介绍
在计算机视觉中,存在不同的活体物体检测技术,包括更快 RCNN, SSD及 YOLO。每种技术都有其局限性和优点。虽然 Faster R-CNN 可能在准确性方面表现出色,但它在实时场景中的表现可能不佳,这促使人们转向 YOLO算法。
对象检测是计算机视觉的基础,使机器能够识别和定位框架或屏幕内的对象。多年来,人们开发了各种目标检测算法,其中 YOLO 成为最成功的算法之一。最近,YOLOv8的推出,进一步增强了算法的能力。
在本综合指南中,我们探讨了三种著名的目标检测算法:Faster R-CNN、SSD(单次多框检测器)和 YOLOv8。我们讨论实现这些算法的实际问题,包括设置虚拟环境和开发 Streamlit 应用程序。
学习目标
- 了解Faster R-CNN、SSD、YOLO,并分析它们之间的差异。
- 获得使用 OpenCV、Supervision 和 YOLOv8 实现活体物体检测系统的实践经验。
- 使用 Roboflow 注释了解图像分割模型。
- 创建 Streamlit 应用程序以获得简单的用户界面。
让我们探索一下如何使用 YOLOv8 进行图像分割!
目录
这篇文章是作为 数据科学博客马拉松。
更快的R-CNN
Faster R-CNN(Faster Region-based Convolutional Neural Network)是一种基于深度学习的目标检测算法。它使用 R-CNN 和 Fast R-CNN 框架进行评估,可以被视为 Fast R-CNN 的扩展。
该算法引入了区域提议网络(RPN)来生成区域提议,取代了 R-CNN 中使用的选择性搜索。 RPN 与检测网络共享卷积层,从而实现高效的端到端训练。
然后,生成的区域建议被输入到 Fast R-CNN 网络中,以进行边界框细化和对象分类。
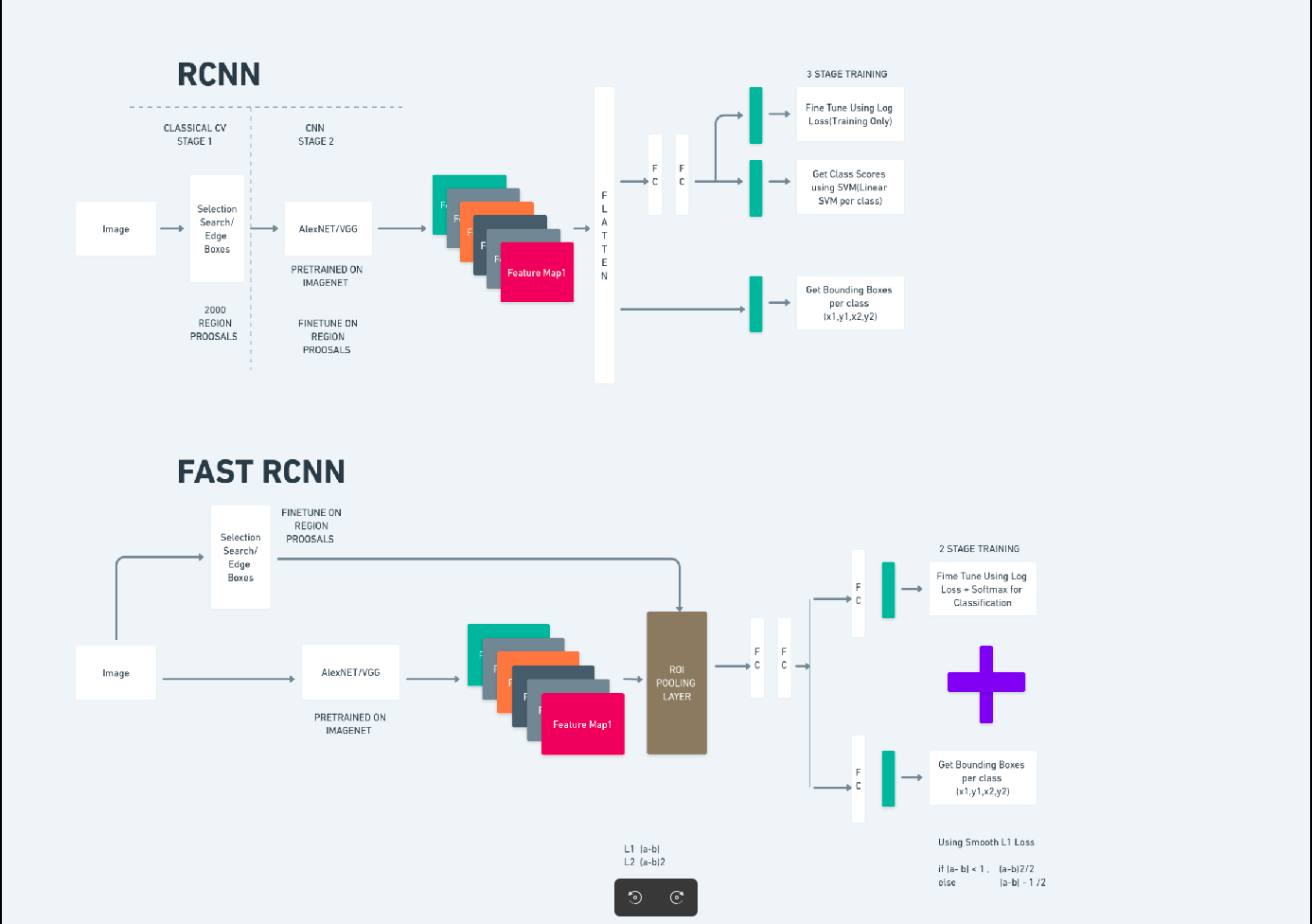
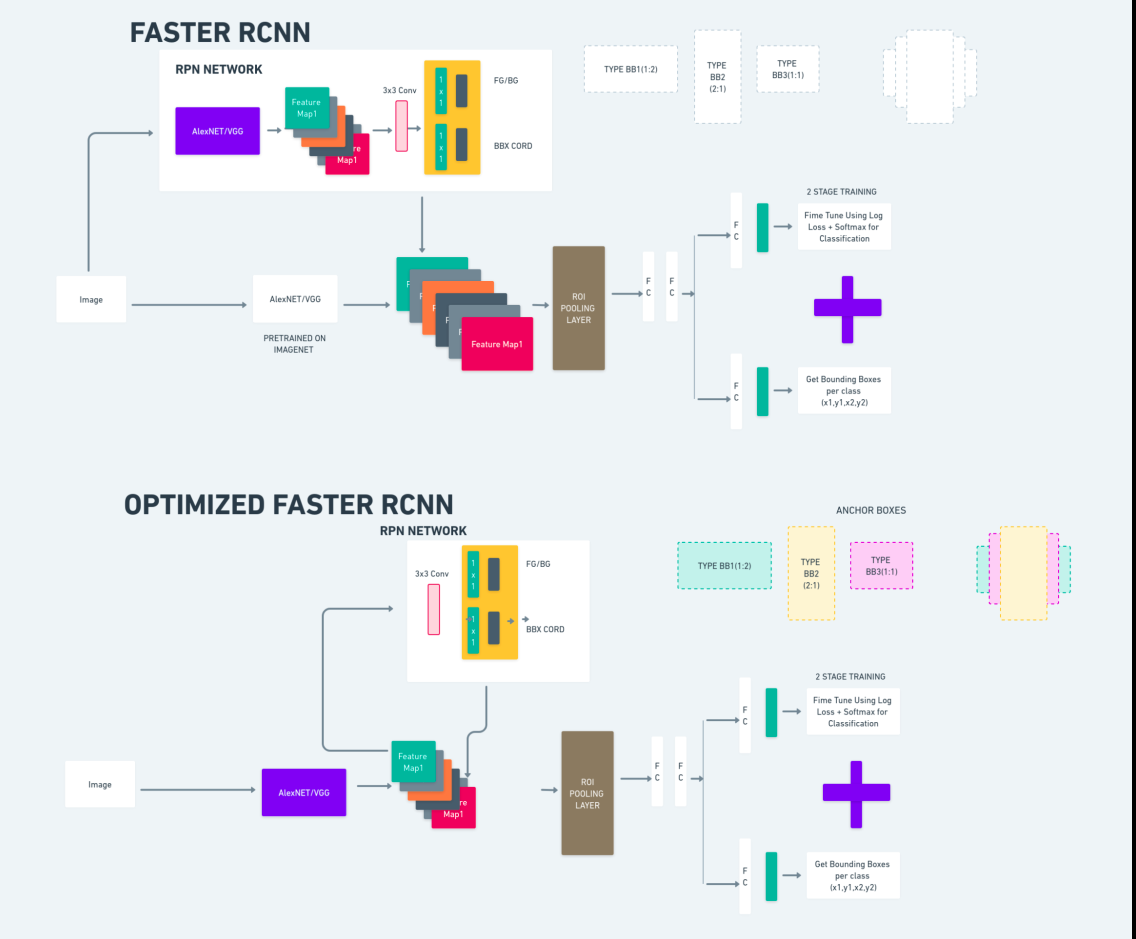
上图全面说明了 Faster R-CNN 系列,并且易于理解以评估每种算法。
单次多盒探测器(SSD)
单次多盒探测器 (SSD)在物体检测中很流行,主要用于计算机视觉任务。在之前的方法 Faster R-CNN 中,我们遵循两个步骤:第一步涉及检测部分,第二步涉及回归。然而,对于 SSD,我们只执行单个检测步骤。 SSD 于 2016 年推出,旨在满足快速、准确的目标检测模型的需求。

与 Faster R-CNN 等早期目标检测方法相比,SSD 具有多个优势:
- 效率:SSD 是一种单级检测器,这意味着它可以直接预测边界框和类别分数,而不需要单独的提案生成步骤。这使得它比 Faster R-CNN 等两级检测器更快。
