Ngày nay, các tổ chức dành một lượng thời gian đáng kể để hiểu các quy trình kinh doanh, lập hồ sơ dữ liệu và phân tích dữ liệu từ nhiều nguồn khác nhau. Kết quả là dữ liệu có cấu trúc và tổ chức cao được sử dụng chủ yếu cho mục đích báo cáo. Các hệ thống truyền thống này trích xuất dữ liệu từ các hệ thống giao dịch bao gồm các chỉ số và thuộc tính mô tả các khía cạnh khác nhau của doanh nghiệp. Các nguồn dữ liệu phi truyền thống như nhật ký máy chủ web, dữ liệu cảm biến, dữ liệu dòng nhấp, hoạt động mạng xã hội, văn bản và hình ảnh thúc đẩy các trường hợp sử dụng mới và thú vị như phát hiện xâm nhập, bảo trì dự đoán, vị trí đặt quảng cáo và nhiều tối ưu hóa trong nhiều ngành . Tuy nhiên, việc lưu trữ các bộ dữ liệu khác nhau có thể trở nên tốn kém và khó khăn khi khối lượng dữ liệu tăng lên.
Cách tiếp cận hồ dữ liệu bao gồm các kiểu dữ liệu phi truyền thống này, trong đó tất cả dữ liệu được giữ ở dạng thô và chỉ được chuyển đổi khi cần thiết. Hồ dữ liệu là một kho lưu trữ tập trung cho phép bạn lưu trữ tất cả dữ liệu có cấu trúc và phi cấu trúc của mình ở bất kỳ quy mô nào. Các hồ dữ liệu có thể thu thập dữ liệu âm thanh, video, nhật ký cuộc gọi, cảm xúc và dữ liệu truyền thông xã hội để cung cấp thông tin chi tiết đầy đủ và mạnh mẽ hơn. Điều này có tác động đáng kể đến khả năng thực hiện AI, học máy (ML) và khoa học dữ liệu.
Trước khi xây dựng hồ dữ liệu, các tổ chức cần hoàn thành các điều kiện tiên quyết sau:
- Hiểu các khối xây dựng cơ bản của hồ dữ liệu
- Hiểu các dịch vụ liên quan đến việc xây dựng hồ dữ liệu
- Xác định các tính cách cần thiết để quản lý hồ dữ liệu
- Tạo các chính sách bảo mật cần thiết để các dịch vụ khác nhau hoạt động hài hòa khi di chuyển dữ liệu để tạo hồ dữ liệu
Để làm cho việc xây dựng một hồ dữ liệu dễ dàng hơn, bài đăng này trình bày một giải pháp để quản lý và triển khai hồ dữ liệu của bạn như một Danh mục dịch vụ AWS sản phẩm. Điều này cho phép bạn tạo một hồ dữ liệu cho toàn bộ tổ chức hoặc các ngành kinh doanh riêng lẻ của bạn hoặc chỉ đơn giản là để bắt đầu với các trường hợp sử dụng ML và phân tích.
Tổng quan về giải pháp
Bài đăng này cung cấp một cách đơn giản để triển khai hồ dữ liệu dưới dạng sản phẩm Danh mục dịch vụ AWS. Danh mục dịch vụ AWS cho phép bạn quản lý tập trung và triển khai các dịch vụ và ứng dụng CNTT theo cách tự phục vụ thông qua danh mục sản phẩm chung, có thể tùy chỉnh. Chúng tôi tạo các đường ống tự động để di chuyển dữ liệu từ cơ sở dữ liệu hoạt động vào một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) dựa trên hồ dữ liệu cũng như xác định các cách để di chuyển dữ liệu phi cấu trúc từ các nguồn dữ liệu khác nhau vào hồ dữ liệu. Chúng tôi cũng xác định các quyền chi tiết trong hồ dữ liệu để cho phép các công cụ truy vấn như amazon Athena để phân tích dữ liệu một cách an toàn.
Sau đây là một số lợi thế của việc sử dụng hồ dữ liệu của bạn dưới dạng sản phẩm Danh mục dịch vụ AWS:
- Thực thi việc tuân thủ các tiêu chuẩn của công ty để bạn có thể kiểm soát các dịch vụ và phiên bản CNTT nào có sẵn và ai được cấp quyền truy cập bởi cá nhân, nhóm, bộ phận hoặc trung tâm chi phí.
- Thực thi quản trị bằng cách giúp nhân viên nhanh chóng tìm và chỉ triển khai các dịch vụ CNTT đã được phê duyệt mà không cấp quyền truy cập trực tiếp vào các dịch vụ cơ bản.
- Người dùng cuối, như nhà phát triển, nhà khoa học dữ liệu hoặc người dùng doanh nghiệp, có quyền truy cập nhanh chóng và dễ dàng vào danh sách sản phẩm tùy chỉnh, được quản lý có thể được triển khai nhất quán, luôn tuân thủ và luôn an toàn thông qua tự phục vụ, giúp thúc đẩy hoạt động kinh doanh sự phát triển.
- Thực thi các ràng buộc, chẳng hạn như giới hạn Vùng AWS mà trong đó hồ dữ liệu có thể được khởi chạy.
- Thực thi gắn thẻ dựa trên bộ phận hoặc trung tâm chi phí để theo dõi hồ dữ liệu được xây dựng cho các bộ phận khác nhau.
- Quản lý tập trung vòng đời dịch vụ CNTT bằng cách thêm các phiên bản mới vào sản phẩm data lake một cách tập trung.
- Nâng cao hiệu quả hoạt động bằng cách tích hợp với các sản phẩm của bên thứ ba và các công cụ ITSM như ServiceNow và Jira.
- Xây dựng hồ dữ liệu dựa trên nền tảng có thể tái sử dụng được cung cấp bởi một tổ chức CNTT trung tâm.
Sơ đồ sau minh họa cách dữ liệu hồ có thể được đóng gói như một sản phẩm bên trong Danh mục Danh mục Dịch vụ cùng với các sản phẩm khác:

