Đây là bài đăng thứ hai trong loạt bài gồm hai phần, trong đó tôi đề xuất một hướng dẫn thực tế cho các tổ chức để bạn có thể đánh giá chất lượng của các mô hình tóm tắt văn bản cho miền của mình.
Để biết phần giới thiệu về tóm tắt văn bản, tổng quan về hướng dẫn này và các bước để tạo đường cơ sở cho dự án của chúng tôi (còn được gọi là phần 1), hãy quay lại phần bài viết đầu tiên.
Bài đăng này được chia thành ba phần:
- Phần 2: Tạo tóm tắt bằng mô hình zero-shot
- Phần 3: Đào tạo một mô hình tóm tắt
- Phần 4: Đánh giá mô hình được đào tạo
Phần 2: Tạo tóm tắt bằng mô hình zero-shot
Trong bài đăng này, chúng tôi sử dụng khái niệm học không bắn (ZSL), có nghĩa là chúng tôi sử dụng một mô hình đã được đào tạo để tóm tắt văn bản nhưng chưa thấy bất kỳ ví dụ nào về tập dữ liệu arXiv. Nó hơi giống như cố gắng vẽ một bức chân dung khi tất cả những gì bạn đã làm trong đời là vẽ phong cảnh. Bạn biết cách vẽ tranh, nhưng bạn có thể không quá quen thuộc với những phức tạp của vẽ chân dung.
Đối với phần này, chúng tôi sử dụng máy tính xách tay.
Tại sao phải học zero-shot?
ZSL đã trở nên phổ biến trong những năm qua vì nó cho phép bạn sử dụng các mô hình NLP hiện đại mà không cần đào tạo. Và hiệu suất của họ đôi khi khá đáng kinh ngạc: Nhóm làm việc nghiên cứu khoa học lớn gần đây đã phát hành mô hình T0pp (phát âm là “T Zero Plus Plus”) của họ, được đào tạo đặc biệt để nghiên cứu việc học đa nhiệm không chụp. Nó thường có thể hoạt động tốt hơn các mô hình lớn hơn sáu lần trên Băng ghế dự bị lớn điểm chuẩn và có thể vượt trội hơn GPT-3 (Lớn hơn 16 lần) trên một số điểm chuẩn NLP khác.
Một lợi ích khác của ZSL là chỉ cần hai dòng mã để sử dụng nó. Bằng cách dùng thử, chúng tôi tạo ra đường cơ sở thứ hai, chúng tôi sử dụng để định lượng mức tăng hiệu suất mô hình sau khi chúng tôi tinh chỉnh mô hình trên tập dữ liệu của mình.
Thiết lập một quy trình học tập zero-shot
Để sử dụng các mẫu ZSL, chúng ta có thể sử dụng Hugging Face's API đường ống. API này cho phép chúng tôi sử dụng mô hình tóm tắt văn bản chỉ với hai dòng mã. Nó đảm nhận các bước xử lý chính trong mô hình NLP:
- Xử lý trước văn bản thành một định dạng mà mô hình có thể hiểu được.
- Chuyển các đầu vào được xử lý trước vào mô hình.
- Xử lý sau các dự đoán của mô hình để bạn có thể hiểu được chúng.
Nó sử dụng các mô hình tóm tắt đã có sẵn trên Trung tâm mô hình ôm mặt.
Để sử dụng nó, hãy chạy đoạn mã sau:
Đó là nó! Mã tải xuống mô hình tóm tắt và tạo tóm tắt cục bộ trên máy của bạn. Nếu bạn đang tự hỏi mô hình nó sử dụng, bạn có thể tra cứu nó trong mã nguồn hoặc sử dụng lệnh sau:
Khi chúng tôi chạy lệnh này, chúng tôi thấy rằng mô hình mặc định cho tóm tắt văn bản được gọi là sshleifer/distilbart-cnn-12-6:
![]()
Chúng tôi có thể tìm thấy thẻ mẫu cho mô hình này trên trang web Hugging Face, nơi chúng tôi cũng có thể thấy rằng mô hình đã được đào tạo trên hai tập dữ liệu: CNN Dailymail tập dữ liệu và Tập dữ liệu Tóm tắt cực đoan (XSum). Cần lưu ý rằng mô hình này không quen thuộc với tập dữ liệu arXiv và chỉ được sử dụng để tóm tắt các văn bản tương tự với các văn bản mà nó đã được đào tạo (chủ yếu là các bài báo). Số 12 và 6 trong tên kiểu máy lần lượt đề cập đến số lớp bộ mã hóa và lớp bộ giải mã. Giải thích những điều này nằm ngoài phạm vi của hướng dẫn này, nhưng bạn có thể đọc thêm về nó trong bài đăng Giới thiệu BART bởi Sam Shleifer, người đã tạo ra mô hình.
