亚马逊泰坦图像生成器 G1 是一种尖端的文本到图像模型,可通过 亚马逊基岩,它能够理解在不同上下文中描述多个对象的提示,并在其生成的图像中捕获这些相关细节。它已在美国东部(弗吉尼亚北部)和美国西部(俄勒冈)AWS 区域推出,可以执行高级图像编辑任务,例如智能裁剪、修复和背景更改。然而,用户希望使模型适应模型尚未训练的自定义数据集中的独特特征。自定义数据集可以包含与您的品牌指南或特定风格(例如之前的营销活动)一致的高度专有的数据。为了解决这些用例并生成完全个性化的图像,您可以使用您自己的数据微调 Amazon Titan Image Generator Amazon Bedrock 的自定义模型.
从生成图像到编辑图像,文本到图像模型在各个行业都有广泛的应用。它们可以增强员工的创造力,并提供仅通过文字描述想象新可能性的能力。例如,它可以帮助建筑师进行设计和平面图规划,并通过提供可视化各种设计的能力来实现更快的创新,而无需手动创建它们。同样,它可以通过简化图形和插图的生成来帮助各个行业的设计,例如制造业、零售业的时装设计和游戏设计。文本到图像模型还允许个性化广告以及媒体和娱乐用例中的交互式和沉浸式视觉聊天机器人,从而增强您的客户体验。
在这篇文章中,我们将引导您完成对 Amazon Titan 图像生成器模型进行微调的过程,以了解两个新类别:我们最喜欢的宠物 Ron 狗和 Smila 猫。我们讨论如何为模型微调任务准备数据以及如何在 Amazon Bedrock 中创建模型自定义作业。最后,我们向您展示如何测试和部署您的微调模型 预置吞吐量.
 |
 |
| 罗恩狗 | 斯米拉猫 |
在微调作业之前评估模型功能
基础模型经过大量数据的训练,因此您的模型可能开箱即用,运行良好。这就是为什么检查您是否确实需要针对您的用例微调模型或者即时工程是否足够的原因是一个很好的做法。让我们尝试使用基本 Amazon Titan 图像生成器模型生成狗 Ron 和猫 Smila 的一些图像,如以下屏幕截图所示。
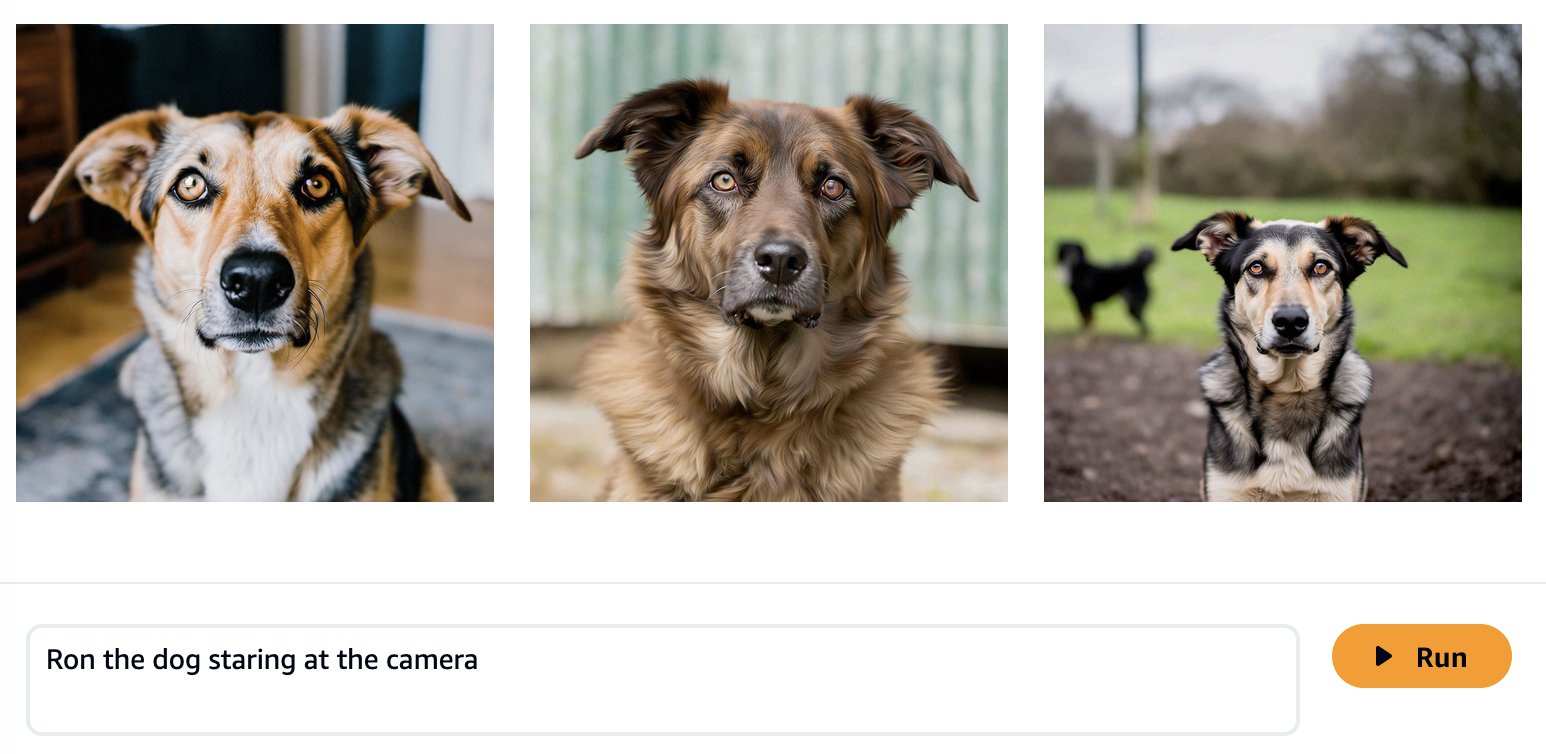

正如预期的那样,开箱即用的模型还不认识 Ron 和 Smila,并且生成的输出显示不同的狗和猫。通过一些及时的工程设计,我们可以提供更多细节,以更接近我们最喜欢的宠物的外观。


尽管生成的图像与 Ron 和 Smila 更相似,但我们发现该模型无法再现他们的完整相似之处。现在让我们开始对 Ron 和 Smila 的照片进行微调,以获得一致的个性化输出。