Giải pháp xây dựng
Sơ đồ sau minh họa kiến trúc cho giải pháp này:

Chúng tôi sử dụng các dịch vụ sau trong giải pháp này:
- Amazon S3 - Amazon S3 là một dịch vụ lưu trữ đối tượng cung cấp khả năng mở rộng, tính khả dụng dữ liệu, bảo mật và hiệu suất hàng đầu trong ngành. Đối với trường hợp sử dụng này, bạn sử dụng Amazon S3 làm bộ nhớ cho hồ dữ liệu.
- Sự hình thành hồ AWS - Lake Formation giúp việc thiết lập một hồ dữ liệu an toàn trở nên đơn giản — một kho lưu trữ tập trung, được quản lý và bảo mật để lưu trữ tất cả dữ liệu của bạn — cả ở dạng ban đầu và được chuẩn bị để phân tích. Quản trị viên hồ dữ liệu có thể dễ dàng gắn nhãn dữ liệu và cung cấp cho người dùng quyền chi tiết để truy cập các tập dữ liệu được ủy quyền.
- Keo AWS - AWS Glue là dịch vụ tích hợp dữ liệu không máy chủ giúp dễ dàng khám phá, chuẩn bị và kết hợp dữ liệu để phân tích, ML và phát triển ứng dụng.
- amazon Athena - Athena là một dịch vụ truy vấn tương tác giúp việc phân tích dữ liệu trong Amazon S3 trở nên đơn giản bằng cách sử dụng SQL tiêu chuẩn. Athena không có máy chủ, vì vậy không có cơ sở hạ tầng để quản lý và bạn chỉ trả tiền cho các truy vấn bạn chạy và lượng dữ liệu được quét.
Bộ dữ liệu
Để minh họa cách dữ liệu được quản lý trong hồ dữ liệu, chúng tôi sử dụng bộ dữ liệu mẫu được công bố công khai. Tập dữ liệu đầu tiên là Hoa Kỳ dữ liệu điều tra dân số của các nhà sản xuất mà chúng tôi tải xuống ở định dạng có cấu trúc vào cơ sở dữ liệu quan hệ. Ngoài ra, chúng tôi có thể tải United States dữ liệu điều tra dân số trường học ở định dạng thô của nó vào hồ dữ liệu.
Tổng quan về hướng dẫn
Danh mục dịch vụ AWS cho phép các tổ chức tạo và quản lý danh mục các dịch vụ CNTT được phê duyệt để sử dụng trên AWS. Nó cho phép bạn quản lý tập trung các dịch vụ CNTT đã triển khai và các ứng dụng, tài nguyên và siêu dữ liệu của bạn. Theo cùng một khái niệm, chúng tôi triển khai hồ dữ liệu dưới dạng tập hợp các dịch vụ và tài nguyên AWS dưới dạng sản phẩm Danh mục dịch vụ AWS. Điều này giúp bạn đạt được quản trị nhất quán và đáp ứng các yêu cầu tuân thủ của bạn, đồng thời cho phép người dùng chỉ nhanh chóng triển khai các dịch vụ đã được phê duyệt.
Làm theo các bước trong các phần tiếp theo để triển khai hồ dữ liệu dưới dạng sản phẩm Danh mục dịch vụ AWS. Đối với bài đăng này, chúng tôi tải dữ liệu điều tra dân số công cộng của Hoa Kỳ vào một Dịch vụ cơ sở dữ liệu quan hệ của Amazon (Amazon RDS) dành cho MySQL ví dụ để chứng minh việc nhập dữ liệu vào hồ dữ liệu từ cơ sở dữ liệu quan hệ. Chúng tôi sử dụng một Hình thành đám mây AWS mẫu để tạo nhóm S3 để tải tập lệnh tạo hồ dữ liệu dưới dạng sản phẩm Danh mục dịch vụ AWS cũng như các tập lệnh để chuyển đổi dữ liệu.
Triển khai mẫu CloudFormation
Đảm bảo triển khai các nguồn lực của bạn ở Vùng Đông Hoa Kỳ (N. Virginia) (us-east-1). Chúng tôi sử dụng mẫu CloudFormation được cung cấp để tạo tất cả các tài nguyên cần thiết. Bước này loại bỏ mọi lỗi thủ công bằng cách tăng hiệu quả và cung cấp cấu hình nhất quán theo thời gian.
- Chọn Khởi chạy Stack:

