介绍
在这篇文章中,我们将探讨什么是 假设检验,重点是零假设和备择假设的制定,建立假设检验,我们将深入研究参数和非参数检验,讨论它们各自的假设和在Python中的实现。但我们的主要关注点是非参数检验,例如 Mann-Whitney U 检验和 Kruskal-Wallis 检验。最后,您将对假设检验以及将这些概念应用到您自己的统计分析中的实用工具有一个全面的了解。
学习目标
- 了解假设检验的原理,包括零假设和备择假设的制定。
- 设置假设检验。
- 了解参数测试及其类型。
- 了解非参数测试及其类型及其实现。
- 参数化和非参数化之间的差异。
目录
什么是假设检验?
假设是个人/组织提出的主张。该主张通常与总体参数有关,例如平均值或比例,我们从样本中寻求证据来支持该主张。
假设检验,有时称为显着性检验,是一种使用样本中测量的数据来确认有关总体中参数的主张或假设的方法。使用这种方法,我们通过确定在总体参数假设成立的情况下可能选择样本统计量的可能性来探索几种理论。
假设检验涉及提出两个假设:
- 原假设 (H0)
- 备择假设 (H1)
零假设 : 它通常是无差异的假设,通常用 H0 表示。根据 RA Fisher 的说法,零假设是在假设为真的情况下测试可能拒绝的假设(参考数理统计基础)。
替代假设: 任何与原假设互补的假设称为备择假设,通常用 H1 表示。
假设检验的目的是拒绝或保留原假设,以在两个变量(通常是一个自变量和一个因变量,即通常一个是原因,一个是结果)之间建立统计上显着的关系。
设置假设检验
- 用文字描述假设或提出主张。
- 根据权利要求定义无效假设和替代假设。
- 确定适合上述主张的假设检验类型。
- 确定用于检验原假设有效性的检验统计量。
- 确定拒绝和保留原假设的标准。这称为显着性值,传统上用符号α(alpha)表示。
- 计算 p 值,即原假设为真时观察检验统计值的条件概率。简单来说,p 值是支持原假设的证据。
参数和非参数测试
非参数统计检验不依赖于对数据采样的总体分布参数的假设,而参数统计检验则依赖于对总体分布参数的假设。
参数测试
大多数统计测试都是使用一组假设作为基础来进行的。当违反某些假设时,分析可能会产生误导性或完全错误的结论。
通常的假设是:
- 正态性:待测参数的抽样分布遵循正态(或至少对称)分布。
- 方差同质性:不同组之间的数据方差是相同的,除非我们测试来自两个不同总体的总体均值。
一些参数测试是:
- Z 测试: 当总体标准差已知时,检验总体均值、方差或比例。
- 学生 t 检验: 当总体标准差未知时,检验总体均值、方差或比例。
- 配对 t 检验: 用于比较两个相关组或条件的平均值。
- 方差分析(ANOVA): 用于比较三个或更多独立组的平均值。
- 回归分析: 用于评估一个或多个自变量与因变量之间的关系。
- 协方差分析 (ANCOVA): 通过将额外的协变量纳入分析来扩展方差分析。
- 多元方差分析 (MANOVA): 扩展方差分析以评估组间多个因变量的差异。
现在让我们深入研究非参数测试。
非参数测试
1942年,沃尔福威茨首次使用“非参数”一词。要理解非参数统计的思想,首先必须对我们刚才讨论的参数统计有一个基本的了解。 A 参数测试 需要遵循特定分布(通常是正态分布)的样本。此外,非参数检验独立于正态性等参数假设。
非参数检验(也称为无分布检验,因为它们没有关于总体分布的假设)。非参数检验意味着检验并非基于数据取自某个数据的假设 概率分布 通过平均值、比例和标准差等参数定义。
在以下情况下使用非参数检验:
- 该检验与总体参数(例如均值或比例)无关。
- 该方法不需要对人口分布进行假设(例如人口服从正态分布)。
非参数检验的类型
现在让我们讨论卡方检验、Mann-Whitney 检验、Wilcoxon 符号秩检验和 Kruskal-Wallis 检验的概念和程序:
卡方检验
为了确定两个定性变量之间的关联是否具有统计显着性,必须进行称为卡方检验的显着性检验。
卡方检验有两种主要类型:
卡方拟合优度
