Amazon RedShift là một kho dữ liệu đám mây quy mô petabyte được sử dụng rộng rãi, được quản lý đầy đủ. Hàng chục nghìn khách hàng sử dụng Amazon Redshift để xử lý hàng exabyte dữ liệu mỗi ngày nhằm cung cấp năng lượng cho khối lượng công việc phân tích của họ. Khách hàng đang tìm kiếm các công cụ giúp di chuyển dễ dàng hơn từ các kho dữ liệu khác, chẳng hạn như Google BigQuery, sang Amazon Redshift để tận dụng lợi thế của giá dịch vụ-hiệu suất, dễ sử dụng, bảo mật và độ tin cậy.
Trong bài đăng này, chúng tôi hướng dẫn bạn cách sử dụng các dịch vụ gốc của AWS để tăng tốc quá trình di chuyển của bạn từ Google BigQuery sang Amazon Redshift. Chúng tôi sử dụng Keo AWS, một dịch vụ ETL (trích xuất, chuyển đổi và tải) được quản lý hoàn toàn, không có máy chủ và Google BigQuery Connector cho keo AWS (để biết thêm thông tin, tham khảo Di chuyển dữ liệu từ Google BigQuery sang Amazon S3 bằng trình kết nối tùy chỉnh AWS Glue). Chúng tôi cũng bổ sung khả năng tự động hóa và tính linh hoạt để đơn giản hóa quá trình di chuyển nhiều bảng sang Amazon Redshift bằng cách sử dụng Khung tải tự động tùy chỉnh.
Tổng quan về giải pháp
Giải pháp cung cấp quy trình di chuyển dữ liệu được quản lý và có thể mở rộng để di chuyển dữ liệu từ Google BigQuery sang Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), rồi từ Amazon S3 sang Amazon Redshift. Giải pháp dựng sẵn này chia tỷ lệ để tải dữ liệu song song bằng các tham số đầu vào.
Sơ đồ kiến trúc sau đây cho thấy giải pháp hoạt động như thế nào. Nó bắt đầu bằng việc thiết lập cấu hình di chuyển để kết nối với Google BigQuery, sau đó chuyển đổi các lược đồ cơ sở dữ liệu và cuối cùng là di chuyển dữ liệu sang Amazon Redshift.
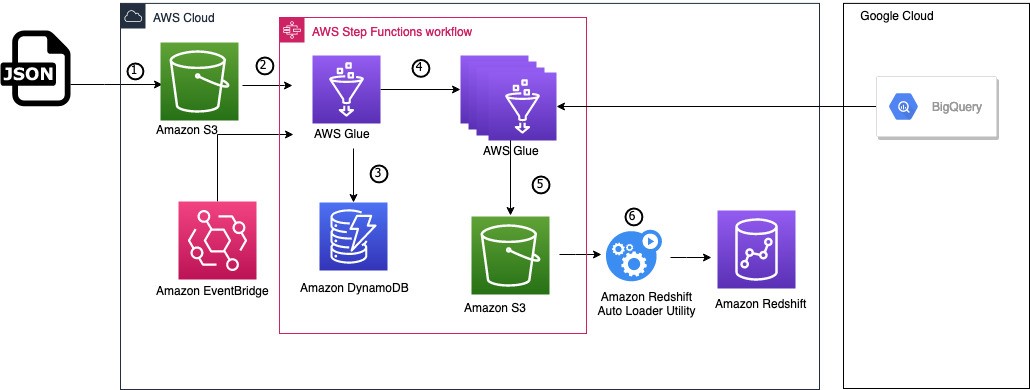
Dòng công việc bao gồm các bước sau:
- Tệp cấu hình được tải lên bộ chứa S3 mà bạn đã chọn cho giải pháp này. Tệp JSON này chứa siêu dữ liệu di chuyển, cụ thể là như sau:
- Danh sách các dự án và bộ dữ liệu Google BigQuery.
- Danh sách tất cả các bảng sẽ được di chuyển cho từng dự án và cặp dữ liệu.
- An Sự kiện Amazon quy tắc kích hoạt một Chức năng bước AWS máy trạng thái để bắt đầu di chuyển các bảng.
- Máy trạng thái Step Functions lặp lại trên các bảng sẽ được di chuyển và chạy tác vụ AWS Glue Python shell để trích xuất siêu dữ liệu từ Google BigQuery và lưu trữ trong một Máy phát điện Amazon bảng được sử dụng để theo dõi trạng thái di chuyển của bảng.
- Máy trạng thái lặp lại siêu dữ liệu từ bảng DynamoDB này để chạy song song quá trình di chuyển bảng, dựa trên số lượng tác vụ di chuyển tối đa mà không phát sinh giới hạn hoặc hạn ngạch trên Google BigQuery. Nó thực hiện các bước sau:
- Chạy song song tác vụ di chuyển AWS Glue cho từng bảng.
- Theo dõi trạng thái chạy trong bảng DynamoDB.
- Sau khi các bảng đã được di chuyển, hãy kiểm tra lỗi và thoát.