- trên Tạo ngăn xếp trang, URL Amazon S3 nên hiển thị như
https://aws-bigdata-blog.s3.amazonaws.com/artifacts/datalake-service-catalog/datalake_portfolio.yaml. - Chọn Sau.

- đăng ký hạng mục thi
datalake-portfoliocho tên ngăn xếp. - Trong Tên danh mục đầu tư, hãy nhập tên cho danh mục Danh mục dịch vụ AWS chứa sản phẩm hồ dữ liệu.
- Chọn Sau.
- Chọn Tạo ngăn xếp và đợi ngăn xếp tạo tài nguyên trong tài khoản AWS của bạn.
Trên ngăn xếp của Thông tin , bạn có thể tìm thấy những thông tin sau:
- Dữ liệuHồDanh mục đầu tư - Danh mục Danh mục dịch vụ AWS
- ProdAsDataHồ - Hồ dữ liệu như một sản phẩm
- Sản phẩmCFTDữ liệuHồ - Mẫu CloudFormation như một sản phẩm
Nếu bạn chọn mũi tên bên cạnh Dữ liệuHồDanh mục đầu tư tài nguyên, bạn được chuyển hướng đến danh mục Danh mục dịch vụ AWS, với datalake được liệt kê như một sản phẩm.
Cấp quyền để khởi chạy sản phẩm Danh mục dịch vụ AWS
Chúng tôi cần cung cấp các quyền thích hợp cho người dùng hiện tại để khởi chạy datalake sản phẩm chúng tôi vừa tạo.
- Trên trang danh mục đầu tư trên bảng điều khiển Danh mục dịch vụ AWS, hãy chọn Nhóm, vai trò và người dùng tab.
- Chọn Thêm nhóm, vai trò, người dùng.
- Chọn nhóm, vai trò hoặc người dùng bạn muốn cấp quyền để khởi chạy sản phẩm.