使用拟合优度检验来确定未知分布的总体是否“适合”已知分布。在这种情况下,将有一个单一的定性调查问题或来自单一人群的单一实验结果。拟合优度通常用于查看总体是否均匀(所有结果以相同的频率发生)、总体是否正态,或者总体是否与具有已知分布的另一个总体相同。原假设和备择假设是:
- H0:人口符合给定的分布。
- Ha:人口不符合给定的分布。
让我们通过一个例子来理解这一点
| 日 | 周一 | 周二 | 周三 | 星期四 | 周五 | 周六 | 星期日 |
| 故障次数 | 14 | 22 | 16 | 18 | 12 | 19 | 11 |
该表显示了某个因素的细分数量。在此示例中,只有一个变量,我们必须确定观察到的分布(表中给出)是否符合预期分布。
为此,原假设和备择假设将表述为:
- H0:故障是均匀分布的。
- Ha:故障分布不均匀。
自由度将为 n-1 (在这种情况下 n=7 ,所以 df = 7-1=6)
Expected value will be= (14+22+16+18+12+19+11)/7=16
| 日 | 周一 | 周二 | 周三 | 星期四 | 周五 | 周六 | 星期日 |
| 故障次数(观察到的) | 14 | 22 | 16 | 18 | 12 | 19 | 11 |
| 预期 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
| (观察-预期) | -2 | 6 | 0 | 2 | -4 | 3 | -5 |
| (观察到预期)^2 | 4 | 36 | 0 | 4 | 16 | 9 | 25 |
使用此公式计算卡方
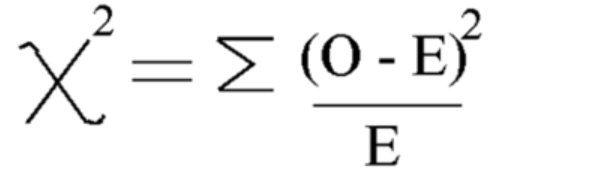
卡方 = 5.875
自由度=n-1=7-1=6
现在让我们看看临界值 卡方分布表 显着性水平为 5%
所以临界值为12.592
由于卡方计算值小于临界值 ,因此我们接受原假设并得出故障是均匀分布的结论。
卡方独立性检验
使用独立性检验来判断两个变量(因素)是独立的还是相关的,即这两个变量之间是否存在显着的关联关系。在这种情况下,将有两个定性调查问题或实验,并将构建一个列联表。目标是查看两个变量是否不相关(独立)或相关(相关)。原假设和备择假设是:
- H0:两个变量(因素)是独立的。
- Ha:两个变量(因素)是相关的。
让我们举个例子
我们想要调查性别和喜欢的衬衫颜色是否独立的示例。这意味着我们想了解一个人的性别是否影响他们对颜色的选择。我们进行了调查,并将数据整理在表中。
此表为观测值:
| 黑色 | 白色 | 红色 | 蓝色 | |
| 男性 | 48 | 12 | 33 | 57 |
| 女性 | 34 | 46 | 42 | 26 |
现在首先制定原假设和备择假设
- H0:性别和偏好的衬衫颜色是独立的
- Ha:性别和偏好的衬衫颜色不是独立的
为了计算卡方检验统计量,我们需要计算期望值。因此,添加所有行和列以及总计:
| 黑色 | 白色 | 红色 | 蓝色 | 合计 | |
| 男性 | 48 | 12 | 33 | 57 | 150 |
| 女性 | 34 | 46 | 42 | 26 | 148 |
| 合计 | 82 | 58 | 75 | 83 | 298 |
之后,我们可以使用以下公式计算上表中每个条目的预期值表 = (行总计 * 列总计)/总体总计
期望值表:
| 黑色 | 白色 | 红色 | 蓝色 | |
| 男性 | 41.3 | 29.2 | 37.8 | 41.8 |
| 女性 | 40.7 | 28.8 | 37.2 | 41.2 |
现在使用卡方检验公式计算卡方值:
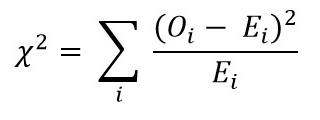
- Oi = 观测值
- Ei = 期望值
我们得到的值为: Χ2 = 34.9572
计算自由度
DF=(行数-1)*(列数-1)
现在找到临界值并将其与卡方检验进行比较 统计值:
为此,您可以从以下位置查找自由度和显着性水平 (alpha): 卡方分布表
当 alpha =0.050 时,我们将得到临界值= 7.815
由于卡方>临界值
因此,我们拒绝原假设,并且可以得出结论,性别和首选衬衫颜色不是独立的。
