数字化是新常态,没有回头路。 每年,消费者平均访问 191 个需要用户名和密码的网站或服务,预计数字足迹将呈指数级增长。 如此多的风险敞口自然会带来额外的风险,例如账户接管 (ATO)。
每年,不良行为者通过窃取凭据、网络钓鱼、社会工程和多种形式的 ATO 危害数十亿个帐户。 换个角度来看:与 90 年相比,11.4 年的账户接管欺诈增加了 2021%,估计为 2020 亿美元。除了财务影响之外,ATO 损害客户体验,威胁品牌忠诚度和声誉,并在欺诈团队管理拒付和客户索赔。
许多公司,即使是那些拥有复杂欺诈团队的公司,也使用基于规则的解决方案来检测受损账户,因为它们易于创建。 为了加强防御并减少合法用户的摩擦,企业越来越多地投资于人工智能和机器学习 (ML) 以检测帐户接管。
AWS 可以通过以下解决方案帮助您改善欺诈缓解措施 亚马逊欺诈检测器. 这种完全托管的 AI 服务使您能够在没有 ML 专业知识的情况下训练自定义 ML 欺诈检测模型,从而识别潜在的欺诈性在线活动。
这篇文章讨论了如何使用 Amazon Fraud Detector 中的新 Account Takeover Insights (ATI) 模型创建实时检测器终端节点。
解决方案概述
Amazon Fraud Detector 依靠具有定制算法、扩充和特征转换的特定模型来检测多个用例中的欺诈事件。 新推出的 ATI 模型是一种低延迟欺诈检测 ML 模型,旨在检测潜在受损账户和 ATO 欺诈。 ATI 模型检测到的 ATO 欺诈比传统的基于规则的帐户接管解决方案多四倍,同时将合法用户的摩擦程度降至最低。
ATI 模型使用包含您企业历史登录事件的数据集进行训练。 事件标签对于模型训练是可选的,因为 ATI 模型使用了一种创新的无监督学习方法。 该模型区分了实际帐户所有者生成的事件(合法事件)和不良行为者生成的事件(异常事件)。
Amazon Fraud Detector 通过不断汇总提供的数据来得出用户过去的行为。 用户行为的示例包括用户从特定 IP 地址登录的次数。 借助这些额外的扩充和聚合,Amazon Fraud Detector 可以从您的登录事件的一小组输入中生成强大的模型性能。
对于实时预测,您调用 GetEventPrediction 用户提供有效登录凭据后的 API 以量化 ATO 的风险。 作为响应,您会收到一个介于 0 到 1000 之间的模型分数,其中 0 表示欺诈风险低,1000 表示欺诈风险高,结果基于您定义的一组业务规则。 然后,您可以采取适当的措施:批准登录、拒绝登录或通过强制执行额外的身份验证来质询用户。
您还可以使用 ATI 模型异步评估帐户登录并根据结果采取行动,例如将帐户添加到调查队列,以便人工审核者可以确定是否应采取进一步行动。
以下步骤概述了训练 ATI 模型和发布检测器端点以生成欺诈预测的过程:
- 准备和验证数据。
- 定义实体、事件和事件变量以及事件标签(可选)。
- 上传事件数据。
- 开始模型训练。
- 评估模型。
- 创建检测器端点并定义业务规则。
- 获得实时预测。
先决条件
在开始之前,请完成以下先决条件步骤:
准备和验证数据
Amazon Fraud Detector 要求您以 UTF-8 格式编码的 CSV 文件提供您的用户账户登录数据。 对于 ATI,您必须在 CSV 文件的标题行中提供某些事件元数据和事件变量。
所需的事件元数据如下:
- 事件编号 – 登录事件的唯一标识符。
- 实体_类型 – 执行登录事件的实体,例如商家或客户。
- ENTITY_ID – 执行登录事件的实体的标识符。
- EVENT_TIMESTAMP – 登录事件发生时的时间戳。 时间戳格式必须采用 UTC 中的 ISO 8601 标准。
- EVENT_LABEL(可选) – 将事件分类为欺诈或合法的标签。 您可以使用任何标签,例如欺诈、合法、1 或 0。
事件元数据必须为大写字母。 登录事件不需要标签。 但是,我们建议包括 EVENT_LABEL 元数据并为您的登录事件提供标签(如果有)。 如果您提供标签,Amazon Fraud Detector 会使用它们来自动计算账户接管发现率并将其显示在模型性能指标中。
ATI 模型具有必需变量和可选变量。 事件变量名称必须为小写字母。
下表总结了强制变量。
| 产品分类 | 变量类型 | 产品描述 |
|---|---|---|
| IP地址 | IP_ADDRESS |
登录事件中使用的 IP 地址 |
| 浏览器和设备 | USERAGENT |
登录事件中使用的浏览器、设备和操作系统 |
| 有效凭证 | VALIDCRED |
指示用于登录的凭据是否有效 |
下表总结了可选变量。
| 产品分类 | Type | 产品描述 |
|---|---|---|
| 浏览器和设备 | FINGERPRINT |
浏览器或设备指纹的唯一标识符 |
| 会话ID | SESSION_ID |
身份验证会话的标识符 |
| 标签 | EVENT_LABEL |
将事件分类为欺诈或合法的标签(例如 fraud, legit, 1或 0) |
| 时间戳 | LABEL_TIMESTAMP |
上次更新标签时的时间戳; 这是必需的,如果 EVENT_LABEL 提供 |
您可以提供其他变量。 但是,Amazon Fraud Detector 不会包含这些变量来训练 ATI 模型。
数据集准备
当您开始准备登录数据时,您必须满足以下要求:
- 提供至少 1,500 个实体(个人用户帐户),每个实体至少有两个关联的登录事件
- 您的数据集必须涵盖至少 30 天的登录事件
以下配置是可选的:
- 您的数据集可以包含登录失败事件的示例
- 您可以选择将这些不成功的登录标记为
fraudulentorlegitimate - 您可以准备超过 6 个月的登录事件的历史数据,包括 100,000 个实体
我们提供了一个 样本数据集 用于您可以开始使用的测试目的。
数据验证
在创建 ATI 模型之前,Amazon Fraud Detector 会检查您包含在数据集中用于训练模型的元数据和变量是否满足大小和格式要求。 有关详细信息,请参阅 数据集验证. 如果数据集未通过验证,则不会创建模型。 有关常见数据集错误的详细信息,请参阅 常见事件数据集错误.