- Dữ liệu được xuất từ Google BigQuery được lưu vào Amazon S3. Chúng tôi sử dụng Amazon S3 (mặc dù các tác vụ AWS Glue có thể ghi trực tiếp vào bảng Amazon Redshift) vì một vài lý do cụ thể:
- Chúng ta có thể tách riêng các bước di chuyển dữ liệu và tải dữ liệu.
- Nó cung cấp nhiều quyền kiểm soát hơn đối với các bước tải, với khả năng tải lại dữ liệu hoặc tạm dừng quá trình.
- Nó cung cấp khả năng giám sát chi tiết về trạng thái tải của Amazon Redshift.
- Sản phẩm Khung tải tự động tùy chỉnh tự động tạo các lược đồ và bảng trong cơ sở dữ liệu đích và liên tục tải dữ liệu từ Amazon S3 sang Amazon Redshift.
Một vài điểm bổ sung cần lưu ý:
- Nếu bạn đã tạo các bảng và lược đồ đích trong cơ sở dữ liệu Amazon Redshift, thì bạn có thể định cấu hình Khung trình tải tự động tùy chỉnh để không tự động phát hiện và chuyển đổi lược đồ.
- Nếu muốn kiểm soát nhiều hơn đối với việc chuyển đổi lược đồ Google BigQuery, bạn có thể sử dụng Công cụ chuyển đổi giản đồ AWS (AWS Thuế TTĐB). Để biết thêm thông tin, hãy tham khảo Di chuyển Google BigQuery sang Amazon Redshift bằng công cụ Chuyển đổi lược đồ AWS (SCT).
- Tại thời điểm viết bài này, AWS SCT cũng như Khung trình tải tự động tùy chỉnh đều không hỗ trợ chuyển đổi các loại dữ liệu lồng nhau (bản ghi, mảng và cấu trúc). Amazon Redshift hỗ trợ dữ liệu bán cấu trúc bằng cách sử dụng loại siêu dữ liệu, vì vậy nếu bảng của bạn sử dụng các loại dữ liệu phức tạp như vậy thì bạn cần phải tạo các bảng đích theo cách thủ công.
Để triển khai giải pháp, có hai bước chính:
- Triển khai ngăn xếp giải pháp bằng cách sử dụng Hình thành đám mây AWS.
- Triển khai và định cấu hình Khung trình tải tự động tùy chỉnh để tải tệp từ Amazon S3 sang Amazon Redshift.
Điều kiện tiên quyết
Trước khi bắt đầu, hãy chắc chắn rằng bạn có những điều sau đây:
- Tài khoản trong Google Cloud, cụ thể là tài khoản dịch vụ có quyền đối với Google BigQuery.
- Một tài khoản AWS với một Quản lý truy cập và nhận dạng AWS (IAM) người dùng có khóa truy cập và khóa bí mật để định cấu hình Giao diện dòng lệnh AWS (AWS CLI). Người dùng IAM cũng cần có quyền để tạo vai trò và chính sách IAM.
- Một cụm Amazon Redshift hoặc Nhóm làm việc Amazon Redshift Serverless. Nếu bạn chưa có, hãy tham khảo Amazon Redshift không có máy chủ.
- Một thùng S3. Nếu bạn không muốn sử dụng một trong các nhóm hiện có của mình, bạn có thể tạo một cái mới. Lưu ý tên của bộ chứa để sử dụng sau này khi bạn chuyển nó vào ngăn xếp CloudFormation làm tham số đầu vào.
- Một tệp cấu hình với danh sách các bảng sẽ được di chuyển. Tệp này phải có cấu trúc sau:
Ngoài ra, bạn có thể tải về tập tin demo, sử dụng tập dữ liệu mở được tạo bởi Trung tâm Dịch vụ Medicare & Medicaid.
Trong ví dụ này, chúng tôi đặt tên cho tệp bq-mig-config.json
-
- Định cấu hình tài khoản Google của bạn.
- Tạo vai trò IAM cho AWS Glue (và ghi lại tên của vai trò IAM).
- Đăng ký và kích hoạt Google BigQuery Connector cho AWS Glue.
Triển khai giải pháp bằng AWS CloudFormation
Để triển khai ngăn xếp giải pháp bằng AWS CloudFormation, hãy hoàn thành các bước sau:
- Chọn Khởi chạy Stack:
![]()
Mẫu này cung cấp tài nguyên AWS trong us-east-1 Vùng đất. Nếu bạn muốn triển khai sang một Khu vực khác, hãy tải xuống mẫu bigquery-cft.yaml và khởi chạy thủ công: trên bảng điều khiển AWS CloudFormation, chọn Tạo ngăn xếp với tài nguyên mới và tải lên tệp mẫu mà bạn đã tải xuống.
Danh sách các tài nguyên được cung cấp như sau:
-
- Quy tắc EventBridge để khởi động máy trạng thái Step Functions khi tải tệp cấu hình lên.
- Máy trạng thái Step Functions chạy logic di chuyển. Sơ đồ sau minh họa máy trạng thái.
