Khách hàng đã và đang sử dụng các giải pháp kho dữ liệu để thực hiện các nhiệm vụ phân tích truyền thống của họ. Gần đây, các hồ dữ liệu đã đạt được nhiều sức hút để trở thành nền tảng cho các giải pháp phân tích, bởi vì chúng đi kèm với các lợi ích như khả năng mở rộng, khả năng chịu lỗi và hỗ trợ cho các bộ dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc.
Hồ dữ liệu không phải là giao dịch theo mặc định; tuy nhiên, có nhiều khung nguồn mở giúp tăng cường hồ dữ liệu với các thuộc tính ACID, cung cấp giải pháp tốt nhất cho cả hai thế giới giữa cơ chế lưu trữ giao dịch và phi giao dịch.
Quy trình xử lý và nhập hàng loạt truyền thống liên quan đến các hoạt động như làm sạch dữ liệu và kết hợp với dữ liệu tham chiếu rất dễ tạo và tiết kiệm chi phí để duy trì. Tuy nhiên, có một thách thức đối với việc nhập các bộ dữ liệu, chẳng hạn như Internet of Things (IoT) và luồng nhấp chuột, với tốc độ nhanh với SLA phân phối gần như theo thời gian thực. Bạn cũng sẽ muốn áp dụng các bản cập nhật gia tăng với thu thập dữ liệu thay đổi (CDC) từ hệ thống nguồn đến đích. Để kịp thời đưa ra quyết định dựa trên dữ liệu, bạn cần tính đến các bản ghi bị bỏ sót và áp lực ngược, đồng thời duy trì thứ tự và tính toàn vẹn của sự kiện, đặc biệt nếu dữ liệu tham chiếu cũng thay đổi nhanh chóng.
Trong bài đăng này, chúng tôi mong muốn giải quyết những thách thức này. Chúng tôi cung cấp hướng dẫn từng bước để tham gia truyền dữ liệu vào bảng tham chiếu thay đổi theo thời gian thực bằng cách sử dụng Keo AWS, Máy phát điện Amazonvà Dịch vụ di chuyển cơ sở dữ liệu AWS (AWS DMS). Chúng tôi cũng trình bày cách nhập dữ liệu phát trực tuyến vào kho dữ liệu giao dịch bằng cách sử dụng Apache Hudi để đạt được các cập nhật gia tăng với các giao dịch ACID.
Tổng quan về giải pháp
Đối với trường hợp sử dụng ví dụ của chúng tôi, truyền dữ liệu đang đi qua Luồng dữ liệu Amazon Kinesisvà dữ liệu tham chiếu được quản lý trong MySQL. Dữ liệu tham chiếu liên tục được sao chép từ MySQL sang DynamoDB thông qua AWS DMS. Yêu cầu ở đây là làm phong phú thêm dữ liệu luồng thời gian thực bằng cách kết hợp với dữ liệu tham chiếu trong thời gian gần như thực và làm cho nó có thể truy vấn được từ một công cụ truy vấn, chẳng hạn như amazon Athena trong khi vẫn giữ tính nhất quán. Trong trường hợp sử dụng này, dữ liệu tham chiếu trong MySQL có thể được cập nhật khi yêu cầu thay đổi, sau đó các truy vấn cần trả về kết quả bằng cách phản ánh các cập nhật trong dữ liệu tham chiếu.
Giải pháp này giải quyết vấn đề người dùng muốn tham gia các luồng bằng cách thay đổi tập dữ liệu tham chiếu khi kích thước của tập dữ liệu tham chiếu nhỏ. Dữ liệu tham chiếu được duy trì trong các bảng DynamoDB và tác vụ truyền trực tuyến sẽ tải toàn bộ bảng vào bộ nhớ cho từng lô vi mô, kết hợp một luồng thông lượng cao với một tập dữ liệu tham chiếu nhỏ.
Sơ đồ sau minh họa kiến trúc giải pháp.

Điều kiện tiên quyết
Đối với hướng dẫn này, bạn nên có các điều kiện tiên quyết sau:
Tạo vai trò IAM và bộ chứa S3
Trong phần này, bạn tạo một Dịch vụ lưu trữ đơn giản của Amazon thùng (Amazon S3) và hai Quản lý truy cập và nhận dạng AWS (IAM): một vai trò cho công việc AWS Glue và một cho AWS DMS. Chúng tôi làm điều này bằng cách sử dụng một Hình thành đám mây AWS mẫu. Hoàn thành các bước sau:
- Đăng nhập vào bảng điều khiển AWS CloudFormation.
- Chọn Khởi chạy Stack::

- Chọn Sau.
- Trong Tên ngăn xếp, nhập tên cho ngăn xếp của bạn.
- Trong Tên bảng DynamoDB, đi vào
tgt_country_lookup_table. Đây là tên của bảng DynamoDB mới của bạn. - Trong Tiền tố tên nhóm S3, hãy nhập tiền tố của bộ chứa S3 mới của bạn.