定义实体、事件类型和事件变量
在本节中,我们将介绍创建实体、事件类型和事件变量的步骤。 或者,您还可以定义事件标签。
定义实体
实体 定义谁在执行事件。 要创建实体,请完成以下步骤:
- 在 Amazon Fraud Detector 控制台的导航窗格中,选择 实体.
- 创建.
- 输入实体名称和可选描述。
- 创建实体.
定义事件和事件变量
事件是针对欺诈风险评估的业务活动; 此事件由我们刚刚创建的实体执行。 事件类型定义发送到 Amazon Fraud Detector 的事件的结构,包括事件变量、执行事件的实体,以及对事件进行分类的标签(如果有)。
要创建事件,请完成以下步骤:
- 在 Amazon Fraud Detector 控制台的导航窗格中,选择 展会活动.
- 创建.
- 针对 名字,输入事件类型的名称。
- 针对 实体,选择在上一步中创建的实体。
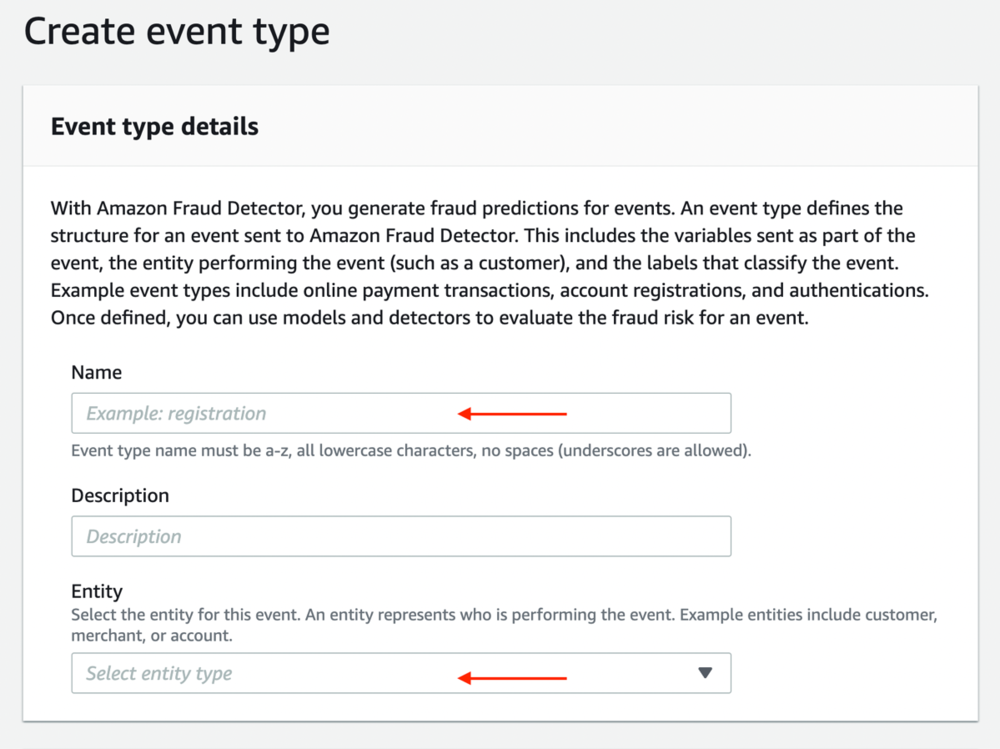
定义事件变量
对于事件变量,请完成以下步骤:
- 在 创建 IAM 角色部分,输入您上传训练数据的特定存储桶名称。
S3 存储桶的名称必须是您上传数据集的名称。 否则,您会收到拒绝访问异常错误。 - 创建角色.

- 针对 资料位置,输入您的训练数据的路径,该路径是您在先决条件步骤中复制的 S3 URI,然后选择 上传.
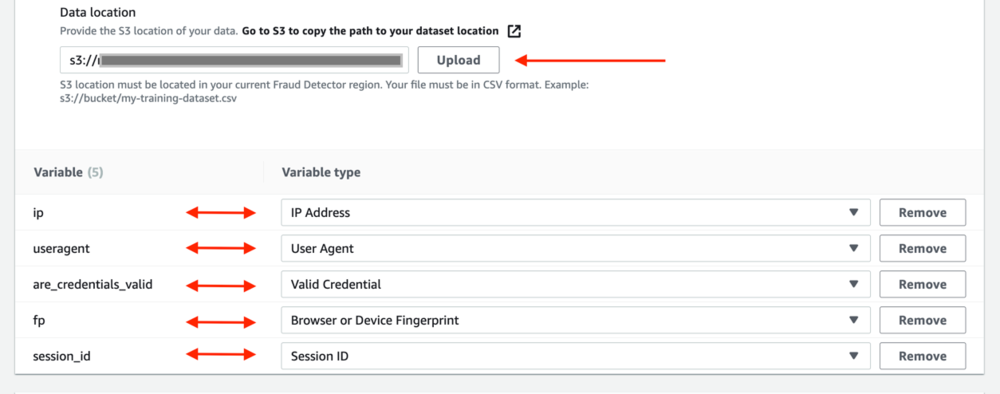
Amazon Fraud Detector 从您的训练数据集中提取标头并为每个标头创建一个变量。 确保将变量分配给正确的变量类型。 作为模型训练过程的一部分,Amazon Fraud Detector 使用与变量关联的变量类型来执行变量扩充和特征工程。 有关变量类型的更多详细信息,请参阅 变量类型.