- 端到端训练:SSD可以进行端到端训练,联合优化基础网络和检测头,从而简化了训练过程。
- 多尺度特征融合:SSD在多个尺度的特征图上运行,使其能够更有效地检测不同尺寸的物体。
SSD在速度和精度之间取得了良好的平衡,使其适合性能和效率都至关重要的实时应用。
你只看一次(YOLOv8)
2015 年,Joseph Redmon、Santosh Divvala、Ross Girshick 和 Ali Farhadi 在一篇研究论文中引入了 You Only Look Once (YOLO) 作为一种对象检测算法。 YOLO 是一种单次算法,通过仅一个神经网络使用完整图像作为输入来预测边界框和类概率,从而在单次传递中直接对对象进行分类。
现在,让我们将 YOLOv8 理解为实时目标检测领域最先进的进步,具有更高的准确性和速度。 YOLOv8 允许您利用预先训练的模型,这些模型已经在 COCO(上下文中的通用对象)等庞大数据集上进行了训练。图像分割提供有关每个对象的像素级信息,从而能够更详细地分析和理解图像内容。
虽然图像分割的计算成本可能很高,但 YOLOv8 将此方法集成到其神经网络架构中,从而实现高效、准确的对象分割。
YOLOv8的工作原理
YOLOv8 工作原理是首先将输入图像划分为网格单元。使用这些网格单元,YOLOv8 可以预测具有类别概率的边界框 (bbox)。
之后,YOLOv8采用NMS算法来减少重叠。例如,如果图像中存在多辆汽车,导致边界框重叠,NMS 算法有助于减少这种重叠。
Yolo V8 变体之间的差异:YOLOv8 提供三种变体:YOLOv8、YOLOv8-L 和 YOLOv8-X。变体之间的主要区别在于主干网络的大小。 YOLOv8具有最小的主干网络,而YOLOv8-X具有最大的主干网络。
区别 Faster R-CNN、SSD 和 YOLO 之间
| 方面 | 更快的R-CNN | SSD | YOLO |
|---|---|---|---|
| 建筑 | 具有 RPN 和 Fast R-CNN 的两级检测器 | 单级探测器 | 单级探测器 |
| 地区提案 | USB MIDI(XNUMX通道) | 没有 | 没有 |
| 检测速度 | 与 SSD 和 YOLO 相比速度较慢 | 比 Faster R-CNN 更快,比 YOLO 慢 | 速度非常快 |
| 准确性 | 一般精度较高 | 平衡精度和速度 | 不错的准确性,特别是对于实时应用程序 |
| 高度灵活 | 灵活,可以处理各种物体尺寸和长宽比 | 可以处理多种尺寸的物体 | 难以准确定位小物体 |
| 统一检测 | 没有 | 没有 | USB MIDI(XNUMX通道) |
| 速度与准确性的权衡 | 通常为了准确性而牺牲速度 | 平衡速度和准确性 | 优先考虑速度,同时保持良好的准确性 |
什么是分段?