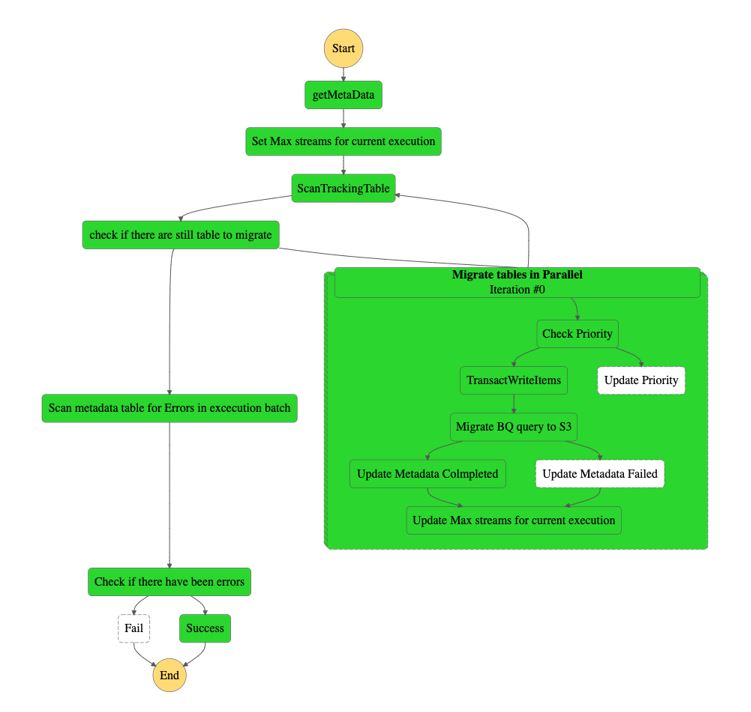
- Công việc shell AWS Glue Python được sử dụng để trích xuất siêu dữ liệu từ Google BigQuery. Siêu dữ liệu sẽ được lưu trữ trong bảng DynamoDB, với thuộc tính được tính toán để ưu tiên công việc di chuyển. Theo mặc định, trình kết nối tạo một phân vùng trên 400 MB trong bảng đang được đọc (trước khi lọc). Theo văn bản này, các API lưu trữ Google BigQuery có tối đa hạn ngạch cho các luồng đọc song song, vì vậy chúng tôi đặt giới hạn cho các nút worker đối với các bảng lớn hơn 400 GB. Chúng tôi cũng tính toán số lượng công việc tối đa có thể chạy song song dựa trên các giá trị đó.
- Công việc AWS Glue ETL được sử dụng để trích xuất dữ liệu từ mỗi bảng Google BigQuery và lưu dữ liệu đó trong Amazon S3 ở định dạng Parquet.
- Một bảng DynamoDB (
bq_to_s3_tracking) được sử dụng để lưu trữ siêu dữ liệu cho mỗi bảng được di chuyển (kích thước của bảng, đường dẫn S3 được sử dụng để lưu trữ dữ liệu được di chuyển và số lượng công nhân cần thiết để di chuyển bảng). - Một bảng DynamoDB (
bq_to_s3_maxstreams) được sử dụng để lưu trữ số lượng luồng tối đa trên mỗi lần chạy máy trạng thái. Điều này giúp chúng tôi giảm thiểu thất bại trong công việc do giới hạn hoặc hạn ngạch. Sử dụng mẫu Cloud Formation để tùy chỉnh tên của bảng DynamoDB. Tiền tố cho bảng DynamoDB làbq_to_s3. - Vai trò IAM cần thiết cho máy trạng thái và công việc AWS Glue.
- Chọn Sau.
