


我们想知道是否可以将生成模型应用于内容合成问题,以使图形设计师的工作自动化。 所以我们专注于标识综合并检查了这个假设。 我们的目标是找出该技术的可能性和局限性,以及其在图像生成中的应用前景。
为了创建独特的图标并探索图像生成如何与生成模型一起工作,MobiDev 的 人工智能团队 使用了最强大的生成架构之一——StyleGan2。 在人工智能的帮助下,生成图形界面元素和其他组件的任务通常需要人类设计师来完成,这具有巨大的潜力,并且仍处于早期阶段。
本文将解释结果如何,以及我们在解决这个问题时遇到了哪些障碍。
GAN 图像生成的预处理操作——基于文本的图像去除、聚类、最近图像搜索
我们使用了两个数据源进行研究——来自 LLD-logo 数据集 和 51,744 张图片来自 升压LLD. 不幸的是,BoostedLLD 仅包含 15,000 张真正的新图像,而其余的则取自 LLD-logo。 在被馈送到 StyleGAN2 以在未来接收 GAN 生成的图像之前,对数据进行了预处理,其总大小减少到 48,652 张图像。
即使最近 GAN 的架构有所改进,训练生成模型也可能是一项艰巨的任务。 造成这种情况的原因是此类模型固有的不稳定性以及缺乏监督指标来评估输出。
因此,在将现有图像数据集输入模型之前以某种方式对其进行预处理以提高生成输出的质量是合理的。
在我们的例子中,首先想到的是从数据集中删除基于文本的图像。 GAN 能够生成图像,但要正确添加文本元素,必须训练额外的神经网络层。
很明显,虽然典型的 GAN 可以学习不同的形状和模式,但语言语义是无法仅从图像中轻易获得的知识。 这使得输出看起来更像是文本的模仿,而不是实际的文本。
要生成文本标识,至少需要三个模型。
第一个是语言模型, BERT or GPT-2,这是对徽标标题生成任务的微调。
第二个模型将生成一组具有独特字体的字符,以可视化生成的内容。 该模型可以基于 GAN 架构,通过一些约束来确保属于一种字体的所有字符都具有一致的样式。 这是在 字形GAN 模型。
最后一个模型将生成其余的标识视觉效果,并将它们与已经生成的文本结合起来。 由此产生的管道非常复杂,显然需要长时间的开发才能产生良好的结果。 因此,我们决定将注意力完全集中在非基于文本的标识上。
为了查找和删除包含文本的标识,我们使用了最近发布的 手艺 字符级文本检测模型。 该模型本身非常有趣,因为如图 24 所示,即使在模糊图像和扭曲/异常定向的字符或单词中,它也能够检测到文本。

图24。 使用标识中的文本检测 手艺 模型
LLD-logo 和 BoostedLLD 都应用了字符删除,导致数据集大小从原来的 50k 减少到约 130k 图像。
最近邻搜索的视觉相似性
图像聚类并不是我们使用 MoCo(或任何其他能够构建输入数据压缩表示的模型)的深度嵌入来实现的唯一目标。 我们可以在嵌入空间中搜索最近的邻居,从而找到与查询图像最相似的图像。 这种技术被广泛用于使图像搜索引擎能够帮助在数据库中找到最相似的项目,通常包含数百万张图像(图 29)。

图29。 家居用品的视觉相似度搜索(资源)
我们发现,使用 MoCo 的嵌入,对 k 个最近邻居的简单欧几里德距离搜索会产生有用的结果,因为邻居在配色方案和实际内容方面与查询相似。 此外,我们看到该技术可用于在图像数据库中查找图像重复项(图 30)。 唯一的问题是,有时原始的低分辨率副本没有获得足够高的分数,最终成为第二或第三最相似的邻居。 这可以通过在正常/低分辨率图像对上专门训练模型或在将图像输入模型之前应用降噪方法(例如高斯模糊)来解决。