众所周知,分割意味着我们根据某些特征将大图像分成更小的组。让我们了解图像分割,这是一种计算机视觉技术,用于将图像分割成不同的多个片段或区域。由于图像是由像素组成的,因此在图像分割中,像素根据颜色、强度、纹理或其他视觉属性的相似性分组在一起。
例如,如果图像包含树木、汽车或人,那么图像分割会将图像划分为不同的类,这些类代表有意义的对象或图像的部分。图像分割广泛应用于医学成像、卫星图像分析、计算机视觉中的对象识别等不同领域。

在分割部分,我们首先使用 Robflow 创建第一个 YOLOv8 分割模型。然后,我们导入分割模型来执行分割任务。问题出现了:当单独使用检测算法就可以完成任务时,为什么我们还要创建分割模型?
分割使我们能够获得一个类的全身图像。虽然检测算法专注于检测对象的存在,但分割通过描绘对象的确切边界提供了更精确的理解。这可以更准确地定位和理解图像中存在的对象。
然而,与检测算法相比,分割通常涉及更高的时间复杂度,因为它需要额外的步骤,例如分离注释和创建模型。尽管存在这一缺点,但在精确对象描绘至关重要的任务中,分割提供的更高精度可能会超过计算成本。
使用 YOLOv8 逐步进行活体检测和图像分割
在此概念中,我们将探索使用 conda 创建虚拟环境、激活 venv 以及使用 pip 安装需求包的步骤。首先创建普通的 python 脚本,然后创建 Streamlit 应用程序。
Step1:使用Conda创建虚拟环境
conda create -p ./venv python=3.8 -yStep2:激活虚拟环境
conda activate ./venv
步骤3:创建requirements.txt
打开终端并粘贴以下脚本:
