Giới thiệu
Bài viết này trình bày tổng quan về vấn đề phát hiện bot, nhấn mạnh những thách thức chính liên quan đến việc phát hiện bot. Nó khám phá các kỹ thuật và phương pháp khác nhau được sử dụng rộng rãi để xác định và chặn hoạt động của bot. Bài báo cũng sẽ thảo luận về ý nghĩa của việc phát hiện bot đối với quyền riêng tư, bảo mật trực tuyến. Nó cũng xem xét vai trò của máy học và trí tuệ nhân tạo trong việc cải thiện độ chính xác và hiệu quả của việc phát hiện bot.

Mục tiêu học tập:
- Hiểu khái niệm phát hiện bot trong bối cảnh khoa học dữ liệu
- Khám phá các loại bot khác nhau gặp phải trong các nền tảng trực tuyến
- Kiểm tra các kỹ thuật và thuật toán khác nhau được sử dụng để phát hiện bot
- Hiểu vai trò của khoa học dữ liệu và học máy trong phát hiện bot
- Thảo luận về những hạn chế và thách thức của việc phát hiện bot và những phát triển tiềm năng trong tương lai
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Bot là gì?
Các chương trình phần mềm được gọi là bot được thiết kế để thực hiện các tác vụ trên internet mà không cần sự can thiệp của con người. Chúng có thể bao gồm từ trình quét web đơn giản và bot nhập dữ liệu đến chatbot tinh vi hơn, bot truyền thông xã hội, bot phần mềm độc hại và bot spam. Bot sở hữu một số đặc điểm giúp phân biệt chúng với người dùng, bao gồm tốc độ, tính nhất quán, thiếu cảm xúc, hành vi lặp đi lặp lại và khả năng sáng tạo hạn chế.

Có nhiều loại bot khác nhau phục vụ các mục đích khác nhau. Một số loại bot phổ biến bao gồm:
- Trình thu thập dữ liệu web: Các bot tự động quét các trang web và thu thập dữ liệu cho các công cụ tìm kiếm khác nhau và các ứng dụng khác
- Chatbots: Các bot mô phỏng cuộc trò chuyện của con người và cung cấp dịch vụ hoặc hỗ trợ khách hàng tự động trên các nền tảng nhắn tin.
- Bot phương tiện truyền thông xã hội: Các bot tạo và quản lý các tài khoản mạng xã hội, tự động đăng bài và bình luận cũng như điều khiển diễn ngôn trực tuyến.
- Phần mềm độc hại bot: Các bot lây nhiễm phần mềm độc hại vào máy tính và thiết bị, đồng thời thực hiện các hoạt động độc hại như đánh cắp dữ liệu và thực hiện các cuộc tấn công mạng.
- bot thư rác: Các bot gửi tin nhắn và quảng cáo không mong muốn cho người dùng trên các nền tảng email và nhắn tin.
Bot chia sẻ một số đặc điểm phân biệt chúng với người dùng. Một số đặc điểm này bao gồm:
- Tốc độ: Bot có thể thực hiện các nhiệm vụ với tốc độ nhanh hơn nhiều so với con người.
- Tính nhất quán: Bots có thể thực hiện các nhiệm vụ với độ chính xác và nhất quán cao.
- Thiếu cảm xúc: Bot không có cảm xúc hoặc thành kiến chủ quan có thể ảnh hưởng đến hành vi của chúng.
- Hành vi lặp đi lặp lại: Các lập trình viên tạo bot để thực hiện các nhiệm vụ cụ thể lặp đi lặp lại.
- Thiếu sáng tạo: Bot không có khả năng suy nghĩ sáng tạo hoặc thích nghi với các tình huống mới giống như con người.
Tại sao Bot tồn tại?
Bot tồn tại vì nhiều lý do, tùy thuộc vào ý định của người tạo ra chúng. Một số lý do phổ biến để tạo bot bao gồm:
- Hiệu quả:Bot có thể thực hiện các tác vụ nhanh hơn và hiệu quả hơn so với con người, giúp chúng trở nên hữu ích trong việc tự động hóa các tác vụ lặp đi lặp lại hoặc tốn nhiều thời gian.