- Chọn Tôi xác nhận rằng AWS CloudFormation có thể tạo tài nguyên IAM với tên tùy chỉnh.
- Chọn Tạo ngăn xếp.
Quá trình tạo ngăn xếp có thể mất khoảng 1 phút.
Tạo luồng dữ liệu Kinesis
Trong phần này, bạn tạo luồng dữ liệu Kinesis:
- Trên bảng điều khiển Kinesis, chọn luồng dữ liệu trong khung điều hướng.
- Chọn Tạo luồng dữ liệu.
- Trong Tên luồng dữ liệu, hãy nhập tên luồng của bạn.
- Để các cài đặt còn lại làm mặc định và chọn Tạo luồng dữ liệu.
Luồng dữ liệu Kinesis được tạo bằng chế độ theo yêu cầu.
Tạo và đặt cấu hình cụm Aurora MySQL
Trong phần này, bạn tạo và đặt cấu hình cụm Aurora MySQL làm cơ sở dữ liệu nguồn. Đầu tiên, định cấu hình cụm cơ sở dữ liệu Aurora MySQL nguồn của bạn để bật CDC thông qua AWS DMS đến DynamoDB.
Tạo một nhóm tham số
Hoàn thành các bước sau để tạo một nhóm thông số mới:
- Trên bảng điều khiển Amazon RDS, chọn Nhóm thông số trong khung điều hướng.
- Chọn Tạo nhóm thông số.
- Trong Họ nhóm thông số, lựa chọn
aurora-mysql5.7. - Trong Kiểu, chọn Nhóm tham số cụm DB.
- Trong Tên nhóm, đi vào
my-mysql-dynamodb-cdc. - Trong Mô tả, đi vào
Parameter group for demo Aurora MySQL database. - Chọn Tạo.
- Chọn
my-mysql-dynamodb-cdc, và lựa chọn Chỉnh sửa Dưới Hành động của nhóm thông số. - Chỉnh sửa nhóm tham số như sau:
| Họ tên | Giá trị |
| binlog_row_image | Full |
| binlog_format | HÀNG |
| binlog_checksum | NONE |
| log_slave_updates | 1 |
- Chọn Lưu các thay đổi.

Tạo cụm Aurora MySQL
Hoàn thành các bước sau để tạo cụm Aurora MySQL:
- Trên bảng điều khiển Amazon RDS, chọn Cơ sở dữ liệu trong khung điều hướng.
- Chọn Tạo cơ sở dữ liệu.
- Trong Chọn phương pháp tạo cơ sở dữ liệu, chọn tạo tiêu chuẩn.
- Theo tùy chọn động cơ, Cho Loại động cơ, chọn Aurora (Tương thích với MySQL).
- Trong Phiên bản động cơ, chọn Cực quang (MySQL 5.7) 2.11.2.
- Trong Templates, chọn Sản lượng.
- Theo Cài đặt, Cho mã định danh cụm DB, hãy nhập tên cho cơ sở dữ liệu của bạn.
- Trong tên người dùng chính, hãy nhập tên người dùng chính của bạn.
- Trong Mật khẩu cấp cao và Xác nhận mật khẩu chính, hãy nhập mật khẩu chính của bạn.
- Theo cấu hình phiên bản, Cho lớp phiên bản cơ sở dữ liệu, chọn Các lớp ổn định (bao gồm t lớp) Và chọn db.t3.small.
- Theo Sẵn có & độ bền, Cho Triển khai Multi-AZ, chọn Không tạo Bản sao Aurora.
- Theo Kết nối, Cho tài nguyên máy tính, chọn Không kết nối với tài nguyên điện toán EC2.
- Trong loại mạng, chọn IPv4.
- Trong Đám mây riêng ảo (VPC), hãy chọn VPC của bạn.
- Trong Nhóm mạng con DB, hãy chọn mạng con công cộng của bạn.
- Trong Quyền truy cập công khai, chọn Có.
- Trong Nhóm bảo mật VPC (tường lửa), hãy chọn nhóm bảo mật cho mạng con công khai của bạn.
- Theo xác thực cơ sở dữ liệu, Cho Tùy chọn xác thực cơ sở dữ liệu, chọn Xác thực mật khẩu.
- Theo Cấu hình bổ sung, Cho Nhóm tham số cụm DB, hãy chọn nhóm tham số cụm mà bạn đã tạo trước đó.
- Chọn Tạo cơ sở dữ liệu.
