تعارف
کمپیوٹر ویژن میں، لائیو آبجیکٹ کا پتہ لگانے کی مختلف تکنیکیں موجود ہیں، بشمول تیز R-CNN، ایس ایس ڈی، اور Yolo کی. ہر تکنیک کی اپنی حدود اور فوائد ہیں۔ اگرچہ تیز تر R-CNN درستگی میں سبقت لے سکتا ہے، لیکن یہ حقیقی وقت کے منظرناموں میں اچھی کارکردگی نہیں دکھا سکتا، جس سے YOLO الگورتھم۔
کمپیوٹر وژن میں آبجیکٹ کا پتہ لگانا بنیادی چیز ہے، جو مشینوں کو فریم یا اسکرین کے اندر اشیاء کی شناخت اور ان کا پتہ لگانے کے قابل بناتی ہے۔ سالوں کے دوران، مختلف آبجیکٹ کا پتہ لگانے والے الگورتھم تیار کیے گئے ہیں، جس میں YOLO سب سے کامیاب کے طور پر ابھر رہا ہے۔ حال ہی میں، YOLOv8 متعارف کرایا گیا ہے، جو الگورتھم کی صلاحیتوں کو مزید بڑھاتا ہے۔
اس جامع گائیڈ میں، ہم آبجیکٹ کا پتہ لگانے کے تین نمایاں الگورتھم دریافت کرتے ہیں: تیز R-CNN، SSD (سنگل شاٹ ملٹی باکس ڈیٹیکٹر)، اور YOLOv8۔ ہم ان الگورتھم کو لاگو کرنے کے عملی پہلوؤں پر تبادلہ خیال کرتے ہیں، بشمول ایک ورچوئل ماحول قائم کرنا اور ایک Streamlit ایپلیکیشن تیار کرنا۔
سیکھنے کا مقصد
- تیز تر R-CNN، SSD، اور YOLO کو سمجھیں، اور ان کے درمیان فرق کا تجزیہ کریں۔
- OpenCV، نگرانی، اور YOLOv8 کا استعمال کرتے ہوئے لائیو آبجیکٹ کا پتہ لگانے کے نظام کو نافذ کرنے میں عملی تجربہ حاصل کریں۔
- روبوفلو تشریح کا استعمال کرتے ہوئے امیج سیگمنٹیشن ماڈل کو سمجھنا۔
- آسان یوزر انٹرفیس کے لیے اسٹریم لِٹ ایپلیکیشن بنائیں۔
آئیے دریافت کریں کہ YOLOv8 کے ساتھ تصویر کی تقسیم کیسے کی جائے!
فہرست
اس مضمون کے ایک حصے کے طور پر شائع کیا گیا تھا۔ ڈیٹا سائنس بلاگتھون۔
تیز تر R-CNN
تیز R-CNN (تیز ریجن پر مبنی Convolutional Neural Network) ایک گہری سیکھنے پر مبنی آبجیکٹ کا پتہ لگانے والا الگورتھم ہے۔ اس کا اندازہ R-CNN اور Fast R-CNN فریم ورک کا استعمال کرتے ہوئے کیا جاتا ہے اور اسے فاسٹ R-CNN کی توسیع سمجھا جا سکتا ہے۔
یہ الگورتھم ریجن پروپوزل نیٹ ورک (RPN) کو متعارف کراتا ہے تاکہ R-CNN میں استعمال ہونے والی منتخب تلاش کی جگہ لے کر علاقائی تجاویز تیار کی جا سکے۔ RPN پتہ لگانے والے نیٹ ورک کے ساتھ convolutional تہوں کا اشتراک کرتا ہے، جس سے آخر سے آخر تک موثر تربیت کی اجازت دی جاتی ہے۔
اس کے بعد تیار کردہ ریجن کی تجاویز کو باؤنڈنگ باکس ریفائنمنٹ اور آبجیکٹ کی درجہ بندی کے لیے فاسٹ R-CNN نیٹ ورک میں فیڈ کیا جاتا ہے۔
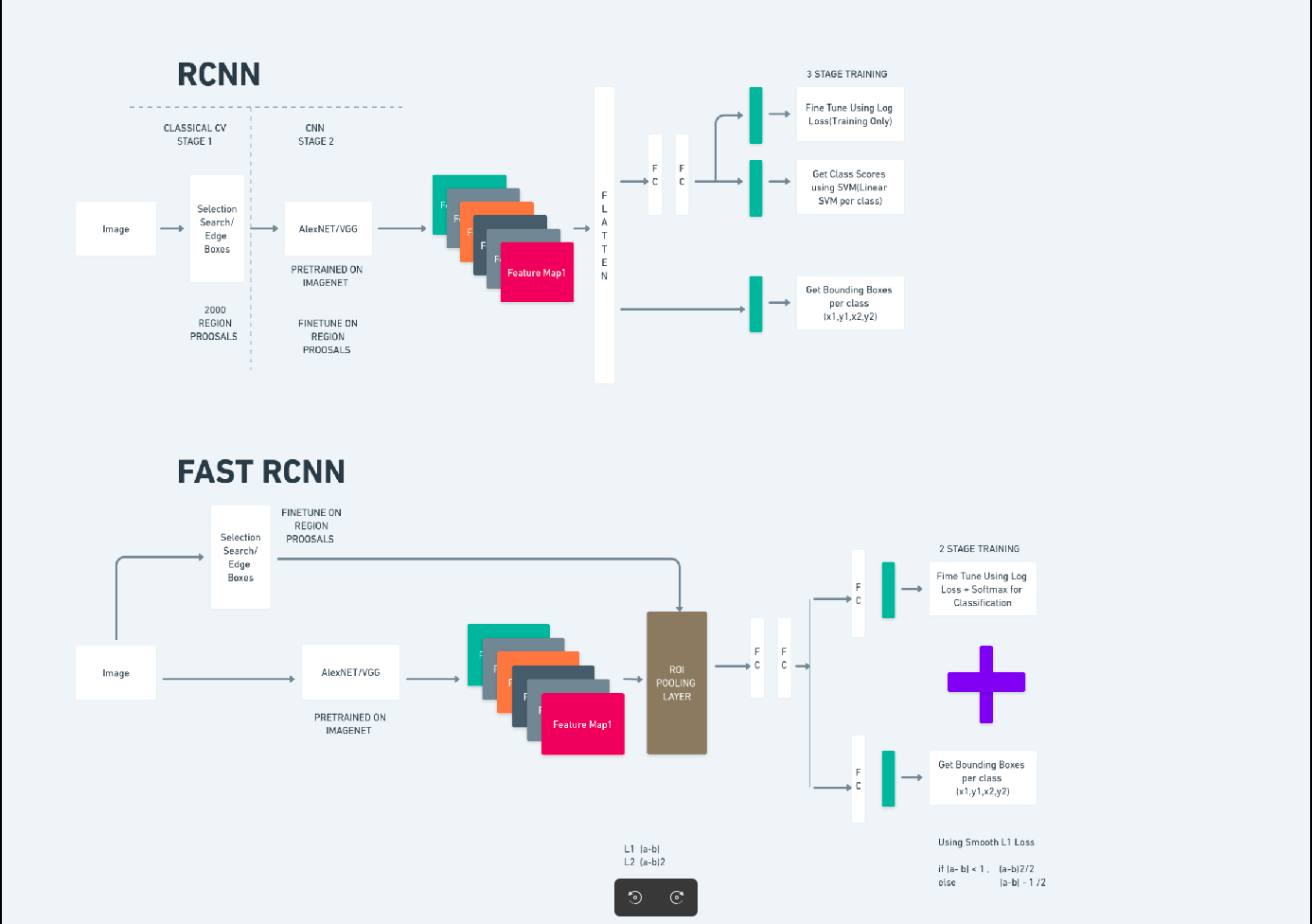
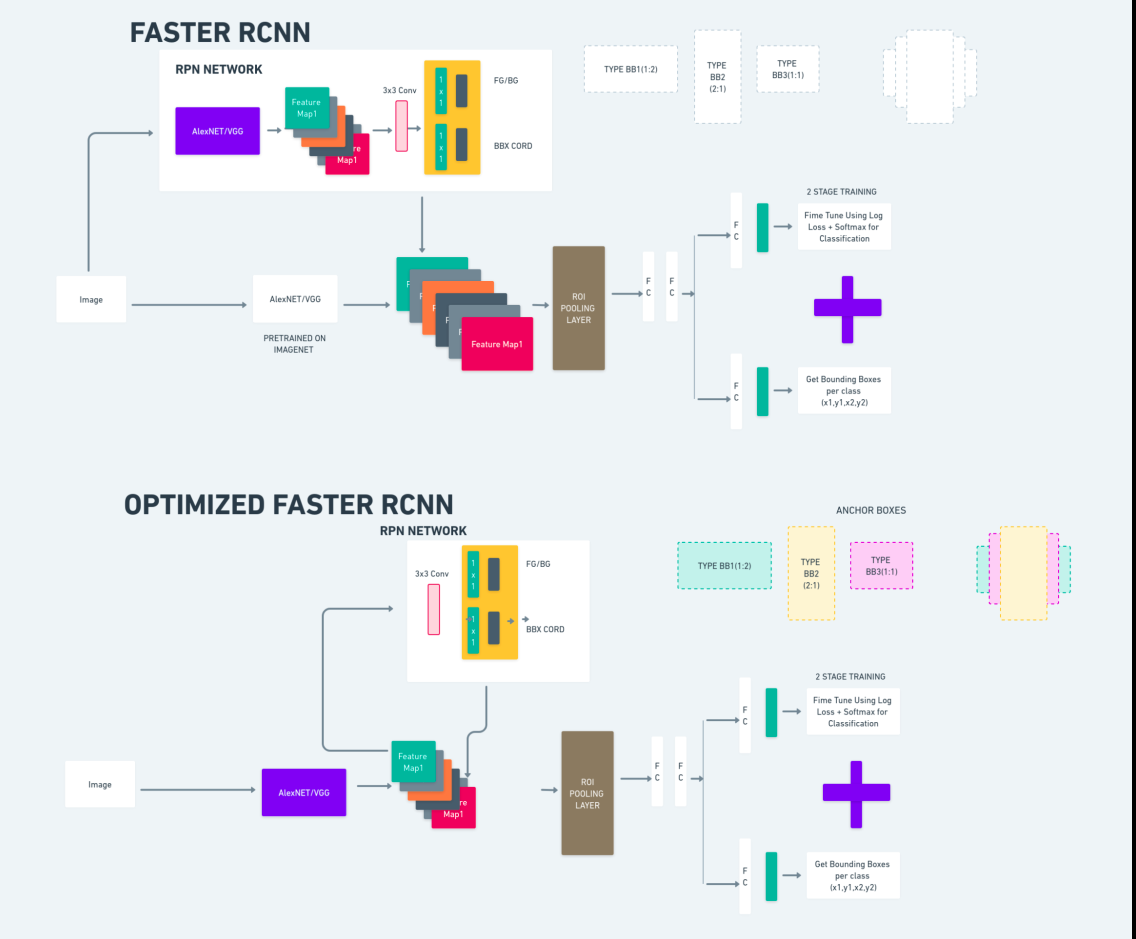
اوپر دیا گیا خاکہ تیز R-CNN فیملی کو جامع طور پر واضح کرتا ہے اور ہر الگورتھم کا جائزہ لینے کے لیے اسے سمجھنا آسان ہے۔
سنگل شاٹ ملٹی باکس ڈٹیکٹر (SSD)
۔ سنگل شاٹ ملٹی باکس ڈیٹیکٹر (SSD) آبجیکٹ کا پتہ لگانے میں مقبول ہے اور بنیادی طور پر کمپیوٹر وژن کے کاموں میں استعمال ہوتا ہے۔ پچھلے طریقہ میں، تیز R-CNN، ہم نے دو مراحل کی پیروی کی: پہلے مرحلے میں پتہ لگانے کا حصہ اور دوسرے میں رجعت شامل تھی۔ تاہم، SSD کے ساتھ، ہم صرف ایک پتہ لگانے کا مرحلہ انجام دیتے ہیں۔ ایس ایس ڈی کو 2016 میں ایک تیز اور درست آبجیکٹ کا پتہ لگانے کے ماڈل کی ضرورت کو پورا کرنے کے لیے متعارف کرایا گیا تھا۔

