亚马逊SageMaker Studio 为数据科学家提供完全托管的解决方案,以交互方式构建、训练和部署机器学习 (ML) 模型。在处理机器学习任务的过程中,数据科学家通常通过发现相关数据源并连接到它们来开始工作流程。然后,他们使用 SQL 来探索、分析、可视化和集成来自各种来源的数据,然后将其用于 ML 训练和推理。以前,数据科学家经常发现自己在工作流程中使用多种工具来支持 SQL,这降低了工作效率。
我们很高兴地宣布,SageMaker Studio 中的 JupyterLab 笔记本现在内置了对 SQL 的支持。数据科学家现在可以:
- 连接到流行的数据服务,包括 亚马逊雅典娜, 亚马逊Redshift, 亚马逊数据区,以及直接在笔记本中的 Snowflake
- 浏览和搜索数据库、模式、表和视图,并在笔记本界面中预览数据
- 在同一个笔记本中混合 SQL 和 Python 代码,以便高效探索和转换数据以在 ML 项目中使用
- 使用 SQL 命令完成、代码格式化帮助和语法突出显示等开发人员生产力功能来帮助加速代码开发并提高开发人员的整体生产力
此外,管理员可以安全地管理与这些数据服务的连接,使数据科学家无需手动管理凭据即可访问授权数据。
在这篇文章中,我们将指导您在 SageMaker Studio 中设置此功能,并引导您了解此功能的各种功能。然后,我们将展示如何使用高级大语言模型 (LLM) 提供的文本到 SQL 功能来增强笔记本中的 SQL 体验,以使用自然语言文本作为输入来编写复杂的 SQL 查询。最后,为了使更广泛的用户能够从笔记本中的自然语言输入生成 SQL 查询,我们向您展示如何使用以下命令部署这些文本到 SQL 模型 亚马逊SageMaker 端点。
解决方案概述