卡方的实施
现在,让我们使用 Python 中的一些实际示例来看看卡方的实现:
- H0:性别和偏好的衬衫颜色是独立的
- Ha:性别和偏好的衬衫颜色不是独立的
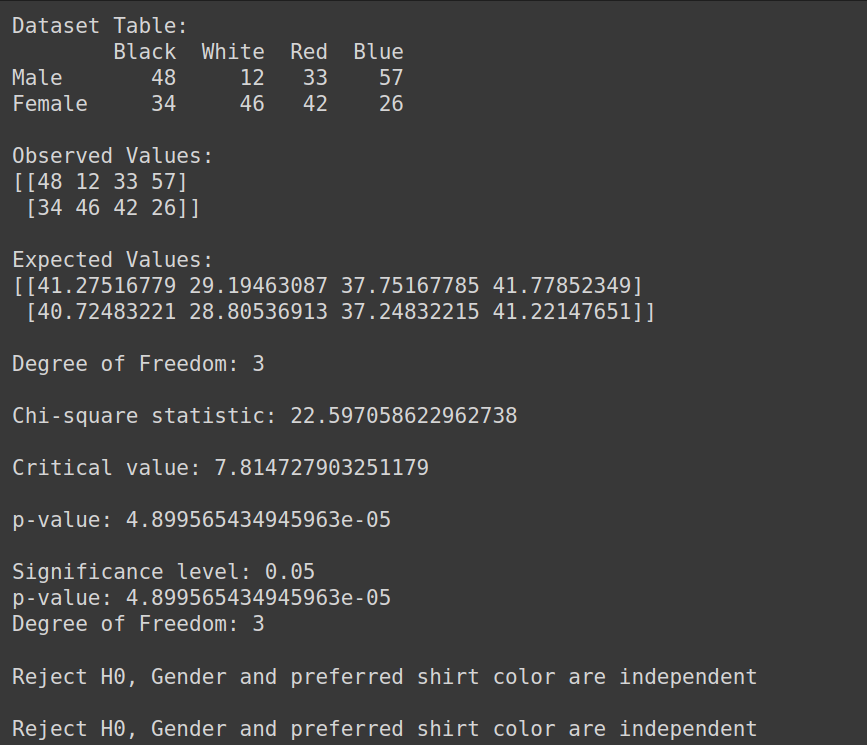
创建数据集:
import pandas as pd
from scipy.stats import chi2_contingency
from scipy.stats import chi2
# Given dataset
df_dict = {
'Black': [48, 34],
'White': [12, 46],
'Red': [33, 42],
'Blue': [57, 26]
}
dataset_table = pd.DataFrame(df_dict, index=['Male', 'Female'])
print("Dataset Table:")
print(dataset_table)
print()
# Observed Values
Observed_Values = dataset_table.values
print("Observed Values:")
print(Observed_Values)
print()
# Perform chi-square test
val = chi2_contingency(dataset_table)
Expected_Values = val[3]
print("Expected Values:")
print(Expected_Values)
print()
# Degree of Freedom
no_of_rows = len(dataset_table.iloc[0:2, 0])
no_of_columns = 4
ddof = (no_of_rows - 1) * (no_of_columns - 1)
print("Degree of Freedom:", ddof)
print()
# Chi-square statistic
chi_square = sum([(o - e) ** 2. / e for o, e in zip(Observed_Values, Expected_Values)])
chi_square_statistic = chi_square[0] + chi_square[1]
print("Chi-square statistic:", chi_square_statistic)
print()
# Critical value
alpha = 0.05
critical_value = chi2.ppf(q=1-alpha, df=ddof)
print('Critical value:', critical_value)
print()
# p-value
p_value = 1 - chi2.cdf(x=chi_square_statistic, df=ddof)
print('p-value:', p_value)
print()
# Significance level
print('Significance level:', alpha)
print('p-value:', p_value)
print('Degree of Freedom:', ddof)
print()
# Hypothesis testing
if chi_square_statistic >= critical_value:
print("Reject H0, Gender and preferred shirt color are independent")
else:
print("Fail to reject H0, Gender and preferred shirt color are not independent")
print()
if p_value <= alpha:
print("Reject H0, Gender and preferred shirt color are independent")