ایس ایس ڈی کے پہلے آبجیکٹ کا پتہ لگانے کے طریقوں جیسے تیز R-CNN پر کئی فوائد ہیں:
- کارکردگی: SSD ایک سنگل سٹیج کا پتہ لگانے والا ہے، یعنی یہ براہ راست باؤنڈنگ بکس اور کلاس سکور کی پیش گوئی کرتا ہے بغیر کسی علیحدہ پروپوزل جنریشن سٹیپ کی ضرورت کے۔ یہ تیز تر R-CNN جیسے دو مرحلے کے پتہ لگانے والوں کے مقابلے میں تیز تر بناتا ہے۔
- اینڈ ٹو اینڈ ٹریننگ: ایس ایس ڈی کو آخر سے آخر تک تربیت دی جا سکتی ہے، بیس نیٹ ورک اور ڈیٹیکشن ہیڈ دونوں کو مشترکہ طور پر بہتر بناتے ہوئے، جو تربیت کے عمل کو آسان بناتا ہے۔
- ملٹی اسکیل فیچر فیوژن: ایس ایس ڈی فیچر میپس پر ایک سے زیادہ پیمانے پر کام کرتا ہے، جس سے یہ مختلف سائز کی اشیاء کو زیادہ مؤثر طریقے سے تلاش کر سکتا ہے۔
SSD رفتار اور درستگی کے درمیان ایک اچھا توازن رکھتا ہے، جس سے یہ ریئل ٹائم ایپلی کیشنز کے لیے موزوں ہوتا ہے جہاں کارکردگی اور کارکردگی دونوں اہم ہیں۔
آپ صرف ایک بار دیکھیں (YOLOv8)
2015 میں، You Only Look One (YOLO) کو جوزف ریڈمون، سنتوش ڈیوالا، راس گرشک، اور علی فرہادی کے ایک تحقیقی مقالے میں آبجیکٹ کا پتہ لگانے والے الگورتھم کے طور پر متعارف کرایا گیا تھا۔ YOLO ایک سنگل شاٹ الگورتھم ہے جو ایک ہی پاس میں کسی شے کی براہ راست درجہ بندی کرتا ہے جس میں صرف ایک نیورل نیٹ ورک کی پیشن گوئی باؤنڈنگ باکسز اور کلاس کے امکانات کو بطور ان پٹ استعمال کرتے ہوئے مکمل تصویر کا استعمال ہوتا ہے۔
اب، آئیے YOLOv8 کو بہتر درستگی اور رفتار کے ساتھ ریئل ٹائم آبجیکٹ کا پتہ لگانے میں جدید ترین پیشرفت کے طور پر سمجھتے ہیں۔ YOLOv8 آپ کو پہلے سے تربیت یافتہ ماڈلز کا فائدہ اٹھانے کی اجازت دیتا ہے، جو پہلے ہی ایک وسیع ڈیٹا سیٹ جیسے COCO (Common Objects in Context) پر تربیت یافتہ ہیں۔ تصویری تقسیم ہر شے کے بارے میں پکسل کی سطح کی معلومات فراہم کرتی ہے، جس سے تصویری مواد کی مزید تفصیلی تجزیہ اور تفہیم ممکن ہوتی ہے۔
اگرچہ امیج سیگمنٹیشن کمپیوٹیشنل طور پر مہنگا ہو سکتا ہے، YOLOv8 اس طریقہ کو اپنے نیورل نیٹ ورک فن تعمیر میں ضم کرتا ہے، جس سے موثر اور درست آبجیکٹ سیگمنٹیشن کی اجازت دی جا سکتی ہے۔
YOLOv8 کے کام کرنے کا اصول
YOLOv8 پہلے ان پٹ امیج کو گرڈ سیلز میں تقسیم کرکے کام کرتا ہے۔ ان گرڈ سیلز کا استعمال کرتے ہوئے، YOLOv8 کلاس کے امکانات کے ساتھ باؤنڈنگ بکس (bbox) کی پیش گوئی کرتا ہے۔
اس کے بعد، YOLOv8 اوور لیپنگ کو کم کرنے کے لیے NMS الگورتھم کا استعمال کرتا ہے۔ مثال کے طور پر، اگر تصویر میں ایک سے زیادہ کاریں موجود ہیں جس کے نتیجے میں اوورلیپنگ باؤنڈنگ باکسز ہوتے ہیں، تو NMS الگورتھم اس اوورلیپ کو کم کرنے میں مدد کرتا ہے۔
Yolo V8 کی مختلف حالتوں کے درمیان فرق: YOLOv8 تین قسموں میں دستیاب ہے: YOLOv8، YOLOv8-L، اور YOLOv8-X۔ مختلف حالتوں کے درمیان بنیادی فرق بیک بون نیٹ ورک کا سائز ہے۔ YOLOv8 میں ریڑھ کی ہڈی کا سب سے چھوٹا نیٹ ورک ہے، جبکہ YOLOv8-X کے پاس ریڑھ کی ہڈی کا سب سے بڑا نیٹ ورک ہے۔
فرق تیز تر R-CNN، SSD، اور YOLO کے درمیان
| پہلو | تیز تر R-CNN | ایس ایس ڈی | Yolo کی |
|---|---|---|---|
| آرکیٹیکچر | RPN اور فاسٹ R-CNN کے ساتھ دو مرحلے کا پتہ لگانے والا | سنگل اسٹیج کا پتہ لگانے والا | سنگل اسٹیج کا پتہ لگانے والا |
