克朗斯 为世界各地的啤酒厂、饮料装瓶商和食品生产商提供单独的机器和完整的生产线。每天,数以百万计的玻璃瓶、罐头和 PET 容器在克朗斯生产线上运行。生产线是复杂的系统,可能存在许多错误,这些错误可能会导致生产线停顿并降低产量。克朗斯希望尽早(有时甚至在故障发生之前)检测到故障,并通知生产线操作员以提高可靠性和产量。那么如何检测故障呢?克朗斯为其生产线配备了用于数据收集的传感器,然后可以根据规则进行评估。克朗斯作为生产线制造商以及生产线操作员可以为机器创建监控规则。因此,饮料装瓶商和其他操作员可以定义自己的生产线误差范围。过去,克朗斯使用基于时间序列数据库的系统。主要挑战是该系统难以调试,而且查询代表机器的当前状态,而不是状态转换。
这篇文章展示了克朗斯如何构建流媒体解决方案来监控其生产线,基于 亚马逊Kinesis 和 适用于 Apache Flink 的 Amazon 托管服务。这些完全托管的服务降低了使用 Apache Flink 构建流应用程序的复杂性。 Apache Flink 托管服务管理底层 Apache Flink 组件,提供持久的应用程序状态、指标、日志等,Kinesis 使您能够经济高效地处理任何规模的流数据。如果您想开始使用自己的 Apache Flink 应用程序,请查看 GitHub存储库 适用于使用 Flink 的 Java、Python 或 SQL API 的示例。
解决方案概述
克朗斯的生产线监控是 克朗斯车间指南 系统。它为公司所有活动的组织、优先级排序、管理和记录提供支持。如果机器停止或需要材料,他们可以通知操作员,无论操作员位于生产线的哪个位置。经过验证的状态监控规则已经内置,但也可以通过用户界面由用户定义。例如,如果监控的某个数据点违反阈值,则线路上可能会出现一条短信或触发维护订单。
状态监控和规则评估系统基于 AWS 构建,使用 AWS 分析服务。下图说明了该架构。
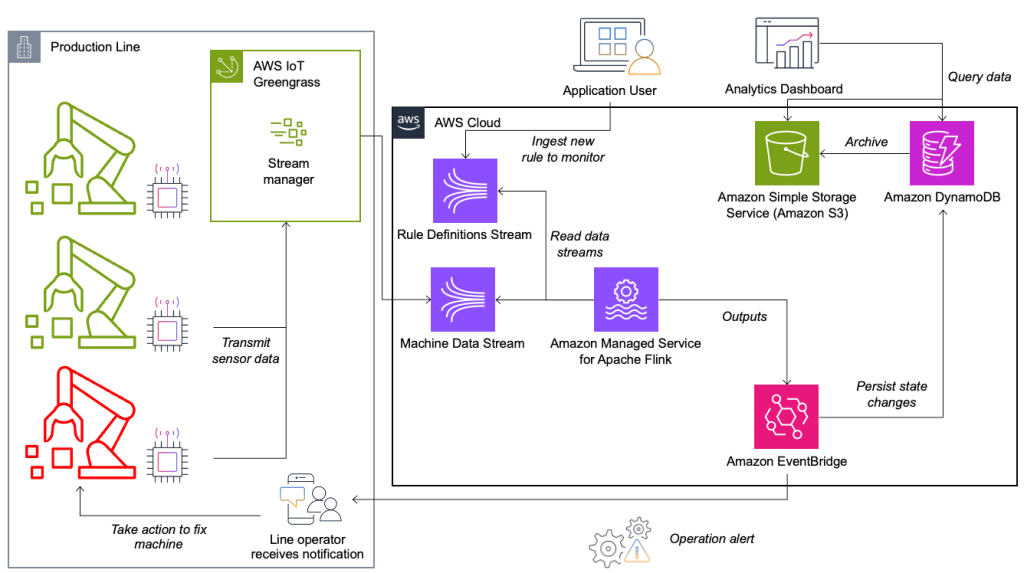
几乎每个数据流应用程序都由五层组成:数据源、流摄取、流存储、流处理以及一个或多个目的地。在以下部分中,我们将深入探讨每一层以及克朗斯构建的生产线监控解决方案的工作原理。
数据源
数据由边缘设备上运行的服务收集,该服务读取多种协议(例如西门子 S7 或 OPC/UA)。原始数据经过预处理以创建统一的 JSON 结构,这使得稍后在规则引擎中处理更容易。转换为 JSON 的示例负载可能如下所示:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}流摄取
AWS IoT Greengrass 是一种开源物联网 (IoT) 边缘运行时和云服务。这允许您在本地处理数据并聚合和过滤设备数据。 AWS IoT Greengrass 提供可部署到边缘的预构建组件。生产线解决方案使用流管理器组件,该组件可以处理数据并将其传输到AWS目的地,例如 AWS 物联网分析, 亚马逊简单存储服务 (亚马逊 S3)和 Kinesis。流管理器缓冲并聚合记录,然后将其发送到 Kinesis 数据流。
流存储