图30。 大多数相似的邻居使用图像嵌入之间的欧几里德距离进行搜索。 显示原始图像的 5 个最相似的邻居。
使用 StyleGan2 生成标识的 GAN 图像
回顾预处理阶段,我们准备了一个由 50k 标识图像组成的数据集,方法是合并两个单独的数据集,删除基于文本的标识,并在数据中找到 10 个图像具有相似视觉特征的集群。
现在,让我们想象一下,我们将构建一个工具来帮助设计师提出新的标识创意。 这就是生成模型可以提供帮助的地方!
下一步是在该数据集上训练一个实际的生成模型,以生成新颖的标识样本。 聚类信息可以用作帮助模型学习从不同标识组生成图像的条件。 我们使用完整数据集和 StyleGan2 模型开始我们的非条件 GAN 图像生成实验。
在实验中,我们使用 StyleGan2 和一个小说 自适应鉴别器增强 ADA(图 31)— 图像增强技术,与训练期间的典型数据增强不同,它取决于模型对数据的过度拟合程度。
StyleGan2 有两个子网络:鉴别器和生成器。 在 GAN 训练期间,生成器的任务是生成合成图像,而鉴别器被训练以区分来自生成器的赝品和真实图像。 当 Discriminator 对训练样本的记忆太好并且不再向 Generator 提供有用的反馈时,就会发生过拟合。
此外,增强功能被设计为不泄漏。 泄漏增强会导致生成器生成增强图像,而不是更好地生成正常图像。 ADA 引入的改进允许对有限大小的数据集进行更有效的训练。 在我们的案例中,将数据拆分为集群后,每个集群的数据量变得相当小。

图31。 具有自适应鉴别器增强(左)和增强示例(右)的 StyleGan2 架构(资源)
为了实现所呈现的结果,我们使用了具有 2 个 Nvidia V100 GPU 和批量大小为 200 的服务器。为 128×128 图像准备模型的典型训练运行需要 80,000 - 120,000 次迭代和 48-72 小时的时间。
无条件 GAN 图像——好、中等和差质量的图像
在训练 GAN 图像生成器之后,我们收集了许多视觉质量不同的标识。 让我们看一下高质量徽标的示例(图 32)。 如您所见,该网络不仅学会了重现标识常见的简单形状(例如圆形),而且还生成了更复杂的对象(例如兔子、鸟、脸、心等),更重要的是,将这些形状融入标识设计中。 此外,经过训练的网络能够生成具有吸引力的纹理和配色方案,以使徽标的最终外观多样化。

图32。 来自 StyleGan2 的优质标识
继续,让我们看看中等质量的图像(图 33)。 在这里,我们开始看到一些形状看起来不像完成的图像,而更像是从一种形状到另一种形状的过渡。 此外,有时该模型可以产生一些非常简单的结果,质量不错,但也不是很有趣。 我们在这个阶段看到的一个常见问题是由于训练数据中有大量的圆形。 类似的形状会经常出现在生成的结果中。 这就是为什么创建一个精心策划的、多样化的训练数据集对于获得高保真结果至关重要——模型直接从数据中学习,并且只能与数据一样好。

图33。 StyleGan2 的中等质量标识
最后,我们得出了质量较差的结果(图 34)。 这些图像的很大一部分是模型尝试生成尚未正确学习的形状或没有足够数量的训练示例的形状。 例如,GAN 经常尝试生成类似草图的图像(图 x AC),但无法输出任何有价值的东西。 如前所述,在集群 4 中发现了许多草图图像(表 1)。 少量的示例和草图的复杂性使得训练任务难以弄清楚。 我们假设这可以通过为模型提供更多的草图图像来解决。

