亚马逊基岩 提供来自 Amazon 和第三方提供商的广泛模型,包括 Anthropic、AI21、Meta、Cohere 和 Stability AI,并涵盖广泛的用例,包括文本和图像生成、嵌入、聊天、高级代理推理和编排等等。 Amazon Bedrock 知识库 允许您使用 AWS 和第三方模型在 AWS 和第三方矢量存储之上构建高性能和定制的检索增强生成 (RAG) 应用程序。 Amazon Bedrock 知识库可自动将数据与向量存储同步,包括更新数据时比较数据、文档加载、分块以及语义嵌入。它允许您无缝地定制您的 RAG 提示和检索策略——我们提供源归属,并自动处理内存管理。知识库完全无服务器,因此您不需要管理任何基础设施,并且在使用知识库时,您只需为您使用的模型、矢量数据库和存储付费。
RAG 是一种流行的技术,它将私有数据的使用与大型语言模型 (LLM) 结合起来。 RAG 首先根据用户的查询从数据存储(最常见的是向量索引)检索相关文档。然后,它使用语言模型通过考虑检索到的文档和原始查询来生成响应。
在这篇文章中,我们演示了如何使用 Amazon Bedrock 知识库为药物发现用例构建 RAG 工作流程。
Amazon Bedrock 知识库概述
Amazon Bedrock 知识库支持多种常见文件类型,包括 .txt、.docx、.pdf、.csv 等。为了能够有效地检索私有数据,常见的做法是首先将这些文档分割成可管理的块。知识库实施了默认的分块策略,该策略在大多数情况下运行良好,可让您更快地开始使用。如果您想要更多控制,知识库可让您通过一组预配置选项来控制分块策略。您可以控制最大令牌大小和跨块创建的重叠量,以为嵌入提供连贯的上下文。 Amazon Bedrock 知识库管理同步数据的过程 亚马逊简单存储服务 (Amazon S3) 存储桶,将其分割成更小的块,生成向量嵌入,并将嵌入存储在向量索引中。该过程具有智能差异、吞吐量和故障管理。
在运行时,嵌入模型用于将用户的查询转换为向量。然后通过将文档向量与用户查询向量进行比较来查询向量索引以查找与用户查询相似的文档。在最后一步中,将从向量索引检索到的语义相似的文档添加为原始用户查询的上下文。当为用户生成响应时,文本模型中会提示语义相似的文档,以及源属性以实现可追溯性。
Amazon Bedrock 知识库支持多种矢量数据库,包括 亚马逊 OpenSearch 无服务器, 亚马逊极光、Pinecone 和 Redis 企业云。 Retrieve 和 RetrieveAndGenerate API 允许您的应用程序使用统一且标准的语法直接查询索引,而无需为每个不同的矢量数据库学习单独的 API,从而减少了针对矢量存储编写自定义索引查询的需要。 Retrieve API 接受传入的查询,将其转换为嵌入向量,并使用在向量数据库级别配置的算法查询后端存储; RetrieveAndGenerate API 使用 Amazon Bedrock 提供的用户配置的 LLM 并以自然语言生成最终答案。本机可追溯性支持告知请求应用程序用于回答问题的来源。对于企业实施,知识库支持 AWS密钥管理服务 (AWS KMS) 加密, AWS 云跟踪 集成等。
在以下部分中,我们将演示如何使用 Amazon Bedrock 知识库(由 OpenSearch Serverless 矢量引擎支持)构建 RAG 工作流程,以分析药物发现用例的非结构化临床试验数据集。这些数据信息丰富,但可能存在极大的异构性。正确处理不同格式的专业术语和概念对于检测见解和确保分析完整性至关重要。借助 Amazon Bedrock 知识库,您可以通过简单、自然的查询来访问详细信息。
为 Amazon Bedrock 构建知识库
在本部分中,我们将演示通过控制台为 Amazon Bedrock 创建知识库的过程。完成以下步骤:
- 在 Amazon Bedrock 控制台上,在 编曲配置 在导航窗格中,选择 知识库.
- 创建知识库.
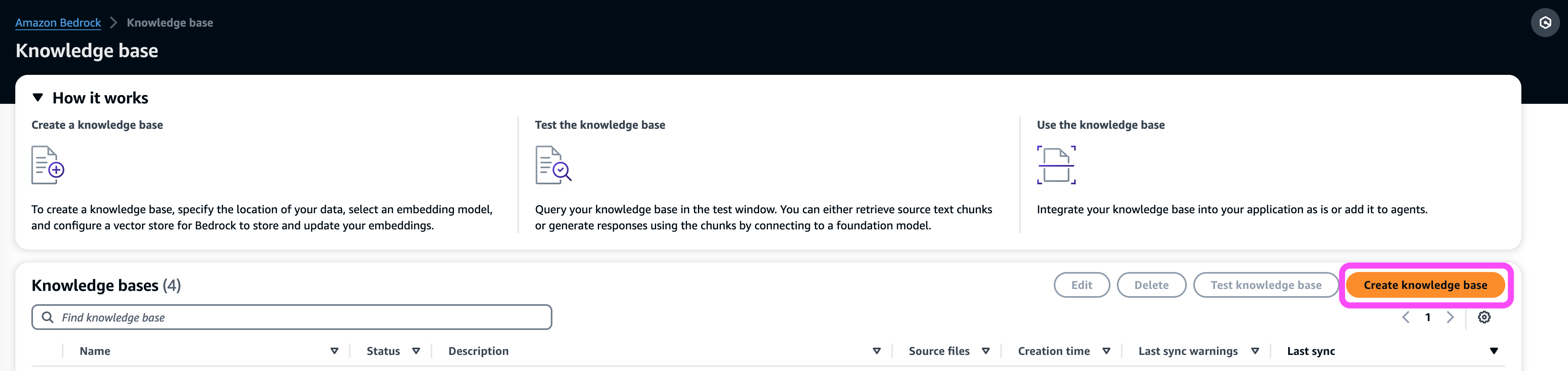
- 在 知识库详细信息 部分,输入名称和可选说明。
- 在 IAM 权限 部分,选择 创建并使用新的服务角色.