借助 SageMaker Studio JupyterLab 笔记本的 SQL 集成,您现在可以连接到流行的数据源,例如 Snowflake、Athena、Amazon Redshift 和 Amazon DataZone。这项新功能使您能够执行各种功能。
例如,您可以直接从 JupyterLab 生态系统直观地探索数据库、表和架构等数据源。如果您的笔记本环境在 SageMaker Distribution 1.6 或更高版本上运行,请在 JupyterLab 界面的左侧查找新的小部件。此添加增强了开发环境中的数据可访问性和管理。
如果您当前未使用建议的 SageMaker 发行版(1.5 或更低版本)或自定义环境,请参阅附录了解更多信息。
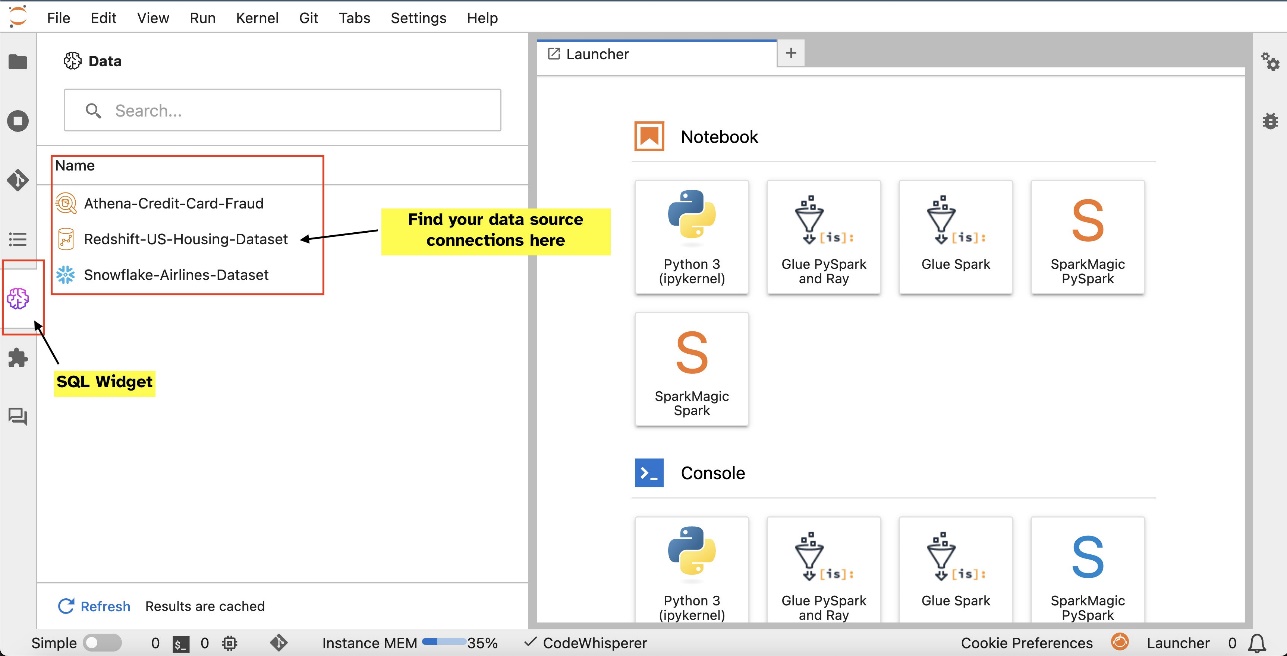
设置连接(在下一节中说明)后,您可以列出数据连接、浏览数据库和表以及检查架构。
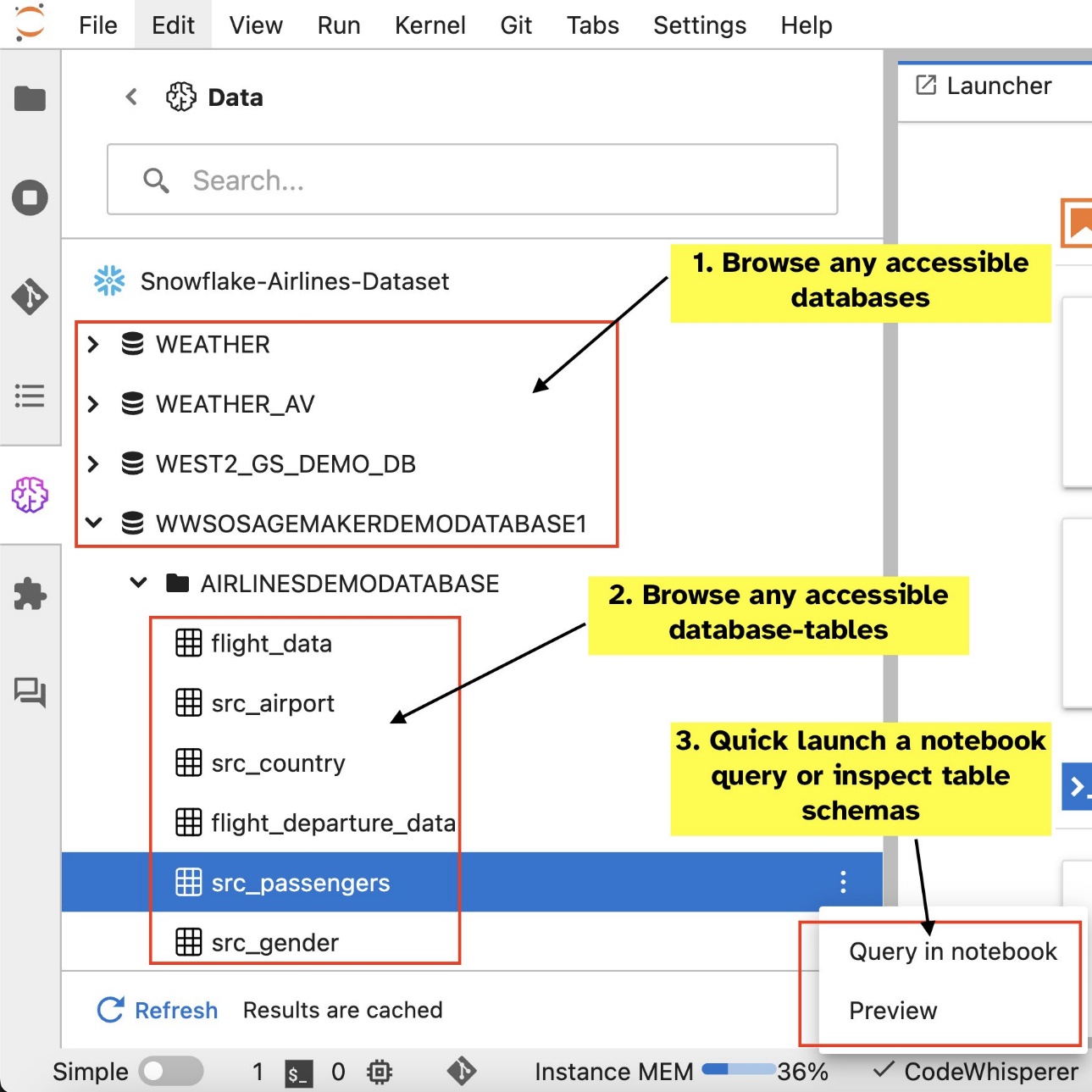
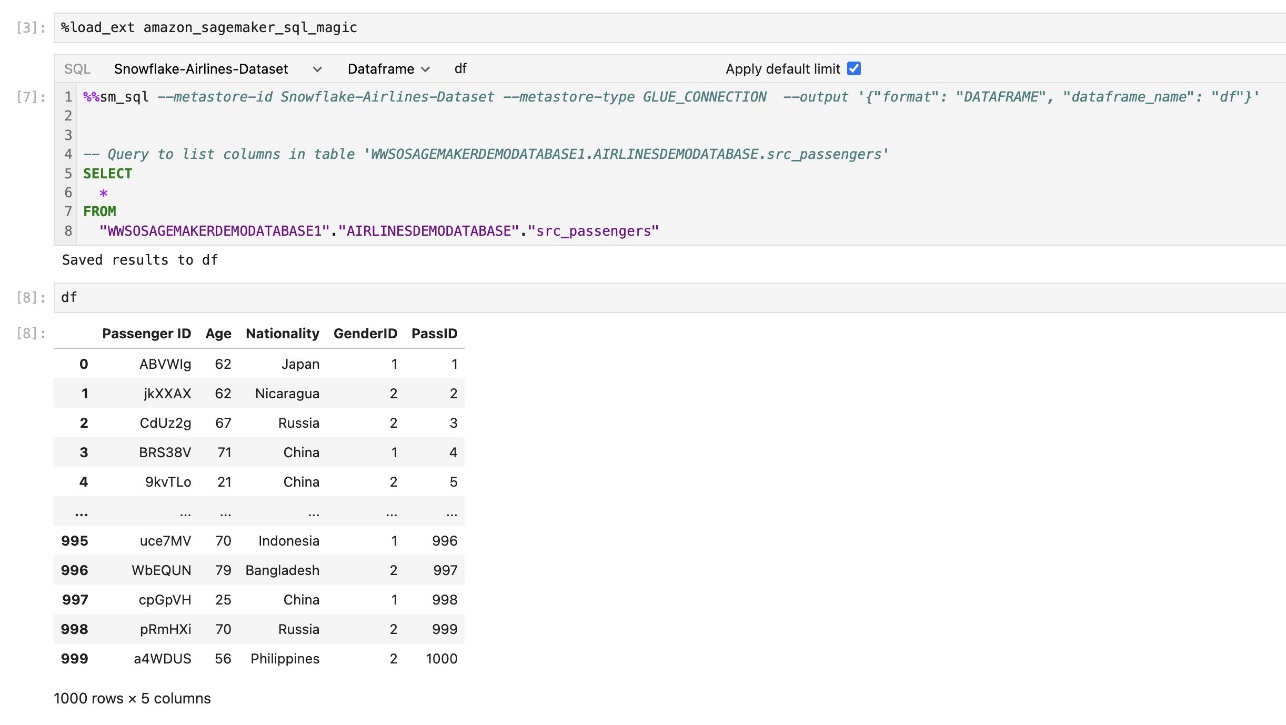
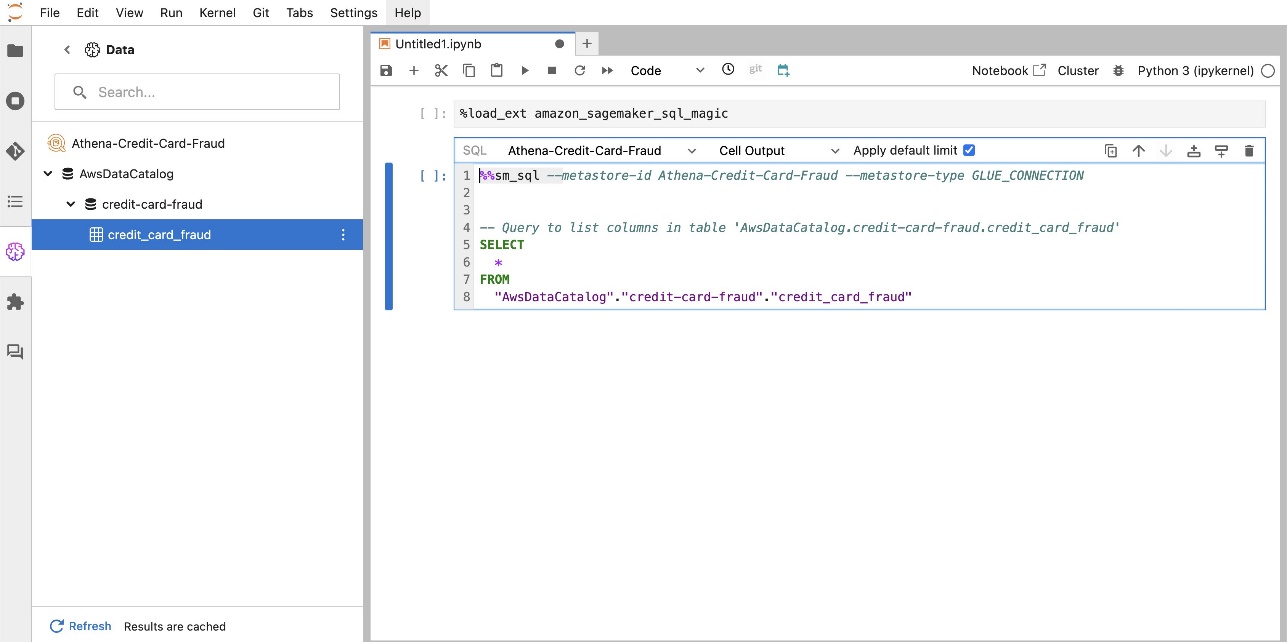
SageMaker Studio JupyterLab 内置 SQL 扩展还允许您直接从笔记本运行 SQL 查询。 Jupyter 笔记本可以使用以下命令区分 SQL 和 Python 代码 %%sm_sql magic 命令,必须放置在任何包含 SQL 代码的单元格的顶部。此命令向 JupyterLab 发出信号,表明以下指令是 SQL 命令而不是 Python 代码。查询的输出可以直接显示在笔记本中,从而促进数据分析中 SQL 和 Python 工作流程的无缝集成。
查询的输出可以直观地显示为 HTML 表,如以下屏幕截图所示。

它们也可以写入 熊猫数据框.