图34。 StyleGan2 的低质量标识
其他失败的尝试也与模型试图表示复杂的对象和失败有关(图 D、E)。 正如数据探索阶段向我们展示的那样,有一组图像显示了一些 3d 效果,并且模型可能试图复制这些效果,就像在草图的情况下一样。
最后,有失败的生成尝试(图 E,G)不能归因于任何特定原因,这对于生成模型来说是很正常的。 总会有一些不成功的合成图像,但它们的百分比可能会有所不同。 然而,我们总是可以产生更多的例子,只要劣质图像不是太丰富,它们就不会成为严重的问题来源。
无条件 GAN 图像——插值
简单地使用 GAN 生成图像并不是获得有趣结果的唯一可用选项。 事实上,任何两个图像的两个潜在空间嵌入(W)可以以不同的比例混合在一起,以获得所描绘内容的中间组合(图 35)。 在用于图片生成的机器学习中,可以利用此功能来进一步增强标识的多样性,或者使设计师能够将一个标识的视觉风格“轻推”到另一个标识的方向。

图35。 不同生成的标识之间的潜在空间插值
无条件GAN——风格混合
控制生成的标识外观的另一个有趣选项是部分混合两种标识的样式。 在下面的示例中,每行使用相同的粗略样式源(控制标识的形状),而列具有不同的精细样式(控制次要细节和颜色),如图 36 所示。结果,我们可以想象设计师将能够使用来自另一个标识的配色方案修改首选内容的标识。

图36。 混合粗略(行,控制标志的内容)和精细样式(列,控制颜色和精细细节)
条件GAN——来自集群的数据示例
您可以在下面看到我们在将图像集群作为条件训练模型后获得的结果(图 37)。 合成图像的质量和内容在集群之间差异很大。
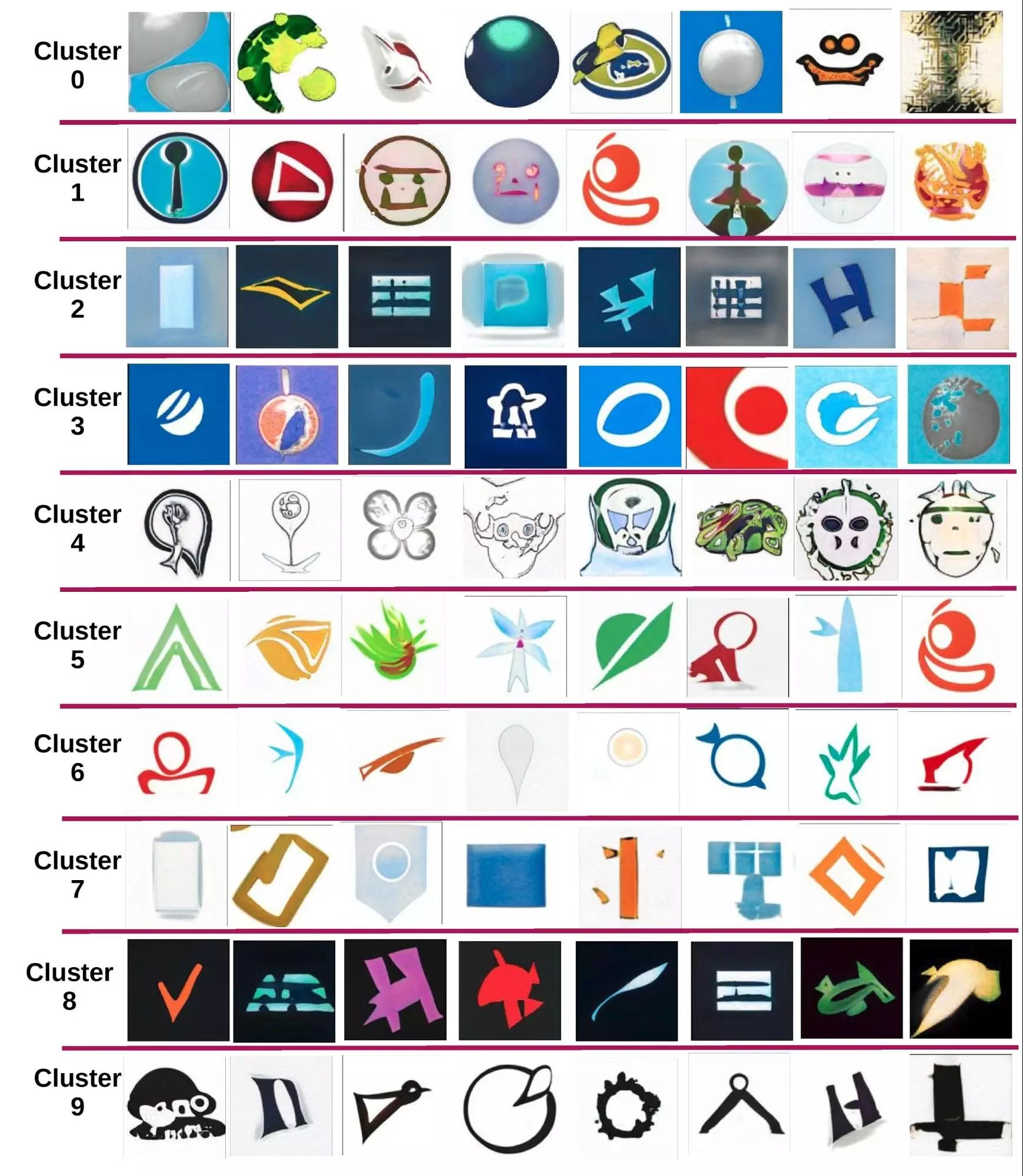
图37。 在 10 个图像集群上生成条件图像
最有趣的结果出现在集群 0 和 4 中,因为它们最初包含说明各种对象的最复杂的图像。 不利的一面是,这些集群的失败生成尝试次数也最多,这是合理的,因为这里的训练示例数量相对较少(约 18% 来自 50k 个徽标)。 其他集群更稳定(例如 2、3、7、8),但产生的几何形状更可预测,变化更少。 最后,集群 1、5、6 和 9 提供了或多或少独特的视觉风格和更高的成功生成结果的组合。
