Giới thiệu
Chỉ trong sáu tháng, ChatGPT của OpenAI đã trở thành một phần không thể thiếu trong cuộc sống của chúng ta. Nó không chỉ giới hạn trong lĩnh vực công nghệ nữa; mọi người ở mọi lứa tuổi và ngành nghề, từ sinh viên đến nhà văn, đang sử dụng nó một cách rộng rãi. Các mô hình trò chuyện này vượt trội về độ chính xác, tốc độ và cuộc trò chuyện giống con người. Họ sẵn sàng đóng một vai trò quan trọng trong nhiều lĩnh vực khác nhau, không chỉ công nghệ.
Các công cụ nguồn mở như AutoGPT, BabyAGI và Langchain đã xuất hiện, khai thác sức mạnh của các mô hình ngôn ngữ. Tự động hóa các tác vụ lập trình bằng lời nhắc, kết nối các mô hình ngôn ngữ với nguồn dữ liệu và tạo các ứng dụng AI nhanh hơn bao giờ hết. Langchain là một công cụ Hỏi & Đáp hỗ trợ ChatGPT dành cho các tệp PDF, biến nó thành một cửa hàng duy nhất để xây dựng các ứng dụng AI.
Mục tiêu học tập
- Xây dựng giao diện chatbot bằng Gradio
- Trích xuất văn bản từ pdf và tạo nhúng
- Lưu trữ các phần nhúng trong cơ sở dữ liệu vectơ Chroma
- Gửi truy vấn đến phụ trợ (chuỗi Langchain)
- Thực hiện tìm kiếm ngữ nghĩa trên các văn bản để tìm các nguồn dữ liệu có liên quan
- Gửi dữ liệu đến LLM (ChatGPT) và nhận câu trả lời trên chatbot
Langchain giúp bạn dễ dàng thực hiện tất cả các bước này trong một vài dòng mã. Nó có các trình bao bọc cho nhiều dịch vụ, bao gồm mô hình nhúng, mô hình trò chuyện và cơ sở dữ liệu vectơ.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Langchain là gì?
Langchain là một công cụ mã nguồn mở được viết bằng Python giúp kết nối dữ liệu bên ngoài với các Mô hình ngôn ngữ lớn. Nó làm cho các mô hình trò chuyện như GPT-4 hoặc GPT-3.5 trở nên có tác dụng và nhận biết dữ liệu hơn. Vì vậy, theo một cách nào đó, Langchain cung cấp một cách để cung cấp dữ liệu mới cho các LLM mà nó chưa được đào tạo. Langchain cung cấp nhiều chuỗi trừu tượng hóa sự phức tạp khi tương tác với các mô hình ngôn ngữ. Chúng tôi cũng cần một số công cụ khác, chẳng hạn như Mô hình để tạo nhúng vectơ và cơ sở dữ liệu vectơ để lưu trữ vectơ. Trước khi tiếp tục, chúng ta hãy xem qua nhúng văn bản. Đây là những gì và tại sao nó quan trọng?
Nhúng văn bản
Nhúng văn bản là trái tim và linh hồn của Large Language Operations. Về mặt kỹ thuật, chúng ta có thể làm việc với các mô hình ngôn ngữ bằng ngôn ngữ tự nhiên nhưng việc lưu trữ và truy xuất ngôn ngữ tự nhiên là rất kém hiệu quả. Ví dụ, trong dự án này, chúng ta sẽ cần thực hiện các thao tác tìm kiếm tốc độ cao trên khối dữ liệu lớn. Không thể thực hiện các thao tác như vậy trên dữ liệu ngôn ngữ tự nhiên.