- Các hoạt động độc hại: Sử dụng bot cho các hoạt động độc hại như phát tán thư rác, thực hiện các cuộc tấn công mạng và đánh cắp dữ liệu.
- Tiếp thị và quảng cáo: Sử dụng bot để quảng bá sản phẩm và dịch vụ bằng cách tạo đánh giá giả của người dùng và tương tác trên mạng xã hội.
- Nghiên cứu và thu thập dữ liệu: Sử dụng bot để thu thập dữ liệu từ internet cho mục đích nghiên cứu hoặc để cung cấp thông tin cho các quyết định kinh doanh.

Ví dụ về việc sử dụng bot bao gồm:
- Rút trích nội dung trang web: Sử dụng bot để truy xuất dữ liệu từ các trang web có thể hữu ích cho nghiên cứu thị trường, so sánh giá và các mục đích kinh doanh khác.
- Dịch vụ khách hàng: Chatbots cung cấp hỗ trợ khách hàng tự động trên nền tảng nhắn tin, giảm nhu cầu can thiệp của con người.
- Thao túng phương tiện truyền thông xã hội: Sử dụng bot để tạo và quản lý các tài khoản mạng xã hội giả, làm tăng số liệu tương tác một cách giả tạo và lan truyền thông tin sai lệch.
- Tấn công mạng: Sử dụng bot phần mềm độc hại để lây nhiễm phần mềm độc hại vào máy tính và thiết bị, phần mềm này có thể được sử dụng để đánh cắp dữ liệu, khởi chạy các cuộc tấn công DDoS và thực hiện các hoạt động độc hại khác.
- chơi game: Sử dụng bot để tự động hóa lối chơi và giành lợi thế không công bằng trong trò chơi trực tuyến.
Kỹ thuật phát hiện bot
Một số kỹ thuật khác nhau để phát hiện bot, bao gồm:
- Phân tích hành vi: Kỹ thuật này liên quan đến việc phân tích các mẫu hành vi của người dùng để phân biệt giữa hoạt động của con người và bot.
- Dấu vân tay thiết bị: Kỹ thuật này liên quan đến việc phân tích các đặc điểm độc đáo của thiết bị truy cập trang web hoặc ứng dụng để xác định bot.
- CAPTCHA: Kỹ thuật này liên quan đến việc sử dụng các câu đố hoặc thử thách khó giải đối với bot nhưng lại dễ dàng đối với con người.
- Machine Learning: Kỹ thuật này liên quan đến các thuật toán đào tạo để xác định các mẫu và đặc điểm liên quan đến hoạt động của bot.

Mỗi kỹ thuật phát hiện bot đều có những ưu điểm và nhược điểm riêng. Một số trong số này bao gồm:
- Phân tích hành vi
Lợi thế: Nó có thể phát hiện các bot chưa từng thấy trước đây và cũng có thể cung cấp thông tin chi tiết về hành vi của người dùng.
Bất lợi: Nó có thể tốn thời gian và cũng tốn kém để thiết lập và có thể tạo ra kết quả dương tính giả hoặc âm tính giả.
2. Vân tay thiết bị
Lợi thế: Nó có hiệu quả trong việc xác định các bot sử dụng các công cụ hoặc tập lệnh tự động và cung cấp mức độ chính xác cao.
Bất lợi: Các bot tinh vi sử dụng thiết bị ảo hoặc giả mạo có thể vượt qua nó, có khả năng thu thập thông tin nhạy cảm của thiết bị và gây lo ngại về quyền riêng tư.
3. CAPTCHA
Lợi thế: Nó hiệu quả trong việc chặn các bot đơn giản không có khả năng AI phức tạp.
Bất lợi: Người dùng cảm thấy bất tiện và khó chịu vì bot có thể bỏ qua nó bằng cách sử dụng máy học hoặc các kỹ thuật nâng cao khác.
4. Machine Learning
Lợi thế: Nó đạt được mức độ chính xác cao trong việc thích ứng với các loại hoạt động bot mới và phát hiện các mẫu tinh vi mà con người khó có thể xác định được.