微调 Amazon Titan 图像生成器
Amazon Bedrock 为您提供无服务器体验,用于微调 Amazon Titan 图像生成器模型。您只需准备数据并选择超参数,AWS 将为您处理繁重的工作。
当您使用 Amazon Titan Image Generator 模型进行微调时,将在由 AWS 拥有和管理的 AWS 模型开发账户中创建该模型的副本,并创建模型自定义作业。然后,该作业访问来自 VPC 的微调数据,并且亚马逊 Titan 模型的权重已更新。然后将新模型保存到 亚马逊简单存储服务 (Amazon S3) 与预训练模型位于同一模型开发帐户中。它现在只能由您的账户用于推理,不会与任何其他 AWS 账户共享。运行推理时,您可以通过 预配置容量计算 或直接使用 Amazon Bedrock 的批量推理。独立于所选的推理模式,您的数据保留在您的账户中,不会复制到任何 AWS 拥有的账户或用于改进 Amazon Titan Image Generator 模型。
下图说明了此工作流程。
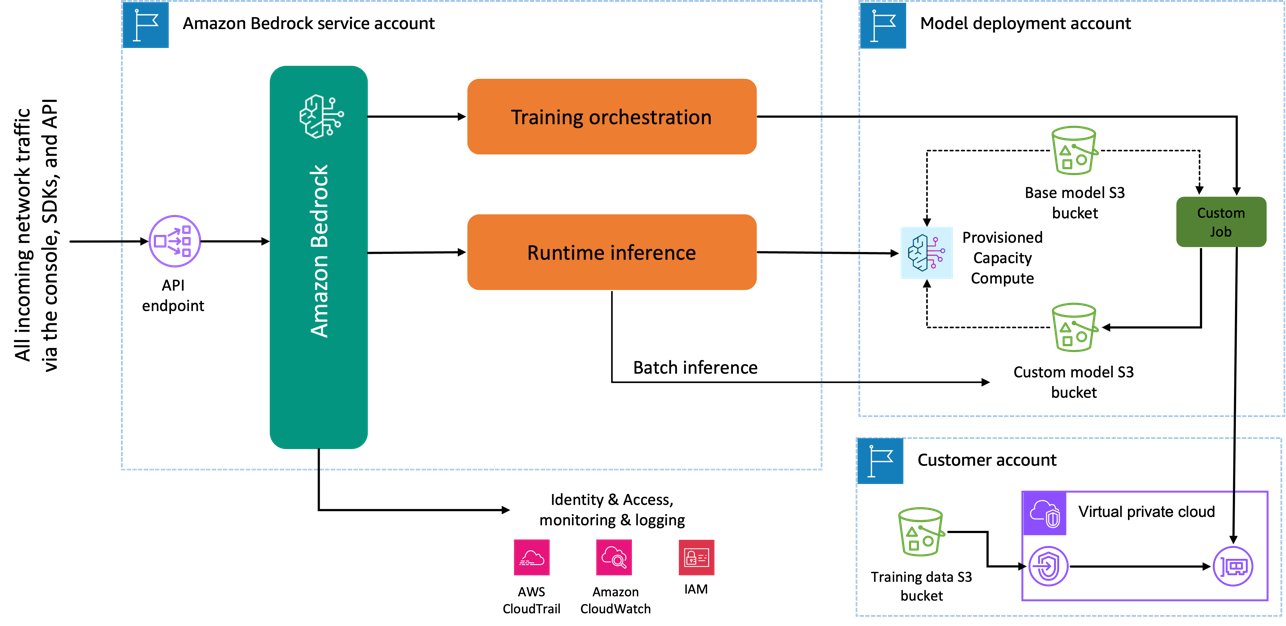
数据隐私和网络安全
用于微调的数据(包括提示)以及自定义模型在您的 AWS 账户中保持私密。它们不会共享或用于模型训练或服务改进,也不会与第三方模型提供商共享。所有用于微调的数据在传输和静态时都经过加密。数据保留在处理 API 调用的同一区域中。您还可以使用 AWS私有链接 在您的数据所在的 AWS 账户与 VPC 之间创建私有连接。
资料准备
在创建模型定制作业之前,您需要 准备你的训练数据集。训练数据集的格式取决于您正在创建的自定义作业的类型(微调或持续预训练)以及数据的形式(文本到文本、文本到图像或图像到图像)嵌入)。对于 Amazon Titan 图像生成器模型,您需要提供要用于微调的图像以及每个图像的标题。 Amazon Bedrock 希望您的图像存储在 Amazon S3 上,并且图像和标题对以包含多个 JSON 行的 JSONL 格式提供。
每个 JSON 行都是一个示例,其中包含图像引用、图像的 S3 URI 以及包含图像文本提示的标题。您的图像必须是 JPEG 或 PNG 格式。以下代码显示了该格式的示例:
{“image-ref”:“s3://bucket/path/to/image001.png”,“标题”:“"} {"image-ref": "s3://bucket/path/to/image002.png", "标题": ""} {"image-ref": "s3://bucket/path/to/image003.png", "标题": ""}
由于“Ron”和“Smila”是也可以在其他上下文中使用的名称,例如人名,因此我们在创建提示以微调模型时添加标识符“Ron the dogs”和“Smila the cat” 。尽管这不是微调工作流程的要求,但这些附加信息在为新类定制模型时为模型提供了更多的上下文清晰度,并且将避免“Ron the dogs”与一个叫 Ron 的人以及“斯米拉猫”与乌克兰斯米拉市。使用这种逻辑,下图显示了我们的训练数据集的示例。
 |
 |
 |
| 罗恩狗躺在白色的狗床上 | 罗恩狗坐在瓷砖地板上 | 罗恩狗躺在汽车座椅上 |
 |
 |
 |
| 躺在沙发上的斯米拉猫 | 猫斯米拉躺在沙发上盯着相机 | 躺在宠物笼里的斯米拉猫 |
当将数据转换为定制作业所需的格式时,我们得到以下示例结构:
{“图像参考”:“/ron_01.jpg", "caption": "罗恩狗躺在白色的狗床上"} {"image-ref": "/ron_02.jpg", "caption": "罗恩狗坐在瓷砖地板上"} {"image-ref": "/ron_03.jpg", "caption": "罗恩狗躺在汽车座椅上"} {"image-ref": "/smila_01.jpg", "caption": "躺在沙发上的 Smila 猫"} {"image-ref": "/smila_02.jpg", "caption": "Smila 猫坐在窗边,旁边是一只雕像猫"} {"image-ref": "/smila_03.jpg", "caption": "躺在宠物笼上的 Smila 猫"}
创建 JSONL 文件后,我们需要将其存储在 S3 存储桶上以开始自定义作业。 Amazon Titan Image Generator G1 微调作业将处理 5-10,000 张图像。对于本文讨论的示例,我们使用 60 张图像:30 张狗 Ron 的图像和 30 张猫 Smila 的图像。一般来说,提供更多您想要学习的风格或类别将提高微调模型的准确性。但是,用于微调的图像越多,完成微调作业所需的时间就越多。使用的图像数量也会影响微调工作的定价。参考 亚马逊基岩定价 获取更多信息.