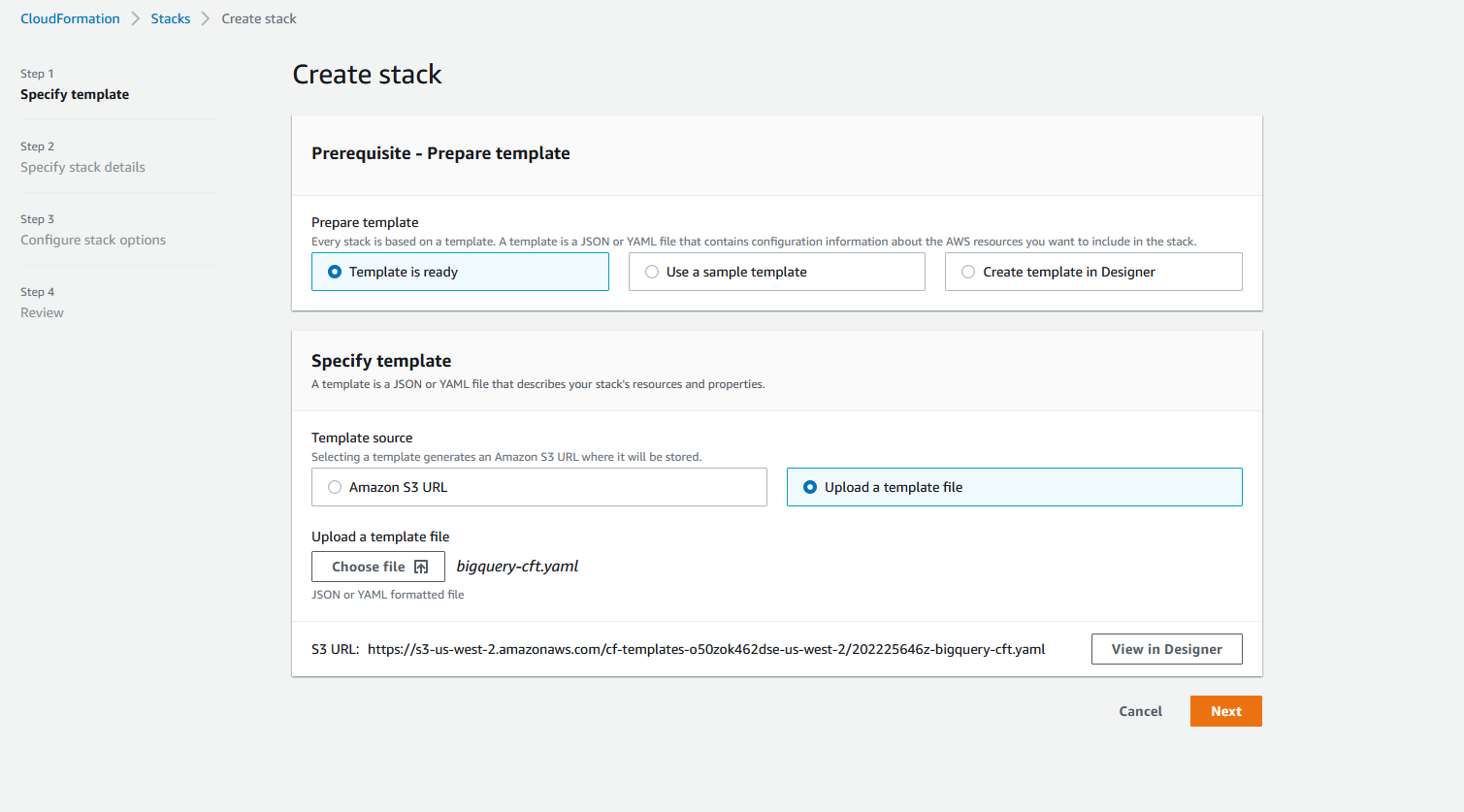
- Trong Tên ngăn xếp, nhập tên.
- Trong Thông số, nhập các tham số được liệt kê trong bảng sau, sau đó chọn Tạo.
| Tham số mẫu CloudFormation | Giá trị được phép | Mô tả |
InputBucketName |
Tên bộ chứa S3 |
Bộ chứa S3 nơi tác vụ AWS Glue lưu trữ dữ liệu đã di chuyển. Dữ liệu sẽ thực sự được lưu trữ trong một thư mục có tên |
InputConnectionName |
Tên kết nối AWS Glue, mặc định là glue-bq-connector-24 |
Tên của kết nối AWS Glue được tạo bằng trình kết nối Google BigQuery. |
InputDynamoDBTablePrefix |
Tiền tố tên bảng DynamoDB, mặc định là bq_to_s3 |
Tiền tố sẽ được sử dụng khi đặt tên cho hai bảng DynamoDB do giải pháp tạo ra. |
InputGlueETLJob |
Tên công việc AWS Glue ETL, mặc định là bq-migration-ETL |
Tên bạn muốn đặt cho công việc AWS Glue ETL. Tập lệnh thực tế được lưu trong đường dẫn S3 được chỉ định trong tham số InputGlueS3Path. |
InputGlueMetaJob |
AWS Glue Python shell tên công việc, mặc định là bq-get-metadata |
Tên bạn muốn đặt cho tác vụ AWS Glue Python shell. Tập lệnh thực tế được lưu trong đường dẫn S3 được chỉ định trong tham số InputGlueS3Path. |
InputGlueS3Path |
Đường dẫn S3, mặc định là s3://aws-glue-scripts-${AWS::Account}-${AWS::Region}/admin/ |
Đây là đường dẫn S3 trong đó ngăn xếp sẽ sao chép tập lệnh cho các công việc AWS Glue. Nhớ thay: ${AWS::Account} với ID tài khoản AWS thực tế và ${AWS::Region} với Khu vực bạn định sử dụng hoặc cung cấp nhóm và tiền tố của riêng bạn trong một đường dẫn hoàn chỉnh. |
InputMaxParallelism |
Số lượng công việc di chuyển song song để chạy, mặc định là 30 | Số lượng bảng tối đa mà bạn muốn di chuyển đồng thời. |
InputBQSecret |
Tên bí mật AWS Secrets Manager | Tên bí mật AWS Secrets Manager mà bạn đã lưu trữ thông tin đăng nhập Google BigQuery. |
InputBQProjectName |
Tên dự án Google BigQuery | Tên dự án của bạn trong Google BigQuery mà bạn muốn lưu trữ các bảng tạm thời; bạn sẽ cần quyền ghi trên dự án. |
StateMachineName |
Bước Chức năng nêu tên máy, mặc định là
|
Tên của máy trạng thái Step Functions. |
SourceS3BucketName |
Tên bộ chứa S3, mặc định là aws-blogs-artifacts-public |
Bộ chứa S3 nơi lưu trữ các thành phần lạ cho bài đăng này. Không thay đổi mặc định. |
Triển khai và định cấu hình Khung trình tải tự động tùy chỉnh để tải tệp từ Amazon S3 sang Amazon Redshift
Tiện ích Custom Auto Loader Framework giúp việc nhập dữ liệu vào Amazon Redshift trở nên đơn giản hơn và tự động tải các tệp dữ liệu từ Amazon S3 sang Amazon Redshift. Các tệp được ánh xạ tới các bảng tương ứng bằng cách thả tệp vào các vị trí được cấu hình sẵn trên Amazon S3. Để biết thêm chi tiết về kiến trúc và quy trình làm việc nội bộ, hãy tham khảo Khung tải tự động tùy chỉnh.