Chúng tôi sử dụng mô hình mặc định trong tương lai, nhưng tôi khuyến khích bạn nên thử các mô hình được đào tạo trước khác nhau. Tất cả các mô hình phù hợp để tóm tắt có thể được tìm thấy trên Trang web Hugging Face. Để sử dụng một mô hình khác, bạn có thể chỉ định tên mô hình khi gọi API Pipeline:
Tóm tắt chiết xuất so với trừu tượng
Chúng tôi chưa nói về hai cách tiếp cận khả thi nhưng khác nhau để tóm tắt văn bản: khai thác vs. trừu tượng. Tóm tắt chiết xuất là chiến lược nối các đoạn trích được lấy từ một văn bản thành một bản tóm tắt, trong khi tóm tắt trừu tượng liên quan đến việc diễn giải ngữ liệu bằng cách sử dụng các câu mới. Hầu hết các mô hình tóm tắt đều dựa trên các mô hình tạo ra văn bản mới lạ (chúng là các mô hình tạo ngôn ngữ tự nhiên, chẳng hạn như GPT-3). Điều này có nghĩa là các mô hình tóm tắt cũng tạo ra văn bản mới, khiến chúng trở thành các mô hình tóm tắt trừu tượng.
Tạo tóm tắt bằng không
Bây giờ chúng tôi đã biết cách sử dụng nó, chúng tôi muốn sử dụng nó trên tập dữ liệu thử nghiệm của mình — cùng một tập dữ liệu mà chúng tôi đã sử dụng trong phần 1 để tạo đường cơ sở. Chúng ta có thể làm điều đó với vòng lặp sau:
Chúng tôi sử dụng min_length và max_length các tham số để kiểm soát tóm tắt mà mô hình tạo ra. Trong ví dụ này, chúng tôi đặt min_length thành 5 vì chúng tôi muốn tiêu đề dài ít nhất năm từ. Và bằng cách ước tính các bản tóm tắt tham khảo (tiêu đề thực tế cho các bài báo nghiên cứu), chúng tôi xác định rằng 20 có thể là một giá trị hợp lý cho max_length. Nhưng một lần nữa, đây chỉ là một nỗ lực đầu tiên. Khi dự án đang trong giai đoạn thử nghiệm, hai thông số này có thể và nên được thay đổi để xem hiệu suất của mô hình có thay đổi hay không.
Các thông số bổ sung
Nếu bạn đã quen thuộc với việc tạo văn bản, bạn có thể biết có nhiều tham số khác để ảnh hưởng đến văn bản mà một mô hình tạo ra, chẳng hạn như tìm kiếm chùm, lấy mẫu và nhiệt độ. Các tham số này cho phép bạn kiểm soát nhiều hơn đối với văn bản đang được tạo, chẳng hạn như làm cho văn bản trôi chảy hơn và ít lặp lại hơn. Các kỹ thuật này không có sẵn trong API Pipeline — bạn có thể xem trong mã nguồn việc này min_length và max_length là các tham số duy nhất được xem xét. Tuy nhiên, sau khi chúng tôi đào tạo và triển khai mô hình của riêng mình, chúng tôi có quyền truy cập vào các tham số đó. Thêm về điều đó trong phần 4 của bài đăng này.
Đánh giá mô hình
Sau khi chúng tôi đã tạo các bản tóm tắt zero-shot, chúng tôi có thể sử dụng lại hàm ROUGE để so sánh các bản tóm tắt ứng viên với các bản tóm tắt tham chiếu:
Chạy phép tính này trên các bản tóm tắt được tạo bằng mô hình ZSL cho chúng tôi các kết quả sau:
![]()
Khi chúng tôi so sánh những mô hình này với đường cơ sở của chúng tôi, chúng tôi thấy rằng mô hình ZSL này thực sự hoạt động kém hơn so với phương pháp phỏng đoán đơn giản của chúng tôi khi chỉ lấy câu đầu tiên. Một lần nữa, điều này không nằm ngoài dự đoán: mặc dù mô hình này biết cách tóm tắt các bài báo, nó chưa bao giờ thấy một ví dụ về tóm tắt phần tóm tắt của một bài báo nghiên cứu học thuật.