Bất lợi: Nó đòi hỏi một lượng lớn dữ liệu đào tạo để có hiệu quả và có thể dễ bị tấn công nhằm mục đích thao túng dữ liệu đào tạo hoặc các thuật toán máy học.
Chúng ta đã thấy những ưu điểm và nhược điểm của từng kỹ thuật phát hiện bot, bây giờ hãy xem một số ví dụ thực tế về chúng.
Ví dụ trong thế giới thực
- Phân tích hành vi: Một số công ty an ninh mạng sử dụng kỹ thuật này để phát hiện hoạt động của mạng botnet. Họ phân tích hành vi của lưu lượng mạng và xác định các kiểu giao tiếp giữa các thiết bị.
- Vân tay thiết bị: Một số trang web và ứng dụng sử dụng kỹ thuật này để phát hiện hoạt động của bot. Họ phân tích các đặc điểm của thiết bị được sử dụng để truy cập dịch vụ, bao gồm tác nhân người dùng, độ phân giải màn hình và các thuộc tính khác của thiết bị.
- CAPTCHA: Các trang web thường sử dụng kỹ thuật này để ngăn việc tạo tài khoản tự động, spam nhận xét và các loại hoạt động bot khác.
- Học máy: Các công ty như Google sử dụng kỹ thuật này để phát hiện hoạt động của bot trên nền tảng của họ. Họ đào tạo các thuật toán máy học để xác định các kiểu hành vi liên quan đến bot.
Học máy để phát hiện bot
ML, là một phần của trí tuệ nhân tạo, bao gồm các thuật toán đào tạo để tìm hiểu các mẫu và mối quan hệ trong dữ liệu mà không cần lập trình rõ ràng. Nó được sử dụng rộng rãi trong việc phát hiện bot bằng thuật toán huấn luyện trên bộ dữ liệu mở rộng về hành vi người dùng, lưu lượng truy cập mạng hoặc dữ liệu liên quan khác. Khóa đào tạo này cho phép xác định các mẫu liên quan đến hoạt động của bot. Sau đó, các thuật toán được đào tạo có thể tự động phân loại dữ liệu mới thành hoạt động của bot hoặc không phải bot.
Lợi ích của việc sử dụng máy học để phát hiện bot bao gồm:
- Khả năng mở rộng: Các thuật toán máy học có thể xử lý một lượng lớn dữ liệu một cách nhanh chóng, khiến chúng phù hợp để phát hiện hoạt động của bot trong thời gian thực.
- Khả năng thích ứng: Các thuật toán máy học có thể được đào tạo dựa trên dữ liệu mới để thích ứng với các loại hoạt động bot mới, giúp chúng hiệu quả hơn trong việc phát hiện các mối đe dọa mới và đang phát triển.
- tính chính xác: Các thuật toán máy học có thể xác định các mẫu tinh vi trong dữ liệu mà con người khó phát hiện, làm cho chúng chính xác hơn các phương pháp dựa trên quy tắc truyền thống.
Hạn chế của việc sử dụng máy học để phát hiện bot bao gồm:
- Xu hướng: Các thuật toán học máy đôi khi bị sai lệch nếu dữ liệu đào tạo không đại diện cho dân số được phân tích.
- phức tạp: Các thuật toán máy học có thể phức tạp và khó diễn giải, do đó gây khó khăn cho việc hiểu cách chúng đưa ra quyết định của mình.
- trang bị quá mức: Các thuật toán máy học có thể khớp quá dữ liệu đào tạo, khiến chúng kém hiệu quả hơn trong việc phát hiện hoạt động bot mới và chưa thấy.
Bây giờ, hãy để chúng tôi hiểu điều này thông qua một ví dụ mã đơn giản, người dùng chỉ cần mở Google Collab và cố gắng triển khai mã sau đây để hiểu rõ hơn.