- 针对 服务名称角色,输入您的角色名称,该名称必须以
AmazonBedrockExecutionRoleForKnowledgeBase_.
- 下一页.
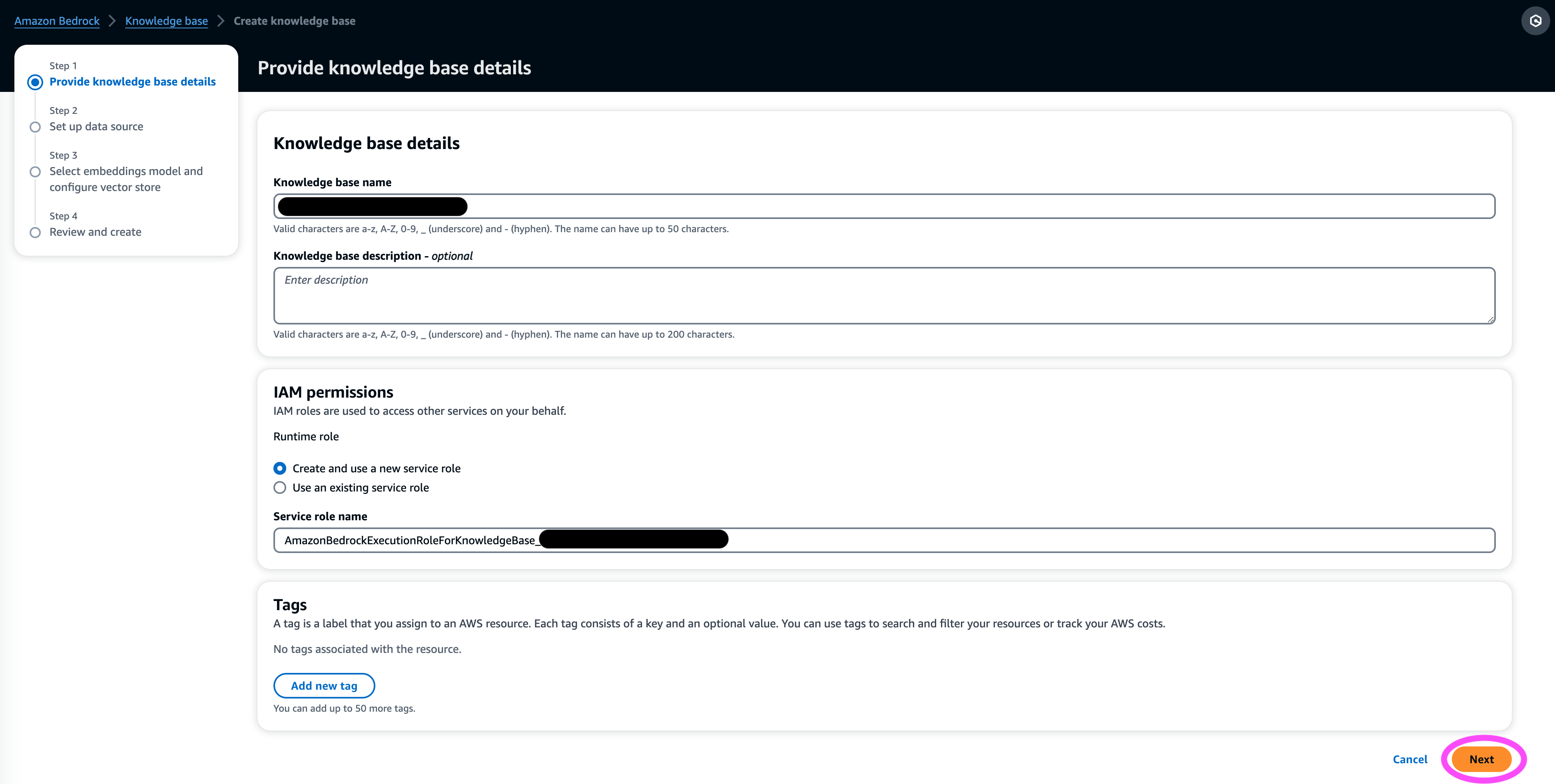
- 在 数据源 部分,输入数据源的名称和数据集所在的 S3 URI。知识库支持以下文件格式:
- 纯文本 (.txt)
- 降价 (.md)
- 超文本标记语言 (.html)
- Microsoft Word 文档 (.doc/.docx)
- 逗号分隔值(.csv)
- Microsoft Excel 电子表格 (.xls/.xlsx)
- 可移植文档格式 (.pdf)
- 下 其他设置¸ 选择您首选的分块策略(对于本文,我们选择 固定大小分块)并以百分比指定块大小和覆盖。或者,您可以使用默认设置。
- 下一页.
