创建强大且可重用的机器学习 (ML) 管道可能是一个复杂且耗时的过程。 开发人员通常在本地测试他们的处理和训练脚本,但管道本身通常在云端进行测试。 在实验期间创建和运行完整的管道会增加开发生命周期的不必要开销和成本。 在这篇文章中,我们详细介绍了如何使用 Amazon SageMaker Pipelines 本地模式 在本地运行 ML 管道以减少管道开发和运行时间,同时降低成本。 管道在本地经过全面测试后,您可以轻松地重新运行它 亚马逊SageMaker 只需几行代码更改即可管理资源。
机器学习生命周期概述
ML 中新的创新和应用的主要驱动力之一是数据的可用性和数量以及更便宜的计算选项。 在多个领域,ML 已被证明能够解决以前经典大数据和分析技术无法解决的问题,并且对数据科学和 ML 从业者的需求正在稳步增长。 从非常高的层面来看,ML 生命周期由许多不同的部分组成,但 ML 模型的构建通常包括以下一般步骤:
- 数据清洗和准备(特征工程)
- 模型训练和调优
- 模型评估
- 模型部署(或批量转换)
在数据准备步骤中,数据被加载、处理并转换为 ML 模型期望的输入类型或特征。 编写脚本来转换数据通常是一个迭代过程,其中快速反馈循环对于加快开发速度很重要。 在测试特征工程脚本时通常不需要使用完整的数据集,这就是为什么你可以使用 本地模式功能 SageMaker 处理。 这允许您使用较小的数据集在本地运行并迭代更新代码。 最终代码准备就绪后,将提交给远程处理作业,该作业使用完整的数据集并在 SageMaker 托管实例上运行。
开发过程类似于模型训练和模型评估步骤的数据准备步骤。 数据科学家使用 本地模式功能 在使用 SageMaker 托管的 ML 优化实例集群中的所有数据之前,使用 SageMaker 训练在本地快速迭代较小的数据集。 这加快了开发过程并消除了在试验时运行由 SageMaker 管理的 ML 实例的成本。
随着组织的 ML 成熟度的提高,您可以使用 Amazon SageMaker管道 创建将这些步骤拼接在一起的 ML 管道,创建更复杂的 ML 工作流来处理、训练和评估 ML 模型。 SageMaker Pipelines 是一项完全托管的服务,用于自动执行 ML 工作流的不同步骤,包括数据加载、数据转换、模型训练和调整以及模型部署。 直到最近,您还可以在本地开发和测试您的脚本,但必须在云中测试您的 ML 管道。 这使得迭代 ML 管道的流程和形式成为一个缓慢且成本高昂的过程。 现在,借助 SageMaker Pipelines 添加的本地模式功能,您可以迭代和测试您的 ML 管道,就像您测试和迭代处理和训练脚本的方式一样。 您可以在本地机器上运行和测试您的管道,使用一小部分数据来验证管道语法和功能。
SageMaker管道
SageMaker Pipelines 提供了一种完全自动化的方式来运行简单或复杂的 ML 工作流程。 借助 SageMaker Pipelines,您可以使用易于使用的 Python SDK 创建 ML 工作流,然后使用可视化和管理您的工作流 亚马逊SageMaker Studio. 通过存储和重复使用您在 SageMaker Pipelines 中创建的工作流程步骤,您的数据科学团队可以提高效率并更快地扩展。 您还可以使用自动创建基础架构和存储库的预构建模板在您的机器学习环境中构建、测试、注册和部署模型。 这些模板自动可供您的组织使用,并使用 AWS服务目录 产品。
SageMaker Pipelines 为 ML 带来持续集成和持续部署 (CI/CD) 实践,例如维护开发和生产环境之间的对等性、版本控制、按需测试和端到端自动化,这有助于您在整个过程中扩展 ML组织。 DevOps 从业者知道使用 CI/CD 技术的一些主要好处包括通过可重用组件提高生产力和通过自动化测试提高质量,从而为您的业务目标带来更快的投资回报率。 现在,通过使用 SageMaker Pipelines 来自动化 ML 模型的训练、测试和部署,MLOps 从业者可以获得这些好处。 使用本地模式,您现在可以在开发用于管道的脚本时更快地进行迭代。 请注意,无法在 Studio IDE 中查看或运行本地管道实例; 但是,不久将提供本地管道的其他查看选项。