Ví dụ về mã
Chúng tôi sẽ tạo một tập dữ liệu giả và làm việc với nó cho mục đích minh họa
import pandas as pd
# Define dummy data
data = { 'num_requests': [50, 100, 150, 200, 250, 300, 350, 400, 450, 500], 'num_failed_requests': [5, 10, 15, 20, 25, 30, 35, 40, 45, 50], 'num_successful_requests': [45, 90, 135, 180, 225, 270, 315, 360, 405, 450], 'avg_response_time': [100, 110, 120, 130, 140, 150, 160, 170, 180, 190], 'is_bot': [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
} # Convert data to pandas dataframe
df = pd.DataFrame(data) # Save dataframe to csv file
df.to_csv('bot_data.csv', index=False) from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # Load dataset
data = pd.read_csv('bot_data.csv') # Split dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split( data.drop('is_bot', axis=1), data['is_bot'], test_size=0.3) # Initialize random forest classifier
rfc = RandomForestClassifier() # Train classifier on training set
rfc.fit(X_train, y_train) # Predict labels for test set
y_pred = rfc.predict(X_test) # Evaluate the accuracy of classifier
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# Load trained model
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
Bây giờ chúng tôi đã đào tạo mô hình của mình và chúng tôi có độ chính xác cao. (Lưu ý: Trong các tình huống thực tế, độ chính xác có thể thay đổi rất nhiều) giờ đây chúng tôi có thể kiểm tra mô hình của mình bằng cách cung cấp dữ liệu ngẫu nhiên mới.)
# Create new request data
new_data = { 'num_requests': [500], 'num_failed_requests': [60], 'num_successful_requests': [200], 'avg_response_time': [190]
} # Convert new data to pandas dataframe
new_df = pd.DataFrame(new_data) # Predict whether new data represents a bot or not
prediction = rfc.predict(new_df)
if prediction[0] == 1: print('This request data is likely from a bot.')
else: print('This request data is likely from a human.') 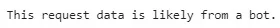
Sự tham gia của con người trong việc phát hiện bot
Con người sử dụng khả năng nhận thức của mình để xác định và giải thích các mẫu phức tạp mà máy móc khó có thể nhận ra.
Những lợi thế của sự tham gia của con người trong việc phát hiện bot bao gồm:
- Con người có thể phát hiện các mô hình tinh vi và sự bất thường mà máy móc không thể dễ dàng xác định được.
- Con người thích ứng với các mối đe dọa bot mới và đang phát triển, đồng thời có thể nhanh chóng cập nhật các chiến lược phát hiện để luôn đi trước những kẻ tấn công.
- Các chuyên gia con người có thể mang lại kiến thức và kỹ năng chuyên môn cho các nỗ lực phát hiện bot, chẳng hạn như kiến thức về các ngành hoặc công nghệ cụ thể.
Hạn chế
Những hạn chế của sự tham gia của con người trong việc phát hiện bot bao gồm:
- Chủ quan: Phát hiện của con người có thể chủ quan và dễ bị sai lệch và sai sót.
- Mất thời gian: Phát hiện thủ công có thể tốn nhiều thời gian và công sức, đặc biệt là trong các tập dữ liệu lớn.
- khả năng mở rộng: Phát hiện con người có thể không mở rộng được, đặc biệt là trong các tình huống phát hiện thời gian thực.
Ví dụ dựa trên ngành
Ví dụ về các nỗ lực phát hiện bot do con người lãnh đạo thành công bao gồm:
- Tại Hoa Kỳ (CISA) Cơ quan An ninh Cơ sở hạ tầng và An ninh mạng có một nhóm các nhà phân tích giám sát lưu lượng mạng để tìm dấu hiệu hoạt động của bot. Các nhà phân tích sử dụng kiến thức chuyên môn của mình để xác định hoạt động đáng ngờ, sau đó làm việc với các công cụ tự động để xác nhận và giảm thiểu mối đe dọa.
- Các tổ chức tài chính thường dựa vào các nhà phân tích con người để phát hiện hoạt động gian lận, bao gồm các cuộc tấn công do bot điều khiển như chiếm đoạt tài khoản và nhồi nhét thông tin xác thực.