| ریجن کی تجاویز | جی ہاں | نہیں | نہیں |
| پتہ لگانے کی رفتار | SSD اور YOLO کے مقابلے میں سست | تیز R-CNN کے مقابلے میں تیز، YOLO سے سست | بہت تیز |
| درستگی | عام طور پر زیادہ درستگی | متوازن درستگی اور رفتار | مہذب درستگی، خاص طور پر ریئل ٹائم ایپلی کیشنز کے لیے |
| لچک | لچکدار، مختلف آبجیکٹ کے سائز اور پہلو کے تناسب کو سنبھال سکتا ہے۔ | اشیاء کے ایک سے زیادہ ترازو کو سنبھال سکتا ہے۔ | چھوٹی اشیاء کے درست لوکلائزیشن کے ساتھ جدوجہد کر سکتے ہیں۔ |
| متحد کھوج | نہیں | نہیں | جی ہاں |
| رفتار بمقابلہ درستگی ٹریڈ آف | عام طور پر درستگی کے لیے رفتار کی قربانی دیتا ہے۔ | رفتار اور درستگی کو متوازن کرتا ہے۔ | مہذب درستگی کو برقرار رکھتے ہوئے رفتار کو ترجیح دیتا ہے۔ |
Segmentation کیا ہے؟
جیسا کہ ہم جانتے ہیں کہ سیگمنٹیشن کا مطلب ہے کہ ہم کچھ خاص خصوصیات کی بنیاد پر بڑی تصویر کو چھوٹے گروپوں میں تقسیم کر رہے ہیں۔ آئیے امیج سیگمنٹیشن کو سمجھتے ہیں جو کہ کمپیوٹر ویژن تکنیک ہے جو ایک تصویر کو مختلف متعدد حصوں یا خطوں میں تقسیم کرنے کے لیے استعمال ہوتی ہے۔ جیسا کہ تصویریں پکسلز سے بنی ہیں اور امیج سیگمنٹیشن میں، رنگ، شدت، ساخت، یا دیگر بصری خصوصیات میں مماثلت کے مطابق پکسلز کو ایک ساتھ گروپ کیا گیا ہے۔
مثال کے طور پر، اگر کسی تصویر میں درخت، کاریں، یا لوگ شامل ہیں تو تصویر کی تقسیم تصویر کو مختلف طبقات میں تقسیم کرنے جا رہی ہے جو معنی خیز اشیاء یا تصویر کے حصوں کی نمائندگی کرتی ہیں۔ امیج سیگمنٹیشن مختلف شعبوں میں وسیع پیمانے پر استعمال ہوتی ہے جیسے میڈیکل امیجنگ، سیٹلائٹ امیج کا تجزیہ، کمپیوٹر ویژن میں آبجیکٹ کی شناخت، اور بہت کچھ۔

سیگمنٹیشن حصے میں، ہم ابتدائی طور پر روب فلو کا استعمال کرتے ہوئے پہلا YOLOv8 سیگمنٹیشن ماڈل بناتے ہیں۔ پھر، ہم سیگمنٹیشن کا کام انجام دینے کے لیے سیگمنٹیشن ماڈل درآمد کرتے ہیں۔ سوال یہ پیدا ہوتا ہے: جب کام کو اکیلے پتہ لگانے والے الگورتھم سے مکمل کیا جا سکتا ہے تو ہم سیگمنٹیشن ماڈل کیوں بناتے ہیں؟
سیگمنٹیشن ہمیں کلاس کی مکمل باڈی امیج حاصل کرنے کی اجازت دیتی ہے۔ اگرچہ کھوج لگانے والے الگورتھم اشیاء کی موجودگی کا پتہ لگانے پر توجہ مرکوز کرتے ہیں، لیکن تقسیم اشیاء کی صحیح حدود کو بیان کرکے زیادہ درست تفہیم فراہم کرتی ہے۔ یہ تصویر میں موجود اشیاء کی زیادہ درست لوکلائزیشن اور تفہیم کی طرف جاتا ہے۔
تاہم، سیگمنٹیشن میں عام طور پر پتہ لگانے والے الگورتھم کے مقابلے زیادہ وقت کی پیچیدگی شامل ہوتی ہے کیونکہ اس کے لیے اضافی اقدامات کی ضرورت ہوتی ہے جیسے تشریحات کو الگ کرنا اور ماڈل بنانا۔ اس خرابی کے باوجود، سیگمنٹیشن کی طرف سے پیش کی جانے والی بڑھتی ہوئی درستگی ان کاموں میں کمپیوٹیشنل لاگت سے کہیں زیادہ ہو سکتی ہے جہاں آبجیکٹ کی درست وضاحت بہت ضروری ہے۔
YOLOv8 کے ساتھ مرحلہ وار لائیو ڈیٹیکشن اور امیج سیگمنٹیشن
اس تصور میں ہم conda کا استعمال کرتے ہوئے ایک ورچوئل ماحول بنانے، venv کو چالو کرنے اور pip کا استعمال کرتے ہوئے ضروریات کے پیکجز کو انسٹال کرنے کے اقدامات کو تلاش کر رہے ہیں۔ پہلے عام python اسکرپٹ بناتے ہیں پھر ہم اسٹریملٹ ایپلیکیشن بناتے ہیں۔