定义事件标签(可选)
标签用于将个别事件分类为欺诈或合法事件。 事件标签对于模型训练是可选的,因为 ATI 模型使用了一种创新的无监督学习方法。 该模型区分了实际帐户所有者生成的事件(合法事件)和滥用行为者生成的事件(异常事件)。 我们建议您包括 EVENT_LABEL 元数据并为您的登录事件提供标签(如果有)。 如果您提供标签,Amazon Fraud Detector 会使用它们来自动计算账户接管发现率并将其显示在模型性能指标中。
要创建事件,请完成以下步骤:
- 定义两个标签(对于这篇文章,1 和 0)。
- 创建事件类型.

上传活动数据
在本次会议中,我们将介绍将事件数据上传到服务以进行模型训练的步骤。
ATI 模型在 Amazon Fraud Detector 内部存储的数据集上进行训练。 通过将事件数据存储在 Amazon Fraud Detector 中,您可以训练使用自动计算变量的模型来提高性能、简化模型重新训练并更新欺诈标签以关闭机器学习反馈循环。 看 存储的事件 有关使用 Amazon Fraud Detector 存储事件数据集的更多信息。
定义事件后,导航到 存储的事件 标签。 在 存储的事件 选项卡,您可以查看有关数据集的信息,例如存储的事件数和数据集的总大小(以 MB 为单位)。 因为您刚刚创建了这个事件类型,所以还没有存储的事件。 在此页面上,您可以打开或关闭事件提取。 当事件摄取开启时,您可以将历史事件数据上传到 Amazon Fraud Detector,并实时自动存储来自预测的事件数据。
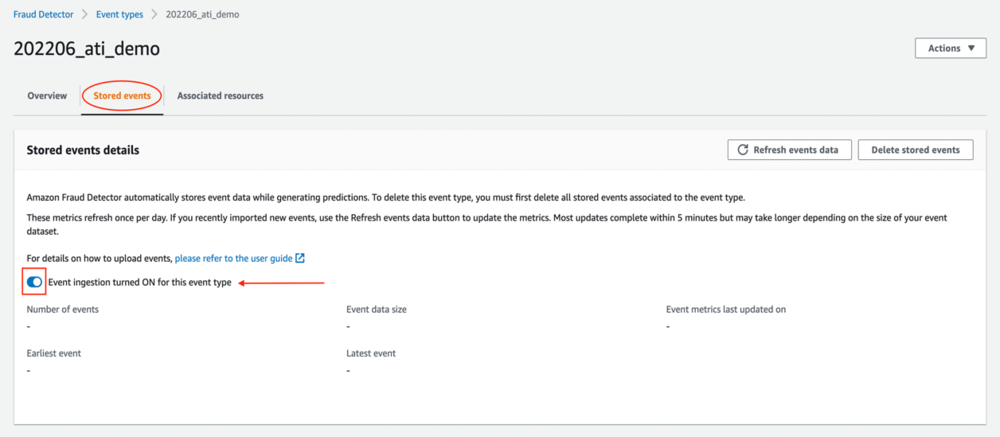
存储历史数据的最简单方法是上传 CSV 文件并导入事件。 或者,您可以使用 SendEvent API(见我们的 GitHub存储库 用于示例笔记本)。 要从 CSV 文件导入事件,请完成以下步骤:
- 下 导入事件数据,选择 新进口.
您可能需要创建一个新的 IAM 角色。 导入事件功能需要对 Amazon S3 的读取和写入访问权限。

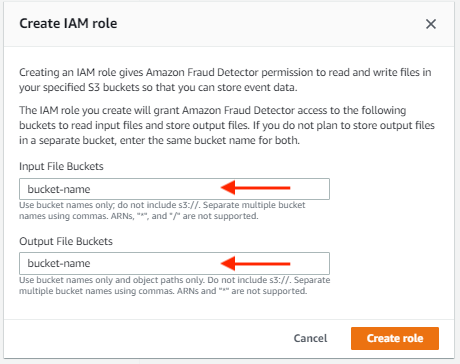
- 创建一个新的 IAM 角色并为输入和输出文件提供 S3 存储桶。
您创建的 IAM 角色授予 Amazon Fraud Detector 访问这些存储桶以读取输入文件和存储输出文件的权限。 如果您不打算将输出文件存储在单独的存储桶中,请为两者输入相同的存储桶名称。 - 创建角色.