So sánh đường cơ sở
Bây giờ chúng tôi đã tạo ra hai đường cơ sở: một bằng cách sử dụng heuristic đơn giản và một bằng mô hình ZSL. Bằng cách so sánh điểm ROUGE, chúng ta thấy rằng phương pháp phỏng đoán đơn giản hiện đang tốt hơn mô hình học sâu.
![]()
Trong phần tiếp theo, chúng tôi sử dụng cùng một mô hình học sâu này và cố gắng cải thiện hiệu suất của nó. Chúng tôi làm như vậy bằng cách đào tạo nó trên tập dữ liệu arXiv (bước này còn được gọi là tinh chỉnh). Chúng tôi tận dụng lợi thế của thực tế là nó đã biết cách tóm tắt văn bản nói chung. Sau đó, chúng tôi hiển thị cho nó rất nhiều ví dụ về tập dữ liệu arXiv của chúng tôi. Các mô hình học sâu đặc biệt tốt trong việc xác định các mẫu trong tập dữ liệu sau khi chúng được đào tạo về nó, vì vậy chúng tôi hy vọng mô hình sẽ hoàn thành tốt hơn nhiệm vụ cụ thể này.
Phần 3: Đào tạo một mô hình tóm tắt
Trong phần này, chúng tôi đào tạo mô hình mà chúng tôi đã sử dụng để tóm tắt chế độ zero-shot trong phần 2 (sshleifer/distilbart-cnn-12-6) trên tập dữ liệu của chúng tôi. Ý tưởng là dạy cho mô hình biết phần tóm tắt của các bài báo nghiên cứu trông như thế nào bằng cách cho nó xem nhiều ví dụ. Theo thời gian, mô hình sẽ nhận ra các mẫu trong tập dữ liệu này, điều này sẽ cho phép nó tạo ra các bản tóm tắt tốt hơn.
Một lần nữa cần lưu ý rằng nếu bạn đã gắn nhãn dữ liệu, cụ thể là văn bản và các bản tóm tắt tương ứng, bạn nên sử dụng những dữ liệu đó để đào tạo một mô hình. Chỉ khi làm như vậy, mô hình mới có thể học các mẫu của tập dữ liệu cụ thể của bạn.
Mã hoàn chỉnh cho việc đào tạo mô hình như sau máy tính xách tay.
Thiết lập một công việc đào tạo
Bởi vì việc đào tạo một mô hình học sâu sẽ mất vài tuần trên máy tính xách tay, chúng tôi sử dụng Amazon SageMaker đào tạo công việc thay thế. Để biết thêm chi tiết, hãy tham khảo Đào tạo người mẫu với Amazon SageMaker. Trong bài đăng này, tôi nêu bật ngắn gọn lợi thế của việc sử dụng các công việc đào tạo này, bên cạnh việc chúng cho phép chúng tôi sử dụng các phiên bản tính toán GPU.
Giả sử chúng ta có một nhóm các phiên bản GPU mà chúng ta có thể sử dụng. Trong trường hợp đó, chúng tôi có thể muốn tạo một hình ảnh Docker để chạy đào tạo để chúng tôi có thể dễ dàng sao chép môi trường đào tạo trên các máy khác. Sau đó, chúng tôi cài đặt các gói bắt buộc và vì chúng tôi muốn sử dụng một số phiên bản, chúng tôi cũng cần thiết lập đào tạo phân tán. Khi quá trình đào tạo hoàn tất, chúng tôi muốn nhanh chóng tắt các máy tính này vì chúng rất tốn kém.
Tất cả các bước này được chúng tôi trừu tượng hóa khi sử dụng các công việc đào tạo. Trên thực tế, chúng ta có thể huấn luyện một mô hình theo cách giống như đã mô tả bằng cách chỉ định các tham số huấn luyện và sau đó chỉ cần gọi một phương thức. SageMaker sẽ lo phần còn lại, bao gồm cả việc dừng các phiên bản GPU khi quá trình đào tạo hoàn tất để không phải chịu thêm bất kỳ chi phí nào.