Một cách tiếp cận khác là nâng cao khả năng của hồ dữ liệu bằng cách xây dựng hồ dữ liệu nhiều người thuê. Một hồ dữ liệu nhiều người thuê cho phép lưu trữ dữ liệu từ nhiều đơn vị kinh doanh trong cùng một hồ dữ liệu và duy trì sự cô lập dữ liệu thông qua các vai trò với các bộ quyền khác nhau. Để xây dựng hồ dữ liệu nhiều người thuê, bạn có thể thêm nhiều bên liên quan (nhà phát triển, nhà phân tích, nhà khoa học dữ liệu) từ các đơn vị tổ chức khác nhau. Bằng cách xác định các vai trò thích hợp, cho thuê nhiều lần giúp đạt được sự hợp tác và chia sẻ dữ liệu giữa các nhóm khác nhau và tích hợp nhiều silo dữ liệu để có được cái nhìn thống nhất về dữ liệu. Bạn có thể thêm các vai trò thích hợp này trên trang danh mục đầu tư.
Trong ảnh chụp màn hình ví dụ sau, các nhà phân tích dữ liệu từ Nhân sự và Tiếp thị có quyền truy cập vào tập dữ liệu của riêng họ, nhà phân tích kinh doanh có quyền truy cập vào cả hai tập dữ liệu để có được cái nhìn thống nhất về dữ liệu nhằm thu được thông tin chi tiết có ý nghĩa và admin người dùng quản lý các hoạt động của hồ dữ liệu trung tâm.
Ngoài ra, bạn có thể thực thi các ràng buộc đối với hồ dữ liệu từ bảng điều khiển Danh mục dịch vụ AWS thay vì sản phẩm hồ dữ liệu được khởi chạy độc lập dưới dạng tập lệnh CloudFormation. Điều này cho phép nhóm CNTT trung tâm cho phép kiểm soát quản trị khi một bộ phận chọn xây dựng một hồ dữ liệu cho người dùng doanh nghiệp của họ.
- Để bật các ràng buộc, hãy chọn Những ràng buộc trên trang danh mục đầu tư.
Ví dụ: một ràng buộc mẫu cho phép bạn giới hạn các tùy chọn có sẵn cho người dùng cuối khi họ khởi chạy sản phẩm. Ảnh chụp màn hình sau đây cho thấy một ví dụ về định cấu hình ràng buộc mẫu.
Phạm vi VPC CIDR bị hạn chế trong một phạm vi nhất định khi khởi chạy hồ dữ liệu.
Bây giờ chúng ta có thể thấy ràng buộc mẫu được liệt kê trên Những ràng buộc tab.
Nếu ràng buộc bị vi phạm và một phạm vi CIDR khác được nhập trong khi khởi chạy sản phẩm, mẫu sẽ tạo ra lỗi, như được hiển thị trong ảnh chụp màn hình sau.
Ngoài ra, trong khi khởi chạy sản phẩm để theo dõi chi phí cho mỗi bộ phận hoặc nhóm, nhóm CNTT trung tâm có thể xác định các thẻ trong TagOptions thư viện và buộc nhóm vận hành chọn các thẻ từ danh sách các giá trị để chọn rõ ràng đơn vị kinh doanh mà hồ dữ liệu đang được tạo và cuối cùng theo dõi chi phí cho mỗi bộ phận hoặc đơn vị kinh doanh.
- Chọn Tag để quản lý các thẻ.

- Sau khi thiết lập các tiêu chuẩn của tổ chức bạn cho các vai trò, ràng buộc và thẻ, nhóm CNTT trung tâm có thể chia sẻ Danh mục dịch vụ AWS
datalakedanh mục đầu tư với
tài khoản hoặc tổ chức thông qua Tổ chức AWS.
Sau đó, quản trị viên Danh mục dịch vụ AWS từ một tài khoản AWS khác có thể phân phối sản phẩm hồ dữ liệu cho người dùng cuối của họ.
Bạn có thể xem các tài khoản có quyền truy cập vào danh mục đầu tư trên Chia sẻ tab.
Khởi chạy hồ dữ liệu
Để khởi chạy hồ dữ liệu, hãy hoàn thành các bước sau:
- Đăng nhập với tư cách người dùng hoặc vai trò mà bạn đã cấp quyền khởi chạy hồ dữ liệu. Nếu bạn chưa bao giờ khởi chạy Sự hình thành hồ AWS dịch vụ và chưa được xác định quản trị viên ban đầu, vui lòng truy cập dịch vụ và thêm quản trị viên.
- Trên bảng điều khiển Danh mục dịch vụ AWS, hãy chọn
datalakesản phẩm và lựa chọn Ra mắt sản phẩm.
- Chọn Tạo tên để tự động nhập tên cho sản phẩm được cấp phép.
- Chọn phiên bản sản phẩm của bạn (đối với bài đăng này, v1.0 được chọn theo mặc định).