先决条件
确保您满足以下先决条件才能使用 SageMaker Studio 笔记本 SQL 体验:
- SageMaker Studio V2 – 确保您运行的是最新版本的 SageMaker Studio 域和用户配置文件。如果您当前使用的是 SageMaker Studio Classic,请参阅 从 Amazon SageMaker Studio Classic 迁移.
- IAM角色 – SageMaker 需要 AWS身份和访问管理 要分配给 SageMaker Studio 域或用户配置文件的 (IAM) 角色,以有效管理权限。可能需要更新执行角色才能引入数据浏览和 SQL 运行功能。以下示例策略使用户能够授予、列出和运行 AWS胶水,雅典娜, 亚马逊简单存储服务 (Amazon S3), AWS机密管理器和 Amazon Redshift 资源:
- JupyterLab空间 – 您需要访问更新的 SageMaker Studio 和 JupyterLab Space SageMaker 发行版 v1.6 或更高版本的镜像版本。如果您使用的是 JupyterLab Spaces 或较早版本的 SageMaker Distribution(v1.5 或更低版本)的自定义映像,请参阅附录,了解安装必要的软件包和模块以在您的环境中启用此功能的说明。要了解有关 SageMaker Studio JupyterLab Spaces 的更多信息,请参阅 提高 Amazon SageMaker Studio 的工作效率:JupyterLab Spaces 和生成式 AI 工具简介.
- 数据源访问凭证 – 此 SageMaker Studio 笔记本功能需要用户名和密码才能访问 Snowflake 和 Amazon Redshift 等数据源。如果您还没有这些数据源,请创建基于用户名和密码的访问权限。截至撰写本文时,基于 OAuth 的 Snowflake 访问尚不受支持。
- 加载 SQL 魔法 – 在从 Jupyter Notebook 单元运行 SQL 查询之前,必须加载 SQL magics 扩展。使用命令
%load_ext amazon_sagemaker_sql_magic启用此功能。此外,您还可以运行%sm_sql?命令查看支持从 SQL 单元查询的选项的完整列表。这些选项包括将默认查询限制设置为 1,000、运行完整提取以及注入查询参数等。此设置允许直接在笔记本环境中进行灵活高效的 SQL 数据操作。
创建数据库连接
AWS Glue 连接增强了 SageMaker Studio 的内置 SQL 浏览和执行功能。 AWS Glue 连接是一个 AWS Glue 数据目录对象,用于存储特定数据存储的登录凭证、URI 字符串和虚拟私有云 (VPC) 信息等基本数据。 AWS Glue 爬网程序、作业和开发终端节点使用这些连接来访问各种类型的数据存储。您可以将这些连接用于源数据和目标数据,甚至可以在多个爬网程序或提取、转换和加载 (ETL) 作业中重复使用相同的连接。
要在 SageMaker Studio 的左侧窗格中探索 SQL 数据源,您首先需要创建 AWS Glue 连接对象。这些连接有助于访问不同的数据源,并允许您探索其原理图数据元素。
在以下部分中,我们将逐步介绍创建特定于 SQL 的 AWS Glue 连接器的过程。这将使您能够访问、查看和探索各种数据存储中的数据集。有关 AWS Glue 连接的更多详细信息,请参阅 连接到数据.
创建 AWS Glue 连接
将数据源引入 SageMaker Studio 的唯一方法是使用 AWS Glue 连接。您需要创建具有特定连接类型的 AWS Glue 连接。截至撰写本文时,创建这些连接的唯一受支持的机制是使用 AWS命令行界面 (AWS CLI)。
连接定义 JSON 文件
在 AWS Glue 中连接到不同数据源时,您必须首先创建一个定义连接属性的 JSON 文件 - 称为 连接定义文件。该文件对于建立 AWS Glue 连接至关重要,并且应详细说明访问数据源所需的所有配置。为了实现安全最佳实践,建议使用 Secrets Manager 安全存储密码等敏感信息。同时,其他连接属性可以直接通过 AWS Glue 连接进行管理。此方法可确保敏感凭据受到保护,同时仍使连接配置可访问和管理。
以下是连接定义 JSON 的示例:
为数据源设置 AWS Glue 连接时,需要遵循一些重要准则以提供功能和安全性:
- 属性的字符串化 – 在
PythonPropertieskey,确保所有属性都是 字符串化的键值对。在必要时使用反斜杠 () 字符正确转义双引号至关重要。这有助于维护正确的格式并避免 JSON 中的语法错误。 - 处理敏感信息 – 尽管可以包含所有连接属性
PythonProperties,建议不要直接在这些属性中包含密码等敏感详细信息。相反,请使用 Secrets Manager 来处理敏感信息。这种方法通过将敏感数据存储在远离主配置文件的受控和加密环境中来保护您的敏感数据。
使用 AWS CLI 创建 AWS Glue 连接
在连接定义 JSON 文件中包含所有必需字段后,您就可以使用 AWS CLI 和以下命令为数据源建立 AWS Glue 连接:
此命令根据 JSON 文件中详细说明的规范启动新的 AWS Glue 连接。以下是命令组件的快速细分:
- -地区 – 这指定将在其中创建 AWS Glue 连接的 AWS 区域。选择数据源和其他服务所在的区域至关重要,以最大限度地减少延迟并遵守数据驻留要求。
- –cli-input-json 文件:///path/to/file/connection/definition/file.json – 此参数指示 AWS CLI 从包含 JSON 格式的连接定义的本地文件读取输入配置。
您应该能够从 Studio JupyterLab 终端使用上述 AWS CLI 命令创建 AWS Glue 连接。上 文件 菜单中选择 全新 和 终端.

如果 create-connection 命令成功运行后,您应该会看到 SQL 浏览器窗格中列出了您的数据源。如果您没有看到列出的数据源,请选择 刷新 更新缓存。

创建雪花连接
在本节中,我们重点介绍 Snowflake 数据源与 SageMaker Studio 的集成。创建 Snowflake 帐户、数据库和仓库不属于本文的讨论范围。要开始使用 Snowflake,请参阅 雪花用户指南。在本文中,我们重点介绍如何创建 Snowflake 定义 JSON 文件并使用 AWS Glue 建立 Snowflake 数据源连接。
创建 Secrets Manager 密钥
您可以使用用户 ID 和密码或使用私钥连接到您的 Snowflake 帐户。要使用用户 ID 和密码进行连接,您需要将凭据安全地存储在 Secrets Manager 中。如前所述,尽管可以将此信息嵌入到 PythonProperties 下,但不建议以纯文本格式存储敏感信息。始终确保敏感数据得到安全处理,以避免潜在的安全风险。
要将信息存储在 Secrets Manager 中,请完成以下步骤:
- 在Secrets Manager控制台上,选择 储存新秘密.
- 针对 秘密类型,选择 其他类型的秘密.
- 对于键值对,选择 纯文本 并输入以下内容:
- 输入您的秘密的名称,例如
sm-sql-snowflake-secret. - 将其他设置保留为默认设置或根据需要进行自定义。
- 创造秘密。
为 Snowflake 创建 AWS Glue 连接
如前所述,AWS Glue 连接对于从 SageMaker Studio 访问任何连接至关重要。您可以找到以下列表 Snowflake 所有支持的连接属性。以下是 Snowflake 的示例连接定义 JSON。将占位符值替换为适当的值,然后再将其保存到磁盘:
要为 Snowflake 数据源创建 AWS Glue 连接对象,请使用以下命令:
此命令在 SQL 浏览器窗格中创建一个可浏览的新 Snowflake 数据源连接,您可以从 JupyterLab 笔记本单元对其运行 SQL 查询。
创建 Amazon Redshift 连接
Amazon Redshift 是一项完全托管的 PB 级数据仓库服务,可简化使用标准 SQL 分析所有数据的过程并降低成本。创建 Amazon Redshift 连接的过程与 Snowflake 连接的过程非常相似。
创建 Secrets Manager 密钥
与 Snowflake 设置类似,要使用用户 ID 和密码连接到 Amazon Redshift,您需要将密钥信息安全地存储在 Secrets Manager 中。完成以下步骤:
- 在Secrets Manager控制台上,选择 储存新秘密.
