Giới thiệu
Phân loại cảm xúc trong văn bản câu bằng cách sử dụng mạng thần kinh liên quan đến việc gán cảm xúc cho một đoạn văn bản. Nó có thể đạt được thông qua các kỹ thuật như mạng thần kinh hoặc phương pháp dựa trên từ vựng. Mạng lưới thần kinh liên quan đến việc đào tạo một mô hình trên dữ liệu văn bản được gắn thẻ để dự đoán cảm xúc trong văn bản mới. Các phương pháp dựa trên từ vựng sử dụng từ điển từ liên quan đến cảm xúc. Mặc dù đầy thách thức, phân loại cảm xúc văn bản có nhiều ứng dụng tiềm năng.

Mục tiêu chính của việc phân loại cảm xúc văn bản là:
- Để hiểu được tâm trạng của tác giả. Điều này có thể hữu ích trong nhiều ngữ cảnh khác nhau, chẳng hạn như dịch vụ khách hàng, chăm sóc sức khỏe và giáo dục.
- Để cải thiện độ chính xác của hệ thống dịch máy. Các hệ thống dịch máy thường gặp khó khăn trong việc dịch chính xác văn bản mang tính cảm xúc.
- Để phát triển các ứng dụng mới cho phương tiện truyền thông xã hội và các nền tảng trực tuyến khác. Ví dụ: phân loại cảm xúc văn bản có thể được sử dụng để đề xuất nội dung cho người dùng dựa trên trạng thái cảm xúc của họ.
Dựa trên những mục tiêu này, chúng tôi sẽ phân loại các trạng thái cảm xúc trong văn bản câu bằng thuật toán Mạng thần kinh để phát triển một mô hình có thể phân loại chính xác các trạng thái cảm xúc trên văn bản. Bài viết này sẽ hướng dẫn bạn từng bước phân loại văn bản người dùng nhập vào với những cảm xúc cụ thể.
Mục lục
Bước 1: Nhập thư viện
import pandas as pd
import numpy as np
import keras
import tensorflow
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Embedding, Flatten, DenseChúng tôi nhập 'Tokenizer' để chuyển đổi văn bản thành một chuỗi mã thông báo. 'pad_sequences' được sử dụng để đệm các chuỗi có độ dài cố định. Điều này là cần thiết vì các mạng thần kinh mong đợi đầu vào có kích thước cố định. 'LabelEncoder' được sử dụng để chuyển đổi dữ liệu phân loại thành dữ liệu số. Sequential được sử dụng để tạo một chồng lớp tuyến tính. Sau đó, 'Embedding' được sử dụng để chuyển từ thành vectơ để biểu thị nghĩa của từ. 'Làm phẳng' được sử dụng để làm phẳng một tensor đa chiều thành một tensor 1D. Cuối cùng, 'Dense' được sử dụng để áp dụng phép biến đổi phi tuyến tính cho một tenxơ đầu vào.
Bước 2: Đọc dữ liệu
Tập dữ liệu mà Praveen đã tải lên Kaggle phù hợp với nhiệm vụ phân loại cảm xúc trong văn bản, rất phù hợp trong trường hợp này. Tuy nhiên, tôi đã đưa nó lên GitHub của mình để tiện cho việc phân tích sâu hơn.
url = "https://raw.githubusercontent.com/ataislucky/Data-Science/main/dataset/emotion_train.txt"
data = pd.read_csv(url, sep=';')
data.columns = ["Text", "Emotions"]
print(data.head())
Mã này mô tả cách đọc tệp văn bản từ một URL và lưu trữ tệp đó trong Khung dữ liệu Pandas. Tệp văn bản chứa danh sách các câu và nhãn cảm xúc. Vì vậy, tập dữ liệu chúng tôi sử dụng chỉ bao gồm hai cột.
Bước 3: Tiền xử lý dữ liệu
Việc tiền xử lý dữ liệu là một bước quan trọng trong việc phân loại các cảm xúc văn bản. Điều này bao gồm quá trình làm sạch và chuẩn bị dữ liệu để các mô hình máy học sử dụng. Một số bước tiền xử lý dữ liệu phổ biến để phân loại cảm xúc văn bản bao gồm mã thông báo, loại bỏ từ dừng, từ vựng, v.v. Nói chung, những thách thức trong việc thực hiện quy trình xử lý ban đầu là làm sạch dữ liệu, chọn dữ liệu và định dạng dữ liệu.
Trình mã thông báo là một chức năng chia chuỗi văn bản thành các từ hoặc mã thông báo riêng lẻ. Do đó, để đánh dấu các chuỗi văn bản, trước tiên phải thay đổi kiểu dữ liệu chuỗi thành một danh sách. Điều này là do danh sách là một tập hợp các đối tượng và mỗi đối tượng trong danh sách có thể là một từ hoặc một mã thông báo.
texts = data["Text"].tolist()
labels = data["Emotions"].tolist()Đối tượng mã thông báo sau đó được căn chỉnh với danh sách văn bản. Nó nhằm mục đích tìm hiểu các mã thông báo duy nhất trong dữ liệu văn bản. Bằng cách mã hóa dữ liệu văn bản, các đối tượng mã thông báo có thể chuyển đổi dữ liệu văn bản thành định dạng mà các mô hình máy học có thể sử dụng được.