else:
print("Fail to reject H0, Gender and preferred shirt color are not independent")
输出:
曼-惠特尼 U 检验
Mann-Whitney U 检验是独立样本 t 检验的非参数替代方法。它比较来自同一总体的两个样本均值,确定它们是否相等。此检验通常用于序数数据或不满足 t 检验假设时。
Mann-Whitney U 检验对两组的所有值进行排名,然后对每组的排名进行求和。它根据这些排名计算检验统计量 U。 U 统计量与表中的临界值进行比较或使用近似值进行计算。如果 U 统计量小于临界值,则拒绝原假设。
这与 t 检验等参数检验不同,后者比较平均值并假设正态分布。 Mann-Whitney U 检验比较排名,并且不需要假设正态分布。
理解 Mann-Whitney U 检验可能很困难,因为结果以组排名差异而不是组平均差异的形式呈现。
曼惠特尼检验的公式:
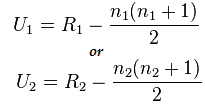
U=最小值(U1,U2)
在这里,
- U= 曼惠特尼 U 检验
- n1= 样本量一
- n2= 样本量二
- R1= 样本量一的排名
- R2= 样本量 2 的排名
那么,让我们通过一个简短的例子来理解这一点:
假设我们想要比较两种不同治疗方法(方法 A 和方法 B)在改善患者健康方面的有效性。我们有以下数据:
- 方法A:3,4,2,6,2,5
- 方法B:9,7,5,10,6,8
在这里,我们可以看到数据不呈正态分布,并且样本量很小。
曼惠特尼 U 检验的实施
现在,让我们执行 Mann-Whitney U 检验:
但首先让我们制定原假设和备择假设
- H0:各处理的Rank没有差异
- Ha:各处理的Rank存在差异
组合所有处理:3,4,2,6,2,5,9,7,5,10,6,8
排序数据:2,2,3,4,5,5,6,6,7,8,9,10
排序数据的排名:1,2,3,4,5,6,7,8,9,10,11,12
- 分别对数据进行排名:
- Method A: 3(3),4(4),2(1.5),6(7.5),2(1.5),5(5.5)
- Method B: 9(11),7(9),5(5.5),10(12),6(1.5),8(10)
- 计算排名总和):
- R1: 3+4+1.5+7.5+1.5+5.5=23
- R2: 11+9+5.5+12+1.5+10=55
现在使用以下公式计算统计值:
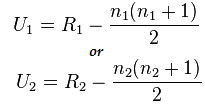
这里 n1=6 且 n2=6
计算后的值 U1=2 和 U2= 34
计算 U 统计量:
我们=分钟(U1,U2)=分钟(2,34)= 2
从 曼惠特尼表 我们可以找到临界值
在这种情况下,临界值为 5
由于 Uc= 5 在 5% 显着性水平上大于 Us。因此,我们拒绝 H0
因此我们可以得出结论,每种处理的Rank之间存在差异。
用python实现
from scipy.stats import mannwhitneyu, norm
import numpy as np
TreatmentA = np.array([3,4,2,6,2,5])
TreatmentB = np.array([9,7,5,10,6,8])
# Perform Mann-Whitney U test
U_statistic, p_value = mannwhitneyu(TreatmentA, TreatmentB)
# Print the result
print(f'The U-statistic is {U_statistic:.2f} and the p-value is {p_value:.4f}')
if p_value < 0.05:
print("Reject Null Hypothesis: There is a significant difference between the Rank of each treatment.")