- 输入包含您的事件数据的 CSV 文件的位置。 这应该是您之前复制的 S3 URI。
- 选择 Start 开始 开始导入事件。
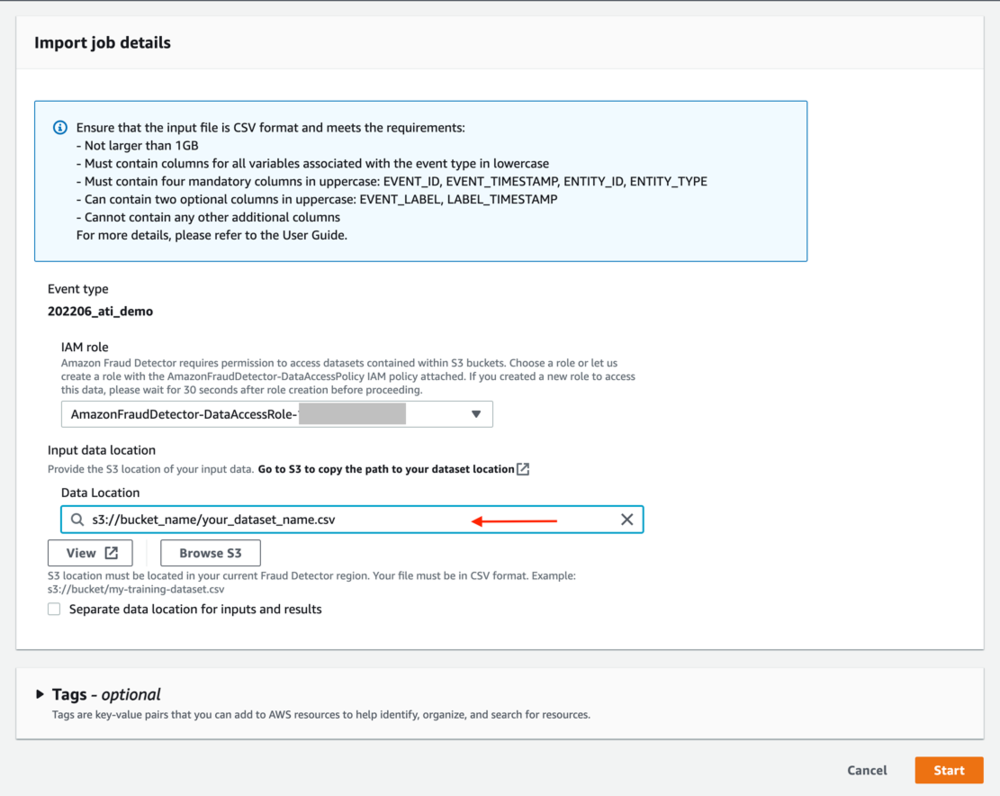
导入时间因您要导入的事件数量而异。 对于包含 20,000 个事件的数据集,该过程大约需要 12 分钟,并且在您刷新页面后,状态会更改为 Completed. 如果状态更改为 Error,选择作业名称以显示导入失败的原因。
启动模型训练
成功导入事件后,您就拥有了启动模型训练的所有部分。 要训练模型,请完成以下步骤:
- 在 Amazon Fraud Detector 控制台的导航窗格中,选择 型号.
- 新增模型 并选择 建立模型.
- 针对 型号名称, 为您的模型输入所需的名称
- 针对 型号类型, 选择 收购账户洞察.
- 针对 事件类型,选择您之前创建的事件类型。
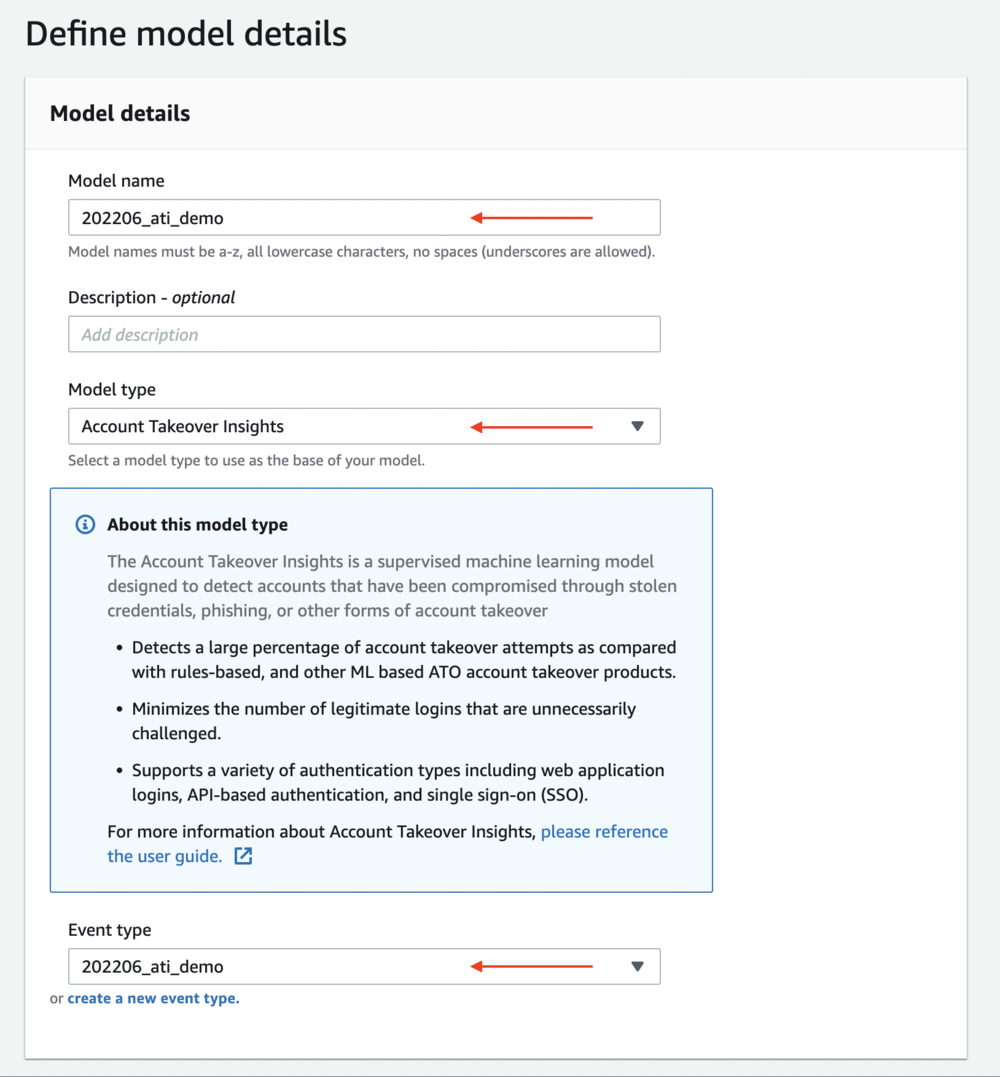
- 下 历史事件数据,如果需要,您可以指定事件的日期范围来训练模型。
- 下一页.

- 在本文中,您通过识别用作模型输入的变量来配置训练。
- 评估变量后,选择 下一页.