- Nhập tên người dùng và mật khẩu DB.
- Xác minh tên ngăn xếp của mẫu CloudFormation đã khởi chạy trước đó,
datalake-portfolio. - Chọn Ra mắt sản phẩm.
Sản phẩm datalake sản phẩm kích hoạt mẫu CloudFormation trong nền, tạo tất cả tài nguyên và khởi chạy hồ dữ liệu trong tài khoản của bạn.
- Trên bảng điều khiển Danh mục dịch vụ AWS, hãy chọn Sản phẩm được cung cấp trong khung điều hướng.

- Chọn giá trị đầu ra có liên kết đến ngăn xếp CloudFormation đã tạo hồ dữ liệu cho tài khoản của bạn.
- trên Thông tin , xem lại thông tin chi tiết của các tài nguyên đã tạo.
Các tài nguyên sau được tạo trong bước này như một phần của quá trình khởi chạy sản phẩm Danh mục dịch vụ AWS:
- Nhập dữ liệu:
- Một VPC với các mạng con và nhóm bảo mật để lưu trữ cơ sở dữ liệu RDS cho MySQL với dữ liệu mẫu.
- Cơ sở dữ liệu RDS cho MySQL làm nguồn mẫu để tải dữ liệu vào hồ dữ liệu. Xác minh phạm vi VPC CIDR để lưu trữ hồ dữ liệu cũng như phạm vi CIDR mạng con của cơ sở dữ liệu cho cơ sở dữ liệu.
- RDS mặc định cho cơ sở dữ liệu MySQL. Bạn có thể thay đổi mật khẩu nếu cần trên bảng điều khiển Amazon RDS.
- Kết nối AWS Glue JDBC để kết nối với cơ sở dữ liệu RDS cho MySQL với dữ liệu mẫu được tải.
- Trình thu thập dữ liệu AWS Glue để nhập dữ liệu vào hồ dữ liệu.
- Chuyển đổi dữ liệu:
- Các công việc AWS Glue để chuyển đổi dữ liệu.
- Cơ sở dữ liệu Danh mục dữ liệu AWS Glue để lưu giữ thông tin siêu dữ liệu.
- Quản lý truy cập và nhận dạng AWS (IAM) Keo AWS và AWS Lambda vai trò luồng công việc để đọc dữ liệu từ cơ sở dữ liệu RDS cho MySQL và tải dữ liệu vào hồ dữ liệu.
- Trực quan hóa dữ liệu:
- Quản trị viên hồ dữ liệu IAM và nhà phân tích hồ dữ liệu có vai trò quản lý và truy cập dữ liệu trong hồ dữ liệu thông qua Lake Formation.
- Hai truy vấn có tên Athena.
- Hai người dùng:
- datalake_admin - Chịu trách nhiệm về hoạt động hàng ngày, quản lý và điều hành hồ dữ liệu.
- datalake_analyst - Có quyền chỉ xem và phân tích dữ liệu bằng các công cụ trực quan hóa khác nhau.
Nhập, chuyển đổi và trực quan hóa dữ liệu
Sau khi ngăn xếp CloudFormation đã sẵn sàng, chúng tôi hoàn thành các bước sau để nhập, chuyển đổi và trực quan hóa dữ liệu.
Nhập dữ liệu
Chúng tôi chạy trình thu thập AWS Glue để tải dữ liệu vào hồ dữ liệu. Theo tùy chọn, bạn có thể xác minh rằng dữ liệu có sẵn trong nguồn dữ liệu bằng cách thực hiện theo các bước trong phụ lục của bài đăng này. Để chạy trình thu thập thông tin, hãy hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn Trình thu thập thông tin trong khung điều hướng.
Sản phẩm Trình thu thập thông tin trang hiển thị bốn trình thu thập thông tin được tạo như một phần của quá trình triển khai sản phẩm hồ dữ liệu.
- Chọn trình thu thập thông tin
GlueRDSCrawler-xxxx. - Chọn Chạy trình thu thập thông tin.
Một bảng được thêm vào cơ sở dữ liệu AWS Glue gluedatabasemysql-blogdb.
Dữ liệu thô hiện đã sẵn sàng để chạy bất kỳ loại biến đổi nào cần thiết. Trong ví dụ này, chúng tôi chuyển đổi dữ liệu thô thành định dạng Parquet.
Chuyển đổi dữ liệu
AWS Glue cung cấp bảng điều khiển và các hoạt động API để thiết lập và quản lý khối lượng công việc trích xuất, chuyển đổi và tải (ETL) của bạn. Một công việc là logic nghiệp vụ thực hiện công việc ETL trong AWS Glue. Khi bạn bắt đầu một công việc, AWS Glue chạy một tập lệnh trích xuất dữ liệu từ các nguồn, chuyển đổi dữ liệu và tải nó vào các mục tiêu. Trong trường hợp này, nguồn của chúng tôi là nhóm S3 thô và đích là nhóm S3 đã được quản lý để lưu trữ dữ liệu đã chuyển đổi ở định dạng Parquet sau khi công việc AWS Glue chạy.
Để chuyển đổi dữ liệu, hãy hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn việc làm trong khung điều hướng.
Sản phẩm việc làm trang liệt kê công việc AWS Glue được tạo như một phần của quá trình triển khai sản phẩm hồ dữ liệu.
- Chọn công việc bắt đầu với
GlueRDSJob. - trên Hoạt động menu, chọn Chỉnh sửa tập lệnh.