مرحلہ 1: کونڈا کا استعمال کرتے ہوئے ایک ورچوئل ماحول بنائیں
conda create -p ./venv python=3.8 -yمرحلہ 2: ورچوئل ماحول کو فعال کریں۔
conda activate ./venv
مرحلہ 3: requirements.txt بنائیں
ٹرمینل کھولیں اور درج ذیل اسکرپٹ کو پیسٹ کریں:
touch requirements.txtمرحلہ 4: نینو کمانڈ استعمال کریں اور requirements.txt میں ترمیم کریں۔
Requiments.txt بنانے کے بعد requirements.txt میں ترمیم کرنے کے لیے درج ذیل کمانڈ کو استعمال کریں۔
nano requirements.txtمذکورہ اسکرپٹ کو چلانے کے بعد آپ یہ UI دیکھ سکتے ہیں۔
اس کے مطلوبہ پیکجز لکھیں۔
ultralytics==8.0.32
supervision==0.2.1
streamlitپھر دبائیں "ctrl+o"(یہ کمانڈ ایڈیٹنگ کا حصہ بچا رہی ہے) پھر دبائیں "درج کریں"
دبانے کے بعد "Ctrl+x"۔ آپ فائل سے باہر نکل سکتے ہیں۔ اور مرکزی راستے کی طرف جانا۔
مرحلہ 5: requirements.txt انسٹال کرنا
pip install -r requirements.txtمرحلہ 6: ازگر اسکرپٹ بنائیں
ٹرمینل میں درج ذیل اسکرپٹ لکھیں یا ہم کمانڈ کہہ سکتے ہیں۔
touch main.pymain.py بنانے کے بعد vs کوڈ کو کھولیں جس کو آپ ٹرمینل میں لکھنے کا کمانڈ استعمال کرتے ہیں،
code مرحلہ 7: ازگر کا اسکرپٹ لکھنا
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
اس کمانڈ کو چلانے کے بعد آپ دیکھ سکتے ہیں کہ آپ کا کیمرہ کھلا ہوا ہے اور آپ کے کچھ حصے کا پتہ لگا رہا ہے۔ جیسے جنس اور پس منظر کے حصے۔
مرحلہ 7: اسٹریملٹ ایپ بنائیں
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
اس اسکرپٹ میں، ہم اسٹریملٹ ایپلیکیشن بنا رہے ہیں اور بٹن بنا رہے ہیں تاکہ بٹن دبانے کے بعد آپ کی ڈیوائس کیمرہ کھل جائے اور فریم میں موجود حصے کا پتہ لگا سکے۔
اس کمانڈ کو استعمال کرکے اس اسکرپٹ کو چلائیں۔
streamlit run app.py
# first create the app.py then paste the above code and run this script.مندرجہ بالا کمانڈ کو چلانے کے بعد فرض کریں کہ آپ کو پہنچنے میں غلطی ہوئی ہے جیسے،
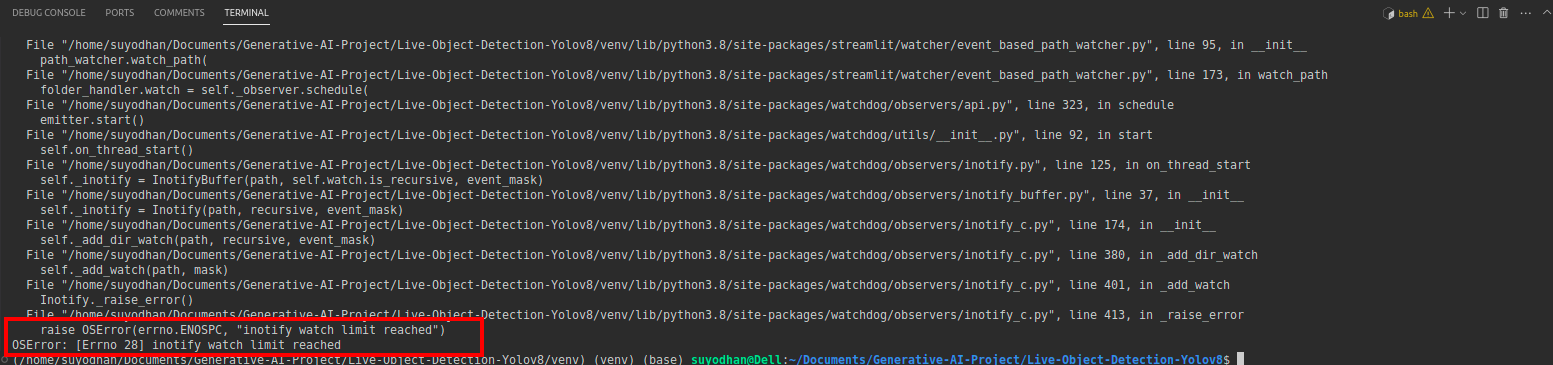
پھر اس کمانڈ کو دبائیں،
sudo sysctl fs.inotify.max_user_watches=524288کمانڈ کو مارنے کے بعد آپ اپنا پاس ورڈ لکھنا چاہتے ہیں کیونکہ ہم sudo کمانڈ استعمال کر رہے ہیں sudo is god :)
اسکرپٹ کو دوبارہ چلائیں۔ اور آپ اسٹریم لائٹ ایپلیکیشن دیکھ سکتے ہیں۔
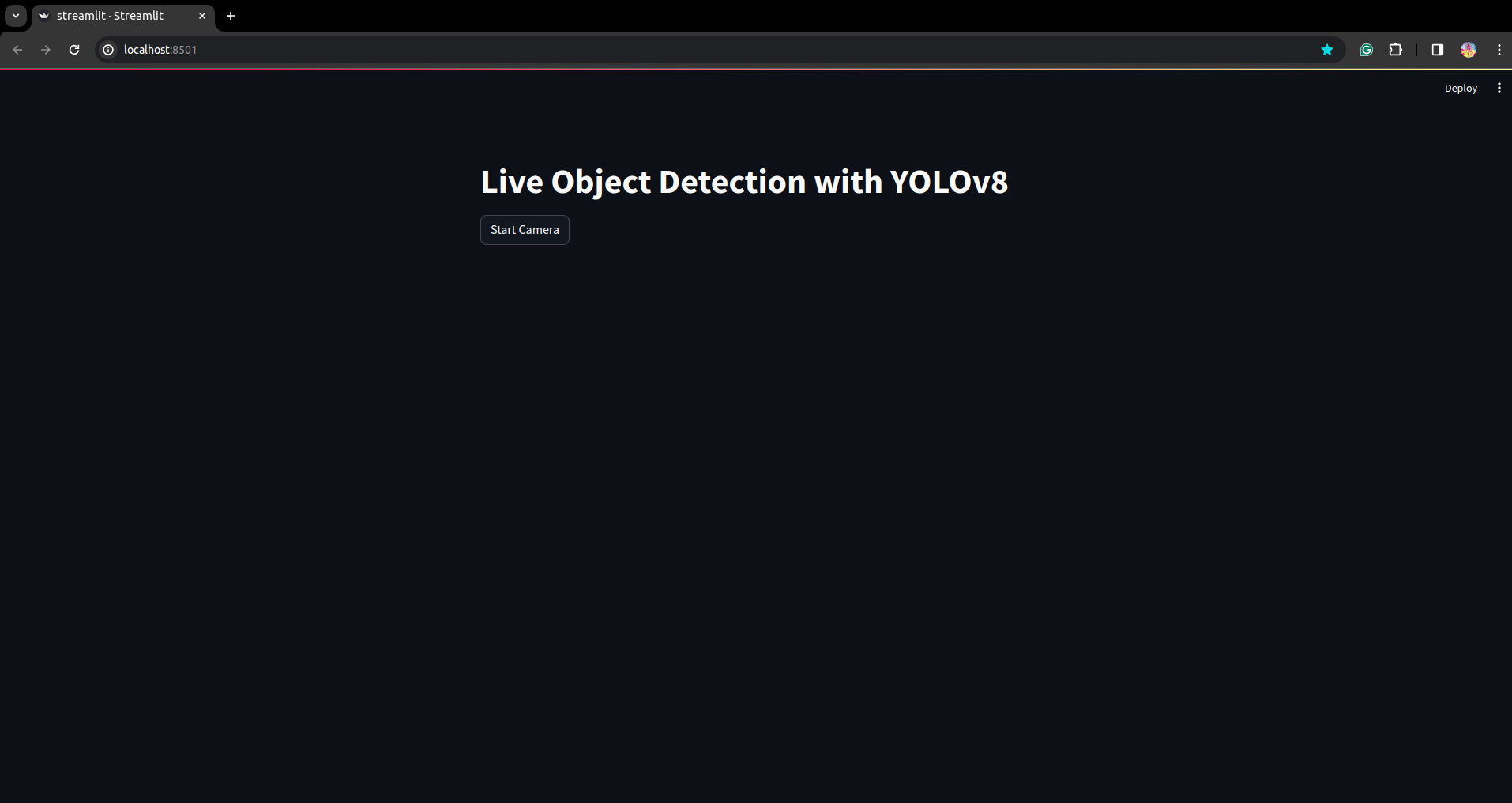
یہاں ہم ایک کامیاب لائیو ڈیٹیکشن ایپلی کیشن بنا سکتے ہیں اگلے حصے میں ہم سیگمنٹیشن کا حصہ دیکھیں گے۔
تشریح کے لیے اقدامات
مرحلہ 1: روبو فلو سیٹ اپ
سائن ان کرنے کے بعد "پروجیکٹ بنائیں"۔ یہاں آپ پروجیکٹ اور تشریح گروپ بنا سکتے ہیں۔

مرحلہ 2: ڈیٹا سیٹ ڈاؤن لوڈ کرنا
یہاں ہم سادہ مثال پر غور کرتے ہیں لیکن آپ اسے اپنے مسئلے کے بیان پر استعمال کرنا چاہتے ہیں لہذا میں یہاں بتھ ڈیٹا سیٹ استعمال کر رہا ہوں۔
یہ جاؤ لنک اور بطخ کا ڈیٹاسیٹ ڈاؤن لوڈ کریں۔

فولڈر کو نکالیں وہاں آپ تین فولڈر دیکھ سکتے ہیں: ٹرین، ٹیسٹ اور ویل.
مرحلہ 3: روبو فلو پر ڈیٹا سیٹ اپ لوڈ کرنا
روبو فلو میں پروجیکٹ بنانے کے بعد آپ اس UI کو یہاں دیکھ سکتے ہیں کہ آپ اپنا ڈیٹا سیٹ اپ لوڈ کر سکتے ہیں لہذا صرف ٹرین کے حصے کی تصاویر اپ لوڈ کر رہے ہیں "فولڈر منتخب کریں" آپشن.