Để làm cho nó hiệu quả hơn, chúng ta cần chuyển đổi dữ liệu văn bản thành dạng vector. Có các mô hình ML chuyên dụng để tạo nhúng từ văn bản. Các văn bản được chuyển đổi thành các vectơ đa chiều. Sau khi được nhúng, chúng tôi có thể nhóm, sắp xếp, tìm kiếm, v.v. trên những dữ liệu này. Ta có thể tính khoảng cách giữa hai câu để biết chúng có quan hệ mật thiết với nhau như thế nào. Và phần hay nhất của nó là các thao tác này không chỉ giới hạn ở các từ khóa như tìm kiếm cơ sở dữ liệu truyền thống mà còn nắm bắt được sự gần gũi về mặt ngữ nghĩa của hai câu. Điều này làm cho nó mạnh mẽ hơn rất nhiều nhờ Machine Learning.
Công cụ Langchain
Langchain có các hàm bao cho tất cả các cơ sở dữ liệu vectơ chính như Chroma, Redis, Pinecone, Alpine db, v.v. Và điều tương tự cũng đúng với các LLM, cùng với các mô hình OpeanAI, nó cũng hỗ trợ các mô hình của Cohere, GPT4ALL- một giải pháp thay thế mã nguồn mở cho các mô hình GPT. Đối với các nhúng, nó cung cấp các hàm bao cho các nhúng OpeanAI, Cohere và HuggingFace. Bạn cũng có thể sử dụng các mô hình nhúng tùy chỉnh của mình.
Vì vậy, nói tóm lại, Langchain là một siêu công cụ trừu tượng hóa rất nhiều sự phức tạp khi tương tác với các công nghệ cơ bản, giúp mọi người dễ dàng xây dựng các ứng dụng AI một cách nhanh chóng.
Trong bài này, chúng ta sẽ sử dụng Ứng dụng nhúng OpenanAI mô hình để tạo nhúng. Nếu bạn muốn triển khai ứng dụng AI cho người dùng cuối, hãy cân nhắc sử dụng bất kỳ mô hình Opensource nào, chẳng hạn như mô hình Huggingface hoặc bộ mã hóa câu Universal của Google.
Để lưu trữ các vectơ, chúng tôi sẽ sử dụng sắc độ DB, một cơ sở dữ liệu lưu trữ vector mã nguồn mở. Vui lòng khám phá các cơ sở dữ liệu khác như Alpine, Pinecone và Redis. Langchain có các hàm bao cho tất cả các cửa hàng vectơ này.
Để tạo chuỗi Langchain, chúng ta sẽ sử dụng ConversationalRetrievalChuỗi(), lý tưởng cho cuộc trò chuyện với các mô hình trò chuyện có lịch sử (để giữ ngữ cảnh của cuộc trò chuyện). Hãy kiểm tra của họ tài liệu chính thức liên quan đến các chuỗi LLM khác nhau.
Thiết lập môi trường Dev
Có khá nhiều thư viện chúng tôi sẽ sử dụng. Vì vậy, cài đặt chúng trước. Để tạo một môi trường phát triển liền mạch, không lộn xộn, hãy sử dụng môi trường ảo or phu bến tàu.
gradio = "^3.27.0"
openai = "^0.27.4"
langchain = "^0.0.148"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
pypdf = "^3.8.1"
pymupdf = "^1.22.2"Bây giờ, nhập các thư viện này
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import ImageXây dựng giao diện trò chuyện
Giao diện của ứng dụng sẽ có hai chức năng chính, một là giao diện trò chuyện và chức năng còn lại hiển thị trang liên quan của PDF dưới dạng hình ảnh. Ngoài ra, một hộp văn bản để chấp nhận các khóa API OpenAI từ người dùng cuối. Tôi thực sự khuyên bạn nên xem qua bài viết cho xây dựng chatbot GPT với Gradio từ đầu. Bài viết thảo luận về các khía cạnh cơ bản của Gradio. Chúng tôi sẽ mượn rất nhiều thứ từ bài viết này.
Lớp Gradio Blocks cho phép chúng ta xây dựng một ứng dụng web. Các lớp Hàng và Cột cho phép căn chỉnh nhiều thành phần trên ứng dụng web. Chúng tôi sẽ sử dụng chúng để tùy chỉnh giao diện web.
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
Giao diện đơn giản với một vài thành phần.