Ngoài ra, Hugging Face và AWS đã công bố mối quan hệ đối tác trước đó vào năm 2022, giúp việc đào tạo các mô hình Khuôn mặt ôm trên SageMaker thậm chí còn dễ dàng hơn. Chức năng này có sẵn thông qua sự phát triển của Khuôn mặt ôm AWS Deep Learning Container (DLC). Những vùng chứa này bao gồm Máy biến hình khuôn mặt ôm, Tokenizers và thư viện Bộ dữ liệu, cho phép chúng tôi sử dụng các tài nguyên này cho các công việc đào tạo và suy luận. Để biết danh sách các hình ảnh DLC có sẵn, hãy xem có sẵn Hình ảnh Ôm Face Deep Learning Containers. Chúng được bảo trì và cập nhật thường xuyên với các bản vá bảo mật. Chúng tôi có thể tìm thấy nhiều ví dụ về cách huấn luyện mô hình Khuôn mặt ôm với các DLC này và Ôm Face Python SDK trong những điều sau đây Repo GitHub.
Chúng tôi sử dụng một trong những ví dụ đó làm mẫu vì nó thực hiện hầu hết mọi thứ chúng tôi cần cho mục đích của mình: đào tạo một mô hình tóm tắt trên một tập dữ liệu cụ thể theo cách phân tán (sử dụng nhiều phiên bản GPU).
Tuy nhiên, chúng ta phải tính đến một điều là ví dụ này sử dụng tập dữ liệu trực tiếp từ trung tâm tập dữ liệu Hugging Face. Bởi vì chúng tôi muốn cung cấp dữ liệu tùy chỉnh của riêng mình, chúng tôi cần sửa đổi sổ ghi chép một chút.
Chuyển dữ liệu cho công việc đào tạo
Để giải thích cho thực tế là chúng tôi mang tập dữ liệu của riêng mình, chúng tôi cần sử dụng kênh. Để biết thêm thông tin, hãy tham khảo Cách Amazon SageMaker cung cấp thông tin đào tạo.
Cá nhân tôi thấy thuật ngữ này hơi khó hiểu nên trong đầu tôi luôn nghĩ lập bản đồ khi tôi nghe kênh, bởi vì nó giúp tôi hình dung rõ hơn về những gì sẽ xảy ra. Hãy để tôi giải thích: như chúng ta đã học, công việc đào tạo xoay quanh một nhóm Đám mây điện toán đàn hồi Amazon (Amazon EC2) các phiên bản và sao chép hình ảnh Docker vào đó. Tuy nhiên, bộ dữ liệu của chúng tôi được lưu trữ trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) và không thể truy cập bằng hình ảnh Docker đó. Thay vào đó, công việc đào tạo cần sao chép dữ liệu từ Amazon S3 sang tệp định sẵn
ined đường dẫn cục bộ trong hình ảnh Docker đó. Cách nó thực hiện là chúng tôi cho tác vụ đào tạo biết vị trí của dữ liệu trong Amazon S3 và vị trí trên hình ảnh Docker mà dữ liệu sẽ được sao chép vào để tác vụ đào tạo có thể truy cập dữ liệu đó. chúng tôi bản đồ vị trí Amazon S3 với đường dẫn cục bộ.
Chúng tôi đặt đường dẫn cục bộ trong phần siêu tham số của công việc đào tạo:
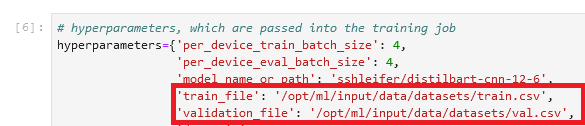
Sau đó, chúng tôi cho công việc đào tạo biết nơi dữ liệu nằm trong Amazon S3 khi gọi phương thức fit (), bắt đầu đào tạo:
![]()
Lưu ý rằng tên thư mục sau /opt/ml/input/data khớp với tên kênh (datasets). Điều này cho phép công việc đào tạo sao chép dữ liệu từ Amazon S3 vào đường dẫn cục bộ.
Bắt đầu đào tạo
Bây giờ chúng tôi đã sẵn sàng để bắt đầu công việc đào tạo. Như đã đề cập trước đây, chúng tôi làm như vậy bằng cách gọi fit() phương pháp. Công việc đào tạo diễn ra trong khoảng 40 phút. Bạn có thể theo dõi tiến trình và xem thông tin bổ sung trên bảng điều khiển SageMaker.
![]()
Khi công việc đào tạo hoàn tất, đã đến lúc đánh giá mô hình mới được đào tạo của chúng tôi.