微调 Amazon Titan 图像生成器
现在我们已经准备好了训练数据,我们可以开始新的定制工作。此过程可以通过 Amazon Bedrock 控制台或 API 完成。要使用 Amazon Bedrock 控制台,请完成以下步骤:
- 在 Amazon Bedrock 控制台上,选择 定制款 在导航窗格中。
- 点击 定制型号 菜单中选择 创建微调作业.
- 针对 微调型号名称,输入新模型的名称。
- 针对 作业配置,输入训练作业的名称。
- 针对 输入数据,输入输入数据的S3路径。
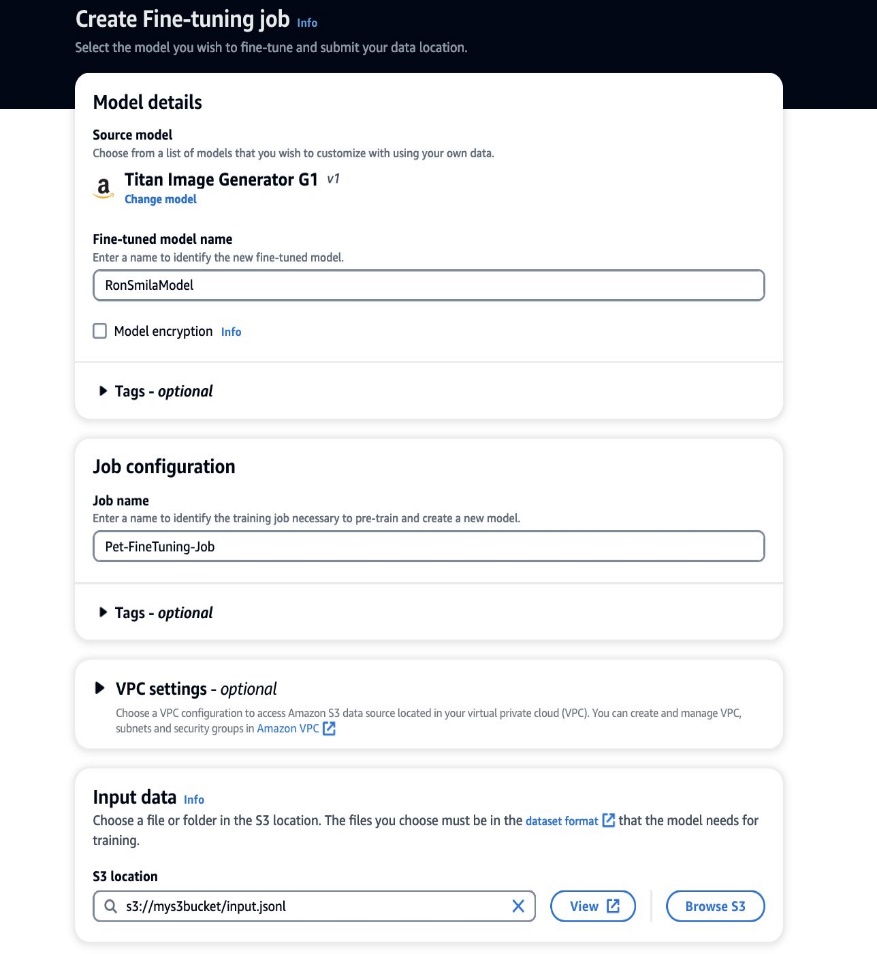
- 在 超参数 部分,提供以下值:
- 步数 – 模型暴露于每批次的次数。
- 批量大小 – 更新模型参数之前处理的样本数量。
- 学习率 – 每批次后模型参数更新的速率。这些参数的选择取决于给定的数据集。作为一般准则,我们建议您首先将批量大小固定为 8,将学习率固定为 1e-5,并根据使用的图像数量设置步数,如下表所示。
| 提供的图像数量 | 8 | 32 | 64 | 1,000 | 10,000 |
| 建议步数 | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
如果微调工作的结果不令人满意,如果您在生成的图像中没有观察到任何样式的迹象,请考虑增加步数;如果您在生成的图像中观察到样式,但仍然存在,请考虑减少步数。存在伪影或模糊。如果微调后的模型即使经过 40,000 个步骤也无法学习数据集中的独特风格,请考虑增加批量大小或学习率。
- 在 输出数据 部分,输入存储验证输出的 S3 输出路径,包括定期记录的验证损失和准确性指标。