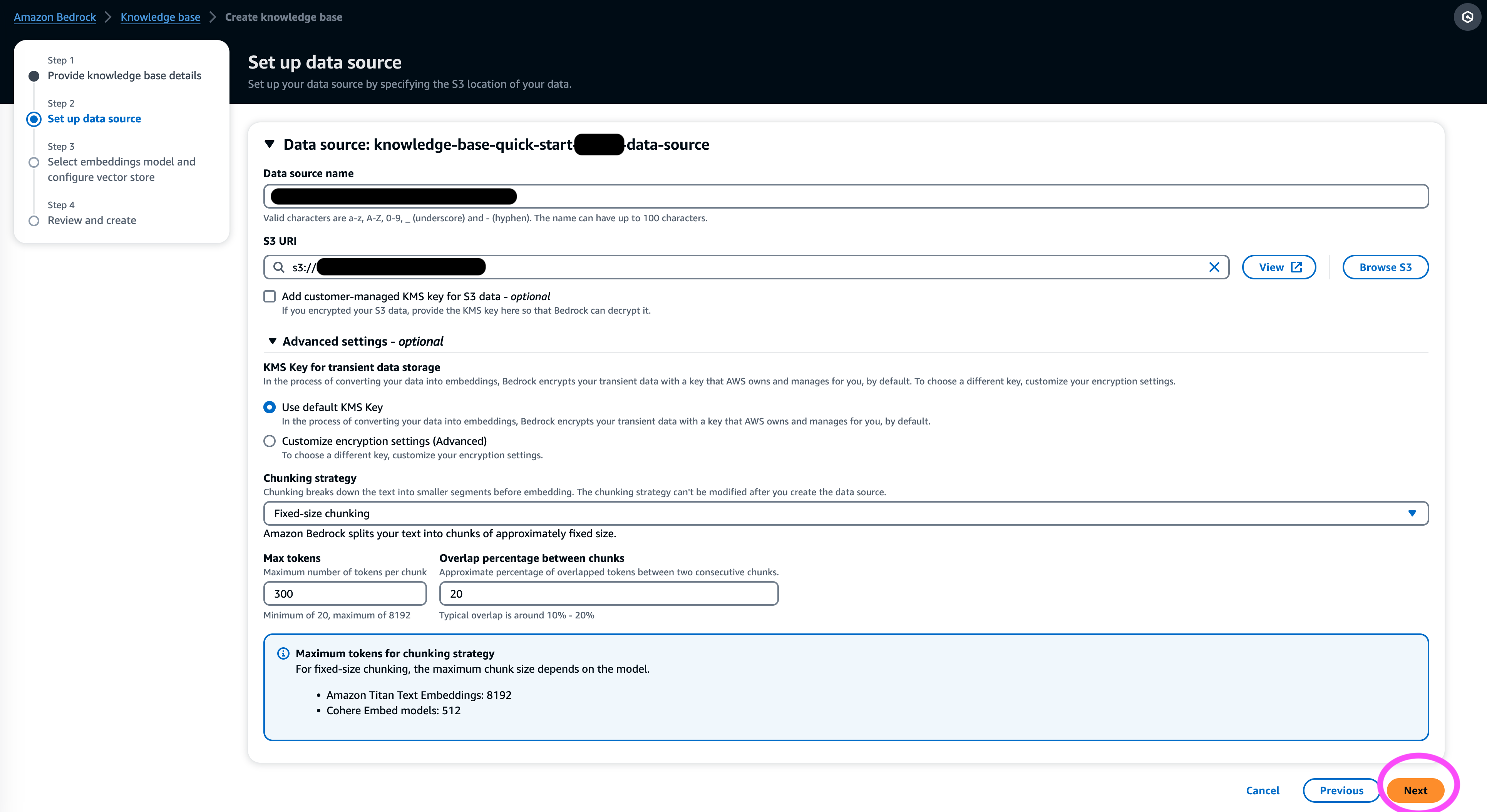
- 在 嵌入模型 部分,从 Amazon Bedrock 选择 Titan Embeddings 模型。
- 在 矢量数据库 部分,选择 快速创建新的矢量存储,它管理设置矢量存储的过程。
- 下一页.

- 查看设置并选择 创建知识库.