Để thiết lập Khung trình tải tự động tùy chỉnh, hãy hoàn thành các bước sau:
- Chọn Khởi chạy Stack để triển khai ngăn xếp CloudFormation trong
us-east-1Khu vực:
![]()
- Trên bảng điều khiển AWS CloudFormation, hãy chọn Sau.
- Cung cấp các tham số sau để giúp đảm bảo tạo tài nguyên thành công. Đảm bảo rằng bạn đã thu thập các giá trị này trước đó.
| Tên tham số | Giá trị được phép | Mô tả |
|---|---|---|
CopyCommandSchedule |
cron(0/5 * ? * * *) |
Quy tắc EventBridge KickoffFileProcessingSchedule và QueueRSProcessingSchedule được kích hoạt dựa trên lịch trình này. Mặc định là 5 phút. |
DatabaseName |
dev |
Tên cơ sở dữ liệu Amazon Redshift. |
DatabaseSchemaName |
public |
Tên lược đồ Amazon Redshift. |
DatabaseUserName |
demo |
Tên người dùng Amazon Redshift có quyền truy cập để chạy các lệnh SAO CHÉP trên lược đồ và cơ sở dữ liệu Amazon Redshift. |
RedshiftClusterIdentifier |
democluster |
Tên cụm Amazon Redshift. |
RedshiftIAMRoleARN |
arn:aws:iam::7000000000:role/RedshiftDemoRole |
Vai trò đính kèm của cụm Amazon Redshift có quyền truy cập vào bộ chứa S3. Vai trò này được sử dụng trong lệnh COPY. |
SourceS3Bucket |
Your-bucket-name |
Bộ chứa S3 chứa dữ liệu. Sử dụng cùng một bộ chứa mà bạn đã sử dụng để lưu trữ dữ liệu đã di chuyển như được chỉ ra trong ngăn xếp trước đó. |
CopyCommandOptions |
delimiter '|' gzip |
Cung cấp các tham số định dạng dữ liệu lệnh COPY bổ sung như sau:
|
InitiateSchemaDetection |
Yes |
Cài đặt để tự động phát hiện lược đồ trước khi tải tệp lên. |
Ảnh chụp màn hình sau đây cho thấy một ví dụ về các thông số của chúng tôi.
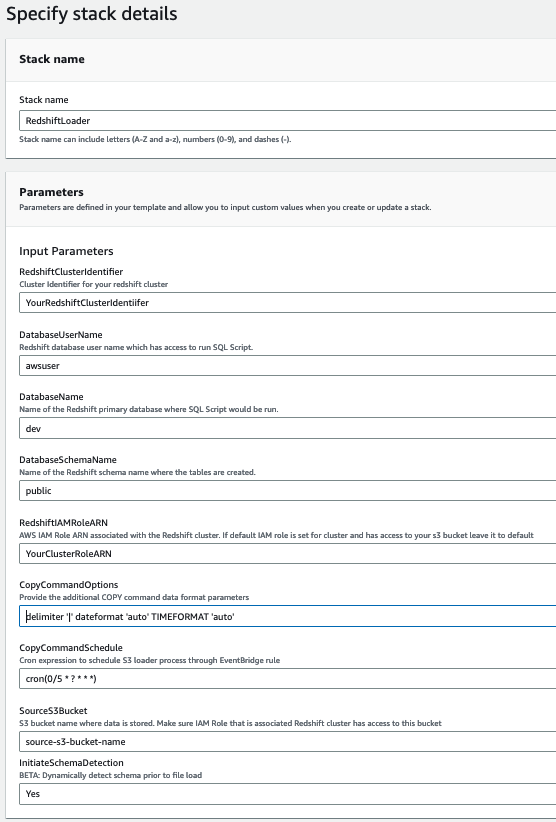
- Chọn Tạo.
- Theo dõi tiến trình tạo Stack và đợi cho đến khi hoàn tất.