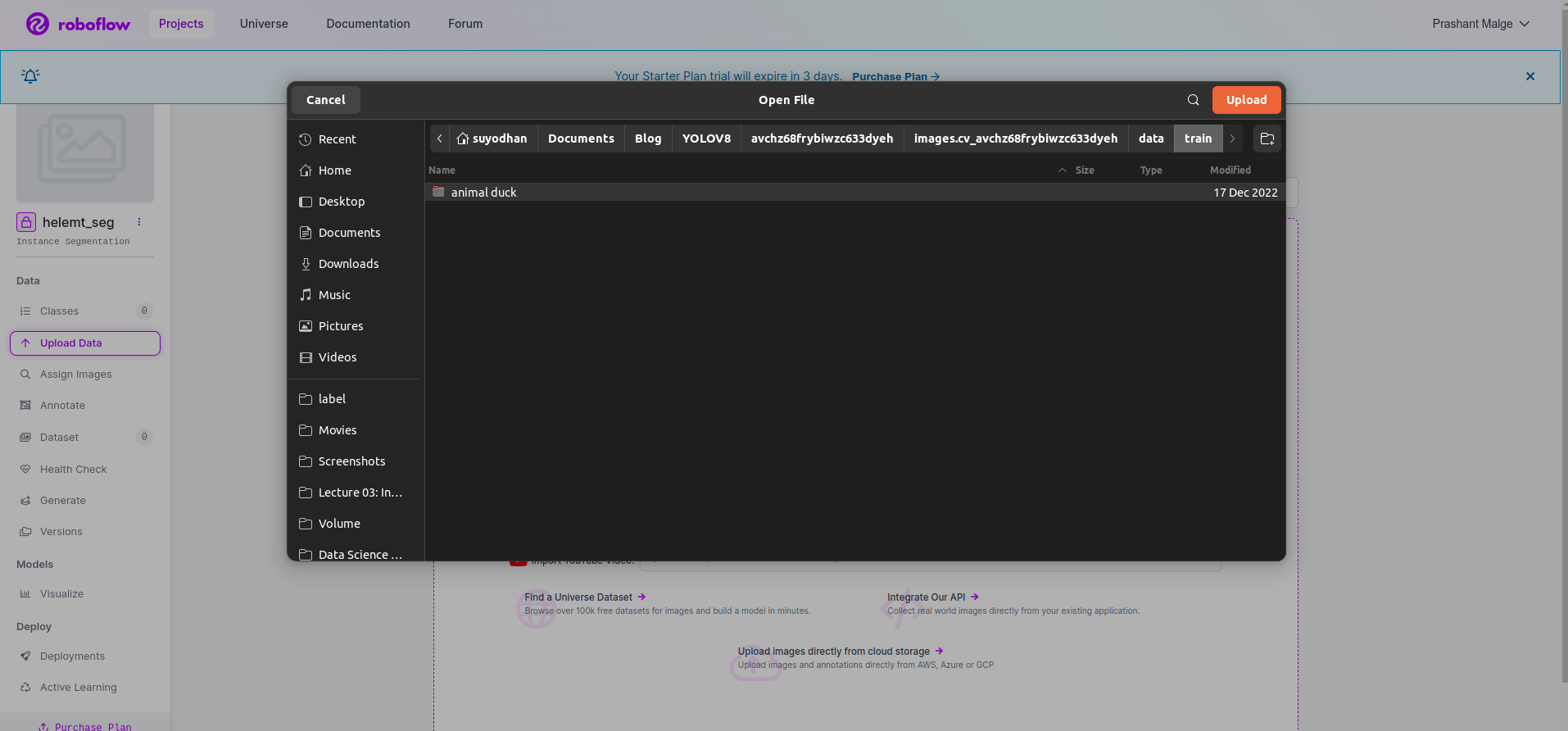
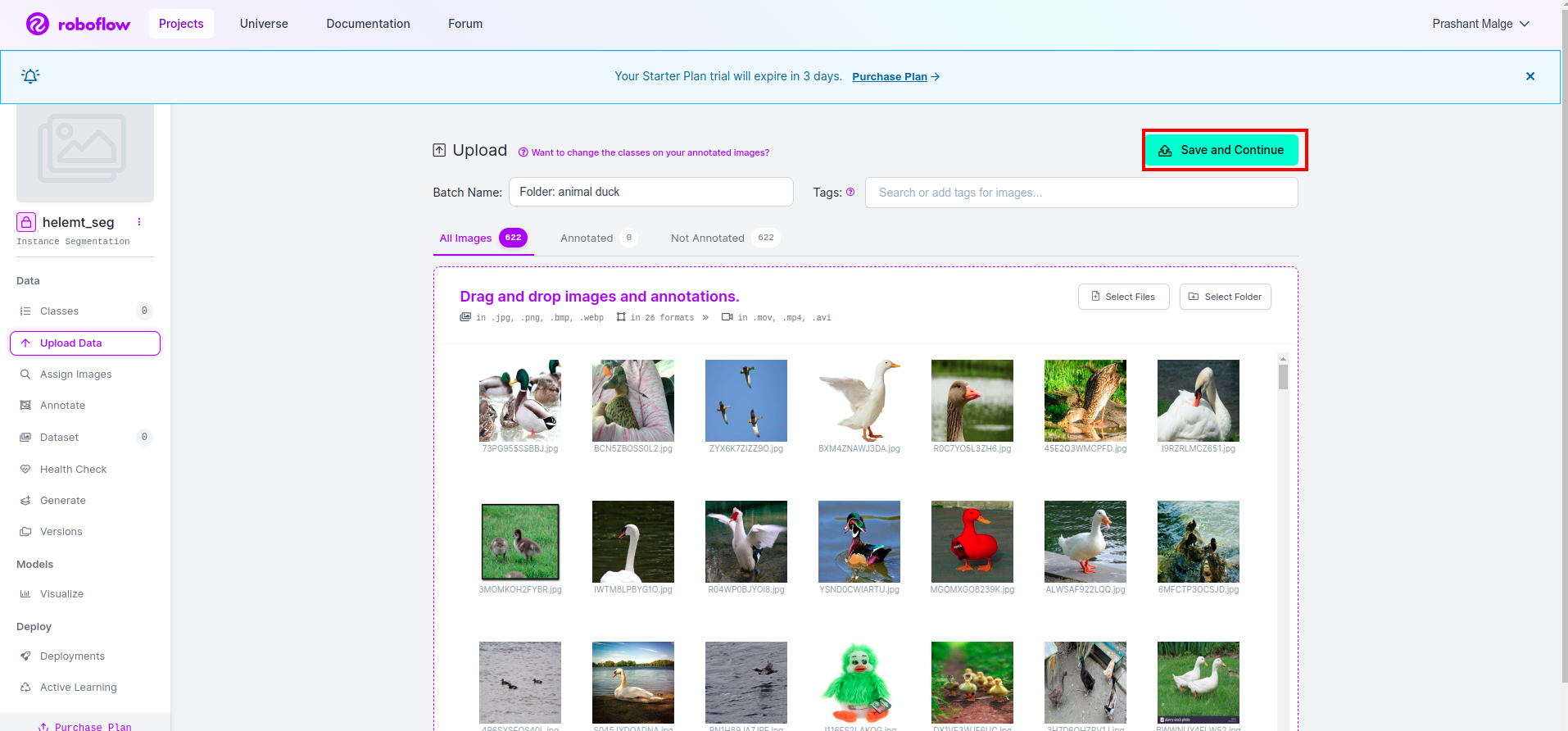
پھر "محفوظ کریں اور جاری رکھیں" آپشن جیسا کہ میں سرخ مستطیل باکس میں نشان زد کرتا ہوں۔
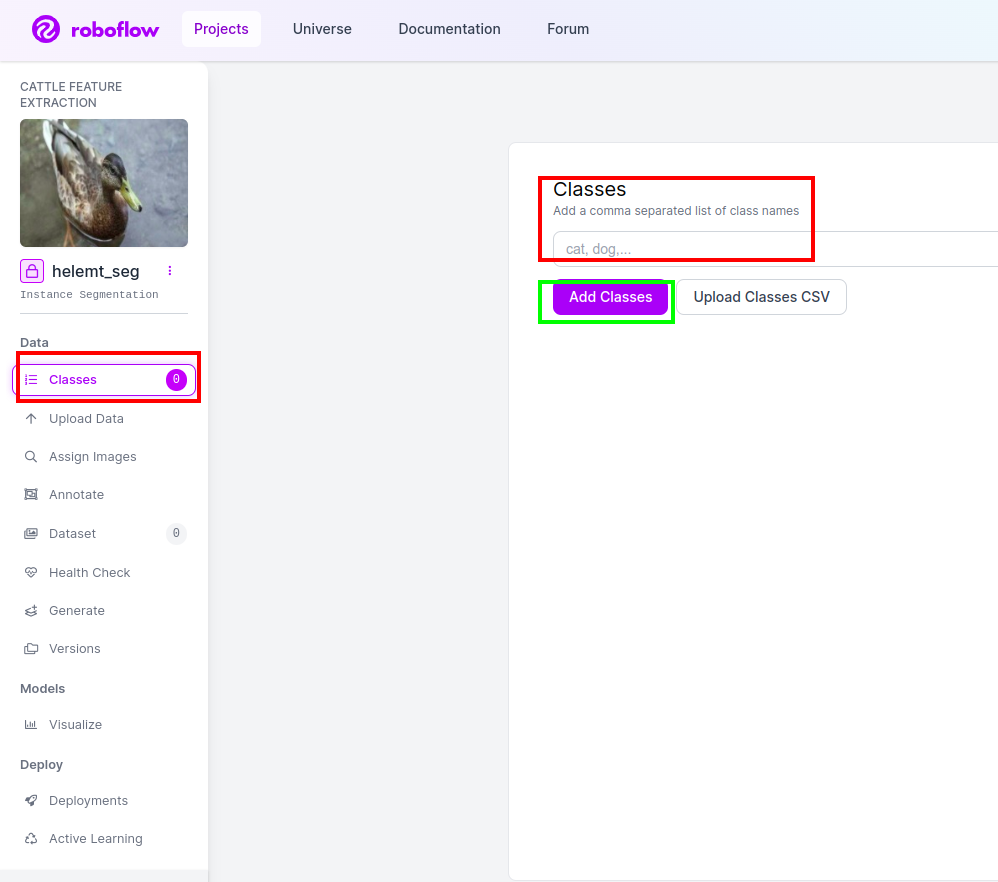
مرحلہ 4: کلاس کا نام شامل کریں۔
پھر جاؤ کلاس کا حصہ بائیں جانب سرخ باکس کو چیک کریں۔ اور کلاس کا نام لکھیں۔ بطخ، گرین باکس پر کلک کرنے کے بعد.