- 针对 秘密类型,选择 Amazon Redshift 集群的凭证.
- 输入用于登录以访问 Amazon Redshift 作为数据源的凭证。
- 选择与密钥关联的 Redshift 集群。
- 输入秘密的名称,例如
sm-sql-redshift-secret. - 将其他设置保留为默认设置或根据需要进行自定义。
- 创造秘密。
通过执行这些步骤,您可以确保安全地处理您的连接凭证,并使用 AWS 强大的安全功能有效管理敏感数据。
为 Amazon Redshift 创建 AWS Glue 连接
要使用 JSON 定义设置与 Amazon Redshift 的连接,请填写必要的字段并将以下 JSON 配置保存到磁盘:
要为 Redshift 数据源创建 AWS Glue 连接对象,请使用以下 AWS CLI 命令:
此命令在 AWS Glue 中创建链接到您的 Redshift 数据源的连接。如果命令成功运行,您将能够在 SageMaker Studio JupyterLab 笔记本中看到 Redshift 数据源,准备好运行 SQL 查询和执行数据分析。

创建 Athena 连接
Athena 是 AWS 提供的完全托管的 SQL 查询服务,支持使用标准 SQL 分析 Amazon S3 中存储的数据。要将 Athena 连接设置为 JupyterLab 笔记本的 SQL 浏览器中的数据源,您需要创建 Athena 示例连接定义 JSON。以下 JSON 结构配置连接到 Athena 所需的详细信息,指定数据目录、S3 暂存目录和区域:
要为 Athena 数据源创建 AWS Glue 连接对象,请使用以下 AWS CLI 命令:
如果命令成功,您将能够直接从 SageMaker Studio JupyterLab 笔记本中的 SQL 浏览器访问 Athena 数据目录和表。
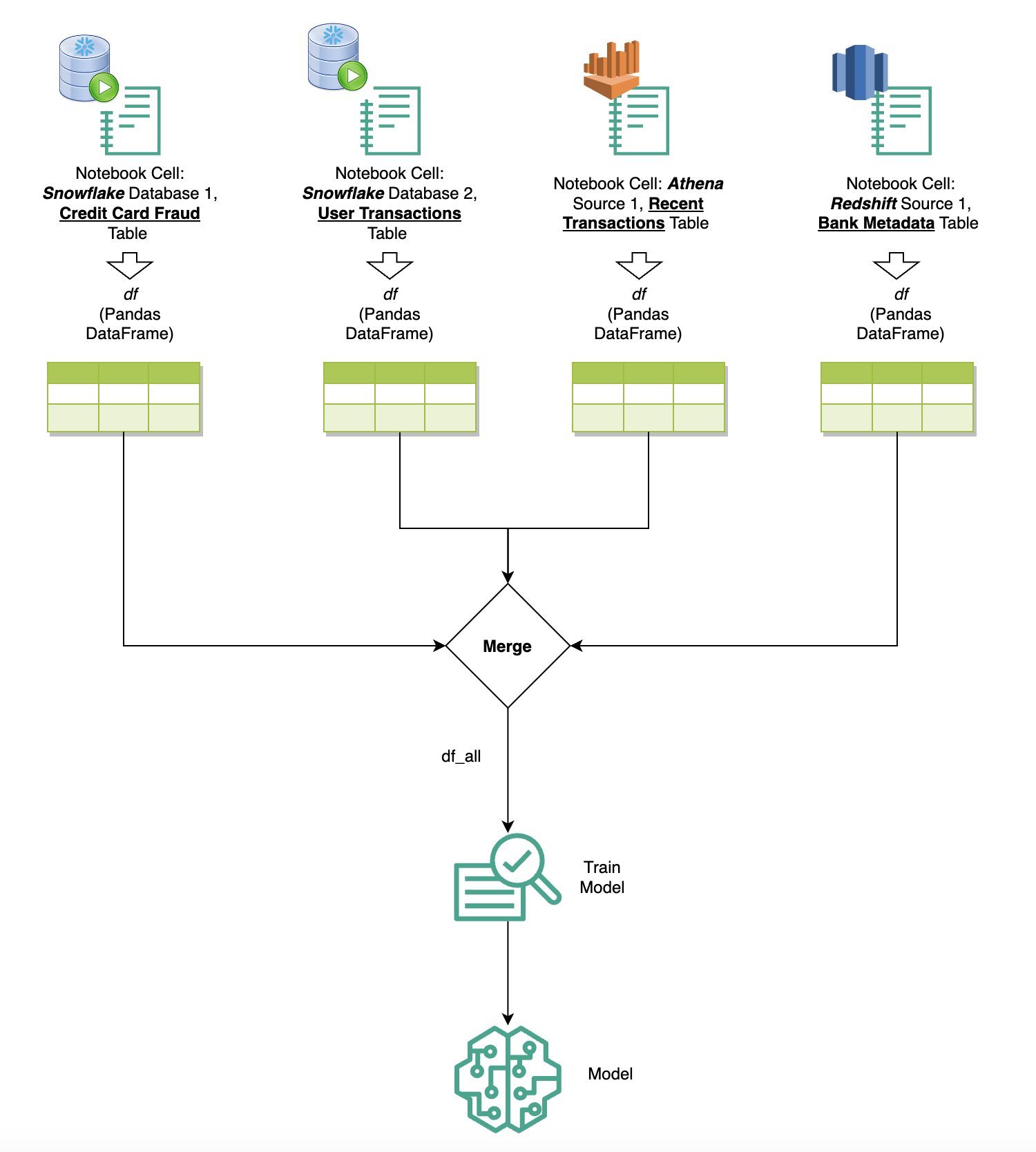
查询多个来源的数据
如果您通过内置 SQL 浏览器和笔记本 SQL 功能将多个数据源集成到 SageMaker Studio 中,则可以快速运行查询并轻松在笔记本内后续单元中的数据源后端之间切换。此功能允许在分析工作流程期间在不同数据库或数据源之间无缝转换。
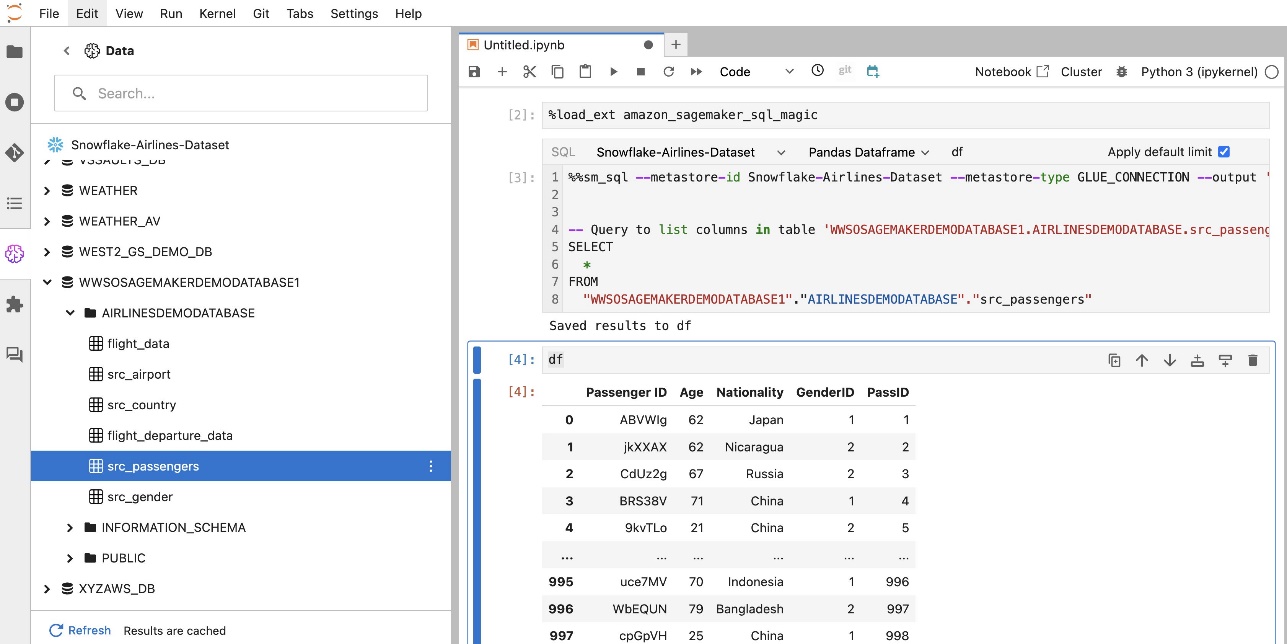
您可以对各种数据源后端集合运行查询,并将结果直接带入 Python 空间以进行进一步分析或可视化。这是由 %%sm_sql SageMaker Studio 笔记本中提供 magic 命令。要将 SQL 查询的结果输出到 pandas DataFrame 中,有两个选项:
- 从笔记本单元格工具栏中选择输出类型 数据框 并命名您的 DataFrame 变量
- 将以下参数附加到您的
%%sm_sql命令:
下图说明了此工作流程,并展示了如何轻松地在后续笔记本单元中跨各种源运行查询,以及如何使用训练作业或直接在笔记本中使用本地计算来训练 SageMaker 模型。此外,该图还突出显示了 SageMaker Studio 的内置 SQL 集成如何简化直接在熟悉的 JupyterLab 笔记本单元环境中提取和构建的过程。
文本到 SQL:使用自然语言增强查询创作
SQL 是一种复杂的语言,需要了解数据库、表、语法和元数据。如今,生成式人工智能 (AI) 可以让您编写复杂的 SQL 查询,而无需深入的 SQL 经验。法学硕士的进步极大地影响了基于自然语言处理 (NLP) 的 SQL 生成,允许从自然语言描述创建精确的 SQL 查询——一种称为“文本到 SQL”的技术。然而,必须承认人类语言和 SQL 之间的固有差异。人类语言有时可能含糊不清或不精确,而 SQL 是结构化的、明确的且明确的。弥合这一差距并将自然语言准确地转换为 SQL 查询可能会带来巨大的挑战。当提供适当的提示时,法学硕士可以通过理解人类语言背后的意图并相应地生成准确的 SQL 查询来帮助弥合这一差距。
随着 SageMaker Studio 笔记本内 SQL 查询功能的发布,SageMaker Studio 可以轻松检查数据库和架构,以及编写、运行和调试 SQL 查询,而无需离开 Jupyter 笔记本 IDE。本节探讨高级法学硕士的文本到 SQL 功能如何促进在 Jupyter Notebook 中使用自然语言生成 SQL 查询。我们采用最先进的文本到 SQL 模型 defog/sqlcoder-7b-2 与专门为 Jupyter Notebook 设计的生成式 AI 助手 Jupyter AI 结合使用,可以从自然语言创建复杂的 SQL 查询。通过使用这种高级模型,我们可以使用自然语言轻松高效地创建复杂的 SQL 查询,从而增强我们在笔记本中的 SQL 体验。
使用 Hugging Face Hub 进行笔记本原型设计
要开始原型设计,您需要以下内容:
- GitHub代码 – 本节中提供的代码可在以下位置找到 GitHub回购 并通过引用 示例笔记本.
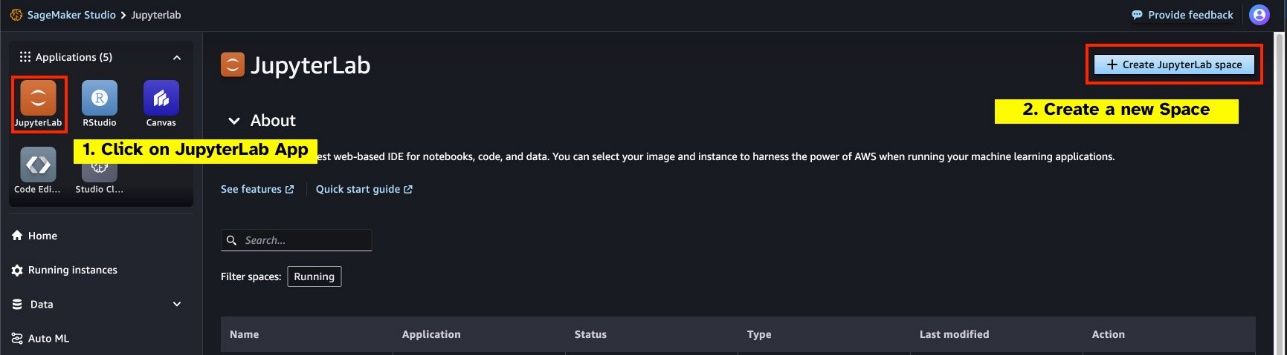
- JupyterLab空间 – 访问由基于 GPU 的实例支持的 SageMaker Studio JupyterLab Space 至关重要。为了
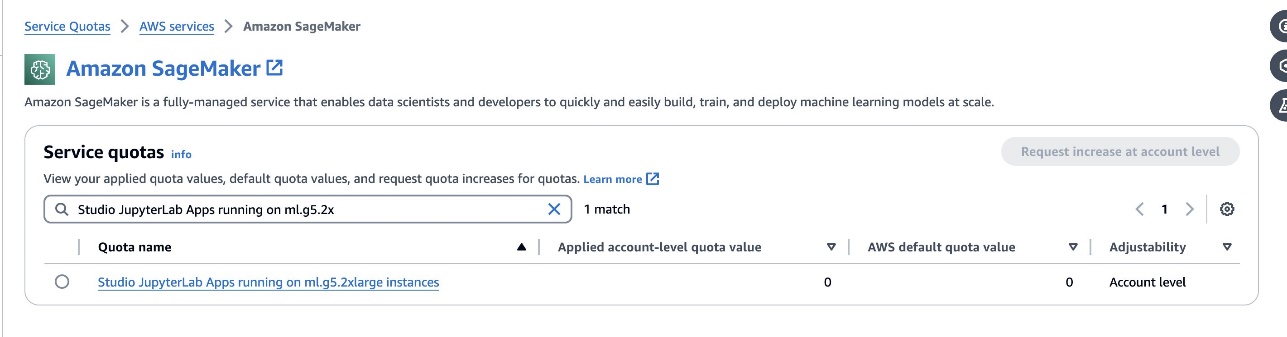
defog/sqlcoder-7b-2模型,7B参数模型,推荐使用ml.g5.2xlarge实例。替代方案如defog/sqlcoder-70b-alph一个或defog/sqlcoder-34b-alpha对于自然语言到 SQL 的转换也是可行的,但原型设计可能需要更大的实例类型。确保您有配额来启动 GPU 支持的实例,方法是导航到服务配额控制台,搜索 SageMaker,然后搜索Studio JupyterLab Apps running on <instance type>.