Nó có:
- Một giao diện trò chuyện để giao tiếp với PDF.
- Một thành phần để hiển thị các trang PDF có liên quan.
- Hộp văn bản để chấp nhận khóa API và nút thay đổi khóa.
- Một hộp văn bản để đặt câu hỏi và một nút gửi.
- Một nút để tải lên các tập tin.
Đây là một ảnh chụp nhanh của giao diện người dùng web.
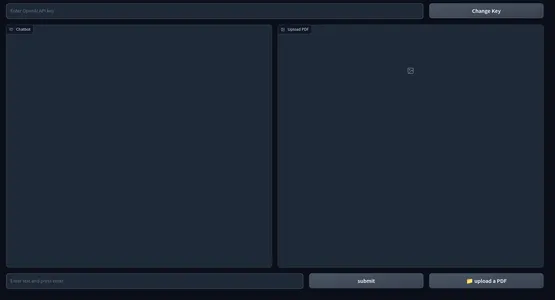
Phần frontend của ứng dụng của chúng ta đã hoàn tất. Hãy nhảy vào phần phụ trợ.
Backend
Trước tiên, hãy phác thảo các quy trình mà chúng ta sẽ giải quyết.
- Xử lý khóa API PDF và OpenAI đã tải lên
- Trích xuất văn bản từ PDF và tạo phần nhúng văn bản từ nó bằng cách sử dụng phần mềm nhúng OpenAI.
- Lưu trữ các phần nhúng vectơ trong kho lưu trữ vectơ ChromaDB.
- Tạo chuỗi Truy xuất hội thoại với Langchain.
- Tạo phần nhúng của văn bản được truy vấn và thực hiện tìm kiếm tương tự trên các tài liệu được nhúng.
- Gửi tài liệu liên quan đến mô hình trò chuyện OpenAI (gpt-3.5-turbo).
- Tìm nạp câu trả lời và phát trực tuyến trên giao diện người dùng trò chuyện.
- Kết xuất trang PDF có liên quan trên giao diện người dùng web.
Đây là tổng quan về ứng dụng của chúng tôi. Hãy bắt đầu xây dựng nó.
sự kiện cấp độ
Khi một hành động cụ thể trên giao diện người dùng web được thực hiện, các sự kiện này sẽ được kích hoạt. Vì vậy, các sự kiện làm cho ứng dụng web tương tác và năng động. Gradio cho phép chúng tôi xác định các sự kiện bằng mã Python.
Sự kiện Gradio sử dụng các biến thành phần mà chúng tôi đã xác định trước đó để giao tiếp với chương trình phụ trợ. Chúng tôi sẽ xác định một vài Sự kiện mà chúng tôi cần cho ứng dụng của mình. đó là
- Gửi sự kiện khóa API: Nhấn enter sau khi dán khóa API sẽ kích hoạt sự kiện này.
- Thay đổi khóa: Điều này sẽ cho phép bạn cung cấp khóa API mới
- Nhập truy vấn: Gửi truy vấn văn bản tới chatbot
- Upload File: Điều này sẽ cho phép người dùng cuối tải lên tệp PDF
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )Cho đến nay, chúng tôi vẫn chưa xác định các hàm được gọi bên trong các trình xử lý sự kiện ở trên. Tiếp theo, chúng tôi sẽ xác định tất cả các chức năng này để tạo một ứng dụng web chức năng.
Xử lý khóa API
Việc xử lý các khóa API của người dùng rất quan trọng vì toàn bộ hoạt động theo nguyên tắc BYOK (Mang theo khóa của riêng bạn). Bất cứ khi nào người dùng gửi khóa, hộp văn bản phải trở nên bất biến với lời nhắc cho biết khóa đã được đặt. Và khi sự kiện “Thay đổi khóa” được kích hoạt, hộp phải có khả năng nhận dữ liệu đầu vào.