# Tokenize the text data
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)Bây giờ, tất cả những gì chúng ta cần làm là xếp lớp các chuỗi có độ dài bằng nhau và đưa chúng vào mạng thần kinh. Đây là cách chúng ta có thể xếp lớp một chuỗi văn bản sao cho chúng có cùng độ dài:
sequences = tokenizer.texts_to_sequences(texts)
max_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_length)Tiếp theo, chúng ta sẽ sử dụng phương pháp mã hóa nhãn để chuyển đổi kiểu dữ liệu từ chuỗi sang dữ liệu số.
# Encode the string labels to integers
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)Sau đó, chúng tôi thực hiện mã hóa một lần để thể hiện dữ liệu phân loại trong mô hình máy học. Điều này là do nhiều mô hình học máy, chẳng hạn như mạng thần kinh, mong đợi dữ liệu đầu vào ở định dạng số. Hãy làm nó.
# One-hot encode the labels
one_hot_labels = keras.utils.to_categorical(labels)Bước 4: Xây dựng mô hình và đưa ra dự đoán
Sau khi trải qua quá trình tiền xử lý, chúng tôi sẽ bắt đầu tạo mô hình học máy.
Chúng tôi có thể triển khai một kỹ thuật, cụ thể là chia tập dữ liệu thành tập huấn luyện và tập kiểm tra, để đơn giản hóa việc đánh giá hiệu suất mô hình trên dữ liệu chưa từng thấy trước đây. Khả năng xác minh rằng mô hình không quá phù hợp với tập dữ liệu huấn luyện khiến điều này trở nên quan trọng.
# Split the data into training and testing sets
xtrain, xtest, ytrain, ytest = train_test_split(padded_sequences, one_hot_labels, test_size=0.2)Bây giờ chúng ta hãy xác định kiến trúc mạng thần kinh để đào tạo mô hình và phân loại cảm xúc.
# Define the model
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=128, input_length=max_length))
model.add(Flatten())
model.add(Dense(units=128, activation="relu"))
model.add(Dense(units=len(one_hot_labels[0]), activation="softmax")) model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(xtrain, ytrain, epochs=10, batch_size=32, validation_data=(xtest, ytest))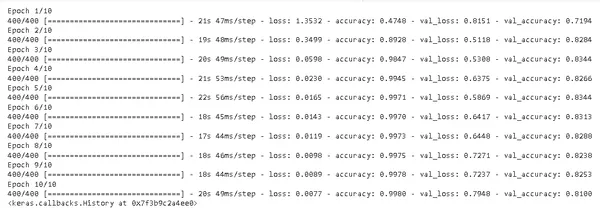
Mô hình được đào tạo trong mười kỷ nguyên, với mỗi kỷ nguyên bao gồm đào tạo mô hình trên dữ liệu huấn luyện và sau đó đánh giá mô hình đó trên dữ liệu xác thực. Xác thực dữ liệu được sử dụng để đánh giá hiệu suất của mô hình đối với dữ liệu chưa từng thấy trước đây. Điều này rất quan trọng vì nó đảm bảo rằng mô hình không khớp quá mức với dữ liệu huấn luyện.
Sau khi mô hình được đào tạo, nó sẵn sàng được sử dụng để đưa ra dự đoán về dữ liệu mới.
#input_text from user
input_text = input("Please input sentence here : ") # Preprocess the input text
input_sequence = tokenizer.texts_to_sequences([input_text])
padded_input_sequence = pad_sequences(input_sequence, maxlen=max_length)
prediction = model.predict(padded_input_sequence)
predicted_label = label_encoder.inverse_transform([np.argmax(prediction[0])])
print(predicted_label)
Trong kết quả xuất ra, người dùng nhập câu “Hôm nay cô ấy không đến vì mẹ cô ấy mất ngày hôm qua”. Mô hình dự đoán rằng tình cảm của câu là nỗi buồn.
Nó được đào tạo trên một tập dữ liệu gồm các câu được gắn nhãn tình cảm của họ. Mô hình này học cách liên kết các từ và cụm từ nhất định với những cảm xúc nhất định. Thuật ngữ "chết" thường được kết nối với nỗi buồn. Khi thuật toán phát hiện từ “chết” trong một cụm từ, rất có thể nó sẽ dự đoán nỗi buồn.
Kết luận
Bài viết này bắt đầu với quá trình tiền xử lý, bao gồm thay đổi định dạng khung dữ liệu thành danh sách, quy trình mã thông báo, nhãn mã hóa, v.v. Nhân tiện, trong bài đăng này, chúng ta đã thảo luận những điều sau:
- phân loại cảm xúc trong văn bản câu sử dụng mạng nơ-ron có thể phân loại cảm xúc thể hiện trong dữ liệu văn bản.
- Kỹ thuật tính năng đóng một vai trò quan trọng trong việc phân loại cảm xúc văn bản vì việc trích xuất các tính năng có liên quan từ văn bản có thể cải thiện hiệu suất của mô hình.
- Huấn luyện mô hình mạng thần kinh trên dữ liệu văn bản được gắn nhãn để tìm hiểu các nguyên mẫu và mối liên hệ giữa văn bản và cảm xúc tương ứng.
- Mạng lưới thần kinh mang lại lợi thế trong việc nắm bắt các mẫu và mối quan hệ phức tạp trong dữ liệu văn bản, do đó cho phép phân loại cảm xúc chính xác.
Nhìn chung, bài viết này cung cấp một hướng dẫn toàn diện để phân loại cảm xúc văn bản bằng mạng thần kinh sử dụng Python. Vui lòng đặt câu hỏi có giá trị trong phần bình luận bên dưới. Mã đầy đủ là Ở đây.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/05/classifying-emotions-in-sentence-text-using-neural-networks/

