生成式人工智能是一种可以创造新内容和想法的人工智能,包括对话、故事、图像、视频和音乐。 它由大型语言模型 (LLM) 提供支持,这些模型经过大量数据的预训练,通常称为基础模型 (FM)。
随着这些法学硕士或法学硕士的出现,客户可以轻松构建基于生成式人工智能的应用程序,用于广告、知识管理和客户支持。 认识到这些应用程序的影响可以为客户提供增强的洞察力,并通过轻松的信息检索和自动化某些耗时的任务,对组织的绩效效率产生积极影响。
借助 AWS 上的生成式 AI,您可以重塑应用程序、打造全新的客户体验并提高整体生产力。
在这篇文章中,我们使用构建一个安全的企业应用程序 AWS放大 调用一个 亚马逊SageMaker JumpStart 基础模型, 亚马逊SageMaker 端点,以及 亚马逊开放搜索服务 解释如何创建文本到文本或文本到图像以及检索增强生成 (RAG)。 您可以使用这篇文章作为参考,使用 AWS 服务在生成式 AI 领域构建安全的企业应用程序。
解决方案概述
该解决方案使用 SageMaker JumpStart 模型将文本到文本、文本到图像和文本嵌入模型部署为 SageMaker 端点。 这些 SageMaker 端点通过以下方式在 Amplify React 应用程序中使用: Amazon API网关 和 AWS Lambda 功能。 为了保护应用程序和 API 免遭无意访问, 亚马逊Cognito 集成到 Amplify React、API Gateway 和 Lambda 函数中。 SageMaker 端点和 Lambda 部署在 私有VPC,因此从 API Gateway 到 Lambda 函数的通信受到 API Gateway VPC 链接的保护。 以下工作流程图说明了该解决方案。
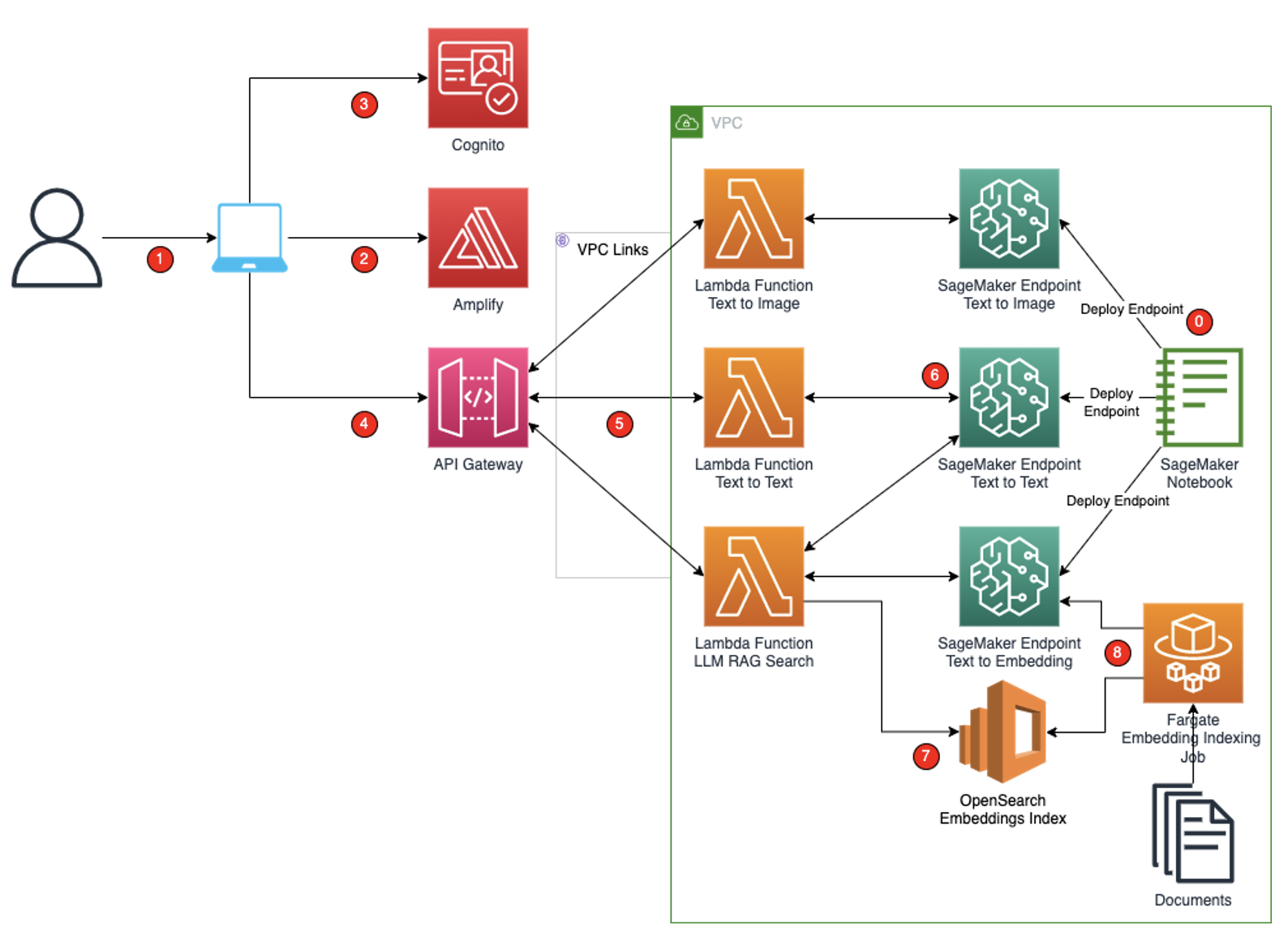
工作流程包括以下步骤:
- 初始设置: SageMaker JumpStart FM 部署为 SageMaker 端点,其中三个端点是根据 SageMaker JumpStart 模型创建的。 文本到图像模型是 Stability AI Stable Diffusion 基础模型,将用于生成图像。 解决方案中部署的用于生成文本的文本到文本模型是 Hugging Face Flan T5 XL 模型。 文本嵌入模型是 Hugging Face GPT 6B FP16 嵌入模型,将用于生成要在 Amazon OpenSearch Service 中索引的嵌入或搜索传入问题的上下文。 可以根据用例和模型性能基准部署替代法学硕士。 有关基础模型的更多信息,请参见 开始使用 Amazon SageMaker JumpStart.