Để làm điều này, xác định hai biến toàn cầu.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)Xác định chức năng
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box def enable_api_box(): return enable_boxHàm set_apikey nhận đầu vào là chuỗi và trả về biến disable_box, biến này làm cho hộp văn bản không thay đổi sau khi thực thi. Trong phần Sự kiện Gradio, chúng tôi đã xác định Sự kiện gửi api_key, gọi hàm set_apikey. Chúng tôi đặt khóa API làm biến môi trường bằng thư viện hệ điều hành.
Nhấp vào nút Thay đổi khóa API sẽ trả về biến enable_box, cho phép lại khả năng thay đổi của hộp văn bản.
Tạo chuỗi
Đây là bước quan trọng nhất. Bước này liên quan đến việc trích xuất văn bản và tạo các phần nhúng và lưu trữ chúng trong kho lưu trữ vectơ. Cảm ơn Langchain, nơi cung cấp trình bao bọc cho nhiều dịch vụ giúp mọi việc trở nên dễ dàng hơn. Vì vậy, hãy xác định chức năng.
def process_file(file): # raise an error if API key is not provided if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') # Load the PDF file using PyPDFLoader loader = PyPDFLoader(file.name) documents = loader.load() # Initialize OpenAIEmbeddings for text embeddings embeddings = OpenAIEmbeddings() # Create a ConversationalRetrievalChain with ChatOpenAI language model # and PDF search retriever pdfsearch = Chroma.from_documents(documents, embeddings,) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever= pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True,) return chain- Đã tạo kiểm tra xem khóa API có được đặt hay không. Điều này sẽ gây ra lỗi ở giao diện người dùng nếu Khóa không được đặt.
- Tải tệp PDF bằng PyPDFLoader
- Chức năng nhúng được xác định với OpenAIEmbeddings.
- Đã tạo một kho lưu trữ vectơ từ danh sách các văn bản từ PDF bằng chức năng nhúng.
- Đã xác định chuỗi với chatOpenAI (theo mặc định ChatOpenAI sử dụng gpt-3.5-turbo), trình truy xuất cơ sở (sử dụng tìm kiếm tương đồng).
Tạo phản hồi
Khi chuỗi được tạo, chúng tôi sẽ gọi chuỗi và gửi truy vấn của chúng tôi. Gửi lịch sử trò chuyện cùng với các truy vấn để giữ ngữ cảnh của cuộc trò chuyện và truyền phản hồi tới giao diện trò chuyện. Hãy xác định chức năng.
def generate_response(history, query, btn): global COUNT, N, chat_history # Check if a PDF file is uploaded if not btn: raise gr.Error(message='Upload a PDF') # Initialize the conversation chain only once if COUNT == 0: chain = process_file(btn) COUNT += 1 # Generate a response using the conversation chain result = chain({"question": query, 'chat_history':chat_history}, return_only_outputs=True) # Update the chat history with the query and its corresponding answer chat_history += [(query, result["answer"])] # Retrieve the page number from the source document N = list(result['source_documents'][0])[1][1]['page'] # Append each character of the answer to the last message in the history for char in result['answer']: history[-1][-1] += char # Yield the updated history and an empty string yield history, ''
- Phát sinh lỗi nếu không có tệp PDF nào được tải lên.
- Chỉ gọi hàm process_file một lần.
- Gửi truy vấn và lịch sử trò chuyện đến chuỗi
- Truy xuất số trang của câu trả lời phù hợp nhất.
- Mang lại phản hồi cho giao diện người dùng.
Kết xuất hình ảnh của tệp PDF
Bước cuối cùng là kết xuất hình ảnh của tệp PDF với câu trả lời phù hợp nhất. Chúng tôi có thể sử dụng thư viện PyMuPdf và PIL để hiển thị hình ảnh của tài liệu.
def render_file(file): global N # Open the PDF document using fitz doc = fitz.open(file.name) # Get the specific page to render page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) # Create an Image object from the rendered pixel data image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) # Return the rendered image return image
- Mở tệp bằng Fitz của PyMuPdf.
- Nhận trang có liên quan.
- Nhận bản đồ pix cho trang.
- Tạo hình ảnh từ lớp Image của PIL.