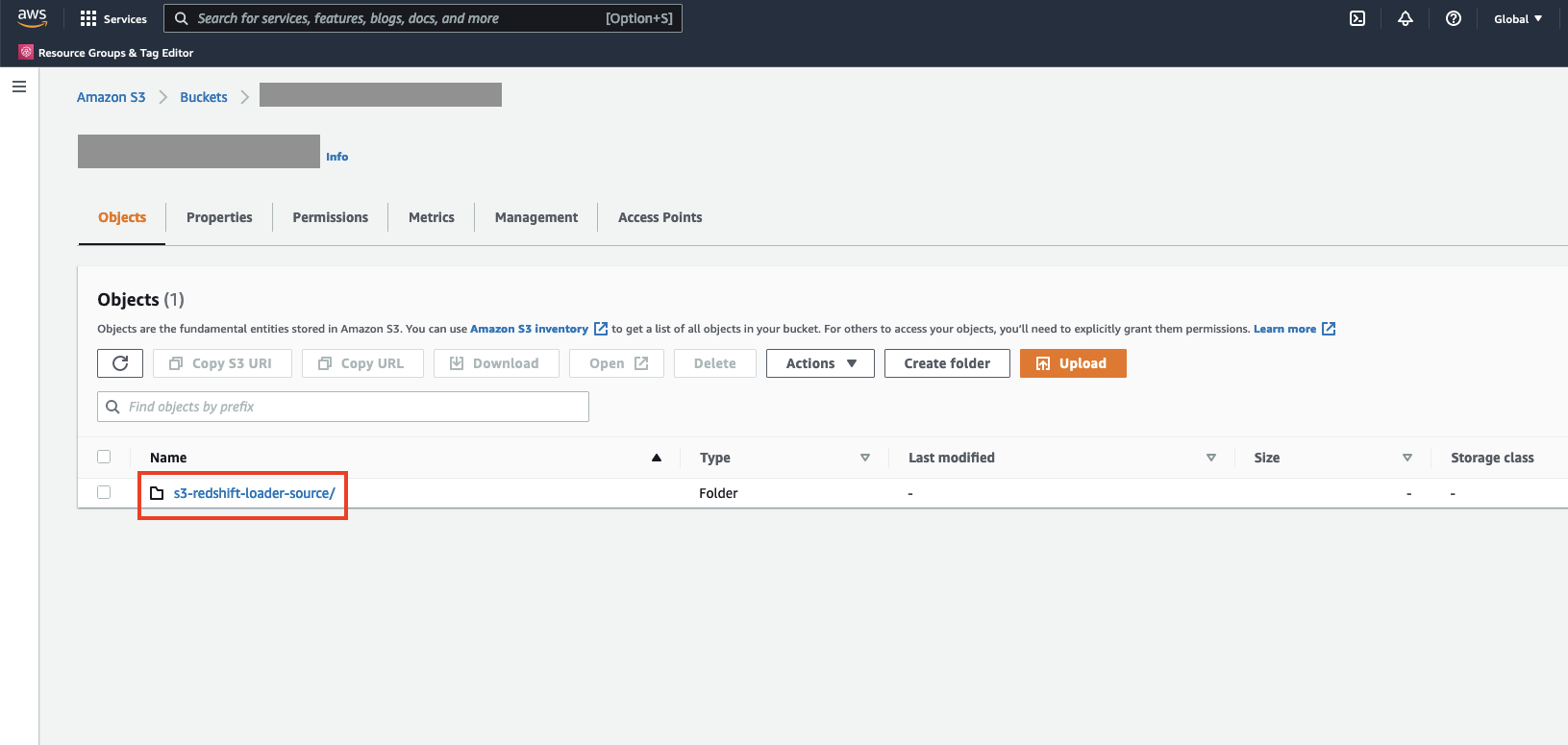
- Để xác minh cấu hình Custom Auto Loader Framework, hãy đăng nhập vào Bảng điều khiển Amazon S3 và điều hướng đến bộ chứa S3 mà bạn đã cung cấp làm giá trị cho
SourceS3Buckettham số.
Bạn sẽ thấy một thư mục mới có tên s3-redshift-loader-source được tạo ra.
Kiểm tra giải pháp
Để kiểm tra giải pháp, hãy hoàn thành các bước sau:
- Tạo tệp cấu hình dựa trên các điều kiện tiên quyết. Bạn cũng có thể tải về tập tin demo.
- Để thiết lập bộ chứa S3, trên bảng điều khiển Amazon S3, hãy điều hướng đến thư mục
bq-mig-configtrong thùng bạn đã cung cấp trong ngăn xếp. - Upload file config vào đó.