- 您可以从计算机访问 React 应用程序。 React应用程序有三个页面:一个是获取图像提示并显示生成的图像的页面; 接受文本提示并显示生成文本的页面; 一个页面接受一个问题,找到与问题匹配的上下文,并显示文本到文本模型生成的答案。
- 使用 Amplify 库构建的 React 应用程序托管在 Amplify 上,并通过 Amplify 主机 URL 向用户提供服务。 Amplify 为 React 应用程序提供托管环境。 Amplify CLI 用于引导 Amplify 托管环境并将代码部署到 Amplify 托管环境中。
- 如果您尚未经过身份验证,我们将使用 Amplify React UI 库针对 Amazon Cognito 对您进行身份验证。
- 当您提供输入并提交表单时,请求将通过 API 网关进行处理。
- Lambda 函数清理用户输入并调用相应的 SageMaker 端点。 Lambda 函数还根据经过清理的用户输入以 LLM 期望的相应格式构建提示。 这些 Lambda 函数还会重新格式化 LLM 的输出并将响应发送回用户。
- SageMaker 端点部署用于文本到文本 (Flan T5 XXL)、文本到嵌入 (GPTJ-6B) 和文本到图像模型 (Stability AI)。 部署了三个使用推荐的默认 SageMaker 实例类型的独立端点。
- 文档的嵌入是使用文本到嵌入模型生成的,并且这些嵌入被索引到 OpenSearch 服务中。 启用 k 最近邻 (k-NN) 索引以允许从 OpenSearch 服务搜索嵌入。
- An AWS 法门 job 获取文档并将它们分割成更小的包,调用文本到嵌入 LLM 模型,并将返回的嵌入索引到 OpenSearch 服务中以用于搜索上下文,如前所述。
数据集概述
该解决方案使用的数据集是 pile-of-law 字幕可视电话用于 拥抱脸存储库。 该数据集是一个大型法律和行政数据语料库。 对于这个例子,我们使用 train.cc_casebooks.jsonl.xz 在此存储库中。 这是根据法学硕士的要求以 JSONL 格式整理的教育案例集。
先决条件
在开始之前,请确保您具有以下先决条件:
实施解决方案
此 AWS 示例中提供了包含所有架构组件的 AWS CDK 项目 GitHub存储库。 要实施此解决方案,请执行以下操作:
- 克隆 GitHub存储库 到您的计算机。
- 转到根文件夹。
- 初始化Python虚拟环境。
- 安装中指定的所需依赖项
requirements.txt文件中。 - 在项目文件夹中初始化AWS CDK。
- 在项目文件夹中引导 AWS CDK。
- 使用 AWS CDK 部署命令部署堆栈。
- 转到项目文件夹中的 Amplify 文件夹。
- 初始化 Amplify 并接受 CLI 提供的默认值。
- 添加放大托管。
- 从 Amplify 文件夹中发布 Amplify 前端,并记下运行结束时提供的域名。
- 在 Amazon Cognito 控制台上,将用户添加到通过部署预置的 Amazon Cognito 实例。
- 转到步骤 11 中的域名并提供 Amazon Cognito 登录详细信息以访问该应用程序。
触发 OpenSearch 索引作业
AWS CDK 项目部署了一个名为 GenAIServiceTxt2EmbeddingsOSIndexingLambda。 在 Lambda 控制台上导航到此函数。
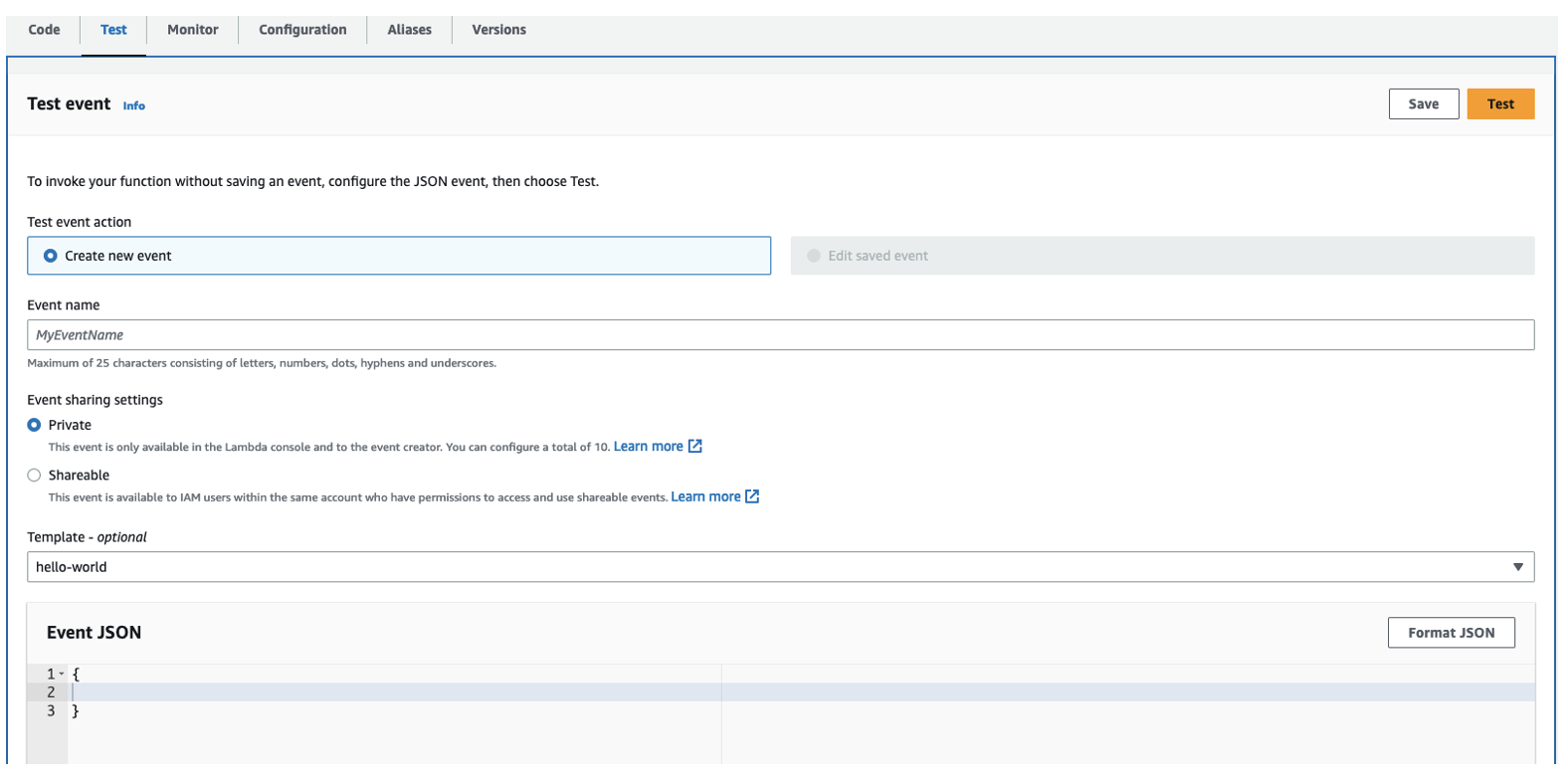
使用空负载运行测试,如以下屏幕截图所示。
此 Lambda 函数触发 Fargate 任务 亚马逊弹性容器服务 (Amazon ECS) 在 VPC 内运行。 此 Fargate 任务采用包含的 JSONL 文件来分段并创建嵌入索引。 每个段嵌入都是调用作为 AWS CDK 项目一部分部署的文本到嵌入 LLM 终端节点的结果。
清理
为了避免将来产生费用,请删除 SageMaker 终端节点并停止所有 Lambda 函数。 此外,删除您在运行应用程序工作流程时创建的 Amazon S3 中的输出数据。 您必须先删除 S3 存储桶中的数据,然后才能删除存储桶。
结论
在这篇文章中,我们演示了一种使用生成式 AI 和 RAG 创建安全企业应用程序的端到端方法。 这种方法可用于在 AWS 上构建安全且可扩展的生成式 AI 应用程序。 我们鼓励您将 AWS CDK 应用程序部署到您的账户中并构建生成式 AI 解决方案。
额外的资源
有关 AWS 上的生成式 AI 应用程序的更多信息,请参阅以下内容:
作者简介
 杰·皮莱 是 Amazon Web Services 的首席解决方案架构师。 作为信息技术领导者,Jay 专注于人工智能、数据集成、商业智能和用户界面领域。 他拥有 23 年与房地产、金融服务、保险、支付和市场研究业务领域的多家客户合作的丰富经验。