GAN 图像生成的结论和未来工作
本文探讨了 GAN 图像生成。 它在实践中展示了如何使用 StyleGAN 模型进行标识合成、生成模型的能力以及如何操纵此类模型中的内容生成。
从获得的结果中,我们看到虽然生成的图像质量可能相当高,但当前阶段的主要问题是控制模型输出的能力。 这可以使用图像之间的插值、风格混合、条件图像生成和图像反转(使用 GAN 将任何图像转换为标识)来完成。 但是,问题仍然没有完全解决。
展望未来,我们认为用于内容合成的生成模型的自然进化路径是支持文本的图像生成,因为它缓解了通常生成模型中遇到的大部分问题。 这种方法的一个很好的例子是 DALL-E 模型于 2021 年由 OpenAI. DALL-E 基于来自同一团队的另一个模型,语言模型 GPT-3,它已升级为不仅可以使用单词标记,还可以使用图像标记(256×256 图像编码为 32×32=1024 标记使用输入到变分自动编码器的 8×8 图像块)。

图38。 使用 DALL-E 将文本输入“带有蓝色草莓图像的彩色玻璃窗”转换为图像(资源)
在通过文本描述重建图像的训练之后,生成的模型可以解释复杂的文本输入片段并产生令人惊讶的多样化和高质量的图像(图 38)。
这种方法有两个明显的缺点。 所呈现的模型的大小对于大多数应用程序(1.2B 参数)来说是令人望而却步的。 训练这样的模型需要作者从互联网上挖掘的文本标题-图像对。 虽然第一个问题可以通过创建一个更小的、特定领域的模型来解决,但第二个问题可能有点难以解决(收集数千个文本标识描述不是一件容易的事)。 然而,文本图像生成所提出的优势太重要了,不容忽视。
目前,最好的选择是使用我们在本文中展示的方法(使用 GAN 生成条件图像)。 这种新的图像生成方法的未来确实有很多希望,我们预计在接下来的几年中会在这个方向上取得更多进展。
标签
创建您的免费帐户以解锁您的自定义阅读体验。
柏拉图重新构想的 Web3。 数据智能放大。
单击此处访问。