Phần 4: Đánh giá mô hình được đào tạo
Đánh giá mô hình được đào tạo của chúng tôi rất giống với những gì chúng tôi đã làm trong phần 2, nơi chúng tôi đánh giá mô hình ZSL. Chúng tôi gọi mô hình và tạo các bản tóm tắt của ứng viên và so sánh chúng với các bản tóm tắt tham khảo bằng cách tính điểm ROUGE. Nhưng bây giờ, mô hình nằm trong Amazon S3 trong một tệp có tên model.tar.gz (để tìm vị trí chính xác, bạn có thể kiểm tra công việc đào tạo trên bảng điều khiển). Vậy làm cách nào để truy cập mô hình để tạo tóm tắt?
Chúng tôi có hai lựa chọn: triển khai mô hình tới điểm cuối SageMaker hoặc tải xuống cục bộ, tương tự như những gì chúng tôi đã làm trong phần 2 với mô hình ZSL. Trong hướng dẫn này, tôi triển khai mô hình tới điểm cuối SageMaker bởi vì nó thuận tiện hơn và bằng cách chọn một thể hiện mạnh mẽ hơn cho điểm cuối, chúng ta có thể rút ngắn đáng kể thời gian suy luận. Kho lưu trữ GitHub chứa máy tính xách tay điều đó cho thấy cách đánh giá mô hình tại địa phương.
Triển khai một mô hình
Thường rất dễ dàng triển khai một mô hình được đào tạo trên SageMaker (xem lại ví dụ sau trên GitHub từ Khuôn mặt ôm). Sau khi người mẫu đã được đào tạo, chúng tôi có thể gọi estimator.deploy() và SageMaker thực hiện phần còn lại cho chúng tôi trong nền. Bởi vì trong hướng dẫn của chúng tôi, chúng tôi chuyển từ sổ ghi chép này sang sổ ghi chép tiếp theo, trước tiên, chúng tôi phải xác định công việc đào tạo và mô hình được liên kết, trước khi chúng tôi có thể triển khai nó:
![]()
Sau khi chúng tôi truy xuất vị trí mô hình, chúng tôi có thể triển khai nó tới một điểm cuối của SageMaker:
Việc triển khai trên SageMaker rất đơn giản vì nó sử dụng Bộ công cụ suy luận khuôn mặt ôm SageMaker, một thư viện mã nguồn mở để phục vụ các mô hình Transformers trên SageMaker. Chúng tôi thậm chí không cần phải cung cấp một kịch bản suy luận; bộ công cụ sẽ giải quyết vấn đề đó. Tuy nhiên, trong trường hợp đó, bộ công cụ sử dụng lại API Pipeline và như chúng ta đã thảo luận trong phần 2, API Pipeline không cho phép chúng tôi sử dụng các kỹ thuật tạo văn bản nâng cao như tìm kiếm chùm và lấy mẫu. Để tránh hạn chế này, chúng tôi cung cấp kịch bản suy luận tùy chỉnh.
Đánh giá đầu tiên
Đối với đánh giá đầu tiên về mô hình mới được đào tạo của chúng tôi, chúng tôi sử dụng các thông số tương tự như trong phần 2 với mô hình zero-shot để tạo ra các tóm tắt ứng viên. Điều này cho phép so sánh táo với táo:
Chúng tôi so sánh các tóm tắt do mô hình tạo ra với các tóm tắt tham khảo:
![]()
Điều này thật đáng khích lệ! Nỗ lực đầu tiên của chúng tôi để đào tạo mô hình, mà không cần bất kỳ điều chỉnh siêu thông số nào, đã cải thiện đáng kể điểm ROUGE.
![]()
Đánh giá thứ hai
Bây giờ đã đến lúc sử dụng một số kỹ thuật nâng cao hơn như tìm kiếm chùm và lấy mẫu để thử nghiệm với mô hình. Để được giải thích chi tiết về chức năng của từng thông số này, hãy tham khảo Cách tạo văn bản: sử dụng các phương pháp giải mã khác nhau để tạo ngôn ngữ với Người máy biến hình. Hãy thử nó với một bộ giá trị bán ngẫu nhiên cho một số thông số sau:
Khi chạy mô hình của chúng tôi với các thông số này, chúng tôi nhận được các điểm số sau:
![]()
Điều đó không diễn ra hoàn toàn như chúng tôi hy vọng — điểm ROUGE thực sự đã giảm nhẹ. Tuy nhiên, đừng để điều này làm bạn nản lòng khi thử các giá trị khác nhau cho các tham số này. Trên thực tế, đây là thời điểm mà chúng tôi kết thúc giai đoạn thiết lập và chuyển sang giai đoạn thử nghiệm của dự án.