- Cập nhật tên của nhóm S3 trên dòng 33 thành
ProcessedBucketS3giá trị trên Kết quả đầu ra tab của ngăn xếp CloudFormation thứ hai. - Chọn lại công việc và trên Hoạt động menu, chọn Chạy công việc.
Bạn có thể xem trạng thái của công việc khi nó chạy.
Công việc ETL sử dụng vai trò AWS Glue IAM được tạo như một phần của tập lệnh CloudFormation. Để ghi dữ liệu vào nhóm được quản lý của hồ dữ liệu, bạn cần phải cấp các quyền thích hợp cho vai trò này. Các quyền này đã được cấp như một phần của việc triển khai hồ dữ liệu. Khi công việc hoàn tất, trạng thái của nó hiển thị là Succeeded.
Dữ liệu đã chuyển đổi được lưu trữ trong nhóm được sắp xếp trên hồ dữ liệu.
Dữ liệu mẫu hiện đã được chuyển đổi và sẵn sàng để trực quan hóa dữ liệu.
Trực quan hóa dữ liệu
Trong bước cuối cùng này, chúng tôi sử dụng Lake Formation để quản lý và chi phối dữ liệu xác định ai có quyền truy cập vào dữ liệu và mức độ truy cập của họ. Chúng tôi thực hiện việc này bằng cách chỉ định các quyền chi tiết cho người dùng và cá nhân được tạo bởi sản phẩm data lake. Sau đó, chúng tôi có thể truy vấn dữ liệu bằng Athena.
Những người sử dụng datalake-admin và datalake-analyst đã được tạo. datalake_admin chịu trách nhiệm về hoạt động hàng ngày, quản lý và điều hành hồ dữ liệu. datalake_analyst có quyền xem và phân tích dữ liệu bằng các công cụ trực quan hóa khác nhau.
Là một phần của việc triển khai hồ dữ liệu, chúng tôi đã xác định nhóm S3 được sắp xếp làm vị trí hồ dữ liệu trong Hồ hình thành. Để đọc và ghi vào vị trí hồ dữ liệu, chúng tôi phải đảm bảo rằng tất cả các quyền được chỉ định đúng. Trong phần trước, chúng tôi đã nhúng quyền cho công việc AWS Glue ETL để đọc và ghi vào vị trí hồ dữ liệu trong mẫu CloudFormation. Do đó, vai trò SC-xxxxGlueWorkFlowRole-xxxxx có quyền thích hợp để trình thu thập thông tin giả định và tạo cơ sở dữ liệu và lược đồ bảng cần thiết để truy vấn dữ liệu. Lưu ý rằng trình thu thập thông tin đầu tiên phân tích dữ liệu trong cơ sở dữ liệu RDS cho MySQL và không truy cập vào hồ dữ liệu, vì vậy chúng tôi không cần cấp cho nó quyền đối với hồ dữ liệu.
Để chạy trình thu thập thông tin, hãy hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn Trình thu thập thông tin trong khung điều hướng.
- Chọn trình thu thập thông tin
LakeCuratedZoneCrawler-xxxxxVà chọn Chạy trình thu thập thông tin.
Trình thu thập thông tin đọc dữ liệu từ data lake và điền vào bảng trong cơ sở dữ liệu AWS Glue được tạo trong giai đoạn nhập dữ liệu và làm cho nó có sẵn để truy vấn bằng Athena.
Để truy vấn dữ liệu phổ biến trong Danh mục dữ liệu AWS Glue bằng Athena, chúng tôi cần cung cấp quyền chi tiết cho vai trò bằng cách sử dụng quản lý và điều hành Lake Formation.
- Trên bảng điều khiển Lake Formation, hãy chọn Quyền của hồ dữ liệu trong khung điều hướng.