Cấp quyền cho cơ sở dữ liệu nguồn
Bước tiếp theo là cấp quyền cần thiết trên cơ sở dữ liệu Aurora MySQL nguồn. Bây giờ bạn có thể kết nối với cụm DB bằng cách sử dụng tiện ích MySQL. Bạn có thể chạy truy vấn để hoàn thành các tác vụ sau:
- Tạo cơ sở dữ liệu demo và bảng và chạy các truy vấn trên dữ liệu
- Cấp quyền cho người dùng được sử dụng bởi điểm cuối AWS DMS
Hoàn thành các bước sau:
- Đăng nhập vào phiên bản EC2 mà bạn đang sử dụng để kết nối với cụm DB của mình.
- Nhập lệnh sau tại dấu nhắc lệnh để kết nối với phiên bản DB chính của cụm DB của bạn:
- Chạy lệnh SQL sau để tạo cơ sở dữ liệu:
- Chạy lệnh SQL sau để tạo bảng:
- Chạy lệnh SQL sau để điền dữ liệu vào bảng:
- Chạy lệnh SQL sau để tạo người dùng cho điểm cuối AWS DMS và cấp quyền cho nhiệm vụ CDC (thay thế trình giữ chỗ bằng mật khẩu ưa thích của bạn):
Tạo và định cấu hình tài nguyên AWS DMS để tải dữ liệu vào bảng tham chiếu DynamoDB
Trong phần này, bạn tạo và định cấu hình AWS DMS để sao chép dữ liệu vào bảng tham chiếu DynamoDB.
Tạo phiên bản sao chép AWS DMS
Trước tiên, hãy tạo một phiên bản sao chép AWS DMS bằng cách hoàn thành các bước sau:
- Trên bảng điều khiển AWS DMS, hãy chọn trường hợp sao chép trong khung điều hướng.
- Chọn Tạo phiên bản sao chép.
- Theo Cài đặt, Cho Họ tên, hãy nhập tên cho phiên bản của bạn.
- Theo cấu hình phiên bản, Cho Tính sẵn sàng cao, chọn Khối lượng công việc dành cho nhà phát triển hoặc thử nghiệm (Một vùng sẵn sàng).
- Theo Kết nối và bảo mật, Cho Nhóm bảo mật VPC, chọn mặc định.
- Chọn Tạo phiên bản sao chép.
Tạo điểm cuối Amazon VPC
Theo tùy chọn, bạn có thể tạo Điểm cuối Amazon VPC cho DynamoDB khi bạn cần kết nối với bảng DynamoDB của mình từ phiên bản AWS DMS trong một mạng riêng. Cũng đảm bảo rằng bạn kích hoạt Truy cập công cộng khi bạn cần kết nối với cơ sở dữ liệu bên ngoài VPC của mình.
Tạo điểm cuối nguồn AWS DMS
Tạo điểm cuối nguồn AWS DMS bằng cách hoàn tất các bước sau:
- Trên bảng điều khiển AWS DMS, hãy chọn Điểm cuối trong khung điều hướng.
- Chọn Tạo điểm cuối.
- Trong loại điểm cuối, chọn điểm cuối nguồn.
- Theo cấu hình điểm cuối, Cho định danh điểm cuối, hãy nhập tên cho điểm cuối của bạn.
- Trong công cụ nguồn, chọn Amazon AuroraMySQL.
- Trong Truy cập vào cơ sở dữ liệu điểm cuối, chọn Cung cấp thông tin truy cập theo cách thủ công.
- Trong Name Server, hãy nhập tên điểm cuối của phiên bản trình ghi Aurora của bạn (ví dụ:
mycluster.cluster-123456789012.us-east-1.rds.amazonaws.com). - Trong Hải cảng, đi vào
3306. - Trong Tên người dùng, hãy nhập tên người dùng cho tác vụ AWS DMS của bạn.
- Trong Mật khẩu, gõ mật khẩu.
- Chọn Tạo điểm cuối.
Tạo một điểm cuối mục tiêu AWS DMS
Tạo điểm cuối đích AWS DMS bằng cách hoàn tất các bước sau:
- Trên bảng điều khiển AWS DMS, hãy chọn Điểm cuối trong khung điều hướng.
- Chọn Tạo điểm cuối.
- Trong loại điểm cuối, chọn Điểm cuối mục tiêu.
- Theo cấu hình điểm cuối, Cho định danh điểm cuối, hãy nhập tên cho điểm cuối của bạn.
- Trong động cơ mục tiêu, chọn Máy phát điện Amazon.
- Trong Vai trò truy cập dịch vụ ARN, hãy nhập vai trò IAM cho tác vụ AWS DMS của bạn.
- Chọn Tạo điểm cuối.
Tạo tác vụ di chuyển AWS DMS
Tạo tác vụ di chuyển cơ sở dữ liệu AWS DMS bằng cách hoàn thành các bước sau:
- Trên bảng điều khiển AWS DMS, hãy chọn Nhiệm vụ di chuyển cơ sở dữ liệu trong khung điều hướng.
- Chọn Tạo nhiệm vụ.