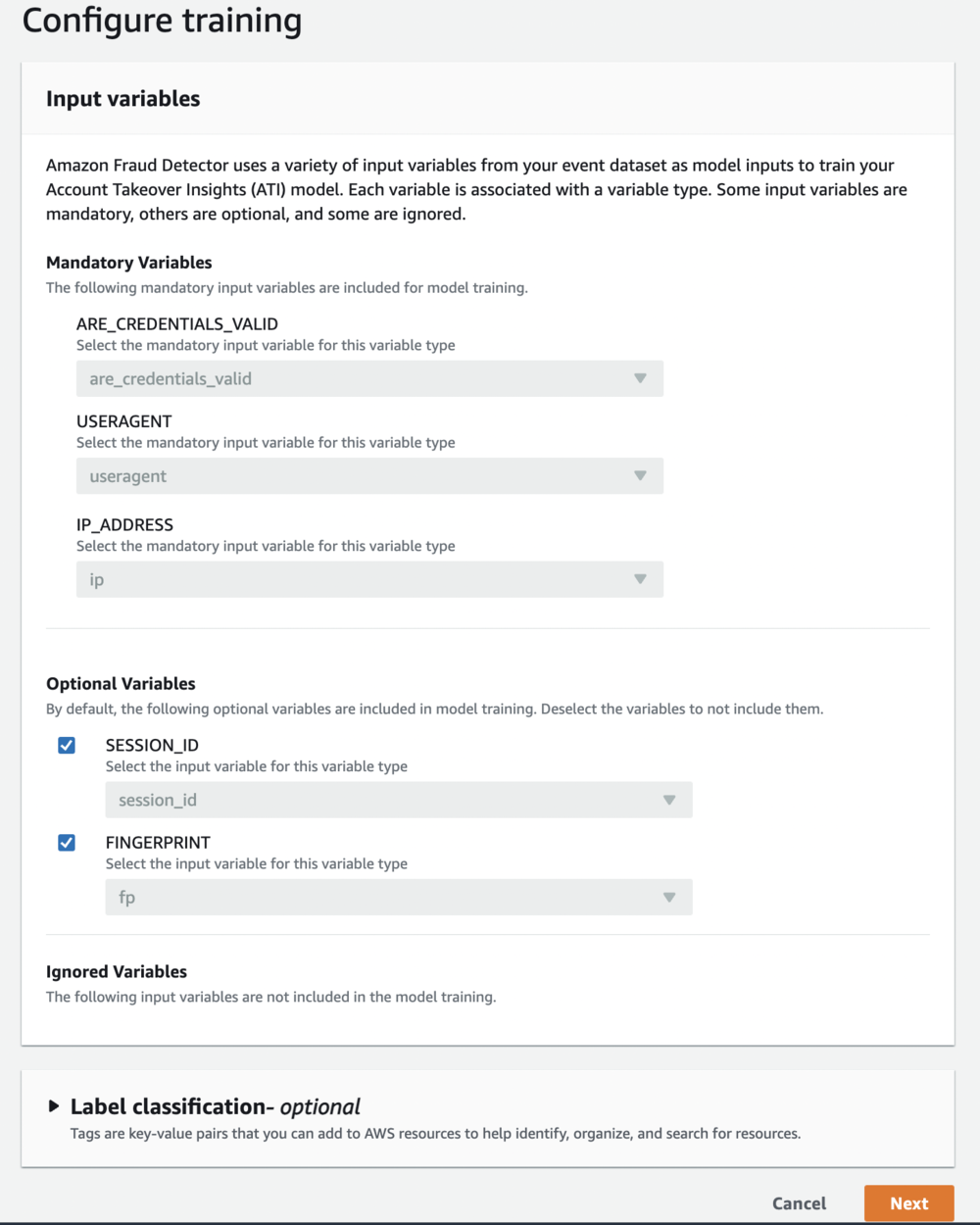
最好的做法是包含所有可用变量,即使您不确定它们对模型的价值。 训练模型后,Amazon Fraud Detector 会提供每个变量对模型性能影响的排名列表,以便您知道是否在未来的模型训练中包含该变量。 如果提供了标签,Amazon Fraud Detector 会根据模型的发现率使用它们来评估和显示模型性能。
如果未提供标签,Amazon Fraud Detector 会使用负抽样来提供示例或类似的登录尝试,帮助模型区分合法活动和欺诈活动。 这会产生精确的风险评分,从而提高模型捕获错误标记的合法活动的能力。
查看前两步配置的模型后,选择 创建 并训练模型。
您可以在控制台页面中看到模型处于训练状态。 创建和训练模型大约需要 45 分钟才能完成。 当模型停止训练时,您可以通过选择模型版本来检查模型性能。

评估模型性能并部署模型
在本次会议中,我们将逐步介绍审查和评估模型性能的步骤。
Amazon Fraud Detector 使用 15% 的未用于训练模型的数据来验证模型性能并提供性能指标。 您需要考虑这些指标和您的业务目标,以定义与您的业务模型相一致的阈值。 有关指标以及如何确定阈值的更多详细信息,请参阅 模型绩效指标.