- Chọn Cấp.
- Trong Người dùng IAM và vai trò, chọn vai trò mà bạn muốn gán quyền.
- Chọn Tài nguyên danh mục dữ liệu được đặt tên.
- Chọn cơ sở dữ liệu và bảng.

- Trong Quyền bảng, lựa chọn Chọn.
- Trong Quyền dữ liệu, lựa chọn Tất cả quyền truy cập dữ liệu.
Điều này cho phép người dùng xem tất cả dữ liệu trong bảng nhưng không phải sửa đổi nó.
- Chọn Cấp.

Bây giờ bạn có thể truy vấn dữ liệu với Athena. Nếu bạn chưa thiết lập đường dẫn kết quả truy vấn Athena, hãy xem Chỉ định Vị trí Kết quả Truy vấn để được hướng dẫn.
- Trên bảng điều khiển Athena, mở trình chỉnh sửa truy vấn.
- Chọn Các truy vấn đã lưu tab.
Bạn sẽ thấy hai truy vấn được tạo như một phần của việc triển khai sản phẩm data lake.
- Chọn truy vấn
CensusManufacturersQuery.
Cơ sở dữ liệu, bảng và truy vấn được điền sẵn trong trình chỉnh sửa truy vấn.
- Chọn Chạy truy vấn để truy cập dữ liệu trong hồ dữ liệu.

Chúng tôi đã hoàn tất quá trình tải, chuyển đổi và trực quan hóa dữ liệu trong hồ dữ liệu bằng cách triển khai nhanh hồ dữ liệu dưới dạng sản phẩm Danh mục dịch vụ AWS. Chúng tôi đã sử dụng dữ liệu mẫu được nhập trong cơ sở dữ liệu RDS cho MySQL làm ví dụ. Bạn có thể lặp lại quy trình này và triển khai các bước tương tự bằng cách sử dụng Amazon S3 làm nguồn dữ liệu. Để làm như vậy, tệp dữ liệu mẫu school-medus-data.csv được tải và trình thu thập dữ liệu AWS Glue tương ứng và công việc để nhập, chuyển đổi và trực quan hóa dữ liệu đã được tạo cho bạn như một phần của việc triển khai sản phẩm hồ dữ liệu Danh mục dịch vụ AWS này .
Kết luận
Trong bài đăng này, chúng tôi đã thấy cách bạn có thể giảm thiểu thời gian và công sức cần thiết để xây dựng một hồ dữ liệu. Việc thiết lập hồ dữ liệu giúp các tổ chức hoạt động theo hướng dữ liệu, xác định các mẫu trong dữ liệu và hành động nhanh chóng để đẩy nhanh tốc độ tăng trưởng kinh doanh. Ngoài ra, để tận dụng toàn bộ hồ sơ dữ liệu của mình, bạn có thể xây dựng và cung cấp các sản phẩm và ứng dụng theo hướng dữ liệu một cách dễ dàng thông qua danh mục sản phẩm có thể tùy chỉnh cao. Với Danh mục dịch vụ AWS, bạn có thể dễ dàng và nhanh chóng triển khai hồ dữ liệu theo các phương pháp hay nhất phổ biến. Danh mục dịch vụ AWS cũng thực thi các ràng buộc đối với đường cơ sở mạng và tài khoản để xây dựng hồ dữ liệu một cách an toàn trong môi trường người dùng cuối.
Phụ lục
Để xác minh dữ liệu mẫu được tải vào Amazon RDS, hãy hoàn thành các bước sau:
- trên Đám mây điện toán đàn hồi Amazon
(Amazon EC2) bảng điều khiển, chọnEC2SampleRDSdataví dụ. - trên Hoạt động menu, chọn Giám sát và khắc phục sự cố.
- Chọn Nhận nhật ký hệ thống.
Nhật ký hệ thống hiển thị số lượng bản ghi được tải vào cơ sở dữ liệu RDS cho MySQL:

Tiếp theo, chúng ta có thể kiểm tra kết nối với cơ sở dữ liệu.
- Trên bảng điều khiển AWS Glue, hãy chọn Kết nối trong khung điều hướng.
Bạn nên thấy RDSConnectionMySQL-xxxx được tạo ra cho bạn.
- Chọn kết nối và chọn Kiểm tra kết nối.