- 在 服务访问 部分,生成一个新的 AWS身份和访问管理 (IAM) 角色或选择具有访问 S3 存储桶所需权限的现有 IAM 角色。
此授权使 Amazon Bedrock 能够从您指定的存储桶中检索输入和验证数据集,并将验证输出无缝存储在您的 S3 存储桶中。
- 微调模型.
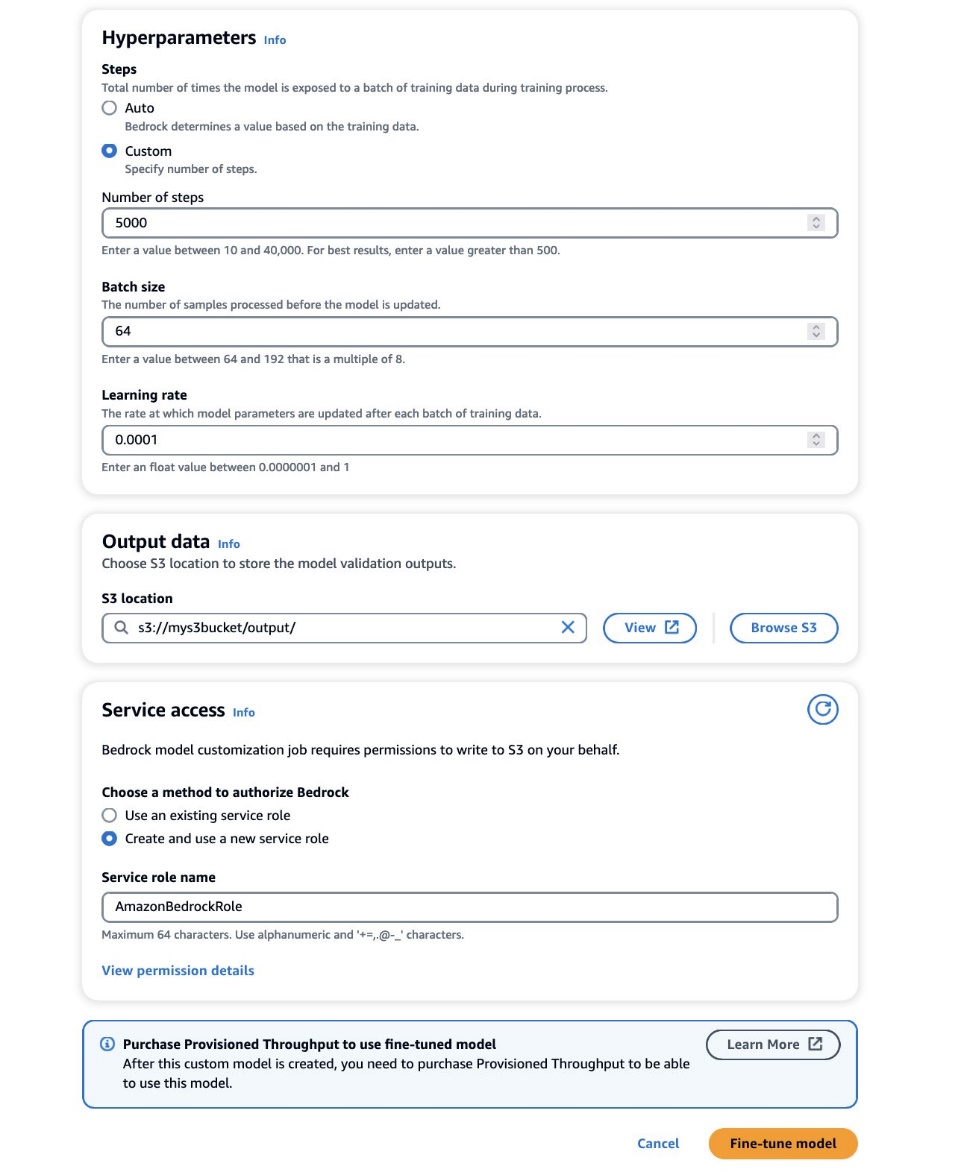
设置正确的配置后,Amazon Bedrock 现在将训练您的自定义模型。
部署具有预配置吞吐量的经过微调的 Amazon Titan 图像生成器
创建自定义模型后,预置吞吐量允许您为自定义模型分配预定的固定速率的处理能力。这种分配为处理工作负载提供了一致的性能和容量水平,从而提高了生产工作负载的性能。预配置吞吐量的第二个优势是成本控制,因为采用按需推理模式的基于标准代币的定价可能难以大规模预测。
模型微调完成后,该模型将出现在 定制型号' Amazon Bedrock 控制台上的页面。
要购买预配置吞吐量,请选择您刚刚微调的自定义模型,然后选择 购买预配置吞吐量.
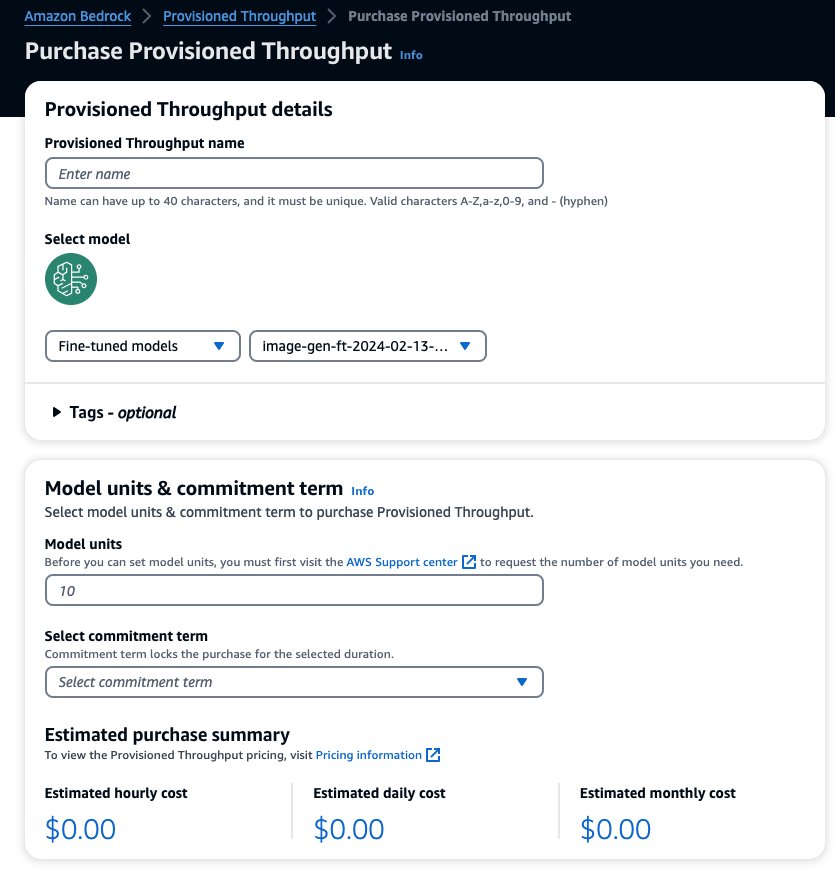
这会预先填充您要为其购买预配置吞吐量的选定模型。要在部署之前测试微调模型,请将模型单位设置为值 1 并将承诺期限设置为 没有承诺。这可以让您快速开始使用自定义提示测试模型并检查训练是否足够。而且,当新的微调模型和新版本出现时,只要用同模型的其他版本更新就可以更新Provisioned Throughput。
微调结果