- Wikimedia Foundation sử dụng kết hợp các kỹ thuật phát hiện bot tự động và thủ công để xác định và chặn bot trên Wikipedia. Người chỉnh sửa sử dụng nhiều chiến lược khác nhau để phát hiện và chặn bot, bao gồm phân tích lịch sử chỉnh sửa, địa chỉ IP và hành vi của người dùng.
Bây giờ chúng ta đã biết tầm quan trọng của sự can thiệp của con người và tầm quan trọng của việc bot phân biệt chính xác giữa yêu cầu của con người và bot, hãy tiến hành kiểm tra hiệu suất của mô hình với một điểm dữ liệu mẫu. Chúng tôi sẽ kiểm tra xem mô hình của chúng tôi có dự đoán chính xác liệu một yêu cầu nhất định là từ con người hay bot hay không.
Ví dụ về mã
import pandas as pd
from sklearn.ensemble import RandomForestClassifier # Load trained model
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train) # Create new request data
new_data = { 'num_requests': [100], 'num_failed_requests': [10], 'num_successful_requests': [90], 'avg_response_time': [120]
} # Convert new data to pandas dataframe
new_df = pd.DataFrame(new_data) # Predict whether new data represents a bot or not
prediction = rfc.predict(new_df)
if prediction[0] == 1: print('This request data is likely from a bot.')
else: print('This request data is likely from a human.') 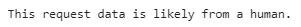
Các ví dụ và nghiên cứu điển hình trong thế giới thực
Nhiều tổ chức và công ty an ninh mạng đã nhận ra tầm quan trọng của các kỹ thuật khoa học dữ liệu trong việc phát hiện bot và đã triển khai chúng trong nền tảng của họ. Hãy khám phá một vài ví dụ trong thế giới thực:
- Mạng truyền thông xã hội: Các nền tảng truyền thông xã hội thường là mục tiêu của các bot tìm cách truyền bá thông tin sai lệch, thao túng dư luận hoặc tham gia vào các hoạt động spam. Khoa học dữ liệu đóng một vai trò quan trọng trong việc xác định và giảm thiểu các hoạt động bot này. Các mô hình máy học được đào tạo dựa trên khối lượng lớn dữ liệu người dùng để phát hiện các mẫu hành vi đáng ngờ, chẳng hạn như tạo hàng loạt tài khoản giả, đăng nội dung tự động hoặc tương tác mạng phối hợp.
- Trang web thương mại điện tử: Các thị trường trực tuyến phải đối mặt với những thách thức như bot cào giá, chúng trích xuất thông tin về giá để đạt được lợi thế cạnh tranh hoặc thao túng giá. Các kỹ thuật khoa học dữ liệu cho phép nhận dạng và chặn các bot như vậy bằng cách phân tích hành vi duyệt web, địa chỉ IP và mẫu mua hàng. Các thuật toán máy học có thể nhận ra các kiểu truy cập dữ liệu bất thường và phân biệt giữa người dùng hợp pháp và bot độc hại.
- Học viện Tài chính: Các ngân hàng và tổ chức tài chính là mục tiêu chính của các hoạt động gian lận do bot điều khiển, chẳng hạn như chiếm đoạt tài khoản, đánh cắp danh tính hoặc giao dịch gian lận. Khoa học dữ liệu đóng một vai trò quan trọng trong việc xây dựng các hệ thống phát hiện gian lận có thể xác định hành vi đáng ngờ, gắn cờ các hoạt động tiềm năng do bot điều khiển để điều tra thêm. Bằng cách phân tích các mẫu giao dịch, hành vi của người dùng và thông tin thiết bị, các mô hình máy học có thể phát hiện các điểm bất thường và bảo vệ tài khoản của khách hàng.
Tương lai của phát hiện bot

- Sự phức tạp của các cuộc tấn công Bot: Các bot ngày càng trở nên tinh vi hơn, khiến chúng khó bị phát hiện hơn bằng các phương pháp truyền thống.
- Sự trỗi dậy của máy học: Mặc dù ML hiệu quả trong việc phát hiện bot, nhưng nó yêu cầu một lượng lớn dữ liệu và kiến thức chuyên môn để huấn luyện các mô hình. Điều này gây khó khăn cho các tổ chức nhỏ hơn trong việc thực hiện.