SageMaker SDK 提供了一个通用的 本地模式配置 这允许开发人员在其本地环境中运行和测试支持的处理器和估算器。 您可以对多个 AWS 支持的框架图像(TensorFlow、MXNet、Chainer、PyTorch 和 Scikit-Learn)以及您自己提供的图像使用本地模式训练。
SageMaker Pipelines 构建了一个协调工作流步骤的有向无环图 (DAG),支持许多属于 ML 生命周期的活动。 在本地模式下,支持以下步骤:
- 处理作业步骤 – 在 SageMaker 上运行数据处理工作负载的简化、托管体验,例如特征工程、数据验证、模型评估和模型解释
- 培训工作步骤 – 一个迭代过程,通过展示训练数据集中的示例来教模型进行预测
- 超参数调整作业 – 一种自动评估和选择产生最准确模型的超参数的方法
- 条件运行步骤 – 在管道中提供有条件的分支运行的步骤
- 模型步骤 – 使用 CreateModel 参数,此步骤可以创建模型以用于转换步骤或稍后部署为端点
- 转换作业步骤 – 批量转换作业,可从大型数据集生成预测,并在不需要持久端点时运行推理
- 失败步骤 – 停止管道运行并将运行标记为失败的步骤
解决方案概述
我们的解决方案演示了在本地模式下创建和运行 SageMaker Pipelines 的基本步骤,这意味着使用本地 CPU、RAM 和磁盘资源来加载和运行工作流程步骤。 您的本地环境可以在笔记本电脑上运行,使用 VSCode 或 PyCharm 等流行的 IDE,也可以由 SageMaker 使用经典笔记本实例托管。
本地模式允许数据科学家将包括处理、训练和评估作业在内的步骤拼接在一起,并在本地运行整个工作流程。 在本地完成测试后,您可以在 SageMaker 托管环境中重新运行管道,方法是替换 LocalPipelineSession 对象与 PipelineSession,这为 ML 生命周期带来了一致性。
对于此笔记本示例,我们使用标准的公开可用数据集,即 UCI 机器学习鲍鱼数据集. 目标是训练一个机器学习模型,通过物理测量来确定鲍鱼蜗牛的年龄。 从本质上讲,这是一个回归问题。
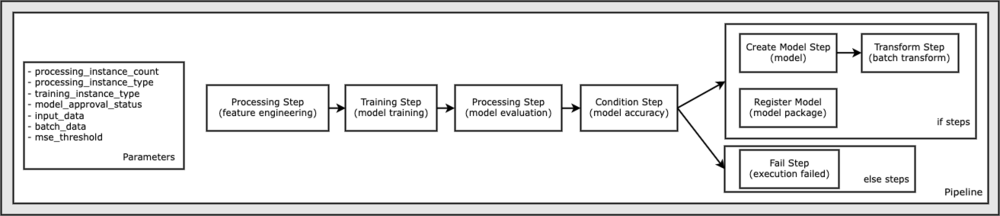
运行此笔记本示例所需的所有代码都可以在 GitHub 的 amazon-sagemaker 示例 存储库。 在此笔记本示例中,每个管道工作流步骤都是独立创建的,然后连接在一起以创建管道。 我们创建以下步骤:
- 处理步骤(特征工程)
- 训练步骤(模型训练)
- 处理步骤(模型评估)
- 条件步骤(模型精度)
- 创建模型步骤(模型)
- 变换步骤(批量变换)
- 注册模型步骤(模型包)
- 失败步骤(运行失败)
下图说明了我们的管道。
先决条件
要继续阅读这篇文章,您需要以下内容:
在满足这些先决条件后,您可以按照以下部分中的说明运行示例笔记本。
建立你的管道
在此笔记本示例中,我们使用 SageMaker 脚本模式 对于大多数 ML 流程,这意味着我们提供实际的 Python 代码(脚本)来执行活动并传递对该代码的引用。 脚本模式允许您自定义代码,同时仍利用 XGBoost 或 Scikit-Learn 等 SageMaker 预构建容器,从而为控制 SageMaker 处理中的行为提供了极大的灵活性。 使用以魔法命令开头的单元格将自定义代码写入 Python 脚本文件 %%writefile,如下所示:
%%writefile code/evaluation.py