对于我们在狗 Ron 和猫 Smila 上定制模型的任务,实验表明最佳超参数是 5,000 步,批量大小为 8,学习率为 1e-5。
以下是定制模型生成的图像的一些示例。
 |
 |
 |
| 罗恩小狗穿着超级英雄斗篷 | 月球上的狗罗恩 | 罗恩狗在游泳池里戴着墨镜 |
 |
 |
 |
| 雪地上的斯米拉猫 | Smila 黑白相间的猫盯着相机 | 戴着圣诞帽的猫斯米拉 |
结论
在这篇文章中,我们讨论了何时使用微调而不是设计提示以生成更高质量的图像。我们展示了如何微调 Amazon Titan Image Generator 模型并在 Amazon Bedrock 上部署自定义模型。我们还提供了有关如何准备数据进行微调和设置最佳超参数以实现更准确的模型定制的一般指南。
下一步,您可以调整以下内容 例子 根据您的使用案例,使用 Amazon Titan Image Generator 生成超个性化图像。
作者简介
 迈拉·拉德拉·坦克 是 AWS 的高级生成 AI 数据科学家。她拥有机器学习背景,拥有 10 多年与各行业客户一起设计和构建 AI 应用程序的经验。作为技术主管,她通过 Amazon Bedrock 上的生成式 AI 解决方案帮助客户加速实现业务价值。在空闲时间,Maira 喜欢旅行、与她的猫 Smila 玩耍,以及与家人在温暖的地方共度时光。
迈拉·拉德拉·坦克 是 AWS 的高级生成 AI 数据科学家。她拥有机器学习背景,拥有 10 多年与各行业客户一起设计和构建 AI 应用程序的经验。作为技术主管,她通过 Amazon Bedrock 上的生成式 AI 解决方案帮助客户加速实现业务价值。在空闲时间,Maira 喜欢旅行、与她的猫 Smila 玩耍,以及与家人在温暖的地方共度时光。