从 SageMaker Studio 启动新的 GPU 支持的 JupyterLab Space。建议创建一个至少 75 GB 的新 JupyterLab 空间 Amazon Elastic Block商店 (Amazon EBS) 7B 参数模型的存储。

- 拥抱脸中心 – 如果您的 SageMaker Studio 域有权从以下位置下载模型 拥抱脸中心,你可以使用
AutoModelForCausalLM班级来自 拥抱脸/变形金刚 自动下载模型并将其固定到本地 GPU。模型权重将存储在本地计算机的缓存中。请看下面的代码:
模型完全下载并加载到内存后,您应该会观察到本地计算机上的 GPU 利用率有所增加。这表明该模型正在积极使用 GPU 资源来执行计算任务。您可以通过运行在您自己的 JupyterLab 空间中验证这一点 nvidia-smi (用于一次性显示)或 nvidia-smi —loop=1 (每秒重复一次)从 JupyterLab 终端。
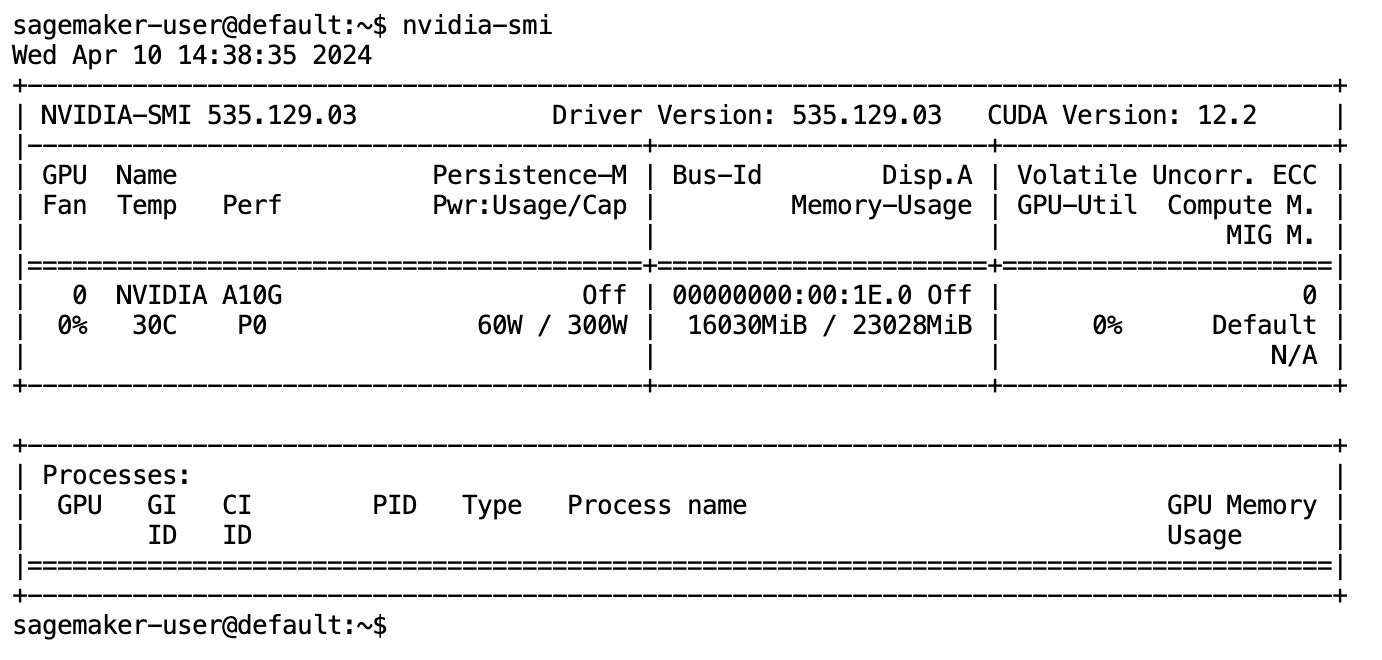
文本到 SQL 模型擅长理解用户请求的意图和上下文,即使使用的语言是会话式的或模棱两可的。该过程涉及将自然语言输入转换为正确的数据库模式元素,例如表名、列名和条件。然而,现成的文本到 SQL 模型本身并不知道数据仓库的结构、特定的数据库模式,或者无法仅根据列名称准确地解释表的内容。为了有效地使用这些模型从自然语言生成实用且高效的 SQL 查询,有必要使 SQL 文本生成模型适应您的特定仓库数据库模式。这种适应是通过使用来促进的 LLM提示。以下是defog/sqlcoder-7b-2 Text-to-SQL模型的推荐提示模板,分为四个部分:
- 任务 – 本节应指定模型要完成的高级任务。它应包括数据库后端的类型(例如 Amazon RDS、PostgreSQL 或 Amazon Redshift),以使模型了解可能影响最终 SQL 查询生成的任何细微语法差异。
- 说明 – 本节应定义模型的任务边界和领域感知,并且可能包括少量示例来指导模型生成微调的 SQL 查询。
- 数据库架构 – 本节应详细介绍您的仓库数据库模式,概述表和列之间的关系,以帮助模型理解数据库结构。
- 回答 – 此部分保留用于模型输出对自然语言输入的 SQL 查询响应。
本节中使用的数据库模式和提示的示例可在 GitHub回购.
即时工程不仅仅是提出问题或陈述;而是提出问题。这是一门微妙的艺术和科学,会显着影响与人工智能模型交互的质量。您制作提示的方式可以深刻地影响人工智能响应的性质和有用性。这项技能对于最大限度地发挥人工智能交互的潜力至关重要,尤其是在需要专业理解和详细响应的复杂任务中。
能够快速构建和测试模型对给定提示的响应并根据响应优化提示非常重要。 JupyterLab 笔记本能够从本地计算上运行的模型接收即时模型反馈,并优化提示并进一步调整模型的响应或完全更改模型。在本文中,我们使用由 ml.g5.2xlarge 的 NVIDIA A10G 24 GB GPU 支持的 SageMaker Studio JupyterLab 笔记本在笔记本上运行文本到 SQL 模型推理,并以交互方式构建模型提示,直到模型的响应充分调整以提供可在 JupyterLab 的 SQL 单元中直接执行的响应。为了运行模型推理并同时流式传输模型响应,我们结合使用 model.generate 和 TextIteratorStreamer 如以下代码中所定义:
模型的输出可以使用 SageMaker SQL magic 进行修饰 %%sm_sql ...,它允许 JupyterLab 笔记本将该单元识别为 SQL 单元。
将文本到 SQL 模型托管为 SageMaker 端点
在原型设计阶段结束时,我们选择了首选的文本到 SQL LLM、有效的提示格式以及用于托管模型的适当实例类型(单 GPU 或多 GPU)。 SageMaker 通过使用 SageMaker 端点促进自定义模型的可扩展托管。这些端点可以根据特定标准进行定义,从而允许将 LLM 部署为端点。此功能使您能够将解决方案扩展到更广泛的受众,允许用户使用自定义托管的 LLM 从自然语言输入生成 SQL 查询。下图说明了这种架构。

要将 LLM 作为 SageMaker 端点托管,您需要生成多个工件。
第一个工件是模型权重。 SageMaker 深度 Java 库 (DJL) 服务 容器允许您通过元设置配置 服务.properties 文件,它使您能够指导模型的来源方式 - 直接从 Hugging Face Hub 或通过从 Amazon S3 下载模型工件。如果您指定 model_id=defog/sqlcoder-7b-2,DJL Serving 将尝试直接从 Hugging Face Hub 下载此模型。但是,每次部署或弹性扩展端点时,您可能会产生网络入口/出口费用。为了避免这些费用并可能加快模型工件的下载速度,建议跳过使用 model_id in serving.properties 并将模型权重保存为 S3 工件,并且仅指定它们 s3url=s3://path/to/model/bin.