اب ہمارا سیٹ اپ مکمل ہے اور اگلا حصہ جیسا کہ تشریحی حصہ بھی آسان ہے۔
مرحلہ 5: شروع کریں۔ تشریح کا حصہ
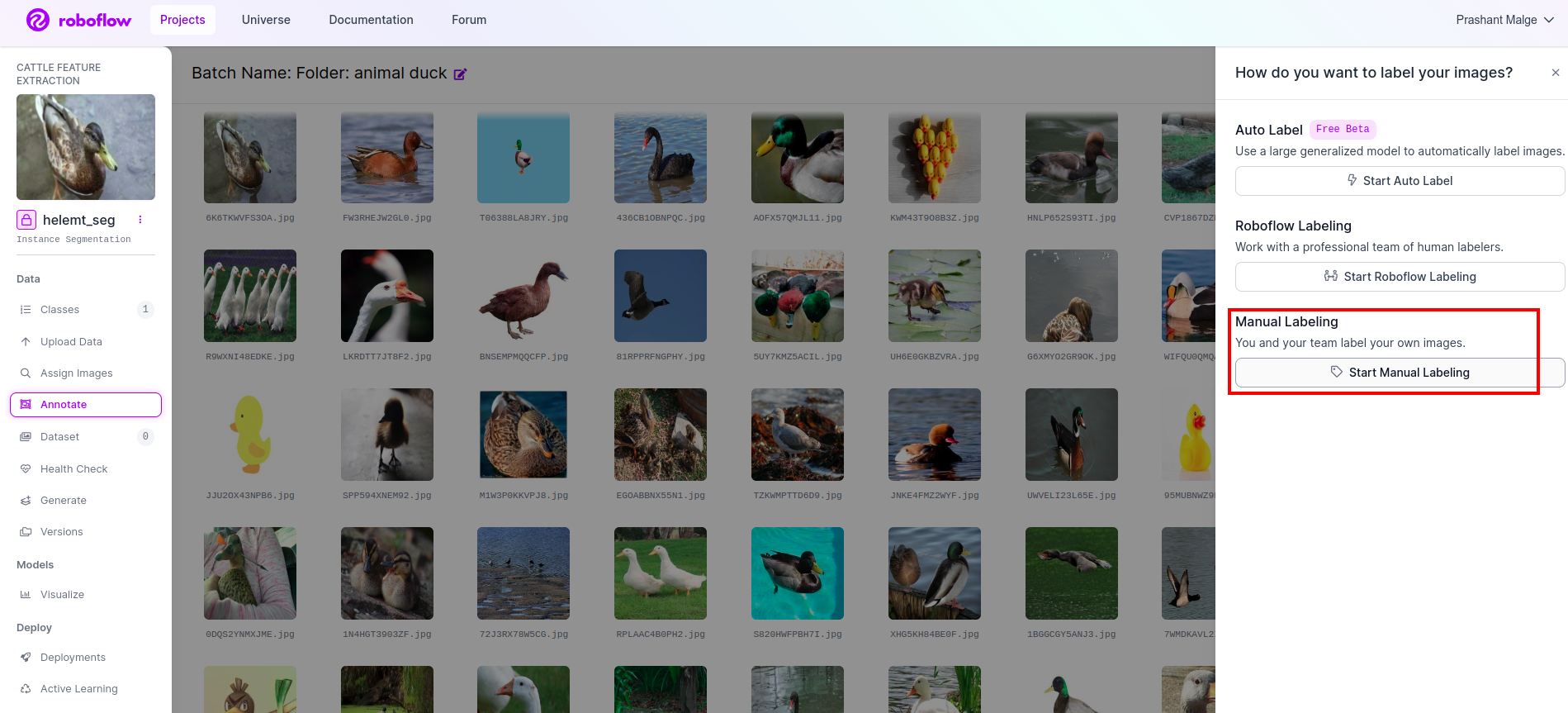
دیکھیں تشریح کا اختیار میں نے سرخ باکس میں نشان زد کیا اور پھر شروع کریں پر کلک کریں جیسا کہ میں نے سبز خانے میں نشان زد کیا ہے۔
پہلی تصویر پر کلک کریں جسے آپ یہ UI دیکھ سکتے ہیں۔ اسے دیکھنے کے بعد دستی تشریح کے آپشن پر کلک کریں۔
پھر اپنی ای میل آئی ڈی یا اپنے ساتھی کا نام شامل کریں تاکہ آپ کام تفویض کر سکیں۔
پہلی تصویر پر کلک کریں جسے آپ یہ UI دیکھ سکتے ہیں۔ یہاں سرخ باکس پر کلک کریں تاکہ آپ کثیر کثیر الثانی ماڈل کو منتخب کر سکیں۔
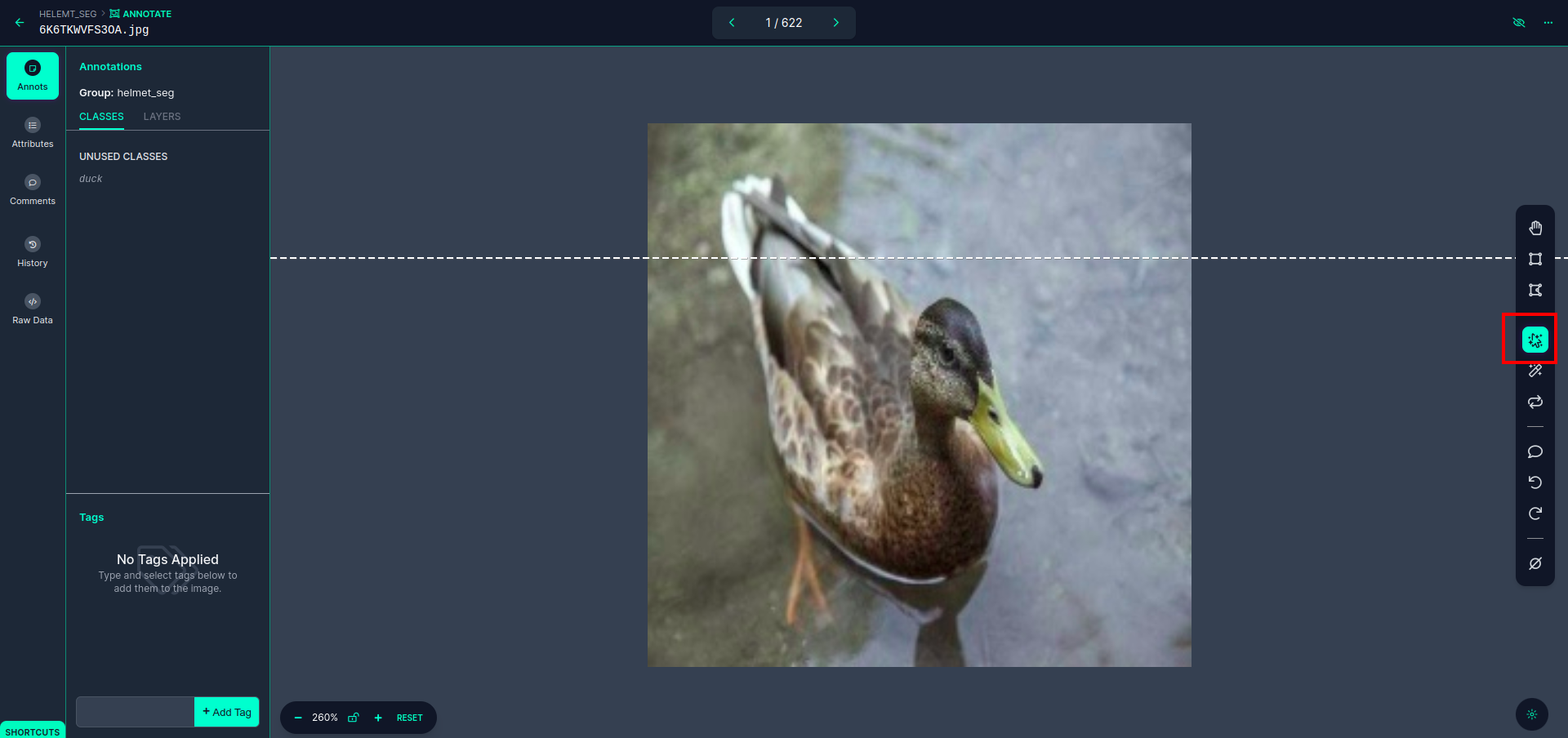
سرخ باکس پر کلک کرنے کے بعد، پہلے سے طے شدہ ماڈل کو منتخب کریں اور بطخ آبجیکٹ پر کلک کریں۔ یہ خود بخود تصویر کو الگ کر دے گا۔ پھر، اگلے حصے پر کلک کریں اور اسے محفوظ کریں۔ اس کے بعد آپ کو بائیں جانب سرخ باکس میں نشان زد نظر آئے گا، جہاں آپ کلاس کا نام دیکھ سکتے ہیں۔
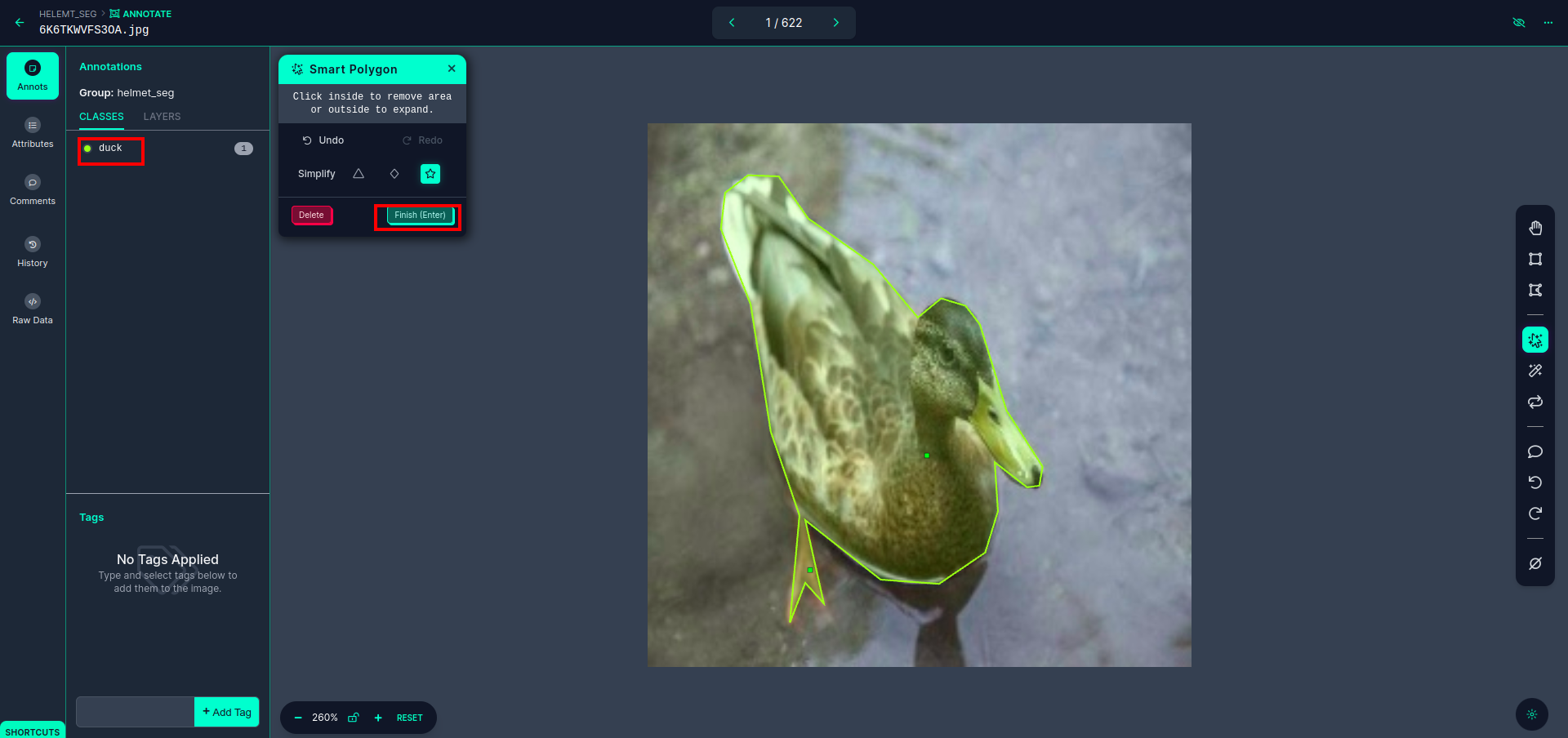
کلک کریں محفوظ کریں اور داخل کریں۔ اختیار تمام تصاویر کی تشریح کریں۔
YOLOv8 فارمیٹ کے لیے تصاویر شامل کریں۔ دائیں جانب، آپ کو تشریح سیکشن میں تصاویر شامل کرنے کا آپشن نظر آئے گا۔ یہاں، دو حصے بنائے گئے ہیں: ایک تشریح شدہ امیجز کے لیے اور ایک غیر تشریح شدہ امیجز کے لیے۔
- سب سے پہلے، بائیں طرف پر کلک کریں "تشریح" پھر اختیار شامل کریں تصاویر ڈیٹاسیٹ تک
- پھر اگلے پر کلک کریں "تصاویر شامل کریں".
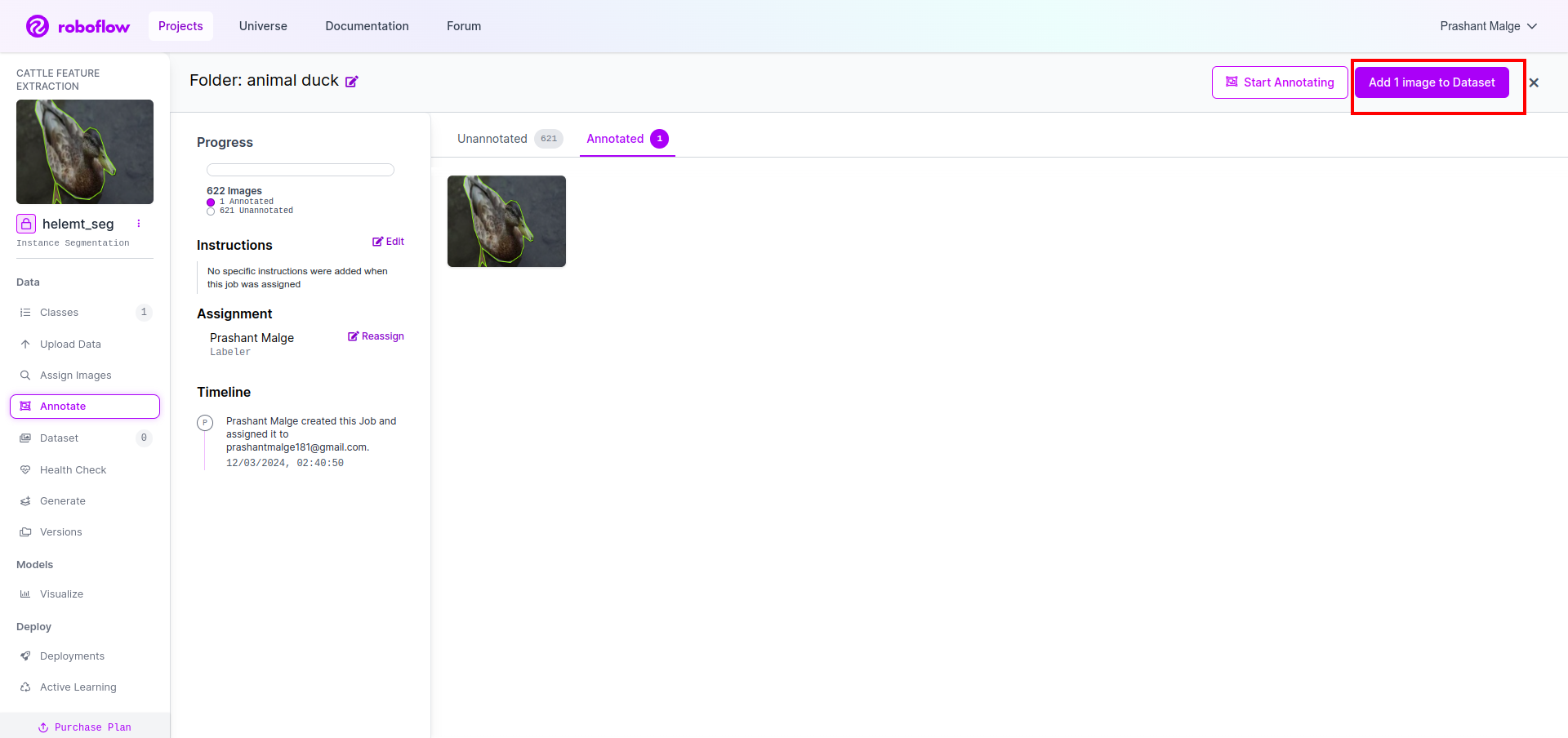
اب آخر میں، ہم ڈیٹاسیٹ بناتے ہیں تو بائیں جانب "جنریٹ" آپشن پر کلک کریں پھر آپشن کو چیک کریں اور کونٹیون آپشن کو دبائیں۔
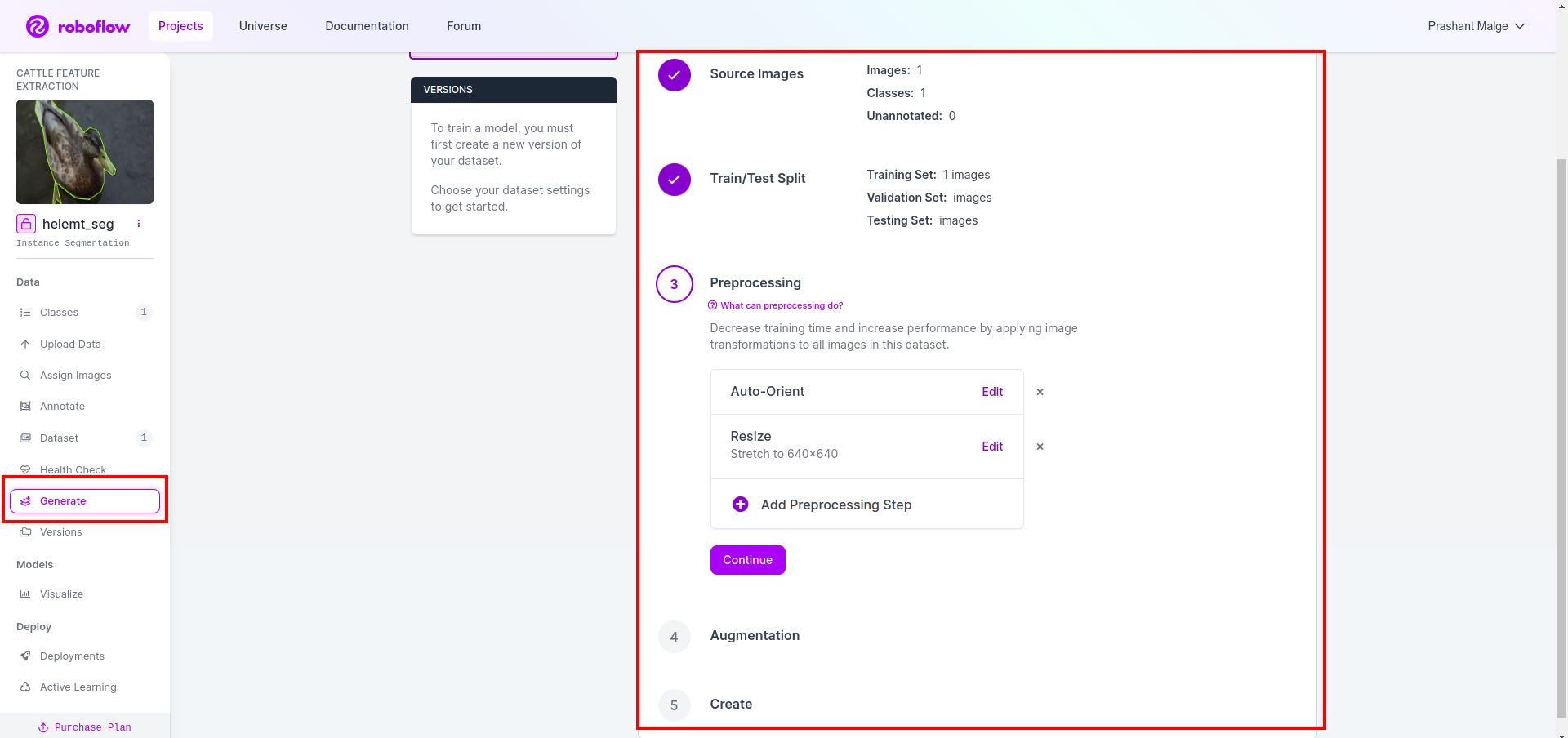
پھر آپ کو ڈیٹاسیٹ اسپلٹ آپشن کا UI ملتا ہے یہاں آپ ٹرین، ٹیسٹ اور ویل فولڈر کو چیک کر سکتے ہیں ان کی تصاویر خود بخود تقسیم ہو جاتی ہیں۔ اور اوپر والے سرخ باکس پر کلک کریں۔ ڈیٹا سیٹ کا اختیار برآمد کریں۔ اور zip فائل ڈاؤن لوڈ کریں۔ زپ فائل فولڈر کا ڈھانچہ اس طرح ہے…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