- Theo cấu hình tác vụ, Cho định danh nhiệm vụ, hãy nhập tên cho nhiệm vụ của bạn.
- Trong Ví dụ sao chép, hãy chọn phiên bản sao chép của bạn.
- Trong Điểm cuối cơ sở dữ liệu nguồn, hãy chọn điểm cuối nguồn của bạn.
- Trong Điểm cuối cơ sở dữ liệu đích, chọn điểm cuối mục tiêu của bạn.
- Trong loại di chuyển, chọn Di chuyển dữ liệu hiện có và sao chép các thay đổi đang diễn ra.
- Theo Cài đặt tác vụ, Cho Chế độ chuẩn bị bảng mục tiêu, chọn không làm gì cả.
- Trong Dừng tác vụ sau khi hoàn thành tải đầy đủ, chọn Đừng dừng lại.
- Trong Cài đặt cột LOB, chọn Chế độ LOB hạn chế.
- Trong Nhật ký tác vụ, cho phép Bật nhật ký CloudWatch và Bật áp dụng tối ưu hóa hàng loạt.
- Theo ánh xạ bảng, chọn Trình soạn thảo JSON và nhập các quy tắc sau.
Tại đây bạn có thể thêm giá trị vào cột. Với các quy tắc sau, tác vụ AWS DMS CDC trước tiên sẽ tạo một bảng DynamoDB mới với tên được chỉ định trong target-table-name. Sau đó, nó sẽ sao chép tất cả các bản ghi, ánh xạ các cột trong bảng DB với các thuộc tính trong bảng DynamoDB.

- Chọn Tạo nhiệm vụ.
Giờ đây, tác vụ sao chép AWS DMS đã được bắt đầu.
- Chờ Trạng thái để hiển thị như Tải hoàn tất.
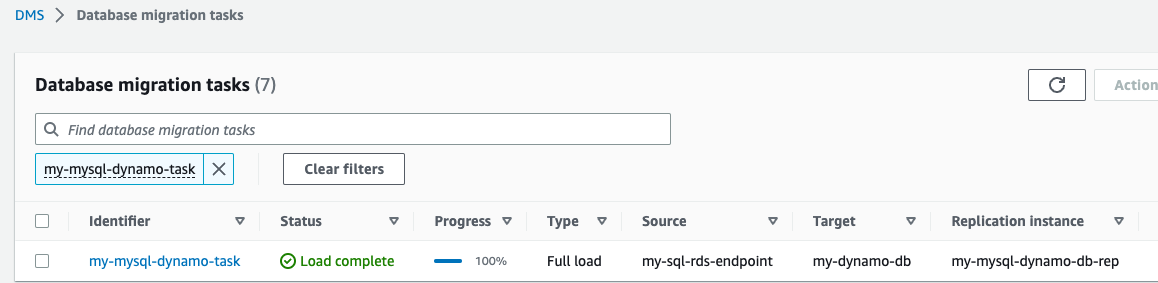
- Trên bảng điều khiển DynamoDB, chọn Bàn trong khung điều hướng.
- Chọn bảng tham chiếu DynamoDB và chọn Khám phá các mục bảng để xem xét các hồ sơ sao chép.

Tạo bảng Danh mục dữ liệu AWS Glue và tác vụ ETL truyền phát AWS Glue
Trong phần này, bạn tạo bảng Danh mục dữ liệu AWS Glue và tác vụ trích xuất, chuyển đổi và tải (ETL) luồng AWS Glue.
Tạo bảng Danh mục dữ liệu
Tạo bảng AWS Glue Data Catalog cho luồng dữ liệu Kinesis nguồn theo các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn Cơ sở dữ liệu Dưới Danh mục dữ liệu trong khung điều hướng.
- Chọn Thêm cơ sở dữ liệu.
- Trong Họ tên, đi vào
my_kinesis_db. - Chọn Tạo cơ sở dữ liệu.
- Chọn Bàn Dưới Cơ sở dữ liệu, sau đó chọn Thêm bảng.
- Trong Họ tên, đi vào
my_stream_src_table. - Trong Cơ sở dữ liệu, chọn
my_kinesis_db. - Trong Chọn loại nguồn, chọn chuyển động.
- Trong Luồng dữ liệu Kinesis nằm trong, chọn tài khoản của tôi.
- Trong Tên luồng Kinesis, hãy nhập tên cho luồng dữ liệu của bạn.
- Trong phân loại, lựa chọn JSON.
- Chọn Sau.
- Chọn Chỉnh sửa lược đồ dưới dạng JSON, nhập JSON sau, sau đó chọn Lưu.