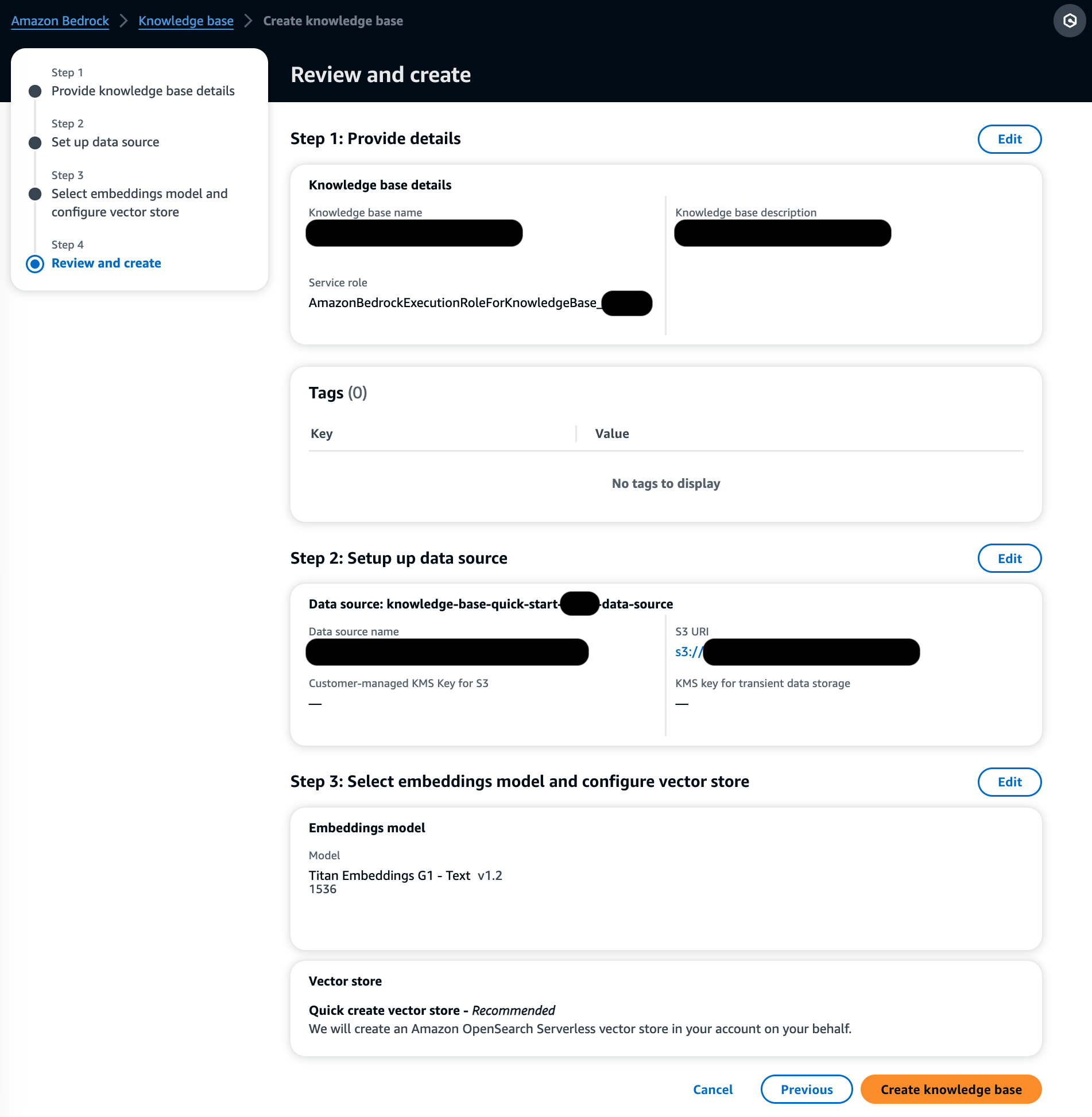
- 等待知识库创建完成并确认其状态为 各就各位.
- 在 数据源 部分,或者在页面顶部的横幅或测试窗口的弹出窗口中,选择 Sync 触发从 S3 存储桶加载数据的过程,将其拆分为您指定大小的块,使用选定的文本嵌入模型生成矢量嵌入,并将它们存储在由 Amazon Bedrock 知识库管理的矢量存储中。
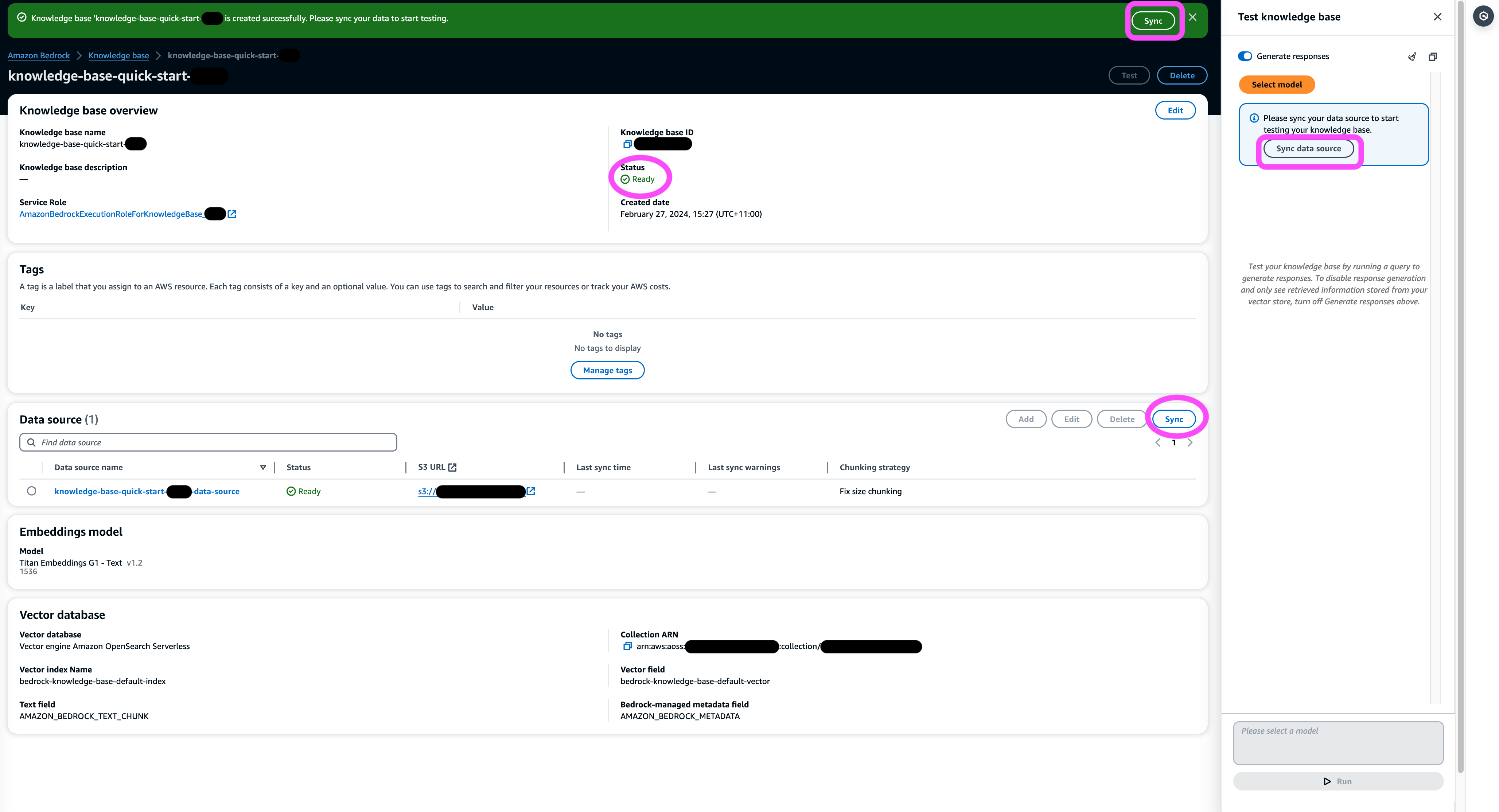
同步功能支持根据 Amazon S3 中文档的更改从向量索引中提取、更新和删除文档。您还可以使用 StartIngestionJob 通过 AWS 开发工具包触发同步的 API。
同步完成后,同步历史记录会显示状态 已完成。

查询知识库
在本节中,我们将演示如何通过简单、自然的查询来访问知识库中的详细信息。我们使用由 PDF 文件组成的非结构化综合数据集,每个文件的页码范围为 10-100 页,模拟拟议新药的临床试验计划,包括统计分析方法和参与者同意书。我们使用 Amazon Bedrock 的知识库 retrieve_and_generate 和 retrieve API 具有 亚马逊 Bedrock LangChain 集成.
在编写使用 Amazon Bedrock API 的脚本之前,您需要在您的环境中安装适当版本的 AWS 开发工具包。对于 Python 脚本,这将是 适用于Python的AWS开发工具包(Boto3):
pip install langchain
pip install boto3
此外,还允许访问 Amazon Titan Embeddings 模型和 Anthropic Claude v2 或 v1。欲了解更多信息,请参阅 模型访问.
使用 Amazon Bedrock 生成问题
我们可以使用 Anthropic Claude 2.1 for Amazon Bedrock 提出针对临床试验数据集提出的问题列表:
import boto3
from langchain.llms.bedrock import Bedrock
bedrock_client = boto3.client("bedrock-runtime")
# Start with the query
prompt = "For medical research trial consent forms to sign, what are the top 5 questions can be asked?"
claude_llm = Bedrock(
model_id="anthropic.claude-v2:1",
model_kwargs={"temperature": 0, "top_k": 10, "max_tokens_to_sample": 3000},
client=bedrock_client,
)
# Provide the prompt to the LLM to generate an answer to the query without any additional context provided
response = claude_llm(prompt)
questions = [
item.split(".")[1].strip() for item in response.strip().split("nn")[1:-1]
]
questions
>>> answer:
'What is the purpose of the study? Make sure you understand the goals of the research and what the study procedures will entail',
'What are the risks and potential benefits? The form should explain all foreseeable risks, side effects, or discomforts you might experience from participating',