- Cân bằng độ chính xác và khả năng sử dụng: Các công cụ phát hiện bot phải đạt được sự cân bằng giữa độ chính xác và khả năng sử dụng. Vì các công cụ quá phức tạp có thể khó sử dụng hiệu quả đối với những người không phải là chuyên gia.
Những phát triển tiềm năng trong tương lai trong công nghệ phát hiện bot:
- Những tiến bộ trong học máy: Các thuật toán máy học sẽ tiếp tục được cải thiện, giúp chúng phát hiện bot hiệu quả hơn.
- Tăng cường sử dụng Phân tích hành vi: Xem cách người dùng tương tác với hệ thống theo thời gian, có thể trở thành một cách tiếp cận phổ biến hơn để phát hiện bot.
- Sử dụng tự động hóa nhiều hơn: Khi các bot trở nên tiên tiến hơn, các hệ thống tự động sẽ ngày càng trở nên quan trọng để phát hiện và giảm thiểu các cuộc tấn công của bot.
Tầm quan trọng của việc tiếp tục nghiên cứu trong việc phát hiện bot:
- Khi các cuộc tấn công bot tiếp tục phát triển, cần tiếp tục nghiên cứu để luôn đi trước những kẻ tấn công.
- Sự hợp tác và chia sẻ thông tin giữa các nhà nghiên cứu, học viên và tổ chức là rất quan trọng để theo kịp các mối đe dọa bot mới nổi.
- Việc phát triển các công cụ phát hiện bot dễ tiếp cận hơn sẽ giúp các tổ chức thuộc mọi quy mô tự bảo vệ mình khỏi các cuộc tấn công của bot.
Kết luận
Phát hiện bot là một khía cạnh quan trọng của khoa học dữ liệu và an ninh mạng, nhằm xác định và giảm thiểu các chương trình tự động bắt chước hành vi của con người. Thông qua việc triển khai các kỹ thuật khác nhau, bao gồm phân tích hành vi, lấy dấu vân tay của thiết bị, CAPTCHA và thuật toán học máy, các nhà khoa học dữ liệu có thể phát triển các hệ thống phát hiện bot mạnh mẽ. Các kỹ thuật khoa học dữ liệu cho phép khả năng mở rộng, khả năng thích ứng với các mối đe dọa mới và phát hiện các mẫu tinh vi. Tuy nhiên, những thách thức như sai lệch trong dữ liệu đào tạo và khả năng diễn giải của các mô hình phức tạp cần được giải quyết. Khi lĩnh vực này phát triển, các kỹ thuật cộng tác, phát hiện thời gian thực và học máy tiên tiến sẽ tiếp tục định hình tương lai của phát hiện bot, cuối cùng là bảo vệ các tương tác trực tuyến và duy trì niềm tin vào các nền tảng kỹ thuật số.
Chìa khóa chính
- Bot không là gì ngoài các chương trình tự động có thể thực hiện nhiều tác vụ trực tuyến.
- Phát hiện bot rất quan trọng để bảo vệ chống lại hoạt động của bot độc hại, có thể bao gồm chiếm đoạt tài khoản, gửi thư rác và tấn công từ chối dịch vụ.
- Có nhiều kỹ thuật phát hiện bot khác nhau, bao gồm chặn dựa trên IP, phát hiện dựa trên chữ ký và máy học.
- Máy học là một phương pháp hiệu quả để phát hiện bot, nhưng nó đòi hỏi một lượng lớn dữ liệu và kiến thức chuyên môn để triển khai.
- Sự tham gia của con người cũng rất quan trọng trong việc phát hiện bot, vì các chuyên gia về con người có thể xác định các mẫu và hành vi mà các hệ thống tự động có thể bỏ qua.
- Tương lai của phát hiện bot có thể sẽ liên quan đến sự kết hợp của cả chuyên môn của con người và cả các công cụ học máy, với trọng tâm là tự động hóa và phân tích hành vi.
Phương tiện được hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định của Tác giả
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/05/guardians-of-the-internet-power-of-data-science-in-bot-detection/