Kết luận và các bước tiếp theo
Chúng tôi đã kết thúc quá trình thiết lập cho giai đoạn thử nghiệm. Trong loạt bài gồm hai phần này, chúng tôi đã tải xuống và chuẩn bị dữ liệu của mình, tạo một đường cơ sở với phương pháp phỏng đoán đơn giản, tạo một đường cơ sở khác bằng cách sử dụng phương pháp học zero-shot, sau đó đào tạo mô hình của chúng tôi và thấy hiệu suất tăng đáng kể. Bây giờ đã đến lúc thử với mọi phần chúng tôi đã tạo để tạo ra những bản tóm tắt tốt hơn nữa. Hãy xem xét những điều sau:
- Xử lý trước dữ liệu đúng cách - Ví dụ: loại bỏ các từ dừng và dấu chấm câu. Đừng đánh giá thấp phần này — trong nhiều dự án khoa học dữ liệu, tiền xử lý dữ liệu là một trong những khía cạnh quan trọng nhất (nếu không muốn nói là quan trọng nhất) và các nhà khoa học dữ liệu thường dành phần lớn thời gian của họ cho nhiệm vụ này.
- Hãy thử các mô hình khác nhau - Trong hướng dẫn của chúng tôi, chúng tôi đã sử dụng mô hình chuẩn để tóm tắt (
sshleifer/distilbart-cnn-12-6), Nhưng nhiều mô hình khác có sẵn mà bạn có thể sử dụng cho nhiệm vụ này. Một trong số đó có thể phù hợp hơn với trường hợp sử dụng của bạn. - Thực hiện điều chỉnh siêu tham số - Khi đào tạo mô hình, chúng tôi đã sử dụng một bộ siêu tham số nhất định (tốc độ học, số kỷ nguyên, v.v.). Các thông số này không được thiết lập sẵn — hoàn toàn ngược lại. Bạn nên thay đổi các thông số này để hiểu cách chúng ảnh hưởng đến hiệu suất mô hình của bạn.
- Sử dụng các tham số khác nhau để tạo văn bản - Chúng tôi đã thực hiện một vòng tạo tóm tắt với các tham số khác nhau để sử dụng tìm kiếm và lấy mẫu chùm. Hãy thử các giá trị và thông số khác nhau. Để biết thêm thông tin, hãy tham khảo Cách tạo văn bản: sử dụng các phương pháp giải mã khác nhau để tạo ngôn ngữ với Người máy biến hình.
Tôi hy vọng bạn đã làm đến cùng và thấy hướng dẫn này hữu ích.
Lưu ý
![]() Heiko Hotz là Kiến trúc sư giải pháp cao cấp về AI & Machine Learning và lãnh đạo cộng đồng Xử lý ngôn ngữ tự nhiên (NLP) trong AWS. Trước khi đảm nhiệm vai trò này, ông là Trưởng phòng Khoa học Dữ liệu của Dịch vụ Khách hàng EU của Amazon. Heiko giúp khách hàng của chúng tôi thành công trong hành trình AI / ML của họ trên AWS và đã làm việc với các tổ chức trong nhiều ngành, bao gồm Bảo hiểm, Dịch vụ tài chính, Truyền thông và Giải trí, Chăm sóc sức khỏe, Tiện ích và Sản xuất. Khi rảnh rỗi, Heiko đi du lịch nhiều nhất có thể.
Heiko Hotz là Kiến trúc sư giải pháp cao cấp về AI & Machine Learning và lãnh đạo cộng đồng Xử lý ngôn ngữ tự nhiên (NLP) trong AWS. Trước khi đảm nhiệm vai trò này, ông là Trưởng phòng Khoa học Dữ liệu của Dịch vụ Khách hàng EU của Amazon. Heiko giúp khách hàng của chúng tôi thành công trong hành trình AI / ML của họ trên AWS và đã làm việc với các tổ chức trong nhiều ngành, bao gồm Bảo hiểm, Dịch vụ tài chính, Truyền thông và Giải trí, Chăm sóc sức khỏe, Tiện ích và Sản xuất. Khi rảnh rỗi, Heiko đi du lịch nhiều nhất có thể.
- Coinsmart. Sàn giao dịch Bitcoin và tiền điện tử tốt nhất Châu Âu.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. TRUY CẬP MIỄN PHÍ.
- CryptoHawk. Radar Altcoin. Dùng thử miễn phí.
- Nguồn: https://aws.amazon.com/blogs/machine-learning/part-2-set-up-a-text-summarization-project-with-hugging-face-transformers/