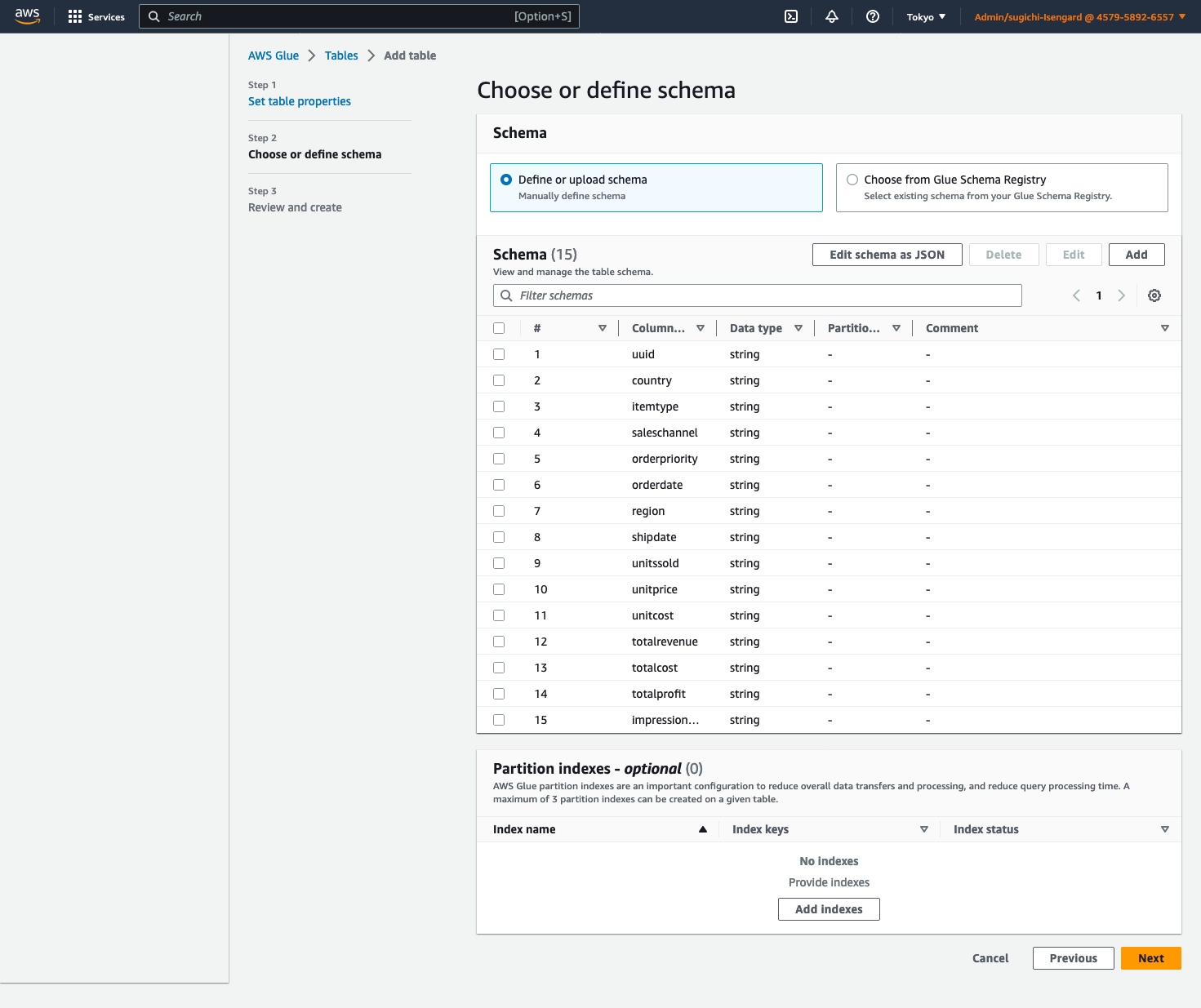
-
- Chọn Sau, sau đó chọn Tạo.
Tạo một công việc ETL phát trực tuyến AWS Glue
Tiếp theo, bạn tạo một tác vụ phát trực tuyến AWS Glue. AWS Glue 3.0 trở lên hỗ trợ Apache Hudi nguyên bản, vì vậy chúng tôi sử dụng tích hợp gốc này để nhập vào bảng Hudi. Hoàn thành các bước sau để tạo tác vụ phát trực tuyến AWS Glue:
- Trên bảng điều khiển AWS Glue Studio, hãy chọn Trình chỉnh sửa tập lệnh Spark Và chọn Tạo.
- Theo Chi tiết công việc tab, cho Họ tên, hãy nhập tên cho công việc của bạn.
- Trong Vai trò IAM, hãy chọn vai trò IAM cho tác vụ AWS Glue của bạn.
- Trong Kiểu, lựa chọn truyền phát tia lửa.
- Trong Phiên bản keo, chọn Keo 4.0 - Hỗ trợ spark 3.3, Scala 2, Python 3.
- Trong Số lượng công nhân yêu cầu, đi vào
3. - Theo Thuộc tính nâng cao, Cho Thông số công việc, chọn Thêm thông số mới.