只需几行代码即可将模型(及其标记生成器)保存到磁盘并将其上传到 Amazon S3:
您还可以使用数据库提示文件。在此设置中,数据库提示由以下部分组成 Task, Instructions, Database Schema及 Answer sections。对于当前的架构,我们为每个数据库模式分配一个单独的提示文件。但是,可以灵活地扩展此设置以在每个提示文件中包含多个数据库,从而允许模型在同一服务器上跨数据库运行复合联接。在原型设计阶段,我们将数据库提示保存为名为的文本文件 <Database-Glue-Connection-Name>.prompt,其中 Database-Glue-Connection-Name 对应于 JupyterLab 环境中可见的连接名称。例如,这篇文章引用了一个名为的 Snowflake 连接 Airlines_Dataset,所以数据库提示文件命名为 Airlines_Dataset.prompt。然后,该文件存储在 Amazon S3 上,随后由我们的模型服务逻辑读取和缓存。
此外,该架构允许该端点的任何授权用户定义、存储和生成 SQL 查询的自然语言,而无需多次重新部署模型。我们使用以下 数据库提示示例 演示文本到 SQL 功能。
接下来,您生成自定义模型服务逻辑。在本节中,您将概述名为的自定义推理逻辑 模型.py。该脚本旨在优化我们的文本到 SQL 服务的性能和集成:
- 定义数据库提示文件缓存逻辑 – 为了最大限度地减少延迟,我们实现了用于下载和缓存数据库提示文件的自定义逻辑。此机制可确保提示随时可用,从而减少与频繁下载相关的开销。
- 定义自定义模型推理逻辑 – 为了提高推理速度,我们的文本到 SQL 模型以 float16 精度格式加载,然后转换为 DeepSpeed 模型。此步骤允许更有效的计算。此外,在此逻辑中,您可以指定用户在推理调用期间可以调整哪些参数,以根据他们的需求定制功能。
- 定义自定义输入和输出逻辑 – 建立清晰且定制的输入/输出格式对于与下游应用程序的顺利集成至关重要。 JupyterAI 就是这样的一个应用程序,我们将在后续部分中讨论它。
此外,我们还包括一个 serving.properties 文件,它充当使用 DJL 服务托管的模型的全局配置文件。欲了解更多信息,请参阅 配置和设置.
最后,您还可以添加一个 requirements.txt 文件来定义推理所需的附加模块,并将所有内容打包到 tarball 中以供部署。
请参见以下代码:
将您的端点与 SageMaker Studio Jupyter AI 助手集成
木星人工智能 是一款开源工具,可将生成式 AI 引入 Jupyter 笔记本,为探索生成式 AI 模型提供强大且用户友好的平台。它通过提供 %%ai magic 等功能来提高 JupyterLab 和 Jupyter 笔记本的工作效率,这些功能用于在笔记本内创建生成式 AI 游乐场、JupyterLab 中用于作为对话助手与 AI 交互的本机聊天 UI,以及对来自各种法学硕士的支持供应商喜欢 亚马逊泰坦、AI21、Anthropic、Cohere 和 Hugging Face 或托管服务,例如 亚马逊基岩 和 SageMaker 端点。在这篇文章中,我们使用 Jupyter AI 与 SageMaker 端点的开箱即用集成,将文本到 SQL 功能引入 JupyterLab 笔记本中。 Jupyter AI 工具预装在由以下公司支持的所有 SageMaker Studio JupyterLab 空间中 SageMaker 发行版图像;最终用户无需进行任何额外配置即可开始使用 Jupyter AI 扩展与 SageMaker 托管端点集成。在本节中,我们将讨论使用集成 Jupyter AI 工具的两种方法。
Jupyter AI 在笔记本中使用魔法
Jupyter AI 的 %%ai magic 命令允许您将 SageMaker Studio JupyterLab 笔记本转变为可重复的生成 AI 环境。要开始使用 AI magics,请确保您已加载要使用的 jupyter_ai_magics 扩展 %%ai 魔法,并额外加载 amazon_sagemaker_sql_magic 使用 %%sm_sql 魔法:
要使用以下命令从笔记本运行对 SageMaker 端点的调用: %%ai magic 命令,提供以下参数并构造命令如下:
- –区域名称 – 指定部署终端的区域。这可确保请求被路由到正确的地理位置。
- –请求模式 – 包括输入数据的模式。此架构概述了模型处理请求所需的输入数据的预期格式和类型。
- –响应路径 – 定义响应对象内模型输出所在的路径。此路径用于从模型返回的响应中提取相关数据。
- -f(可选) - 这是一 输出格式化程序 指示模型返回的输出类型的标志。在 Jupyter 笔记本的上下文中,如果输出是代码,则应相应地设置此标志,以将输出格式化为 Jupyter 笔记本单元顶部的可执行代码,后面是用于用户交互的自由文本输入区域。
例如,Jupyter 笔记本单元中的命令可能类似于以下代码:
Jupyter AI 聊天窗口
或者,您可以通过内置用户界面与 SageMaker 端点进行交互,从而简化生成查询或参与对话的过程。在开始与 SageMaker 端点聊天之前,请在 Jupyter AI 中为 SageMaker 端点配置相关设置,如以下屏幕截图所示。
 |
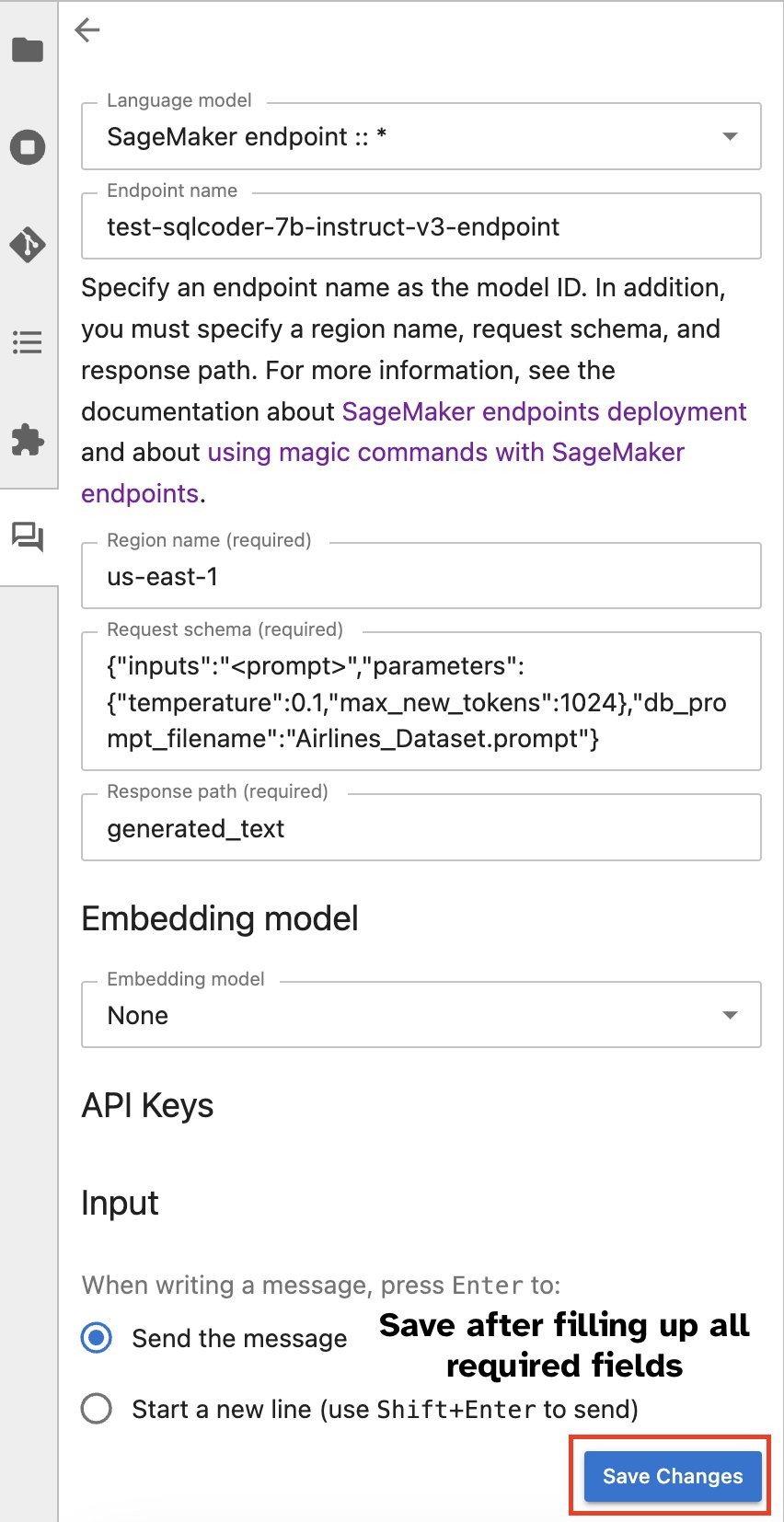 |
结论
SageMaker Studio 现在通过将 SQL 支持集成到 JupyterLab 笔记本中来简化和简化数据科学家的工作流程。这使得数据科学家能够专注于他们的任务,而无需管理多个工具。此外,SageMaker Studio 中新的内置 SQL 集成使数据角色能够使用自然语言文本作为输入轻松生成 SQL 查询,从而加速其工作流程。
我们鼓励您在 SageMaker Studio 中探索这些功能。欲了解更多信息,请参阅 在 Studio 中使用 SQL 准备数据.