'What will participation involve? Get details on what tests, medications, lifestyle changes, or procedures you will go through, how much time it will take, and how long the study will last',
'Are there any costs or payments? Ask if you will be responsible for any costs related to the study or get paid for participating',
'How will my privacy be protected? The form should explain how your personal health information will be kept confidential before, during, and after the trial'
使用 Amazon Bedrock RetrieveAndGenerate API
要获得完全托管的 RAG 体验,您可以使用 Amazon Bedrock 的本机知识库 RetrieveAndGenerate 直接获取答案的API:
bedrock_agent_client = boto3.client("bedrock-agent-runtime")
kb_id = "<YOUR_KNOWLEDGE_BASE_ID>"
def retrieveAndGenerate(
input: str,
kbId: str,
region: str = "us-east-1",
sessionId: str = None,
model_id: str = "anthropic.claude-v2:1",
):
model_arn = f"arn:aws:bedrock:{region}::foundation-model/{model_id}"
if sessionId:
return bedrock_agent_client.retrieve_and_generate(
input={"text": input},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": kbId,
"modelArn": model_arn,
},
},
sessionId=sessionId,
)
else:
return bedrock_agent_client.retrieve_and_generate(
input={"text": input},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": kbId,
"modelArn": model_arn,
},
},
)
response = retrieveAndGenerate(
"What are the potential risks and benefits of participating?", kb_id
)
generated_text = response["output"]["text"]
>>> "The potential risks include side effects from the study medication lithium such as nausea, loose stools, thirst, urination changes, shakiness, headaches, sweating, fatigue, decreased concentration, and skin rash. There is also a risk of lithium interaction with other medications. For women, there is a risk of birth defects if lithium is taken during pregnancy. There are no guaranteed benefits, but possible benefits include new information that could help the participant from the interviews and tests conducted during the study."