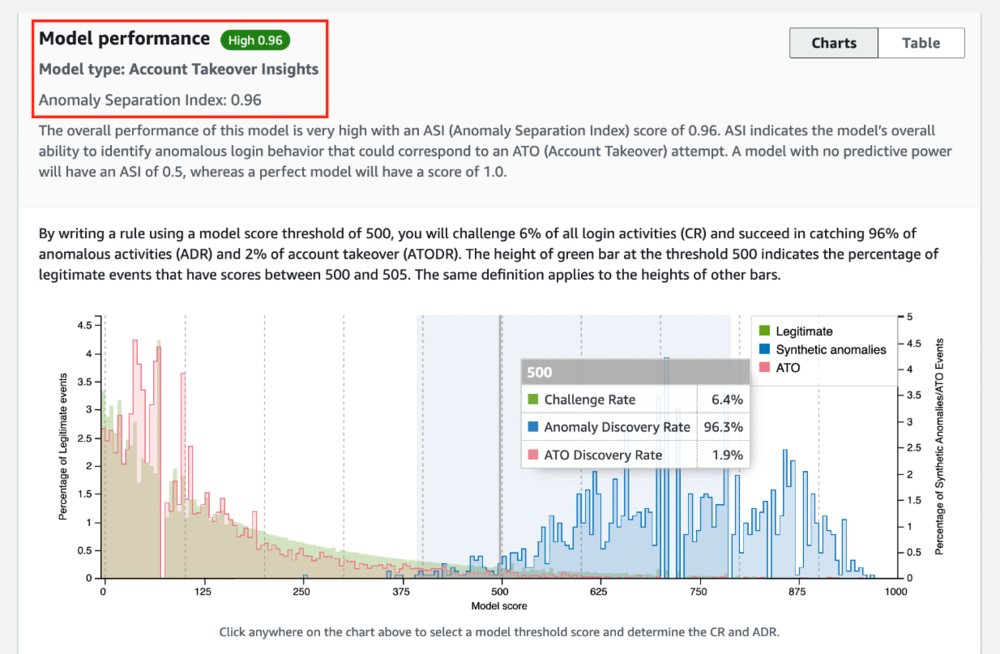
ATI 是异常检测模型而不是分类模型; 因此,评估指标与分类模型不同。 当您的 ATI 模型完成训练后,您可以看到异常分离指数 (ASI),这是模型识别高风险异常登录能力的整体衡量标准。 ASI 75% 或更高被认为是好,90% 或更高被认为是高,低于 75% 被认为是差。
为了帮助选择正确的余额,Amazon Fraud Detector 提供了以下指标来评估 ATI 模型的性能:
- 异常分离指数 (ASI) – 总结模型将异常活动与用户预期行为区分开来的整体能力。 没有可分离能力的模型将具有最低的 ASI 分数,为 0.5。 相比之下,具有高分离能力的模型将具有最高的 ASI 分数,为 1.0。
- 挑战率 (CR) – 分数阈值表示模型建议以一次性密码、多因素身份验证、身份验证、调查等形式挑战的登录事件的百分比。
- 异常发现率 (ADR) – 量化模型在所选分数阈值处可以检测到的异常百分比。 较低的分数阈值会增加模型捕获的异常百分比。 尽管如此,它还需要挑战更大比例的登录事件,从而导致更高的客户摩擦。
- ATO 发现率 (ATODR) – 量化模型可以在所选分数阈值处检测到的帐户泄露事件的百分比。 仅当摄取的数据集中存在 50 个或更多具有至少一个标记 ATO 事件的实体时,此指标才可用。
在以下示例中,我们的 ASI 为 0.96(高),这表明将异常活动与用户的正常行为区分开来的能力很高。 通过使用 500 的模型得分阈值编写规则,您可以对 6% 的所有登录活动提出挑战或制造摩擦,从而捕获 96% 的异常活动。
另一个重要的指标是模型变量的重要性。 变量重要性让您了解不同变量与模型性能的关系。 您可以有两种类型的变量:原始变量和聚合变量。 原始变量是基于数据集定义的变量,而聚合变量是多个变量的组合,这些变量经过丰富并具有聚合的重要性值。
有关变量重要性的更多信息,请参阅 模型变量重要性.

相对于其余变量具有更高数字的变量(原始或聚合)可能表明模型可能过度拟合。 相反,具有相对最低数字的变量可能只是噪音。
在查看模型性能并确定哪些模型分数阈值与您的业务模型一致后,您可以部署模型版本。 为此,在 行动 菜单中选择 部署模型版本. 部署模型后,我们创建一个检测器端点并执行实时预测。

创建检测器端点并定义业务规则
Amazon Fraud Detector 使用检测器终端节点生成欺诈预测。 检测器包含您要评估是否存在欺诈的特定事件的检测逻辑,例如经过训练的模型和业务规则。 检测逻辑使用规则告诉 Amazon Fraud Detector 如何解释与模型关联的数据。
要创建检测器,请完成以下步骤:
- 在 Amazon Fraud Detector 控制台的导航窗格中,选择 探测器.
- 创建检测器.
- 针对 检测器名称,输入名称。
- 或者,描述您的检测器。
- 针对 事件类型,选择与之前创建的模型相同的事件类型。
- 下一页.

- 点击 添加模型(可选) 页面,选择 新增模型.
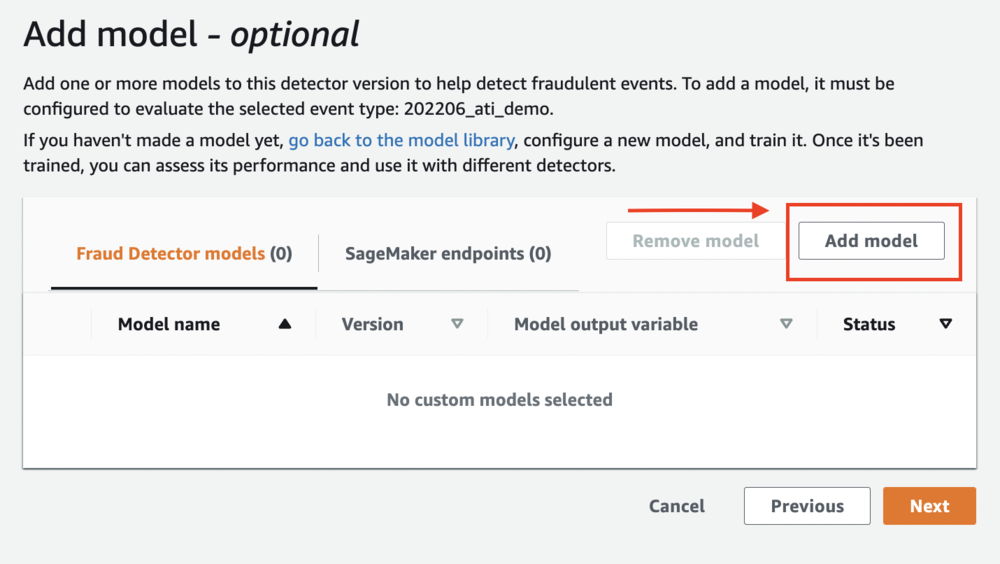
- 要添加模型,请选择您在模型训练步骤中训练和发布的模型,然后选择活动版本。
- 新增模型.