else:
print("Fail to Reject Null Hypothesis: Fail to Reject Null Hypothesis: There is no enough evidence to conclude that there is difference between the Rank of each treatment")输出:

克鲁斯卡尔-沃利斯检验
Kruskal –Wallis 检验适用于多个组。当正态性和方差齐性假设被违反时,它是单向方差分析检验的一种非参数且有价值的替代方法。 Kruskal –Wallis 检验比较两个以上独立组的中位数。
当从具有相同分布的总体中抽取 k 个独立样本 (k>=3) 时,它会检验原假设,而不需要总体的正态性条件。
假设:
确保至少有三个独立随机抽取的样本。每个样本至少有 5 个观察值,n>=5
考虑一个例子,我们想要确定三组学生使用的学习技巧是否会影响他们的考试成绩。我们可以使用 Kruskal-Wallis 检验来分析数据并评估各组之间的考试成绩是否存在统计上的显着差异。
将零假设表述为:
- H0:三组学生的考试成绩没有差异。
- Ha:三组学生的考试成绩存在差异。
Wilcoxon 符号秩检验
Wilcoxon 符号秩检验(也称为 Wilcoxon 匹配对检验)是相关样本 t 检验或配对样本 t 检验的非参数版本。符号检验是配对样本 t 检验的另一种非参数替代方法。当感兴趣的变量本质上是二分的(例如男性和女性、是和否)时使用它。 Wilcoxon 符号秩检验也是一个样本 t 检验的非参数版本。 Wilcoxon 符号秩检验比较两种情况下各组的中位数(配对样本),或者比较该组的中位数与假设中位数(一个样本)。
让我们通过一个例子来理解这一点,假设我们有吸烟者参加为期 8 周的计划之前和之后每日香烟消费量的数据,并且我们想要确定计划前后每日香烟消费量是否存在显着差异,那么我们将使用这个测试
对此的假设表述为
- H0:计划前后每日吸烟量没有差异。
- Ha:项目前后每日吸烟量有差异
正态性测试
现在让我们讨论正态性测试:
夏皮罗威尔克检验
夏皮罗-威尔克检验评估给定的数据样本是否来自正态分布的总体。它是检查正态性的最常用测试之一。该检验在处理相对较小的样本量时特别有用。
在夏皮罗-威尔克检验中:
- 零假设 : 样本数据来自服从正态分布的总体。
- 另类假设: 样本数据并非来自服从正态分布的总体。
Shapiro-Wilk 检验生成的检验统计量在正态假设下测量观测数据与预期数据之间的差异。如果与检验统计量相关的 p 值小于选定的显着性水平(例如 0.05),我们将拒绝原假设,表明数据不是正态分布的。如果 p 值大于显着性水平,我们无法拒绝原假设,表明数据可能服从正态分布。
首先让我们为这些测试创建一个数据集,您可以使用您选择的任何数据集:
import pandas as pd
# Create the dictionary with the provided data
data = {
'population': [6.1101, 5.5277, 8.5186, 7.0032, 5.8598],
'profit': [17.5920, 9.1302, 13.6620, 11.8540, 6.8233]
}
# Create the DataFrame
df = pd.DataFrame(data)
response_var=df['profit']
Here, a sample for running Shapiro -Wilk test on python:
from scipy.stats import shapiro
stat, p_val = shapiro(response_var)
print(f'Shapiro-Wilk Test: Statistic={stat} p-value={p_val}')
if p_val > alpha:
print('Data looks normal (fail to reject H0)')
else:
print('Data looks normal (fail to reject H0)')输出:

此检验最适合相对较小的样本量 (n=< 50-2000),因为样本量较大时它的可靠性会降低。
安德森-达林
它评估给定的数据样本是否来自指定的分布,例如正态分布。它与 Shapiro-Wilk 检验类似,但更敏感,尤其是对于较小的样本量。
对于分布参数未知的情况,它适合多种分布,包括正态分布。
这里是实现它的Python代码:
from scipy.stats import anderson