引用的信息源可以通过以下代码获得(为了简洁起见,对一些输出进行了编辑):
response["citations"]
>>> [
{
"generatedResponsePart": {
"textResponsePart": {
"text": " The potential risks include side effects from the study...",
"span": {"start": 0, "end": 361},
}
},
"retrievedReferences": [
{
"content": {
"text": "590 ICF#2 Page 7 of 19 The primary risks and discomforts of participation…"
},
"location": {"type": "S3", "s3Location": {"uri": "s3://XXXX/XXXX.pdf"}},
},
{
"content": {
"text": "N/A CSP 590 ICF#2 Page 10 of 19 Risks associated with suddenly stopping study medications..."
},
"location": {"type": "S3", "s3Location": {"uri": "s3://XXXX/XXXX.pdf"}},
},
],
},
{
"generatedResponsePart": {
"textResponsePart": {
"text": " There are no guaranteed benefits, but possible benefits include...",
"span": {"start": 363, "end": 531},
}
},
"retrievedReferences": [
{
"content": {
"text": "research, not usual clinical care. After these are done we ask..."
},
"location": {"type": "S3", "s3Location": {"uri": "s3://XXXX/XXXX.pdf"}},
}
],
},
]
通过传递会话 ID RetrieveAndGenerate API,您可以保留对话上下文并提出后续问题。例如,在没有上下文的情况下,如果你从之前的答案中询问更多细节,它可能无法正确回答:
retrieveAndGenerate("elaborate more on the first side effect", kb_id, sessionId=None)["output"]["text"]
>>> "The search results do not provide additional details about the mild nausea side effect that would allow me to elaborate further on it."
但通过传递会话 ID,RAG 管道能够识别相应的上下文并返回相关答案:
retrieveAndGenerate("elaborate more on the first side effect", kb_id, sessionId=response["sessionId"])["output"]["text"]
>>> "The search results provide details that nausea from taking lithium is usually mild and goes away after days or weeks for most people. Specifically, up to 75% of people may experience mild nausea when first starting lithium, but this goes away in 90-99% of people who continue taking it."
下表显示了检索到的所有相应问题的答案。
| 问题 |
回答 |
| 研究的目的是什么?确保您了解研究的目标以及研究程序的内容。 |
该研究的目的是测试锂是否能有效预防抑郁症或双相情感障碍患者反复自杀性的自我暴力。 |
| 有哪些风险和潜在好处?该表格应解释您参与时可能遇到的所有可预见的风险、副作用或不适。 |
可能的风险或不适包括:导致不适的面试问题、锂药物的副作用,如恶心、稀便、口渴、排尿变化、颤抖、头痛、出汗、疲劳、注意力下降、皮疹、甲状腺变化、痤疮恶化/牛皮癣、锂中毒以及突然停止用药的风险。潜在的好处是,测试可能会产生新的信息来帮助参与者,而锂可能有助于防止抑郁症或躁郁症患者反复自杀性的自我暴力。 |
| 参与会涉及什么?详细了解您将接受哪些测试、药物、生活方式的改变或程序、需要多长时间以及研究将持续多长时间。 |
参与将包括完成访谈和调查问卷,内容涵盖思维、行为、心理健康治疗、药物、酒精和毒品使用、家庭和社会支持以及对研究的理解。这大约需要两个小时,可以通过亲自或通过多次会议来完成。如果有资格参加完整的研究,一年内将有大约 20 次研究访问。这将包括服用研究药物、检查生命体征、填写调查问卷、审查副作用以及继续正常的医疗和心理保健。 |
| 是否有任何费用或付款?询问您是否将承担与研究相关的任何费用或因参与而获得报酬。 |
是的,搜索结果中讨论了成本和付款。您无需为研究中的任何治疗或程序付费。然而,您仍然需要支付与研究无关的护理和药物的任何常规 VA 共同付款。您不会因参与而获得报酬,但研究将报销与参与相关的费用,如交通、停车等。提供了报销金额和流程。 |
| 我的隐私将如何受到保护?该表格应说明如何在试验之前、期间和之后对您的个人健康信息保密。 |
我们将通过以下方式保护您的隐私:进行私下采访、在上锁的文件和办公室中保存书面记录、将电子信息存储在加密和受密码保护的文件中,以及从卫生与公众服务部获取保密证书以防止泄露可识别您身份的信息。可以识别您身份的信息可能会与负责您护理或政府机构审核和评估的医生共享,但有关该研究的谈话和论文不会识别您的身份。 |
使用 Amazon Bedrock Retrieve API 进行查询
要自定义 RAG 工作流程,您可以使用 Retrieve API 根据您的查询获取相关块,并将其传递给 Amazon Bedrock 提供的任何 LLM。要使用 Retrieve API,请将其定义如下:
def retrieve(query: str, kbId: str, numberOfResults: int = 5):
return bedrock_agent_client.retrieve(
retrievalQuery={"text": query},
knowledgeBaseId=kbId,
retrievalConfiguration={
"vectorSearchConfiguration": {"numberOfResults": numberOfResults}
},
)
检索相应的上下文(为了简洁起见,对一些输出进行了编辑):
query = "What is the purpose of the medical research study?"