本地模式的主要推动者是 LocalPipelineSession 对象,它是从 Python SDK 实例化的。 以下代码段显示如何在本地模式下创建 SageMaker 管道。 尽管您可以为许多本地管道步骤配置本地数据路径,但 Amazon S3 是存储转换输出的数据的默认位置。 新的 LocalPipelineSession 在本文中描述的许多 SageMaker 工作流 API 调用中,对象被传递到 Python SDK。 请注意,您可以使用 local_pipeline_session 变量以检索对 S3 默认存储桶和当前区域名称的引用。
在创建各个管道步骤之前,我们设置了管道使用的一些参数。 其中一些参数是字符串文字,而其他参数是作为 SDK 提供的特殊枚举类型创建的。 枚举类型确保将有效设置提供给管道,例如传递给 ConditionLessThanOrEqualTo 再往下走:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
为了创建一个在这里用于执行特征工程的数据处理步骤,我们使用 SKLearnProcessor 加载和转换数据集。 我们通过 local_pipeline_session 类构造函数的变量,它指示工作流步骤在本地模式下运行:
接下来,我们创建我们的第一个实际管道步骤,a ProcessingStep 对象,从 SageMaker SDK 导入。 处理器参数从对 SKLearnProcessor 运行()方法。 此工作流程步骤与笔记本末尾的其他步骤相结合,以指示管道中的操作顺序。
接下来,我们通过首先使用 SageMaker SDK 实例化标准估计器来提供代码来建立训练步骤。 我们通过同样的 local_pipeline_session 估计器的变量,名为 xgb_train,作为 sagemaker_session 争论。 因为我们要训练一个 XGBoost 模型,所以我们必须通过指定以下参数来生成有效的图像 URI,包括框架和几个版本参数:
我们可以选择调用其他估算器方法,例如 set_hyperparameters(),为训练作业提供超参数设置。 现在我们已经配置了一个估计器,我们已经准备好创建实际的训练步骤。 我们再次导入 TrainingStep SageMaker SDK 库中的类:
接下来,我们构建另一个处理步骤来执行模型评估。 这是通过创建一个 ScriptProcessor 实例并通过 local_pipeline_session 对象作为参数:
为了启用训练模型的部署,无论是 SageMaker 实时端点 或批量转换,我们需要创建一个 Model 通过传递模型工件、正确的图像 URI 和可选的我们的自定义推理代码来创建对象。 然后我们通过这个 Model 反对一个 ModelStep,它被添加到本地管道中。 请参阅以下代码:
接下来,我们创建一个批量转换步骤,在该步骤中我们提交一组特征向量并执行推理。 我们首先需要创建一个 Transformer 反对并通过 local_pipeline_session 参数给它。 然后我们创建一个 TransformStep,传递所需的参数,并将其添加到管道定义中:
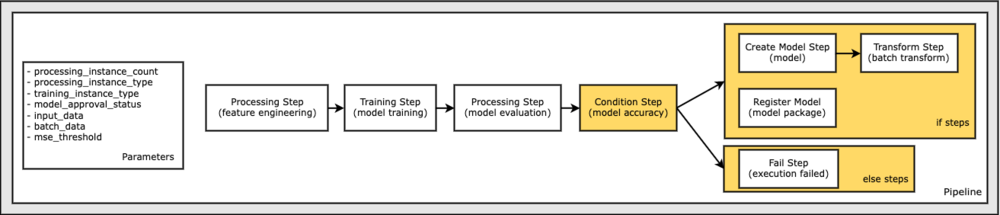
最后,我们想在工作流中添加一个分支条件,以便我们仅在模型评估的结果符合我们的标准时才运行批量转换。 我们可以通过添加一个 ConditionStep 具有特定条件类型,例如 ConditionLessThanOrEqualTo. 然后我们列举两个分支的步骤,本质上定义管道的 if/else 或 true/false 分支。 中提供的 if_steps ConditionStep (步骤创建模型, 步骤转换) 在条件评估为时运行 True.