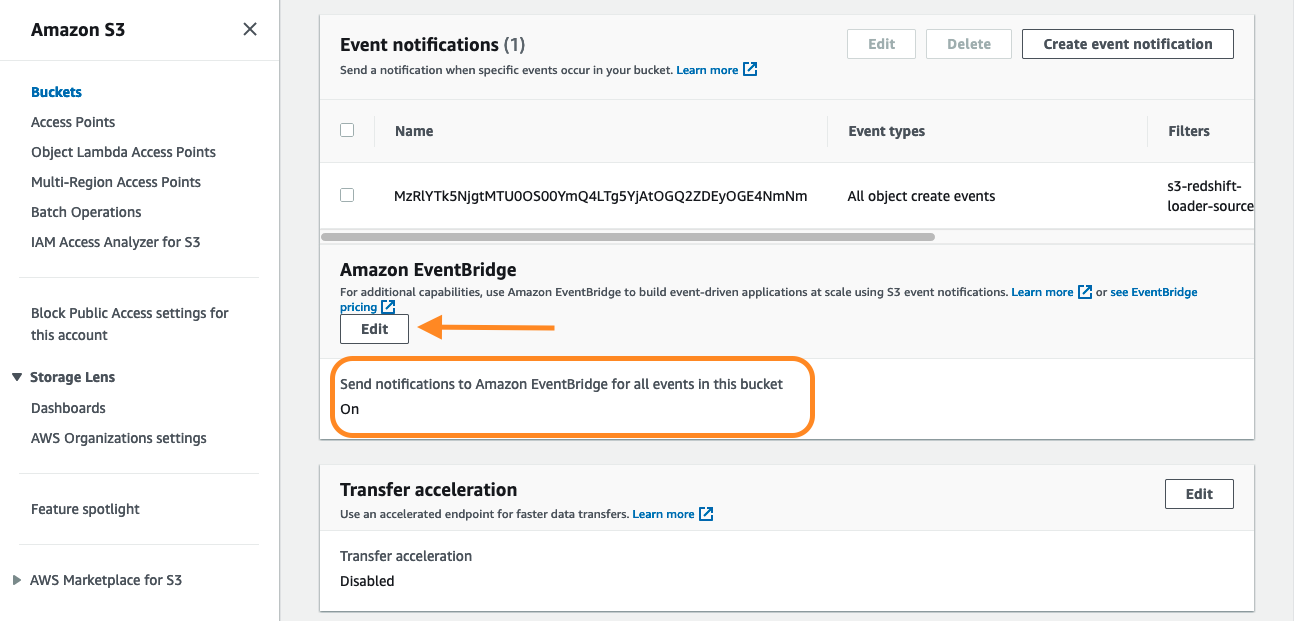
- Để bật thông báo EventBridge cho bộ chứa, hãy mở bộ chứa trên bảng điều khiển và trên Bất động sản tab, định vị Thông báo sự kiện.
- Trong tạp chí Sự kiện Amazon phần, chọn Chỉnh sửa.
- Chọn On, sau đó chọn Lưu các thay đổi.
- Trên bảng điều khiển AWS Step Function, theo dõi hoạt động của máy trạng thái.
- Theo dõi trạng thái tải trong Amazon Redshift. Để biết hướng dẫn, hãy tham khảo Xem tải hiện tại.
- Mở Amazon Redshift Query Editor V2 và truy vấn dữ liệu của bạn.
cân nhắc về giá
Bạn có thể phải trả phí đầu ra khi di chuyển dữ liệu từ Google BigQuery sang Amazon S3. Xem xét và tính toán chi phí di chuyển dữ liệu của bạn trên bảng điều khiển thanh toán trên đám mây của Google. Tại thời điểm viết bài này, AWS Glue 3.0 trở lên tính phí 0.44 USD mỗi giờ DPU, tính phí mỗi giây, với tối thiểu 1 phút cho các công việc Spark ETL. Để biết thêm thông tin, xem Giá keo AWS. Với tự động mở rộng được bật, AWS Glue sẽ tự động thêm và xóa nhân viên khỏi cụm tùy thuộc vào tính song song ở từng giai đoạn hoặc vi lô của quá trình chạy công việc.
Làm sạch
Để tránh phát sinh phí trong tương lai, hãy dọn sạch tài nguyên của bạn:
- Xóa ngăn xếp giải pháp CloudFormation.
- Xóa ngăn xếp Khung tải tự động tùy chỉnh của CloudFormation.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách xây dựng đường dẫn dữ liệu tự động và có thể mở rộng để di chuyển dữ liệu của bạn từ Google BigQuery sang Amazon Redshift. Chúng tôi cũng nêu bật cách khung Trình tải tự động tùy chỉnh có thể tự động phát hiện giản đồ, tạo bảng cho các tệp S3 của bạn và liên tục tải các tệp vào kho Amazon Redshift của bạn. Với phương pháp này, bạn có thể tự động hóa quá trình di chuyển toàn bộ dự án (thậm chí nhiều dự án cùng lúc) trong Google BigQuery sang Amazon Redshift. Điều này giúp cải thiện đáng kể thời gian di chuyển dữ liệu vào Amazon Redshift thông qua quá trình song song hóa di chuyển bảng tự động.