附录
在自定义环境中启用 SQL 浏览器和笔记本 SQL 单元
如果您不使用 SageMaker 发行版映像或使用发行版映像 1.5 或更低版本,请运行以下命令以在 JupyterLab 环境中启用 SQL 浏览功能:
重新定位 SQL 浏览器小部件
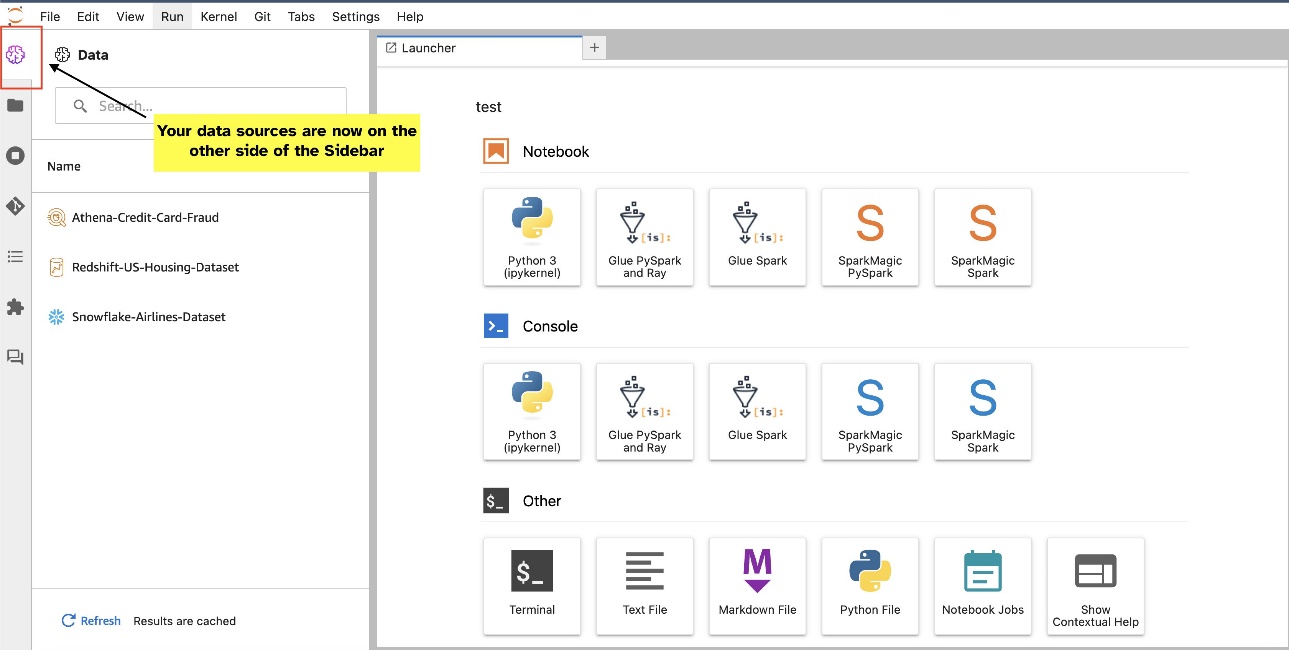
JupyterLab 小部件允许重新定位。根据您的偏好,您可以将小部件移动到 JupyterLab 小部件窗格的任一侧。如果您愿意,只需右键单击小部件图标并选择,即可将 SQL 小部件的方向移动到侧边栏的另一侧(从右到左) 切换侧边栏.
 |
 |
关于作者
 普拉纳夫·穆尔蒂 是 AWS 的 AI/ML 专家解决方案架构师。 他专注于帮助客户构建、训练、部署机器学习 (ML) 工作负载并将其迁移到 SageMaker。 他之前曾在半导体行业工作,开发大型计算机视觉 (CV) 和自然语言处理 (NLP) 模型,以使用最先进的 ML 技术改进半导体工艺。 空闲时间,他喜欢下棋和旅行。 您可以在以下位置找到普拉纳夫: LinkedIn.
普拉纳夫·穆尔蒂 是 AWS 的 AI/ML 专家解决方案架构师。 他专注于帮助客户构建、训练、部署机器学习 (ML) 工作负载并将其迁移到 SageMaker。 他之前曾在半导体行业工作,开发大型计算机视觉 (CV) 和自然语言处理 (NLP) 模型,以使用最先进的 ML 技术改进半导体工艺。 空闲时间,他喜欢下棋和旅行。 您可以在以下位置找到普拉纳夫: LinkedIn.
 瓦伦沙 是一名在 Amazon Web Services 的 Amazon SageMaker Studio 工作的软件工程师。他专注于构建交互式机器学习解决方案,以简化数据处理和数据准备过程。在业余时间,Varun 喜欢户外活动,包括徒步旅行和滑雪,并且总是乐于发现新的、令人兴奋的地方。
瓦伦沙 是一名在 Amazon Web Services 的 Amazon SageMaker Studio 工作的软件工程师。他专注于构建交互式机器学习解决方案,以简化数据处理和数据准备过程。在业余时间,Varun 喜欢户外活动,包括徒步旅行和滑雪,并且总是乐于发现新的、令人兴奋的地方。
 苏梅达斯瓦米 是 Amazon Web Services 的首席产品经理,他领导 SageMaker Studio 团队完成开发数据科学和机器学习首选 IDE 的使命。在过去的 15 年里,他致力于构建基于机器学习的消费者和企业产品。
苏梅达斯瓦米 是 Amazon Web Services 的首席产品经理,他领导 SageMaker Studio 团队完成开发数据科学和机器学习首选 IDE 的使命。在过去的 15 年里,他致力于构建基于机器学习的消费者和企业产品。
 博斯科阿尔伯克基 是 AWS 的高级合作伙伴解决方案架构师,在使用企业数据库供应商和云提供商的数据库和分析产品方面拥有 20 多年的经验。 他曾帮助科技公司设计和实施数据分析解决方案和产品。
博斯科阿尔伯克基 是 AWS 的高级合作伙伴解决方案架构师,在使用企业数据库供应商和云提供商的数据库和分析产品方面拥有 20 多年的经验。 他曾帮助科技公司设计和实施数据分析解决方案和产品。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