杰·皮莱 是 Amazon Web Services 的首席解决方案架构师。 作为信息技术领导者,Jay 专注于人工智能、数据集成、商业智能和用户界面领域。 他拥有 23 年与房地产、金融服务、保险、支付和市场研究业务领域的多家客户合作的丰富经验。
 希哈尔夸特拉 是 Amazon Web Services 的 AI/ML 专家解决方案架构师,与领先的全球系统集成商合作。 他赢得了印度最年轻的发明大师之一的称号,在 AI/ML 和物联网领域拥有 500 多项专利。 Shikhar 协助为组织设计、构建和维护经济高效、可扩展的云环境,并支持 GSI 合作伙伴在 AWS 上构建战略性行业解决方案。 Shikhar 喜欢在业余时间弹吉他、作曲和练习正念。
希哈尔夸特拉 是 Amazon Web Services 的 AI/ML 专家解决方案架构师,与领先的全球系统集成商合作。 他赢得了印度最年轻的发明大师之一的称号,在 AI/ML 和物联网领域拥有 500 多项专利。 Shikhar 协助为组织设计、构建和维护经济高效、可扩展的云环境,并支持 GSI 合作伙伴在 AWS 上构建战略性行业解决方案。 Shikhar 喜欢在业余时间弹吉他、作曲和练习正念。
 卡蒂克·桑蒂 领导一个由解决方案架构师组成的全球团队,专注于与埃森哲一起概念化、构建和推出水平、功能和垂直解决方案,以帮助我们的共同客户在 AWS 上以差异化的方式实现业务转型。
卡蒂克·桑蒂 领导一个由解决方案架构师组成的全球团队,专注于与埃森哲一起概念化、构建和推出水平、功能和垂直解决方案,以帮助我们的共同客户在 AWS 上以差异化的方式实现业务转型。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 汽车/电动汽车, 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- 图表Prime。 使用 ChartPrime 提升您的交易游戏。 访问这里。
- 块偏移量。 现代化环境抵消所有权。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/build-a-secure-enterprise-application-with-generative-ai-and-rag-using-amazon-sagemaker-jumpstart/