下图说明了这个条件分支和相关的 if/else 步骤。 根据在条件步骤中比较的模型评估步骤的结果,只运行一个分支。
现在我们已经定义了所有步骤,并创建了底层类实例,我们可以将它们组合成一个管道。 我们提供了一些参数,并通过简单地按所需顺序列出步骤来关键地定义操作顺序。 请注意, TransformStep 此处未显示,因为它是条件步骤的目标,并且作为 step 参数提供给 ConditionalStep 早。
要运行管道,您必须调用两个方法: pipeline.upsert(),它将管道上传到底层服务,以及 pipeline.start(),它开始运行管道。 您可以使用各种其他方法来询问运行状态、列出管道步骤等。 因为我们使用了本地模式管道会话,所以这些步骤都在您的处理器上本地运行。 start 方法下方的单元格输出显示了管道的输出:
您应该在单元格输出的底部看到类似于以下内容的消息:
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
恢复为托管资源
在我们确认管道运行没有错误并且我们对管道的流程和形式感到满意后,我们可以重新创建管道,但使用 SageMaker 托管资源并重新运行它。 唯一需要的改变是使用 PipelineSession 对象而不是 LocalPipelineSession:
止 sagemaker.workflow.pipeline_context 导入 LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session = LocalPipelineSession()pipeline_session = PipelineSession()
这会通知服务在 SageMaker 托管资源上运行引用此会话对象的每个步骤。 鉴于微小的变化,我们仅在以下代码单元中说明所需的代码更改,但需要在每个单元上使用 local_pipeline_session 目的。 然而,这些变化在所有单元格中都是相同的,因为我们只是替换 local_pipeline_session 与对象 pipeline_session 目的。
在到处替换本地会话对象后,我们重新创建管道并使用 SageMaker 托管资源运行它:
清理
如果您想保持 Studio 环境整洁,可以使用以下方法删除 SageMaker 管道和模型。 完整的代码可以在示例中找到 笔记本.
结论
直到最近,您还可以使用 SageMaker 处理和 SageMaker 训练的本地模式功能在本地迭代处理和训练脚本,然后再使用 SageMaker 托管资源对所有数据运行它们。 借助 SageMaker Pipelines 的新本地模式功能,ML 从业者现在可以在迭代其 ML 管道时应用相同的方法,将不同的 ML 工作流拼接在一起。 当管道准备好投入生产时,使用 SageMaker 托管资源运行它只需要更改几行代码。 这减少了开发期间的管道运行时间,从而以更快的开发周期实现更快速的管道开发,同时降低 SageMaker 托管资源的成本。
要了解更多信息,请访问: Amazon SageMaker管道 or 使用 SageMaker 管道在本地运行您的作业.
关于作者
 保罗·哈吉斯 他在 AWS、Amazon 和 Hortonworks 等多家公司专注于机器学习。 他喜欢构建技术解决方案并教人们如何充分利用它。 在加入 AWS 之前,他是 Amazon Exports and Expansions 的首席架构师,帮助 amazon.com 改善国际购物者的体验。 Paul 喜欢帮助客户扩展他们的机器学习计划以解决实际问题。
保罗·哈吉斯 他在 AWS、Amazon 和 Hortonworks 等多家公司专注于机器学习。 他喜欢构建技术解决方案并教人们如何充分利用它。 在加入 AWS 之前,他是 Amazon Exports and Expansions 的首席架构师,帮助 amazon.com 改善国际购物者的体验。 Paul 喜欢帮助客户扩展他们的机器学习计划以解决实际问题。
 尼克拉斯·帕尔姆(Niklas Palm) 是瑞典斯德哥尔摩AWS的解决方案架构师,他帮助北欧的客户在云中取得成功。 他对无服务器技术以及物联网和机器学习特别感兴趣。 在工作之外,尼克拉斯(Niklas)是一名狂热的越野滑雪者和单板滑雪者,并且是一名煮蛋大师。
尼克拉斯·帕尔姆(Niklas Palm) 是瑞典斯德哥尔摩AWS的解决方案架构师,他帮助北欧的客户在云中取得成功。 他对无服务器技术以及物联网和机器学习特别感兴趣。 在工作之外,尼克拉斯(Niklas)是一名狂热的越野滑雪者和单板滑雪者,并且是一名煮蛋大师。
 基里特·达达卡 是在 SageMaker Service SA 团队工作的 ML 解决方案架构师。 在加入 AWS 之前,Kirit 在早期的 AI 初创公司工作,随后在 AI 研究、MLOps 和技术领导方面担任过一段时间的咨询工作。
基里特·达达卡 是在 SageMaker Service SA 团队工作的 ML 解决方案架构师。 在加入 AWS 之前,Kirit 在早期的 AI 初创公司工作,随后在 AI 研究、MLOps 和技术领导方面担任过一段时间的咨询工作。