- Trong Key, đi vào
--conf. - Trong Giá trị, đi vào
spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false. - Chọn Thêm thông số mới.
- Trong Key, đi vào
--datalake-formats. - Trong Giá trị, đi vào
hudi. - Trong Đường dẫn tập lệnh, đi vào
s3://<S3BucketName>/scripts/. - Trong Đường dẫn tạm thời, đi vào
s3://<S3BucketName>/temporary/. - Tùy chọn, cho Đường dẫn nhật ký giao diện người dùng Spark, đi vào
s3://<S3BucketName>/sparkHistoryLogs/.
- trên Script tab, hãy nhập tập lệnh sau vào trình chỉnh sửa AWS Glue Studio và chọn Tạo.
Công việc truyền trực tuyến gần thời gian thực làm phong phú thêm dữ liệu bằng cách kết hợp luồng dữ liệu Kinesis với bảng DynamoDB chứa dữ liệu tham chiếu được cập nhật thường xuyên. Tập dữ liệu đã làm giàu được tải vào bảng Hudi đích trong kho dữ liệu. Thay thế với bộ chứa mà bạn đã tạo qua AWS CloudFormation:
- Chọn chạy để bắt đầu công việc phát trực tuyến.
Ảnh chụp màn hình sau đây hiển thị các ví dụ về DataFrames data_frame, country_lookup_dfvà final_frame.
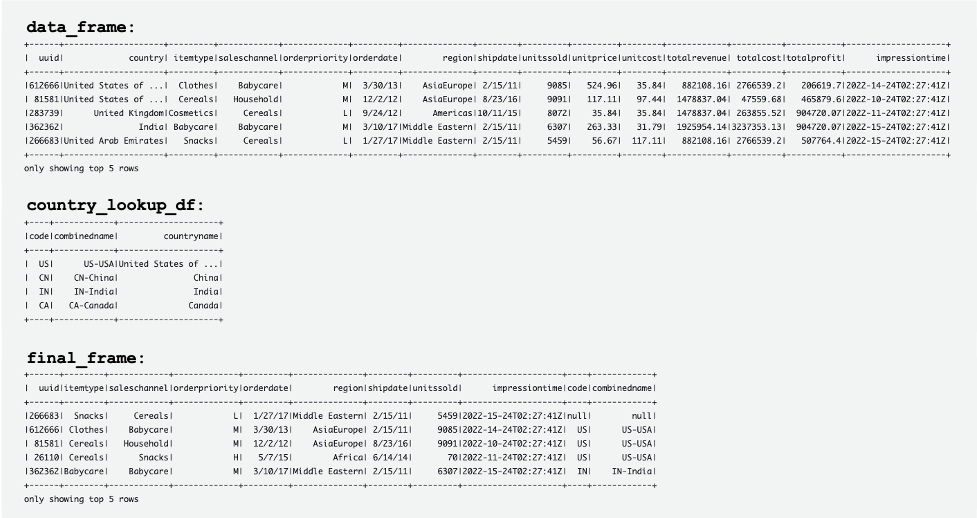
Công việc AWS Glue đã nối thành công các bản ghi đến từ luồng dữ liệu Kinesis và bảng tham chiếu trong DynamoDB, sau đó nhập các bản ghi đã nối vào Amazon S3 ở định dạng Hudi.
Tạo và chạy tập lệnh Python để tạo dữ liệu mẫu và tải vào luồng dữ liệu Kinesis
Trong phần này, bạn tạo và chạy Python để tạo dữ liệu mẫu và tải dữ liệu đó vào luồng dữ liệu Kinesis nguồn. Hoàn thành các bước sau:
- Đăng nhập vào AWS Cloud9, phiên bản EC2 của bạn hoặc bất kỳ máy chủ lưu trữ điện toán nào khác đặt bản ghi vào luồng dữ liệu của bạn.
- Tạo một tệp Python có tên
generate-data-for-kds.py:
- Mở tệp Python và nhập đoạn mã sau:
Tập lệnh này đặt bản ghi luồng dữ liệu Kinesis cứ sau 2 giây.
Mô phỏng cập nhật bảng tham chiếu trong cụm Aurora MySQL
Bây giờ tất cả các tài nguyên và cấu hình đã sẵn sàng. Đối với ví dụ này, chúng tôi muốn thêm mã quốc gia gồm 3 chữ số vào bảng tham chiếu. Hãy cập nhật các bản ghi trong bảng Aurora MySQL để mô phỏng các thay đổi. Hoàn thành các bước sau:
- Đảm bảo rằng công việc phát trực tuyến AWS Glue đang chạy.
- Kết nối lại với phiên bản CSDL chính, như được mô tả trước đó.
- Nhập các lệnh SQL của bạn để cập nhật bản ghi:
Giờ đây, bảng tham chiếu trong cơ sở dữ liệu nguồn Aurora MySQL đã được cập nhật. Sau đó, các thay đổi sẽ tự động được sao chép vào bảng tham chiếu trong DynamoDB.