作为下一步的一部分,您将创建定义结果的业务规则。 规则是告诉 Amazon Fraud Detector 如何在欺诈预测期间解释变量值的条件。 规则由一个或多个变量、一个逻辑表达式和一个或多个结果组成。 结果是欺诈预测的结果,如果在评估期间规则匹配,则会返回结果。
- 确定
decline_ruleas$= 950有结果deny_login. - 确定
friction_ruleas$ your_model_name _insightscore >= 855和$ your_model_name_insightscore >= 950有结果challenge_login. - 确定
approve_ruleas$account_takeover_model_insightscore < 855有结果approve_login.
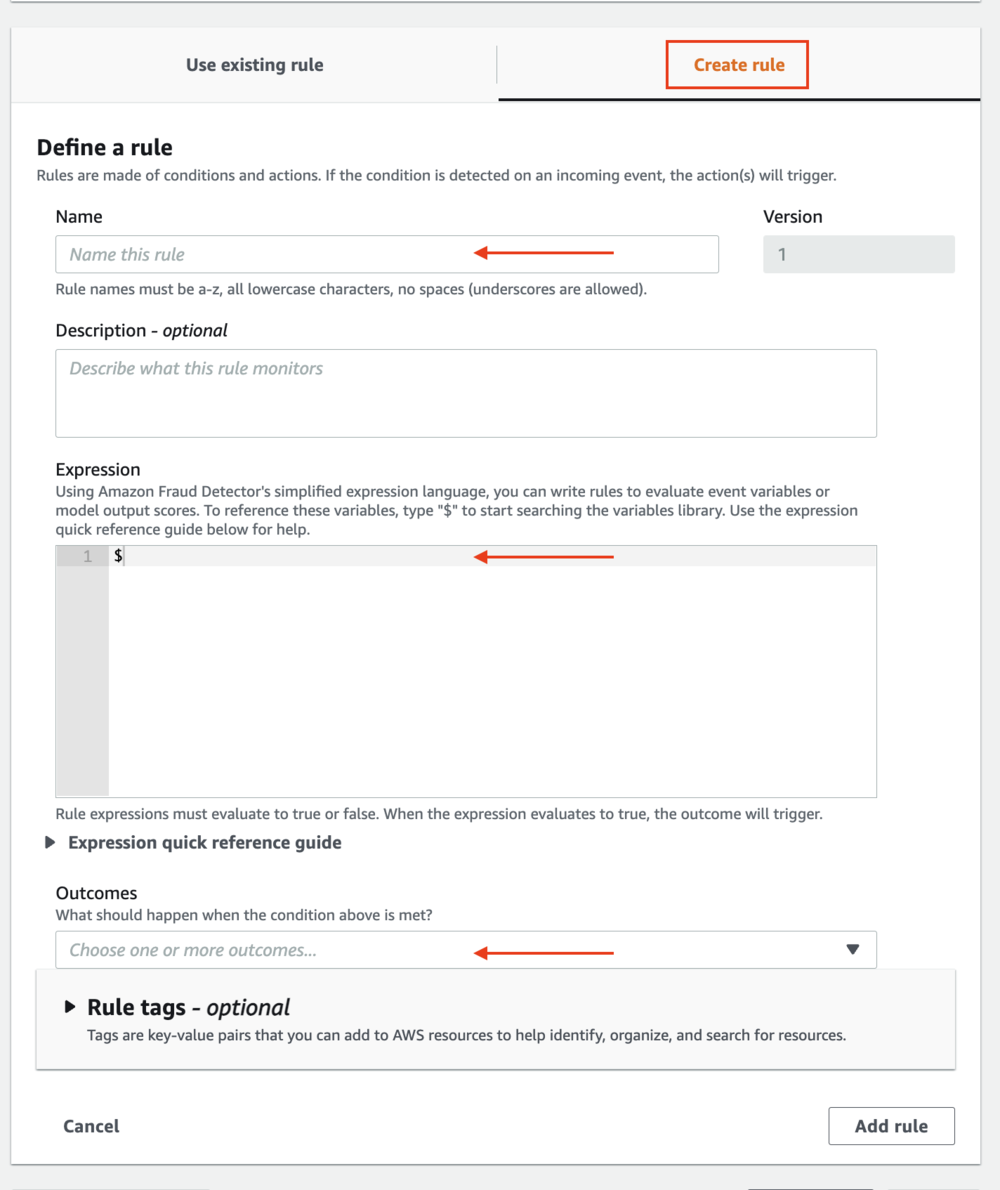
结果是返回的字符串 GetEventPrediction API 响应。 您可以使用结果通过调用应用程序和下游系统来触发事件,或者简单地识别谁可能是欺诈或合法的。
- 点击 添加规则 页面,选择 下一页 添加完所有规则后。

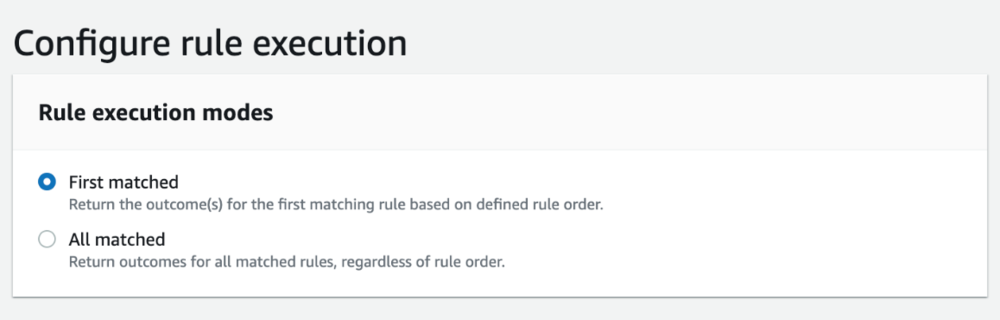
- 在 配置规则执行 部分,为您的规则引擎选择模式。
Amazon Fraud Detector 规则引擎有两种模式:首先匹配或全部匹配。 第一个匹配模式用于顺序规则运行,返回满足第一个条件的结果。 另一种模式是全部匹配,它评估所有规则并返回所有匹配规则的结果。 在此示例中,我们为检测器使用第一个匹配模式。
 在此过程之后,您就可以创建检测器并运行一些测试了。
在此过程之后,您就可以创建检测器并运行一些测试了。
- 要运行测试,请转到您新创建的检测器并选择您要使用的检测器版本。
- 根据要求提供变量值并选择 运行测试.