touch requirements.txt步骤4:使用Nano命令并编辑requirements.txt
创建requirements.txt后,编写以下命令来编辑requirements.txt
nano requirements.txt运行上面的脚本后你可以看到这个UI。
写下她需要的包。
ultralytics==8.0.32
supervision==0.2.1
streamlit然后按 “ctrl+o”(此命令保存编辑部分)然后按 “输入”
按下“Ctrl+x”。 您可以退出该文件。并走向主路。
步骤5:安装requirements.txt
pip install -r requirements.txt第六步:创建Python脚本
在终端中编写以下脚本或者我们可以说命令。
touch main.py创建 main.py 后,打开 VS Code,在终端中使用命令 write,
code 第7步:编写Python脚本
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
运行此命令后,您可以看到相机已打开并检测到您的一部分。比如性别和背景部分。
Step7:创建streamlit应用程序
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
在此脚本中,我们将创建 Streamlit 应用程序并创建按钮,以便在按下按钮后您的设备摄像头将打开并检测框架中的部件。
使用此命令运行此脚本。
streamlit run app.py
# first create the app.py then paste the above code and run this script.运行上述命令后,假设您遇到了类似以下的伸出错误:
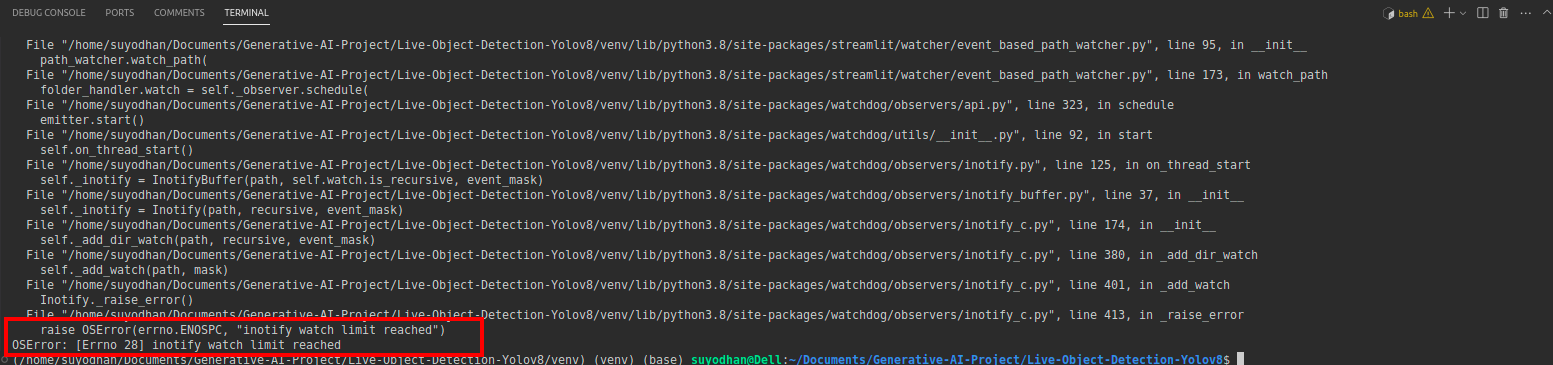
然后按这个命令,
sudo sysctl fs.inotify.max_user_watches=524288点击命令后,您要写入密码,因为我们使用 sudo 命令 sudo 是上帝:)
再次运行脚本。您可以看到精简的应用程序。
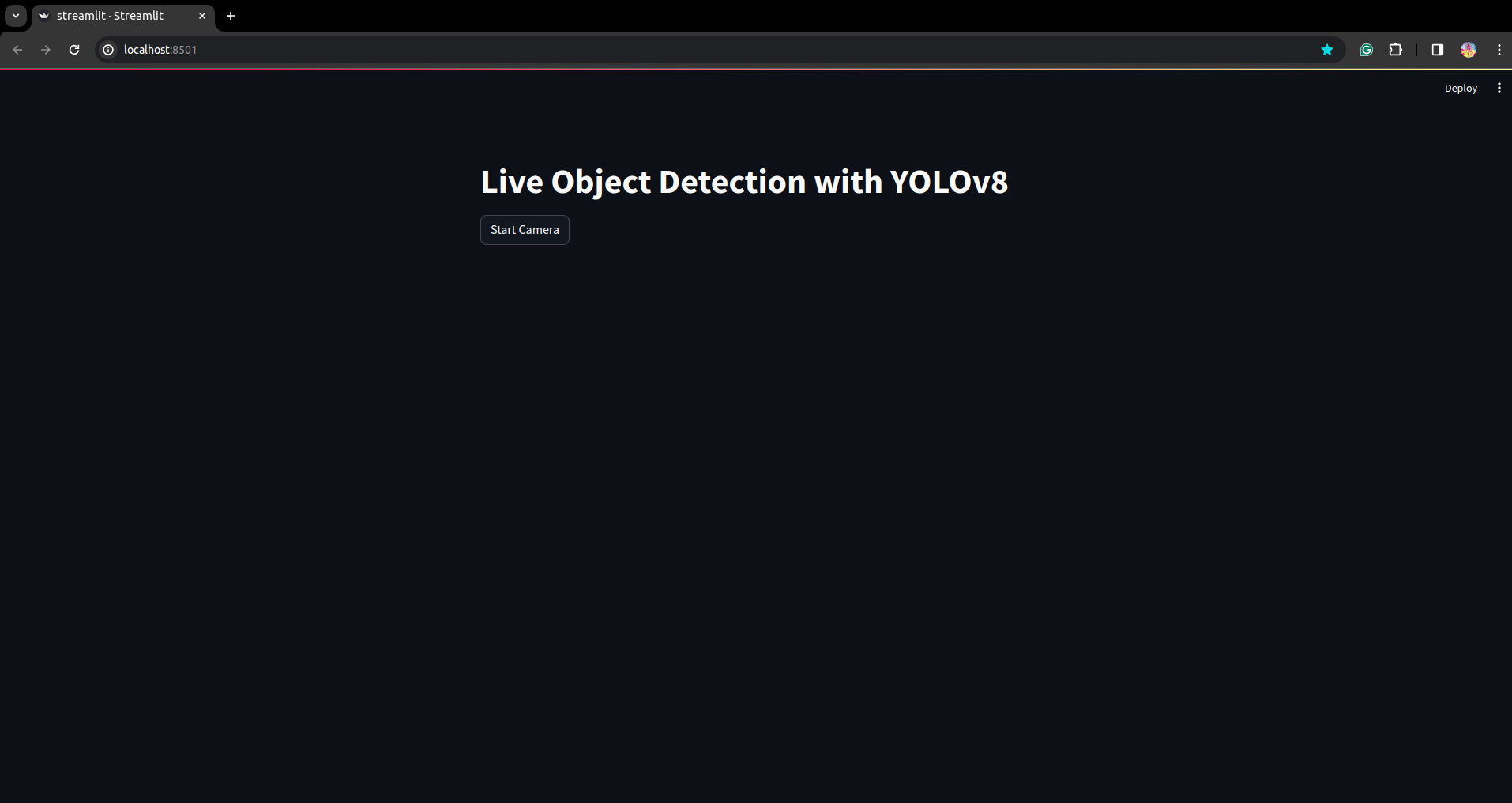
在这里,我们可以创建一个成功的活体检测应用程序,在下一部分中我们将看到分割部分。
注释步骤
第 1 步:Roboflow 设置
签署后“创建项目”。 在这里您可以创建项目和注释组。

Step2:数据集下载
这里我们考虑一个简单的例子,但你想在你的问题陈述中使用它,所以我在这里使用鸭子数据集。
去这个 链接 并下载鸭子数据集。

解压该文件夹,您可以看到三个文件夹: 训练、测试和验证。
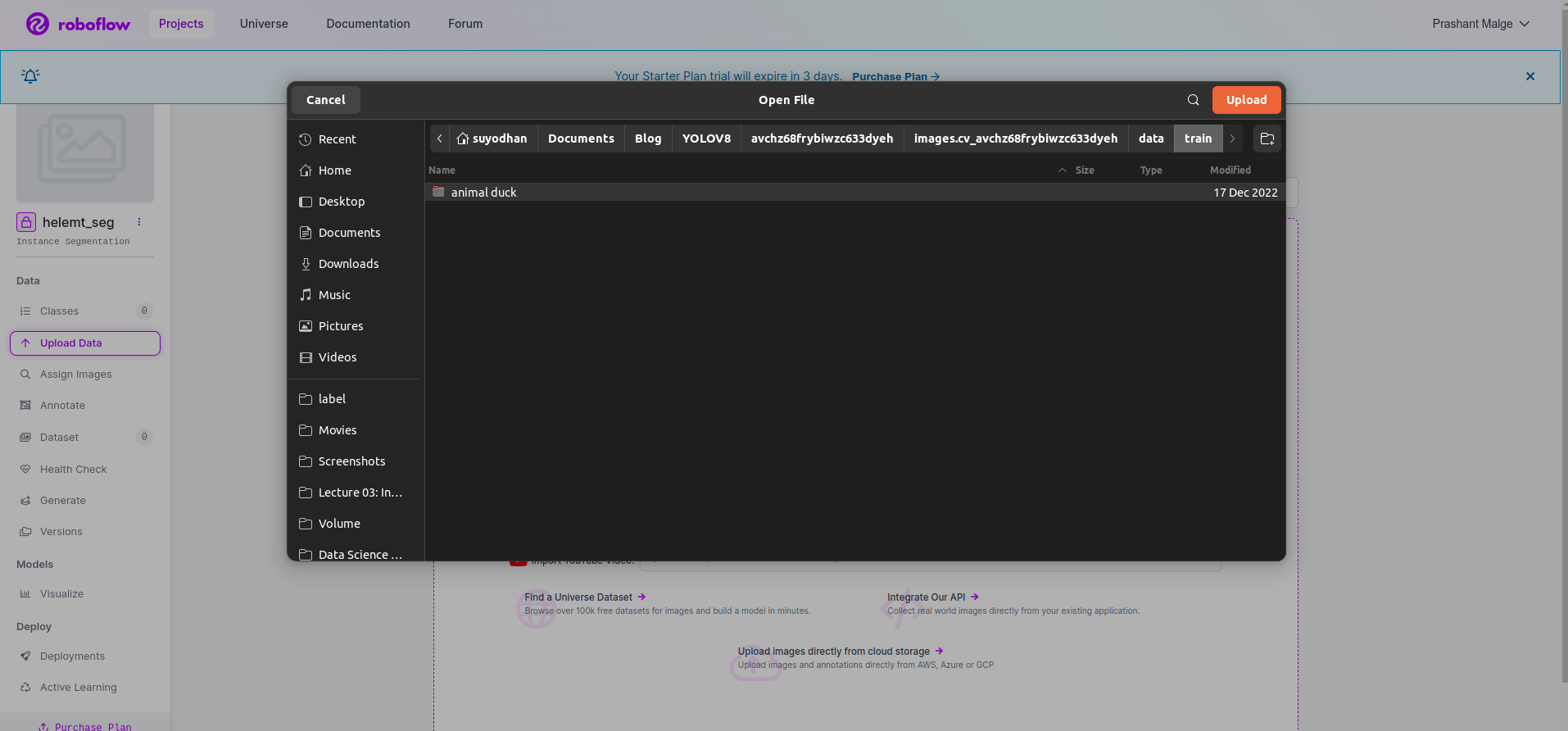
Step3:将数据集上传到roboflow
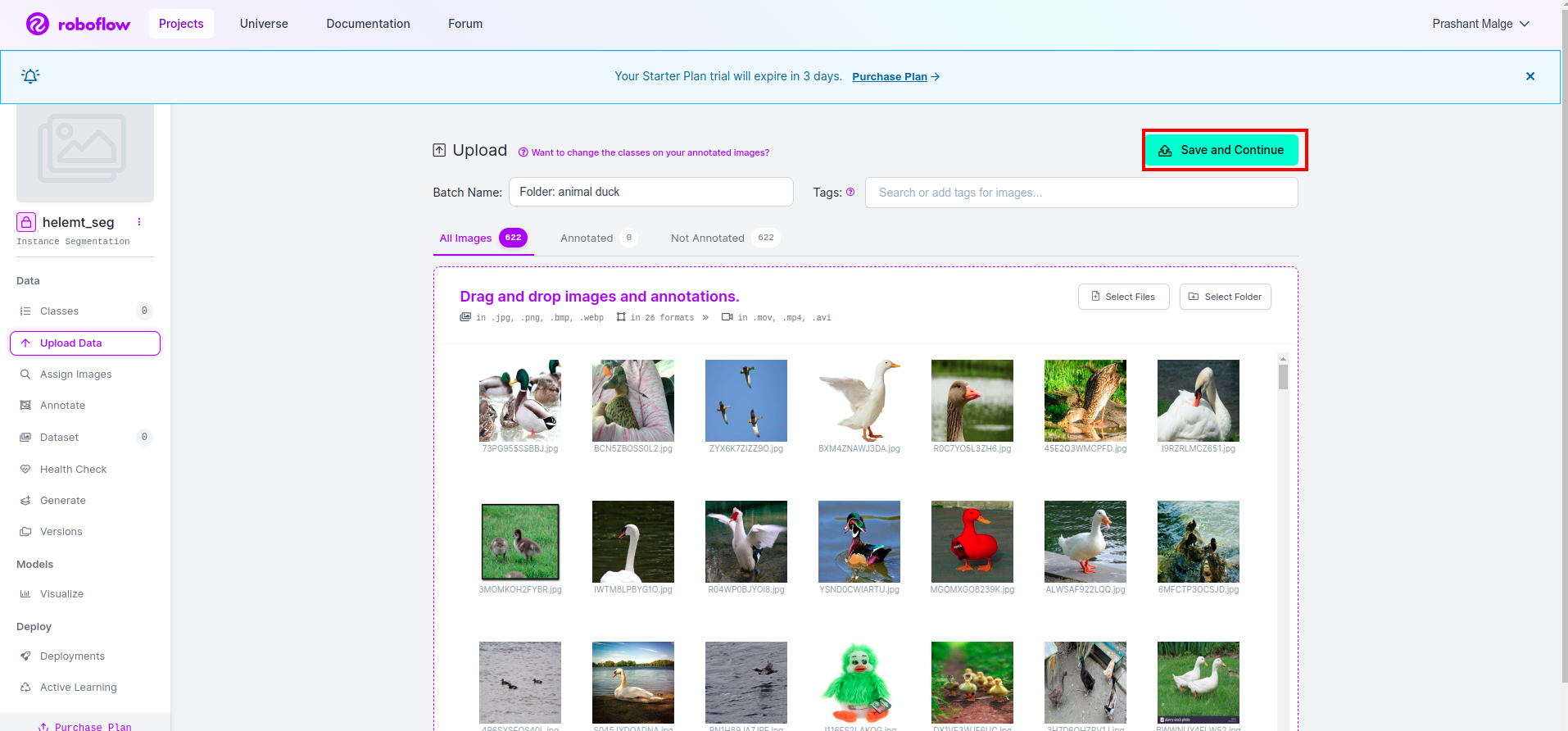
在 roboflow 中创建项目后,您可以在此处看到此 UI,您可以上传数据集,因此仅上传火车部件图像,选择“选择文件夹” 选项。
然后点击“保存并继续” 我在红色矩形框中标记的选项
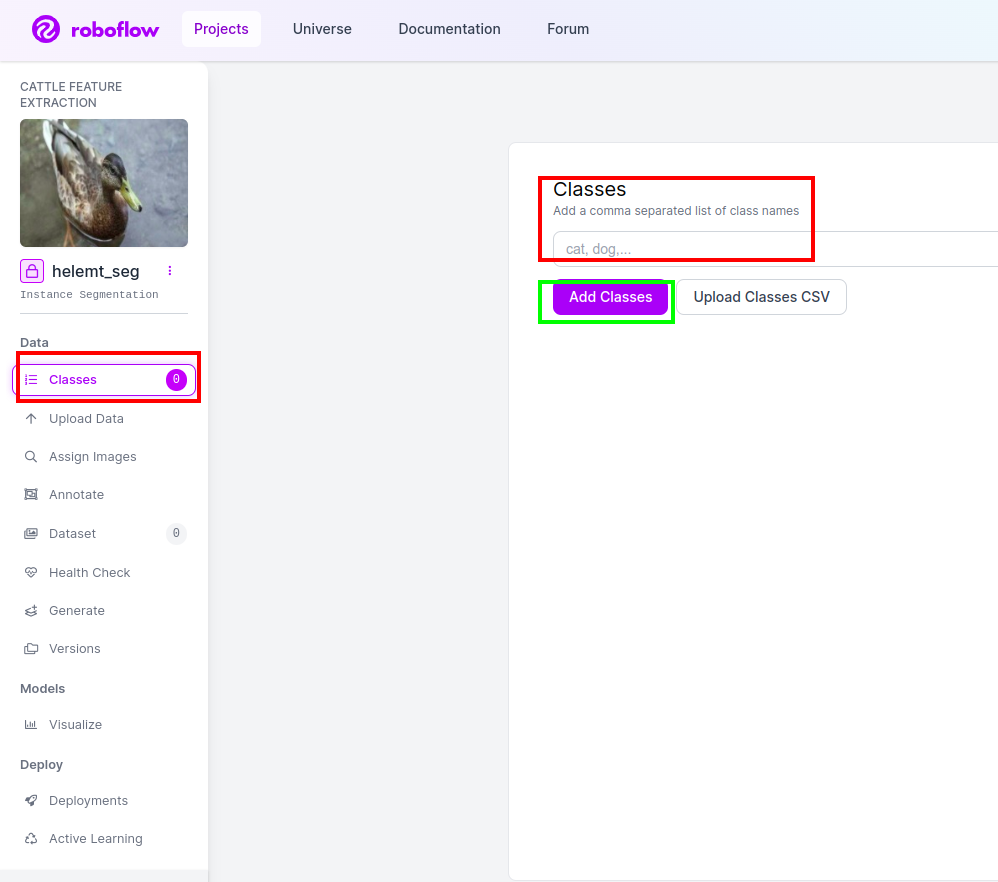
第四步:添加类名
然后去看看 班级部分 选中左侧的红色框。并将类名写为 鸭子, 单击绿色框后。