Các bảng sau hiển thị các bản ghi trong data_frame, country_lookup_dfvà final_frame. Trong country_lookup_df và final_frame, Các combinedname cột có các giá trị được định dạng là <2-digit-country-code>-<3-digit-country-code>-<country-name>, điều này cho thấy rằng các bản ghi đã thay đổi trong bảng được tham chiếu được phản ánh trong bảng mà không cần khởi động lại công việc truyền phát AWS Glue. Điều đó có nghĩa là công việc AWS Glue sẽ kết hợp thành công các bản ghi đến từ luồng dữ liệu Kinesis với bảng tham chiếu ngay cả khi bảng tham chiếu đang thay đổi.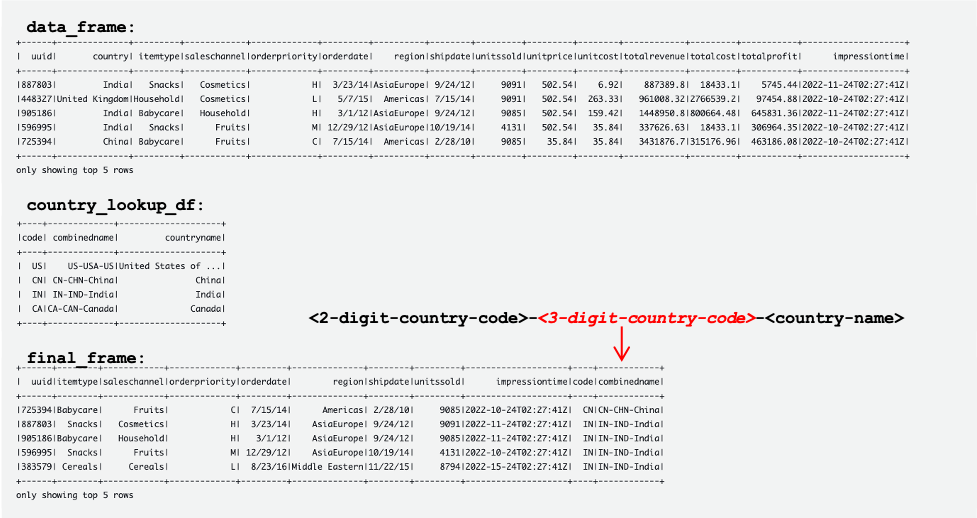
Truy vấn bảng Hudi bằng Athena
Hãy truy vấn bảng Hudi bằng Athena để xem các bản ghi trong bảng đích. Hoàn thành các bước sau:
- Đảm bảo rằng tập lệnh và công việc AWS Glue Streaming vẫn đang hoạt động:
- Tập lệnh Python (
generate-data-for-kds.py) vẫn đang chạy. - Dữ liệu được tạo đang được gửi đến luồng dữ liệu.
- Công việc phát trực tuyến AWS Glue vẫn đang chạy.
- Tập lệnh Python (
- Trên bảng điều khiển Athena, hãy chạy SQL sau trong trình chỉnh sửa truy vấn:
Kết quả truy vấn sau đây hiển thị các bản ghi được xử lý trước khi thay đổi bảng được tham chiếu. Kỷ lục trong combinedname cột tương tự như <2-digit-country-code>-<country-name>.

Kết quả truy vấn sau đây hiển thị các bản ghi được xử lý sau khi thay đổi bảng được tham chiếu. Kỷ lục trong combinedname cột tương tự như <2-digit-country-code>-<3-digit-country-code>-<country-name>.

Bây giờ, bạn hiểu rằng dữ liệu tham chiếu đã thay đổi được phản ánh thành công trong bảng Hudi đích kết hợp các bản ghi từ luồng dữ liệu Kinesis và dữ liệu tham chiếu trong DynamoDB.
Làm sạch
Bước cuối cùng, dọn sạch tài nguyên:
- Xóa luồng dữ liệu Kinesis.
- Xóa nhiệm vụ di chuyển AWS DMS, điểm cuối và phiên bản sao chép.
- Dừng và xóa tác vụ phát trực tuyến AWS Glue.
- Xóa môi trường AWS Cloud9.
- Xóa mẫu CloudFormation.
Kết luận
Việc xây dựng và duy trì hồ dữ liệu giao dịch liên quan đến việc nhập và xử lý dữ liệu theo thời gian thực có nhiều thành phần khác nhau và các quyết định cần được đưa ra, chẳng hạn như sử dụng dịch vụ nhập nào, cách lưu trữ dữ liệu tham chiếu của bạn và sử dụng khung hồ dữ liệu giao dịch nào. Trong bài đăng này, chúng tôi đã cung cấp chi tiết triển khai của một quy trình như vậy, sử dụng các thành phần gốc của AWS làm khối xây dựng và Apache Hudi làm khung nguồn mở cho hồ dữ liệu giao dịch.