Đây là mọi thứ chúng tôi cần làm cho một ứng dụng web chức năng để trò chuyện với bất kỳ tệp PDF nào.
Kết hợp mọi thứ lại với nhau
#import csv
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Image # Global variables
COUNT, N = 0, 0
chat_history = []
chain = ''
enable_box = gr.Textbox.update(value=None, placeholder='Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value='OpenAI API key is Set', interactive=False) # Function to set the OpenAI API key
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box # Function to enable the API key input box
def enable_api_box(): return enable_box # Function to add text to the chat history
def add_text(history, text): if not text: raise gr.Error('Enter text') history = history + [(text, '')] return history # Function to process the PDF file and create a conversation chain
def process_file(file): if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') loader = PyPDFLoader(file.name) documents = loader.load() embeddings = OpenAIEmbeddings() pdfsearch = Chroma.from_documents(documents, embeddings) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever=pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True) return chain # Function to generate a response based on the chat history and query
def generate_response(history, query, btn): global COUNT, N, chat_history, chain if not btn: raise gr.Error(message='Upload a PDF') if COUNT == 0: chain = process_file(btn) COUNT += 1 result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) chat_history += [(query, result["answer"])] N = list(result['source_documents'][0])[1][1]['page'] for char in result['answer']: history[-1][-1] += char yield history, '' # Function to render a specific page of a PDF file as an image
def render_file(file): global N doc = fitz.open(file.name) page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) return image # Gradio application setup
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )
demo.queue()
if __name__ == "__main__": demo.launch()Bây giờ chúng tôi đã định cấu hình mọi thứ, hãy khởi chạy ứng dụng của chúng tôi.
Bạn có thể khởi chạy ứng dụng ở chế độ gỡ lỗi bằng lệnh sau
app.py chuyển sắc
Nếu không, bạn cũng có thể chỉ cần chạy ứng dụng bằng lệnh Python. Dưới đây là ảnh chụp nhanh của sản phẩm cuối cùng. kho lưu trữ GitHub của mã số.
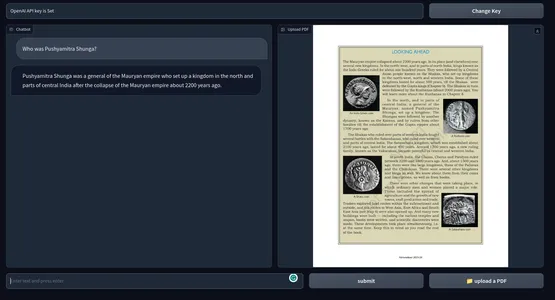
[Nhúng nội dung]
Cải tiến có thể
Ứng dụng hiện tại hoạt động rất tốt. Nhưng có một vài điều bạn có thể làm để làm cho nó tốt hơn.
- Điều này sử dụng các nhúng OpenAI có thể tốn kém về lâu dài. Đối với ứng dụng sẵn sàng sản xuất, bất kỳ mô hình nhúng ngoại tuyến nào cũng có thể phù hợp hơn.
- Gradio để tạo mẫu thì tốt, nhưng đối với thế giới thực, một ứng dụng có khung javascript hiện đại như Next Js hoặc Svelte sẽ tốt hơn nhiều về hiệu suất và tính thẩm mỹ.
- Chúng tôi đã sử dụng độ tương tự cosin để tìm các văn bản có liên quan. Trong một số điều kiện, cách tiếp cận KNN có thể tốt hơn.
- Đối với các tệp PDF có nội dung văn bản dày đặc, việc tạo các đoạn văn bản nhỏ hơn có thể tốt hơn.
- Mô hình tốt hơn, hiệu suất tốt hơn. Thử nghiệm với các LLM khác và so sánh kết quả.