مرحلہ 6: امیج سیگمنٹیشن ماڈل کی تربیت کے لیے اسکرپٹ لکھیں۔
اس حصے میں پہلے، آپ Drive کا استعمال کرتے ہوئے Google Collab فائل بناتے ہیں پھر اپنا ڈیٹا سیٹ اپ لوڈ کرتے ہیں۔ اور گوگل کولیب کا استعمال کرتے ہوئے گوگل ڈرائیو کو ماؤٹ کریں۔
1. کے لیے یہ کمانڈ استعمال کریں۔ گوگل ڈرائیو ماؤنٹ کریں۔
from google.colab import drive
drive.mount('/content/gdrive')2. ڈیٹا ڈائریکٹری کی وضاحت کریں۔ مستقل متغیر کا استعمال کریں۔
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. مطلوبہ پیکیج کو انسٹال کرنا، الٹرالیٹکس انسٹال کریں۔
!pip install ultralytics4. لائبریریوں کو درآمد کرنا
import os
from ultralytics import YOLO5. لوڈ پہلے سے تربیت یافتہ YOLOv8 ماڈل (یہاں ہمارے پاس مختلف ماڈل ہیں سرکاری دستاویزات بھی چیک کریں وہاں آپ مختلف ماڈل دیکھ سکتے ہیں)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. ماڈل کو تربیت دیں۔
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together اپنی ڈرائیو کو چیک نہیں کریں ماڈل کے نام کا فولڈر بنایا گیا ہے اور وہاں ماڈل کو اس پیشین گوئی کے لیے محفوظ کیا گیا ہے جو ہم یہ ماڈل چاہتے ہیں۔
7. ماڈل کی پیشن گوئی کریں۔
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)یہاں آپ دیکھ سکتے ہیں کہ سیگمنٹیشن امیج محفوظ ہے۔

اب آخر کار ہم لائیو ڈیٹیکشن اور امیج سیگمنٹیشن ماڈل دونوں بنا سکتے ہیں۔
نتیجہ
اس بلاگ میں، ہم YOLOv8 کے ساتھ لائیو آبجیکٹ کا پتہ لگانے اور تصویر کی تقسیم کو دریافت کرتے ہیں۔ براہ راست پتہ لگانے کے لیے، ہم پہلے سے تربیت یافتہ YOLOv8 ماڈل درآمد کرتے ہیں اور کیمرہ کھولنے اور اشیاء کا پتہ لگانے کے لیے کمپیوٹر ویژن لائبریری، OpenCV کا استعمال کرتے ہیں۔ مزید برآں، ہم ایک پرکشش صارف انٹرفیس کے لیے ایک Streamlit ایپلیکیشن بناتے ہیں۔
اگلا، ہم YOLOv8 کے ساتھ امیج سیگمنٹیشن پر غور کرتے ہیں۔ ہم پہلے سے تربیت یافتہ ماڈل درآمد کرتے ہیں اور اپنی مرضی کے مطابق ڈیٹا سیٹ پر ٹرانسفر لرننگ انجام دیتے ہیں۔ اس سے پہلے، ہم نے ڈیٹاسیٹ تشریح کے لیے روبوفلو کو تلاش کیا، جو ٹولز کا استعمال میں آسان متبادل فراہم کرتا ہے جیسے لیبل آئی ایم جی.