response = retrieve(query, kb_id, 3)
retrievalResults = response["retrievalResults"]
>>> [
{
"content": {"text": "You will not be charged for any procedures that..."},
"location": {"type": "S3", "s3Location": {"uri": "s3://XXXXX/XXXX.pdf"}},
"score": 0.6552521,
},
{
"content": {"text": "and possible benefits of the study. You have been..."},
"location": {"type": "S3", "s3Location": {"uri": "s3://XXXX/XXXX.pdf"}},
"score": 0.6581577,
},
...,
]
提取提示模板的上下文:
def get_contexts(retrievalResults):
contexts = []
for retrievedResult in retrievalResults:
contexts.append(retrievedResult["content"]["text"])
return " ".join(contexts)
contexts = get_contexts(retrievalResults)
导入Python模块并设置上下文问答提示模板,然后生成最终答案:
from langchain.prompts import PromptTemplate
PROMPT_TEMPLATE = """
Human: You are an AI system working on medical trial research, and provides answers to questions
by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context_str}
</context>
<question>
{query_str}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
claude_prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context_str", "query_str"]
)
prompt = claude_prompt.format(context_str=contexts, query_str=query)
response = claude_llm(prompt)
>>> "Based on the context provided, the purpose of this medical research study is to evaluate the efficacy of lithium compared to a placebo in preventing suicide over a 1 year period. Specifically, participants will be randomly assigned to receive either lithium or a placebo pill for 1 year, with their doctors and the participants themselves not knowing which treatment they receive (double-blind). Blood lithium levels will be monitored and doses adjusted over the first 6-8 visits, then participants will be followed monthly for 1 year to assess outcomes."
使用 Amazon Bedrock LangChain 集成进行查询
为了创建端到端的定制问答应用程序,Amazon Bedrock 知识库提供了与 LangChain 的集成。要设置 LangChain 检索器,请提供知识库 ID 并指定要从查询返回的结果数:
from langchain.retrievers.bedrock import AmazonKnowledgeBasesRetriever
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id=kb_id,
retrieval_config={"vectorSearchConfiguration": {"numberOfResults": 4}},
)
现在设置 LangChain RetrievalQA 并从知识库生成答案:
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=claude_llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": claude_prompt},
)
[qa(q)["result"] for q in questions]
这将生成与上表中列出的类似的相应答案。
清理
请务必删除以下资源以避免产生额外费用:
结论
Amazon Bedrock 提供了一系列广泛的深度集成服务,为各种规模的 RAG 应用程序提供支持,让您可以轻松开始分析公司数据。 Amazon Bedrock 知识库与 Amazon Bedrock 基础模型集成,构建可扩展的文档嵌入管道和文档检索服务,为各种内部和面向客户的应用程序提供支持。我们对未来感到兴奋,您的反馈将在指导该产品的进步方面发挥至关重要的作用。要了解有关 Amazon Bedrock 和知识库的功能的更多信息,请参阅 Amazon Bedrock 知识库.
作者简介
 马克·罗伊 是 AWS 的首席机器学习架构师,帮助客户设计和构建 AI/ML 解决方案。 Mark 的工作涵盖了广泛的 ML 用例,主要关注计算机视觉、深度学习和在整个企业中扩展 ML。 他为许多行业的公司提供过帮助,包括保险、金融服务、媒体和娱乐、医疗保健、公用事业和制造业。 Mark 拥有六项 AWS 认证,包括 ML 专业认证。 在加入 AWS 之前,Mark 担任架构师、开发人员和技术领导者超过 25 年,其中 19 年从事金融服务工作。