现在我们的设置已经完成,下一部分(例如注释部分)也很简单。
第五步:启动 注释部分
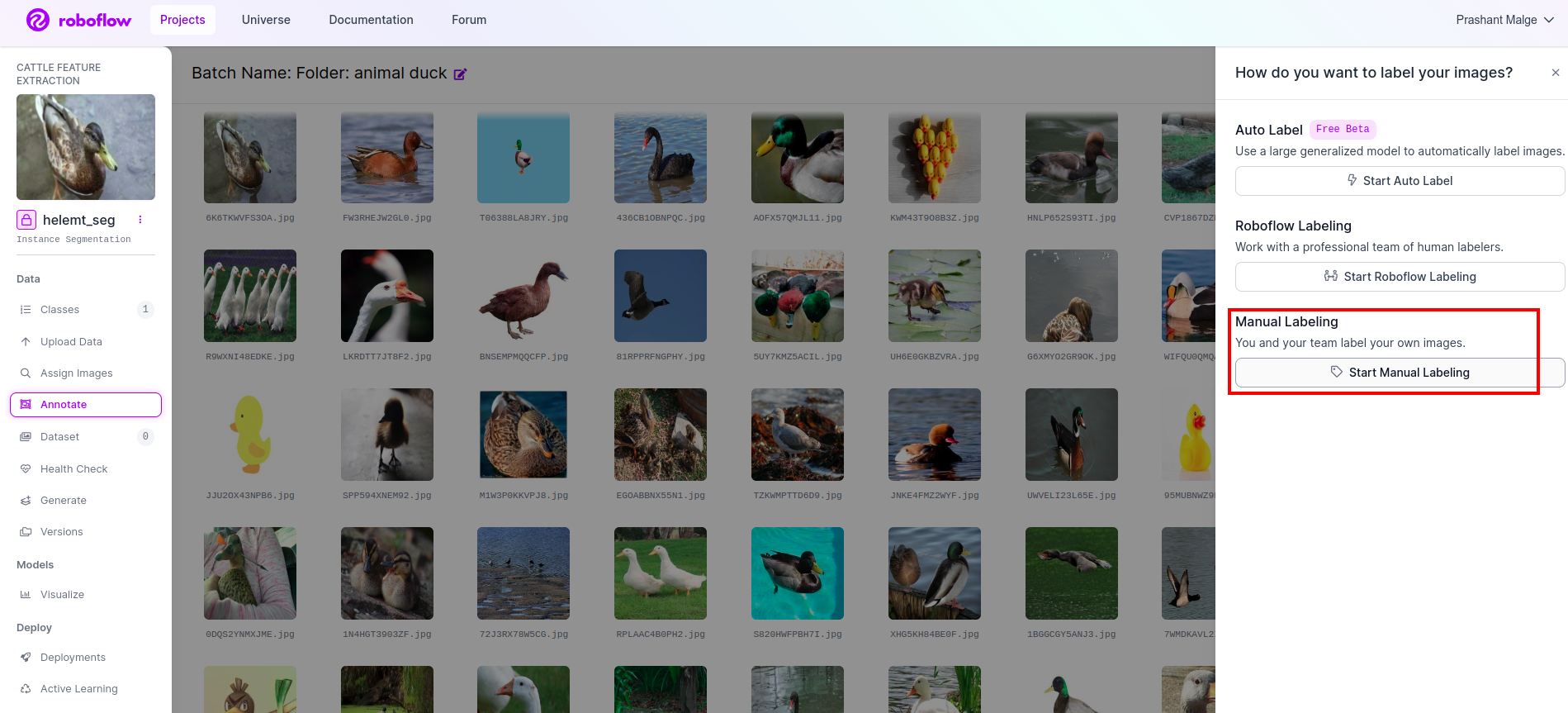
去 注释选项 我在红色框中标记,然后单击开始注释部分,如我在绿色框中标记的那样。
单击第一张图片您可以看到此 UI。看到此内容后,单击手动注释选项。
然后添加您的电子邮件 ID 或队友的姓名,以便您可以分配任务。
单击第一张图片您可以看到此 UI。这里单击红色框,以便您可以选择多项式模型。
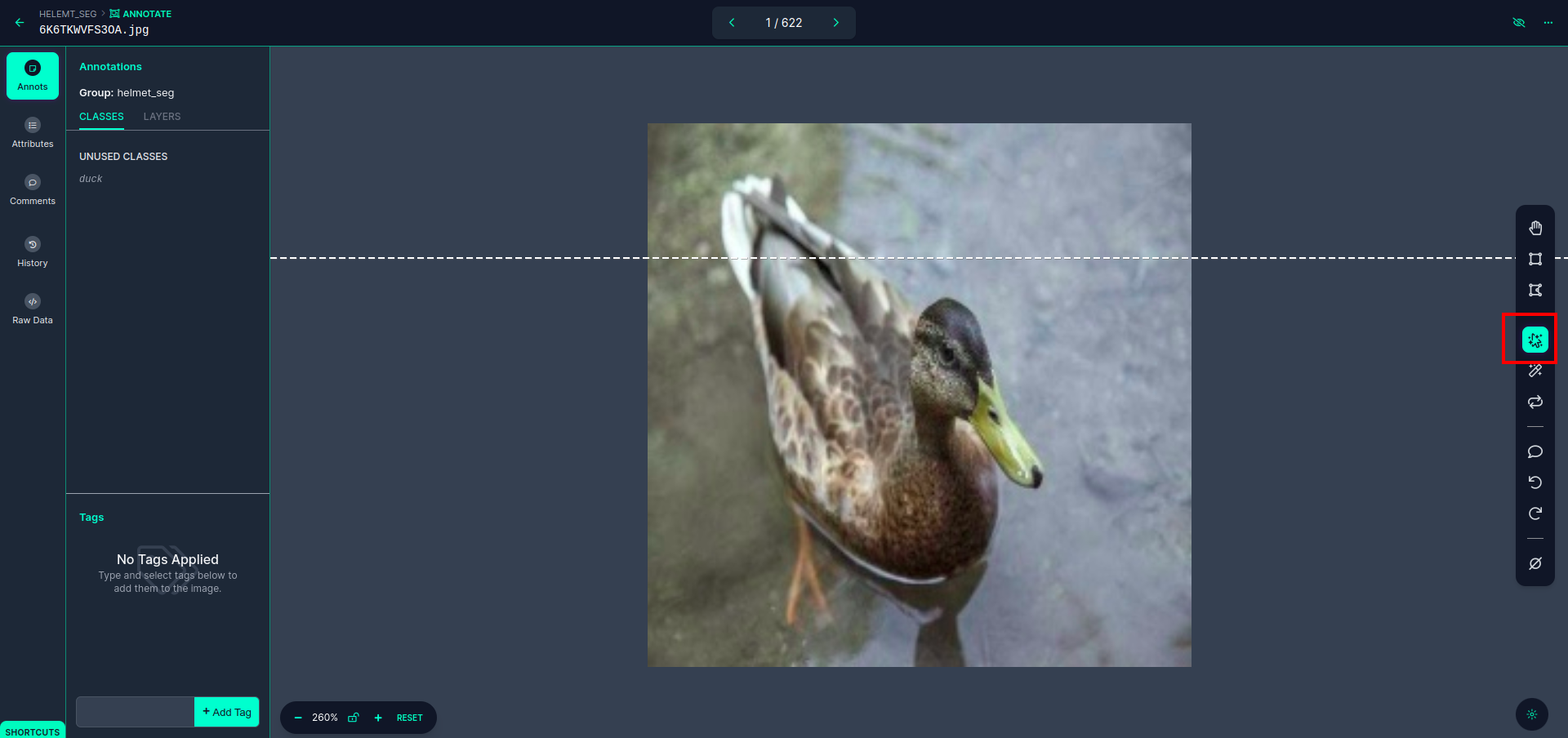
单击红框后,选择默认模型,然后单击鸭子对象。这将自动分割图像。然后,单击下一部分并保存。然后您将看到左侧标记为红色框,您可以在其中看到类名称。
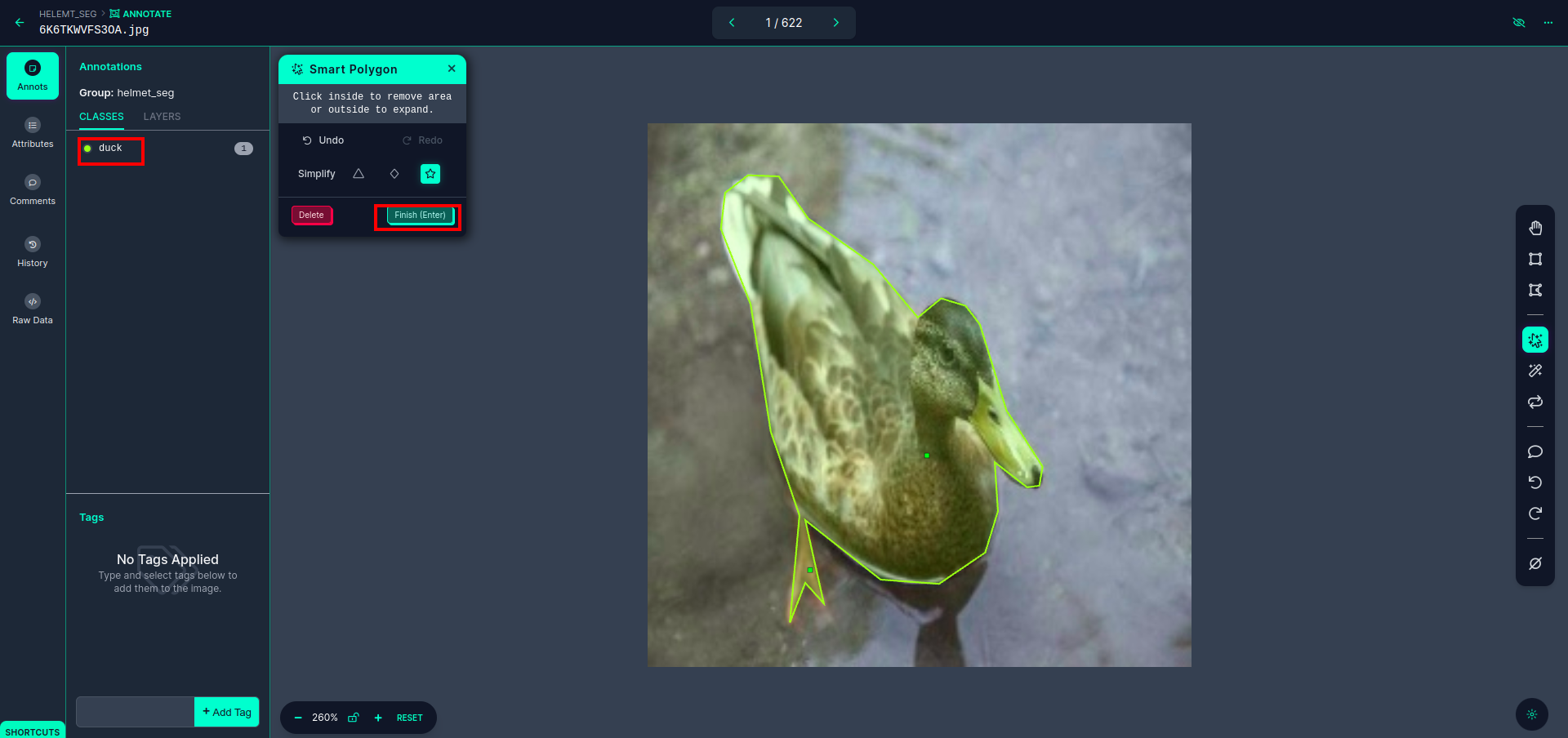
点击 保存并输入 选项。注释所有图像。
添加 YOLOv8 格式的图像。在右侧,您将看到在注释部分添加图像的选项。在这里,创建了两部分:一部分用于带注释的图像,另一部分用于未注释的图像。
- 首先,点击左侧“注释” 然后选择 加 图片 到数据集。
- 然后点击下一步“添加图片“。
最后,我们创建数据集,因此单击左侧的“生成”选项,然后选中该选项并按 conitune 选项。
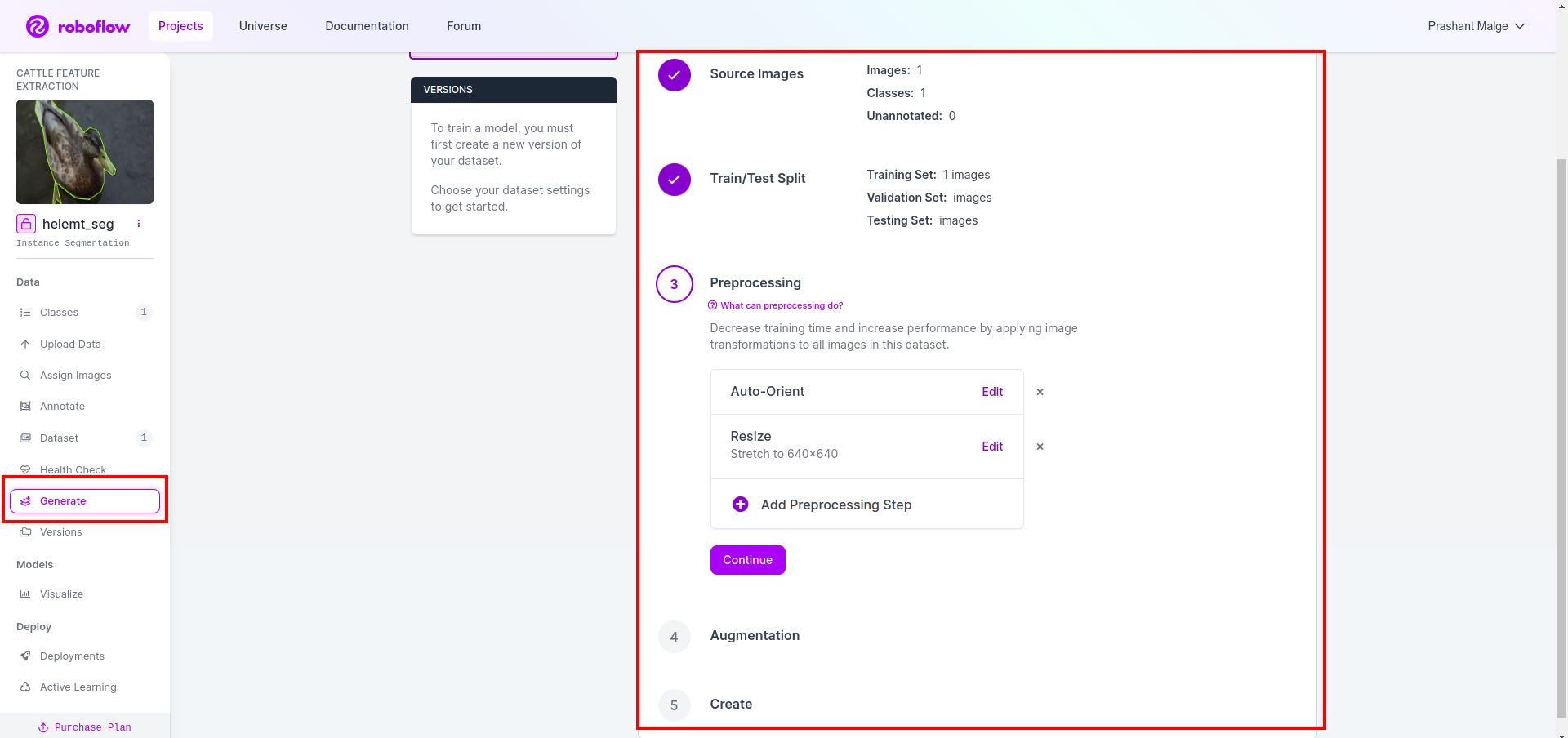
然后您将在此处获得数据集拆分选项的 UI,您可以检查图像自动拆分的训练、测试和 val 文件夹。然后点击上面的红框 导出数据集选项 并下载 zip 文件。 zip 文件夹结构类似于...