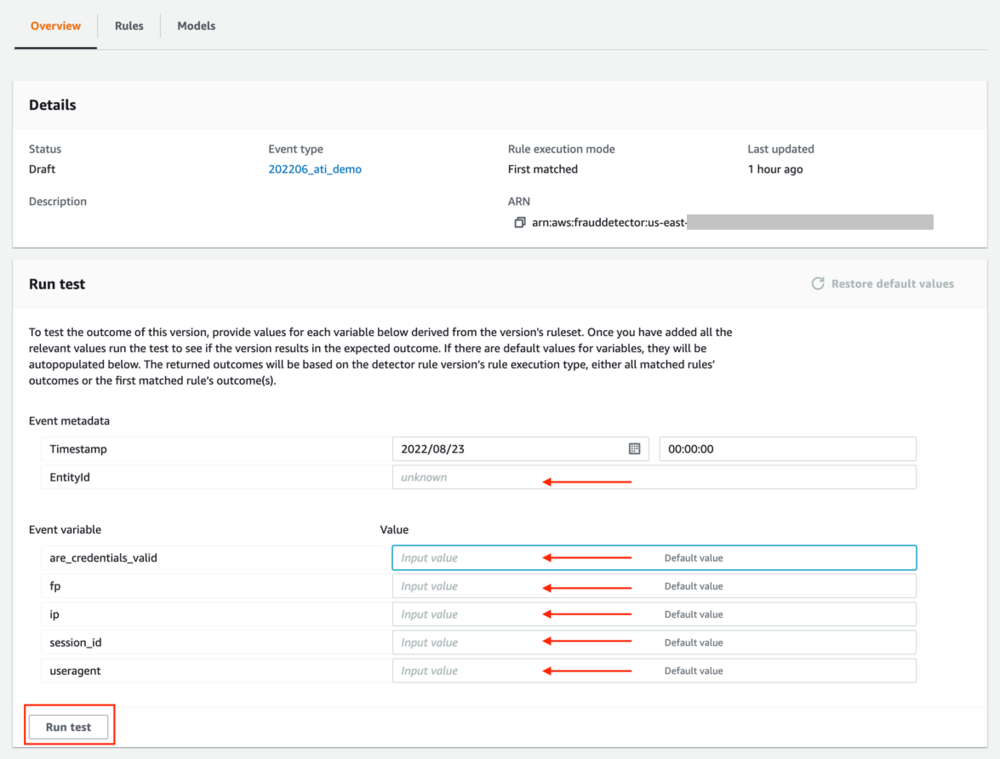
作为测试的结果,您会收到基于您的业务规则的风险评分和结果。
您还可以通过转到左侧面板并选择来搜索过去的预测 搜索过去的预测。 预测基于每个变量对欺诈事件总体可能性的贡献。 以下屏幕截图是过去预测的示例,显示了输入变量以及它们如何影响欺诈预测分数。

获取实时预测
要获得实时预测并将 Amazon Fraud Detector 集成到您的工作流程中,我们需要发布检测器终端节点。 完成以下步骤:
- 转到新创建的检测器并选择检测器版本,即版本 1。
- 点击 行动 菜单中选择 发布.
您可以使用已发布的检测器执行实时预测,方法是调用 GetEventPrediction API。 以下是用于调用的示例 Python 代码 GetEventPrediction API:
结论
Amazon Fraud Detector 依靠具有定制算法、扩充和特征转换的特定模型来检测多个用例中的欺诈事件。 在这篇文章中,您学习了如何摄取数据、训练和部署模型、编写业务规则以及发布检测器,以便对可能被盗的账户生成实时欺诈预测。
参观 亚马逊欺诈检测器 了解有关 Amazon Fraud Detector 或我们的更多信息 GitHub回购 用于代码示例、笔记本和合成数据集。
关于作者
 马塞尔·皮维达尔 是全球专家组织的高级 AI 服务解决方案架构师。 Marcel 拥有 20 多年通过技术为金融科技、支付提供商、制药和政府机构解决业务问题的经验。 他目前的重点领域是风险管理、欺诈预防和身份验证。
马塞尔·皮维达尔 是全球专家组织的高级 AI 服务解决方案架构师。 Marcel 拥有 20 多年通过技术为金融科技、支付提供商、制药和政府机构解决业务问题的经验。 他目前的重点领域是风险管理、欺诈预防和身份验证。
 迈克·艾姆斯 从数据科学家转变为身份验证解决方案专家,他在开发机器学习和人工智能解决方案以保护组织免受欺诈、浪费和滥用方面拥有丰富的经验。 在他的业余时间,你可以找到他徒步旅行、骑山地自行车或和他的狗 Max 一起玩 freebee。
迈克·艾姆斯 从数据科学家转变为身份验证解决方案专家,他在开发机器学习和人工智能解决方案以保护组织免受欺诈、浪费和滥用方面拥有丰富的经验。 在他的业余时间,你可以找到他徒步旅行、骑山地自行车或和他的狗 Max 一起玩 freebee。