马克·罗伊 是 AWS 的首席机器学习架构师,帮助客户设计和构建 AI/ML 解决方案。 Mark 的工作涵盖了广泛的 ML 用例,主要关注计算机视觉、深度学习和在整个企业中扩展 ML。 他为许多行业的公司提供过帮助,包括保险、金融服务、媒体和娱乐、医疗保健、公用事业和制造业。 Mark 拥有六项 AWS 认证,包括 ML 专业认证。 在加入 AWS 之前,Mark 担任架构师、开发人员和技术领导者超过 25 年,其中 19 年从事金融服务工作。
 玛尼哈努加 是生成式 AI 专家的技术主管、《AWS 上的应用机器学习和高性能计算》一书的作者,也是女性制造业教育基金会董事会的成员。 她领导计算机视觉、自然语言处理和生成人工智能等多个领域的机器学习 (ML) 项目。 她帮助客户大规模构建、训练和部署大型机器学习模型。 她在 re:Invent、Women in Manufacturing West、YouTube 网络研讨会和 GHC 23 等内部和外部会议上发表演讲。在空闲时间,她喜欢沿着海滩长距离跑步。
玛尼哈努加 是生成式 AI 专家的技术主管、《AWS 上的应用机器学习和高性能计算》一书的作者,也是女性制造业教育基金会董事会的成员。 她领导计算机视觉、自然语言处理和生成人工智能等多个领域的机器学习 (ML) 项目。 她帮助客户大规模构建、训练和部署大型机器学习模型。 她在 re:Invent、Women in Manufacturing West、YouTube 网络研讨会和 GHC 23 等内部和外部会议上发表演讲。在空闲时间,她喜欢沿着海滩长距离跑步。
 孙百川博士目前担任 AWS 的高级 AI/ML 解决方案架构师,专注于生成式 AI,并运用他在数据科学和机器学习方面的知识来提供实用的、基于云的业务解决方案。凭借管理咨询和人工智能解决方案架构方面的经验,他解决了一系列复杂的挑战,包括机器人计算机视觉、时间序列预测和预测性维护等。他的工作建立在项目管理、软件研发和学术追求的坚实背景之上。工作之余,孙博士喜欢旅行以及与家人和朋友共度时光。
孙百川博士目前担任 AWS 的高级 AI/ML 解决方案架构师,专注于生成式 AI,并运用他在数据科学和机器学习方面的知识来提供实用的、基于云的业务解决方案。凭借管理咨询和人工智能解决方案架构方面的经验,他解决了一系列复杂的挑战,包括机器人计算机视觉、时间序列预测和预测性维护等。他的工作建立在项目管理、软件研发和学术追求的坚实背景之上。工作之余,孙博士喜欢旅行以及与家人和朋友共度时光。
 德里克周 是 AWS 的高级解决方案架构师,专注于加速客户的云之旅并通过采用基于云的解决方案实现业务转型。他的专长是全栈应用程序和机器学习开发。他帮助客户设计和构建涵盖前端用户界面、物联网应用程序、API 和数据集成以及机器学习模型的端到端解决方案。在空闲时间,他喜欢与家人共度时光并尝试摄影和摄像。
德里克周 是 AWS 的高级解决方案架构师,专注于加速客户的云之旅并通过采用基于云的解决方案实现业务转型。他的专长是全栈应用程序和机器学习开发。他帮助客户设计和构建涵盖前端用户界面、物联网应用程序、API 和数据集成以及机器学习模型的端到端解决方案。在空闲时间,他喜欢与家人共度时光并尝试摄影和摄像。
 弗兰克·温克勒 是位于新加坡的 AWS 的高级解决方案架构师和生成式 AI 专家,专注于机器学习和生成式 AI。他与全球数字原生公司合作,在 AWS 上构建可扩展、安全且经济高效的产品和服务。闲暇时,他会陪伴儿子和女儿,并前往东盟各地享受海浪的乐趣。
弗兰克·温克勒 是位于新加坡的 AWS 的高级解决方案架构师和生成式 AI 专家,专注于机器学习和生成式 AI。他与全球数字原生公司合作,在 AWS 上构建可扩展、安全且经济高效的产品和服务。闲暇时,他会陪伴儿子和女儿,并前往东盟各地享受海浪的乐趣。
 尼尔·查德瓦拉(Nihir Chadderwala) 是全球医疗保健和生命科学团队的高级 AI/ML 解决方案架构师。他的专长是为客户问题构建大数据和人工智能驱动的解决方案,特别是在生物医学、生命科学和医疗保健领域。他还对量子信息科学与人工智能的交叉感到兴奋,并喜欢学习并为这个领域做出贡献。业余时间,他喜欢打网球、旅行和学习宇宙学。
尼尔·查德瓦拉(Nihir Chadderwala) 是全球医疗保健和生命科学团队的高级 AI/ML 解决方案架构师。他的专长是为客户问题构建大数据和人工智能驱动的解决方案,特别是在生物医学、生命科学和医疗保健领域。他还对量子信息科学与人工智能的交叉感到兴奋,并喜欢学习并为这个领域做出贡献。业余时间,他喜欢打网球、旅行和学习宇宙学。







 马克·罗伊 是 AWS 的首席机器学习架构师,帮助客户设计和构建 AI/ML 解决方案。 Mark 的工作涵盖了广泛的 ML 用例,主要关注计算机视觉、深度学习和在整个企业中扩展 ML。 他为许多行业的公司提供过帮助,包括保险、金融服务、媒体和娱乐、医疗保健、公用事业和制造业。 Mark 拥有六项 AWS 认证,包括 ML 专业认证。 在加入 AWS 之前,Mark 担任架构师、开发人员和技术领导者超过 25 年,其中 19 年从事金融服务工作。
马克·罗伊 是 AWS 的首席机器学习架构师,帮助客户设计和构建 AI/ML 解决方案。 Mark 的工作涵盖了广泛的 ML 用例,主要关注计算机视觉、深度学习和在整个企业中扩展 ML。 他为许多行业的公司提供过帮助,包括保险、金融服务、媒体和娱乐、医疗保健、公用事业和制造业。 Mark 拥有六项 AWS 认证,包括 ML 专业认证。 在加入 AWS 之前,Mark 担任架构师、开发人员和技术领导者超过 25 年,其中 19 年从事金融服务工作。 弗兰克·温克勒 是位于新加坡的 AWS 的高级解决方案架构师和生成式 AI 专家,专注于机器学习和生成式 AI。他与全球数字原生公司合作,在 AWS 上构建可扩展、安全且经济高效的产品和服务。闲暇时,他会陪伴儿子和女儿,并前往东盟各地享受海浪的乐趣。
弗兰克·温克勒 是位于新加坡的 AWS 的高级解决方案架构师和生成式 AI 专家,专注于机器学习和生成式 AI。他与全球数字原生公司合作,在 AWS 上构建可扩展、安全且经济高效的产品和服务。闲暇时,他会陪伴儿子和女儿,并前往东盟各地享受海浪的乐趣。 尼尔·查德瓦拉(Nihir Chadderwala) 是全球医疗保健和生命科学团队的高级 AI/ML 解决方案架构师。他的专长是为客户问题构建大数据和人工智能驱动的解决方案,特别是在生物医学、生命科学和医疗保健领域。他还对量子信息科学与人工智能的交叉感到兴奋,并喜欢学习并为这个领域做出贡献。业余时间,他喜欢打网球、旅行和学习宇宙学。
尼尔·查德瓦拉(Nihir Chadderwala) 是全球医疗保健和生命科学团队的高级 AI/ML 解决方案架构师。他的专长是为客户问题构建大数据和人工智能驱动的解决方案,特别是在生物医学、生命科学和医疗保健领域。他还对量子信息科学与人工智能的交叉感到兴奋,并喜欢学习并为这个领域做出贡献。业余时间,他喜欢打网球、旅行和学习宇宙学。