response_var = data['profit']
alpha = 0.05
# Anderson-Darling Test
result = anderson(response_var)
print(f'Anderson statistics: {result.statistic:.3f}')
if result.statistic > result.critical_values[-1]:
p_value = 0.0 # The p-value is essentially 0 if the statistic exceeds the largest critical value
else:
p_value = result.significance_level[result.statistic < result.critical_values][-1]
print("P-value:", p_value)
if p_value < alpha:
print("Reject null hypothesis: Data does not look normally distributed")
else:
print("Fail to reject null hypothesis: Data looks normally distributed")输出:

雅克-贝拉测试
Jarque-Bera 检验评估给定的数据样本是否来自正态分布总体。它基于数据的偏度和峰度。
以下是 Jarque-Bera Test 在 Python 中的实现以及示例数据:
from scipy.stats import jarque_bera
# Performing Jarque-Bera test
test_statistic, p_value = jarque_bera(response_var)
print("Jarque-Bera Test Statistic:", test_statistic)
print("P-value:", p_value)
# Interpreting results
alpha = 0.05
if p_value < alpha:
print("Reject null hypothesis: Data does not look normally distributed")
else:
print("Fail to reject null hypothesis: Data looks normally distributed")输出:

| 产品类别 | 参数统计技术 | 非参数统计技术 |
| 相关 | 皮尔逊积矩相关系数 (r) | Spearman 等级系数相关性 (Rho)、Kendall’s Tau |
| 两组,独立测量 | 独立t检验 | 曼惠特尼 U 检验 |
| 两组以上,独立测量 | 单向方差分析 | Kruskal-Wallis 单向方差分析 |
| 两组,重复测量 | 配对 t 检验 | Wilcoxon 配对签名秩检验 |
| 两组以上,重复测量 | 单向重复测量方差分析 | 弗里德曼的双向方差分析 |
结论
假设检验 对于使用样本数据评估有关总体参数的主张至关重要。参数检验依赖于特定的假设,适用于区间或比率数据,而非参数检验更灵活,适用于没有严格分布假设的名义或序数数据。 Shapiro-Wilk 和 Anderson-Darling 等检验评估正态性,而卡方和 Jarque-Bera 评估拟合优度。了解参数检验和非参数检验之间的差异对于选择适当的统计方法至关重要。总体而言,假设检验提供了一个系统框架,用于制定数据驱动的决策并从经验证据中得出可靠的结论。
准备好掌握高级统计分析了吗? 立即报名参加我们的 BlackBelt 数据分析课程! 获得假设检验、参数和非参数测试、Python 实施等方面的专业知识。提高您的统计技能并擅长数据驱动的决策。立即加入!
常见问题解答
A. 参数检验对总体分布和参数做出假设,例如正态性和方差齐性,而非参数检验不依赖于这些假设。当满足假设时,参数检验更有效,而非参数检验更稳健,适用于更广泛的情况,包括当数据倾斜或不正态分布时。
A. 卡方检验用于确定两个 calcategories 变量之间是否存在显着关联。它通常分析分类数据并测试有关列联表中变量独立性的假设。
答:Mann-Whitney U 检验在因变量为序数或非正态分布时比较两个独立组。它评估两组中位数之间是否存在显着差异。
答:夏皮罗-威尔克检验评估样本是否来自正态分布总体。它检验数据服从正态分布的原假设。如果 p 值小于所选的显着性水平(例如 0.05),我们将拒绝原假设,得出数据不呈正态分布的结论。

