型训练、模型调整、部署、监控等的 SageMaker Studio 笔记本环境。如果您的企业面临本文所述的任何挑战,并且希望节省上市时间并降低成本,请联系您所在区域的 AWS 客户团队并开始使用 SageMaker。
作者简介
 桑托什·瓦迪 是 BigBasket 的首席工程师,在解决人工智能挑战方面拥有十多年的专业知识。他拥有计算机视觉、数据科学和深度学习方面的深厚背景,拥有印度理工学院孟买分校的研究生学位。 Santosh 撰写了著名的 IEEE 出版物,并且作为经验丰富的技术博客作者,他在三星任职期间还为计算机视觉解决方案的开发做出了重大贡献。
桑托什·瓦迪 是 BigBasket 的首席工程师,在解决人工智能挑战方面拥有十多年的专业知识。他拥有计算机视觉、数据科学和深度学习方面的深厚背景,拥有印度理工学院孟买分校的研究生学位。 Santosh 撰写了著名的 IEEE 出版物,并且作为经验丰富的技术博客作者,他在三星任职期间还为计算机视觉解决方案的开发做出了重大贡献。
 南达·基肖尔·萨蒂孔达 是 BigBasket 的一名工程经理,负责领导数据工程和分析工作。 Nanda 已经构建了多个异常检测应用程序,并在类似领域申请了专利。他致力于构建企业级应用程序、在多个组织中构建数据平台和报告平台,以简化数据支持的决策。 Nanda 在 Java/J18EE、Spring 技术以及使用 Hadoop 和 Apache Spark 的大数据框架方面拥有超过 2 年的工作经验。
南达·基肖尔·萨蒂孔达 是 BigBasket 的一名工程经理,负责领导数据工程和分析工作。 Nanda 已经构建了多个异常检测应用程序,并在类似领域申请了专利。他致力于构建企业级应用程序、在多个组织中构建数据平台和报告平台,以简化数据支持的决策。 Nanda 在 Java/J18EE、Spring 技术以及使用 Hadoop 和 Apache Spark 的大数据框架方面拥有超过 2 年的工作经验。
 苏丹舒仇恨 是 AWS 的首席 AI 和 ML 专家,与客户合作,为他们的 MLOps 和生成式 AI 之旅提供建议。在之前的职位中,他构思、创建并领导团队构建了一个全新的、基于开源的人工智能和游戏化平台,并成功与 100 多个客户合作将其商业化。 Sudhanshu 拥有多项专利。写过 2 本书、多篇论文和博客;并在各种论坛上发表了自己的观点。他一直是思想领袖和演讲家,在该行业工作了近 25 年。他曾与全球财富 1000 强客户合作,最近正在与印度的数字原生客户合作。
苏丹舒仇恨 是 AWS 的首席 AI 和 ML 专家,与客户合作,为他们的 MLOps 和生成式 AI 之旅提供建议。在之前的职位中,他构思、创建并领导团队构建了一个全新的、基于开源的人工智能和游戏化平台,并成功与 100 多个客户合作将其商业化。 Sudhanshu 拥有多项专利。写过 2 本书、多篇论文和博客;并在各种论坛上发表了自己的观点。他一直是思想领袖和演讲家,在该行业工作了近 25 年。他曾与全球财富 1000 强客户合作,最近正在与印度的数字原生客户合作。
 阿育·库玛(Ayush Kumar) 是 AWS 的解决方案架构师。他正在与各种 AWS 客户合作,帮助他们采用最新的现代应用程序并利用云原生技术更快地进行创新。你会发现他在业余时间在厨房里进行实验。
阿育·库玛(Ayush Kumar) 是 AWS 的解决方案架构师。他正在与各种 AWS 客户合作,帮助他们采用最新的现代应用程序并利用云原生技术更快地进行创新。你会发现他在业余时间在厨房里进行实验。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