- Trong Vai trò IAM¸ chọn vai trò
SC-xxxxGlueWorkFlowRole-xxxxx.
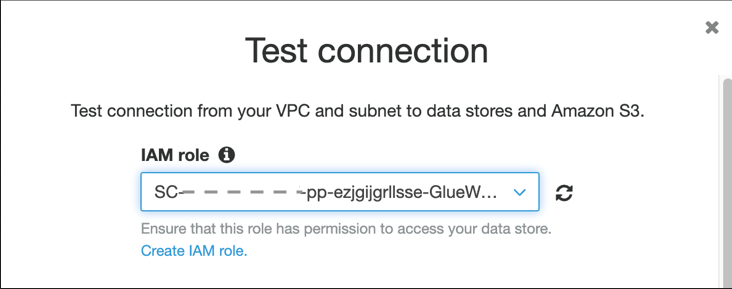
RDSConnectionMySQL-xxxx sẽ kết nối thành công với phiên bản RDS cho MySQL DB của bạn.
Về các tác giả
 Mamata Vaidya là Kiến trúc sư giải pháp cao cấp tại Amazon Web Services (AWS) đang thúc đẩy khách hàng chấp nhận đám mây của họ trong lĩnh vực phân tích dữ liệu lớn và kiến trúc nền tảng. Bà có hơn 20 năm kinh nghiệm trong việc xây dựng và kiến trúc hệ thống doanh nghiệp trong lĩnh vực y tế, tài chính và an ninh mạng với kỹ năng quản lý vững vàng. Trước AWS, Mamata đã làm việc cho Bristol-Myers Squibb và Citigroup ở các vị trí quản lý kỹ thuật cấp cao. Ngoài giờ làm việc, Mamata thích đi bộ đường dài với gia đình, bạn bè và cố vấn cho các học sinh trung học.
Mamata Vaidya là Kiến trúc sư giải pháp cao cấp tại Amazon Web Services (AWS) đang thúc đẩy khách hàng chấp nhận đám mây của họ trong lĩnh vực phân tích dữ liệu lớn và kiến trúc nền tảng. Bà có hơn 20 năm kinh nghiệm trong việc xây dựng và kiến trúc hệ thống doanh nghiệp trong lĩnh vực y tế, tài chính và an ninh mạng với kỹ năng quản lý vững vàng. Trước AWS, Mamata đã làm việc cho Bristol-Myers Squibb và Citigroup ở các vị trí quản lý kỹ thuật cấp cao. Ngoài giờ làm việc, Mamata thích đi bộ đường dài với gia đình, bạn bè và cố vấn cho các học sinh trung học.
 Shan Kandaswamy là Kiến trúc sư giải pháp tại Amazon Web Services (AWS), người có đam mê giúp khách hàng giải quyết các vấn đề phức tạp. Anh ấy là một nhà truyền bá kỹ thuật, người ủng hộ kiến trúc phân tán, phân tích dữ liệu lớn và công nghệ không máy chủ để giúp khách hàng điều hướng bối cảnh đám mây khi họ chuyển sang điện toán đám mây. Anh ấy là một người thích du lịch, xem phim và học hỏi điều gì đó mới mỗi ngày.
Shan Kandaswamy là Kiến trúc sư giải pháp tại Amazon Web Services (AWS), người có đam mê giúp khách hàng giải quyết các vấn đề phức tạp. Anh ấy là một nhà truyền bá kỹ thuật, người ủng hộ kiến trúc phân tán, phân tích dữ liệu lớn và công nghệ không máy chủ để giúp khách hàng điều hướng bối cảnh đám mây khi họ chuyển sang điện toán đám mây. Anh ấy là một người thích du lịch, xem phim và học hỏi điều gì đó mới mỗi ngày.
- Coinsmart. Sàn giao dịch Bitcoin và tiền điện tử tốt nhất Châu Âu.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. TRUY CẬP MIỄN PHÍ.
- CryptoHawk. Radar Altcoin. Dùng thử miễn phí.
- Nguồn: https://aws.amazon.com/blogs/big-data/automate-building-data-lakes-using-aws-service-catalog/