流存储的作用是以容错方式缓冲消息,并使其可供一个或多个消费者应用程序使用。为了在 AWS 上实现这一目标,最常见的技术是 Kinesis 和 适用于Apache Kafka的Amazon托管流 (亚马逊 MSK)。为了存储来自生产线的传感器数据,克朗斯选择了 Kinesis。 Kinesis 是一种无服务器流数据服务,可以在任何规模下以低延迟运行。 Kinesis 数据流中的分片是唯一标识的数据记录序列,其中流由一个或多个分片组成。每个分片具有 2 MB/s 的读取能力和 1 MB/s 的写入能力(最大 1,000 条记录/秒)。为了避免达到这些限制,数据应尽可能均匀地分布在分片之间。发送到 Kinesis 的每条记录都有一个分区键,用于将数据分组到分片中。因此,您希望拥有大量分区键来均匀分配负载。在 AWS IoT Greengrass 上运行的流管理器支持随机分区键分配,这意味着所有记录最终都位于随机分片中,并且负载均匀分布。随机分区键分配的缺点是记录未按顺序存储在 Kinesis 中。我们将在下一节中解释如何解决这个问题,其中我们将讨论水印。
水印
A 水印 是一种用于跟踪和测量数据流中事件时间进度的机制。事件时间是在源处创建事件时的时间戳。水印指示流处理应用程序的及时进度,因此具有较早或相等时间戳的所有事件都被视为已处理。这些信息对于 Flink 提前事件时间并触发相关计算(例如窗口评估)至关重要。可以配置事件时间和水印之间允许的滞后,以确定在考虑窗口完成并推进水印之前等待迟到数据的时间。
克朗斯的系统遍布全球,需要处理由于连接中断或其他网络限制而导致迟到的情况。他们首先监控迟到情况,并将默认的 Flink 迟到处理设置为他们在此指标中看到的最大值。他们遇到了边缘设备的时间同步问题,这导致他们采用了更复杂的水印方式。他们为所有发件人建立了全局水印,并使用最低值作为水印。所有传入事件的时间戳都存储在 HashMap 中。当定期发出水印时,将使用此 HashMap 的最小值。为了避免因丢失数据而导致水印停滞,他们配置了一个 idleTimeOut 参数,它忽略早于某个阈值的时间戳。这会增加延迟,但会提供很强的数据一致性。
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
流处理
从传感器收集数据并摄入 Kinesis 后,需要由规则引擎对其进行评估。该系统中的规则表示单个指标(例如温度)或指标集合的状态。为了解释一项指标,需要使用多个数据点,这是一种有状态计算。在本节中,我们将深入探讨 Apache Flink 中的键控状态和广播状态,以及如何使用它们构建克朗斯规则引擎。
控制流和广播状态模式
在 Apache Flink 中, 州 是指系统跨时间和跨操作持久存储和管理信息的能力,从而能够在支持状态计算的情况下处理流数据。
广播状态模式 允许将状态分配给操作符的所有并行实例。因此,所有算子都具有相同的状态,并且可以使用该相同的状态来处理数据。可以使用控制流来摄取此只读数据。控制流是常规数据流,但通常具有低得多的数据速率。此模式允许您动态更新所有运算符的状态,使用户能够更改应用程序的状态和行为,而无需重新部署。更准确地说,状态的分配是通过使用控制流来完成的。通过将新记录添加到控制流中,所有操作员都会收到此更新并使用新状态来处理新消息。
这允许克朗斯应用程序的用户将新规则引入 Flink 应用程序,而无需重新启动它。这可以避免停机,并在实时发生变化时提供出色的用户体验。规则涵盖场景以检测过程偏差。有时,机器数据并不像乍一看那么容易解释。如果温度传感器发送高值,这可能表明存在错误,但也可能是持续维护过程的影响。将指标放在上下文中并过滤某些值非常重要。这是通过一个称为 分组.