Chúng tôi tin rằng giải pháp này có thể là điểm khởi đầu cho các tổ chức muốn triển khai hồ dữ liệu mới với các yêu cầu như vậy. Ngoài ra, các thành phần khác nhau hoàn toàn có thể cắm được và có thể được kết hợp và khớp với các hồ dữ liệu hiện có để nhắm mục tiêu các yêu cầu mới hoặc di chuyển các yêu cầu hiện có, giải quyết các điểm khó khăn của chúng.
Giới thiệu về tác giả
 Manish Kola là Kiến trúc sư giải pháp phòng thí nghiệm dữ liệu tại AWS, nơi anh hợp tác chặt chẽ với khách hàng trong nhiều ngành khác nhau để kiến trúc các giải pháp dựa trên đám mây cho nhu cầu phân tích dữ liệu và AI của họ. Anh ấy hợp tác với khách hàng trên hành trình AWS của họ để giải quyết các vấn đề kinh doanh của họ và xây dựng các nguyên mẫu có thể mở rộng. Trước khi gia nhập AWS, kinh nghiệm của Manish bao gồm giúp khách hàng triển khai các dự án kho dữ liệu, BI, tích hợp dữ liệu và hồ dữ liệu.
Manish Kola là Kiến trúc sư giải pháp phòng thí nghiệm dữ liệu tại AWS, nơi anh hợp tác chặt chẽ với khách hàng trong nhiều ngành khác nhau để kiến trúc các giải pháp dựa trên đám mây cho nhu cầu phân tích dữ liệu và AI của họ. Anh ấy hợp tác với khách hàng trên hành trình AWS của họ để giải quyết các vấn đề kinh doanh của họ và xây dựng các nguyên mẫu có thể mở rộng. Trước khi gia nhập AWS, kinh nghiệm của Manish bao gồm giúp khách hàng triển khai các dự án kho dữ liệu, BI, tích hợp dữ liệu và hồ dữ liệu.
 Santosh Kotagiri là Kiến trúc sư giải pháp tại AWS có kinh nghiệm về phân tích dữ liệu và giải pháp đám mây dẫn đến kết quả kinh doanh hữu hình. Chuyên môn của ông nằm ở việc thiết kế và triển khai các giải pháp phân tích dữ liệu có thể mở rộng cho khách hàng trong các ngành, tập trung vào các dịch vụ mã nguồn mở và dựa trên nền tảng đám mây. Anh đam mê tận dụng công nghệ để thúc đẩy tăng trưởng kinh doanh và giải quyết các vấn đề phức tạp.
Santosh Kotagiri là Kiến trúc sư giải pháp tại AWS có kinh nghiệm về phân tích dữ liệu và giải pháp đám mây dẫn đến kết quả kinh doanh hữu hình. Chuyên môn của ông nằm ở việc thiết kế và triển khai các giải pháp phân tích dữ liệu có thể mở rộng cho khách hàng trong các ngành, tập trung vào các dịch vụ mã nguồn mở và dựa trên nền tảng đám mây. Anh đam mê tận dụng công nghệ để thúc đẩy tăng trưởng kinh doanh và giải quyết các vấn đề phức tạp.
 Chiho Sugimoto là Kỹ sư hỗ trợ đám mây trong nhóm Hỗ trợ dữ liệu lớn AWS. Cô ấy đam mê giúp khách hàng xây dựng hồ dữ liệu bằng cách sử dụng khối lượng công việc ETL. Cô ấy yêu khoa học hành tinh và thích nghiên cứu tiểu hành tinh Ryugu vào cuối tuần.
Chiho Sugimoto là Kỹ sư hỗ trợ đám mây trong nhóm Hỗ trợ dữ liệu lớn AWS. Cô ấy đam mê giúp khách hàng xây dựng hồ dữ liệu bằng cách sử dụng khối lượng công việc ETL. Cô ấy yêu khoa học hành tinh và thích nghiên cứu tiểu hành tinh Ryugu vào cuối tuần.
 Noritaka Sekiyama là Kiến trúc sư dữ liệu lớn chính trong nhóm AWS Glue. Ông chịu trách nhiệm xây dựng các hiện vật phần mềm để giúp đỡ khách hàng. Khi rảnh rỗi, anh ấy thích đạp xe bằng chiếc xe đạp địa hình mới của mình.
Noritaka Sekiyama là Kiến trúc sư dữ liệu lớn chính trong nhóm AWS Glue. Ông chịu trách nhiệm xây dựng các hiện vật phần mềm để giúp đỡ khách hàng. Khi rảnh rỗi, anh ấy thích đạp xe bằng chiếc xe đạp địa hình mới của mình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/join-streaming-source-cdc-glue/