Trường hợp sử dụng thực tế
Sử dụng các công cụ trên nhiều lĩnh vực từ Giáo dục đến Luật đến Học thuật hoặc bất kỳ lĩnh vực nào bạn có thể tưởng tượng rằng yêu cầu người đó phải xem qua các văn bản khổng lồ. Một số trường hợp sử dụng thực tế của ChatGPT cho PDF là
- Cơ sở giáo dục: Học sinh có thể tải lên sách giáo khoa, tài liệu học tập và bài tập của mình, đồng thời công cụ này có thể trả lời các câu hỏi và giải thích các phần cụ thể. Điều này có thể làm cho toàn bộ quá trình học tập ít vất vả hơn đối với học sinh.
- Hợp pháp: Các công ty luật phải xử lý rất nhiều tài liệu pháp lý ở định dạng PDF. Công cụ này có thể được sử dụng để trích xuất thông tin liên quan từ các tài liệu vụ án, hợp đồng pháp lý và đạo luật một cách thuận tiện. Nó có thể giúp luật sư tìm các điều khoản, tiền lệ và các thông tin khác nhanh hơn.
- Học viện: Các học giả nghiên cứu thường giải quyết các bài báo Nghiên cứu và tài liệu kỹ thuật. Một công cụ có thể tóm tắt tài liệu, phân tích và đưa ra câu trả lời từ các tài liệu có thể giúp tiết kiệm thời gian tổng thể và cải thiện năng suất một cách lâu dài.
- Quản lý: chính phủ văn phòng và các bộ phận hành chính khác xử lý rất nhiều biểu mẫu, đơn đăng ký và báo cáo hàng ngày. Sử dụng một chatbot trả lời tài liệu có thể hợp lý hóa quy trình quản lý, do đó tiết kiệm thời gian và tiền bạc của mọi người.
- Tài chính: Phân tích các báo cáo tài chính và xem đi xem lại chúng rất tẻ nhạt. Điều này có thể được thực hiện dễ dàng hơn bằng cách sử dụng một chatbot. Thực chất là một Thực tập sinh.
- Phương tiện truyền thông: Các nhà báo và Nhà phân tích có thể sử dụng công cụ trả lời câu hỏi PDF hỗ trợ chatGPT để truy vấn kho văn bản lớn nhằm tìm câu trả lời nhanh chóng.
Công cụ Hỏi & Đáp PDF hỗ trợ chatGPT có thể thu thập thông tin nhanh hơn từ hàng đống văn bản PDF. Nó giống như một công cụ tìm kiếm dữ liệu văn bản. Không chỉ các tệp PDF mà chúng tôi còn có thể mở rộng công cụ này sang bất kỳ thứ gì có dữ liệu văn bản với một chút thao tác mã.
Kết luận
Vì vậy, đây là tất cả về việc xây dựng một chatbot để trò chuyện với bất kỳ tệp PDF nào bằng ChatGPT. Nhờ có Langchain, việc xây dựng các ứng dụng AI đã trở nên dễ dàng hơn rất nhiều. Một số điểm chính rút ra từ bài viết là:
- Gradio là một công cụ mã nguồn mở để tạo nguyên mẫu cho các ứng dụng AI. Chúng tôi đã tạo giao diện người dùng của ứng dụng với Gradio.
- Langchain là một công cụ mã nguồn mở khác cho phép chúng tôi xây dựng các ứng dụng AI. Nó có các trình bao bọc cho các LLM phổ biến và kho lưu trữ dữ liệu vectơ, cho phép chúng tôi tương tác dễ dàng với các dịch vụ cơ bản.
- Chúng tôi đã sử dụng Langchain để xây dựng hệ thống phụ trợ cho ứng dụng của mình.
- Các mô hình OpenAI nhìn chung rất quan trọng đối với ứng dụng của chúng tôi. Chúng tôi đã sử dụng công cụ nhúng OpenAI và công cụ GPT 3.5 để trò chuyện với các tệp PDF.
- Công cụ Hỏi & Đáp hỗ trợ ChatGPT dành cho PDF và dữ liệu văn bản khác có thể giúp ích rất nhiều trong việc hợp lý hóa các tác vụ kiến thức.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/05/build-a-chatgpt-for-pdfs-with-langchain/