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Step6:编写训练图像分割模型的脚本
首先,在本部分中,您将使用 Drive 创建 Google Collab 文件,然后上传数据集。并使用 Google Collab 移动 Google Drive。
1. 使用此命令 挂载 Google 云端硬盘
from google.colab import drive
drive.mount('/content/gdrive')2. 定义数据目录 使用常量变量。
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. 安装所需的包, 安装超解
!pip install ultralytics4. 导入库
import os
from ultralytics import YOLO5.负载 预训练的 YOLOv8 型号(这里我们有不同的型号,还可以查看官方文档,您可以看到不同的型号)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. 训练模型
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together 否检查您的驱动器创建模型名称文件夹,并保存模型以用于我们想要此模型的预测。
7. 预测模型
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)在这里可以看到分割图像已保存。

现在我们终于可以构建活体检测和图像分割模型了。
结论
在本博客中,我们将探讨使用 YOLOv8 进行活体目标检测和图像分割。对于活体检测,我们导入预先训练的 YOLOv8 模型,并利用计算机视觉库 OpenCV 打开相机并检测物体。此外,我们还创建了一个 Streamlit 应用程序,以提供有吸引力的用户界面。
接下来,我们深入研究 YOLOv8 的图像分割。我们导入预先训练的模型并在自定义数据集上执行迁移学习。在此之前,我们探索了用于数据集注释的 Roboflow,为诸如 标签图像.
最后,我们预测包含鸭子的图像。尽管图像中的对象看起来是一只鸟,但我们将类名称指定为“鸭”用于演示目的。
关键精华
- 了解 Faster R-CNN、SSD 和最新的 YOLOv8 等对象检测模型。
- 了解注释工具 Roboflow 及其在为 YOLOv8 分割模型创建数据集方面的作用。
- 探索使用 OpenCV (cv2) 和 Supervision 进行活体物体检测,增强实践技能。
- 使用 YOLOv8 训练和部署分割模型,获得实践经验。
常见问题解答
答:对象检测涉及识别和定位图像中的多个对象,通常是通过在对象周围绘制边界框来识别和定位。另一方面,图像分割根据像素相似性将图像划分为片段或区域,从而提供对对象边界的更详细的理解。
答:YOLOv8 通过融合网络架构、训练技术和优化方面的进步,对之前的版本进行了改进。与 YOLOv3 相比,它可以提供更好的准确性、速度和效率。
A. YOLOv8可以用于嵌入式设备上的实时物体检测,具体取决于硬件能力和模型优化。然而,它可能需要模型修剪或量化等优化才能在资源受限的设备上实现实时性能。
答:Roboflow 提供直观的注释工具、数据集管理功能以及对各种注释格式的支持。它简化了注释过程,支持协作并提供版本控制,从而更轻松地创建和管理计算机视觉项目的数据集。