指标分组
数据和指标的分组允许您定义传入数据的相关性并生成准确的结果。让我们看一下下图中的示例。
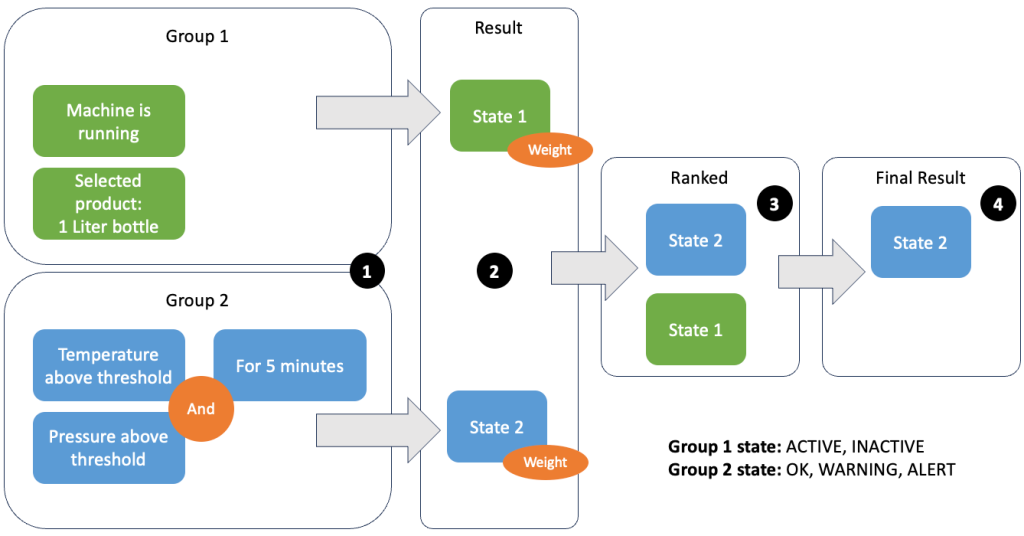
在步骤 1 中,我们定义两个条件组。第 1 组收集机器状态以及正在通过生产线的产品。第 2 组使用温度和压力传感器的值。条件组可以根据其接收的值具有不同的状态。本例中,组1接收到机器正在运行的数据,选择一升瓶作为产品;这给了这个组状态 ACTIVE。第 2 组有温度和压力指标;两个指标均高于其阈值超过 5 分钟。这导致第 2 组处于 WARNING 状态。这意味着第 1 组报告一切正常,而第 2 组则不然。在步骤 2 中,将权重添加到组中。在某些情况下这是必要的,因为团体可能会报告相互矛盾的信息。在这种情况下,组 1 报告 ACTIVE 和第2组报告 WARNING,因此系统不清楚线路的状态是什么。添加权重后,可以对各州进行排名,如步骤 3 所示。最后,选择排名最高的州作为获胜州,如步骤 4 所示。
在评估规则并定义最终机器状态后,将进一步处理结果。采取的操作取决于规则配置;这可以是通知生产线操作员补充材料、进行一些维护,或者只是仪表板上的视觉更新。系统的这一部分评估指标和规则并根据结果采取行动,被称为 规则引擎.