آخر میں، ہم بطخ پر مشتمل ایک تصویر کی پیش گوئی کرتے ہیں۔ اگرچہ تصویر میں موجود شے ایک پرندہ دکھائی دیتی ہے، لیکن ہم کلاس کا نام بطور "جھکو"مظاہرے کے مقاصد کے لیے۔
کلیدی لے لو
- آبجیکٹ کا پتہ لگانے والے ماڈلز جیسے تیز R-CNN، SSD، اور تازہ ترین YOLOv8 کے بارے میں سیکھنا۔
- تشریحی ٹول روبوفلو اور YOLOv8 سیگمنٹیشن ماڈلز کے لیے ڈیٹا سیٹس بنانے میں اس کے کردار کو سمجھنا۔
- OpenCV (cv2) اور نگرانی کا استعمال کرتے ہوئے لائیو آبجیکٹ کا پتہ لگانا، عملی مہارتوں کو بڑھانا۔
- YOLOv8 کا استعمال کرتے ہوئے سیگمنٹیشن ماڈل کی تربیت اور تعیناتی، تجربہ حاصل کرنا۔
اکثر پوچھے گئے سوالات
A. آبجیکٹ کا پتہ لگانے میں ایک تصویر کے اندر ایک سے زیادہ اشیاء کی شناخت اور ان کا پتہ لگانا شامل ہے، عام طور پر ان کے ارد گرد باؤنڈنگ باکسز بنا کر۔ دوسری طرف تصویر کی تقسیم، پکسل کی مماثلت کی بنیاد پر کسی تصویر کو حصوں یا خطوں میں تقسیم کرتی ہے، جس سے آبجیکٹ کی حدود کی مزید تفصیلی تفہیم ملتی ہے۔
A. YOLOv8 نیٹ ورک فن تعمیر، تربیتی تکنیک، اور اصلاح میں پیشرفت کو شامل کرکے پچھلے ورژنز پر بہتر بناتا ہے۔ یہ YOLOv3 کے مقابلے میں بہتر درستگی، رفتار اور کارکردگی پیش کر سکتا ہے۔
A. YOLOv8 کو ایمبیڈڈ ڈیوائسز پر ریئل ٹائم آبجیکٹ کا پتہ لگانے کے لیے استعمال کیا جا سکتا ہے، یہ ہارڈ ویئر کی صلاحیتوں اور ماڈل کی اصلاح پر منحصر ہے۔ تاہم، وسائل سے محدود آلات پر حقیقی وقت کی کارکردگی کو حاصل کرنے کے لیے ماڈل کی کٹائی یا کوانٹائزیشن جیسی اصلاح کی ضرورت پڑ سکتی ہے۔
A. Roboflow بدیہی تشریحی ٹولز، ڈیٹاسیٹ کے انتظام کی خصوصیات، اور تشریح کے مختلف فارمیٹس کے لیے تعاون پیش کرتا ہے۔ یہ تشریح کے عمل کو ہموار کرتا ہے، تعاون کو قابل بناتا ہے، اور ورژن کنٹرول فراہم کرتا ہے، جس سے کمپیوٹر ویژن پروجیکٹس کے لیے ڈیٹا سیٹس بنانا اور ان کا نظم کرنا آسان ہوجاتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