Tính năng tự động sao chép trong Amazon Redshift đơn giản hóa việc tải dữ liệu tự động từ Amazon S3 bằng một lệnh SQL đơn giản, người dùng có thể dễ dàng tự động hóa việc nhập dữ liệu từ Amazon S3 sang Amazon Redshift bằng Amazon Redshift tính năng xem trước bản sao tự động
Để biết thêm thông tin về hiệu suất của Google BigQuery Connector cho AWS Glue, hãy tham khảo Di chuyển hàng terabyte dữ liệu một cách nhanh chóng từ Google Cloud sang Amazon S3 với AWS Glue Connector cho Google BigQuery và tìm hiểu cách di chuyển một lượng lớn dữ liệu (1.9 TB) vào Amazon S3 một cách nhanh chóng (khoảng 8 phút).
Để tìm hiểu thêm về các công việc AWS Glue ETL, hãy xem Đơn giản hóa quy trình truyền dẫn dữ liệu với quy trình tạo mã tự động và quy trình làm việc của AWS Glue và Giúp ETL dễ dàng hơn với AWS Glue Studio.
Về các tác giả
 Tahir Aziz là Kiến trúc sư giải pháp phân tích tại AWS. Ông đã làm việc với việc xây dựng kho dữ liệu và các giải pháp dữ liệu lớn trong hơn 13 năm. Anh ấy thích giúp khách hàng thiết kế các giải pháp phân tích end-to-end trên AWS. Ngoài công việc, anh ấy thích đi du lịch và nấu ăn.
Tahir Aziz là Kiến trúc sư giải pháp phân tích tại AWS. Ông đã làm việc với việc xây dựng kho dữ liệu và các giải pháp dữ liệu lớn trong hơn 13 năm. Anh ấy thích giúp khách hàng thiết kế các giải pháp phân tích end-to-end trên AWS. Ngoài công việc, anh ấy thích đi du lịch và nấu ăn.
 Ritesh Kumar Sinha là Kiến trúc sư giải pháp chuyên gia phân tích có trụ sở tại San Francisco. Ông đã giúp khách hàng xây dựng các giải pháp dữ liệu lớn và kho dữ liệu có thể mở rộng trong hơn 16 năm. Anh ấy thích thiết kế và xây dựng các giải pháp đầu cuối hiệu quả trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách, đi bộ và tập yoga.
Ritesh Kumar Sinha là Kiến trúc sư giải pháp chuyên gia phân tích có trụ sở tại San Francisco. Ông đã giúp khách hàng xây dựng các giải pháp dữ liệu lớn và kho dữ liệu có thể mở rộng trong hơn 16 năm. Anh ấy thích thiết kế và xây dựng các giải pháp đầu cuối hiệu quả trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách, đi bộ và tập yoga.
 Fabrizio Napolitano là Kiến trúc sư giải pháp chuyên gia chính cho DB và Analytics. Anh ấy đã làm việc trong lĩnh vực phân tích trong 20 năm qua và gần đây đã trở thành một người cha khúc côn cầu sau khi chuyển đến Canada một cách khá bất ngờ.
Fabrizio Napolitano là Kiến trúc sư giải pháp chuyên gia chính cho DB và Analytics. Anh ấy đã làm việc trong lĩnh vực phân tích trong 20 năm qua và gần đây đã trở thành một người cha khúc côn cầu sau khi chuyển đến Canada một cách khá bất ngờ.
 Manjula Nagineni là Kiến trúc sư giải pháp cấp cao của AWS có trụ sở tại New York. Cô làm việc với các tổ chức dịch vụ tài chính lớn, kiến trúc và hiện đại hóa các ứng dụng quy mô lớn của họ đồng thời áp dụng các dịch vụ Đám mây AWS. Cô ấy đam mê thiết kế khối lượng công việc dữ liệu lớn trên nền tảng đám mây. Cô có hơn 20 năm kinh nghiệm CNTT trong phát triển phần mềm, phân tích và kiến trúc trên nhiều lĩnh vực như tài chính, bán lẻ và viễn thông.
Manjula Nagineni là Kiến trúc sư giải pháp cấp cao của AWS có trụ sở tại New York. Cô làm việc với các tổ chức dịch vụ tài chính lớn, kiến trúc và hiện đại hóa các ứng dụng quy mô lớn của họ đồng thời áp dụng các dịch vụ Đám mây AWS. Cô ấy đam mê thiết kế khối lượng công việc dữ liệu lớn trên nền tảng đám mây. Cô có hơn 20 năm kinh nghiệm CNTT trong phát triển phần mềm, phân tích và kiến trúc trên nhiều lĩnh vực như tài chính, bán lẻ và viễn thông.
 Sohaib Katariwala là Kiến trúc sư giải pháp chuyên gia phân tích tại AWS. Ông có hơn 12 năm kinh nghiệm giúp các tổ chức rút ra những hiểu biết sâu sắc từ dữ liệu của họ.
Sohaib Katariwala là Kiến trúc sư giải pháp chuyên gia phân tích tại AWS. Ông có hơn 12 năm kinh nghiệm giúp các tổ chức rút ra những hiểu biết sâu sắc từ dữ liệu của họ.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/migrate-from-google-bigquery-to-amazon-redshift-using-aws-glue-and-custom-auto-loader-framework/