扩展规则引擎
通过让用户构建自己的规则,规则引擎可以拥有需要评估的大量规则,并且某些规则可能使用与其他规则相同的传感器数据。 Flink 是一个分布式系统,水平扩展非常好。要将数据流分配给多个任务,您可以使用 keyBy() 方法。这允许您以逻辑方式对数据流进行分区,并将部分数据发送到不同的任务管理器。这通常是通过选择任意密钥来完成的,这样您就可以获得均匀分布的负载。在这种情况下,克朗斯添加了一个 ruleId 到数据点并将其用作密钥。否则,所需的数据点将由另一个任务处理。键控数据流可以像常规变量一样在所有规则中使用。
目的地
当规则更改其状态时,信息将发送到 Kinesis 流,然后通过 亚马逊EventBridge 给消费者。一名消费者根据事件创建通知,并将其传输到生产线并提醒人员采取行动。为了能够分析规则状态更改,另一个服务将数据写入 Amazon DynamoDB 表用于快速访问,并且 TTL 可以将长期历史记录卸载到 Amazon S3 以进行进一步报告。
结论
在这篇文章中,我们向您展示了克朗斯如何在 AWS 上构建实时生产线监控系统。 Apache Flink 托管服务使克朗斯团队能够通过专注于应用程序开发而不是基础设施来快速入门。 Flink 的实时功能使克朗斯能够将机器停机时间减少 10%,并将效率提高高达 5%。
如果您想构建自己的流应用程序,请查看以下网站上的可用示例 GitHub存储库。如果您想使用自定义连接器扩展 Flink 应用程序,请参阅 使用 Apache Flink 更轻松地构建连接器:引入异步接收器。 Async Sink 在 Apache Flink 版本 1.15.1 及更高版本中可用。
作者简介
 弗洛里安·梅尔 是 AWS 的高级解决方案架构师和数据流专家。他是一名技术专家,通过使用 AWS 云服务解决业务挑战,帮助欧洲客户取得成功和创新。除了担任解决方案架构师之外,弗洛里安还是一位充满热情的登山家,曾攀登过欧洲一些最高的山脉。
弗洛里安·梅尔 是 AWS 的高级解决方案架构师和数据流专家。他是一名技术专家,通过使用 AWS 云服务解决业务挑战,帮助欧洲客户取得成功和创新。除了担任解决方案架构师之外,弗洛里安还是一位充满热情的登山家,曾攀登过欧洲一些最高的山脉。
 埃米尔·迪特尔 是克朗斯的高级技术主管,专门从事数据工程,关键领域是 Apache Flink 和微服务。他的工作经常涉及关键任务软件的开发和维护。在职业生活之外,他非常重视与家人共度美好时光。
埃米尔·迪特尔 是克朗斯的高级技术主管,专门从事数据工程,关键领域是 Apache Flink 和微服务。他的工作经常涉及关键任务软件的开发和维护。在职业生活之外,他非常重视与家人共度美好时光。
 西蒙·佩尔 是位于瑞士的 AWS 的解决方案架构师。他是一位务实的实干家,热衷于使用 AWS 云服务连接技术和人员。他特别关注数据流和自动化。除了工作之外,西蒙还享受家庭、户外活动和山间徒步旅行。
西蒙·佩尔 是位于瑞士的 AWS 的解决方案架构师。他是一位务实的实干家,热衷于使用 AWS 云服务连接技术和人员。他特别关注数据流和自动化。除了工作之外,西蒙还享受家庭、户外活动和山间徒步旅行。