 丹尼·米切尔 是 Amazon Web Services 的 AI/ML 专家解决方案架构师。他专注于计算机视觉用例并帮助欧洲、中东和非洲地区的客户加快他们的机器学习之旅。
丹尼·米切尔 是 Amazon Web Services 的 AI/ML 专家解决方案架构师。他专注于计算机视觉用例并帮助欧洲、中东和非洲地区的客户加快他们的机器学习之旅。
 巴拉蒂·斯里尼瓦桑 是 AWS Professional Services 的数据科学家,她喜欢在 Amazon Bedrock 上构建很酷的东西。她热衷于从机器学习应用程序中驱动商业价值,重点关注负责任的人工智能。除了为客户构建新的人工智能体验之外,巴拉蒂还喜欢写科幻小说并通过耐力运动挑战自己。
巴拉蒂·斯里尼瓦桑 是 AWS Professional Services 的数据科学家,她喜欢在 Amazon Bedrock 上构建很酷的东西。她热衷于从机器学习应用程序中驱动商业价值,重点关注负责任的人工智能。除了为客户构建新的人工智能体验之外,巴拉蒂还喜欢写科幻小说并通过耐力运动挑战自己。
 阿钦耆那教 是 Amazon 通用人工智能 (AGI) 团队的应用科学家。他拥有文本到图像模型方面的专业知识,并专注于构建 Amazon Titan 图像生成器。
阿钦耆那教 是 Amazon 通用人工智能 (AGI) 团队的应用科学家。他拥有文本到图像模型方面的专业知识,并专注于构建 Amazon Titan 图像生成器。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

